L'interface de ligne de commande (CLI) de Databricks est un outil puissant qui permet aux utilisateurs d'automatiser des tâches sur la plateforme Databricks directement à partir du terminal ou de l'invite de commande. Avec le CLI, les utilisateurs peuvent exécuter des commandes pour gérer les clusters, les jobs et les notebooks sans avoir à naviguer dans l'interface graphique, ce qui améliore l'efficacité et l'intégration dans les flux de travail automatisés.
Pour l'instant, le CLI de Databricks est en Public Preview pour les versions 0.205 et supérieures. Les utilisateurs de versions plus anciennes doivent savoir que celles-ci sont considérées comme anciennes et qu'elles peuvent ne pas prendre en charge les dernières fonctionnalités ou améliorations disponibles dans les versions plus récentes.
Dans ce tutoriel, je vous montrerai comment installer le CLI et comment naviguer dans le CLI avec les principales commandes pour automatiser vos flux de travail. Pour commencer, je vous recommande vivement de consulter le site de DataCamp How to Learn Databricks : A Beginner's Guide to the Unified Data Platform blog post to help you understand the core features and applications of Databricks and provide a structured path to start your learning.
Pourquoi nous utilisons l'interface de programmation Databricks
En tant qu'utilisateur fréquent, je trouve les raisons suivantes pour lesquelles vous devriez utiliser le CLI de Databricks.
- Automatisation : L'interface CLI vous permet d'effectuer des opérations de script telles que la création de clusters, la soumission de travaux et la gestion des carnets de notes. Cette automatisation permet de gagner du temps et de réduire les risques d'erreur. Par exemple, vous pouvez créer et exécuter des travaux à l'aide d'une seule commande.
- Intégration : Le CLI de Databricks vous permet de vous intégrer de manière transparente aux pipelines DevOps et aux processus CI/CD. En utilisant cette fonctionnalité, vous pouvez facilement configurer vos environnements pour automatiser les déploiements et les mises à jour des flux de travail Databricks sans intervention manuelle. Par exemple, vous pouvez déclencher des tâches automatisées directement à partir d'outils tels que Jenkins, GitHub Actions ou Azure DevOps.
- Simplicité : Vous pouvez exécuter des tâches directement à partir de votre machine locale, ce qui vous évite de devoir naviguer dans l'interface web pour les tâches de routine. Cette fonction facilite la gestion de vos flux de travail en exécutant des commandes pour effectuer des opérations telles que le téléchargement de carnets de notes ou la gestion de clusters sans avoir recours à une interface graphique.
- Flexibilité : Le CLI Databricks prend en charge un large éventail de systèmes d'exploitation et d'environnements, tels que Windows, macOS et Linux, ce qui le rend accessible à diverses équipes. Le CLI prend également en charge l'authentification multi-profils, ce qui vous permet de gérer efficacement plusieurs comptes Databricks ou espaces de travail.
Installation et mise à jour du CLI Databricks
Pour commencer à utiliser le CLI Databricks, vous devez remplir les conditions préalables de l'environnement et suivre les instructions d'installation spécifiques à votre système d'exploitation. Je vous montrerai comment configurer l'environnement et mettre à jour le CLI sous Linux, macOS et Windows.
Conditions préalables à l'environnement
Avant d'installer le CLI Databricks, assurez-vous que votre système répond aux exigences de base suivantes :
- Un gestionnaire de paquets : Bien qu'un gestionnaire de paquets comme Homebrew (pour macOS) ou WinGet (pour Windows) puisse simplifier l'installation, vous pouvez également l'effectuer directement à l'aide des binaires ou du code source.
- Python : L'interface de programmation nécessite Python 3.6 ou une version ultérieure.
- Accès réseau à l'espace de travail Databricks.
- Boucle : Pour certaines méthodes d'installation sous Linux et macOS, assurez-vous que curl est installé.
- Privilèges d'administrateur (pour certaines méthodes d'installation).
Installation sous Linux
Il existe plusieurs approches pour installer le CLI Databricks sur Linux, notamment les suivantes :
Utilisation de Homebrew
Si vous avez installé Homebrew, exécutez :
brew install databricks-cliUtilisation de curl
Vous pouvez télécharger et installer Databricks CLI en utilisant curl en exécutant la commande suivante :
curl -Lo databricks-cli.tar.gz https://github.com/databricks/databricks-cli/releases/latest/download/databricks-cli.tar.gz
tar -xzf databricks-cli.tar.gz -C /usr/local/binTéléchargement du manuel
Vous pouvez également télécharger le binaire CLI depuis le dépôt officiel Databricks CLI GitHub et le déplacer dans un répertoire de votre site PATH.
