
Kurs
KI in der Produktion mit FastAPI bereitstellen
4 Std.
4.5K
Die gängigste Agent-Architektur besteht heute darin, dass ein LLM Tools in einer Schleife aufruft. Das ist zwar einfach und effektiv, aber letztendlich begrenzt. Dieser Ansatz funktioniert zwar bei einfachen Aufgaben, stößt aber an seine Grenzen, wenn es um komplexe, mehrstufige Herausforderungen geht, die Planung, Kontextmanagement und eine nachhaltige Umsetzung über längere Zeiträume erfordern.
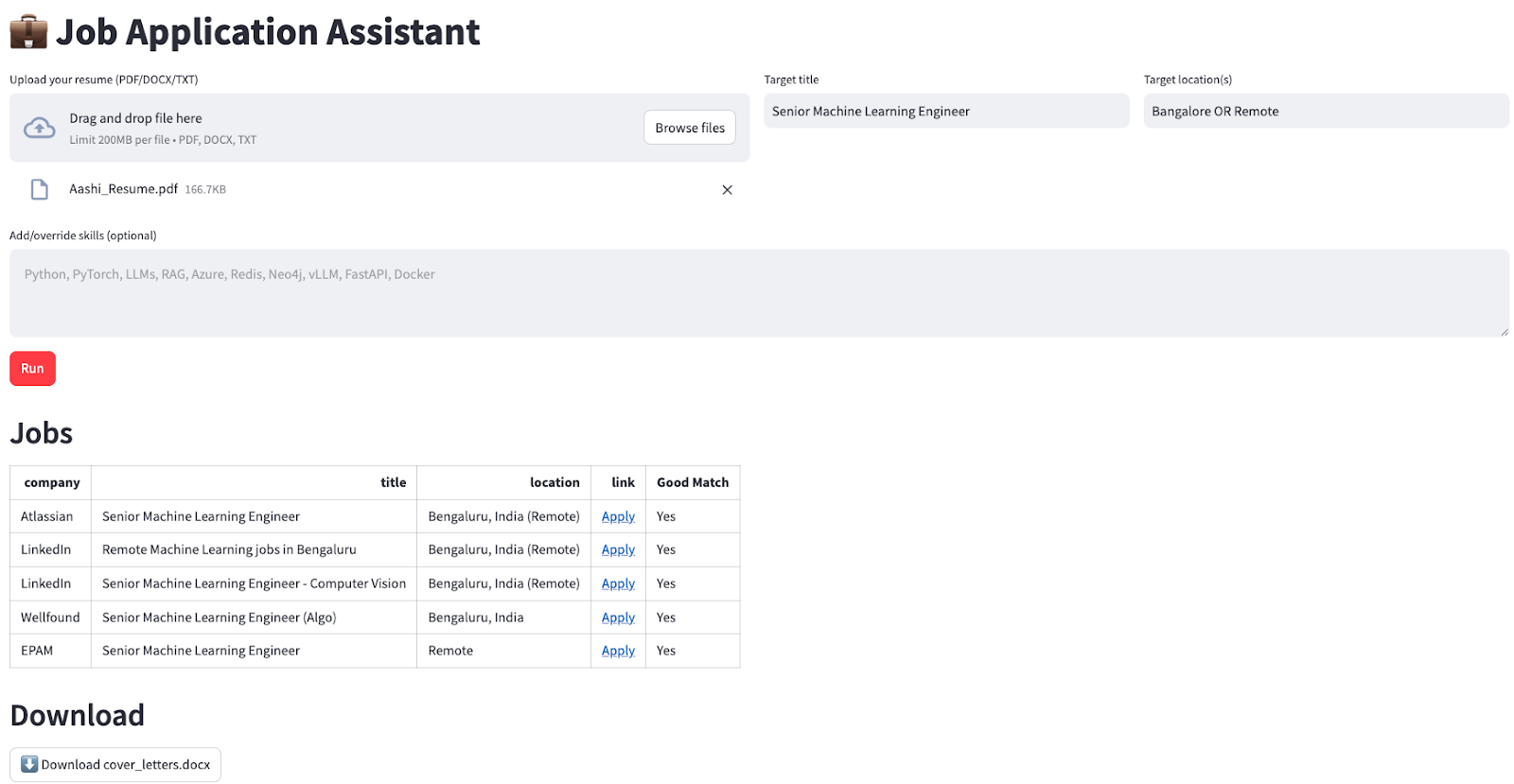
Die Deep-Agents- -Architektur von LangChain bringt detaillierte Systemaufforderungen, Planungstools, Subagenten und Dateisysteme zusammen, um KI-Agenten zu schaffen, die komplexe Forschungs-, Codierungs- und Analyseaufgaben bewältigen können. Anwendungen wie Claude Code, Deep Research und Manus haben gezeigt, dass dieser Ansatz funktioniert, und jetzt macht das Python-Paket „ deepagents “ diese Architektur für alle zugänglich.
