
Cours
Déployer l’IA en production avec FastAPI
4 h
4.5K
L'architecture d'agent la plus courante aujourd'hui implique un LLM appelant des outils en boucle, ce qui est simple, efficace, mais finalement limité. Si cette approche fonctionne pour des tâches simples, elle s'avère insuffisante face à des défis complexes, comportant plusieurs étapes et nécessitant une planification, une gestion du contexte et une exécution soutenue sur le long terme.
L'architecture d' s Deep Agents de LangChain combine des invites système détaillées, des outils de planification, des sous-agents et des systèmes de fichiers pour créer des agents IA capables de mener à bien des tâches complexes de recherche, de codage et d'analyse. Des applications telles que Claude Code, Deep Research et Manus ont démontré l'efficacité de cette approche, et désormais, le package Python deepagents rend cette architecture accessible à tous.
Dans ce tutoriel, je vais vous expliquer étape par étape comment :
Les agents profonds sont une architecture avancée conçue pour gérer des tâches complexes en plusieurs étapes qui nécessitent un raisonnement soutenu, l'utilisation d'outils et une bonne mémoire. Contrairement aux agents traditionnels qui fonctionnent en boucles courtes ou effectuent des appels d'outils simples, les agents profonds planifient leurs actions, gèrent un contexte en constante évolution, délèguent des sous-tâches à des sous-agents spécialisés et maintiennent leur état tout au long d'interactions prolongées. Cette architecture est déjà utilisée dans des applications concrètes telles que Claude Code, Deep Researchet Manus.
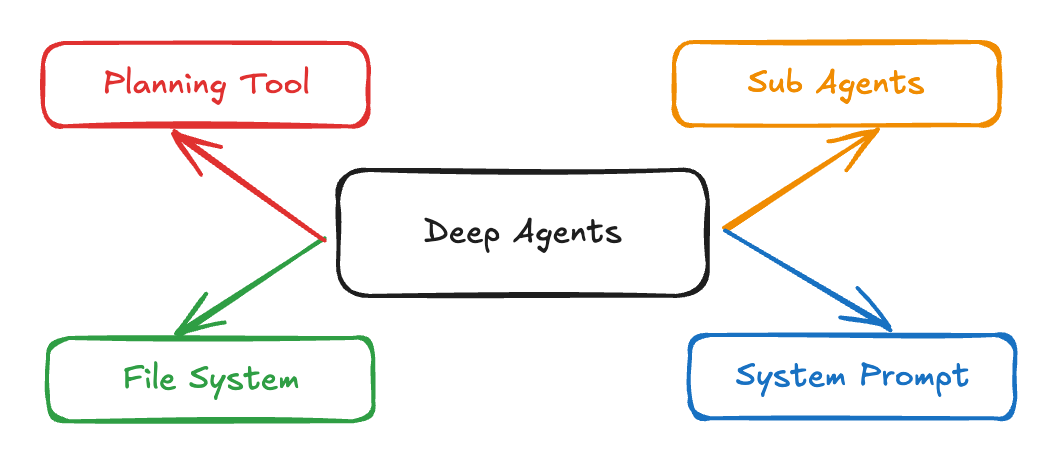
Source : LangChain
Voici les principales caractéristiques des agents profonds :
Les agents profonds surmontent les limites des agents traditionnels grâce à quatre composants essentiels :
Contrairement aux simples invites d'instructions, les agents profonds utilisent des invites système complètes comme suit :
DEEP_AGENT_SYSTEM_PROMPT = """
You are an expert research assistant capable of conducting thorough,
multi-step investigations. Your capabilities include:
PLANNING: Break complex tasks into subtasks using the todo_write tool
RESEARCH: Use internet_search extensively to gather comprehensive information
DELEGATION: Spawn sub-agents for specialized tasks using the call_subagent tool
DOCUMENTATION: Maintain detailed notes using the file system tools
When approaching a complex task:
1. First, create a plan using todo_write
2. Research systematically, saving important findings to files
3. Delegate specialized work to appropriate sub-agents
4. Synthesize findings into a comprehensive response
Examples:
[Detailed few-shot examples follow...]
