Die Databricks-Befehlszeilenschnittstelle (CLI) ist ein leistungsfähiges Tool, mit dem du Aufgaben auf der Databricks-Plattform direkt über das Terminal oder die Eingabeaufforderung automatisieren kannst. Mit der CLI können Nutzer Befehle zur Verwaltung von Clustern, Jobs und Notebooks ausführen, ohne durch die grafische Oberfläche navigieren zu müssen, was die Effizienz und die Integration in automatisierte Workflows verbessert.
Ab sofort ist das Databricks CLI in der Public Preview für die Versionen 0.205 und höher. Nutzer, die mit älteren Versionen arbeiten, sollten beachten, dass diese als veraltet gelten und möglicherweise nicht die neuesten Funktionen oder Verbesserungen unterstützen, die in den neueren Versionen verfügbar sind.
In diesem Tutorial zeige ich dir, wie du die CLI installierst und wie du mit den wichtigsten Befehlen in der CLI navigierst, um deine Arbeitsabläufe zu automatisieren. Für den Anfang empfehle ich dir einen Blick auf DataCamps How to Learn Databricks: Der Blogbeitrag A Beginner's Guide to the Unified Data Platform hilft dir, die wichtigsten Funktionen und Anwendungen von Databricks zu verstehen und bietet dir einen strukturierten Weg, um mit dem Lernen zu beginnen.
Warum wir das Databricks CLI verwenden
Als häufiger Nutzer finde ich die folgenden Gründe, warum du das Databricks CLI verwenden solltest.
- Automatisierung: Mit dem CLI kannst du Vorgänge wie die Erstellung von Clustern, die Übermittlung von Jobs und die Verwaltung von Notebooks skripten. Diese Automatisierung spart Zeit und verringert die Fehlerwahrscheinlichkeit. Du kannst zum Beispiel mit einem einzigen Befehl Aufträge erstellen und ausführen.
- Integration: Mit der Databricks CLI kannst du dich nahtlos in DevOps-Pipelines und CI/CD-Prozesse integrieren. Mit dieser Funktion kannst du deine Umgebungen ganz einfach so konfigurieren, dass Verteilungen und Aktualisierungen von Databricks-Workflows ohne manuelle Eingriffe automatisiert werden. Du kannst zum Beispiel automatisierte Jobs direkt aus Tools wie Jenkins, GitHub Actions oder Azure DevOps auslösen.
- Einfachheit: Du kannst Aufgaben direkt von deinem lokalen Rechner aus ausführen, sodass du für Routineaufgaben nicht mehr durch die Web-UI navigieren musst. Diese Funktion erleichtert die Verwaltung deiner Workflows, indem sie Befehle ausführt, um Vorgänge wie das Hochladen von Notebooks oder die Verwaltung von Clustern ohne den Overhead einer grafischen Oberfläche durchzuführen.
- Flexibilität: Das Databricks CLI unterstützt eine Vielzahl von Betriebssystemen und Umgebungen wie Windows, macOS und Linux, so dass es für unterschiedliche Teams zugänglich ist. Die CLI unterstützt auch die Multiprofil-Authentifizierung, so dass du mehrere Databricks-Konten oder Arbeitsbereiche effizient verwalten kannst.
Installieren und Aktualisieren der Databricks CLI
Um mit dem Databricks CLI loszulegen, musst du die Umgebungsvoraussetzungen erfüllen und die für dein Betriebssystem spezifischen Installationsanweisungen befolgen. Ich zeige dir, wie du die Umgebung einrichtest und die CLI unter Linux, macOS und Windows aktualisierst.
Voraussetzungen für die Umwelt
Bevor du das Databricks CLI installierst, solltest du sicherstellen, dass dein System diese grundlegenden Anforderungen erfüllt:
- Ein Paketmanager: Während ein Paketmanager wie Homebrew (für macOS) oder WinGet (für Windows) die Installation vereinfachen kann, kannst du auch direkt mit Binärdateien oder Quellcode installieren.
- Python: Die CLI erfordert Python 3.6 oder höher.
- Netzwerkzugriff auf den Databricks-Arbeitsbereich.
- Locken: Bei einigen Installationsmethoden unter Linux und macOS musst du sicherstellen, dass curl installiert ist.
- Administratorrechte (für einige Installationsmethoden).
Installieren unter Linux
Es gibt mehrere Möglichkeiten, das Databricks CLI unter Linux zu installieren, darunter die folgenden:
Homebrew verwenden
Wenn du Homebrew installiert hast, führe es aus:
brew install databricks-cliCurl verwenden
Du kannst Databricks CLI mit curl herunterladen und installieren, indem du den folgenden Befehl ausführst:
curl -Lo databricks-cli.tar.gz https://github.com/databricks/databricks-cli/releases/latest/download/databricks-cli.tar.gz
tar -xzf databricks-cli.tar.gz -C /usr/local/binHandbuch Download
Alternativ kannst du die CLI-Binärdatei aus dem offiziellen Databricks CLI GitHub Repository herunterladen und in ein Verzeichnis in deinem PATH verschieben.