Installation sur macOS
Si vous utilisez macOS, vous pouvez installer le CLI Databricks en utilisant les commandes suivantes.
Utilisation de Homebrew
Exécutez la commande ci-dessous pour installer Databricks CLI ;
brew install databricks-cliInstallation binaire directe
Téléchargez le dernier binaire à partir des versions GitHub, extrayez-le et placez-le dans votre site local PATH. Rendez-le exécutable à l'aide de la commande ci-dessous :
chmod +x /usr/local/bin/databricksTéléchargement du manuel
De même, vous pouvez télécharger le binaire CLI depuis le dépôt officiel Databricks CLI GitHub et le déplacer dans un répertoire de votre site PATH.
Installation sous Windows
Si vous utilisez le système d'exploitation Windows, vous pouvez choisir d'installer Databricks CLI à partir des méthodes suivantes :
Utilisation de WinGet
Exécutez la commande suivante dans l'invite de commande :
winget install Databricks.DatabricksCLIUtilisation du chocolat
Si vous avez installé Chocolatey, utilisez :
choco install databricks-cliUtilisation du sous-système Windows pour Linux (WSL)
Si le WSL est configuré, suivez les étapes de l'installation de Linux.
Installation binaire directe
Téléchargez le fichier .exe depuis le dépôt GitHub Databricks CLI.
Ajoutez le répertoire contenant le fichier à l'adresse PATH de votre système pour y accéder facilement.
Vérification de l'installation
Après l'installation, vous devez vérifier que le CLI Databricks est correctement installé. Ouvrez un terminal ou une invite de commande et exécutez :
databricks --versionAuthentification et configuration de la CLI de Databricks
Pour utiliser efficacement le CLI Databricks, vous devez l'authentifier avec votre espace de travail Databricks. Dans cette section, je vous expliquerai comment mettre en place l'authentification et gérer les configurations.
Générer un jeton d'accès personnel
Un jeton d'accès personnel (PAT) est nécessaire pour s'authentifier avec le CLI Databricks. Suivez les étapes suivantes pour en générer un :
Étape 1 : Accéder aux paramètres de l'utilisateur
Connectez-vous à votre espace de travail Databricks et cliquez sur votre nom d'utilisateur dans la barre supérieure. Sélectionnez Settings dans le menu déroulant.
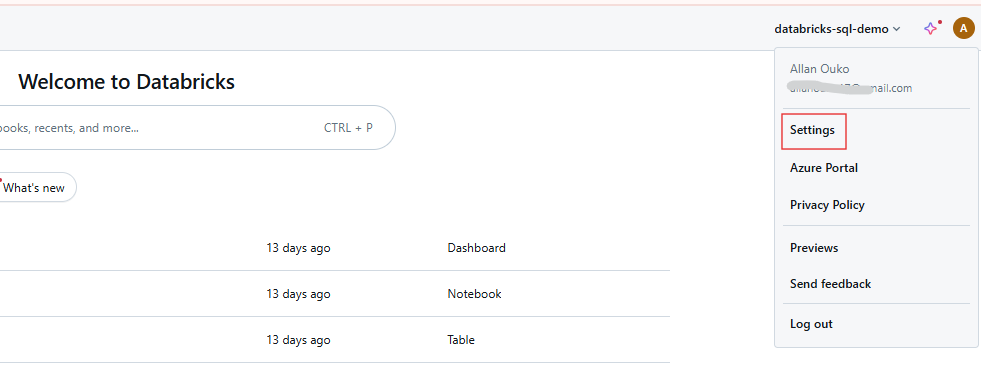
Paramètres de l'utilisateur de l'espace de travail Databricks. Image par l'auteur.
Étape 2 : Accédez aux paramètres du développeur
Cliquez sur Développeur.
