La Interfaz de Línea de Comandos (CLI) de Databricks es una potente herramienta que permite a los usuarios automatizar tareas en la plataforma Databricks directamente desde el terminal o símbolo del sistema. Con la CLI, los usuarios pueden ejecutar comandos para gestionar clusters, trabajos y blocs de notas sin necesidad de navegar por la interfaz gráfica, lo que mejora la eficacia y la integración en flujos de trabajo automatizados.
Por ahora, la CLI de Databricks está en Vista Previa Pública para las versiones 0.205 y superiores. Los usuarios que utilicen versiones anteriores deben tener en cuenta que éstas se consideran heredadas y pueden no ser compatibles con las últimas funciones o mejoras disponibles en las versiones más recientes.
En este tutorial, te mostraré cómo instalar la CLI y cómo navegar por ella con los principales comandos para automatizar tus flujos de trabajo. Para empezar, te recomiendo encarecidamente que consultes el sitio web de DataCamp Cómo aprender Databricks: Guía para principiantes de la Plataforma Unificada de Datos entrada de blog para ayudarte a comprender las características y aplicaciones básicas de Databricks y proporcionarte un camino estructurado para iniciar tu aprendizaje.
Por qué utilizamos la CLI de Databricks
Como usuario frecuente, encuentro las siguientes razones por las que deberías utilizar la CLI de Databricks.
- Automatización: La CLI te permite programar operaciones como la creación de clusters, el envío de trabajos y la gestión de libretas. Esta automatización ahorra tiempo y reduce la probabilidad de cometer errores. Por ejemplo, puedes crear y ejecutar trabajos con un solo comando.
- Integración: La CLI de Databricks te permite integrarte a la perfección con los pipelines DevOps y los procesos CI/CD. Utilizando esta funcionalidad, puedes configurar fácilmente tus entornos para automatizar las implantaciones y actualizaciones de los flujos de trabajo de Databricks sin intervención manual. Por ejemplo, puedes activar trabajos automatizados directamente desde herramientas como Jenkins, Acciones de GitHub o Azure DevOps.
- Simplicidad: Puedes ejecutar tareas directamente desde tu máquina local, evitando la necesidad de navegar por la interfaz web para las tareas rutinarias. Esta función facilita la gestión de tus flujos de trabajo ejecutando comandos para realizar operaciones como subir cuadernos o gestionar clusters sin la sobrecarga de una interfaz gráfica.
- Flexibilidad: La CLI de Databricks es compatible con una amplia gama de sistemas operativos y entornos, como Windows, macOS y Linux, lo que la hace accesible a equipos diversos. La CLI también admite la autenticación multiperfil, lo que te permite gestionar con eficacia varias cuentas o espacios de trabajo de Databricks.
Instalación y actualización de la CLI de Databricks
Para empezar a utilizar la CLI de Databricks, debes cumplir los requisitos previos del entorno y seguir las instrucciones de instalación específicas de tu sistema operativo. Te mostraré cómo configurar el entorno y actualizar la CLI en Linux, macOS y Windows.
Requisitos previos del entorno
Antes de instalar la CLI de Databricks, asegúrate de que tu sistema cumple estos requisitos básicos:
- Un gestor de paquetes: Aunque un gestor de paquetes como Homebrew (para macOS) o WinGet (para Windows) puede simplificar la instalación, también puedes instalarlo directamente utilizando los binarios o el código fuente.
- Pitón: La CLI requiere Python 3.6 o posterior.
- Acceso en red al espacio de trabajo Databricks.
- Riza: Para algunos métodos de instalación en Linux y macOS, asegúrate de que curl está instalado.
- Privilegios de administrador (para algunos métodos de instalación).
Instalación en Linux
Existen varios métodos para instalar la CLI de Databricks en Linux, entre los que se incluyen los siguientes:
Utilizar Homebrew
Si tienes Homebrew instalado, ejecútalo:
brew install databricks-cliUtilizar el rizo
Puedes descargar e instalar Databricks CLI utilizando curl ejecutando el siguiente comando:
curl -Lo databricks-cli.tar.gz https://github.com/databricks/databricks-cli/releases/latest/download/databricks-cli.tar.gz
tar -xzf databricks-cli.tar.gz -C /usr/local/binDescarga manual
Alternativamente, puedes descargar el binario CLI desde el repositorio oficial de Databricks CLI en GitHub y moverlo a un directorio en tu PATH.
