Curso
Minería de texto con Bag-of-Words en R
4 h
44.3K
Los datos de texto son uno de los tipos de datos más comunes que utilizan las empresas hoy en día, pero como no tienen una estructura clara, puede ser difícil y llevar mucho tiempo extraer información de los datos de texto. El tratamiento de datos de texto se enmarca en el Procesamiento del Lenguaje Natural, uno de los subcampos de la inteligencia artificial.
El Procesamiento del Lenguaje Natural (PLN ) es un campo de la informática y la inteligencia artificial que estudia cómo interactúan los ordenadores con las lenguas humanas y cómo programar ordenadores para procesar y analizar grandes cantidades de datos del lenguaje natural.
La PNL se utiliza de muchas formas diferentes, como responder preguntas automáticamente, generar resúmenes de textos, traducir textos de un idioma a otro, etc. La investigación en PNL también se lleva a cabo en áreas como las ciencias cognitivas, la lingüística y la psicología. La clasificación de textos es uno de estos casos de uso de la PNL.
Este blog explorará los casos de uso de la clasificación de textos. También contiene un ejemplo de principio a fin de cómo construir un canal de preprocesamiento de texto seguido de un modelo de clasificación de texto en Python.
Si desea obtener más información sobre el procesamiento del lenguaje natural, le resultarán útiles nuestros temas Procesamiento del lenguaje natural en Python y Procesamiento del lenguaje natural en R. Adquirirá los conocimientos básicos de PNL necesarios para convertir esos datos de texto en información valiosa. También se le presentarán las bibliotecas de Python NLP más conocidas, como NLTK, scikit-learn, spaCy y SpeechRecognition.
La clasificación de textos es una tarea habitual de la PNL que se utiliza para resolver problemas empresariales en diversos campos. El objetivo de la clasificación de textos es categorizar o predecir una clase de documentos de texto no vistos, a menudo con la ayuda del aprendizaje automático supervisado.
Al igual que un algoritmo de clasificación que se ha entrenado en un conjunto de datos tabulares para predecir una clase, la clasificación de texto también utiliza el aprendizaje automático supervisado. El hecho de que en la clasificación de textos intervenga el texto es la principal distinción entre ambas.
También puede realizar la clasificación de textos sin utilizar el aprendizaje automático supervisado. En lugar de algoritmos, se puede diseñar un sistema manual basado en reglas para realizar la tarea de clasificación de textos. En la siguiente sección compararemos y analizaremos los pros y los contras de los sistemas de clasificación de texto basados en reglas y en aprendizaje automático.
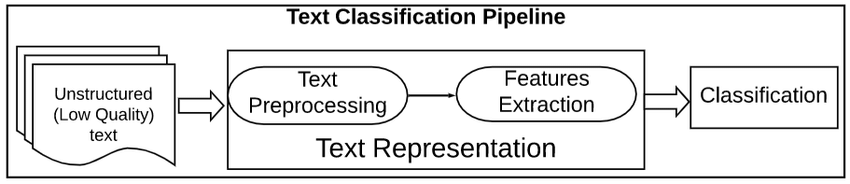
Si desea obtener más información sobre el aprendizaje automático supervisado, consulte nuestro artículo independiente.
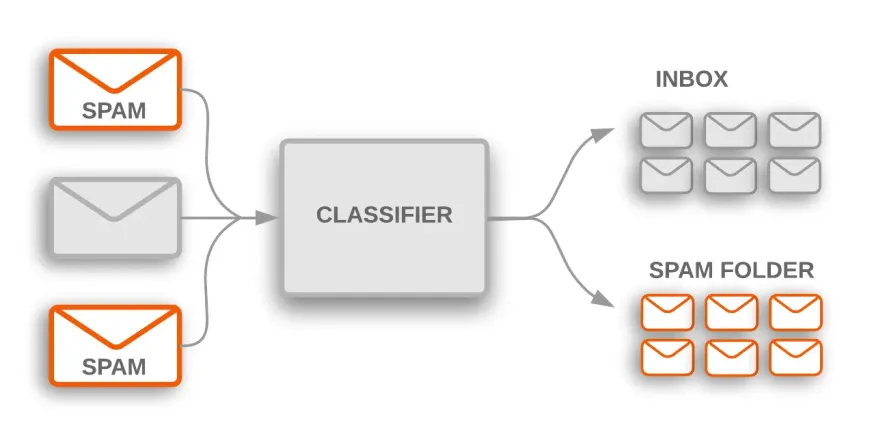
La clasificación de textos tiene muchos usos prácticos en numerosos sectores. Por ejemplo, un filtro de spam es una aplicación común que utiliza la clasificación de texto para clasificar los correos electrónicos en categorías de spam y no spam.
