programa
Ingeniero de datos en Python
40 h
Los lagos de datos son el estándar de oro para almacenar enormes cantidades de datos estructurados y no estructurados, pero a menudo luchan con la inconsistencia de los datos, la evolución del esquema y los problemas de rendimiento. Delta Lake resuelve estos retos añadiendo transacciones ACID, aplicación de esquemas y procesamiento de datos escalableng encima de Apache Spark.
En este tutorial, te explicaré los fundamentos de Delta Lake, incluyendo su arquitectura, características y configuración, junto con ejemplos prácticos que te ayudarán a empezar.

Delta Lake es unacapa de almacenamiento de código abierto diseñada para integrarse con Apache Spark, lo que la convierte en la solución preferida de los equipos que utilizan el ecosistema Spark. Introduce las transacciones ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad) en los entornos de big data.
Al permitir una sólida gestión de metadatos, control de versiones y aplicación de esquemas, Delta Lake mejora los lagos de datos y garantiza una alta calidad de los datos para las cargas de trabajo de análisis y aprendizaje automático.
Delta Lake mejora las arquitecturas de datos tradicionales, en particular la arquitectura Lambda, al unificando el procesamiento de datos por lotes y en un único marco compatible con ACID.
Las plataformas de datos que utilizan Delta Lake suelen seguir una arquitectura medallónque organiza nuestros datos en tres capas lógicas definidas como sigue:
Las tablas de oro pueden ser consumidas por herramientas de inteligencia empresarial, permitiendo el análisis en tiempo real y apoyando la toma de decisiones.
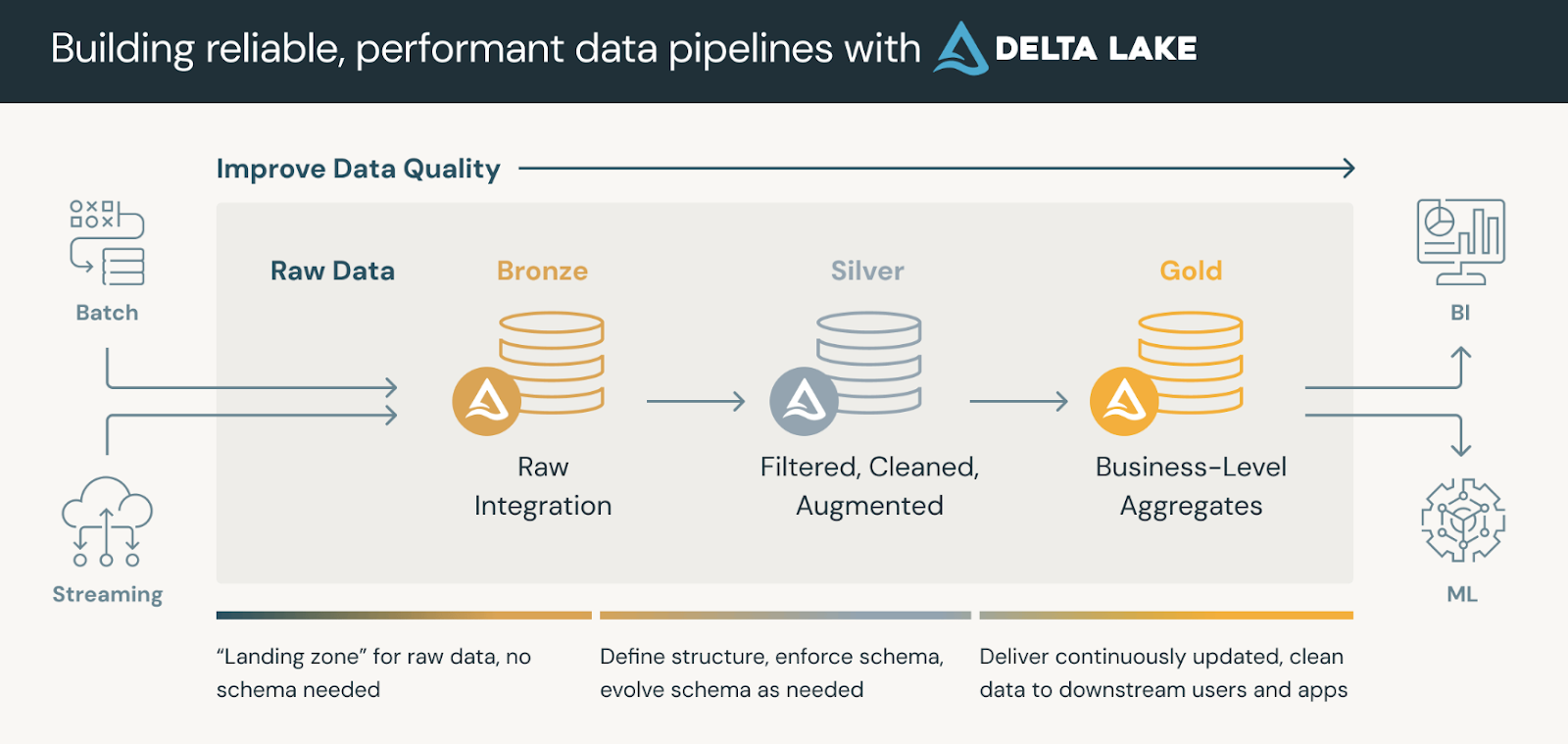
La arquitectura del medallón. Fuente de la imagen: Databricks
Delta Lake está construido sobre Apache Parquet, un formato de almacenamiento de columnasar que permite consultas, compresión y evolución de esquemas eficientes. Sin embargo, lo que diferencia a Delta Lake de los lagos de datos estándar basados en Parquet es el DeltaLog, un registro de transacciones quemantiene un historial de todos los cambios realizados en un conjunto de datos.
Entre los componentes básicos del formato de archivo Delta Lake se incluyen:
_delta_log/ ):Como puedes ver, sin el DeltaLog, los lagos de datos estándar basados en Parquet carecen de transacciones ACID y no pueden gestionar modificaciones concurrentes con seguridad. El formato de archivo de Delta Lake permite que coexistan el streaming y el procesamiento por lotes, manteniendo la coherencia. Por último, funciones como la fusión en lectura, la compactación y las consultas de metadatos optimizadas hacen que las tablas Delta sean muy eficientes para el análisis a gran escala.
¡Vamos a sumergirnos en la configuración de Delta Lake! Lo dividiré en dos sencillos pasos:
Para empezar, asegúrate de que tienes un entorno Apache Spark. A continuación, instala
Paquete Delta Lake (si utilizas Python) con el siguiente comando:
pip install pyspark delta-sparkEl comando anterior instala el paquete delta-spark, que equipa tu sesión Spark con las integraciones Delta Lake necesarias.
Después de instalar el paquete, configura tu sesión Spark para utilizar Delta Lake con
estos ajustes:
from pyspark.sql import SparkSession
# Initialize a SparkSession with Delta support
spark = SparkSession.builder \
.appName("DeltaLakePractice") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
# Check if Spark is working
print("Spark Session Created Successfully!")Aquí, la sesión Spark se establece con dos configuraciones críticas. El primero permite
extensiones SQL de Delta Lake y la segunda define Delta Lake como el predeterminado
garantizando que tus datos en formato Delta se traten correctamente.
Ahora, entremos en lo básico. Delta Lake te permite crear tablas compatibles con ACID utilizando una sencilla API DataFrame.
Crea una tabla Delta escribiendo un DataFrame en formato Delta:
# Sample DataFrame creation
data = [("Alice", 34), ("Bob", 45), ("Cathy", 29)]
columns = ["name", "age"]
df = spark.createDataFrame(data, columns)
# Save the DataFrame as a Delta table (overwrite mode replaces any existing data)
df.write.format("delta").mode("overwrite").save("/path/to/delta/table")El fragmento de código anterior crea un DataFrame básico y lo escribe en una ruta especificada utilizando el formato Delta. Utilizando mode("overwrite") te aseguras de que se sustituye cualquier dato existente.
