Course
Deploying AI into Production with FastAPI
4 hr
4.5K
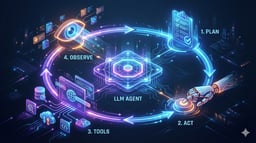
The most common agent architecture today involves an LLM calling tools in a loop, which is simple, effective, but ultimately limited. While this approach works for straightforward tasks, it falls short when faced with complex, multi-step challenges that require planning, context management, and sustained execution over longer time horizons.
LangChain’s Deep Agents architecture combines detailed system prompts, planning tools, sub-agents, and file systems to create AI agents capable of tackling complex research, coding, and analytical tasks. Applications like Claude Code, Deep Research, and Manus have proven this approach's effectiveness, and now the deepagents Python package makes this architecture accessible to everyone.
In this tutorial, I'll explain step by step how to:
Deep Agents are an advanced agent architecture designed for handling complex, multi-step tasks that require sustained reasoning, tool use, and memory. Unlike traditional agents that operate in short loops or perform simple tool calls, Deep Agents plan their actions, manage evolving context, delegate subtasks to specialized sub-agents, and maintain state across long interactions. This architecture is already powering real-world applications like Claude Code, Deep Research, and Manus.
Source: LangChain
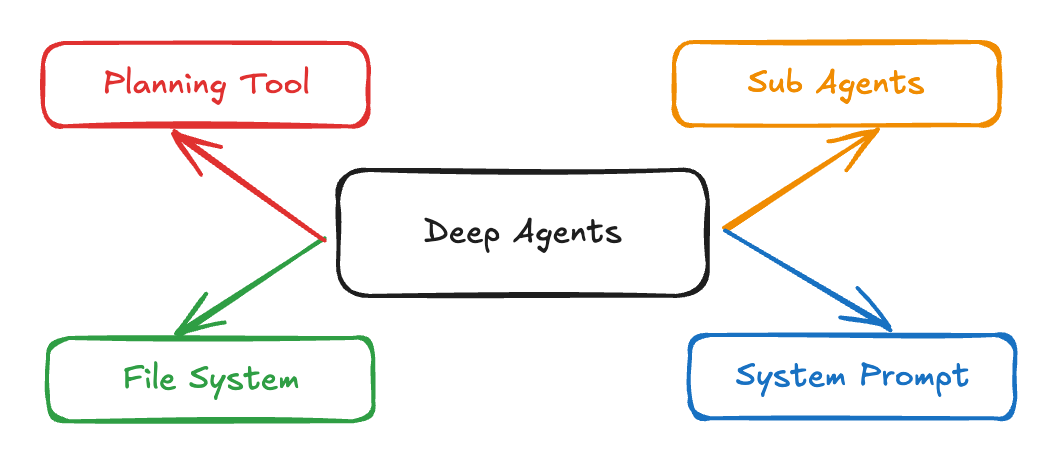
These are the key Characteristics of Deep Agents:
Deep Agents overcome the limitations of traditional agents through four core components:
Unlike simple instruction prompts, Deep Agents use comprehensive system prompts as follows:
DEEP_AGENT_SYSTEM_PROMPT = """
You are an expert research assistant capable of conducting thorough,
multi-step investigations. Your capabilities include:
PLANNING: Break complex tasks into subtasks using the todo_write tool
RESEARCH: Use internet_search extensively to gather comprehensive information
DELEGATION: Spawn sub-agents for specialized tasks using the call_subagent tool
DOCUMENTATION: Maintain detailed notes using the file system tools
When approaching a complex task:
1. First, create a plan using todo_write
2. Research systematically, saving important findings to files
3. Delegate specialized work to appropriate sub-agents
4. Synthesize findings into a comprehensive response
Examples:
[Detailed few-shot examples follow...]
"""The prompt integrates planning, research, and delegation with documentation, utilizing few-shot examples to decompose complex tasks.
The planning tool is often just a "no-op" that helps the agent organize its thoughts:
@tool
def todo_write(tasks: List[str]) -> str:
formatted_tasks = "\n".join([f"- {task}" for task in tasks])
return f"Todo list created:\n{formatted_tasks}"This simple tool provides important context engineering, which forces the agent to plan accordingly and keep that plan visible throughout execution.