Otro caso de uso es la asignación automática de documentos de texto a categorías predeterminadas. Un modelo de aprendizaje automático supervisado se entrena con datos etiquetados, que incluyen tanto el texto en bruto como el objetivo. Una vez entrenado el modelo, se utiliza en producción para obtener una categoría (etiqueta) sobre los datos nuevos y no vistos (artículos/blogs escritos en el futuro).
Una empresa puede utilizar la clasificación de texto para categorizar automáticamente las solicitudes de atención al cliente por temas o para priorizar y dirigir las solicitudes al departamento adecuado.
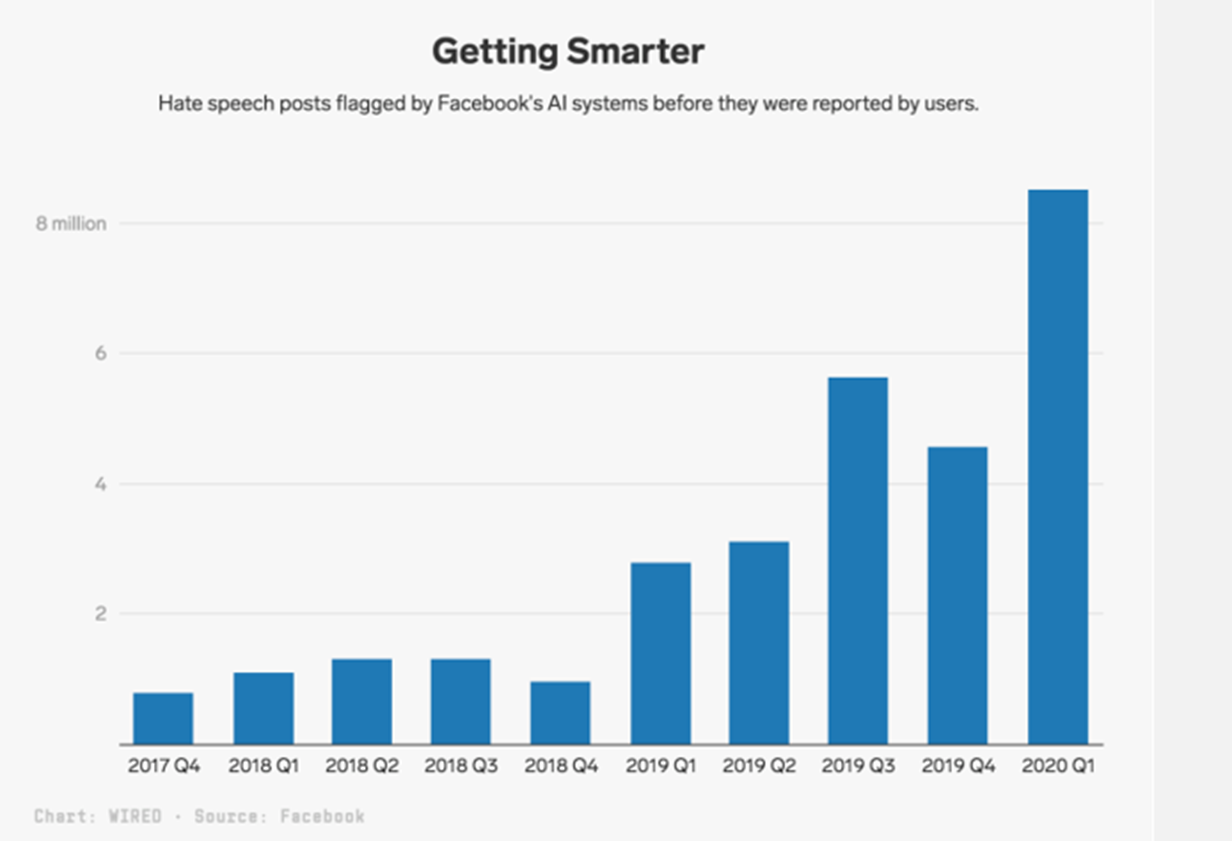
Con más de 1.700 millones de usuarios activos diarios, es inevitable que en Facebook se creen contenidos contrarios a las normas. La incitación al odio está incluida en estos contenidos indeseables.