In diesem Tutorial zeige ich dir Schritt für Schritt, wie du:
Deep Agents sind eine fortschrittliche Agentenarchitektur, die für komplexe, mehrschrittige Aufgaben entwickelt wurde, die langes Nachdenken, den Einsatz von Tools und ein gutes Gedächtnis erfordern. Im Gegensatz zu herkömmlichen Agenten, die in kurzen Schleifen arbeiten oder einfache Tool-Aufrufe ausführen, planen Deep Agents ihre Aktionen, verwalten sich ändernde Kontexte, delegieren Teilaufgaben an spezialisierte Subagenten und behalten den Status über lange Interaktionen hinweg bei. Diese Architektur wird bereits in echten Anwendungen eingesetzt, wie zum Beispiel Claude Code, Deep Researchund Manus.
Quelle: LangChain
Hier sind die wichtigsten Merkmale von Deep Agents:
Deep Agents machen mit vier Kernkomponenten Schluss mit den Einschränkungen herkömmlicher Agenten:
Im Gegensatz zu einfachen Anweisungen nutzen Deep Agents umfassende Systemaufforderungen wie folgt:
DEEP_AGENT_SYSTEM_PROMPT = """
You are an expert research assistant capable of conducting thorough,
multi-step investigations. Your capabilities include:
PLANNING: Break complex tasks into subtasks using the todo_write tool
RESEARCH: Use internet_search extensively to gather comprehensive information
DELEGATION: Spawn sub-agents for specialized tasks using the call_subagent tool
DOCUMENTATION: Maintain detailed notes using the file system tools
When approaching a complex task:
1. First, create a plan using todo_write
2. Research systematically, saving important findings to files
3. Delegate specialized work to appropriate sub-agents
4. Synthesize findings into a comprehensive response
Examples:
[Detailed few-shot examples follow...]
"""Die Eingabeaufforderung bringt Planung, Recherche und Delegation mit Dokumentation zusammen und nutzt wenige Beispiele, um komplizierte Aufgaben zu zerlegen.
Das Planungstool ist oft nur ein „No-Op”, das dem Agenten hilft, seine Gedanken zu ordnen:
@tool
def todo_write(tasks: List[str]) -> str:
formatted_tasks = "\n".join([f"- {task}" for task in tasks])
return f"Todo list created:\n{formatted_tasks}"Dieses einfache Tool bietet wichtige Kontextinformationen, die den Agenten dazu zwingen, entsprechend zu planen und diesen Plan während der gesamten Ausführung sichtbar zu halten.
Deep Agents können spezielle Sub-Agenten für bestimmte Aufgaben erstellen. Jeder Subagent hat seine eigene Eingabeaufforderung, Beschreibung und sein eigenes Toolset, was sowohl eine Trennung der Aufgaben als auch eine tiefgehende Optimierung für bestimmte Aufgaben ermöglicht. Hier ist ein Beispiel, wie du Unteragenten in deinem Workflow definieren kannst:
subagents = [
{
"name": "research-agent",
"description": "Conducts deep research on specific topics",
"prompt": "You are a research specialist. Focus intensively on the given topic...",
"tools": ["internet_search", "read_file", "write_file"]
},
{
"name": "analysis-agent",
"description": "Analyzes data and draws insights",
"prompt": "You are a data analyst. Examine the provided information...",
"tools": ["read_file", "write_file"]
}
]Dieser Ansatz sorgt für eine Kontext-Quarantäne, was bedeutet, dass jeder Subagent seinen eigenen Kontext behält und den Speicher des Hauptagenten nicht belastet. Durch das Isolieren spezieller Aufgaben kannst du Folgendes erreichen:
Deep Agents speichern und teilen den Status über ein virtuelles Dateisystem. Anstatt sich nur auf den Gesprächsverlauf zu verlassen, können die Agenten mit diesen Tools Infos während des ganzen Workflows organisieren:
tools = [
"ls", # List files
"read_file", # Read file contents
"write_file", # Write to file
"edit_file" # Edit existing file
]Dieses virtuelle Dateisystem hat ein paar Vorteile:
deepagentsIch zeig dir mal, wie man einen Jobbewerbungsassistenten baut, der automatisch passende Stellenangebote findet und maßgeschneiderte Anschreiben für den Nutzer erstellt.