Instalación en macOS
Si utilizas macOS, puedes instalar la CLI de Databricks utilizando los siguientes comandos.
Utilizar Homebrew
Ejecuta el siguiente comando para instalar Databricks CLI;
brew install databricks-cliInstalación binaria directa
Descarga el último binario de las versiones de GitHub, extráelo y colócalo en tu PATH local. Hazlo ejecutable utilizando el comando que aparece a continuación:
chmod +x /usr/local/bin/databricksDescarga manual
Del mismo modo, puedes descargar el binario CLI del repositorio oficial de Databricks CLI en GitHub y moverlo a un directorio de tu PATH.
Instalación en Windows
Si utilizas el sistema operativo Windows, puedes elegir instalar Databricks CLI de los siguientes métodos:
Utilizar WinGet
Ejecuta el siguiente comando en el símbolo del sistema:
winget install Databricks.DatabricksCLIUtilizar Chocolatey
Si tienes instalado Chocolatey, úsalo:
choco install databricks-cliUtilizar el Subsistema Windows para Linux (WSL)
Si WSL está configurado, sigue los pasos de instalación de Linux.
Instalación binaria directa
Descarga el archivo .exe del repositorio GitHub de Databricks CLI.
Añade el directorio que contiene el archivo a la página PATH de tu sistema para facilitar el acceso.
Verificar la instalación
Tras la instalación, debes comprobar que la CLI de Databricks está instalada correctamente. Abre un terminal o símbolo del sistema y ejecuta
databricks --versionAutenticación y configuración de la CLI de Databricks
Para utilizar eficazmente la CLI de Databricks, necesitas autenticarla con tu espacio de trabajo Databricks. En esta sección, explicaré cómo establecer la autenticación y gestionar las configuraciones.
Generar un token de acceso personal
Se necesita un token de acceso personal (PAT) para autenticarse con la CLI de Databricks. Sigue estos pasos para generar uno:
Paso 1: Acceder a la configuración de usuario
Entra en tu espacio de trabajo Databricks y haz clic en tu nombre de usuario en la barra superior. Selecciona Configuración en el menú desplegable.
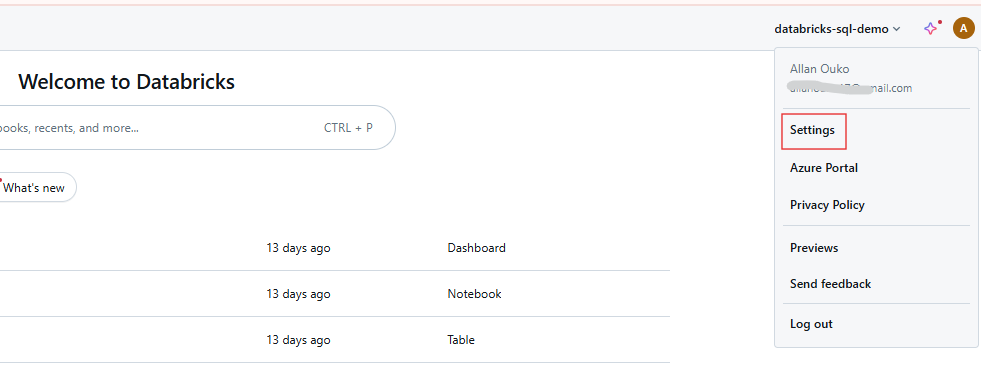
Configuración del usuario del espacio de trabajo Databricks. Imagen del autor.
Paso 2: Accede a la configuración del desarrollador
Haz clic en Desarrollador.