Facebook aborda este problema solicitando una revisión manual de las publicaciones que un clasificador de texto de IA ha identificado como incitación al odio. Las publicaciones marcadas por AI se examinan de la misma manera que las publicaciones denunciadas por los usuarios. De hecho, solo en los tres primeros meses de 2020, la plataforma eliminó 9,6 millones de contenidos clasificados como incitación al odio.
Existen principalmente dos tipos de sistemas de clasificación de textos: los basados en reglas y los basados en aprendizaje automático.
Las técnicas basadas en reglas utilizan un conjunto de reglas lingüísticas construidas manualmente para clasificar el texto en categorías o grupos. Estas reglas indican al sistema que clasifique el texto en una categoría determinada basándose en el contenido de un texto mediante elementos textuales semánticamente relevantes. Cada regla se compone de un antecedente o patrón y una categoría proyectada.
Por ejemplo, imagine que tiene montones de artículos nuevos y su objetivo es asignarlos a categorías relevantes como Deportes, Política, Economía, etc.
Con un sistema de clasificación basado en reglas, realizará una revisión humana de un par de documentos para llegar a reglas lingüísticas como ésta:
Los sistemas basados en reglas pueden perfeccionarse con el tiempo y son comprensibles para el ser humano. Sin embargo, esta estrategia presenta ciertos inconvenientes.
Estos sistemas, para empezar, exigen profundos conocimientos en la materia. Llevan mucho tiempo, ya que crear normas para un sistema complicado puede ser difícil y a menudo requiere un estudio y unas pruebas exhaustivas.
Dado que añadir nuevas reglas puede alterar los resultados de las reglas preexistentes, los sistemas basados en reglas también son difíciles de mantener y no se amplían eficazmente.
La clasificación de textos basada en el aprendizaje automático es un problema de aprendizaje automático supervisado. Aprende el mapeo de los datos de entrada (texto en bruto) con las etiquetas (también conocidas como variables objetivo). Esto es similar a los problemas de clasificación no textual en los que entrenamos un algoritmo de clasificación supervisado en un conjunto de datos tabulares para predecir una clase, con la excepción de que en la clasificación textual, los datos de entrada son texto en bruto en lugar de características numéricas.
Como cualquier otro aprendizaje automático supervisado, el aprendizaje automático de clasificación de textos consta de dos fases: entrenamiento y predicción.
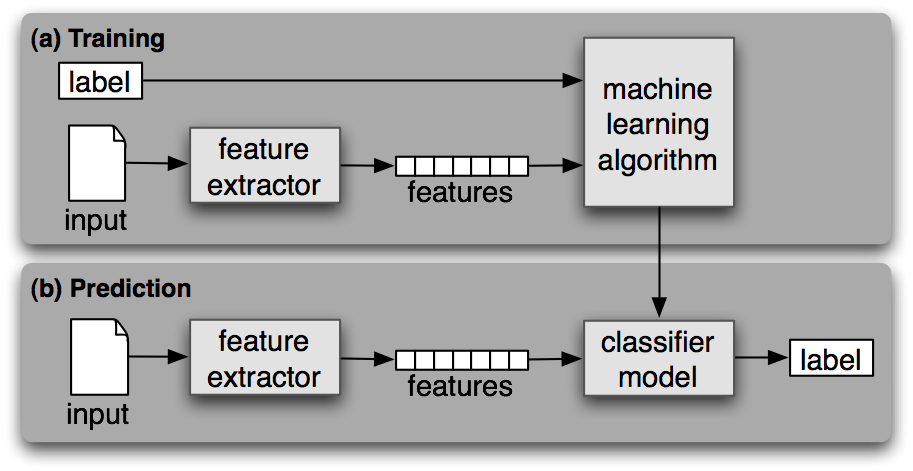
Durante la fase de formación, se entrena un algoritmo de aprendizaje automático supervisado en el conjunto de datos de entrada etiquetados. Al final de este proceso, obtenemos un modelo entrenado que podemos utilizar para obtener predicciones (etiquetas) sobre datos nuevos y no vistos.