Deep Agents can spawn specialized sub-agents for focused tasks. Each sub-agent is designed with its own prompt, description, and toolset, which enables both separation of concerns and deep task-specific optimization. Here’s an example of how you might define sub-agents in your workflow:
subagents = [
{
"name": "research-agent",
"description": "Conducts deep research on specific topics",
"prompt": "You are a research specialist. Focus intensively on the given topic...",
"tools": ["internet_search", "read_file", "write_file"]
},
{
"name": "analysis-agent",
"description": "Analyzes data and draws insights",
"prompt": "You are a data analyst. Examine the provided information...",
"tools": ["read_file", "write_file"]
}
]This approach provides context quarantine, which means that each sub-agent maintains its own context and does not pollute the main agent’s memory. By isolating specialized tasks, you can enable:
Deep Agents maintain and share state using a virtual file system. Instead of relying solely on conversation history, these built-in tools allow agents to organize information throughout a workflow:
tools = [
"ls", # List files
"read_file", # Read file contents
"write_file", # Write to file
"edit_file" # Edit existing file
]This virtual file system offers several advantages:
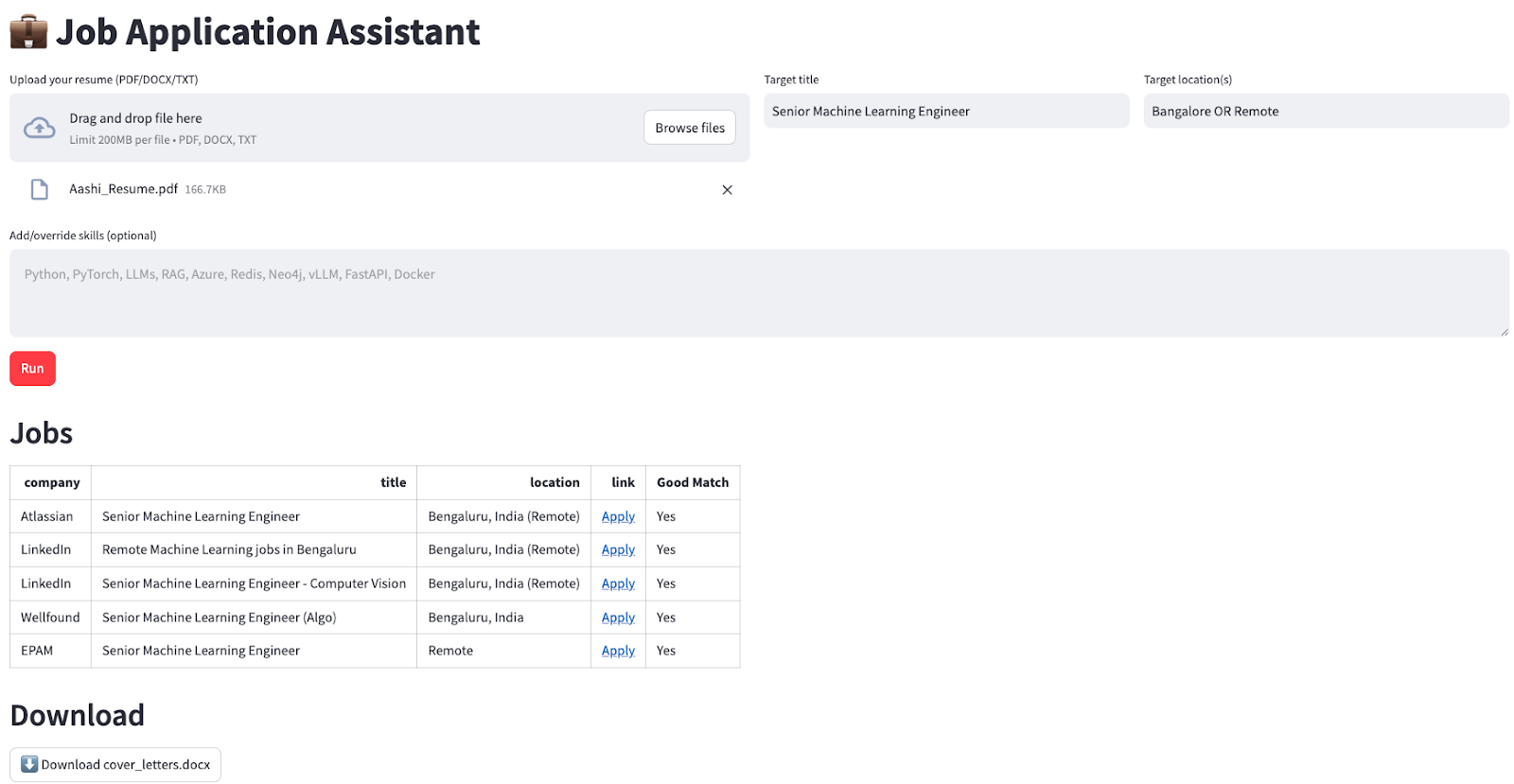
deepagentsI will walk you through a practical example of building a job application assistant that automatically finds relevant job openings and generates tailored cover letters for the user.