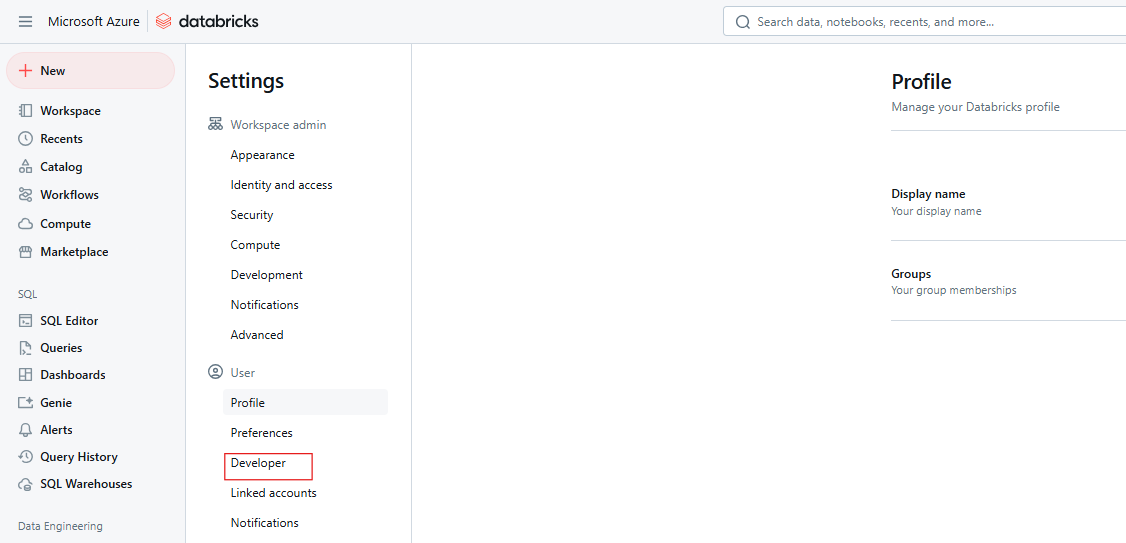
Paramètres du développeur Databricks. Image par l'auteur.
Étape 3 : Gérer les jetons d'accès
En regard de Jetons d' accès, cliquez sur Gérer.
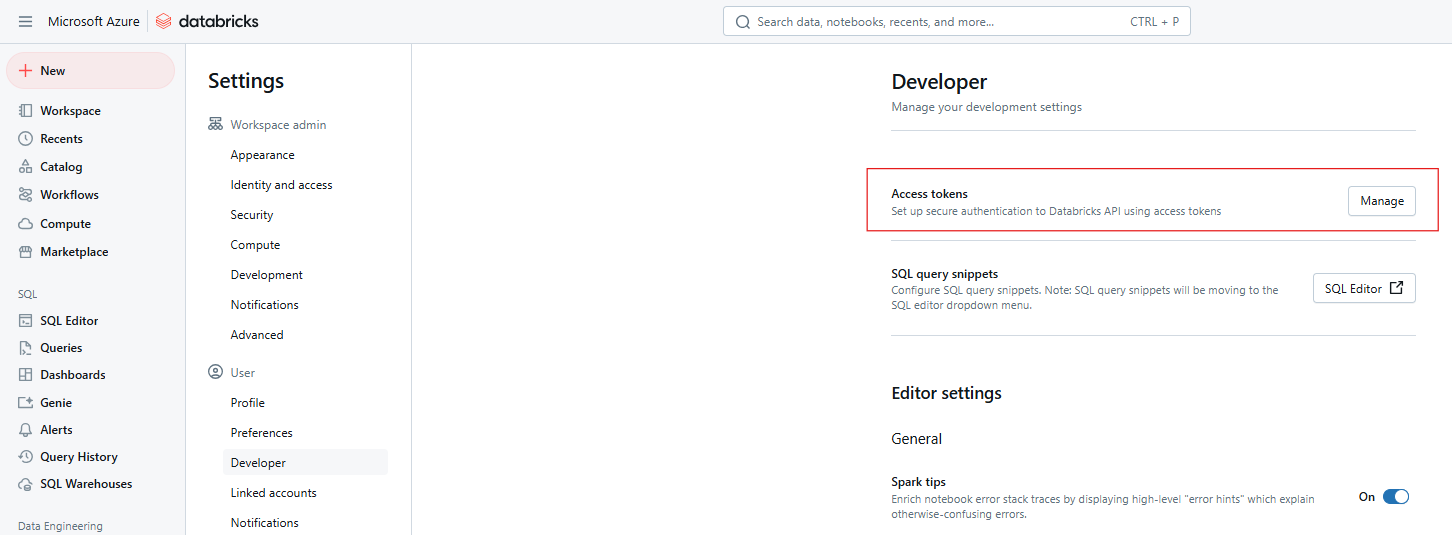
Databricks Jetons d'accès. Image par l'auteur
Étape 4 : Générer un nouveau jeton
Cliquez sur Générer un nouveau jeton.