Una vez entrenado un modelo de aprendizaje automático, puede utilizarse para predecir etiquetas en datos nuevos y no vistos. Esto suele hacerse desplegando el mejor modelo de una fase anterior como API en el servidor.
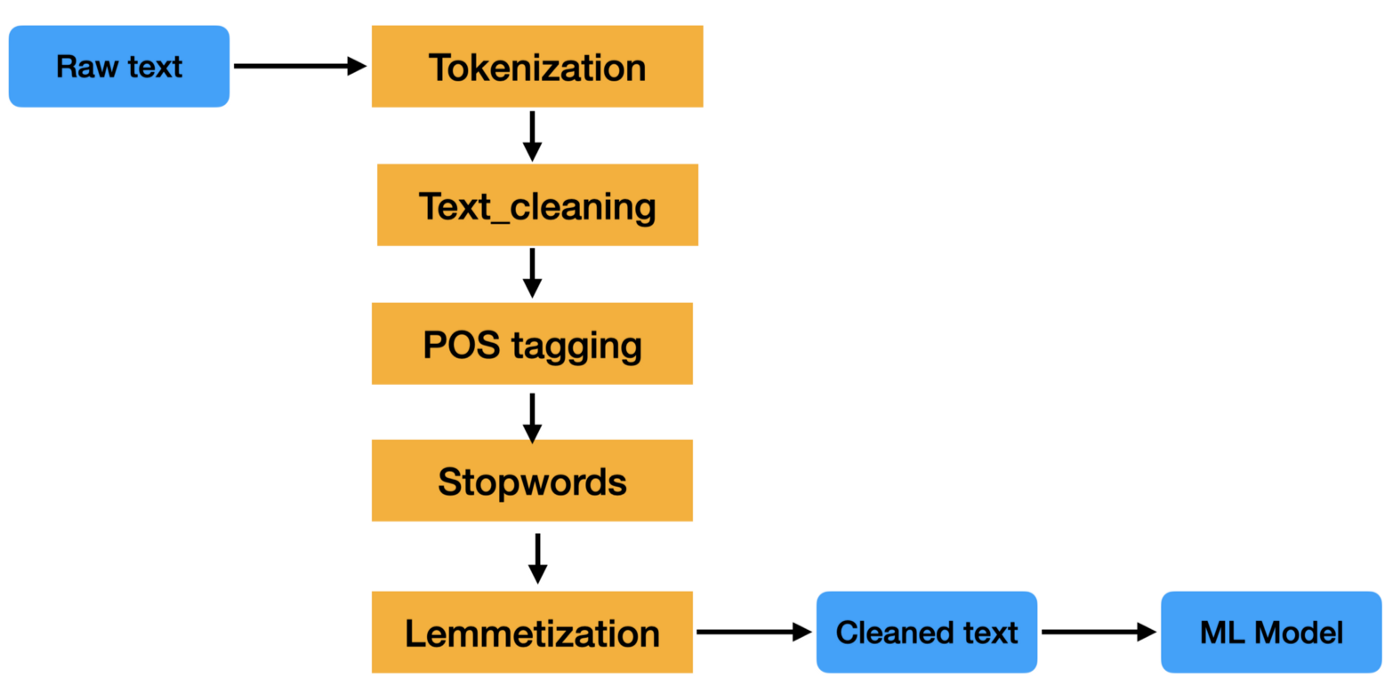
El preprocesamiento de datos de texto es un paso importante en cualquier tarea de procesamiento del lenguaje natural. Ayuda a limpiar y preparar los datos de texto para su posterior tratamiento o análisis.
Un proceso de preprocesamiento de texto es una serie de pasos que se aplican a los datos de texto sin procesar para prepararlos para su uso en tareas de procesamiento del lenguaje natural.
Los pasos de un proceso de preprocesamiento de texto pueden variar, pero suelen incluir tareas como la tokenización, la eliminación de palabras vacías, la separación de palabras y la lematización. Estos pasos ayudan a reducir el tamaño de los datos de texto y también a mejorar la precisión de tareas de PLN como la clasificación de textos y la extracción de información.
