
Curso
Implementación de IA en producción con FastAPI
4 h
4.5K
La arquitectura de agentes más común hoy en día consiste en un LLM que llama a herramientas en un bucle, lo cual es sencillo y eficaz, pero en última instancia limitado. Si bien este enfoque funciona para tareas sencillas, se queda corto cuando se enfrentan retos complejos y de múltiples pasos que requieren planificación, gestión del contexto y ejecución sostenida durante períodos de tiempo más largos.
La arquitectura Deep Agents de LangChain combina indicaciones detalladas del sistema, herramientas de planificación, subagentes y sistemas de archivos para crear agentes de IA capaces de abordar tareas complejas de investigación, codificación y análisis. Aplicaciones como Claude Code, Deep Research y Manus han demostrado la eficacia de este enfoque, y ahora el paquete Python deepagents pone esta arquitectura al alcance de todos.
En este tutorial, explicaré paso a paso cómo:
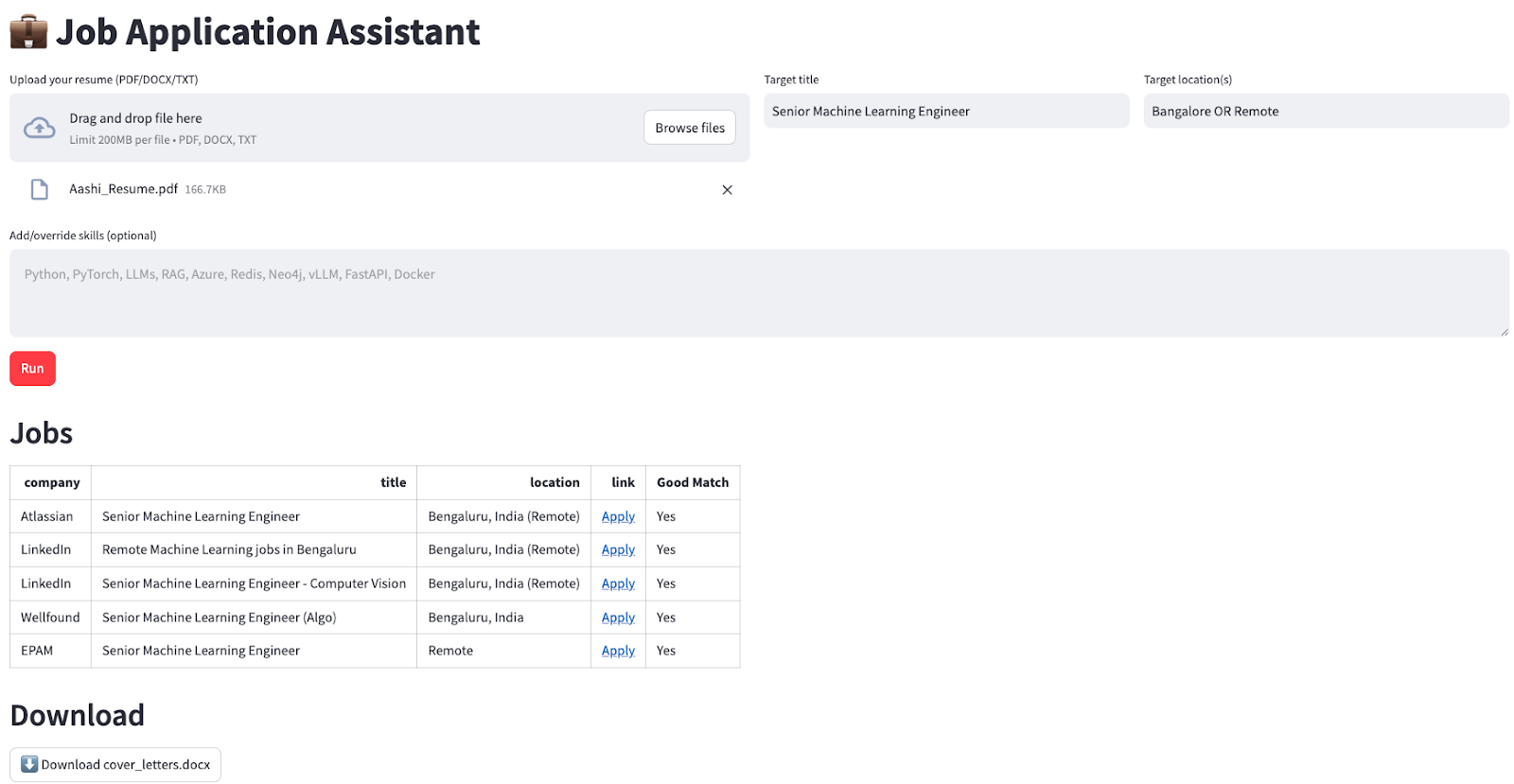
Los Deep Agents son una arquitectura avanzada diseñada para gestionar tareas complejas y de varios pasos que requieren razonamiento sostenido, uso de herramientas y memoria. A diferencia de los agentes tradicionales que operan en bucles cortos o realizan llamadas de herramientas simples, los Deep Agents planifican sus acciones, gestionan el contexto en evolución, delegan subtareas a subagentes especializados y mantienen el estado a lo largo de interacciones prolongadas. Esta arquitectura ya está impulsando aplicaciones del mundo real como Claude Code, Deep Researchy Manus.