Installieren unter macOS
Wenn du macOS verwendest, kannst du das Databricks CLI mit den folgenden Befehlen installieren.
Homebrew verwenden
Führe den folgenden Befehl aus, um Databricks CLI zu installieren;
brew install databricks-cliDirekte Binärinstallation
Lade die neueste Binärdatei von GitHub releases herunter, entpacke sie und platziere sie in deinem lokalen PATH. Mache sie mit dem folgenden Befehl ausführbar:
chmod +x /usr/local/bin/databricksHandbuch Download
Auf ähnliche Weise kannst du die CLI-Binärdatei vom offiziellen Databricks CLI GitHub Repository herunterladen und in ein Verzeichnis in deinem PATH verschieben.
Installieren unter Windows
Wenn du das Windows-Betriebssystem verwendest, kannst du Databricks CLI mit den folgenden Methoden installieren:
WinGet verwenden
Führe den folgenden Befehl in der Eingabeaufforderung aus:
winget install Databricks.DatabricksCLIMit Chocolatey
Wenn du Chocolatey installiert hast, verwende:
choco install databricks-cliVerwendung des Windows Subsystems für Linux (WSL)
Wenn die WSL eingerichtet ist, befolge die Schritte zur Linux-Installation.
Direkte Binärinstallation
Lade die Datei .exe aus dem Databricks CLI GitHub Repositoryherunter .
Füge das Verzeichnis, in dem sich die Datei befindet, zum PATH deines Systems hinzu, damit du leicht darauf zugreifen kannst.
Überprüfung der Installation
Nach der Installation solltest du überprüfen, ob das Databricks CLI korrekt installiert ist. Öffne ein Terminal oder eine Eingabeaufforderung und führe sie aus:
databricks --versionDatabricks CLI-Authentifizierung und Konfiguration
Um das Databricks CLI effektiv nutzen zu können, musst du es mit deinem Databricks-Arbeitsbereich authentifizieren. In diesem Abschnitt erfährst du, wie du die Authentifizierung einrichtest und die Konfigurationen verwaltest.
Erzeugen eines persönlichen Zugangstokens
Für die Authentifizierung beim Databricks CLI ist ein persönliches Zugangstoken (PAT) erforderlich. Befolge diese Schritte, um eine zu erstellen:
Schritt 1: Zugang zu den Benutzereinstellungen
Melde dich in deinem Databricks-Arbeitsbereich an und klicke auf deinen Benutzernamen in der oberen Leiste. Wähle Einstellungen aus dem Dropdown-Menü.
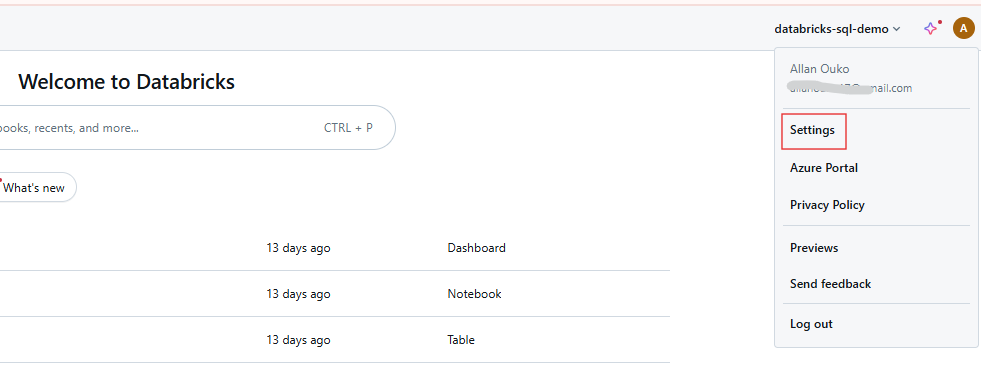
Databricks Arbeitsbereich Benutzereinstellungen. Bild vom Autor.
Schritt 2: Navigiere zu den Entwicklereinstellungen
Klicke auf Entwickler.
