A interface de linha de comando (CLI) da Databricks é uma ferramenta poderosa que permite aos usuários automatizar tarefas na plataforma Databricks diretamente do terminal ou do prompt de comando. Com a CLI, os usuários podem executar comandos para gerenciar clusters, trabalhos e notebooks sem a necessidade de navegar pela interface gráfica, o que aumenta a eficiência e a integração em fluxos de trabalho automatizados.
No momento, a CLI da Databricks está em Public Preview para as versões 0.205 e posteriores. Os usuários que operam em versões mais antigas devem observar que elas são consideradas legadas e podem não oferecer suporte aos recursos ou aprimoramentos mais recentes disponíveis nas versões mais recentes.
Neste tutorial, mostrarei a você como instalar a CLI e como navegar na CLI com os principais comandos para automatizar seus fluxos de trabalho. Para começar, recomendo que você dê uma olhada no site da DataCamp How to Learn Databricks: A Beginner's Guide to the Unified Data Platform blog post para ajudar você a entender os principais recursos e aplicativos do Databricks e fornecer um caminho estruturado para iniciar seu aprendizado.
Por que usamos a CLI da Databricks
Como usuário frequente, encontrei os seguintes motivos pelos quais você deve usar a CLI da Databricks.
- Automação: A CLI permite que você crie scripts de operações como criação de clusters, envio de trabalhos e gerenciamento de notebooks. Essa automação economiza tempo e reduz a probabilidade de erros. Por exemplo, você pode criar e executar trabalhos com um único comando.
- Integração: A CLI da Databricks permite que você se integre perfeitamente aos pipelines de DevOps e aos processos de CI/CD. Usando essa funcionalidade, você pode configurar facilmente seus ambientes para automatizar implementações e atualizações nos fluxos de trabalho do Databricks sem intervenção manual. Por exemplo, você pode acionar trabalhos automatizados diretamente de ferramentas como Jenkins, GitHub Actions ou Azure DevOps.
- Simplicidade: Você pode executar tarefas diretamente do seu computador local, evitando a necessidade de navegar na interface do usuário da Web para tarefas de rotina. Essa função facilita o gerenciamento dos seus fluxos de trabalho, executando comandos para realizar operações como upload de notebooks ou gerenciamento de clusters sem a sobrecarga de uma interface gráfica.
- Flexibilidade: A CLI da Databricks oferece suporte a uma ampla variedade de sistemas operacionais e ambientes, como Windows, macOS e Linux, tornando-a acessível a diversas equipes. A CLI também oferece suporte à autenticação de vários perfis, permitindo que você gerencie várias contas ou espaços de trabalho do Databricks com eficiência.
Instalação e atualização da CLI da Databricks
Para começar a usar a CLI da Databricks, você precisa atender aos pré-requisitos do ambiente e seguir as instruções de instalação específicas do seu sistema operacional. Mostrarei a você como configurar o ambiente e atualizar a CLI no Linux, macOS e Windows.
Pré-requisitos do ambiente
Antes de instalar a CLI da Databricks, verifique se o sistema atende a esses requisitos básicos:
- Um gerenciador de pacotes: Embora um gerenciador de pacotes como o Homebrew (para macOS) ou o WinGet (para Windows) possa simplificar a instalação, você também pode instalar diretamente usando binários ou código-fonte.
- Python: A CLI requer o Python 3.6 ou posterior.
- Acesso à rede para o espaço de trabalho do Databricks.
- Curl: Para alguns métodos de instalação no Linux e no macOS, certifique-se de que o curl esteja instalado.
- Privilégios de administrador (para alguns métodos de instalação).
Instalação no Linux
Há várias abordagens para instalar a CLI da Databricks no Linux, incluindo as seguintes:
Usando o Homebrew
Se você tiver o Homebrew instalado, execute:
brew install databricks-cliUsando curl
Você pode fazer o download e instalar o Databricks CLI usando o curl, executando o seguinte comando:
curl -Lo databricks-cli.tar.gz https://github.com/databricks/databricks-cli/releases/latest/download/databricks-cli.tar.gz
tar -xzf databricks-cli.tar.gz -C /usr/local/binDownload do manual
Como alternativa, você pode fazer o download do binário da CLI no repositório oficial do GitHub da Databricks CLI e movê-lo para um diretório em seu site PATH.