Fuente: LangChain
Estas son las características clave de los agentes profundos:
Los Deep Agents superan las limitaciones de los agentes tradicionales gracias a cuatro componentes básicos:
A diferencia de las simples indicaciones de instrucciones, los agentes profundos utilizan indicaciones completas del sistema, como se muestra a continuación:
DEEP_AGENT_SYSTEM_PROMPT = """
You are an expert research assistant capable of conducting thorough,
multi-step investigations. Your capabilities include:
PLANNING: Break complex tasks into subtasks using the todo_write tool
RESEARCH: Use internet_search extensively to gather comprehensive information
DELEGATION: Spawn sub-agents for specialized tasks using the call_subagent tool
DOCUMENTATION: Maintain detailed notes using the file system tools
When approaching a complex task:
1. First, create a plan using todo_write
2. Research systematically, saving important findings to files
3. Delegate specialized work to appropriate sub-agents
4. Synthesize findings into a comprehensive response
Examples:
[Detailed few-shot examples follow...]
"""El asistente integra la planificación, la investigación y la delegación con la documentación, utilizando ejemplos breves para descomponer tareas complejas.
La herramienta de planificación suele ser simplemente una «operación nula» que ayuda al agente a organizar sus ideas:
@tool
def todo_write(tasks: List[str]) -> str:
formatted_tasks = "\n".join([f"- {task}" for task in tasks])
return f"Todo list created:\n{formatted_tasks}"Esta sencilla herramienta proporciona una importante ingeniería de contexto, que obliga al agente a planificar en consecuencia y a mantener ese plan visible durante toda la ejecución.
Los agentes profundos pueden generar subagentes especializados para tareas específicas. Cada subagente está diseñado con su propio mensaje, descripción y conjunto de herramientas, lo que permite tanto la separación de funciones como una optimización profunda específica para cada tarea. A continuación se muestra un ejemplo de cómo se pueden definir los subagentes en tu flujo de trabajo:
subagents = [
{
"name": "research-agent",
"description": "Conducts deep research on specific topics",
"prompt": "You are a research specialist. Focus intensively on the given topic...",
"tools": ["internet_search", "read_file", "write_file"]
},
{
"name": "analysis-agent",
"description": "Analyzes data and draws insights",
"prompt": "You are a data analyst. Examine the provided information...",
"tools": ["read_file", "write_file"]
}
]Este enfoque proporciona cuarentena de contexto, lo que significa que cada subagente mantiene su propio contexto y no contamina la memoria del agente principal. Al aislar tareas especializadas, puedes habilitar:
Los Deep Agents mantienen y comparten el estado mediante un sistema de archivos virtual. En lugar de depender únicamente del historial de conversaciones, estas herramientas integradas permiten a los agentes organizar la información a lo largo de todo el flujo de trabajo:
tools = [
"ls", # List files
"read_file", # Read file contents
"write_file", # Write to file
"edit_file" # Edit existing file
]Este sistema de archivos virtual ofrece varias ventajas:
deepagentsTe guiaré a través de un ejemplo práctico de cómo crear un asistente para solicitudes de empleo que busca automáticamente ofertas de trabajo relevantes y genera cartas de presentación personalizadas para el usuario.