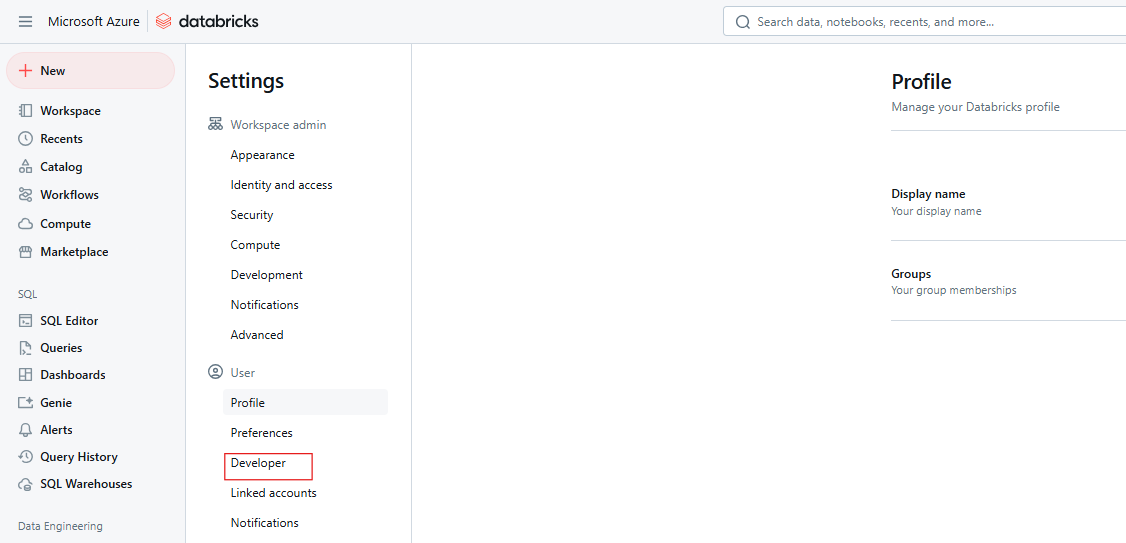
Databricks Developer-Einstellungen. Bild vom Autor.
Schritt 3: Zugangstokens verwalten
Klicke neben Zugriffstoken auf Verwalten.
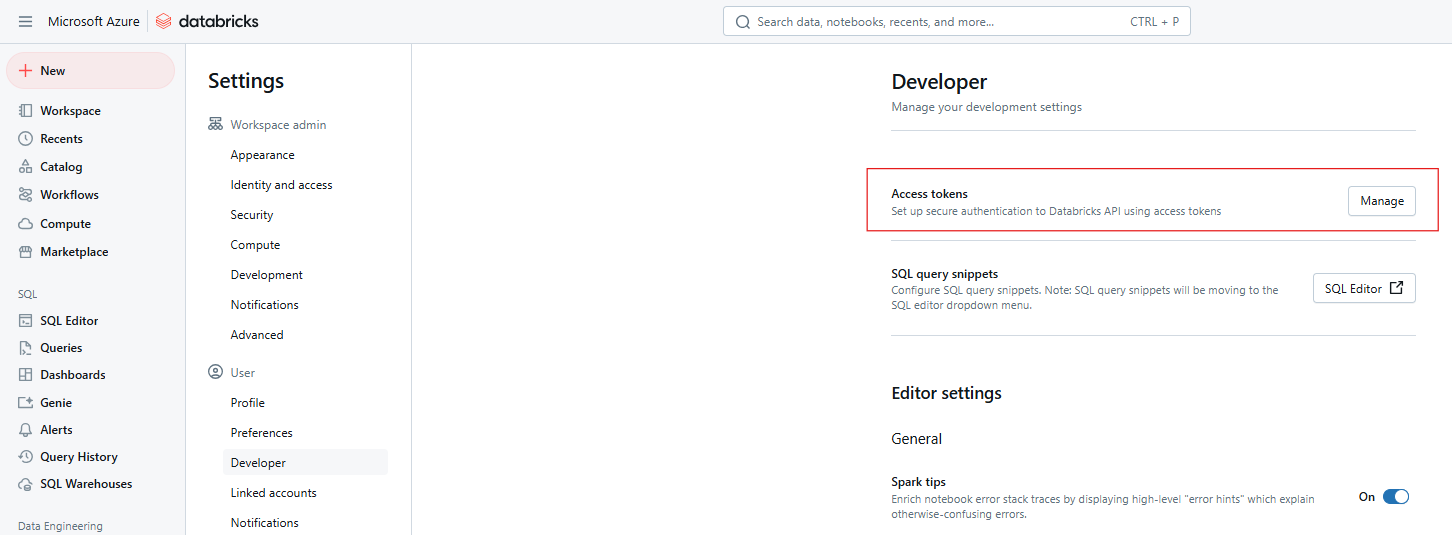
Databricks Zugriffstoken. Bild vom Autor
Schritt 4: Neues Token generieren
Klicke auf Neues Token generieren.