"""L'invite intègre la planification, la recherche et la délégation à la documentation, en utilisant quelques exemples pour décomposer des tâches complexes.
L'outil de planification n'est souvent qu'une simple fonction « no-op » qui aide l'agent à organiser ses pensées :
@tool
def todo_write(tasks: List[str]) -> str:
formatted_tasks = "\n".join([f"- {task}" for task in tasks])
return f"Todo list created:\n{formatted_tasks}"Cet outil simple fournit une ingénierie contextuelle importante, qui oblige l'agent à planifier en conséquence et à garder ce plan visible tout au long de l'exécution.
Les agents profonds peuvent générer des sous-agents spécialisés pour des tâches spécifiques. Chaque sous-agent est conçu avec son propre message, sa propre description et son propre ensemble d'outils, ce qui permet à la fois la séparation des préoccupations et une optimisation approfondie spécifique à chaque tâche. Voici un exemple illustrant comment définir des sous-agents dans votre flux de travail :
subagents = [
{
"name": "research-agent",
"description": "Conducts deep research on specific topics",
"prompt": "You are a research specialist. Focus intensively on the given topic...",
"tools": ["internet_search", "read_file", "write_file"]
},
{
"name": "analysis-agent",
"description": "Analyzes data and draws insights",
"prompt": "You are a data analyst. Examine the provided information...",
"tools": ["read_file", "write_file"]
}
]Cette approche permet une mise en quarantaine contextuelle, ce qui signifie que chaque sous-agent conserve son propre contexte et n'encombre pas la mémoire de l'agent principal. En isolant les tâches spécialisées, vous pouvez :
Les agents profonds conservent et partagent leur état à l'aide d'un système de fichiers virtuel. Au lieu de se fier uniquement à l'historique des conversations, ces outils intégrés permettent aux agents d'organiser les informations tout au long d'un workflow :
tools = [
"ls", # List files
"read_file", # Read file contents
"write_file", # Write to file
"edit_file" # Edit existing file
]Ce système de fichiers virtuel offre plusieurs avantages :
deepagentsJe vais vous présenter un exemple pratique de création d'un assistant de candidature qui trouve automatiquement les offres d'emploi pertinentes et génère des lettres de motivation personnalisées pour l'utilisateur.
Notre assistant sera chargé de :
Commençons par une installation et une configuration de base :
pip install deepagents
pip install tavily-python
pip install streamlit
pip install langchain-openaiUne fois installé, nous configurons nos variables d'environnement :
export OPENAI_API_KEY=sk-projxxxxxxxxxxxxxxxxxxx
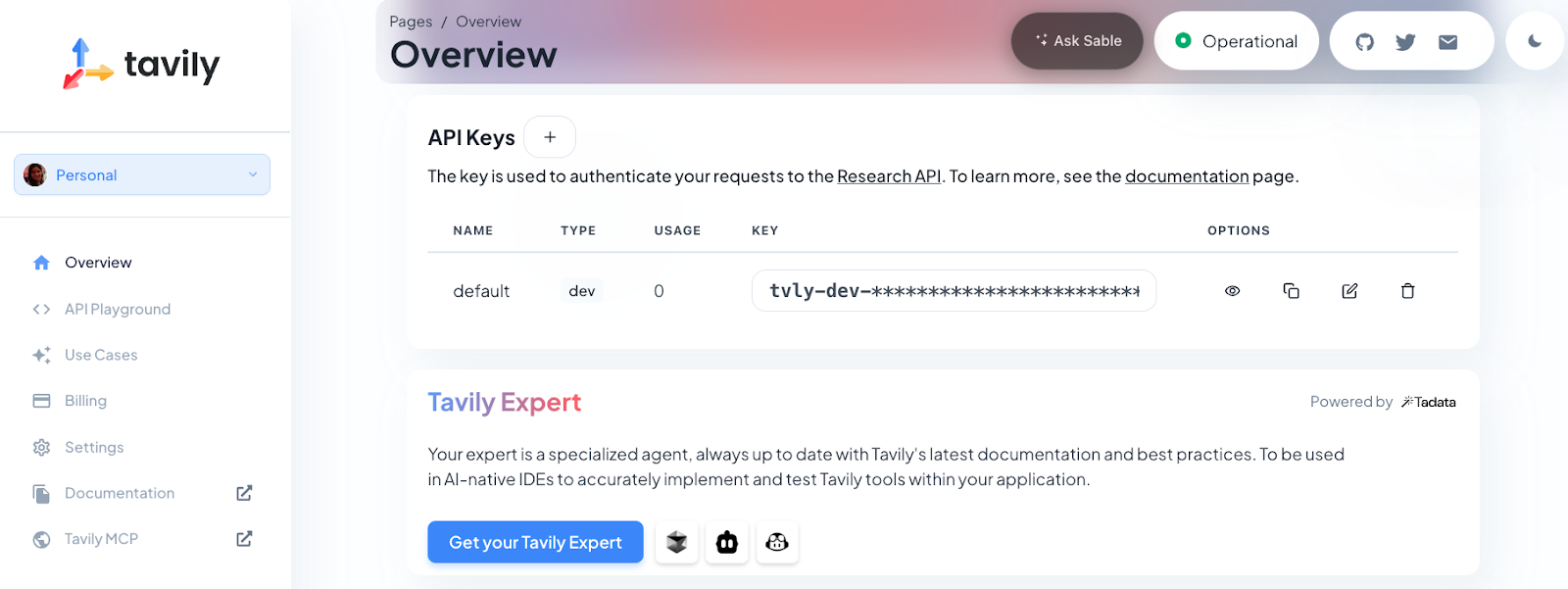