Nuestro asistente se encargará de:
Comencemos con una instalación y configuración básicas:
pip install deepagents
pip install tavily-python
pip install streamlit
pip install langchain-openaiUna vez instalado, configuradas nuestras variables de entorno:
export OPENAI_API_KEY=sk-projxxxxxxxxxxxxxxxxxxx
export TAVILY_API_KEY=tvly-devxxxxxxxxxxxxxxxxxxxPara esta demostración, necesitarás una clave API de OpenAI (para el modelo mini GPT-4o) y una clave API de Tavily (para la función de búsqueda web). Tavily proporciona al agente ofertas de empleo actualizadas directamente desde la web, mientras que el modelo de OpenAI se encarga de toda la comprensión del lenguaje, el razonamiento, la planificación y la generación de contenidos.
Nota: Los nuevos usuarios de Tavily reciben 1000 créditos API gratuitos. Para obtener tu clave, solo tienes que registrarte en https://app.tavily.com.
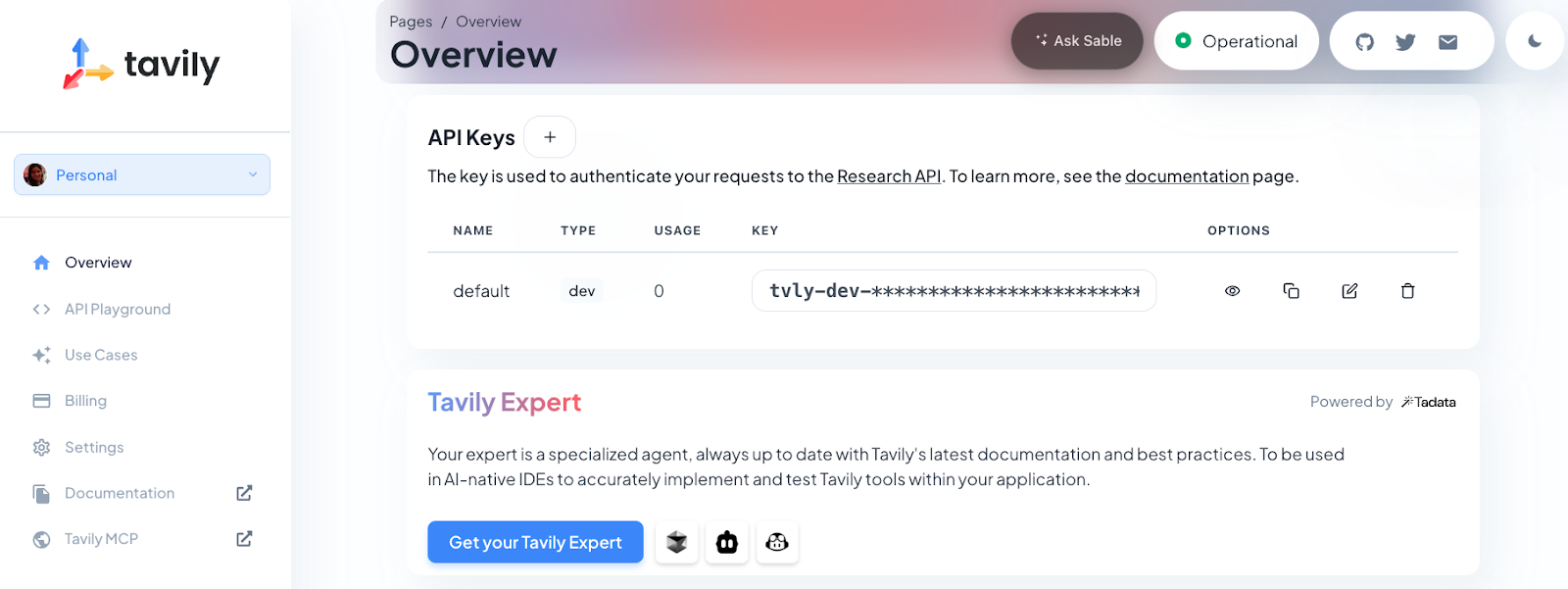
Por último, importaremos las bibliotecas necesarias y configuraremos la interfaz Streamlit:
import os
import io
import json
import re
from typing import Literal, Dict, Any, List
import streamlit as st
import pandas as pd
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from tavily import TavilyClient
from deepagents import create_deep_agentEste paso importa todas las dependencias necesarias para nuestra aplicación Deep Agent. Utilizamos streamlit para la interfaz web, pandas para el manejo de datos, langchain_openai para la integración LLM y deepagents para nuestro marco de agentes.