Unser Assistent wird:
Fangen wir mit der Installation und den Grundeinstellungen an:
pip install deepagents
pip install tavily-python
pip install streamlit
pip install langchain-openaiNach der Installation richten wir unsere Umgebungsvariablen ein:
export OPENAI_API_KEY=sk-projxxxxxxxxxxxxxxxxxxx
export TAVILY_API_KEY=tvly-devxxxxxxxxxxxxxxxxxxxFür diese Demo brauchst du sowohl einen OpenAI-API-Schlüssel (für das GPT-4o-Mini-Modell) als auch einen Tavily-API-Schlüssel (für die Websuchfunktion). Tavily versorgt den Agenten mit aktuellen Stellenangeboten direkt aus dem Internet, während das Modell von OpenAI das Verstehen der Sprache, das Schlussfolgern, die Planung und die Erstellung von Inhalten übernimmt.
Hinweis: Neue Tavily-Nutzer kriegen 1.000 API-Credits gratis. Um deinen Schlüssel zu bekommen, musst du dich einfach unter https://app.tavily.com anmelden.
Zum Schluss importieren wir die benötigten Bibliotheken und richten die Streamlit-Schnittstelle ein:
import os
import io
import json
import re
from typing import Literal, Dict, Any, List
import streamlit as st
import pandas as pd
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from tavily import TavilyClient
from deepagents import create_deep_agentMit diesem Schritt werden alle Abhängigkeiten importiert, die für unsere Deep-Agent-Anwendung gebraucht werden. Wir nutzen streamlit für die Webschnittstelle, pandas für die Datenverarbeitung, langchain_openai für die LLM-Integration und deepagents für unser Agent-Framework.
Als Nächstes starten wir den Streamlit-Sitzungsstatus, damit die Daten zwischen den Interaktionen der Benutzer gespeichert werden. Dadurch wird sichergestellt, dass die App hochgeladene Dateien, Ergebnisse und Fehlerzustände speichert, auch wenn Benutzer mit der Benutzeroberfläche interagieren:
if "jobs_df" not in st.session_state:
st.session_state.jobs_df = None
if "cover_doc" not in st.session_state:
st.session_state.cover_doc = None
if "last_error" not in st.session_state:
st.session_state.last_error = ""
if "raw_final" not in st.session_state:
st.session_state.raw_final = ""Diese Einstellung ist wichtig für eine reibungslose Benutzererfahrung, da wir so die Job-Ergebnisse, die erstellten Anschreiben und alle Fehlermeldungen während der Sitzung speichern können.
Wir nutzen Streamlit-Spalten, um die Eingabefelder in unserer Benutzeroberfläche für den Lebenslauf-Upload, die Berufsbezeichnung, den Standort und optionale Fähigkeiten zu organisieren:
st.set_page_config(page_title="Job Application Assistant", page_icon=" ", layout="wide")
st.title("💼 Job Application Assistant")
c0, c1, c2 = st.columns([2, 1, 1])
with c0:
uploaded = st.file_uploader("Upload your resume (PDF/DOCX/TXT)", type=["pdf", "docx", "txt"])
with c1:
target_title = st.text_input("Target title", "Senior Machine Learning Engineer")
with c2:
target_location = st.text_input("Target location(s)", "Bangalore OR Remote")
skills_hint = st.text_area(
"Add/override skills (optional)",
"",
placeholder="Python, PyTorch, LLMs, RAG, Azure, vLLM, FastAPI",
)Die Benutzeroberfläche ist für eine bessere Übersicht in Spalten angeordnet. Nutzer können ihren Lebenslauf in verschiedenen Formaten hochladen, ihre Wunschposition und ihren Wunscharbeitsort angeben und bestimmte Fähigkeiten hervorheben, die sie in ihrer Bewerbung besonders betonen möchten.