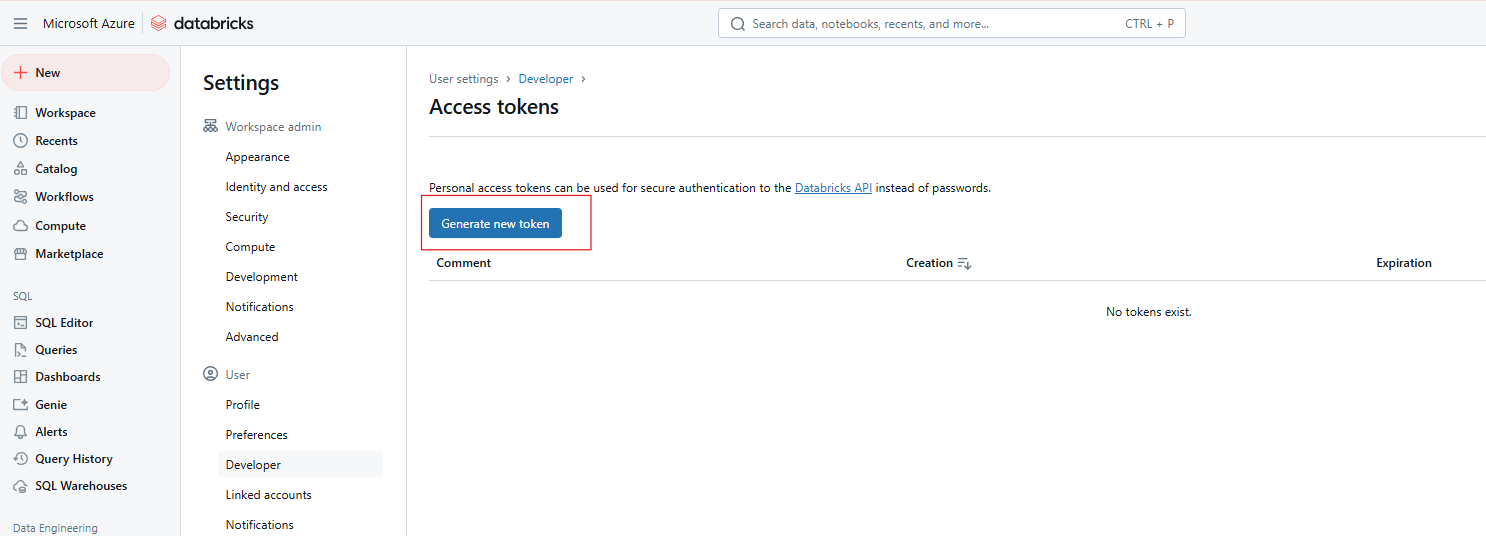
Generierung eines neuen Databricks Access Token. Bild vom Autor.
Schritt 5: Details eingeben und Token speichern
Gib einen Kommentar an, um das Token zu identifizieren und seine Lebensdauer in Tagen festzulegen. Wenn du nichts angibst, wird die maximale Lebensdauer (normalerweise 730 Tage) eingestellt. Klicke auf Erzeugen, kopiere den Token sicher und klicke dann auf Fertig.
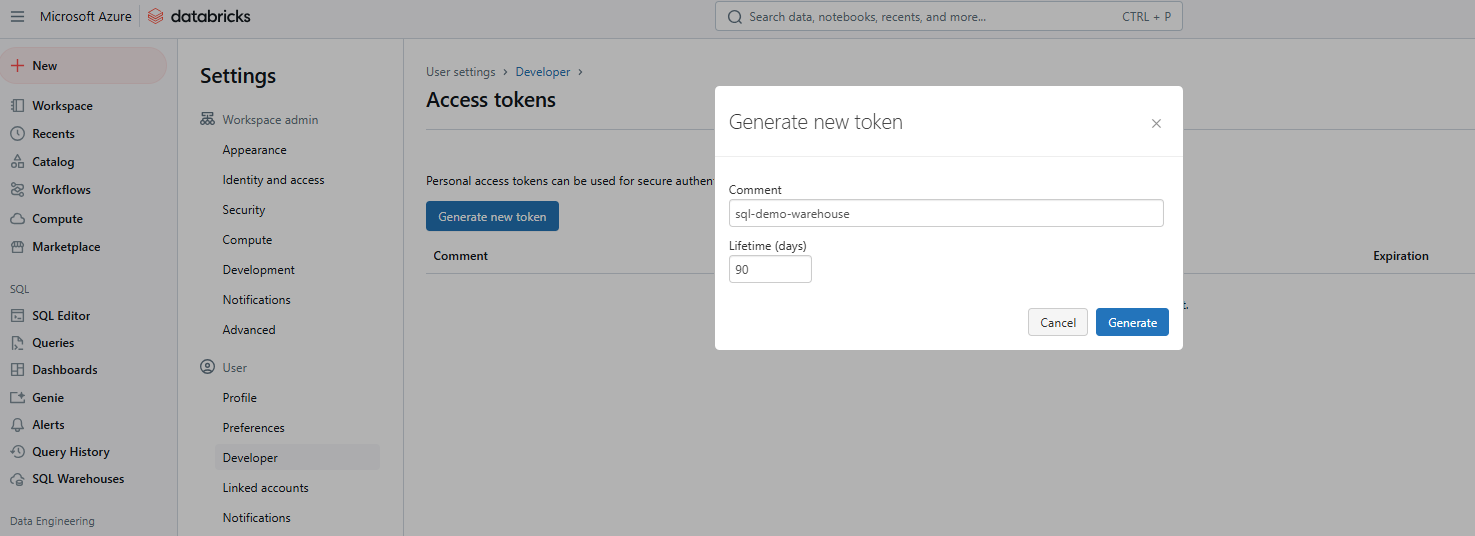
Generierung eines neuen Databricks Access Token. Bild vom Autor.