Instalando no macOS
Se você estiver usando o macOS, poderá instalar a CLI da Databricks usando os seguintes comandos.
Usando o Homebrew
Execute o comando abaixo para instalar o Databricks CLI;
brew install databricks-cliInstalação binária direta
Baixe o binário mais recente das versões do GitHub, extraia-o e coloque-o em seu site local PATH. Torne-o executável usando o comando abaixo:
chmod +x /usr/local/bin/databricksDownload do manual
Da mesma forma, você pode fazer o download do binário da CLI no repositório oficial do GitHub da Databricks CLI e movê-lo para um diretório em seu site PATH.
Instalação no Windows
Se estiver usando o sistema operacional Windows, você pode optar por instalar o Databricks CLI a partir dos seguintes métodos:
Usando o WinGet
Execute o seguinte comando no prompt de comando:
winget install Databricks.DatabricksCLIUsando Chocolatey
Se você tiver o Chocolatey instalado, use:
choco install databricks-cliUsando o subsistema Windows para Linux (WSL)
Se a WSL estiver configurada, siga as etapas de instalação do Linux.
Instalação binária direta
Faça o download do arquivo .exe no repositório do GitHub da CLI da Databricks.
Adicione o diretório que contém o arquivo ao site PATH do seu sistema para facilitar o acesso.
Verificação da instalação
Após a instalação, você deve verificar se a CLI da Databricks está instalada corretamente. Abra um terminal ou prompt de comando e execute:
databricks --versionAutenticação e configuração da CLI da Databricks
Para usar a CLI do Databricks de forma eficaz, você precisa autenticá-la com seu espaço de trabalho do Databricks. Nesta seção, abordarei como definir a autenticação e gerenciar as configurações.
Geração de um token de acesso pessoal
Você precisa de um token de acesso pessoal (PAT) para se autenticar na CLI da Databricks. Siga estas etapas para gerar um:
Etapa 1: Acessar as configurações do usuário
Faça login no seu espaço de trabalho do Databricks e clique no seu nome de usuário na barra superior. Selecione Configurações no menu suspenso.
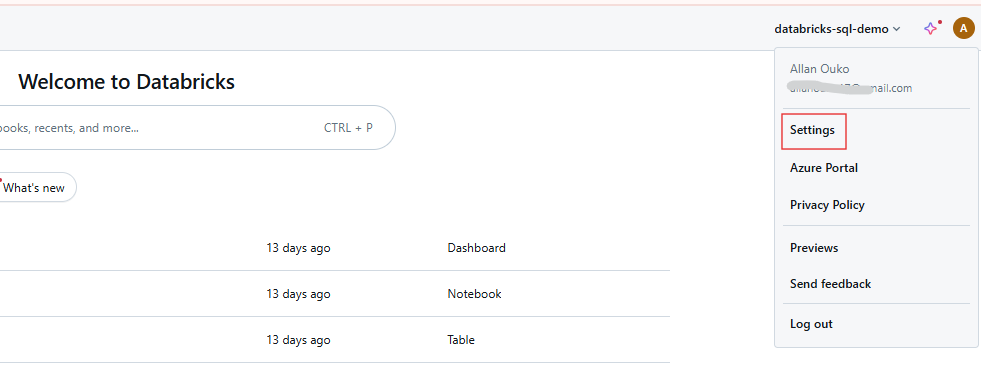
Configurações de usuário do espaço de trabalho do Databricks. Imagem do autor.
Etapa 2: Navegue até as configurações do desenvolvedor
Clique em Desenvolvedor.