Los datos de texto son difíciles de procesar porque no están estructurados y suelen contener mucho ruido. Este ruido puede consistir en faltas de ortografía, errores gramaticales y formatos no estándar. El objetivo de un proceso de preprocesamiento de texto es eliminar este ruido para que los datos puedan analizarse más fácilmente.
¿Quiere saber más? Consulte nuestro tema Minería de textos con R.
Los dos métodos más comunes para extraer características del texto o, en otras palabras, convertir datos de texto (cadenas) en características numéricas para poder entrenar el modelo de aprendizaje automático son: Bag of Words (también conocido como CountVectorizer) y Tf-IDF.
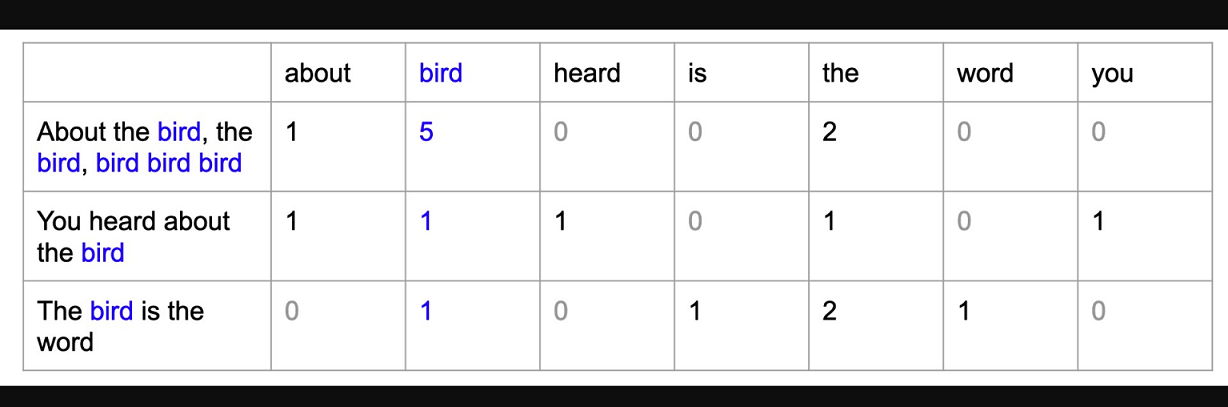
Un modelo de bolsa de palabras (BoW) es una forma sencilla de representar datos de texto como características numéricas. Consiste en crear un vocabulario de palabras conocidas en el corpus y, a continuación, crear un vector para cada documento que contenga recuentos de la frecuencia con la que aparece cada palabra.
TF-IDF significa frecuencia de términos-frecuencia inversa de documentos, y es otra forma de representar texto como características numéricas. El modelo Bag of Words (BoW) presenta algunas deficiencias que Tf-IDF supera. No entraremos en detalles al respecto en este artículo, pero si quieres profundizar en este concepto, consulta nuestro curso Introducción al Procesamiento del Lenguaje Natural en Python.
El modelo TF-IDF se diferencia del modelo de bolsa de palabras en que tiene en cuenta la frecuencia de las palabras del documento, así como la frecuencia inversa del documento. Esto significa que el modelo TF-IDF tiene más probabilidades de identificar las palabras importantes de un documento que el modelo de bolsa de palabras.
En primer lugar, empieza importando el conjunto de datos directamente desde este enlace de GitHub. La colección SMS Spam es un conjunto de datos que contiene 5.574 mensajes SMS en inglés con la etiqueta Spam o Ham (no spam). Nuestro objetivo es entrenar un modelo de aprendizaje automático que aprenda del texto del SMS y de la etiqueta y sea capaz de predecir la clase de los mensajes SMS.
# reading data
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/mohitgupta-omg/Kaggle-SMS-Spam-Collection-Dataset-/master/spam.csv', encoding='latin-1')
data.head()
Después de leer el conjunto de datos, observe que hay algunas columnas adicionales que no necesitamos. Sólo necesitamos las dos primeras columnas. Sigamos adelante y eliminemos las columnas restantes y también cambiemos el nombre de las dos primeras columnas.
# drop unnecessary columns and rename cols
data.drop(['Unnamed: 2', 'Unnamed: 3', 'Unnamed: 4'], axis=1, inplace=True)
data.columns = ['label', 'text']
data.head()
Hagamos un EDA básico para ver si faltan valores en el conjunto de datos y cuál es el equilibrio objetivo.