Profile konfigurieren
Sobald du deinen Token hast, konfigurierst du die CLI, um mit deinem Arbeitsbereich zu kommunizieren. Dazu musst du ein Profil einrichten, das deine Arbeitsbereichs-URL und dein Token enthält.
Grundkonfiguration
Führe den folgenden Befehl aus, um dein Standardprofil einzurichten:
databricks configure --tokenDu wirst zur Eingabe aufgefordert:
Die Databricks-Host-URL (z. B. https://<databricks-instance>.cloud.databricks.com).
Das persönliche Zugangs-Token, das du zuvor erstellt hast.
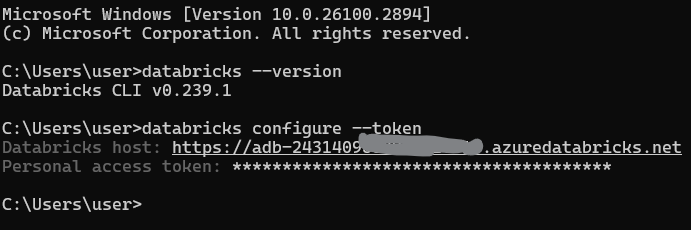
Databricks CLI-Profil konfigurieren. Bild vom Autor.
Mehrere Profile
Du kannst mehrere Profile für verschiedene Umgebungen (z. B. Dev, Staging, Production) konfigurieren:
databricks configure --profile <profile-name> --tokenUm ein bestimmtes Profil zu verwenden, füge das Flag --profile in deine CLI-Befehle ein:
databricks clusters list --profile stagingErweiterte Authentifizierung
Die Databricks CLI unterstützt Databricks Unified Authentication, die sich mit Identitätsmanagementsystemen wie Single Sign-On (SSO) und OAuth integrieren lässt. Dies ermöglicht eine sichere und skalierbare Authentifizierung über alle Databricks-APIs. Die einheitliche Authentifizierung vereinfacht die Benutzerverwaltung, indem sie eine einzige SSO-Konfiguration für mehrere Arbeitsbereiche ermöglicht, was die Verwaltung des Zugriffs und die Automatisierung von Aufgaben mithilfe von Dienstprinzipien erleichtert.
Die wichtigsten Databricks CLI-Befehle
Die Databricks-Befehlszeilen sind in übergeordnete Kategorien eingeteilt, die jeweils Unterbefehle für bestimmte Aufgaben enthalten. Im Folgenden findest du eine Aufschlüsselung der wichtigsten Kategorien und praktische Beispiele, die dir den Einstieg erleichtern. Wenn du dein Wissen über die wichtigsten Funktionen von Databricks auffrischen möchtest, empfehle ich dir unser Tutorial über die 7 wichtigsten Konzepte für jeden Datenspezialisten.
Clusters
Die Cluster-Befehle dienen der Verwaltung von Databricks-Clustern, einschließlich des Erstellens, Auflistens, Startens und Löschens. Zu den üblichen Unterbefehlen gehören die folgenden:
-
create: Erstelle einen neuen Cluster. -
list: Liste alle Cluster im Arbeitsbereich auf. -
startunddelete: Starte oder lösche einen Cluster.
Der folgende Befehl erstellt zum Beispiel einen neuen Cluster mit dem Namen my-cluster und 4 Arbeitern des Typs Standard_D2_v2.
databricks clusters create --cluster-name my-cluster --node-type-id Standard_D2_v2 --num-workers 4Du kannst auch den folgenden Befehl verwenden, um alle Cluster in deinem Databricks-Arbeitsbereich aufzulisten.
databricks clusters listJobs
Dies sind Befehle zur Verwaltung von Databricks-Jobs, einschließlich Erstellung, Ausführung und Auflistung. Zu den üblichen Unterbefehlen in Jobs gehören die folgenden:
-
create: Erstelle einen neuen Job. -
run-now: Einen bestehenden Job sofort auslösen. -
list: Liste alle verfügbaren Stellen auf.