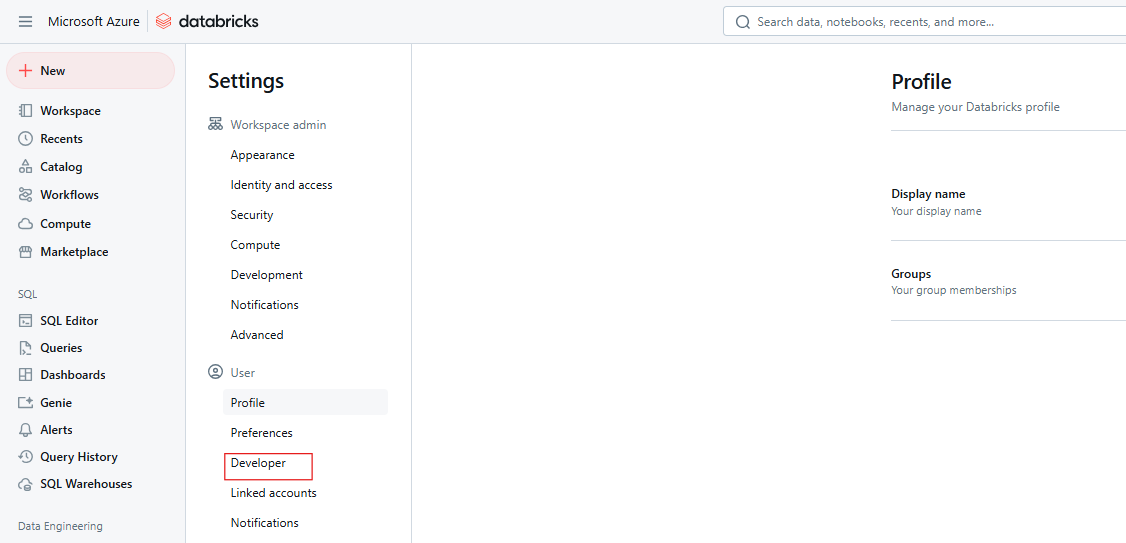
Ajustes de Desarrollador de Databricks. Imagen del autor.
Paso 3: Gestionar los tokens de acceso
Junto a Fichas de acceso, haz clic en Gestionar.
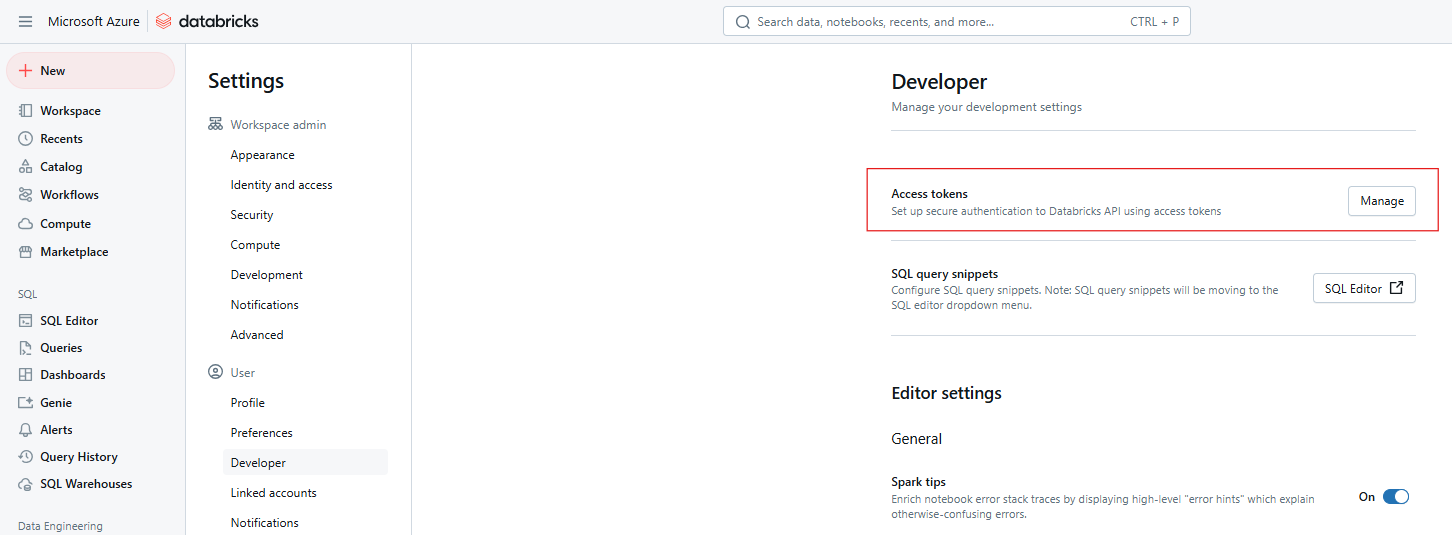
Fichas de acceso a Databricks. Imagen del autor
Paso 4: Generar nuevo token
Haz clic en Generar nuevo token.
