
Course
Databricks Concepts
4 hr
22K
The Databricks Command Line Interface (CLI) is a powerful tool that allows users to automate tasks on the Databricks platform directly from the terminal or command prompt. With the CLI, users can execute commands for managing clusters, jobs, and notebooks without needing to navigate through the graphical interface, which enhances efficiency and integration into automated workflows.
As of now, the Databricks CLI is in Public Preview for versions 0.205 and above. Users operating on older versions should note that these are considered legacy and may not support the latest features or improvements available in the newer versions.
In this tutorial, I will show you how to install the CLI and how to navigate the CLI with the main commands to automate your workflows. As we get started, I highly recommend checking out DataCamp’s How to Learn Databricks: A Beginner’s Guide to the Unified Data Platform blog post to help you understand the core features and applications of Databricks and provide a structured path to start your learning.
As a frequent user, I find the following reasons as to why you should use the Databricks CLI.
To get started with the Databricks CLI, you need to meet the environment prerequisites and follow the installation instructions specific to your operating system. I will show you how to set up the environment and update the CLI on Linux, macOS, and Windows.
Before installing the Databricks CLI, ensure your system meets these basic requirements:
There are several approaches to installing the Databricks CLI on Linux, including the following:
If you have Homebrew installed, run:
brew install databricks-cliYou can download and install Databricks CLI using curl by running the following command:
curl -Lo databricks-cli.tar.gz https://github.com/databricks/databricks-cli/releases/latest/download/databricks-cli.tar.gz
tar -xzf databricks-cli.tar.gz -C /usr/local/binAlternatively, you can download the CLI binary from the official Databricks CLI GitHub repository and move it to a directory in your PATH.
If you are using macOS, you can install the Databricks CLI using the following commands.
Run the command below to install Databricks CLI;
brew install databricks-cliDownload the latest binary from GitHub releases, extract it, and place it in your local PATH. Make it executable using the command below:
chmod +x /usr/local/bin/databricksSimilarly, you can download the CLI binary from the official Databricks CLI GitHub repository and move it to a directory in your PATH.
If you are using the Windows operating system, you can choose to install Databricks CLI from the following methods:
Run the following command in the command prompt:
winget install Databricks.DatabricksCLIIf you have Chocolatey installed, use:
choco install databricks-cliIf WSL is set up, follow the Linux installation steps.
Download the .exe file from the Databricks CLI GitHub repository.
Add the directory containing the file to your system’s PATH for easy access.
After installation, you should verify that the Databricks CLI is installed correctly. Open a terminal or command prompt and run:
databricks --versionTo use the Databricks CLI effectively, you need to authenticate it with your Databricks workspace. In this section, I will cover how to set up authentication and manage configurations.
A personal access token (PAT) is required to authenticate with the Databricks CLI. Follow these steps to generate one:
Log into your Databricks workspace and click on your username in the top bar. Select Settings from the dropdown menu.
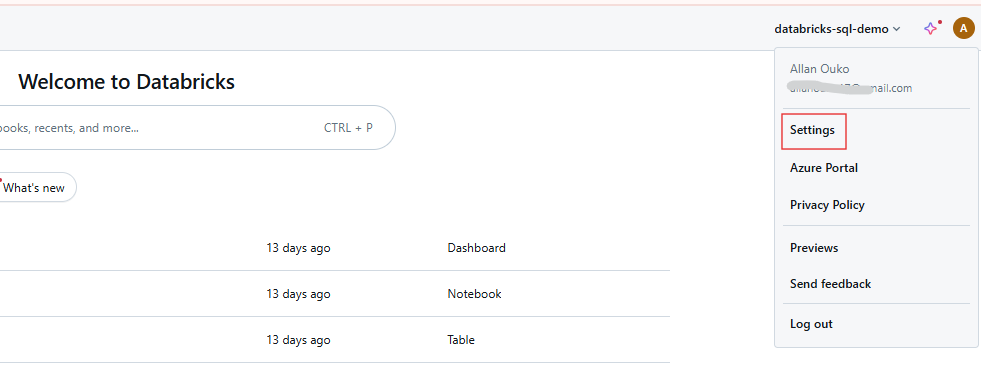
Databricks workspace user settings. Image by Author.
