Curso
Colocando IA em Produção com FastAPI
4 h
4.5K
A arquitetura de agente mais comum hoje em dia envolve um LLM chamando ferramentas em um loop, o que é simples, eficaz, mas, no fim das contas, limitado. Embora essa abordagem funcione para tarefas simples, ela não é suficiente quando se trata de desafios complexos, com várias etapas, que exigem planejamento, gerenciamento de contexto e execução contínua por um longo período.
A arquitetura Deep Agents da LangChain junta prompts detalhados do sistema, ferramentas de planejamento, subagentes e sistemas de arquivos para criar agentes de IA que dão conta de tarefas complexas de pesquisa, codificação e análise. Aplicativos como Claude Code, Deep Research e Manus já mostraram que essa abordagem funciona, e agora o pacote Python deepagents deixa essa arquitetura acessível pra todo mundo.
Neste tutorial, vou explicar passo a passo como:
Agentes profundos são uma arquitetura de agentes avançada, feita pra lidar com tarefas complexas e com várias etapas que precisam de raciocínio contínuo, uso de ferramentas e memória. Diferente dos agentes tradicionais que funcionam em ciclos curtos ou fazem chamadas simples de ferramentas, os Deep Agents planejam suas ações, gerenciam o contexto em evolução, delegam subtarefas a subagentes especializados e mantêm o estado ao longo de interações longas. Essa arquitetura já tá em uso em aplicativos reais, tipo o Claude Code, Deep Researche Manus.
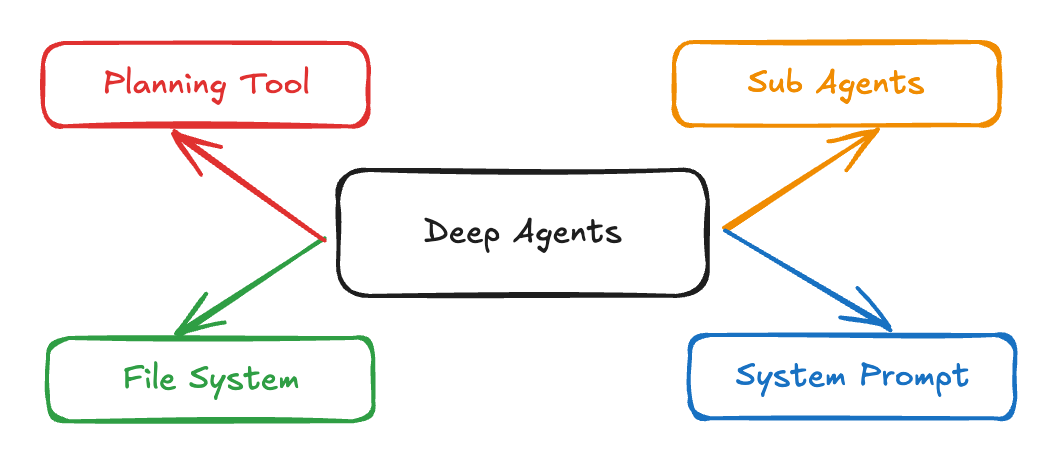
Fonte: LangChain
Essas são as principais características dos Deep Agents:
Os Deep Agents superam as limitações dos agentes tradicionais por meio de quatro componentes principais:
Diferente das instruções simples, os Deep Agents usam mensagens do sistema bem completas, tipo assim:
DEEP_AGENT_SYSTEM_PROMPT = """
You are an expert research assistant capable of conducting thorough,
multi-step investigations. Your capabilities include:
PLANNING: Break complex tasks into subtasks using the todo_write tool
RESEARCH: Use internet_search extensively to gather comprehensive information
DELEGATION: Spawn sub-agents for specialized tasks using the call_subagent tool
DOCUMENTATION: Maintain detailed notes using the file system tools
When approaching a complex task:
1. First, create a plan using todo_write
2. Research systematically, saving important findings to files
3. Delegate specialized work to appropriate sub-agents
4. Synthesize findings into a comprehensive response
Examples:
[Detailed few-shot examples follow...]
"""O prompt junta planejamento, pesquisa e delegação com documentação, usando poucos exemplos para dividir tarefas complexas.