export TAVILY_API_KEY=tvly-devxxxxxxxxxxxxxxxxxxxPour cette démonstration, vous aurez besoin d'une clé API OpenAI (pour le modèle GPT-4o mini) et d'une clé API Tavily (pour la fonctionnalité de recherche Web). Tavily fournit à l'agent des offres d'emploi actualisées provenant directement du web, tandis que le modèle d'OpenAI se charge de la compréhension du langage, du raisonnement, de la planification et de la génération de contenu.
Remarque : Les nouveaux utilisateurs de Tavily reçoivent 1 000 crédits API gratuits. Pour obtenir votre clé, veuillez vous inscrire sur https://app.tavily.com.
Enfin, nous importerons les bibliothèques nécessaires et configurerons l'interface Streamlit:
import os
import io
import json
import re
from typing import Literal, Dict, Any, List
import streamlit as st
import pandas as pd
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from tavily import TavilyClient
from deepagents import create_deep_agentCette étape importe toutes les dépendances requises pour notre application Deep Agent. Nous utilisons streamlit pour l'interface web, pandas pour le traitement des données, langchain_openai pour l'intégration LLM et deepagents pour notre framework d'agent.
Ensuite, nous initialisons l'état de session de Streamlit afin de conserver les données entre les interactions de l'utilisateur. Cela garantit que l'application mémorise les fichiers téléchargés, les résultats et les états d'erreur, même lorsque les utilisateurs interagissent avec l'interface :
if "jobs_df" not in st.session_state:
st.session_state.jobs_df = None
if "cover_doc" not in st.session_state:
st.session_state.cover_doc = None
if "last_error" not in st.session_state:
st.session_state.last_error = ""
if "raw_final" not in st.session_state:
st.session_state.raw_final = ""Cette configuration est essentielle pour garantir une expérience utilisateur fluide, car elle nous permet de stocker les résultats des tâches, les lettres de motivation générées et tout message d'erreur tout au long de la session.
Nous utilisons les colonnes Streamlit pour organiser les champs de saisie dans notre interface utilisateur pour le téléchargement du CV, l'intitulé du poste, le lieu et les compétences facultatives :
st.set_page_config(page_title="Job Application Assistant", page_icon=" ", layout="wide")
st.title("💼 Job Application Assistant")
c0, c1, c2 = st.columns([2, 1, 1])
with c0:
uploaded = st.file_uploader("Upload your resume (PDF/DOCX/TXT)", type=["pdf", "docx", "txt"])
with c1:
target_title = st.text_input("Target title", "Senior Machine Learning Engineer")
with c2:
target_location = st.text_input("Target location(s)", "Bangalore OR Remote")
skills_hint = st.text_area(
"Add/override skills (optional)",
"",
placeholder="Python, PyTorch, LLMs, RAG, Azure, vLLM, FastAPI",
)L'interface utilisateur est organisée en colonnes pour une meilleure présentation. Les utilisateurs peuvent télécharger leur CV dans plusieurs formats, préciser le poste et le lieu de travail qu'ils recherchent, et mettre en avant les compétences spécifiques qu'ils souhaitent mettre en valeur dans leur candidature.