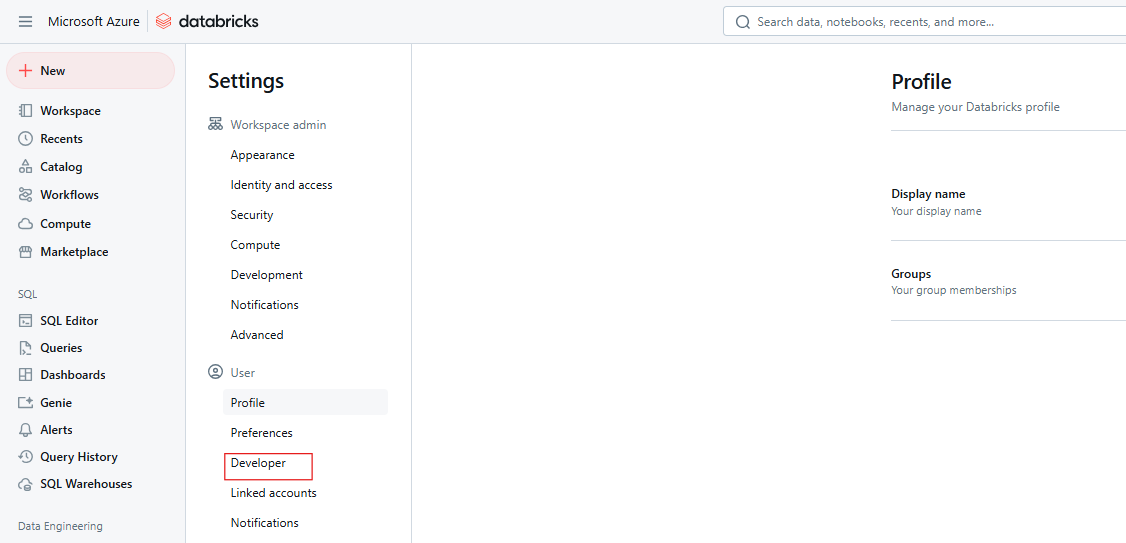
Configurações do Databricks Developer. Imagem do autor.
Etapa 3: Gerenciar tokens de acesso
Ao lado de Access tokens (Tokens de acesso ), clique em Manage (Gerenciar).
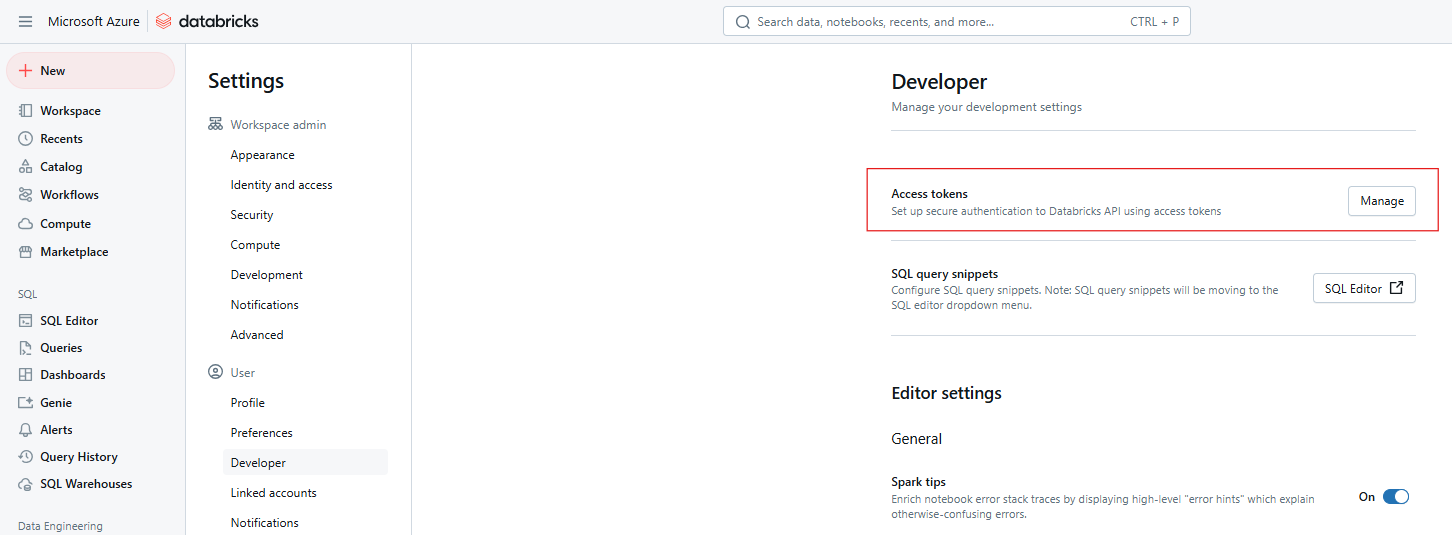
Tokens de acesso ao Databricks. Imagem do autor
Etapa 4: Gerar novo token
Clique em Gerar novo token.