Du kannst zum Beispiel einen neuen Job namens my-job erstellen, der eine Notebook-Aufgabe ausführt.
databricks jobs create --job-name my-job --notebook-task /path/to/notebookDu kannst einen bestehenden Job auch über seine ID auslösen, indem du den folgenden Befehl verwendest.
databricks jobs run-now --job-id 12345Arbeitsbereich
Dies sind Befehle zur Verwaltung von Arbeitsbereichsressourcen, wie z.B. das Importieren und Exportieren von Notizbüchern. Zu den üblichen Unterbefehlen in dieser Kategorie gehören die folgenden:
-
import: Importiere ein Notizbuch oder eine Bibliothek. -
export: Exportiere ein Notizbuch auf deinen lokalen Rechner. -
list: Den Inhalt eines Arbeitsbereich-Verzeichnisses auflisten.
Mit dem folgenden Befehl kannst du zum Beispiel ein Notizbuch in eine lokale Datei exportieren.
databricks workspace export /Users/username/notebook /local/path/notebook.pyAuf ähnliche Weise kannst du ein Notizbuch mit dem folgenden Befehl importieren.
databricks workspace import /local/path/notebook.py /Users/username/notebookDateisystem (DBFS)
Dies sind Befehle für die Interaktion mit dem Databricks File System (DBFS), einschließlich des Hoch- und Herunterladens von Dateien. Zu den üblichen Unterbefehlen in dieser Kategorie gehören die folgenden:
-
cp: Kopiere Dateien in oder aus dem DBFS. -
ls: Dateien in einem DBFS-Verzeichnis auflisten. -
rm: Entferne Dateien oder Verzeichnisse aus dem DBFS.
Du kannst zum Beispiel den folgenden Befehl verwenden, um eine lokale Datei in das DBFS hochzuladen.
databricks fs cp /local/path/file.txt dbfs:/path/in/dbfs/Ebenso kannst du mit dem folgenden Befehl eine Datei aus dem DBFS in einen lokalen Pfad herunterladen.
databricks fs cp dbfs:/path/in/dbfs/file.txt /local/path/Repos
Mit den Repos-Befehlen kannst du Repositories innerhalb von Databricks verwalten und die Versionskontrolle aktivieren. Zu den üblichen Unterbefehlen gehören die folgenden:
-
list: Liste alle Repositories auf. -
create: Füge ein neues Repository hinzu.
Der folgende Befehl listet zum Beispiel alle Databricks Repos in deinem Arbeitsbereich auf.
databricks repos listErlaubnisse
Mit diesen Befehlen kannst du Berechtigungen für Arbeitsbereiche, Jobs und Cluster festlegen und verwalten. Zu den allgemeinen Berechtigungsunterbefehlen gehören die folgenden:
-
get: Aktuelle Berechtigungen anzeigen. -
update: Ändere die Berechtigungen.
Mit dem folgenden Befehl kannst du zum Beispiel die Berechtigungen für eine bestimmte Ressource einsehen.
databricks permissions get --type cluster --id 12345Databricks SQL-Befehle
Mit diesen Befehlen kannst du mit Databricks SQL interagieren, um Datenbanken abzufragen und SQL-Warehouses zu verwalten.
Die folgende Abfrage holt die ersten 10 Zeilen aus der sales_table und zeigt sie an.
databricks sql query --query "SELECT * FROM sales_table LIMIT 10;"Wenn du dein Wissen über Databricks SQL auffrischen musst, empfehle ich dir, unser Databricks SQL-Tutorial zu lesen, um zu lernen, wie du SQL zur Abfrage von Daten aus dem Databricks SQL Warehouse verwendest.
Häufige Anwendungsfälle und Beispielszenarien
Das Databricks CLI bietet praktische Lösungen für die Automatisierung von Routineaufgaben. Im Folgenden findest du ausführliche Beispiele für gängige Szenarien, die seine Vielseitigkeit demonstrieren.
Erstellen oder Bearbeiten eines Clusters
Um einen Cluster zu erstellen, verwendest du eine JSON-Konfigurationsdatei, wie z.B. cluster-config.json,, die die Cluster-Einstellungen festlegt.