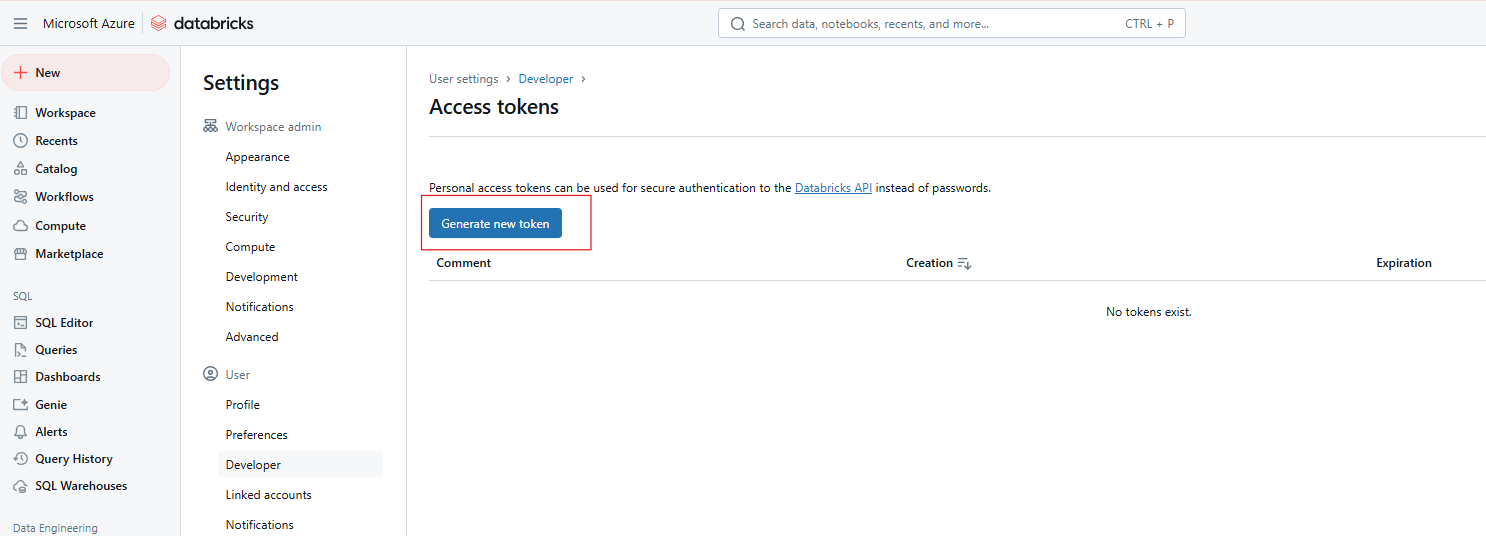
Generando nuevo token de acceso a Databricks. Imagen del autor.
Paso 5: Introduce los datos y guarda el token
Proporciona un comentario para identificar el token y establece su vida útil en días. Si se deja en blanco, se establece por defecto la duración máxima (normalmente 730 días). Haz clic en Generar, copia el token de forma segura y, a continuación, haz clic en Listo.