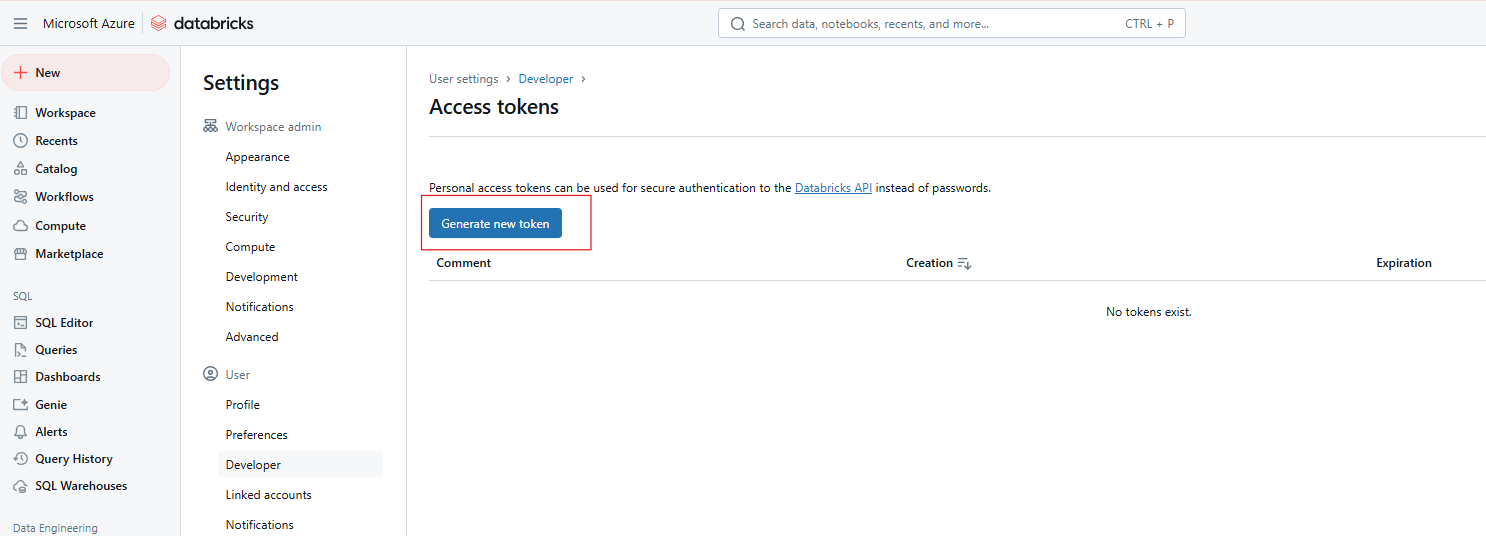
Geração de novo token de acesso ao Databricks. Imagem do autor.
Etapa 5: Insira os detalhes e salve o token
Forneça um comentário para identificar o token e defina sua vida útil em dias. Se você deixar em branco, o padrão será o tempo de vida máximo (normalmente 730 dias). Clique em Generate (Gerar), copie o token com segurança e clique em Done (Concluído).