A ferramenta de planejamento geralmente é só uma “ação nula” que ajuda o agente a organizar suas ideias:
@tool
def todo_write(tasks: List[str]) -> str:
formatted_tasks = "\n".join([f"- {task}" for task in tasks])
return f"Todo list created:\n{formatted_tasks}"Essa ferramenta simples oferece uma engenharia de contexto importante, que faz com que o agente planeje de acordo e mantenha esse plano visível durante toda a execução.
Os Deep Agents podem criar subagentes especializados para tarefas específicas. Cada subagente é projetado com seu próprio prompt, descrição e conjunto de ferramentas, o que permite tanto a separação de interesses quanto uma otimização profunda específica para cada tarefa. Aqui vai um exemplo de como você pode definir subagentes no seu fluxo de trabalho:
subagents = [
{
"name": "research-agent",
"description": "Conducts deep research on specific topics",
"prompt": "You are a research specialist. Focus intensively on the given topic...",
"tools": ["internet_search", "read_file", "write_file"]
},
{
"name": "analysis-agent",
"description": "Analyzes data and draws insights",
"prompt": "You are a data analyst. Examine the provided information...",
"tools": ["read_file", "write_file"]
}
]Essa abordagem oferece quarentena de contexto, o que significa que cada subagente mantém seu próprio contexto e não polui a memória do agente principal. Ao separar tarefas específicas, você pode:
Os Deep Agents mantêm e compartilham o estado usando um sistema de arquivos virtual. Em vez de depender só do histórico de conversas, essas ferramentas integradas permitem que os agentes organizem as informações ao longo de um fluxo de trabalho:
tools = [
"ls", # List files
"read_file", # Read file contents
"write_file", # Write to file
"edit_file" # Edit existing file
]Esse sistema de arquivos virtual tem várias vantagens:
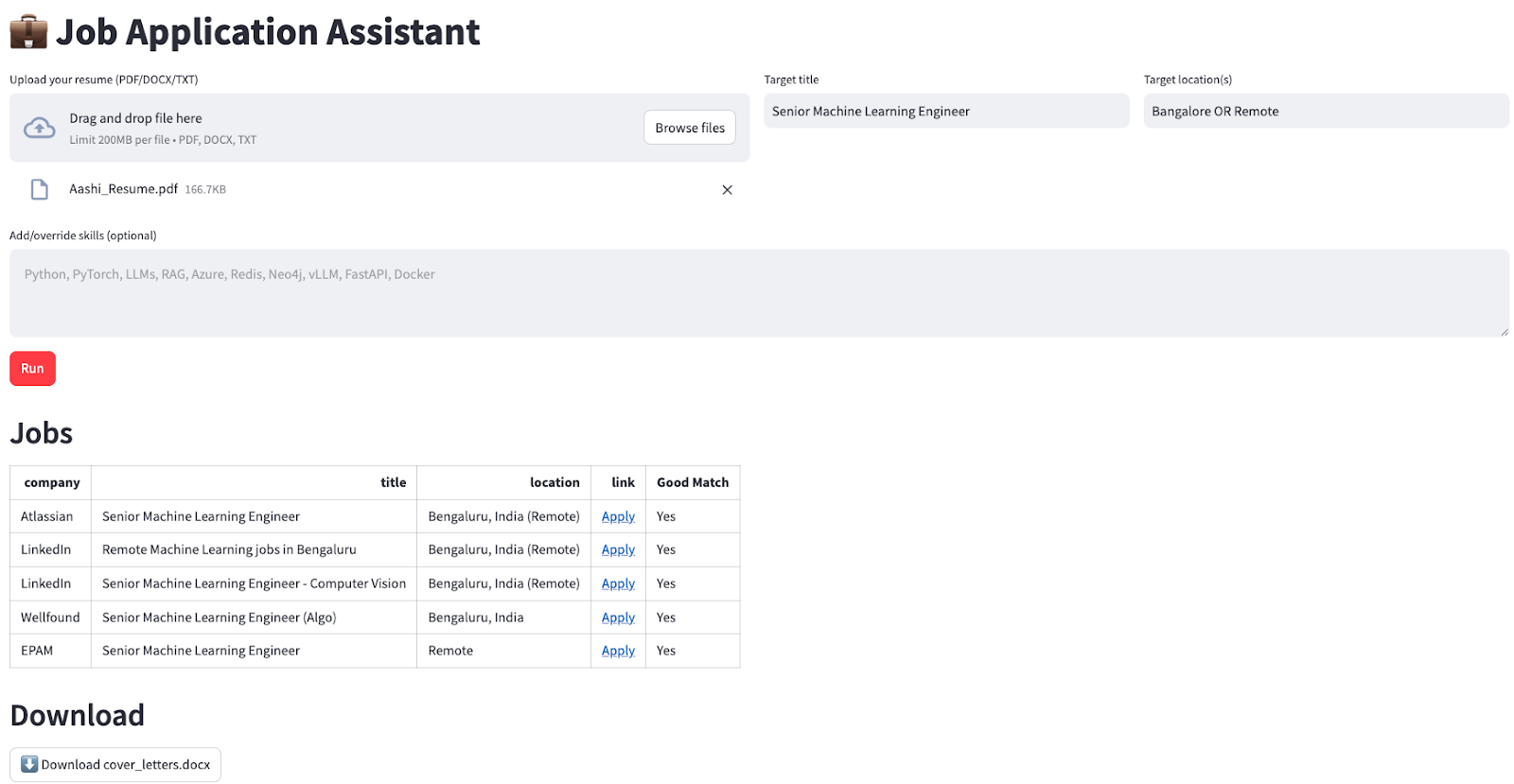
deepagentsVou te mostrar um exemplo prático de como criar um assistente de candidatura a empregos que encontra automaticamente vagas relevantes e gera cartas de apresentação personalizadas para o usuário.
Nosso assistente vai:
Vamos começar com uma instalação e configuração básicas:
pip install deepagents
pip install tavily-python
pip install streamlit
pip install langchain-openaiDepois de instalar, a gente configura as variáveis de ambiente:
export OPENAI_API_KEY=sk-projxxxxxxxxxxxxxxxxxxx
export TAVILY_API_KEY=tvly-devxxxxxxxxxxxxxxxxxxxPra essa demonstração, você vai precisar de uma chave API OpenAI (pra modelo mini GPT-4o) e uma chave API Tavily (pra funcionalidade de pesquisa na web). A Tavily dá ao agente anúncios de emprego atualizados direto da web, enquanto o modelo da OpenAI cuida de toda a compreensão da linguagem, raciocínio, planejamento e geração de conteúdo.
Observação: Os novos usuários do Tavily ganham 1.000 créditos API de graça. Para pegar sua chave, é só se cadastrar em https://app.tavily.com.
Por fim, vamos importar as bibliotecas necessárias e configurar a interface Streamlit:
import os
import io
import json
import re
from typing import Literal, Dict, Any, List
import streamlit as st
import pandas as pd
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from tavily import TavilyClient
from deepagents import create_deep_agentEssa etapa importa todas as dependências necessárias para a nossa aplicação de agente profundo. Usamos streamlit para a interface web, pandas para o tratamento de dados, langchain_openai para a integração LLM e deepagents para a nossa estrutura de agentes.
Depois, a gente inicializa o estado da sessão do Streamlit pra manter os dados entre as interações do usuário. Isso faz com que o aplicativo lembre os arquivos enviados, os resultados e os erros, mesmo quando os usuários estão usando a interface:
if "jobs_df" not in st.session_state:
st.session_state.jobs_df = None
if "cover_doc" not in st.session_state:
st.session_state.cover_doc = None
if "last_error" not in st.session_state:
st.session_state.last_error = ""
if "raw_final" not in st.session_state:
st.session_state.raw_final = ""Essa configuração é essencial para uma experiência tranquila do usuário, permitindo que a gente guarde os resultados do trabalho, as cartas de apresentação geradas e qualquer mensagem de erro durante a sessão.