Click on Developer.
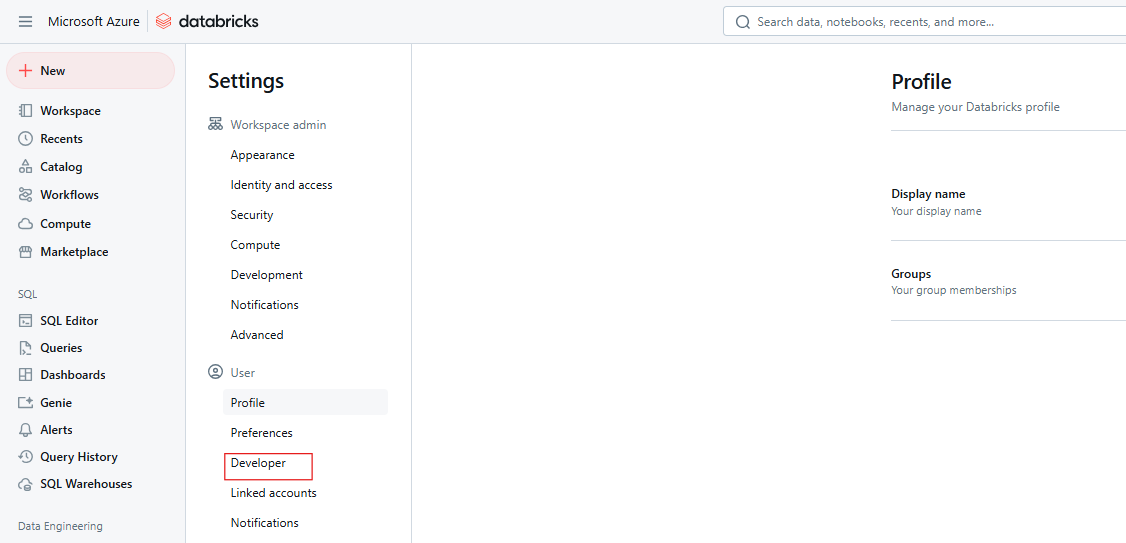
Databricks Developer settings. Image by Author.
Next to Access tokens, click Manage.
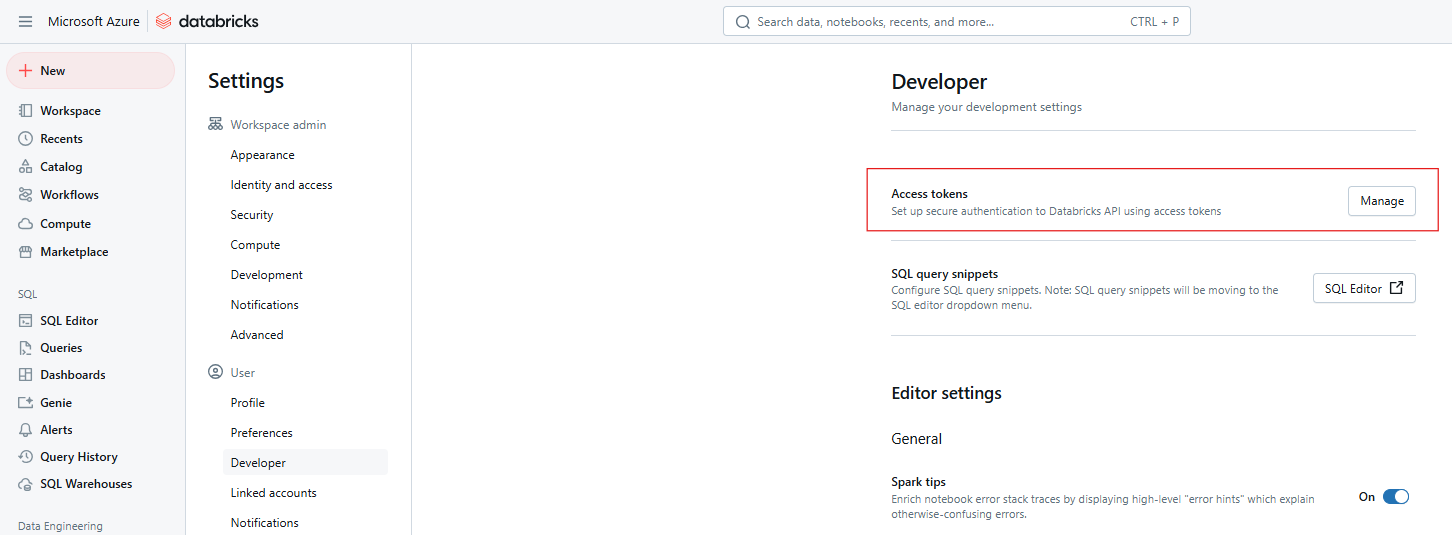
Databricks Access tokens. Image by Author
Click Generate new token.
