Lernpfad
Dateningenieur in Python
40 Std.
Data Lakes sind der Goldstandard für die Speicherung großer Mengen strukturierter und unstrukturierter Daten, haben aber oft mit Dateninkonsistenz, Schemaentwicklung und Leistungsproblemen zu kämpfen. Delta Lake löst diese Herausforderungen, indem es ACID-Transaktionen, Schemadurchsetzung und skalierbare Datenverarbeitungauf Apache Spark aufbaut.
In diesem Tutorial erkläre ich dir die Grundlagen von Delta Lake, einschließlich der Architektur, der Funktionen und der Einrichtung, sowie praktische Beispiele, die dir den Einstieg erleichtern.

Delta Lake ist eineOpen-Source-Speicherschicht, die für die Integration mit Apache Spark entwickelt wurde und damit eine bevorzugte Lösung für Teams ist, die das Spark-Ökosystem nutzen. Es führt ACID-Transaktionen (Atomicity, Consistency, Isolation, Durability) in Big-Data-Umgebungen ein.
Durch robustes Metadatenmanagement, Versionskontrolle und Schemaerzwingung verbessert Delta Lake Data Lakehouses und gewährleistet eine hohe Datenqualität für Analysen und maschinelle Lernprozesse.
Delta Lake verbessert die traditionellen Datenarchitekturen, insbesondere die Lambda-Architektur, indem es Batch- und Streaming-Datenverarbeitung in einem einzigen, ACID-kompatiblen Framework vereint.
Datenplattformen, die Delta Lake nutzen, folgen in der Regel einer Medaillon-Architekturdie unsere Daten in drei logischen Schichten organisiert, die wie folgt definiert sind:
Gold-Tabellen können von Business Intelligence-Tools genutzt werden, um Echtzeit-Analysen zu ermöglichen und die Entscheidungsfindung zu unterstützen.
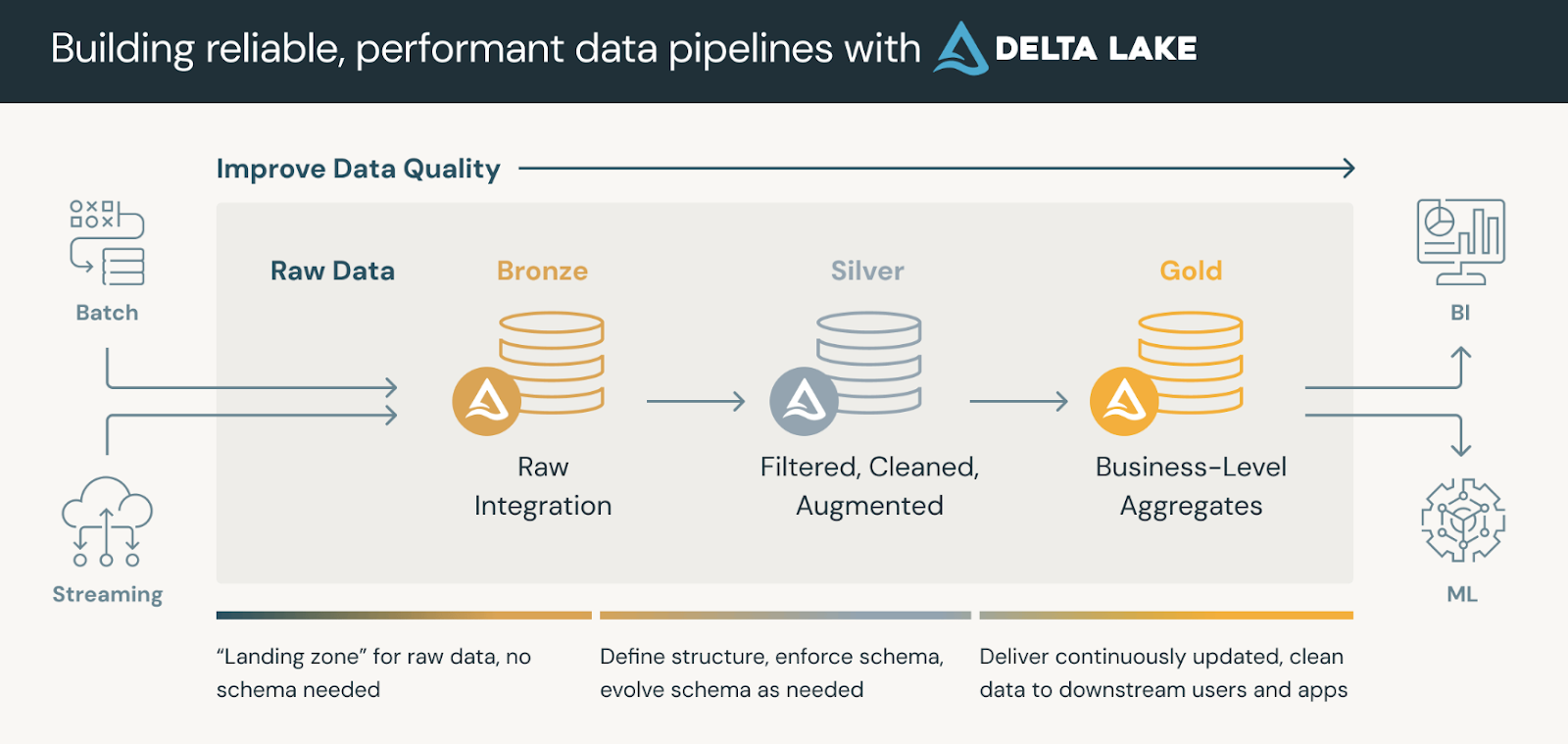
Die Medaillon-Architektur. Bildquelle: Databricks
Delta Lake basiert auf Apache Parquet, einemar Speicherformat, das effiziente Abfragen, Komprimierung und Schemaentwicklung ermöglicht. Was Delta Lake jedoch von den standardmäßigen Parquet-basierten Data Lakes unterscheidet, ist das DeltaLog, ein Transaktionsprotokoll, daseine Historie aller an einem Datensatz vorgenommenen Änderungen speichert.