Ensuite, nous mettons en œuvre un traitement de fichiers robuste pour gérer différents formats de CV et en extraire les textes.
import pypdf
import docx
def extract_text(file) -> str:
if not file:
return ""
name = file.name.lower()
if name.endswith(".txt"):
return file.read().decode("utf-8", errors="ignore")
if name.endswith(".pdf"):
pdf = pypdf.PdfReader(io.BytesIO(file.read()))
return "\n".join((p.extract_text() or "") for p in pdf.pages)
if name.endswith(".docx"):
d = docx.Document(io.BytesIO(file.read()))
return "\n".join(p.text for p in d.paragraphs)
return ""
def md_to_docx(md_text: str) -> bytes:
doc = docx.Document()
for raw in md_text.splitlines():
line = raw.rstrip()
if not line:
doc.add_paragraph("")
continue
if line.startswith("#"):
level = min(len(line) - len(line.lstrip("#")), 3)
doc.add_heading(line.lstrip("#").strip(), level=level)
elif line.startswith(("- ", "* ")):
doc.add_paragraph(line[2:].strip(), style="List Bullet")
else:
doc.add_paragraph(line)
bio = io.BytesIO()
doc.save(bio)
bio.seek(0)
return bio.read()Ces fonctions d'aide gèrent la complexité de l'extraction de texte à partir de différents formats de fichiers (PDF, DOCX, TXT) et la conversion du résultat au format DOCX pour le téléchargement. Voici comment fonctionne chaque fonction :
extract_text() La fonctionnalité « » (Convertir le fichier en texte) de l'outil « » détecte automatiquement le type de fichier téléchargé (TXT, PDF ou DOCX) et en extrait le contenu à l'aide de la bibliothèque appropriée, de sorte que les utilisateurs n'ont pas à se soucier du format du fichier.md_to_docx() » (Exporter vers Word) convertit le texte au format Markdown (tel que les lettres de motivation générées par l'agent) en un document Word propre et bien structuré, prêt à être téléchargé.Cela garantit que l'application peut traiter de manière flexible divers types de CV et fournir des résultats professionnels, quel que soit le format du fichier d'origine.
Ensuite, nous mettons en œuvre une analyse syntaxique robuste pour extraire les données de tâche de la réponse de l'agent.
def normalize_jobs(items: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
normed = []
for it in items:
if not isinstance(it, dict):
continue
# case-insensitive keys
lower_map = {str(k).strip().lower(): it[k] for k in it.keys()}
company = str(lower_map.get("company", "") or "").strip()
title = str(lower_map.get("title", "") or "").strip()
location = str(lower_map.get("location", "") or "").strip()
link = str(lower_map.get("link", "") or "").strip()
why_fit = str(lower_map.get("why_fit", lower_map.get("good match", "")) or "").strip()
if not link:
continue
normed.append({
"company": company or "—",
"title": title or "—",
"location": location or "—",
"link": link,
"Good Match": "Yes" if why_fit else "—",
})
return normed[:5]
def extract_jobs_from_text(text: str) -> List[Dict[str, Any]]:
if not text:
return []
pattern = r"<JOBS>\s*(?:```[\w-]*\s*)?(\[.*?\])\s*(?:```)?\s*</JOBS>"
m = re.search(pattern, text, flags=re.S | re.I)
if not m:
return []
raw = m.group(1).strip().strip("`").strip()
try:
obj = json.loads(raw)
return obj if isinstance(obj, list) else []
except Exception:
try:
salvaged = re.sub(r"(?<!\\)'", '"', raw)
obj = json.loads(salvaged)
return obj if isinstance(obj, list) else []
except Exception:
st.session_state.last_error = f"JSON parse failed: {raw[:1200]}"
return []Comprenons brièvement les fonctions ci-dessus :
extract_jobs_from_text() utilise une expression régulière pour extraire un tableau JSON de tâches à partir de la sortie structurée de l'agent (à l'intérieur des balises <JOBS>...</JOBS>). Une analyse de secours est également incluse pour gérer les erreurs mineures du modèle, telles que le retour de guillemets simples au lieu de guillemets doubles dans JSON.normalize_jobs() , normalise et nettoie chaque dictionnaire de tâches, en supprimant notamment les majuscules et minuscules des clés, les champs obligatoires et les espaces, puis limite la sortie aux 5 premières entrées.Le cœur de la capacité de recherche est alimenté par Tavily. Nous définissons ainsi un outil de recherche Web que l'agent profond utilisera pour trouver des offres d'emploi à jour :
TAVILY_KEY = os.environ.get("TAVILY_API_KEY", "")
@tool
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
) -> List[Dict[str, Any]]:
if not TAVILY_KEY:
raise RuntimeError("TAVILY_API_KEY is not set in the environment.")