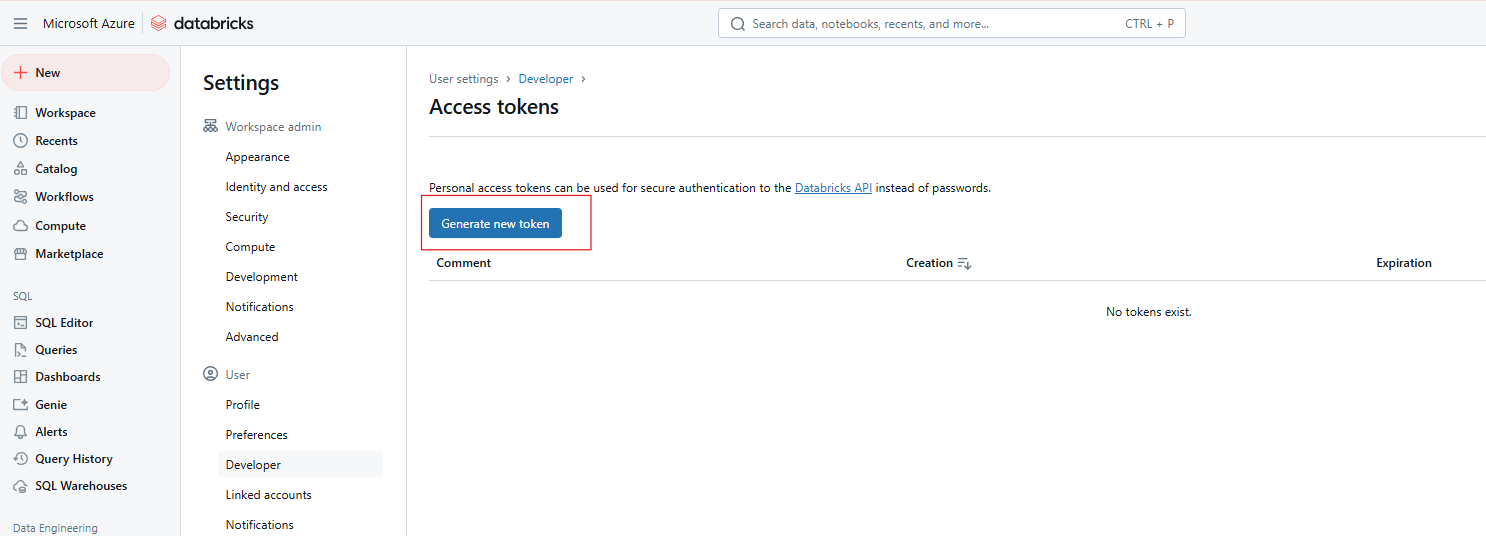
Generating new Databricks Access token. Image by Author.
Provide a comment to identify the token and set its lifetime in days. If left blank, it defaults to the maximum lifetime (typically 730 days). Click Generate, copy the token securely, and then click Done.