Una vez creada una tabla Delta, lee sus datos como se indica a continuación:
# Load the Delta table from a specified path
delta_df = spark.read.format("delta").load("/path/to/delta/table")
delta_df.show()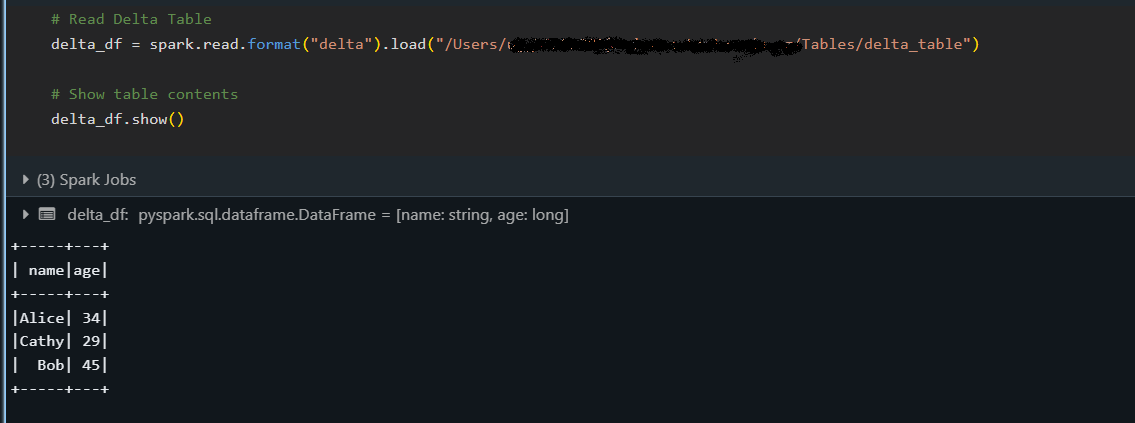
El fragmento anterior carga la tabla Delta en un DataFrame y muestra su contenido con el método show(), confirmando que los datos se han leído correctamente.
Delta Lake admite varios modos de escritura, lo que te permite añadir incrementalmente nuevos registros (añadir) o sustituir datos existentes (sobrescribir), manteniendo las garantías ACID.
Añade nuevos datos a una tabla Delta existente:
# New data to append
new_data = [("David", 40)]
new_df = spark.createDataFrame(new_data, columns)
# Append data to the existing Delta table
new_df.write.format("delta").mode("append").save("/path/to/delta/table")El modo "append" se utiliza para añadir nuevas filas a la tabla sin afectar a los datos existentes.
Sobrescribe toda la tabla Delta con los datos actualizados:
# Updated data for overwrite
updated_data = [("Alice", 35), ("Bob", 46), ("Cathy", 30)]
updated_df = spark.createDataFrame(updated_data, columns)
# Overwrite the current contents of the Delta table
updated_df.write.format("delta").mode("overwrite").save("/path/to/delta/table")Si utilizas el modo "overwrite", se sustituye todo el contenido de la tabla Delta por el nuevo DataFrame actualizado.
Esta sección cubre algunas de las potentes funcionalidades de Delta Lake más allá de las operaciones básicas.
En concreto, exploraremos cómo puedes consultar versiones anteriores de tus datos, gestionar automáticamente los cambios de esquema y realizar transacciones multioperación de forma atómica.
La función de viaje en el tiempo de Delta Lake te permite acceder a versiones anteriores de tu mesa. Cada operación de escritura en una tabla Delta crea una nueva versión para que puedas consultar un estado anterior de tus datos. He utilizado esta función para auditar cambios en los datos, depurar problemas o restaurar una instantánea anterior si algo va mal.
# Querying an earlier version (version 0) of the Delta table:
historical_df = spark.read.format("delta") \
.option("versionAsOf", 0) \
.load("/path/to/delta/table")
historical_df.show()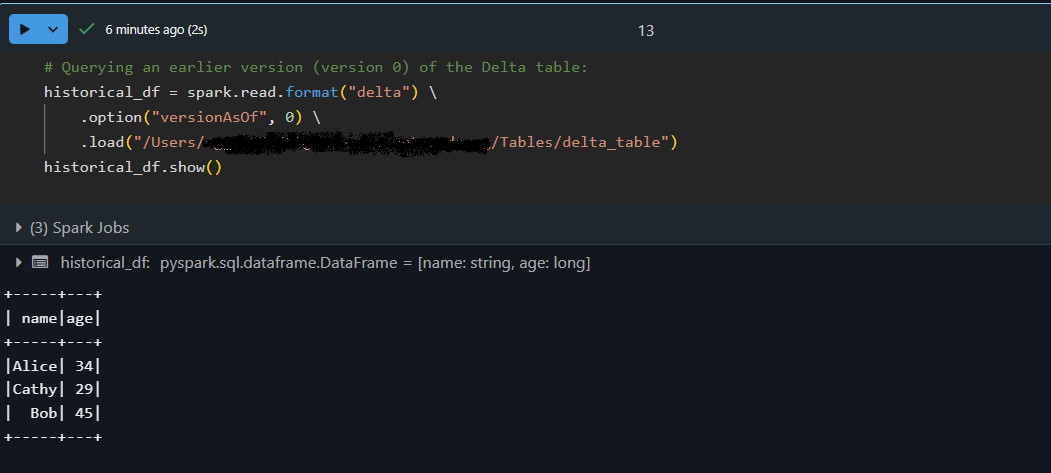
A medida que evolucionan los conjuntos de datos, pueden añadirse nuevas columnas. Delta Lake puedehacer evolucionar automáticamenteel esquema , fusionando nuevos campos en una tabla existente al tiempo que aplica la coherencia delos datos . Esto significa que no tienes que volver a crear o ajustar manualmente tu tabla cada vez que cambie tu estructura de datos.