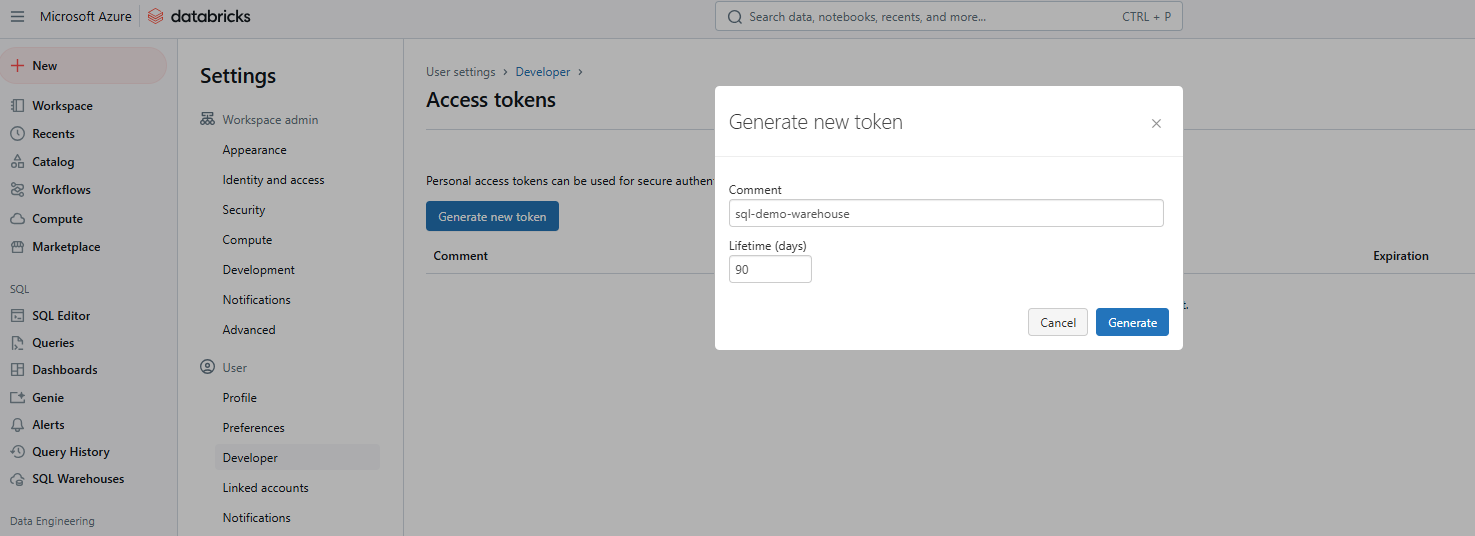
Generando nuevo token de acceso a Databricks. Imagen del autor.
Configurar perfiles
Una vez que tengas tu token, configura la CLI para que se comunique con tu espacio de trabajo. Este proceso implica configurar un perfil que incluya la URL de tu espacio de trabajo y el token.
Configuración básica
Ejecuta el siguiente comando para configurar tu perfil por defecto:
databricks configure --tokenSe te pedirá que lo introduzcas:
La URL del host de Databricks (por ejemplo, https://<databricks-instance>.cloud.databricks.com).
El Identificador de Acceso Personal que generaste anteriormente.
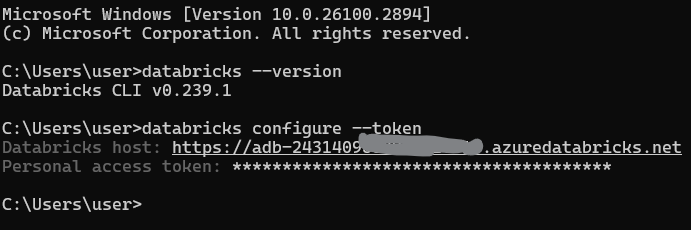
Configurar el perfil CLI de Databricks. Imagen del autor.
Múltiples perfiles
Puedes configurar varios perfiles para distintos entornos (por ejemplo, desarrollo, ensayo, producción):
databricks configure --profile <profile-name> --tokenPara utilizar un perfil específico, incluye la bandera --profile en tus comandos CLI:
databricks clusters list --profile stagingAutenticación avanzada
La CLI de Databricks es compatible con la Autenticación Unificada de Databricks, que se integra con sistemas de gestión de identidades empresariales como Single Sign-On (SSO) y OAuth. Esto permite una autenticación segura y escalable en todas las API de Databricks. La autenticación unificada simplifica la gestión de usuarios al permitir una única configuración de SSO para varios espacios de trabajo, lo que facilita la gestión de accesos y la automatización de tareas mediante principales de servicio.
Los principales comandos CLI de Databricks
La CLI de Databricks organiza su funcionalidad en categorías de alto nivel, cada una con subcomandos adaptados a tareas específicas. A continuación encontrarás un desglose de las principales categorías y ejemplos prácticos para empezar. Si necesitas refrescar tus conocimientos sobre las principales características de Databricks, te recomiendo que consultes nuestro tutorial sobre los 7 conceptos que todo especialista en datos debe conocer.