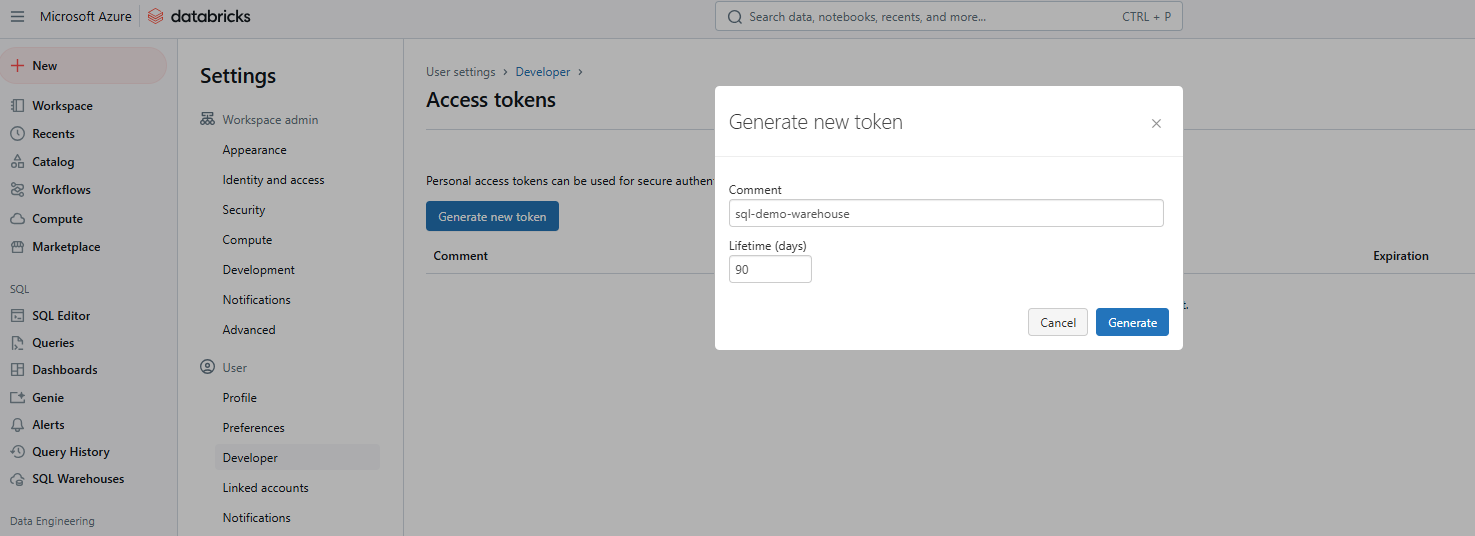
Generating new Databricks Access token. Image by Author.
Once you have your token, configure the CLI to communicate with your workspace. This process involves setting up a profile that includes your workspace URL and token.
Run the following command to set up your default profile:
databricks configure --tokenYou will be prompted to enter:
The Databricks host URL (e.g., https://<databricks-instance>.cloud.databricks.com).
The Personal Access Token you generated earlier.
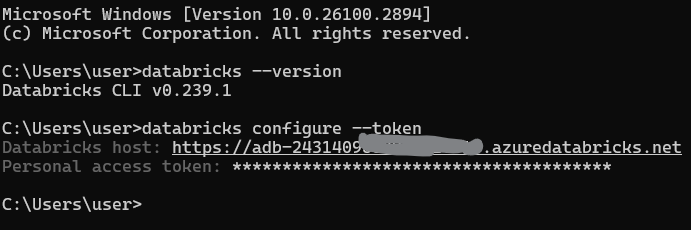
Configuring Databricks CLI profile. Image by Author.
You can configure multiple profiles for different environments (e.g., dev, staging, production):
databricks configure --profile <profile-name> --tokenTo use a specific profile, include the --profile flag in your CLI commands:
databricks clusters list --profile stagingThe Databricks CLI supports Databricks Unified Authentication, which integrates with enterprise identity management systems like Single Sign-On (SSO) and OAuth. This allows for secure and scalable authentication across all Databricks APIs. Unified authentication simplifies user management by enabling a single SSO configuration for multiple workspaces, making it easier to manage access and automate tasks using service principals.