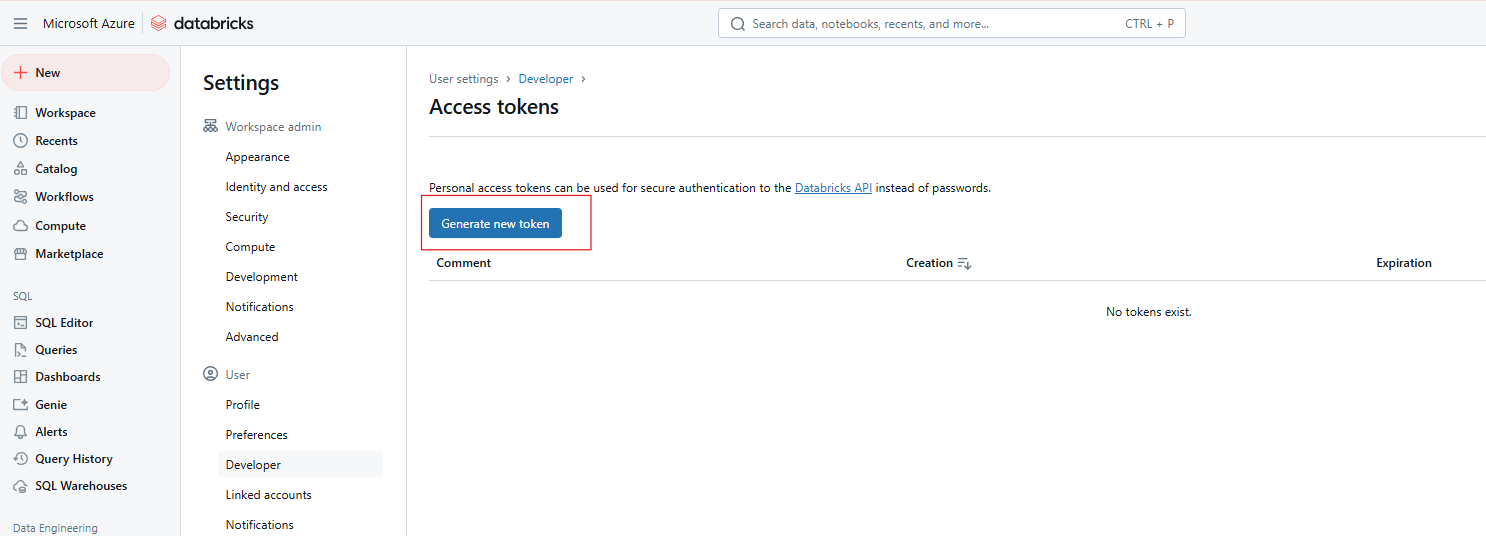
Génération d'un nouveau jeton d'accès à Databricks. Image par l'auteur.
Étape 5 : Saisissez les détails et enregistrez le jeton
Fournissez un commentaire pour identifier le jeton et définissez sa durée de vie en jours. S'il n'est pas renseigné, il correspond par défaut à la durée de vie maximale (généralement 730 jours). Cliquez sur Générer, copiez le jeton en toute sécurité, puis cliquez sur Terminé.