A continuación, inicializamos el estado de la sesión de Streamlit para conservar los datos entre las interacciones del usuario. Esto garantiza que la aplicación recuerde los archivos cargados, los resultados y los estados de error, incluso mientras los usuarios interactúan con la interfaz:
if "jobs_df" not in st.session_state:
st.session_state.jobs_df = None
if "cover_doc" not in st.session_state:
st.session_state.cover_doc = None
if "last_error" not in st.session_state:
st.session_state.last_error = ""
if "raw_final" not in st.session_state:
st.session_state.raw_final = ""Esta configuración es esencial para una experiencia de usuario fluida, ya que nos permite almacenar los resultados del trabajo, las cartas de presentación generadas y cualquier mensaje de error durante toda la sesión.
Utilizamos columnas Streamlit para organizar los campos de entrada dentro de nuestra interfaz de usuario para la carga del currículum, el puesto de trabajo, la ubicación y las habilidades opcionales:
st.set_page_config(page_title="Job Application Assistant", page_icon=" ", layout="wide")
st.title("💼 Job Application Assistant")
c0, c1, c2 = st.columns([2, 1, 1])
with c0:
uploaded = st.file_uploader("Upload your resume (PDF/DOCX/TXT)", type=["pdf", "docx", "txt"])
with c1:
target_title = st.text_input("Target title", "Senior Machine Learning Engineer")
with c2:
target_location = st.text_input("Target location(s)", "Bangalore OR Remote")
skills_hint = st.text_area(
"Add/override skills (optional)",
"",
placeholder="Python, PyTorch, LLMs, RAG, Azure, vLLM, FastAPI",
)La interfaz de usuario está organizada en columnas para mejorar la disposición. Los usuarios pueden subir su currículum en varios formatos, especificar el puesto de trabajo y la ubicación que desean, y destacar las habilidades específicas que quieren resaltar en sus solicitudes.
A continuación, implementamos un procesamiento de archivos robusto para gestionar diferentes formatos de currículums y extraer los textos de ellos.
import pypdf
import docx
def extract_text(file) -> str:
if not file:
return ""
name = file.name.lower()
if name.endswith(".txt"):
return file.read().decode("utf-8", errors="ignore")
if name.endswith(".pdf"):
pdf = pypdf.PdfReader(io.BytesIO(file.read()))
return "\n".join((p.extract_text() or "") for p in pdf.pages)
if name.endswith(".docx"):
d = docx.Document(io.BytesIO(file.read()))
return "\n".join(p.text for p in d.paragraphs)
return ""
def md_to_docx(md_text: str) -> bytes:
doc = docx.Document()
for raw in md_text.splitlines():
line = raw.rstrip()
if not line:
doc.add_paragraph("")
continue
if line.startswith("#"):
level = min(len(line) - len(line.lstrip("#")), 3)
doc.add_heading(line.lstrip("#").strip(), level=level)
elif line.startswith(("- ", "* ")):
doc.add_paragraph(line[2:].strip(), style="List Bullet")
else:
doc.add_paragraph(line)
bio = io.BytesIO()
doc.save(bio)
bio.seek(0)
return bio.read()Estas funciones auxiliares gestionan la complejidad de extraer texto de diferentes formatos de archivo (PDF, DOCX, TXT) y convertir el resultado en formato Markdown de nuevo a DOCX para su descarga. A continuación se explica cómo funciona cada función:
extract_text()» (Insertar archivo en documento) de detecta automáticamente el tipo de archivo cargado (TXT, PDF o DOCX) y extrae el contenido utilizando la biblioteca adecuada, por lo que no tenéis que preocuparos por el formato del archivo.md_to_docx() » (Crear documento de Word) toma texto con formato Markdown (como cartas de presentación generadas por el agente) y lo convierte en un documento de Word limpio y bien estructurado, listo para descargar.Esto garantiza que la aplicación pueda gestionar de forma flexible diversos tipos de currículos y ofrecer resultados profesionales independientemente del formato del archivo original.