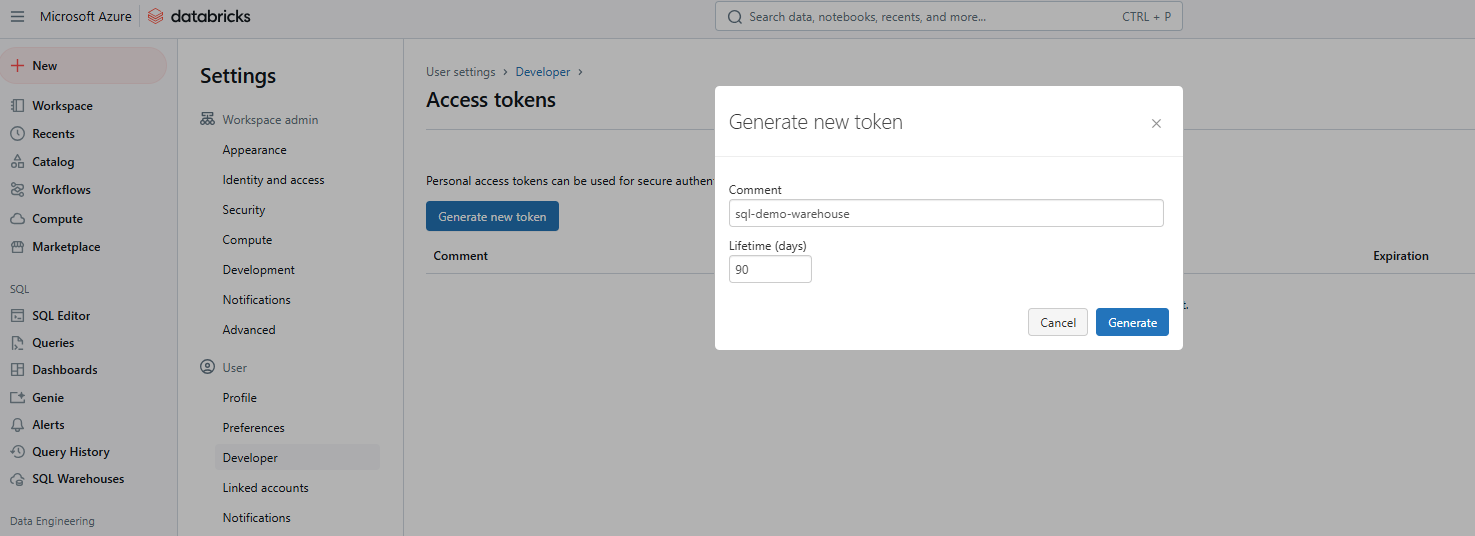
Geração de novo token de acesso ao Databricks. Imagem do autor.
Configuração de perfis
Quando você tiver o token, configure a CLI para se comunicar com o espaço de trabalho. Esse processo envolve a configuração de um perfil que inclui o URL e o token do workspace.
Configuração básica
Execute o seguinte comando para configurar seu perfil padrão:
databricks configure --tokenVocê será solicitado a digitar:
O URL do host do Databricks (por exemplo, https://<databricks-instance>.cloud.databricks.com).
O token de acesso pessoal que você gerou anteriormente.
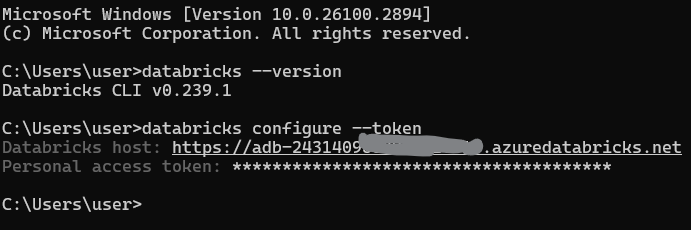
Configuração do perfil da CLI do Databricks. Imagem do autor.
Vários perfis
Você pode configurar vários perfis para diferentes ambientes (por exemplo, desenvolvimento, preparação, produção):
databricks configure --profile <profile-name> --tokenPara usar um perfil específico, inclua o sinalizador --profile em seus comandos da CLI:
databricks clusters list --profile stagingAutenticação avançada
A CLI da Databricks oferece suporte à autenticação unificada da Databricks, que se integra aos sistemas de gerenciamento de identidade corporativa, como o SSO (Single Sign-On) e o OAuth. Isso permite uma autenticação segura e dimensionável em todas as APIs da Databricks. A autenticação unificada simplifica o gerenciamento de usuários ao permitir uma única configuração de SSO para vários espaços de trabalho, facilitando o gerenciamento do acesso e a automatização de tarefas usando princípios de serviço.
Os principais comandos da CLI da Databricks
A CLI da Databricks organiza sua funcionalidade em categorias de alto nível, cada uma com subcomandos adaptados a tarefas específicas. A seguir, você encontrará um detalhamento das principais categorias e exemplos práticos para começar. Se você precisar atualizar seus conhecimentos sobre os principais recursos do Databricks, recomendo que consulte nosso tutorial sobre os 7 conceitos obrigatórios para qualquer especialista em dados.