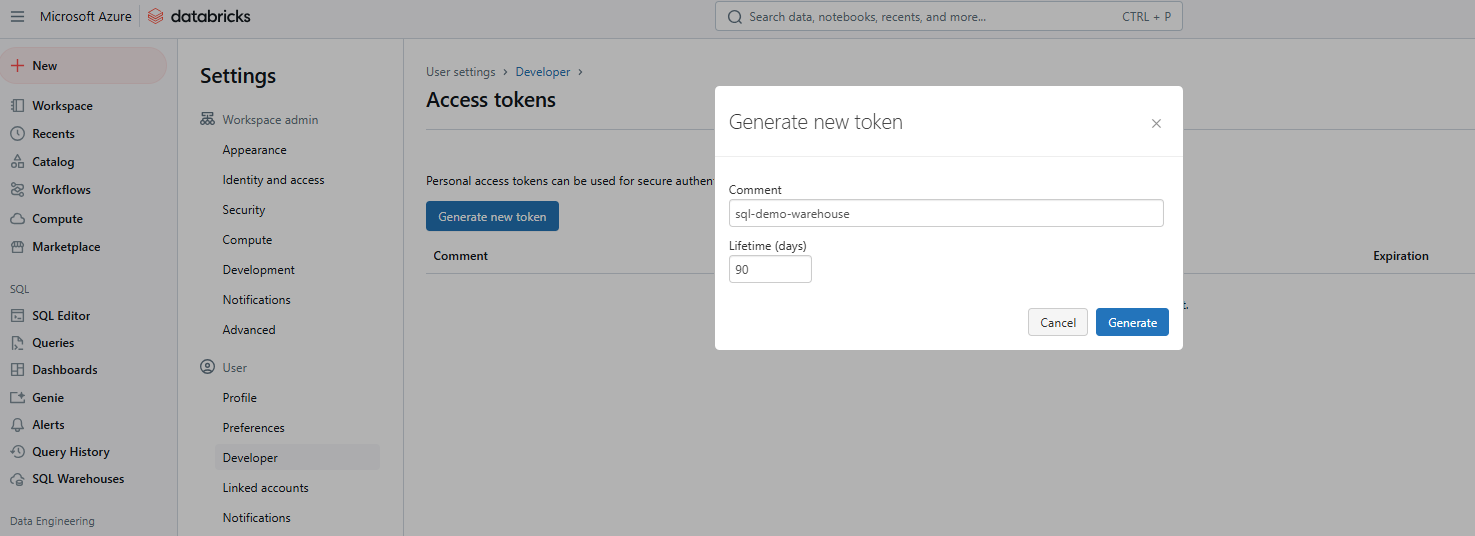
Génération d'un nouveau jeton d'accès à Databricks. Image par l'auteur.
Configuration des profils
Une fois que vous avez votre jeton, configurez le CLI pour communiquer avec votre espace de travail. Ce processus implique la création d'un profil qui inclut l'URL de votre espace de travail et votre jeton.
Configuration de base
Exécutez la commande suivante pour définir votre profil par défaut :
databricks configure --tokenVous serez invité à entrer :
L'URL de l'hôte Databricks (par exemple, https://<databricks-instance>.cloud.databricks.com).
Le jeton d'accès personnel que vous avez généré précédemment.
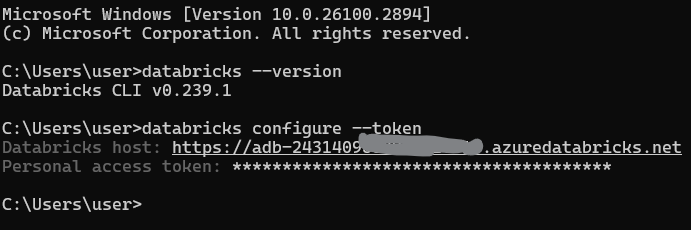
Configuration du profil CLI de Databricks. Image par l'auteur.
Profils multiples
Vous pouvez configurer plusieurs profils pour différents environnements (par exemple, dev, staging, production) :
databricks configure --profile <profile-name> --tokenPour utiliser un profil spécifique, incluez l'indicateur --profile dans vos commandes CLI :
databricks clusters list --profile stagingAuthentification avancée
Le CLI Databricks prend en charge l'authentification unifiée Databricks, qui s'intègre aux systèmes de gestion des identités d'entreprise tels que Single Sign-On (SSO) et OAuth. Cela permet une authentification sécurisée et évolutive dans toutes les API de Databricks. L'authentification unifiée simplifie la gestion des utilisateurs en permettant une configuration SSO unique pour plusieurs espaces de travail, ce qui facilite la gestion des accès et l'automatisation des tâches à l'aide de principes de service.
Les principales commandes CLI de Databricks
L'interface CLI de Databricks organise ses fonctionnalités en catégories de haut niveau, chacune comportant des sous-commandes adaptées à des tâches spécifiques. Vous trouverez ci-dessous une ventilation des principales catégories et des exemples pratiques pour vous aider à démarrer. Si vous avez besoin de rafraîchir vos connaissances sur les principales fonctionnalités de Databricks, je vous recommande de consulter notre tutoriel sur les 7 concepts incontournables pour tout spécialiste des données.
Groupes d'entreprises
Les commandes clusters permettent de gérer les clusters Databricks, notamment de les créer, de les répertorier, de les démarrer et de les supprimer. Les sous-commandes courantes sont les suivantes :
-
create: Créez un nouveau cluster. -
list: Liste de tous les clusters de l'espace de travail. -
startetdelete: Démarrer ou supprimer un cluster.