Usamos colunas Streamlit pra organizar os campos de entrada na nossa interface de usuário pra upload do currículo, cargo, localização e habilidades opcionais:
st.set_page_config(page_title="Job Application Assistant", page_icon=" ", layout="wide")
st.title("💼 Job Application Assistant")
c0, c1, c2 = st.columns([2, 1, 1])
with c0:
uploaded = st.file_uploader("Upload your resume (PDF/DOCX/TXT)", type=["pdf", "docx", "txt"])
with c1:
target_title = st.text_input("Target title", "Senior Machine Learning Engineer")
with c2:
target_location = st.text_input("Target location(s)", "Bangalore OR Remote")
skills_hint = st.text_area(
"Add/override skills (optional)",
"",
placeholder="Python, PyTorch, LLMs, RAG, Azure, vLLM, FastAPI",
)A interface do usuário está organizada em colunas para facilitar a visualização. Os usuários podem enviar seus currículos em vários formatos, dizer qual cargo e localização estão procurando e destacar habilidades específicas que querem mostrar nas suas candidaturas.
Depois, a gente implementa um processamento de arquivos bem robusto pra lidar com diferentes formatos de currículos e extrair textos deles.
import pypdf
import docx
def extract_text(file) -> str:
if not file:
return ""
name = file.name.lower()
if name.endswith(".txt"):
return file.read().decode("utf-8", errors="ignore")
if name.endswith(".pdf"):
pdf = pypdf.PdfReader(io.BytesIO(file.read()))
return "\n".join((p.extract_text() or "") for p in pdf.pages)
if name.endswith(".docx"):
d = docx.Document(io.BytesIO(file.read()))
return "\n".join(p.text for p in d.paragraphs)
return ""
def md_to_docx(md_text: str) -> bytes:
doc = docx.Document()
for raw in md_text.splitlines():
line = raw.rstrip()
if not line:
doc.add_paragraph("")
continue
if line.startswith("#"):
level = min(len(line) - len(line.lstrip("#")), 3)
doc.add_heading(line.lstrip("#").strip(), level=level)
elif line.startswith(("- ", "* ")):
doc.add_paragraph(line[2:].strip(), style="List Bullet")
else:
doc.add_paragraph(line)
bio = io.BytesIO()
doc.save(bio)
bio.seek(0)
return bio.read()Essas funções auxiliares lidam com a complexidade de extrair texto de diferentes formatos de arquivo (PDF, DOCX, TXT) e converter a saída do markdown de volta para o formato DOCX para download. Veja como cada função funciona:
extract_text()” (Converter arquivo em PDF) do detecta automaticamente o tipo de arquivo enviado (TXT, PDF ou DOCX) e extrai o conteúdo usando a biblioteca certa, então você não precisa se preocupar com o formato do arquivo.md_to_docx() ” pega o texto formatado em markdown (como cartas de apresentação geradas pelo agente) e transforma em um documento Word limpo e bem estruturado, pronto para baixar.Isso garante que o aplicativo possa lidar de forma flexível com diversos tipos de currículos e produzir resultados profissionais, independentemente do formato do arquivo original.
Depois, a gente faz uma análise robusta pra extrair os dados da tarefa da resposta do agente.