Agrupamentos
Os comandos de clusters servem para gerenciar os clusters do Databricks, incluindo criação, listagem, inicialização e exclusão. Os subcomandos comuns incluem o seguinte:
-
create: Crie um novo cluster. -
list: Lista todos os clusters no espaço de trabalho. -
startedelete: Iniciar ou excluir um cluster.
Por exemplo, o comando a seguir cria um novo cluster chamado my-cluster com 4 trabalhadores do tipo Standard_D2_v2.
databricks clusters create --cluster-name my-cluster --node-type-id Standard_D2_v2 --num-workers 4Você também pode usar o seguinte comando para listar todos os clusters em seu espaço de trabalho do Databricks.
databricks clusters listEmpregos
Esses são comandos para gerenciar trabalhos do Databricks, incluindo criação, execução e listagem. Os subcomandos comuns em trabalhos incluem o seguinte:
-
create: Criar um novo trabalho. -
run-now: Acionar um trabalho existente imediatamente. -
list: Listar todos os empregos disponíveis.
Por exemplo, você pode criar um novo trabalho chamado my-job que executa uma tarefa de notebook.
databricks jobs create --job-name my-job --notebook-task /path/to/notebookVocê também pode acionar um trabalho existente pelo seu ID usando o comando abaixo.
databricks jobs run-now --job-id 12345Espaço de trabalho
Esses são comandos para gerenciar recursos do espaço de trabalho, como importar e exportar notebooks. Os subcomandos comuns dessa categoria incluem os seguintes:
-
import: Importar um notebook ou biblioteca. -
export: Exporte um notebook para seu computador local. -
list: Lista o conteúdo de um diretório de espaço de trabalho.
Por exemplo, você pode exportar um notebook para um arquivo local usando o comando abaixo.
databricks workspace export /Users/username/notebook /local/path/notebook.pyDa mesma forma, você pode importar um notebook usando o comando abaixo.
databricks workspace import /local/path/notebook.py /Users/username/notebookSistema de arquivos (DBFS)
Esses são comandos para interagir com o DBFS (Databricks File System), incluindo o upload e o download de arquivos. Os subcomandos comuns dessa categoria incluem os seguintes:
-
cp: Copiar arquivos de ou para o DBFS. -
ls: Listar arquivos em um diretório DBFS. -
rm: Remover arquivos ou diretórios do DBFS.
Por exemplo, você pode usar o comando abaixo para carregar um arquivo local no DBFS.
databricks fs cp /local/path/file.txt dbfs:/path/in/dbfs/Da mesma forma, o comando a seguir permite que você faça o download de um arquivo do DBFS para um caminho local.
databricks fs cp dbfs:/path/in/dbfs/file.txt /local/path/Depósitos
Os comandos repos permitem que você gerencie repositórios no Databricks, possibilitando o controle de versão. Os subcomandos comuns incluem o seguinte:
-
list: Listar todos os repositórios. -
create: Adicionar um novo repositório.
Por exemplo, o comando a seguir listará todos os Repositórios do Databricks em seu espaço de trabalho.
databricks repos listPermissões
Você pode usar esses comandos para definir e gerenciar permissões para espaços de trabalho, trabalhos e clusters. Os subcomandos de permissões comuns incluem o seguinte:
-
get: Veja as permissões atuais. -
update: Modificar permissões.
Por exemplo, o comando abaixo permite que você visualize as permissões de um recurso específico.
databricks permissions get --type cluster --id 12345Comandos SQL do Databricks
Esses comandos permitem que você interaja com o Databricks SQL para consultar bancos de dados e gerenciar armazéns SQL.
A consulta a seguir busca e exibe as 10 primeiras linhas do site sales_table.
databricks sql query --query "SELECT * FROM sales_table LIMIT 10;"Se você precisar atualizar seus conhecimentos sobre o Databricks SQL, recomendo a leitura do nosso tutorial do Databricks SQL para saber como usar o SQL para consultar dados do Databricks SQL Warehouse.
Casos de uso comuns e cenários de exemplo
A CLI da Databricks oferece soluções práticas para automatizar tarefas de rotina. A seguir, você encontrará exemplos detalhados de cenários comuns que demonstram sua versatilidade.