Agrupaciones
Los comandos de clústeres sirven para gestionar los clústeres de Databricks, incluyendo su creación, listado, inicio y eliminación. Los subcomandos comunes son los siguientes:
-
create: Crea un nuevo clúster. -
list: Enumera todos los clusters del espacio de trabajo. -
startydelete: Iniciar o eliminar un clúster.
Por ejemplo, el siguiente comando crea un nuevo cluster llamado my-cluster con 4 trabajadores de tipo Standard_D2_v2.
databricks clusters create --cluster-name my-cluster --node-type-id Standard_D2_v2 --num-workers 4También puedes utilizar el siguiente comando para listar todos los clusters de tu espacio de trabajo Databricks.
databricks clusters listEmpleo
Son comandos para gestionar los trabajos de Databricks, incluyendo la creación, ejecución y listado. Los subcomandos habituales en los trabajos son los siguientes:
-
create: Crea un nuevo trabajo. -
run-now: Activa inmediatamente un trabajo existente. -
list: Lista todos los empleos disponibles.
Por ejemplo, puedes crear un nuevo trabajo llamado my-job que ejecute una tarea de bloc de notas.
databricks jobs create --job-name my-job --notebook-task /path/to/notebookTambién puedes activar un trabajo existente por su ID utilizando el comando que aparece a continuación.
databricks jobs run-now --job-id 12345Espacio de trabajo
Son comandos para gestionar los recursos del espacio de trabajo, como importar y exportar blocs de notas. Los subcomandos habituales de esta categoría son los siguientes:
-
import: Importa una libreta o biblioteca. -
export: Exporta un bloc de notas a tu máquina local. -
list: Lista el contenido de un directorio de espacio de trabajo.
Por ejemplo, puedes exportar una libreta a un archivo local utilizando el comando que aparece a continuación.
databricks workspace export /Users/username/notebook /local/path/notebook.pyDel mismo modo, puedes importar una libreta utilizando el comando que se indica a continuación.
databricks workspace import /local/path/notebook.py /Users/username/notebookSistema de archivos (DBFS)
Son comandos para interactuar con el Sistema de Archivos Databricks (DBFS), incluyendo la carga y descarga de archivos. Los subcomandos habituales de esta categoría son los siguientes:
-
cp: Copiar archivos a o desde DBFS. -
ls: Lista los archivos de un directorio DBFS. -
rm: Eliminar archivos o directorios de DBFS.
Por ejemplo, puedes utilizar el siguiente comando para subir un archivo local a DBFS.
databricks fs cp /local/path/file.txt dbfs:/path/in/dbfs/Del mismo modo, el siguiente comando te permite descargar un archivo de DBFS a una ruta local.
databricks fs cp dbfs:/path/in/dbfs/file.txt /local/path/Repos
Los comandos repos te permiten gestionar repositorios dentro de Databricks, posibilitando el control de versiones. Los subcomandos comunes son los siguientes:
-
list: Lista todos los repositorios. -
create: Añade un nuevo repositorio.
Por ejemplo, el siguiente comando listará todos los repositorios Databricks de tu espacio de trabajo.
databricks repos listPermisos
Puedes utilizar estos comandos para establecer y gestionar permisos para espacios de trabajo, trabajos y clusters. Los subcomandos comunes de permisos son los siguientes:
-
get: Ver los permisos actuales. -
update: Modifica los permisos.
Por ejemplo, el comando siguiente te permite ver los permisos de un recurso concreto.
databricks permissions get --type cluster --id 12345Comandos SQL de Databricks
Estos comandos te permiten interactuar con Databricks SQL para consultar bases de datos y gestionar almacenes SQL.
La siguiente consulta obtiene y muestra las 10 primeras filas de sales_table.
databricks sql query --query "SELECT * FROM sales_table LIMIT 10;"Si necesitas refrescar tus conocimientos sobre SQL de Databricks, te recomiendo que leas nuestro tutorial sobre SQL de Databricks para aprender a utilizar SQL para consultar datos del Almacén SQL de Databricks.
Casos de uso común y escenarios de ejemplo
La CLI de Databricks ofrece soluciones prácticas para automatizar tareas rutinarias. A continuación encontrarás ejemplos detallados de situaciones habituales que demuestran su versatilidad.