Our assistant will:
Let's start with a basic installation and setup:
pip install deepagents
pip install tavily-python
pip install streamlit
pip install langchain-openaiOnce installed, we set up our environment variables:
export OPENAI_API_KEY=sk-projxxxxxxxxxxxxxxxxxxx
export TAVILY_API_KEY=tvly-devxxxxxxxxxxxxxxxxxxxFor this demo, you’ll need both an OpenAI API key (for GPT-4o mini model) and a Tavily API key (for web search functionality). Tavily provides the agent with up-to-date job postings directly from the web, while OpenAI’s model handles all the language understanding, reasoning, planning, and content generation.
Note: New Tavily users receive 1,000 free API credits. To get your key, just sign up at https://app.tavily.com.
Finally, we’ll import the necessary libraries and set up the Streamlit interface:
import os
import io
import json
import re
from typing import Literal, Dict, Any, List
import streamlit as st
import pandas as pd
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from tavily import TavilyClient
from deepagents import create_deep_agentThis step imports all the required dependencies for our deep agent application. We use streamlit for the web interface, pandas for data handling, langchain_openai for the LLM integration, and deepagents for our agent framework.
Next, we initialize Streamlit’s session state to persist data between user interactions. This ensures the app remembers uploaded files, results, and error states, even as users interact with the interface:
if "jobs_df" not in st.session_state:
st.session_state.jobs_df = None
if "cover_doc" not in st.session_state:
st.session_state.cover_doc = None
if "last_error" not in st.session_state:
st.session_state.last_error = ""
if "raw_final" not in st.session_state:
st.session_state.raw_final = ""This setup is essential for a smooth user experience, allowing us to store the job results, generated cover letters, and any error messages throughout the session.
We use Streamlit columns to organize input fields within our UI for the resume upload, job title, location, and optional skills:
st.set_page_config(page_title="Job Application Assistant", page_icon=" ", layout="wide")
st.title("💼 Job Application Assistant")
c0, c1, c2 = st.columns([2, 1, 1])
with c0:
uploaded = st.file_uploader("Upload your resume (PDF/DOCX/TXT)", type=["pdf", "docx", "txt"])
with c1:
target_title = st.text_input("Target title", "Senior Machine Learning Engineer")
with c2:
target_location = st.text_input("Target location(s)", "Bangalore OR Remote")
skills_hint = st.text_area(
"Add/override skills (optional)",
"",
placeholder="Python, PyTorch, LLMs, RAG, Azure, vLLM, FastAPI",
)The UI is organized into columns for better layout. Users can upload their resume in multiple formats, specify their target job title and location, and highlight specific skills they want to emphasize in their applications.
Next, we implement robust file processing to handle different resume formats and extract texts from them.
import pypdf
import docx
def extract_text(file) -> str:
if not file:
return ""
name = file.name.lower()
if name.endswith(".txt"):
return file.read().decode("utf-8", errors="ignore")
if name.endswith(".pdf"):
pdf = pypdf.PdfReader(io.BytesIO(file.read()))
return "\n".join((p.extract_text() or "") for p in pdf.pages)
if name.endswith(".docx"):
d = docx.Document(io.BytesIO(file.read()))
return "\n".join(p.text for p in d.paragraphs)
return ""
def md_to_docx(md_text: str) -> bytes:
doc = docx.Document()
for raw in md_text.splitlines():
line = raw.rstrip()
if not line:
doc.add_paragraph("")
continue
if line.startswith("#"):
level = min(len(line) - len(line.lstrip("#")), 3)
doc.add_heading(line.lstrip("#").strip(), level=level)
elif line.startswith(("- ", "* ")):
doc.add_paragraph(line[2:].strip(), style="List Bullet")
else:
doc.add_paragraph(line)
bio = io.BytesIO()
doc.save(bio)
bio.seek(0)
return bio.read()These helper functions handle the complexity of extracting text from different file formats (PDF, DOCX, TXT) and converting markdown output back to DOCX format for download. Here is how each function works:
extract_text() function automatically detects the uploaded file type (TXT, PDF, or DOCX) and extracts the content using the appropriate library, so users don’t need to worry about the file format.md_to_docx() function takes markdown-formatted text (such as cover letters generated by the agent) and converts it into a clean, well-structured Word document ready for download.This ensures the application can flexibly handle diverse resume input and deliver professional outputs regardless of the original file format.