Criar ou editar um cluster
Para criar um cluster, use um arquivo de configuração JSON, como cluster-config.json,, que especifica as configurações do cluster.
{
"cluster_name": "example-cluster",
"spark_version": "11.3.x-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 2
}Em seguida, execute o seguinte comando para criar o cluster:
databricks clusters create --json-file cluster-config.jsonPara atualizar a configuração de um cluster existente, primeiro exporte as configurações atuais do cluster usando o comando abaixo:
databricks clusters get --cluster-id <cluster-id> > cluster-config.jsonEm seguida, edite o arquivo cluster-config.json conforme necessário e aplique as alterações ao cluster.
databricks clusters edit --json-file cluster-config.jsonGerenciando notebooks
Em alguns cenários, você pode querer exportar um notebook do Databricks para um diretório local e depois importá-lo novamente. Use o seguinte comando para importar ou exportar o notebook:
databricks workspace export /path/to/notebook.ipynb /local/path/notebook.ipynbO comando abaixo é usado para carregar o notebook de volta ao Databricks.
databricks workspace import /local/path/notebook.ipynb /path/to/notebook.ipynbAcionamento de trabalhos
Quando quiser criar tarefas automatizadas, talvez você precise criar um trabalho que execute um notebook ou script e programá-lo para ser executado diariamente. Primeiro, use um arquivo JSON, como job-config.json, para definir um trabalho que execute um notebook específico.
{
"name": "example-job",
"new_cluster": {
"spark_version": "11.3.x-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 1
},
"notebook_task": {
"notebook_path": "/Users/username/my-notebook"
},
"schedule": {
"quartz_cron_expression": "0 0 * * * ?",
"timezone_id": "UTC"
}
}Crie o trabalho usando o comando abaixo:
databricks jobs create --json-file job-config.jsonVocê pode então executar o trabalho pelo seu ID de trabalho.
databricks jobs run-now --job-id <job-id>Operações de arquivo no DBFS
Se você precisar listar, copiar ou remover arquivos no DBFS, use os seguintes comandos.
Para visualizar os arquivos em um diretório:
databricks fs ls dbfs:/path/to/directoryFaça upload de um arquivo local para o DBFS:
databricks fs cp /local/path/file.txt dbfs:/path/to/remote-file.txtExcluir um arquivo ou diretório:
databricks fs rm dbfs:/path/to/file.txtPráticas recomendadas e dicas
Considere adotar as práticas recomendadas a seguir para maximizar a eficiência, a segurança e a confiabilidade da CLI da Databricks.
- Mantenha-se atualizado sobre as versões: Certifique-se de que você esteja usando a versão 0.200 ou posterior da Databricks CLI para se beneficiar do desenvolvimento ativo e dos novos recursos. As versões mais antigas são consideradas legadas e podem não oferecer suporte às funcionalidades mais recentes.
- Segurança: Evite armazenar tokens de acesso pessoal em texto simples. Em vez disso, use variáveis de ambiente ou métodos de armazenamento seguro, como arquivos criptografados ou ferramentas de gerenciamento de segredos.
- Roteiro: Use scripts Bash ou Python para automatizar tarefas encadeando vários comandos da CLI. Essa abordagem simplifica fluxos de trabalho complexos e aumenta a reprodutibilidade.
- Registro/Depuração: Use o sinalizador --debug para ativar a saída detalhada para fins de depuração. Isso pode ajudar a diagnosticar problemas, fornecendo mensagens de erro detalhadas.
databricks --debug clusters create --cluster-name my-cluster --node-type-id Standard_D2_v2 --num-workers 4Comparando a CLI do Databricks com outras abordagens
Ao trabalhar com a Databricks, os usuários têm várias opções para interagir com a plataforma, incluindo a CLI da Databricks, as APIs REST, o SDK Python da Databricks e a interface de usuário da Web. Cada método tem suas vantagens e desvantagens, dependendo das necessidades e preferências específicas do usuário ou da organização.
APIs REST
As APIs REST da Databricks fornecem acesso direto e de baixo nível à funcionalidade da Databricks, oferecendo a maior flexibilidade para integrações independentes de idioma.