def normalize_jobs(items: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
normed = []
for it in items:
if not isinstance(it, dict):
continue
# case-insensitive keys
lower_map = {str(k).strip().lower(): it[k] for k in it.keys()}
company = str(lower_map.get("company", "") or "").strip()
title = str(lower_map.get("title", "") or "").strip()
location = str(lower_map.get("location", "") or "").strip()
link = str(lower_map.get("link", "") or "").strip()
why_fit = str(lower_map.get("why_fit", lower_map.get("good match", "")) or "").strip()
if not link:
continue
normed.append({
"company": company or "—",
"title": title or "—",
"location": location or "—",
"link": link,
"Good Match": "Yes" if why_fit else "—",
})
return normed[:5]
def extract_jobs_from_text(text: str) -> List[Dict[str, Any]]:
if not text:
return []
pattern = r"<JOBS>\s*(?:```[\w-]*\s*)?(\[.*?\])\s*(?:```)?\s*</JOBS>"
m = re.search(pattern, text, flags=re.S | re.I)
if not m:
return []
raw = m.group(1).strip().strip("`").strip()
try:
obj = json.loads(raw)
return obj if isinstance(obj, list) else []
except Exception:
try:
salvaged = re.sub(r"(?<!\\)'", '"', raw)
obj = json.loads(salvaged)
return obj if isinstance(obj, list) else []
except Exception:
st.session_state.last_error = f"JSON parse failed: {raw[:1200]}"
return []Vamos entender rapidamente as funções acima:
extract_jobs_from_text() usa uma expressão regular pra extrair uma matriz JSON de tarefas da saída estruturada do agente (dentro das tags <JOBS>...</JOBS>). A análise de fallback também está incluída para lidar com pequenos erros de modelo, como retornar aspas simples em vez de aspas duplas em JSON.normalize_jobs() padroniza e limpa cada dicionário de tarefas, como chaves que não diferenciam maiúsculas de minúsculas, campos obrigatórios e remoção de espaços em branco, e limita a saída às 5 entradas principais.O coração da capacidade de pesquisa é alimentado pela Tavily. Então, a gente define uma ferramenta de busca na web que o agente profundo vai usar pra achar vagas de emprego atualizadas:
TAVILY_KEY = os.environ.get("TAVILY_API_KEY", "")
@tool
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
) -> List[Dict[str, Any]]:
if not TAVILY_KEY:
raise RuntimeError("TAVILY_API_KEY is not set in the environment.")
client = TavilyClient(api_key=TAVILY_KEY)
return client.search(
query=query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)A função ` internet_search() ` tem a decoração ` @tool`, o que a torna acessível ao agente e aos subagentes. Depois, ele chama a API da Tavily, que mostra resultados de pesquisa recentes e relevantes, o que é ótimo para pesquisas e consultas dinâmicas de vagas.
Observação: Você pode adicionar mais ferramentas dessa maneira (como resumo de documentos, execução de código ou enriquecimento de dados) para ampliar ainda mais as capacidades do seu agente profundo.
Agora, vamos juntar tudo configurando o agente principal e seus subagentes, cada um com instruções específicas, assim:
INSTRUCTIONS = (
"You are a job application assistant. Do two things:\n"
"1) Use the web search tool to find exactly 5 CURRENT job postings (matching the user's target title, locations, and skills). "
"Return them ONLY as JSON in this exact wrapper:\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}, ... five total]\n"
"</JOBS>\n"
"Rules: The list must be valid JSON (no comments), real links to the job page or application page, no duplicates.\n"
"2) Produce a concise cover letter (≤150 words) for EACH job, with a subject line, appended to cover_letters.md under a heading per job.\n"
"Do not invent jobs. Prefer reputable sources (company career pages, LinkedIn, Lever, Greenhouse)."
)
JOB_SEARCH_PROMPT = (
"Search and select 5 real postings that match the user's title, locations, and skills. "
"Output ONLY this block format (no extra text before/after the wrapper):\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}]"
"\n</JOBS>"
)
COVER_LETTER_PROMPT = (
"For each job in the found list, write a subject line and a concise cover letter (≤150 words) that ties the user's skills/resume to the role. "
"Append to cover_letters.md under a heading per job. Keep writing tight and specific."
)
def build_agent():
api_key = os.environ.get("OPENAI_API_KEY")
if not api_key:
st.error("Please set OPENAI_API_KEY in your environment.")