Als Nächstes machen wir eine robuste Dateiverarbeitung, um verschiedene Lebenslaufformate zu verarbeiten und Texte daraus zu extrahieren.
import pypdf
import docx
def extract_text(file) -> str:
if not file:
return ""
name = file.name.lower()
if name.endswith(".txt"):
return file.read().decode("utf-8", errors="ignore")
if name.endswith(".pdf"):
pdf = pypdf.PdfReader(io.BytesIO(file.read()))
return "\n".join((p.extract_text() or "") for p in pdf.pages)
if name.endswith(".docx"):
d = docx.Document(io.BytesIO(file.read()))
return "\n".join(p.text for p in d.paragraphs)
return ""
def md_to_docx(md_text: str) -> bytes:
doc = docx.Document()
for raw in md_text.splitlines():
line = raw.rstrip()
if not line:
doc.add_paragraph("")
continue
if line.startswith("#"):
level = min(len(line) - len(line.lstrip("#")), 3)
doc.add_heading(line.lstrip("#").strip(), level=level)
elif line.startswith(("- ", "* ")):
doc.add_paragraph(line[2:].strip(), style="List Bullet")
else:
doc.add_paragraph(line)
bio = io.BytesIO()
doc.save(bio)
bio.seek(0)
return bio.read()Diese Hilfsfunktionen kümmern sich um die knifflige Aufgabe, Text aus verschiedenen Dateiformaten (PDF, DOCX, TXT) rauszuziehen und die Markdown-Ausgabe wieder ins DOCX-Format zu verwandeln, damit du sie runterladen kannst. So funktioniert jede Funktion:
extract_text()“ (Dokument-PDF-Konvertierung) von erkennt automatisch den Typ der hochgeladenen Datei (TXT, PDF oder DOCX) und extrahiert den Inhalt mit der passenden Bibliothek, sodass du dir keine Gedanken über das Dateiformat machen musst.md_to_docx() “ nimmt Text im Markdown-Format (z. B. vom Agenten erstellte Anschreiben) und macht daraus ein sauberes, gut strukturiertes Word-Dokument, das du gleich runterladen kannst.Dadurch wird sichergestellt, dass die Anwendung verschiedene Lebensläufe flexibel verarbeiten und unabhängig vom ursprünglichen Dateiformat professionelle Ergebnisse liefern kann.
Als Nächstes machen wir eine solide Analyse, um die Jobdaten aus der Antwort des Agenten rauszuholen.
def normalize_jobs(items: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
normed = []
for it in items:
if not isinstance(it, dict):
continue
# case-insensitive keys
lower_map = {str(k).strip().lower(): it[k] for k in it.keys()}
company = str(lower_map.get("company", "") or "").strip()
title = str(lower_map.get("title", "") or "").strip()
location = str(lower_map.get("location", "") or "").strip()
link = str(lower_map.get("link", "") or "").strip()
why_fit = str(lower_map.get("why_fit", lower_map.get("good match", "")) or "").strip()
if not link:
continue
normed.append({
"company": company or "—",
"title": title or "—",
"location": location or "—",
"link": link,
"Good Match": "Yes" if why_fit else "—",
})
return normed[:5]
def extract_jobs_from_text(text: str) -> List[Dict[str, Any]]:
if not text:
return []
pattern = r"<JOBS>\s*(?:```[\w-]*\s*)?(\[.*?\])\s*(?:```)?\s*</JOBS>"
m = re.search(pattern, text, flags=re.S | re.I)
if not m:
return []
raw = m.group(1).strip().strip("`").strip()
try:
obj = json.loads(raw)
return obj if isinstance(obj, list) else []
except Exception:
try:
salvaged = re.sub(r"(?<!\\)'", '"', raw)
obj = json.loads(salvaged)
return obj if isinstance(obj, list) else []
except Exception:
st.session_state.last_error = f"JSON parse failed: {raw[:1200]}"
return []Schauen wir uns die obigen Funktionen kurz an:
extract_jobs_from_text() “ nutzt einen regulären Ausdruck, um ein JSON-Array mit Jobs aus der strukturierten Ausgabe des Agenten (innerhalb der Tags „<JOBS>...</JOBS>“) zu extrahieren. Es gibt auch eine Fallback-Parsing-Funktion, die kleinere Modellfehler abfängt, wie zum Beispiel, wenn in JSON statt doppelter Anführungszeichen einfache Anführungszeichen verwendet werden.normalize_jobs()“ (Standardisierung und Bereinigung des Job-Wörterbuchs) das Job-Wörterbuch sauber, indem sie Sachen wie Groß-/Kleinschreibung in Schlüsseln, Pflichtfelder und Leerzeichen bereinigt und die Ausgabe auf die ersten 5 Einträge beschränkt.Die Forschung wird hauptsächlich von Tavily gemacht. Also definieren wir ein Web-Suchtool, das der Deep Agent nutzen wird, um aktuelle Stellenanzeigen zu finden:
TAVILY_KEY = os.environ.get("TAVILY_API_KEY", "")
@tool
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
) -> List[Dict[str, Any]]:
if not TAVILY_KEY:
raise RuntimeError("TAVILY_API_KEY is not set in the environment.")