Añadamos datos con un esquema actualizado utilizando la evolución automática del esquema:
# Create a DataFrame with an additional "country" column:
new_data = [("Alice", 34, "USA"), ("Bob", 45, "Canada")]
columns = ["name", "age", "country"]
new_df = spark.createDataFrame(new_data, columns)
# Append the new data to the Delta table with schema evolution enabled:
new_df.write.format("delta") \
.mode("append") \
.option("mergeSchema", "true") \
.save("/path/to/delta/table")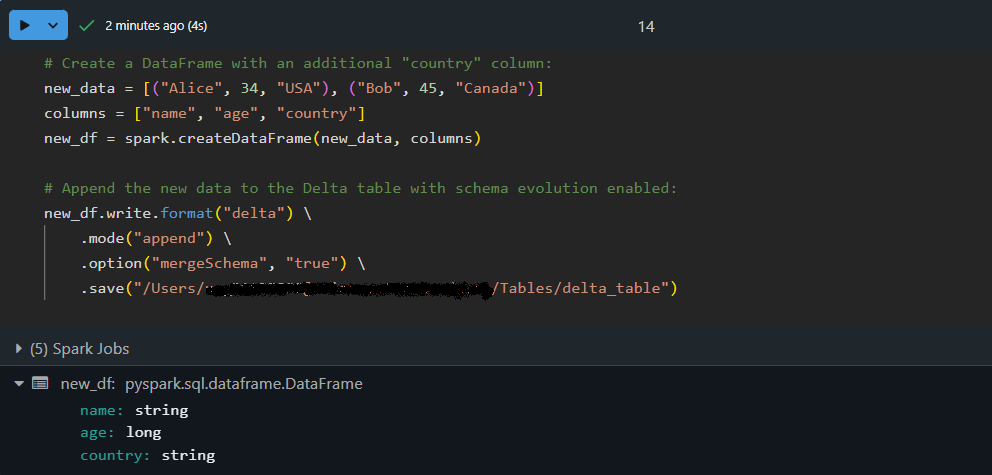
Aquí, el DataFrame new_df contiene una columna extra, country. Utilizando option("mergeSchema", "true") , el motor de Delta Lake actualiza automáticamente el esquema de la tabla para acomodar la nueva columna, ¡al tiempo que añade los datos de forma segura!
Las transacciones ACID de Delta Lake garantizan que las operaciones complejas se ejecuten de forma fiable, incluso en condiciones de alta concurrencia. Esto significa que una serie de operaciones (como actualizaciones e inserciones) se tratan como una sola unidad. Sifalla alguna parte de latransacción de , no se aplica ningún cambio, lo que garantiza la coherencia detus datos .
Vamos a realizar una transacción atómica con una operación MERGE:
-- Execute a MERGE statement in SQL to update or insert data atomically:
MERGE INTO delta./path/to/delta/table AS target
USING (SELECT 'Alice' AS name, 35 AS age, 'USA' AS country) AS source
ON target.name = source.name AND target.country IS NULL
WHEN MATCHED THEN
UPDATE SET target.age = source.age, target.country = source.country
WHEN NOT MATCHED THEN
INSERT (name, age, country) VALUES (source.name, source.age, source.country)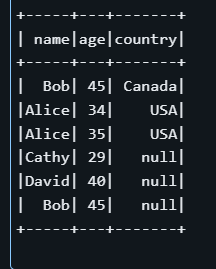
En el ejemplo anterior, la sentencia MERGE busca filas en la tabla de destino en las que coincida el nombre y el campo país sea NULL. Si se encuentra una coincidencia, actualiza lafila ; en caso contrario, inserta un nuevo registro .