client = TavilyClient(api_key=TAVILY_KEY)
return client.search(
query=query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)La fonction « internet_search() » est décorée avec « @tool », ce qui la rend accessible à l'agent et aux sous-agents. Il fait ensuite appel à l'API Tavily, qui renvoie des résultats de recherche pertinents et récents, ce qui le rend idéal pour les requêtes et les recherches d'emploi dynamiques.
Remarque : Vous pouvez ajouter d'autres outils de cette manière (tels que la synthèse de documents, l'exécution de code ou l'enrichissement des données) afin d'étendre davantage les capacités de votre agent profond.
Maintenant, nous rassemblons tous les éléments en configurant l'agent principal et ses sous-agents, chacun avec des instructions ciblées comme suit :
INSTRUCTIONS = (
"You are a job application assistant. Do two things:\n"
"1) Use the web search tool to find exactly 5 CURRENT job postings (matching the user's target title, locations, and skills). "
"Return them ONLY as JSON in this exact wrapper:\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}, ... five total]\n"
"</JOBS>\n"
"Rules: The list must be valid JSON (no comments), real links to the job page or application page, no duplicates.\n"
"2) Produce a concise cover letter (≤150 words) for EACH job, with a subject line, appended to cover_letters.md under a heading per job.\n"
"Do not invent jobs. Prefer reputable sources (company career pages, LinkedIn, Lever, Greenhouse)."
)
JOB_SEARCH_PROMPT = (
"Search and select 5 real postings that match the user's title, locations, and skills. "
"Output ONLY this block format (no extra text before/after the wrapper):\n"
"<JOBS>\n"
"[{\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"},"
" {\"company\":\"...\",\"title\":\"...\",\"location\":\"...\",\"link\":\"https://...\",\"Good Match\":\"one sentence\"}]"
"\n</JOBS>"
)
COVER_LETTER_PROMPT = (
"For each job in the found list, write a subject line and a concise cover letter (≤150 words) that ties the user's skills/resume to the role. "
"Append to cover_letters.md under a heading per job. Keep writing tight and specific."
)
def build_agent():
api_key = os.environ.get("OPENAI_API_KEY")
if not api_key:
st.error("Please set OPENAI_API_KEY in your environment.")