{
"cluster_name": "example-cluster",
"spark_version": "11.3.x-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 2
}Führe dann den folgenden Befehl aus, um den Cluster zu erstellen:
databricks clusters create --json-file cluster-config.jsonUm die Konfiguration eines bestehenden Clusters zu aktualisieren, exportiere zunächst die aktuellen Cluster-Einstellungen mit dem folgenden Befehl:
databricks clusters get --cluster-id <cluster-id> > cluster-config.jsonAls nächstes bearbeitest du die Datei cluster-config.json nach Bedarf und wendest die Änderungen auf den Cluster an.
databricks clusters edit --json-file cluster-config.jsonNotizbücher verwalten
In manchen Szenarien möchtest du vielleicht ein Notizbuch aus Databricks in ein lokales Verzeichnis exportieren und dann wieder importieren. Verwende den folgenden Befehl, um das Notizbuch zu importieren und zu exportieren:
databricks workspace export /path/to/notebook.ipynb /local/path/notebook.ipynbMit dem folgenden Befehl lädst du das Notizbuch zurück zu Databricks.
databricks workspace import /local/path/notebook.ipynb /path/to/notebook.ipynbJobs auslösen
Wenn du automatisierte Aufgaben erstellen willst, musst du vielleicht einen Job erstellen, der ein Notebook oder ein Skript ausführt und ihn für die tägliche Ausführung planen. Verwende zunächst eine JSON-Datei wie job-config.json, um einen Job zu definieren, der ein bestimmtes Notebook ausführt.
{
"name": "example-job",
"new_cluster": {
"spark_version": "11.3.x-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 1
},
"notebook_task": {
"notebook_path": "/Users/username/my-notebook"
},
"schedule": {
"quartz_cron_expression": "0 0 * * * ?",
"timezone_id": "UTC"
}
}Erstelle den Auftrag mit dem unten stehenden Befehl:
databricks jobs create --json-file job-config.jsonDu kannst den Job dann anhand seiner Job-ID ausführen.
databricks jobs run-now --job-id <job-id>Dateioperationen auf DBFS
Wenn du Dateien im DBFS auflisten, kopieren oder entfernen musst, verwende die folgenden Befehle.
Um Dateien in einem Verzeichnis anzuzeigen:
databricks fs ls dbfs:/path/to/directoryLade eine lokale Datei auf das DBFS hoch:
databricks fs cp /local/path/file.txt dbfs:/path/to/remote-file.txtLösche eine Datei oder ein Verzeichnis:
databricks fs rm dbfs:/path/to/file.txtBewährte Praktiken und Tipps
Um die Effizienz, Sicherheit und Zuverlässigkeit der Databricks CLI zu maximieren, solltest du die folgenden Best Practices anwenden.
- Bleib auf dem neuesten Stand der Versionen: Stelle sicher, dass du Databricks CLI Version 0.200 oder höher verwendest, um von der aktiven Entwicklung und den neuen Funktionen zu profitieren. Ältere Versionen gelten als veraltet und unterstützen möglicherweise nicht die neuesten Funktionalitäten.
- Sicherheit: Vermeide es, persönliche Zugangskennungen im Klartext zu speichern. Verwende stattdessen Umgebungsvariablen oder sichere Speichermethoden wie verschlüsselte Dateien oder Tools zur Verwaltung von Geheimnissen.
- Skript: Verwende Bash- oder Python-Skripte, um Aufgaben durch die Verkettung mehrerer CLI-Befehle zu automatisieren. Dieser Ansatz vereinfacht komplexe Arbeitsabläufe und verbessert die Reproduzierbarkeit.
- Logging/Debugging: Verwende das --debug-Flag, um ausführliche Ausgaben für Debugging-Zwecke zu aktivieren. Dies kann bei der Diagnose von Problemen helfen, da detaillierte Fehlermeldungen angezeigt werden.
databricks --debug clusters create --cluster-name my-cluster --node-type-id Standard_D2_v2 --num-workers 4Vergleich der Databricks CLI mit anderen Ansätzen
Wenn du mit Databricks arbeitest, hast du mehrere Möglichkeiten, mit der Plattform zu interagieren. Dazu gehören die Databricks CLI, die REST APIs, das Databricks Python SDK und die Web-UI. Jede Methode hat ihre Vor- und Nachteile, je nach den spezifischen Bedürfnissen und Vorlieben des Nutzers oder der Organisation.
REST-APIs
Die REST-APIs von Databricks bieten einen direkten Low-Level-Zugang zu den Funktionen von Databricks und bieten die größte Flexibilität für sprachunabhängige Integrationen.
Databricks Python SDK
Das Databricks Python SDK bietet eine Python-Schnittstelle für die Interaktion mit Databricks, die eine hohe Abstraktion über REST-APIs bietet.
Web UI
Die Databricks Web UI bietet eine interaktive grafische Oberfläche zur Verwaltung von Clustern, Jobs, Notebooks und mehr.