Zu den wichtigsten Komponenten des Delta Lake-Dateiformats gehören:
_delta_log/ ):Wie du siehst, fehlt es den standardmäßigen Parquet-basierten Data Lakes ohne DeltaLog an ACID-Transaktionen und sie können nicht sicher mit gleichzeitigen Änderungen umgehen. Das Dateiformat von Delta Lake ermöglicht die Koexistenz von Streaming und Stapelverarbeitung bei gleichzeitiger Wahrung der Konsistenz. Und schließlich machen Funktionen wie Merge-on-Read, Verdichtung und optimierte Metadatenabfragen Delta-Tabellen äußerst effizient für umfangreiche Analysen.
Los geht's mit der Einrichtung von Delta Lake! Ich werde es in zwei einfache Schritte unterteilen:
Um loszulegen, musst du sicherstellen, dass du eine Apache Spark-Umgebung hast. Dann installiere die
Delta Lake Paket (wenn du Python verwendest) mit folgendem Befehl:
pip install pyspark delta-sparkMit dem obigen Befehl wird das Paket delta-spark installiert, das deine Spark-Sitzung mit den notwendigen Delta Lake-Integrationen ausstattet.
Nach der Installation des Pakets konfigurierst du deine Spark-Sitzung für die Verwendung von Delta Lake mit
diese Einstellungen:
from pyspark.sql import SparkSession
# Initialize a SparkSession with Delta support
spark = SparkSession.builder \
.appName("DeltaLakePractice") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
# Check if Spark is working
print("Spark Session Created Successfully!")Hier wird die Spark-Sitzung mit zwei wichtigen Konfigurationen eingerichtet. Die erste ermöglicht
Delta Lake SQL-Erweiterungen und die zweite definiert Delta Lake als Standard
Katalog, um sicherzustellen, dass deine Daten im Delta-Format korrekt verarbeitet werden.
Kommen wir nun zu den Grundlagen. Mit Delta Lake kannst du ACID-konforme Tabellen mithilfe einer einfachen DataFrame-API erstellen.