st.stop()
llm = ChatOpenAI(model=os.environ.get("OPENAI_MODEL", "gpt-4o-mini"), temperature=0.2)
tools = [internet_search]
subagents = [
{"name": "job-search-agent", "description": "Finds relevant jobs", "prompt": JOB_SEARCH_PROMPT},
{"name": "cover-letter-writer-agent", "description": "Writes cover letters", "prompt": COVER_LETTER_PROMPT},
]
return create_deep_agent(tools, INSTRUCTIONS, subagents=subagents, model=llm)
def make_task_prompt(resume_text: str, skills_hint: str, title: str, location: str) -> str:
skills = skills_hint.strip()
skill_line = f" Prioritize these skills: {skills}." if skills else ""
return (
f"Target title: {title}\n"
f"Target location(s): {location}\n"
f"{skill_line}\n\n"
f"RESUME RAW TEXT:\n{resume_text[:8000]}"
)Cette étape démontre la puissance des agents profonds grâce à des sous-agents spécialisés. Les instructions principales fournissent des indications générales, tandis que chaque sous-agent dispose d'instructions spécifiques pour des tâches particulières :
INSTRUCTIONSJOB_SEARCH_PROMPT et COVER_LETTER_PROMPT définissent l'invite principale du système et les instructions spécialisées pour chaque sous-agent. Cela garantit que l'agent produit toujours des résultats bien structurés et des lettres de motivation personnalisées dans le format requis.build_agent() » vérifie la clé API OpenAI, configure le modèle linguistique et crée l'agent profond avec les sous-agents « recherche d'emploi » et « lettre de motivation ». Cette configuration modulaire permet à chaque sous-agent de se concentrer sur sa partie du flux de travail.make_task_prompt() » génère une seule invite qui combine le CV, les compétences, le titre du poste et la localisation de l'utilisateur. Cela fournit à l'agent tout le contexte nécessaire pour commencer le processus de recherche et de rédaction.Ensemble, ces fonctions apportent structure et spécialisation au flux de travail.
Cette étape correspond à la logique d'application centrale qui traite les entrées utilisateur et coordonne l'agent profond :
resume_text = extract_text(uploaded) if uploaded else ""
run_clicked = st.button("Run", type="primary", disabled=not uploaded)
if run_clicked:
st.session_state.last_error = ""
st.session_state.raw_final = ""
try:
if not os.environ.get("OPENAI_API_KEY"):
st.error("OPENAI_API_KEY not set.")
st.stop()
if not TAVILY_KEY:
st.error("TAVILY_API_KEY not set.")
st.stop()
agent = build_agent()
task = make_task_prompt(resume_text, skills_hint, target_title, target_location)
state = {
"messages": [{"role": "user", "content": task}],
"files": {"cover_letters.md": ""},
}
with st.spinner("Finding jobs and drafting cover letters..."):
result = agent.invoke(state)
final_msgs = result.get("messages", [])
final_text = (final_msgs[-1].content if final_msgs else "") or ""
st.session_state.raw_final = final_text
files = result.get("files", {}) or {}
cover_md = (files.get("cover_letters.md") or "").strip()
st.session_state.cover_doc = md_to_docx(cover_md) if cover_md else None
raw_jobs = extract_jobs_from_text(final_text)
jobs_list = normalize_jobs(raw_jobs)
st.session_state.jobs_df = pd.DataFrame(jobs_list) if jobs_list else None
st.success("Done. Results generated and saved.")
except Exception as e:
st.session_state.last_error = str(e)
st.error(f"Error: {e}")Le code ci-dessus gère les actions de l'utilisateur, lance l'agent profond et affiche les résultats comme suit :
Enfin, nous présentons les résultats dans un format convivial :
st.header("Jobs")
if st.session_state.jobs_df is None or st.session_state.jobs_df.empty:
st.write("No jobs to show yet.")