Next, we implement robust parsing to extract job data from the agent's response.
def normalize_jobs(items: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
normed = []
for it in items:
if not isinstance(it, dict):
continue
# case-insensitive keys
lower_map = {str(k).strip().lower(): it[k] for k in it.keys()}
company = str(lower_map.get("company", "") or "").strip()
title = str(lower_map.get("title", "") or "").strip()
location = str(lower_map.get("location", "") or "").strip()
link = str(lower_map.get("link", "") or "").strip()
why_fit = str(lower_map.get("why_fit", lower_map.get("good match", "")) or "").strip()
if not link:
continue
normed.append({
"company": company or "—",
"title": title or "—",
"location": location or "—",
"link": link,
"Good Match": "Yes" if why_fit else "—",
})
return normed[:5]
def extract_jobs_from_text(text: str) -> List[Dict[str, Any]]:
if not text:
return []
pattern = r"<JOBS>\s*(?:```[\w-]*\s*)?(\[.*?\])\s*(?:```)?\s*</JOBS>"
m = re.search(pattern, text, flags=re.S | re.I)
if not m:
return []
raw = m.group(1).strip().strip("`").strip()
try:
obj = json.loads(raw)
return obj if isinstance(obj, list) else []
except Exception:
try:
salvaged = re.sub(r"(?<!\\)'", '"', raw)
obj = json.loads(salvaged)
return obj if isinstance(obj, list) else []
except Exception:
st.session_state.last_error = f"JSON parse failed: {raw[:1200]}"
return []Let’s understand the above functions briefly:
extract_jobs_from_text() function uses a regular expression to extract a JSON array of jobs from the agent’s structured output (inside <JOBS>...</JOBS> tags). Fallback parsing is also included to handle minor model mistakes, such as returning single quotes instead of double quotes in JSON.normalize_jobs() function standardizes and cleans up each job dictionary, like case-insensitive keys, required fields, and whitespace stripping, and limits the output to the top 5 entries.The heart of the research capability is powered by Tavily. Thus, we define a web search tool that the deep agent will use to find up-to-date job listings:
TAVILY_KEY = os.environ.get("TAVILY_API_KEY", "")
@tool
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
) -> List[Dict[str, Any]]:
if not TAVILY_KEY:
raise RuntimeError("TAVILY_API_KEY is not set in the environment.")
client = TavilyClient(api_key=TAVILY_KEY)
return client.search(
query=query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)The internet_search() function is decorated with @tool, making it accessible to the agent and sub-agents. It then calls the Tavily API, which returns relevant, recent search results, making it ideal for dynamic job queries and research.
Note: You can add more tools this way (such as document summarization, code execution, or data enrichment) to further extend your deep agent’s abilities.
Now, we bring everything together by configuring the main agent and its sub-agents, each with targeted instructions as follows:
INSTRUCTIONS = (
"You are a job application assistant. Do two things:\n"
"1) Use the web search tool to find exactly 5 CURRENT job postings (matching the user's target title, locations, and skills). "
"Return them ONLY as JSON in this exact wrapper:\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}, ... five total]\n"
"</JOBS>\n"
"Rules: The list must be valid JSON (no comments), real links to the job page or application page, no duplicates.\n"
"2) Produce a concise cover letter (≤150 words) for EACH job, with a subject line, appended to cover_letters.md under a heading per job.\n"
"Do not invent jobs. Prefer reputable sources (company career pages, LinkedIn, Lever, Greenhouse)."
)
JOB_SEARCH_PROMPT = (
"Search and select 5 real postings that match the user's title, locations, and skills. "
"Output ONLY this block format (no extra text before/after the wrapper):\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}]"
"\n</JOBS>"
)
COVER_LETTER_PROMPT = (
"For each job in the found list, write a subject line and a concise cover letter (≤150 words) that ties the user's skills/resume to the role. "
"Append to cover_letters.md under a heading per job. Keep writing tight and specific."