Crear o editar un clúster
Para crear un clúster, utiliza un archivo de configuración JSON, como cluster-config.json,, que especifique la configuración del clúster.
{
"cluster_name": "example-cluster",
"spark_version": "11.3.x-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 2
}A continuación, ejecuta el siguiente comando para crear el clúster:
databricks clusters create --json-file cluster-config.jsonPara actualizar la configuración de un cluster existente, primero exporta la configuración actual del cluster utilizando el comando que aparece a continuación:
databricks clusters get --cluster-id <cluster-id> > cluster-config.jsonA continuación, edita el archivo cluster-config.json según sea necesario y aplica los cambios al clúster.
databricks clusters edit --json-file cluster-config.jsonGestionar cuadernos
En algunos casos, puede que quieras exportar una libreta de Databricks a un directorio local y luego volver a importarla. Utiliza el siguiente comando para importar o exportar el bloc de notas:
databricks workspace export /path/to/notebook.ipynb /local/path/notebook.ipynbEl siguiente comando se utiliza para volver a subir el bloc de notas a Databricks.
databricks workspace import /local/path/notebook.ipynb /path/to/notebook.ipynbDesencadenar trabajos
Cuando quieras crear tareas automatizadas, puede que necesites crear un trabajo que ejecute una libreta o script y programarlo para que se ejecute diariamente. Primero, utiliza un archivo JSON como job-config.json para definir un trabajo que ejecute un bloc de notas concreto.
{
"name": "example-job",
"new_cluster": {
"spark_version": "11.3.x-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 1
},
"notebook_task": {
"notebook_path": "/Users/username/my-notebook"
},
"schedule": {
"quartz_cron_expression": "0 0 * * * ?",
"timezone_id": "UTC"
}
}Crea el trabajo utilizando el comando siguiente:
databricks jobs create --json-file job-config.jsonA continuación, puedes ejecutar el trabajo por su ID de trabajo.
databricks jobs run-now --job-id <job-id>Operaciones de archivo en DBFS
Si necesitas listar, copiar o eliminar archivos en DBFS utiliza los siguientes comandos.
Para ver los archivos de un directorio:
databricks fs ls dbfs:/path/to/directorySube un archivo local a DBFS:
databricks fs cp /local/path/file.txt dbfs:/path/to/remote-file.txtElimina un archivo o directorio:
databricks fs rm dbfs:/path/to/file.txtBuenas prácticas y consejos
Considera la posibilidad de adoptar las siguientes prácticas recomendadas para maximizar la eficacia, seguridad y fiabilidad de la CLI de Databricks.
- Mantente al día de las versiones: Asegúrate de que utilizas la versión 0.200 o posterior de Databricks CLI para beneficiarte del desarrollo activo y de las nuevas funciones. Las versiones anteriores se consideran heredadas y pueden carecer de compatibilidad con las funcionalidades más recientes.
- Seguridad: Evita almacenar los tokens de acceso personal en texto plano. En su lugar, utiliza variables de entorno o métodos de almacenamiento seguro como archivos encriptados o herramientas de gestión de secretos.
- Guión: Utiliza scripts Bash o Python para automatizar tareas encadenando varios comandos CLI. Este enfoque simplifica los flujos de trabajo complejos y mejora la reproducibilidad.
- Registro/Depuración: Utiliza la opción --debug para activar la salida detallada con fines de depuración. Esto puede ayudar a diagnosticar problemas proporcionando mensajes de error detallados.
databricks --debug clusters create --cluster-name my-cluster --node-type-id Standard_D2_v2 --num-workers 4Comparación de la CLI de Databricks con otros enfoques
Al trabajar con Databricks, los usuarios tienen varias opciones para interactuar con la plataforma, como la CLI de Databricks, las API REST, el SDK Python de Databricks y la interfaz de usuario web. Cada método tiene sus ventajas e inconvenientes, según las necesidades y preferencias específicas del usuario o de la organización.
API REST
Las API REST de Databricks proporcionan un acceso directo y de bajo nivel a la funcionalidad de Databricks, ofreciendo la mayor flexibilidad para las integraciones agnósticas del lenguaje.