The Databricks CLI organizes its functionality into high-level categories, each with subcommands tailored to specific tasks. The following is a breakdown of the main categories and practical examples to get you started. If you need to refresh your knowledge about the main features of Databricks, I recommend checking out our tutorial on the 7 Must-know Concepts For Any Data Specialist.
The clusters commands are for managing Databricks clusters, including creation, listing, starting, and deletion. The common subcommands include the following:
create: Create a new cluster.
list: List all clusters in the workspace.
start and delete: Start or delete a cluster.
For example, the following command creates a new cluster named my-cluster with 4 workers of type Standard_D2_v2.
databricks clusters create --cluster-name my-cluster --node-type-id Standard_D2_v2 --num-workers 4You can also use the following command to list all clusters in your Databricks workspace.
databricks clusters listThese are commands for managing Databricks jobs, including creation, running, and listing. The common subcommands in jobs include the following:
create: Create a new job.
run-now: Trigger an existing job immediately.
list: List all available jobs.
For example, you can create a new job named my-job that runs a notebook task.
databricks jobs create --job-name my-job --notebook-task /path/to/notebookYou can also trigger an existing job by its ID using the command below.
databricks jobs run-now --job-id 12345These are commands for managing workspace resources, such as importing and exporting notebooks. The common subcommands in this category include the following:
import: Import a notebook or library.
export: Export a notebook to your local machine.
list: List contents of a workspace directory.
For example, you can export a notebook to a local file using the command below.
databricks workspace export /Users/username/notebook /local/path/notebook.pySimilarly, you can import a notebook using the command below.
databricks workspace import /local/path/notebook.py /Users/username/notebookThese are commands for interacting with the Databricks File System (DBFS), including uploading and downloading files. The common subcommands in this category include the following:
cp: Copy files to or from DBFS.
ls: List files in a DBFS directory.
rm: Remove files or directories from DBFS.
For example, you can use the command below to upload a local file to DBFS.
databricks fs cp /local/path/file.txt dbfs:/path/in/dbfs/Similarly, the following command allows you to download a file from DBFS to a local path.
databricks fs cp dbfs:/path/in/dbfs/file.txt /local/path/The repos commands allow you to manage repositories within Databricks, enabling version control. The common subcommands include the following:
list: List all repositories.
create: Add a new repository.
For example, the following command will list all Databricks Repos in your workspace.
databricks repos listYou can use these commands to set and manage permissions for workspaces, jobs, and clusters. The common permissions subcommands include the following:
get: View current permissions.
update: Modify permissions.
For example, the command below lets you view permissions for a specific resource.
databricks permissions get --type cluster --id 12345These commands let you interact with Databricks SQL to query databases and manage SQL warehouses.
The following query fetches and displays the first 10 rows from the sales_table.
databricks sql query --query "SELECT * FROM sales_table LIMIT 10;"If you need to refresh your knowledge about Databricks SQL, I recommend reading our Databricks SQL tutorial to learn how to use SQL to query data from the Databricks SQL Warehouse.
The Databricks CLI offers practical solutions for automating routine tasks. Below are detailed examples of common scenarios that demonstrate its versatility.
To create a cluster, use a JSON configuration file, such as cluster-config.json, that specifies cluster settings.
{
"cluster_name": "example-cluster",
"spark_version": "11.3.x-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 2
}Then run the following command to create the cluster:
databricks clusters create --json-file cluster-config.jsonTo update an existing cluster’s configuration, first export the current cluster settings using the command below:
databricks clusters get --cluster-id <cluster-id> > cluster-config.jsonNext, edit the cluster-config.json file as needed and apply the changes to the cluster.
databricks clusters edit --json-file cluster-config.jsonIn some scenarios, you may want to export a notebook from Databricks to a local directory and then import it back. Use the following command to import the export the notebook:
databricks workspace export /path/to/notebook.ipynb /local/path/notebook.ipynbThe command below is used to upload the notebook back to Databricks.
databricks workspace import /local/path/notebook.ipynb /path/to/notebook.ipynbWhen you want to create automated tasks, you may need to create a job that runs a notebook or script and schedule it to run daily. First, use a JSON file such as job-config.json to define a job that runs a specific notebook.