else:
df = st.session_state.jobs_df.copy()
def as_link(u: str) -> str:
u = u if isinstance(u, str) else ""
return f'<a href="{u}" target="_blank">Apply</a>' if u else "—"
if "link" in df.columns:
df["link"] = df["link"].apply(as_link)
cols = [c for c in ["company", "title", "location", "link", "Good Match"] if c in df.columns]
df = df[cols]
st.write(df.to_html(escape=False, index=False), unsafe_allow_html=True)
st.header("Download")
if st.session_state.cover_doc:
st.download_button(
"Download cover_letters.docx",
data=st.session_state.cover_doc,
file_name="cover_letters.docx",
mime="application/vnd.openxmlformats-officedocument.wordprocessingml.document",
key="dl_cover_letters",
)
else:
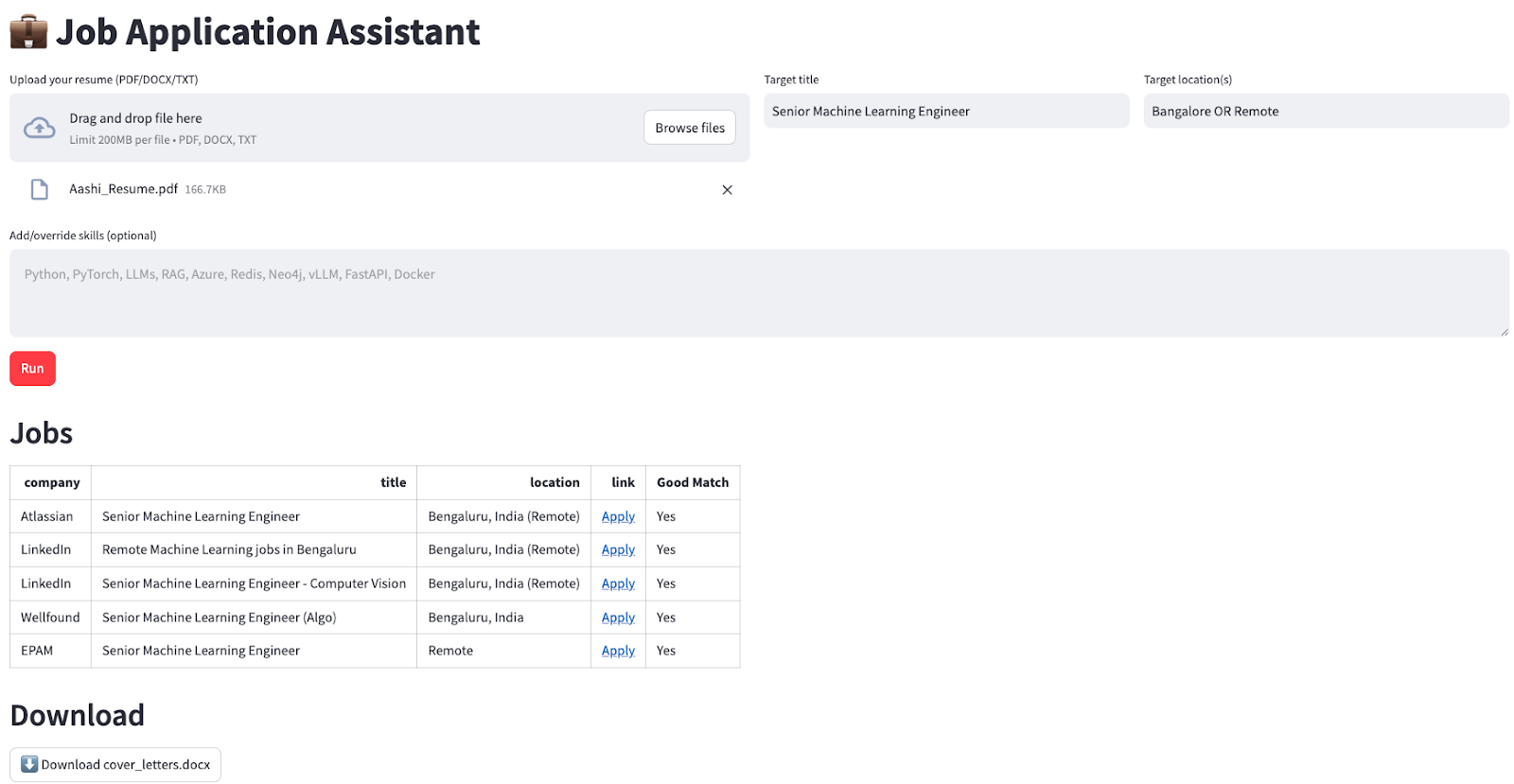
st.caption("Cover letters not produced yet.")Une fois que l'agent a terminé, nous présentons les résultats dans une mise en page soignée, par exemple :
Cela transforme un flux de travail IA en plusieurs étapes en une expérience simple en un seul clic.
Pour lancer l'application, veuillez exécuter :
streamlit app.pyApprenez l'IA grâce à ces cours !
Cours
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Mark Pedigo