SDK Python de Databricks
El SDK Python de Databricks proporciona una interfaz pitónica para interactuar con Databricks, ofreciendo abstracciones de alto nivel sobre las API REST.
Web UI
La Web UI de Databricks proporciona una interfaz gráfica interactiva para gestionar clusters, trabajos, blocs de notas y mucho más.
Resumiré las ventajas, los puntos débiles y los casos de uso de los métodos anteriores en la siguiente tabla:
| Acércate a | Puntos fuertes | Puntos débiles | Mejor uso |
|---|---|---|---|
| CLI de Databricks | Automatización sencilla, programable e independiente del sistema operativo | Limitado a comandos CLI compatibles | Automatización ligera y tareas repetitivas |
| API REST | Flexible e independiente del idioma | Complejo, requiere más esfuerzo para ponerlo en práctica | Integraciones personalizadas y funciones de vanguardia |
| SDK de Python | Abstracciones de alto nivel compatibles con Python | Añade dependencias, requiere conocimientos de Python | Flujos de trabajo y canalizaciones de datos intensivos en Python |
| Web UI | Fácil de usar, no requiere configuración | No escalable para la automatización | Tareas interactivas, puntuales o exploratorias |
Solución de problemas y cuestiones conocidas
Cuando utilices la CLI de Databricks, puedes encontrarte con errores y dificultades comunes. A continuación encontrarás un resumen de problemas frecuentes y soluciones prácticas, junto con consejos para diagnosticar problemas relacionados con la red.
Errores frecuentes
Los errores frecuentes al utilizar la CLI de Databricks son los siguientes:
- Autorización fallida: El error podría deberse a un token de acceso personal incorrecto o caducado. Para solucionar este error, asegúrate de que tu token es válido y está correctamente configurado en los ajustes de tu CLI. Si es necesario, genera un nuevo token.
- CLI no encontrado en PATH: Este error se produce cuando el ejecutable CLI de Databricks no está en el PATH de tu sistema. Para solucionar el problema, añade siempre el directorio que contiene el ejecutable de la CLI a la variable de entorno PATH de tu sistema.
- Caducidad del token: Las fichas tienen una duración limitada y caducan tras un periodo determinado. Para evitar este error, renueva siempre tu token periódicamente o establece un mecanismo para actualizar automáticamente los tokens.
Diagnosticar problemas de red
En entornos con redes restringidas o listas de direcciones IP permitidas, puedes tener problemas para conectarte a los Databricks. Aquí tienes algunos pasos para diagnosticar y resolver estos problemas:
-
Comprueba la configuración de la red: Asegúrate de que tu red permite conexiones salientes a la URL del espacio de trabajo Databricks. Comprueba que los cortafuegos o servidores proxy están configurados correctamente.
-
Listas de direcciones IP: Si tu espacio de trabajo requiere una lista de IP permitidas, asegúrate de que tu dirección IP está incluida en la lista. Utiliza herramientas como
curlpara probar la conectividad de tu máquina con la API de Databricks. -
Verificación SSL: Si encuentras errores de verificación SSL, prueba a desactivar temporalmente la verificación SSL utilizando la opción-k con curl para aislar el problema.
Conclusión y otros recursos
Espero haberte convencido de que practicar con la CLI de Databricks merece la pena. Como has visto, la CLI de Databricks permite automatizar rápidamente y mediante scripts tareas como la gestión de clusters, la activación de trabajos y las operaciones con archivos, reduciendo la dependencia de la interfaz de usuario web, lo que ahorra tiempo. Me ha impresionado su flexibilidad y el hecho de que tenga integración con los pipelines DevOps.
Definitivamente hay muchos detalles particulares que no podría cubrir en un artículo, así que intenta buscar en la documentación oficial de Databricks o en la página GitHub de la CLI si estás intentando encontrar la respuesta a una pregunta concreta. Para aprender más sobre los conceptos básicos importantes, prueba nuestro curso Introducción a Databricks. Este curso te enseña Databricks como solución de almacenamiento de datos para Business Intelligence. También te recomiendo, si vas por el camino de aprender Databricks, que leas también nuestra guía sobre Certificaciones Databricks, para que no sólo aprendas Databricks, sino que también te posiciones bien en el mercado laboral.