Observa que, aunque ya exista una fila para "Alicia" en la tabla, la condición target.country IS NULL puede hacer que la operación inserte una nueva fila en lugar de actualizar una con un país no nulo. Este ejemplo demuestra la importancia de definir cuidadosamente los criterios de concordancia en las operaciones transaccionales.
Éstas son las mejores prácticas que sigo cuando trabajo con Delta Lake. Pueden ayudarte a construir conductos de datos eficientes y mantenibles.
Particionar tus tablas Delta puede mejorar significativamente el rendimiento de las consultas cuando con grandes conjuntos de datos.
Consejo: Cuando escribas tu DataFrame, utiliza la opción .partitionBy("column_name") para dividir tus datos en trozos más pequeños y manejables (por ejemplo, por fecha o categoría). Este enfoque reduce la cantidad de datos escaneados durantelas consultas típicasen .
Delta Lake utiliza un registro de transacciones (el _delta_log) para mantener los metadatos de todas las operaciones en tu tabla.
Consejo: Programa operaciones periódicas de mantenimiento (como el comando VACUUM ) para eliminar los archivos de datos obsoletos y racionalizar los metadatos. El resultado es un rendimiento más rápido de las consultas y una gestión más sencilla de los grandes conjuntos de datos.
La ordenación en Z es una técnica de agrupación de datos que los organiza en el disco para mejorar la eficacia de las consultas, especialmente al filtrar por columnas concretas:
OPTIMIZE delta./path/to/delta/table
ZORDER BY (name, age);El comando SQL anterior indica a Delta Lake que reorganice los datos físicamente basándose en las columnas name y age. Al coubicar valores similares, las consultas que filtran en estas columnas escanean menos datos y se ejecutan más rápido.
Cuando trabajes con Delta Lake, puede que de vez en cuando te encuentres con obstáculos. Laclave es tratar estos retos como oportunidades para profundizar en tu comprensión y dominar la tecnología. He aquí algunas de mis ideas y consejos prácticos para que vuelvas al buen camino.
Puedes encontrarte con problemas como desajustes de esquema o problemas de alineación de particiones . Por ejemplo, si los datos entrantes no coinciden con el esquema de la tabla, podrías ver errores durante las operaciones de escritura. Considera la posibilidad de utilizar opciones como mergeSchema para permitir que Delta Lake se ajuste.
Además, si el rendimiento de tu consulta disminuye, comprueba si tus datos están particionados de forma óptima o si un comando de mantenimiento como VACUUM podría ayudar a eliminar archivos obsoletos.
Cuando las cosas no funcionen como esperabas, no te preocupes: ¡forma parte del proceso! Un gran primer paso es inspeccionar el registro de transacciones (que se encuentra en el directorio _delta_log ). Este registro ofrece un historial detallado de las transacciones y puede ayudarte a localizar cuándo y dónde se desviaron las cosas .
Además, si observas incoherencias o cambios inesperados, intenta utilizar el viaje en el tiempo para comparar diferentes versiones de la tabla. Este enfoque te ayudará a aislar el problema y a comprender los acontecimientos que condujeron al error.
Delta Lake aporta una serie de ventajas -desde sólidas transacciones ACID y gestión eficaz de metadatos hasta funciones como el viaje en el tiempo y la evolución de esquemas- que te permiten construir canalizaciones de datos resistentes y escalables. Su integración con Apache Spark significa que Delta Lake podría ser el complemento perfecto para agilizar tus flujos de trabajo si ya has invertido en el ecosistema Spark.
A quienes deseen profundizar en sus conocimientos, les animo a explorar más recursos en DataCamp:
Feliz aprendizaje, y ¡mucha suerte en tu viaje de datos!
¡Aprende más sobre ingeniería de datos con estos cursos!
programa
Curso
Curso
blog
Tim Lu
12 min
blog
Gus Frazer
14 min
Tutorial
Natassha Selvaraj
Tutorial
Abid Ali Awan
Tutorial
Oluseye Jeremiah
Tutorial
Moez Ali