Ich fasse die Vorteile, Schwächen und Anwendungsfälle der oben genannten Methoden in der folgenden Tabelle zusammen:
| Annäherung | Stärken | Schwachstellen | Beste Verwendung |
|---|---|---|---|
| Databricks CLI | Einfache, skriptfähige, OS-unabhängige Automatisierung | Begrenzt auf unterstützte CLI-Befehle | Leichte Automatisierung und sich wiederholende Aufgaben |
| REST-APIs | Flexibel, sprachunabhängig | Kompliziert, erfordert mehr Aufwand bei der Umsetzung | Benutzerdefinierte Integrationen und hochmoderne Funktionen |
| Python SDK | Python-freundliche, hochgradige Abstraktionen | Fügt Abhängigkeiten hinzu, erfordert Python-Kenntnisse | Python-lastige Workflows und Datenpipelines |
| Web UI | Benutzerfreundlich, keine Einrichtung erforderlich | Nicht skalierbar für Automatisierung | Interaktive, einmalige oder Erkundungsaufgaben |
Fehlersuche und bekannte Probleme
Bei der Verwendung von Databricks CLI kannst du auf häufige Fehler und Herausforderungen stoßen. Im Folgenden findest du eine Übersicht über häufige Probleme und praktische Lösungen sowie Tipps zur Diagnose von Netzwerkproblemen.
Häufige Fehler
Zu den häufigen Fehlern bei der Verwendung von Databricks CLI gehören die folgenden:
- Autorisierung fehlgeschlagen: Der Fehler könnte durch ein falsches oder abgelaufenes persönliches Zugangstoken verursacht werden. Um diesen Fehler zu beheben, stelle sicher, dass dein Token gültig und in deinen CLI-Einstellungen richtig konfiguriert ist. Erstelle bei Bedarf einen neuen Token.
- CLI nicht in PATH gefunden: Dieser Fehler tritt auf, wenn sich die ausführbare Databricks CLI-Datei nicht im PATH deines Systems befindet. Um das Problem zu beheben, füge das Verzeichnis, das die ausführbare CLI-Datei enthält, zur Umgebungsvariablen PATH deines Systems hinzu.
- Ablauf des Tokens: Token haben eine begrenzte Lebensdauer und verfallen nach einer bestimmten Zeit. Um diesen Fehler zu vermeiden, solltest du dein Token regelmäßig erneuern oder einen Mechanismus zur automatischen Aktualisierung der Token einrichten.
Diagnose von Netzwerkproblemen
In Umgebungen mit eingeschränkten Netzwerken oder IP-Listen kann es zu Problemen bei der Verbindung mit Databricks kommen. Hier sind einige Schritte, um diese Probleme zu diagnostizieren und zu beheben:
-
Überprüfe die Netzwerkkonfiguration: Stelle sicher, dass dein Netzwerk ausgehende Verbindungen zur URL des Databricks-Arbeitsbereichs zulässt. Überprüfe, ob Firewalls oder Proxy-Server richtig konfiguriert sind.
-
IP Allowlists: Wenn dein Arbeitsbereich eine IP-Zulassungsliste erfordert, stelle sicher, dass deine IP-Adresse in der Liste enthalten ist. Verwende Tools wie
curl, um die Konnektivität deines Computers mit der Databricks-API zu testen. -
SSL-Überprüfung: Wenn du Fehler bei der SSL-Verifizierung feststellst, versuche, die SSL-Verifizierung mit der Option-k in curl vorübergehend zu deaktivieren, um das Problem einzugrenzen.
Fazit und weitere Ressourcen
Ich hoffe, ich konnte dich von der Idee überzeugen, dass es sich lohnt, mit dem Databricks CLI zu üben. Wie du gesehen hast, ermöglicht die Databricks CLI eine schnelle, skriptfähige Automatisierung von Aufgaben wie Cluster-Management, Job-Triggering und Dateioperationen, wodurch die Abhängigkeit von der Web-UI verringert wird, was Zeit spart. Ich bin beeindruckt von seiner Flexibilität und der Tatsache, dass es sich in DevOps-Pipelines integrieren lässt.
Es gibt definitiv eine Menge Details, die ich nicht in einem Artikel abdecken konnte. Schau also in der offiziellen Databricks-Dokumentation oder auf der GitHub-Seite des CLI nach, wenn du nach einer Antwort auf eine bestimmte Frage suchst. Um mehr über die wichtigen Grundkonzepte zu erfahren, probiere unseren Kurs Einführung in Databricks aus. In diesem Kurs lernst du Databricks als Data Warehousing-Lösung für Business Intelligence kennen. Außerdem empfehle ich dir, wenn du den Weg des Databricks-Lernens beschreitest, auch unseren Leitfaden zu Databricks-Zertifizierungen zu lesen, damit du nicht nur Databricks lernen, sondern dich auch auf dem Arbeitsmarkt gut positionieren kannst.