Par exemple, la commande suivante crée un nouveau cluster nommé my-cluster avec 4 travailleurs de type Standard_D2_v2.
databricks clusters create --cluster-name my-cluster --node-type-id Standard_D2_v2 --num-workers 4Vous pouvez également utiliser la commande suivante pour répertorier tous les clusters de votre espace de travail Databricks.
databricks clusters listEmplois
Il s'agit de commandes permettant de gérer les travaux Databricks, notamment la création, l'exécution et l'énumération. Les sous-commandes les plus courantes dans les jobs sont les suivantes :
-
create: Créez un nouvel emploi. -
run-now: Déclencher immédiatement un travail existant. -
list: Liste de tous les emplois disponibles.
Par exemple, vous pouvez créer un nouveau travail nommé my-job qui exécute une tâche de bloc-notes.
databricks jobs create --job-name my-job --notebook-task /path/to/notebookVous pouvez également déclencher un travail existant par son ID à l'aide de la commande ci-dessous.
databricks jobs run-now --job-id 12345Espace de travail
Il s'agit de commandes permettant de gérer les ressources de l'espace de travail, telles que l'importation et l'exportation de carnets de notes. Les sous-commandes les plus courantes de cette catégorie sont les suivantes :
-
import: Importer un carnet ou une bibliothèque. -
export: Exporter un carnet de notes vers votre machine locale. -
list: Liste du contenu d'un répertoire de l'espace de travail.
Par exemple, vous pouvez exporter un carnet de notes vers un fichier local à l'aide de la commande ci-dessous.
databricks workspace export /Users/username/notebook /local/path/notebook.pyDe même, vous pouvez importer un carnet de notes à l'aide de la commande ci-dessous.
databricks workspace import /local/path/notebook.py /Users/username/notebookSystème de fichiers (DBFS)
Il s'agit de commandes permettant d'interagir avec le système de fichiers Databricks (DBFS), y compris l'envoi et le téléchargement de fichiers. Les sous-commandes les plus courantes de cette catégorie sont les suivantes :
-
cp: Copier des fichiers vers ou depuis DBFS. -
ls: Liste des fichiers d'un répertoire DBFS. -
rm: Supprimez des fichiers ou des répertoires de DBFS.
Par exemple, vous pouvez utiliser la commande ci-dessous pour télécharger un fichier local vers DBFS.
databricks fs cp /local/path/file.txt dbfs:/path/in/dbfs/De même, la commande suivante vous permet de télécharger un fichier de DBFS vers un chemin local.
databricks fs cp dbfs:/path/in/dbfs/file.txt /local/path/Dépôts
Les commandes repos vous permettent de gérer les dépôts au sein de Databricks, permettant ainsi le contrôle des versions. Les sous-commandes courantes sont les suivantes :
-
list: Lister tous les dépôts. -
create: Ajouter un nouveau dépôt.
Par exemple, la commande suivante listera tous les Databricks Repos de votre espace de travail.
databricks repos listPermissions
Vous pouvez utiliser ces commandes pour définir et gérer les autorisations pour les espaces de travail, les travaux et les clusters. Les sous-commandes d'autorisation courantes sont les suivantes :
-
get: Voir les autorisations actuelles. -
update: Modifier les autorisations.
Par exemple, la commande ci-dessous vous permet de visualiser les autorisations pour une ressource spécifique.
databricks permissions get --type cluster --id 12345Commandes SQL de Databricks
Ces commandes vous permettent d'interagir avec Databricks SQL pour interroger des bases de données et gérer des entrepôts SQL.
La requête suivante récupère et affiche les 10 premières lignes du site sales_table.
databricks sql query --query "SELECT * FROM sales_table LIMIT 10;"Si vous avez besoin de rafraîchir vos connaissances sur Databricks SQL, je vous recommande de lire notre tutoriel Databricks SQL pour apprendre à utiliser SQL pour interroger les données de Databricks SQL Warehouse.
Cas d'utilisation courants et exemples de scénarios
Le CLI de Databricks offre des solutions pratiques pour automatiser les tâches de routine. Vous trouverez ci-dessous des exemples détaillés de scénarios courants qui démontrent sa polyvalence.
Créer ou modifier un cluster
Pour créer un cluster, utilisez un fichier de configuration JSON, tel que cluster-config.json,, qui spécifie les paramètres du cluster.