A continuación, implementamos un análisis sintáctico robusto para extraer los datos del trabajo de la respuesta del agente.
def normalize_jobs(items: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
normed = []
for it in items:
if not isinstance(it, dict):
continue
# case-insensitive keys
lower_map = {str(k).strip().lower(): it[k] for k in it.keys()}
company = str(lower_map.get("company", "") or "").strip()
title = str(lower_map.get("title", "") or "").strip()
location = str(lower_map.get("location", "") or "").strip()
link = str(lower_map.get("link", "") or "").strip()
why_fit = str(lower_map.get("why_fit", lower_map.get("good match", "")) or "").strip()
if not link:
continue
normed.append({
"company": company or "—",
"title": title or "—",
"location": location or "—",
"link": link,
"Good Match": "Yes" if why_fit else "—",
})
return normed[:5]
def extract_jobs_from_text(text: str) -> List[Dict[str, Any]]:
if not text:
return []
pattern = r"<JOBS>\s*(?:```[\w-]*\s*)?(\[.*?\])\s*(?:```)?\s*</JOBS>"
m = re.search(pattern, text, flags=re.S | re.I)
if not m:
return []
raw = m.group(1).strip().strip("`").strip()
try:
obj = json.loads(raw)
return obj if isinstance(obj, list) else []
except Exception:
try:
salvaged = re.sub(r"(?<!\\)'", '"', raw)
obj = json.loads(salvaged)
return obj if isinstance(obj, list) else []
except Exception:
st.session_state.last_error = f"JSON parse failed: {raw[:1200]}"
return []Entendamos brevemente las funciones anteriores:
extract_jobs_from_text() utiliza una expresión regular para extraer un arreglo JSON de trabajos de la salida estructurada del agente (dentro de las etiquetas <JOBS>...</JOBS>). También se incluye un análisis de respaldo para gestionar errores menores del modelo, como devolver comillas simples en lugar de comillas dobles en JSON.normalize_jobs() estandariza y limpia cada diccionario de trabajos, como las claves que no distinguen entre mayúsculas y minúsculas, los campos obligatorios y el eliminación de espacios en blanco, y limita la salida a las 5 entradas principales.El núcleo de la capacidad de investigación está impulsado por Tavily. Así, definimos una herramienta de búsqueda web que el agente profundo utilizará para encontrar ofertas de empleo actualizadas:
TAVILY_KEY = os.environ.get("TAVILY_API_KEY", "")
@tool
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
) -> List[Dict[str, Any]]:
if not TAVILY_KEY:
raise RuntimeError("TAVILY_API_KEY is not set in the environment.")
client = TavilyClient(api_key=TAVILY_KEY)
return client.search(
query=query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)La función « internet_search() » está decorada con « @tool », lo que la hace accesible al agente y a los subagentes. A continuación, llama a la API de Tavily, que devuelve resultados de búsqueda relevantes y recientes, lo que lo hace ideal para consultas y búsquedas dinámicas de empleo.
Nota: Puedes añadir más herramientas de esta manera (como resumen de documentos, ejecución de código o enriquecimiento de datos) para ampliar aún más las capacidades de tu agente profundo.
Ahora, unimos todo configurando el agente principal y sus subagentes, cada uno con instrucciones específicas, como se indica a continuación:
INSTRUCTIONS = (
"You are a job application assistant. Do two things:\n"
"1) Use the web search tool to find exactly 5 CURRENT job postings (matching the user's target title, locations, and skills). "
"Return them ONLY as JSON in this exact wrapper:\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}, ... five total]\n"
"</JOBS>\n"
"Rules: The list must be valid JSON (no comments), real links to the job page or application page, no duplicates.\n"
"2) Produce a concise cover letter (≤150 words) for EACH job, with a subject line, appended to cover_letters.md under a heading per job.\n"
"Do not invent jobs. Prefer reputable sources (company career pages, LinkedIn, Lever, Greenhouse)."
)
JOB_SEARCH_PROMPT = (
"Search and select 5 real postings that match the user's title, locations, and skills. "
"Output ONLY this block format (no extra text before/after the wrapper):\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}]"
"\n</JOBS>"
)
COVER_LETTER_PROMPT = (
"For each job in the found list, write a subject line and a concise cover letter (≤150 words) that ties the user's skills/resume to the role. "
"Append to cover_letters.md under a heading per job. Keep writing tight and specific."
)
def build_agent():
api_key = os.environ.get("OPENAI_API_KEY")
if not api_key:
st.error("Please set OPENAI_API_KEY in your environment.")