client = TavilyClient(api_key=TAVILY_KEY)
return client.search(
query=query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)Die Funktion „ internet_search() ” ist mit „ @tool ” versehen, sodass sie für den Agenten und die Unteragenten zugänglich ist. Dann ruft es die Tavily-API auf, die relevante, aktuelle Suchergebnisse liefert, was es super für dynamische Jobanfragen und Recherchen macht.
Hinweis: Auf diese Weise kannst du weitere Tools hinzufügen (z. B. Dokumentenzusammenfassung, Codeausführung oder Datenanreicherung), um die Fähigkeiten deines Deep Agents noch weiter auszubauen.
Jetzt bringen wir alles zusammen, indem wir den Hauptagenten und seine Unteragenten mit den folgenden gezielten Anweisungen konfigurieren:
INSTRUCTIONS = (
"You are a job application assistant. Do two things:\n"
"1) Use the web search tool to find exactly 5 CURRENT job postings (matching the user's target title, locations, and skills). "
"Return them ONLY as JSON in this exact wrapper:\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}, ... five total]\n"
"</JOBS>\n"
"Rules: The list must be valid JSON (no comments), real links to the job page or application page, no duplicates.\n"
"2) Produce a concise cover letter (≤150 words) for EACH job, with a subject line, appended to cover_letters.md under a heading per job.\n"
"Do not invent jobs. Prefer reputable sources (company career pages, LinkedIn, Lever, Greenhouse)."
)
JOB_SEARCH_PROMPT = (
"Search and select 5 real postings that match the user's title, locations, and skills. "
"Output ONLY this block format (no extra text before/after the wrapper):\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}]"
"\n</JOBS>"
)
COVER_LETTER_PROMPT = (
"For each job in the found list, write a subject line and a concise cover letter (≤150 words) that ties the user's skills/resume to the role. "
"Append to cover_letters.md under a heading per job. Keep writing tight and specific."
)
def build_agent():
api_key = os.environ.get("OPENAI_API_KEY")
if not api_key:
st.error("Please set OPENAI_API_KEY in your environment.")