{
"cluster_name": "example-cluster",
"spark_version": "11.3.x-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 2
}Exécutez ensuite la commande suivante pour créer le cluster :
databricks clusters create --json-file cluster-config.jsonPour mettre à jour la configuration d'un cluster existant, exportez d'abord les paramètres actuels du cluster à l'aide de la commande ci-dessous :
databricks clusters get --cluster-id <cluster-id> > cluster-config.jsonEnsuite, modifiez le fichier cluster-config.json si nécessaire et appliquez les changements au cluster.
databricks clusters edit --json-file cluster-config.jsonGestion des carnets de notes
Dans certains cas, vous pouvez exporter un carnet de notes de Databricks vers un répertoire local, puis le réimporter. Utilisez la commande suivante pour importer ou exporter le carnet :
databricks workspace export /path/to/notebook.ipynb /local/path/notebook.ipynbLa commande ci-dessous est utilisée pour télécharger le carnet vers Databricks.
databricks workspace import /local/path/notebook.ipynb /path/to/notebook.ipynbDéclencher des emplois
Lorsque vous souhaitez créer des tâches automatisées, vous pouvez avoir besoin de créer un travail qui exécute un cahier ou un script et de le programmer pour qu'il s'exécute tous les jours. Tout d'abord, utilisez un fichier JSON tel que job-config.json pour définir un travail qui exécute un bloc-notes spécifique.
{
"name": "example-job",
"new_cluster": {
"spark_version": "11.3.x-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 1
},
"notebook_task": {
"notebook_path": "/Users/username/my-notebook"
},
"schedule": {
"quartz_cron_expression": "0 0 * * * ?",
"timezone_id": "UTC"
}
}Créez le job à l'aide de la commande ci-dessous :
databricks jobs create --json-file job-config.jsonVous pouvez ensuite exécuter le travail en utilisant son numéro d'identification.
databricks jobs run-now --job-id <job-id>Opérations de fichiers sur DBFS
Si vous devez répertorier, copier ou supprimer des fichiers dans DBFS, utilisez les commandes suivantes.
Pour visualiser les fichiers d'un répertoire :
databricks fs ls dbfs:/path/to/directoryTéléchargez un fichier local vers DBFS :
databricks fs cp /local/path/file.txt dbfs:/path/to/remote-file.txtSupprimez un fichier ou un répertoire :
databricks fs rm dbfs:/path/to/file.txtMeilleures pratiques et conseils
Pensez à adopter les meilleures pratiques suivantes pour maximiser l'efficacité, la sécurité et la fiabilité de l'interface CLI de Databricks.
- Restez à jour sur les versions : Assurez-vous d'utiliser la version 0.200 ou ultérieure de Databricks CLI pour bénéficier du développement actif et des nouvelles fonctionnalités. Les versions antérieures sont considérées comme anciennes et peuvent ne pas prendre en charge les fonctionnalités les plus récentes.
- La sécurité : Évitez de stocker des jetons d'accès personnels en texte clair. Utilisez plutôt des variables d'environnement ou des méthodes de stockage sécurisées telles que des fichiers cryptés ou des outils de gestion des secrets.
- Le texte : Utilisez des scripts Bash ou Python pour automatiser des tâches en enchaînant plusieurs commandes CLI. Cette approche simplifie les flux de travail complexes et améliore la reproductibilité.
- Journalisation/débogage : Utilisez l'option --debug pour activer la sortie verbale à des fins de débogage. Cela peut aider à diagnostiquer les problèmes en fournissant des messages d'erreur détaillés.
databricks --debug clusters create --cluster-name my-cluster --node-type-id Standard_D2_v2 --num-workers 4Comparaison de l'interface de programmation Databricks avec d'autres approches
Lorsqu'ils travaillent avec Databricks, les utilisateurs disposent de plusieurs options pour interagir avec la plateforme, notamment la CLI Databricks, les API REST, le SDK Databricks Python et l'interface utilisateur web. Chaque méthode a ses avantages et ses inconvénients, en fonction des besoins et des préférences spécifiques de l'utilisateur ou de l'organisation.
API REST
Les API REST de Databricks fournissent un accès direct et de bas niveau aux fonctionnalités de Databricks, offrant la plus grande flexibilité pour des intégrations agnostiques en termes de langues.
SDK Python de Databricks
Le SDK Databricks Python fournit une interface Python pour interagir avec Databricks, offrant des abstractions de haut niveau sur les API REST.
Interface utilisateur Web
L'interface Web de Databricks fournit une interface graphique interactive pour gérer les clusters, les jobs, les notebooks, etc.