st.stop()
llm = ChatOpenAI(model=os.environ.get("OPENAI_MODEL", "gpt-4o-mini"), temperature=0.2)
tools = [internet_search]
subagents = [
{"name": "job-search-agent", "description": "Finds relevant jobs", "prompt": JOB_SEARCH_PROMPT},
{"name": "cover-letter-writer-agent", "description": "Writes cover letters", "prompt": COVER_LETTER_PROMPT},
]
return create_deep_agent(tools, INSTRUCTIONS, subagents=subagents, model=llm)
def make_task_prompt(resume_text: str, skills_hint: str, title: str, location: str) -> str:
skills = skills_hint.strip()
skill_line = f" Prioritize these skills: {skills}." if skills else ""
return (
f"Target title: {title}\n"
f"Target location(s): {location}\n"
f"{skill_line}\n\n"
f"RESUME RAW TEXT:\n{resume_text[:8000]}"
)Essa etapa mostra o poder do Deep Agents por meio de subagentes especializados. As instruções principais fornecem orientações gerais, enquanto cada subagente tem instruções específicas para tarefas específicas:
INSTRUCTIONS, JOB_SEARCH_PROMPT e COVER_LETTER_PROMPT definem o prompt principal do sistema e instruções específicas para cada subagente. Isso garante que o agente sempre entregue trabalhos bem estruturados e cartas de apresentação personalizadas no formato certo.build_agent() ” verifica a chave da API OpenAI, configura o modelo de linguagem e cria o agente profundo com os subagentes de busca de emprego e carta de apresentação. Essa configuração modular permite que cada subagente se concentre na sua parte do fluxo de trabalho.make_task_prompt() ” gera um único prompt que junta o currículo, as habilidades, o cargo e a localização do usuário. Isso dá ao agente todo o contexto necessário para iniciar o processo de pesquisa e redação.Juntas, essas funções dão estrutura e especialização ao fluxo de trabalho.
Essa etapa é a lógica central do aplicativo que lida com as entradas do usuário e coordena o agente profundo:
resume_text = extract_text(uploaded) if uploaded else ""
run_clicked = st.button("Run", type="primary", disabled=not uploaded)
if run_clicked:
st.session_state.last_error = ""
st.session_state.raw_final = ""
try:
if not os.environ.get("OPENAI_API_KEY"):
st.error("OPENAI_API_KEY not set.")
st.stop()
if not TAVILY_KEY:
st.error("TAVILY_API_KEY not set.")
st.stop()
agent = build_agent()
task = make_task_prompt(resume_text, skills_hint, target_title, target_location)
state = {
"messages": [{"role": "user", "content": task}],
"files": {"cover_letters.md": ""},
}
with st.spinner("Finding jobs and drafting cover letters..."):
result = agent.invoke(state)
final_msgs = result.get("messages", [])
final_text = (final_msgs[-1].content if final_msgs else "") or ""
st.session_state.raw_final = final_text
files = result.get("files", {}) or {}
cover_md = (files.get("cover_letters.md") or "").strip()
st.session_state.cover_doc = md_to_docx(cover_md) if cover_md else None
raw_jobs = extract_jobs_from_text(final_text)
jobs_list = normalize_jobs(raw_jobs)
st.session_state.jobs_df = pd.DataFrame(jobs_list) if jobs_list else None
st.success("Done. Results generated and saved.")
except Exception as e:
st.session_state.last_error = str(e)
st.error(f"Error: {e}")O código acima lida com as ações do usuário, inicia o agente profundo e mostra os resultados assim:
Por fim, mostramos os resultados de um jeito fácil de entender:
st.header("Jobs")
if st.session_state.jobs_df is None or st.session_state.jobs_df.empty:
st.write("No jobs to show yet.")
else:
df = st.session_state.jobs_df.copy()
def as_link(u: str) -> str:
u = u if isinstance(u, str) else ""
return f'<a href="{u}" target="_blank">Apply</a>' if u else "—"
if "link" in df.columns:
df["link"] = df["link"].apply(as_link)
cols = [c for c in ["company", "title", "location", "link", "Good Match"] if c in df.columns]
df = df[cols]
st.write(df.to_html(escape=False, index=False), unsafe_allow_html=True)
st.header("Download")
if st.session_state.cover_doc:
st.download_button(
"Download cover_letters.docx",
data=st.session_state.cover_doc,
file_name="cover_letters.docx",
mime="application/vnd.openxmlformats-officedocument.wordprocessingml.document",
key="dl_cover_letters",
)
else:
st.caption("Cover letters not produced yet.")Depois que o agente terminar, a gente apresenta os resultados num layout bacana, tipo:
Isso transforma um fluxo de trabalho de IA com várias etapas em uma experiência simples com um clique.
Para abrir o aplicativo, é só executar:
streamlit app.pyAprenda IA com esses cursos!
Curso
Curso
Curso
blog
blog
Abid Ali Awan
15 min
Tutorial
Bex Tuychiev
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Moez Ali