st.stop()
llm = ChatOpenAI(model=os.environ.get("OPENAI_MODEL", "gpt-4o-mini"), temperature=0.2)
tools = [internet_search]
subagents = [
{"name": "job-search-agent", "description": "Finds relevant jobs", "prompt": JOB_SEARCH_PROMPT},
{"name": "cover-letter-writer-agent", "description": "Writes cover letters", "prompt": COVER_LETTER_PROMPT},
]
return create_deep_agent(tools, INSTRUCTIONS, subagents=subagents, model=llm)
def make_task_prompt(resume_text: str, skills_hint: str, title: str, location: str) -> str:
skills = skills_hint.strip()
skill_line = f" Prioritize these skills: {skills}." if skills else ""
return (
f"Target title: {title}\n"
f"Target location(s): {location}\n"
f"{skill_line}\n\n"
f"RESUME RAW TEXT:\n{resume_text[:8000]}"
)Dieser Schritt zeigt, wie stark Deep Agents mit speziellen Subagenten sind. Die Hauptanweisungen geben allgemeine Hinweise, während jeder Unteragent gezielte Anweisungen für bestimmte Aufgaben hat:
INSTRUCTIONSJOB_SEARCH_PROMPT und COVER_LETTER_PROMPT beschreiben die Hauptsystemaufforderung und spezielle Anweisungen für jeden Unteragenten. So stellen wir sicher, dass der Agent immer gut strukturierte Job-Ergebnisse und passende Anschreiben im gewünschten Format liefert.build_agent() ” checkt den OpenAI-API-Schlüssel, richtet das Sprachmodell ein und erstellt den Deep Agent mit den Unteragenten für die Jobsuche und das Anschreiben. Dank dieser modularen Struktur kann sich jeder Subagent voll auf seinen Teil des Arbeitsablaufs konzentrieren.make_task_prompt() “ eine einzige Eingabeaufforderung, die den Lebenslauf, die Fähigkeiten, die Berufsbezeichnung und den Standort des Benutzers zusammenfasst. Damit hat der Makler alle Infos, die er braucht, um mit der Suche und dem Entwurf loszulegen.Zusammen sorgen diese Funktionen für mehr Struktur und Spezialisierung im Arbeitsablauf.
Dieser Schritt ist die Kernanwendungslogik, die Benutzereingaben verarbeitet und den Deep Agent koordiniert:
resume_text = extract_text(uploaded) if uploaded else ""
run_clicked = st.button("Run", type="primary", disabled=not uploaded)
if run_clicked:
st.session_state.last_error = ""
st.session_state.raw_final = ""
try:
if not os.environ.get("OPENAI_API_KEY"):
st.error("OPENAI_API_KEY not set.")
st.stop()
if not TAVILY_KEY:
st.error("TAVILY_API_KEY not set.")
st.stop()
agent = build_agent()
task = make_task_prompt(resume_text, skills_hint, target_title, target_location)
state = {
"messages": [{"role": "user", "content": task}],
"files": {"cover_letters.md": ""},
}
with st.spinner("Finding jobs and drafting cover letters..."):
result = agent.invoke(state)
final_msgs = result.get("messages", [])
final_text = (final_msgs[-1].content if final_msgs else "") or ""
st.session_state.raw_final = final_text
files = result.get("files", {}) or {}
cover_md = (files.get("cover_letters.md") or "").strip()
st.session_state.cover_doc = md_to_docx(cover_md) if cover_md else None
raw_jobs = extract_jobs_from_text(final_text)
jobs_list = normalize_jobs(raw_jobs)
st.session_state.jobs_df = pd.DataFrame(jobs_list) if jobs_list else None
st.success("Done. Results generated and saved.")
except Exception as e:
st.session_state.last_error = str(e)
st.error(f"Error: {e}")Der obige Code kümmert sich um die Aktionen der Nutzer, startet den Deep Agent und zeigt die Ergebnisse so an:
Zum Schluss zeigen wir die Ergebnisse in einem benutzerfreundlichen Format:
st.header("Jobs")
if st.session_state.jobs_df is None or st.session_state.jobs_df.empty:
st.write("No jobs to show yet.")
else:
df = st.session_state.jobs_df.copy()
def as_link(u: str) -> str:
u = u if isinstance(u, str) else ""
return f'<a href="{u}" target="_blank">Apply</a>' if u else "—"
if "link" in df.columns:
df["link"] = df["link"].apply(as_link)
cols = [c for c in ["company", "title", "location", "link", "Good Match"] if c in df.columns]
df = df[cols]
st.write(df.to_html(escape=False, index=False), unsafe_allow_html=True)
st.header("Download")
if st.session_state.cover_doc:
st.download_button(
"Download cover_letters.docx",
data=st.session_state.cover_doc,
file_name="cover_letters.docx",
mime="application/vnd.openxmlformats-officedocument.wordprocessingml.document",
key="dl_cover_letters",
)
else:
st.caption("Cover letters not produced yet.")Sobald der Agent fertig ist, zeigen wir die Ergebnisse in einem schicken Layout, z. B.:
Damit wird ein mehrstufiger KI-Workflow zu einem einfachen Vorgang mit nur einem Klick.
Um die App zu starten, mach einfach Folgendes:
streamlit app.pyLerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Matt Crabtree
14 Min.
Tutorial
Mark Pedigo
Tutorial
Derrick Mwiti