Je vais résumer les avantages, les faiblesses et les cas d'utilisation des méthodes susmentionnées dans le tableau suivant :
| Approche | Points forts | Faiblesses | Meilleure utilisation |
|---|---|---|---|
| CLI Databricks | Automatisation simple, scriptable et indépendante du système d'exploitation | Limité aux commandes CLI prises en charge | Automatisation légère et tâches répétitives |
| API REST | Flexible, agnostique sur le plan linguistique | Complexe, nécessite plus d'efforts pour sa mise en œuvre | Intégrations personnalisées et fonctionnalités de pointe |
| SDK Python | Abstractions de haut niveau adaptées à Python | Ajoute des dépendances, nécessite des compétences en Python | Workflows et pipelines de données à forte intensité de Python. |
| Interface utilisateur Web | Convivialité, aucune configuration n'est requise | Pas d'automatisation possible | Tâches interactives, ponctuelles ou exploratoires |
Dépannage et problèmes connus
Lorsque vous utilisez le CLI de Databricks, vous pouvez rencontrer des erreurs et des défis communs. Vous trouverez ci-dessous un résumé des problèmes les plus fréquents et des solutions pratiques, ainsi que des conseils pour diagnostiquer les problèmes liés au réseau.
Erreurs fréquentes
Les erreurs fréquentes lors de l'utilisation de Databricks CLI sont les suivantes :
- Échec de l'autorisation : L'erreur peut être due à un jeton d'accès personnel incorrect ou expiré. Pour corriger cette erreur, assurez-vous que votre jeton est valide et correctement configuré dans les paramètres de votre CLI. Si nécessaire, générez un nouveau jeton.
- CLI introuvable dans PATH : Cette erreur se produit lorsque l'exécutable Databricks CLI ne se trouve pas dans le PATH de votre système. Pour résoudre ce problème, ajoutez toujours le répertoire contenant l'exécutable CLI à la variable d'environnement PATH de votre système.
- Expiration du jeton : Les jetons ont une durée de vie limitée et expirent après une période déterminée. Pour éviter cette erreur, renouvelez toujours votre jeton périodiquement ou mettez en place un mécanisme de rafraîchissement automatique des jetons.
Diagnostiquer les problèmes de réseau
Dans les environnements avec des réseaux restreints ou des listes d'autorisations IP, vous pouvez rencontrer des problèmes de connexion aux Databricks. Voici quelques étapes pour diagnostiquer et résoudre ces problèmes :
-
Vérifiez la configuration du réseau : Assurez-vous que votre réseau autorise les connexions sortantes vers l'URL de l'espace de travail Databricks. Vérifiez que les pare-feu ou les serveurs proxy sont correctement configurés.
-
Listes d'adresses IP : Si votre espace de travail nécessite une liste d'autorisations IP, assurez-vous que votre adresse IP est incluse dans la liste. Utilisez des outils tels que
curlpour tester la connectivité de votre machine à l'API Databricks. -
Vérification SSL : Si vous rencontrez des erreurs de vérification SSL, essayez de désactiver temporairement la vérification SSL en utilisant l'option-k avec curl pour isoler le problème.
Conclusion et autres ressources
J'espère vous avoir convaincu que la pratique de l'utilisation de l'interface CLI de Databricks en vaut la peine. Comme vous l'avez vu, l'interface CLI de Databricks permet une automatisation rapide et scriptable de tâches telles que la gestion des clusters, le déclenchement de tâches et les opérations sur les fichiers, réduisant ainsi la dépendance à l'égard de l'interface utilisateur Web, ce qui permet de gagner du temps. J'ai été impressionné par sa flexibilité et par le fait qu'il s'intègre aux pipelines DevOps.
Il y a certainement beaucoup de détails particuliers que je n'ai pas pu couvrir dans un seul article, alors essayez de regarder la documentation officielle de Databricks ou la page GitHub du CLI si vous essayez de trouver la réponse à une question spécifique. Pour en savoir plus sur les concepts fondamentaux, essayez notre cours Introduction à Databricks. Ce cours vous apprend à connaître Databricks en tant que solution d'entreposage de données pour la Business Intelligence. Je vous recommande également, si vous vous apprêtez à apprendre Databricks, de lire notre guide sur les certifications Databricks, afin que vous puissiez non seulement apprendre Databricks mais aussi bien vous positionner sur le marché de l'emploi.