# check missing values
data.isna().sum()
# check data shape
data.shape>>> (5572, 2)# check target balance
data['label'].value_counts(normalize = True).plot.bar()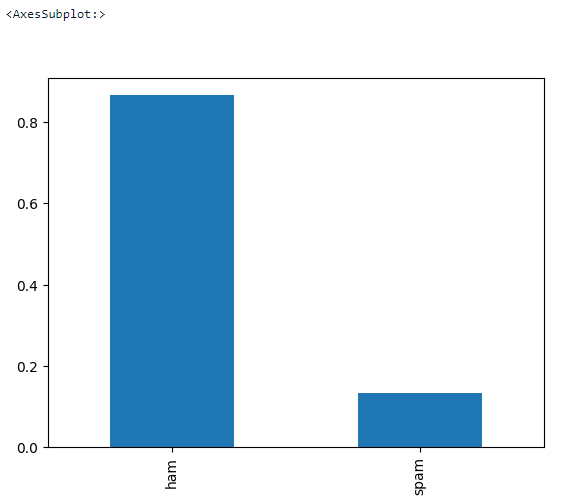
Aquí es donde tiene lugar toda la limpieza del texto. Es un bucle que itera a través de los 5.572 documentos y hace lo siguiente:
# text preprocessing
# download nltk
import nltk
nltk.download('all')
# create a list text
text = list(data['text'])
# preprocessing loop
import re
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
corpus = []
for i in range(len(text)):
r = re.sub('[^a-zA-Z]', ' ', text[i])
r = r.lower()
r = r.split()
r = [word for word in r if word not in stopwords.words('english')]
r = [lemmatizer.lemmatize(word) for word in r]
r = ' '.join(r)
corpus.append(r)
#assign corpus to data['text']
data['text'] = corpus
data.head()
Dividamos el conjunto de datos en entrenamiento y prueba antes de la extracción de características.
# Create Feature and Label sets
X = data['text']
y = data['label']
# train test split (66% train - 33% test)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=123)
print('Training Data :', X_train.shape)
print('Testing Data : ', X_test.shape)>>> Training Data : (3733,)
>>> Testing Data : (1839,)Aquí utilizamos el modelo de bolsa de palabras (CountVectorizer) para convertir el texto depurado en características numéricas. Esto es necesario para entrenar el modelo de aprendizaje automático.
# Train Bag of Words model
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
X_train_cv = cv.fit_transform(X_train)
X_train_cv.shape>>> (3733, 7020)En esta parte, entrenamos un modelo de Regresión Logística y evaluamos la matriz de confusión del modelo entrenado.
# Training Logistic Regression model
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train_cv, y_train)
# transform X_test using CV
X_test_cv = cv.transform(X_test)
# generate predictions
predictions = lr.predict(X_test_cv)
predictions>>> array(['ham', 'spam', 'ham', ..., 'ham', 'ham', 'spam'], dtype=object)# confusion matrix
import pandas as pd
from sklearn import metrics
df = pd.DataFrame(metrics.confusion_matrix(y_test,predictions), index=['ham','spam'], columns=['ham','spam'])
df
Consulta el cuaderno completo de DataLab para obtener más información.
La PNL sigue siendo un área activa de investigación y desarrollo, con muchas universidades y empresas trabajando en el desarrollo de nuevos algoritmos y aplicaciones. La PNL es un campo interdisciplinar en el que los investigadores proceden de diversos campos, como la informática, la lingüística, la psicología y las ciencias cognitivas.
La clasificación de textos es una tarea potente y ampliamente utilizada en PNL que puede emplearse para categorizar o predecir automáticamente una clase de documentos de texto no vistos, a menudo con ayuda del aprendizaje automático supervisado.
No siempre es preciso, pero cuando se utiliza correctamente, puede añadir mucho valor a sus análisis. Hay muchas formas y algoritmos diferentes de configurar un clasificador de texto, y no hay un único enfoque que sea el mejor. Es importante experimentar y encontrar lo que funciona mejor para tus datos y tus objetivos.
Cursos superiores
Curso
Curso
Curso
blog
Zoumana Keita
14 min
Tutorial
Moez Ali
Tutorial
Moez Ali
Tutorial
Avinash Navlani