{
"name": "example-job",
"new_cluster": {
"spark_version": "11.3.x-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 1
},
"notebook_task": {
"notebook_path": "/Users/username/my-notebook"
},
"schedule": {
"quartz_cron_expression": "0 0 * * * ?",
"timezone_id": "UTC"
}
}Create the job using the command below:
databricks jobs create --json-file job-config.jsonYou can then run the job by its job ID.
databricks jobs run-now --job-id <job-id>If you need to list, copy, or remove files in DBFS use the following commands.
To view files in a directory:
databricks fs ls dbfs:/path/to/directoryUpload a local file to DBFS:
databricks fs cp /local/path/file.txt dbfs:/path/to/remote-file.txtDelete a file or directory:
databricks fs rm dbfs:/path/to/file.txtConsider adopting the following best practices to maximize the efficiency, security, and reliability of the Databricks CLI.
databricks --debug clusters create --cluster-name my-cluster --node-type-id Standard_D2_v2 --num-workers 4When working with Databricks, users have several options for interacting with the platform, including the Databricks CLI, REST APIs, Databricks Python SDK, and the web UI. Each method has its advantages and disadvantages, depending on the specific needs and preferences of the user or organization.
The Databricks REST APIs provide direct, low-level access to Databricks functionality, offering the most flexibility for language-agnostic integrations.
The Databricks Python SDK provides a Pythonic interface for interacting with Databricks, offering high-level abstractions over REST APIs.
The Databricks Web UI provides an interactive graphical interface for managing clusters, jobs, notebooks, and more.
I will summarize the advantages, weaknesses, and use cases of the above methods in the following table:
| Approach | Strengths | Weaknesses | Best Use |
|---|---|---|---|
| Databricks CLI | Simple, scriptable, OS-agnostic automation | Limited to supported CLI commands | Lightweight automation and repetitive tasks |
| REST APIs | Flexible, language-agnostic | Complex, requires more effort to implement | Custom integrations and cutting-edge features |
| Python SDK | Python-friendly, high-level abstractions | Adds dependencies, requires Python skills | Python-heavy workflows and data pipelines |
| Web UI | User-friendly, no setup required | Not scalable for automation | Interactive, one-off, or exploratory tasks |
When using the Databricks CLI, you may encounter common errors and challenges. Below is a summary of frequent issues and practical solutions, along with tips for diagnosing network-related problems.
The frequent errors when using Databricks CLI include the following:
In environments with restricted networks or IP allowlists, you might encounter issues connecting to Databricks. Here are some steps to diagnose and resolve these issues:
Check Network Configuration: Ensure that your network allows outgoing connections to the Databricks workspace URL. Verify that any firewalls or proxy servers are configured correctly.
IP Allowlists: If your workspace requires IP allowlisting, ensure that your IP address is included in the list. Use tools like curl to test connectivity from your machine to the Databricks API.
SSL Verification: If you encounter SSL verification errors, try temporarily disabling SSL verification using the—k option with curl to isolate the issue.
I hope I have sold you on the idea that practicing using the Databricks CLI is worth it. As you have seen, the Databricks CLI enables quick, scriptable automation of tasks such as cluster management, job triggering, and file operations, reducing reliance on the web UI, which saves time. I've been impressed with its flexibility and the fact that it has integration with DevOps pipelines.
There are definitely a lot of particular details that I couldn't cover in one article, so try looking at the official Databricks documentation or the CLI's GitHub page if you are trying to hunt down the answer to a specific question. To learn more of the important foundational concepts, try our Introduction to Databricks course. This course teaches you about Databricks as a data warehousing solution for Business Intelligence. I also recommend, if you are going down the path of learning Databricks, to also read our guide on Databricks Certifications, so that you can not only learn Databricks but also position yourself well in the job market.
Learn Databricks with DataCamp
Course
Course
Course
blog
Josep Ferrer
blog
Gus Frazer
11 min
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Bex Tuychiev