SDK Python da Databricks
O Databricks Python SDK fornece uma interface Pythonic para interagir com o Databricks, oferecendo abstrações de alto nível sobre APIs REST.
IU da Web
A interface de usuário da Web do Databricks oferece uma interface gráfica interativa para gerenciar clusters, trabalhos, notebooks e muito mais.
Vou resumir as vantagens, os pontos fracos e os casos de uso dos métodos acima na tabela a seguir:
| Abordagem | Pontos fortes | Pontos fracos | Melhor uso |
|---|---|---|---|
| CLI da Databricks | Automação simples, com scripts e independente de sistema operacional | Limitado aos comandos CLI compatíveis | Automação leve e tarefas repetitivas |
| APIs REST | Flexível, independente de idioma | Complexo, requer mais esforço para ser implementado | Integrações personalizadas e recursos de ponta |
| SDK do Python | Abstrações de alto nível compatíveis com Python | Adiciona dependências, requer habilidades em Python | Fluxos de trabalho e pipelines de dados com uso intenso de Python |
| IU da Web | Fácil de usar, sem necessidade de configuração | Não pode ser dimensionado para automação | Tarefas interativas, únicas ou exploratórias |
Solução de problemas e problemas conhecidos
Ao usar a CLI da Databricks, você pode encontrar erros e desafios comuns. A seguir, você encontrará um resumo dos problemas frequentes e das soluções práticas, além de dicas para diagnosticar problemas relacionados à rede.
Erros frequentes
Os erros frequentes ao usar a CLI do Databricks incluem o seguinte:
- A autorização falhou: O erro pode ser causado por um token de acesso pessoal incorreto ou expirado. Para corrigir esse erro, verifique se o token é válido e está configurado corretamente nas definições da CLI. Se necessário, gere um novo token.
- CLI não encontrada no PATH: Esse erro ocorre quando o executável da CLI da Databricks não está no PATH do seu sistema. Para corrigir o problema, sempre adicione o diretório que contém o executável da CLI à variável de ambiente PATH do sistema.
- Validade do token: Os tokens têm uma vida útil limitada e expiram após um período definido. Para evitar esse erro, sempre renove seu token periodicamente ou configure um mecanismo para atualizar automaticamente os tokens.
Diagnosticar problemas de rede
Em ambientes com redes restritas ou listas de permissões de IP, você pode encontrar problemas para se conectar ao Databricks. Aqui estão algumas etapas para diagnosticar e resolver esses problemas:
-
Verifique a configuração da rede: Certifique-se de que sua rede permita conexões de saída para o URL do espaço de trabalho do Databricks. Verifique se todos os firewalls ou servidores proxy estão configurados corretamente.
-
Listas de permissões de IP: Se o seu espaço de trabalho exigir uma lista de permissões de IP, verifique se o seu endereço IP está incluído na lista. Use ferramentas como
curlpara testar a conectividade de sua máquina com a API da Databricks. -
Verificação de SSL: Se você encontrar erros de verificação de SSL, tente desativar temporariamente a verificação de SSL usando a opção-k com curl para isolar o problema.
Conclusão e recursos adicionais
Espero ter convencido você da ideia de que vale a pena praticar o uso da CLI da Databricks. Como você viu, a CLI do Databricks permite a automação rápida e com scripts de tarefas como gerenciamento de cluster, acionamento de trabalhos e operações de arquivos, reduzindo a dependência da interface do usuário da Web, o que economiza tempo. Fiquei impressionado com sua flexibilidade e com o fato de ter integração com pipelines de DevOps.
Definitivamente, há muitos detalhes específicos que eu não conseguiria abordar em um artigo, portanto, procure a documentação oficial da Databricks ou a página do GitHub da CLI se você estiver tentando encontrar a resposta para uma pergunta específica. Para saber mais sobre os conceitos básicos importantes, experimente nosso curso Introduction to Databricks. Este curso ensina a você sobre o Databricks como uma solução de armazenamento de dados para Business Intelligence. Também recomendo que, se você estiver seguindo o caminho do aprendizado da Databricks, leia também nosso guia sobre Certificações da Databricks, para que você possa não apenas aprender a Databricks, mas também se posicionar bem no mercado de trabalho.