)
def build_agent():
api_key = os.environ.get("OPENAI_API_KEY")
if not api_key:
st.error("Please set OPENAI_API_KEY in your environment.")
st.stop()
llm = ChatOpenAI(model=os.environ.get("OPENAI_MODEL", "gpt-4o-mini"), temperature=0.2)
tools = [internet_search]
subagents = [
{"name": "job-search-agent", "description": "Finds relevant jobs", "prompt": JOB_SEARCH_PROMPT},
{"name": "cover-letter-writer-agent", "description": "Writes cover letters", "prompt": COVER_LETTER_PROMPT},
]
return create_deep_agent(tools, INSTRUCTIONS, subagents=subagents, model=llm)
def make_task_prompt(resume_text: str, skills_hint: str, title: str, location: str) -> str:
skills = skills_hint.strip()
skill_line = f" Prioritize these skills: {skills}." if skills else ""
return (
f"Target title: {title}\n"
f"Target location(s): {location}\n"
f"{skill_line}\n\n"
f"RESUME RAW TEXT:\n{resume_text[:8000]}"
)This step demonstrates the power of Deep Agents through specialized sub-agents. The main instructions provide overall guidance, while each sub-agent has focused prompts for specific tasks:
INSTRUCTIONS, JOB_SEARCH_PROMPT, and COVER_LETTER_PROMPT define the main system prompt and specialized instructions for each sub-agent. This ensures the agent always produces well-structured job results and tailored cover letters in the required format.build_agent() function checks for the OpenAI API key, sets up the language model, and creates the deep agent with both the job search and cover letter sub-agents. This modular setup lets each sub-agent focus on its part of the workflow.make_task_prompt() function generates a single prompt that combines the user’s resume, skills, job title, and location. This gives the agent all the context it needs to start the search and drafting process.Together, these functions add structure and specialization in the workflow.
This step is the core application logic that handles user input and orchestrates the deep agent:
resume_text = extract_text(uploaded) if uploaded else ""
run_clicked = st.button("Run", type="primary", disabled=not uploaded)
if run_clicked:
st.session_state.last_error = ""
st.session_state.raw_final = ""
try:
if not os.environ.get("OPENAI_API_KEY"):
st.error("OPENAI_API_KEY not set.")
st.stop()
if not TAVILY_KEY:
st.error("TAVILY_API_KEY not set.")
st.stop()
agent = build_agent()
task = make_task_prompt(resume_text, skills_hint, target_title, target_location)
state = {
"messages": [{"role": "user", "content": task}],
"files": {"cover_letters.md": ""},
}
with st.spinner("Finding jobs and drafting cover letters..."):
result = agent.invoke(state)
final_msgs = result.get("messages", [])
final_text = (final_msgs[-1].content if final_msgs else "") or ""
st.session_state.raw_final = final_text
files = result.get("files", {}) or {}
cover_md = (files.get("cover_letters.md") or "").strip()
st.session_state.cover_doc = md_to_docx(cover_md) if cover_md else None
raw_jobs = extract_jobs_from_text(final_text)
jobs_list = normalize_jobs(raw_jobs)
st.session_state.jobs_df = pd.DataFrame(jobs_list) if jobs_list else None
st.success("Done. Results generated and saved.")
except Exception as e:
st.session_state.last_error = str(e)
st.error(f"Error: {e}")The above code handles user actions, launches the deep agent, and displays results as follows:
Finally, we present the results in a user-friendly format:
st.header("Jobs")
if st.session_state.jobs_df is None or st.session_state.jobs_df.empty:
st.write("No jobs to show yet.")
else:
df = st.session_state.jobs_df.copy()
def as_link(u: str) -> str:
u = u if isinstance(u, str) else ""
return f'<a href="{u}" target="_blank">Apply</a>' if u else "—"
if "link" in df.columns:
df["link"] = df["link"].apply(as_link)
cols = [c for c in ["company", "title", "location", "link", "Good Match"] if c in df.columns]
df = df[cols]
st.write(df.to_html(escape=False, index=False), unsafe_allow_html=True)
st.header("Download")
if st.session_state.cover_doc:
st.download_button(
"Download cover_letters.docx",
data=st.session_state.cover_doc,
file_name="cover_letters.docx",
mime="application/vnd.openxmlformats-officedocument.wordprocessingml.document",
key="dl_cover_letters",
)
else:
st.caption("Cover letters not produced yet.")After the agent finishes, we present the results in a polished layout i.e.:
This turns a multi-step AI workflow into a simple one-click experience.
To launch the app, simply run:
streamlit app.pyLearn AI with these courses!
Course
Course
Course
blog
Tim Lu
13 min
Tutorial
Aashi Dutt
Tutorial
Bex Tuychiev
Tutorial
Richie Cotton
Tutorial
Aashi Dutt
code-along
Emmanuel Pire