st.stop()
llm = ChatOpenAI(model=os.environ.get("OPENAI_MODEL", "gpt-4o-mini"), temperature=0.2)
tools = [internet_search]
subagents = [
{"name": "job-search-agent", "description": "Finds relevant jobs", "prompt": JOB_SEARCH_PROMPT},
{"name": "cover-letter-writer-agent", "description": "Writes cover letters", "prompt": COVER_LETTER_PROMPT},
]
return create_deep_agent(tools, INSTRUCTIONS, subagents=subagents, model=llm)
def make_task_prompt(resume_text: str, skills_hint: str, title: str, location: str) -> str:
skills = skills_hint.strip()
skill_line = f" Prioritize these skills: {skills}." if skills else ""
return (
f"Target title: {title}\n"
f"Target location(s): {location}\n"
f"{skill_line}\n\n"
f"RESUME RAW TEXT:\n{resume_text[:8000]}"
)Este paso demuestra el poder de Deep Agents a través de subagentes especializados. Las instrucciones principales proporcionan orientación general, mientras que cada subagente tiene indicaciones específicas para tareas concretas:
INSTRUCTIONS, JOB_SEARCH_PROMPT y COVER_LETTER_PROMPT definen el mensaje principal del sistema y las instrucciones especializadas para cada subagente. Esto garantiza que el agente siempre produzca resultados bien estructurados y cartas de presentación personalizadas en el formato requerido.build_agent() ` comprueba la clave API de OpenAI, configura el modelo de lenguaje y crea el agente profundo con los subagentes de búsqueda de empleo y carta de presentación. Esta configuración modular permite que cada subagente se centre en su parte del flujo de trabajo.make_task_prompt() » genera un único mensaje que combina el currículum, las habilidades, el cargo y la ubicación del usuario. Esto proporciona al agente todo el contexto que necesita para iniciar el proceso de búsqueda y redacción.En conjunto, estas funciones añaden estructura y especialización al flujo de trabajo.
Este paso es la lógica central de la aplicación que gestiona la entrada del usuario y coordina el agente profundo:
resume_text = extract_text(uploaded) if uploaded else ""
run_clicked = st.button("Run", type="primary", disabled=not uploaded)
if run_clicked:
st.session_state.last_error = ""
st.session_state.raw_final = ""
try:
if not os.environ.get("OPENAI_API_KEY"):
st.error("OPENAI_API_KEY not set.")
st.stop()
if not TAVILY_KEY:
st.error("TAVILY_API_KEY not set.")
st.stop()
agent = build_agent()
task = make_task_prompt(resume_text, skills_hint, target_title, target_location)
state = {
"messages": [{"role": "user", "content": task}],
"files": {"cover_letters.md": ""},
}
with st.spinner("Finding jobs and drafting cover letters..."):
result = agent.invoke(state)
final_msgs = result.get("messages", [])
final_text = (final_msgs[-1].content if final_msgs else "") or ""
st.session_state.raw_final = final_text
files = result.get("files", {}) or {}
cover_md = (files.get("cover_letters.md") or "").strip()
st.session_state.cover_doc = md_to_docx(cover_md) if cover_md else None
raw_jobs = extract_jobs_from_text(final_text)
jobs_list = normalize_jobs(raw_jobs)
st.session_state.jobs_df = pd.DataFrame(jobs_list) if jobs_list else None
st.success("Done. Results generated and saved.")
except Exception as e:
st.session_state.last_error = str(e)
st.error(f"Error: {e}")El código anterior gestiona las acciones del usuario, inicia el agente profundo y muestra los resultados de la siguiente manera:
Por último, presentamos los resultados en un formato fácil de usar:
st.header("Jobs")
if st.session_state.jobs_df is None or st.session_state.jobs_df.empty:
st.write("No jobs to show yet.")
else:
df = st.session_state.jobs_df.copy()
def as_link(u: str) -> str:
u = u if isinstance(u, str) else ""
return f'<a href="{u}" target="_blank">Apply</a>' if u else "—"
if "link" in df.columns:
df["link"] = df["link"].apply(as_link)
cols = [c for c in ["company", "title", "location", "link", "Good Match"] if c in df.columns]
df = df[cols]
st.write(df.to_html(escape=False, index=False), unsafe_allow_html=True)
st.header("Download")
if st.session_state.cover_doc:
st.download_button(
"Download cover_letters.docx",
data=st.session_state.cover_doc,
file_name="cover_letters.docx",
mime="application/vnd.openxmlformats-officedocument.wordprocessingml.document",
key="dl_cover_letters",
)
else:
st.caption("Cover letters not produced yet.")Una vez que el agente ha terminado, presentamos los resultados en un formato pulido, por ejemplo:
Esto convierte un flujo de trabajo de IA de varios pasos en una experiencia sencilla con un solo clic.
Para iniciar la aplicación, simplemente ejecuta:
streamlit app.py¡Aprende IA con estos cursos!
Curso
Curso
Curso
blog
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Ryan Ong

