
Curso
Comprender la ingeniería de datos
2 h
355.8K
Databricks es una plataforma analítica abierta para construir, desplegar y mantener soluciones de datos, análisis e IA a escala. Está basado en Apache Spark y se integra con cualquiera de los tres principales proveedores de la nube (AWS, Azure o GCP), lo que nos permite gestionar y desplegar la infraestructura de la nube en nuestro nombre, a la vez que ofrecemos cualquier aplicación de ciencia de datos que puedas imaginar.
Hoy quiero guiarte a través de una completa introducción a Databricks, cubriendo sus características principales, aplicaciones prácticas y rutas de aprendizaje estructuradas para que puedas empezar. Desde la configuración de tu entorno hasta el dominio del procesamiento de datos, la orquestación y la visualización, encontrarás todo lo que necesitas para empezar con Databricks.
Aprender Databricks y tener unas bases sólidas en él puede tener varias ventajas positivas principales para ti:
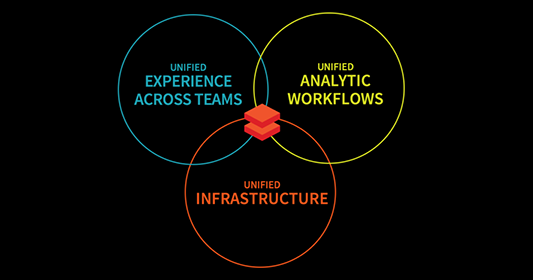
Databricks es una plataforma integral para la ingeniería de datos, la analítica y el aprendizaje automático, que combina cinco características principales que mejoran la escalabilidad, la colaboración y la eficacia del flujo de trabajo.

Características principales de Databricks. Imagen del autor.
Databricks combina los tres flujos de trabajo de ingeniería de datos, ciencia de datos y aprendizaje automático en una única plataforma. Esto simplifica aún más el procesamiento de datos, la formación de modelos y la implantación. Al unificar estos dominios, Databricks acelera las iniciativas de IA, ayudando a las empresas a transformar los datos aislados en información práctica, al tiempo que fomenta la colaboración.
Apache Spark, el principal marco de computación distribuida, está profundamente integrado con Databricks. Esto permite a Databricks gestionar la configuración de Spark automáticamente. Por tanto, los usuarios pueden centrarse en crear soluciones de datos sin preocuparse de la configuración.
Además, la potencia de procesamiento distribuido de Spark es ideal para tareas de big data, y Databricks la mejora con seguridad, escalabilidad y optimización de nivel empresarial.
Delta Lake es la columna vertebral de la arquitectura Lakehouse de Databricks, que añade funciones como transacciones ACID, aplicación de esquemas y coherencia de datos en tiempo real. Esto garantiza la fiabilidad y precisión de los datos, lo que convierte a Delta Lake en una herramienta fundamental para gestionar tanto datos por lotes como datos en flujo.
MLflow es una plataforma de código abierto para gestionar todo el ciclo de vida del aprendizaje automático. Desde el seguimiento de experimentos hasta la gestión del despliegue de modelos, MLflow simplifica el proceso de creación y puesta en funcionamiento de modelos de ML.
Además, con las últimas integraciones para herramientas de IA generativa como OpenAI y Hugging Face, MLflow amplía sus capacidades para incluir aplicaciones de vanguardia como chatbots, resumen de documentos y análisis de sentimientos.
Databricks fomenta la colaboración mediante:
Empezar a utilizar Databricks puede ser tan emocionante como abrumador. Por eso, el primer paso en el aprendizaje de cualquier tecnología nueva es tener claros tus objetivos: por qué quieres aprenderla y cómo piensas utilizarla.
Antes de sumergirte, define lo que quieres conseguir con Databricks.
¿Buscas agilizar el procesamiento de big data como ingeniero de datos? ¿O estás centrado en aprovechar sus capacidades ML para construir y desplegar modelos predictivos?
Al definir tus objetivos principales, puedes crear un plan de aprendizaje enfocado en consecuencia. Aquí tienes algunos consejos en función de tu principal aspiración:
Empezar a utilizar Databricks puede ser más fácil de lo que crees. Para ello, te guiaré paso a paso, para que puedas familiarizarte fácilmente con lo esencial de la plataforma.
Empieza por crear una cuenta gratuita en Databricks Edición Comunidadque proporciona acceso a las funciones básicas de la plataforma sin coste alguno. Esta edición es perfecta para la exploración práctica, ya que te permite experimentar con Espacios de trabajo, Clusters y Cuadernos sin necesidad de una suscripción de pago.
Captura de pantalla de la vista principal del registro en Databricks. Imagen del autor
Una vez que des tus datos, aparecerá la siguiente vista.

Captura de pantalla de la vista principal del registro en Databricks. Imagen del autor
En este caso, se te pedirá que configures un proveedor de la nube o que continúes con la Edición Comunidad. Para mantener las cosas accesibles, utilizaremos la Edición Comunidad. Aunque ofrece menos funciones que la versión Enterprise, es ideal para casos de uso más reducidos, como los tutoriales, y no requiere la configuración de un proveedor en la nube.
Tras seleccionar la Edición Comunidad, verifica tu dirección de correo electrónico. Una vez verificado, te aparecerá un panel principal con el siguiente aspecto:
Captura de pantalla de la página principal de Databricks. Imagen del autor
Una vez conectado, tómate tu tiempo para entender el diseño. A primera vista, la interfaz puede parecer básica, pero una vez que explores más a fondo o actualices tu cuenta, descubrirás un montón de funciones estupendas:
Databricks tiene tres conceptos básicos que seguirán siendo básicos para cualquier profesional dispuesto a dominarlo:
Suscríbete a DataFramed dondequiera que recibas tus podcasts.

Aprende Databricks con DataCamp
Curso
Curso
Curso
blog
Gus Frazer
11 min
blog
Gus Frazer
14 min
Tutorial
Natassha Selvaraj
Tutorial
Joleen Bothma
Tutorial
DataCamp Team
Tutorial
Moez Ali