Erstelle eine Delta-Tabelle, indem du einen DataFrame im Delta-Format ausschreibst:
# Sample DataFrame creation
data = [("Alice", 34), ("Bob", 45), ("Cathy", 29)]
columns = ["name", "age"]
df = spark.createDataFrame(data, columns)
# Save the DataFrame as a Delta table (overwrite mode replaces any existing data)
df.write.format("delta").mode("overwrite").save("/path/to/delta/table")Der obige Codeschnipsel erstellt einen einfachen DataFrame und schreibt ihn im Delta-Format in einen bestimmten Pfad. Durch die Verwendung von mode("overwrite") wird sichergestellt, dass alle vorhandenen Daten ersetzt werden.
Sobald eine Delta-Tabelle erstellt ist, kannst du ihre Daten wie folgt lesen:
# Load the Delta table from a specified path
delta_df = spark.read.format("delta").load("/path/to/delta/table")
delta_df.show()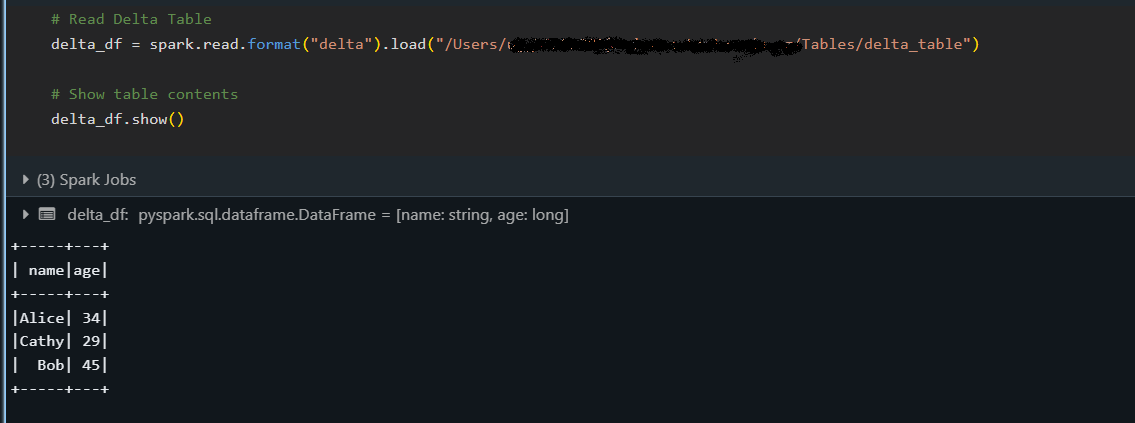
Der obige Ausschnitt lädt die Delta-Tabelle in einen DataFrame und zeigt ihren Inhalt mit der Methode show() an, um zu bestätigen, dass die Daten korrekt gelesen wurden.
Delta Lake unterstützt mehrere Schreibmodi, mit denen du schrittweise neue Datensätze hinzufügen (append) oder bestehende Daten ersetzen (overwrite) kannst, während die ACID-Garantien erhalten bleiben.
Neue Daten an eine bestehende Delta-Tabelle anhängen:
# New data to append
new_data = [("David", 40)]
new_df = spark.createDataFrame(new_data, columns)
# Append data to the existing Delta table
new_df.write.format("delta").mode("append").save("/path/to/delta/table")Der Modus "append" wird verwendet, um der Tabelle neue Zeilen hinzuzufügen, ohne die bestehenden Daten zu verändern.
Überschreibe die gesamte Delta Tabelle mit aktualisierten Daten:
# Updated data for overwrite
updated_data = [("Alice", 35), ("Bob", 46), ("Cathy", 30)]
updated_df = spark.createDataFrame(updated_data, columns)
# Overwrite the current contents of the Delta table
updated_df.write.format("delta").mode("overwrite").save("/path/to/delta/table")Im Modus "overwrite" wird der Inhalt der Delta-Tabelle vollständig durch den neuen aktualisierten DataFrame.
Dieser Abschnitt behandelt einige der leistungsstarken Funktionen von Delta Lake, die über die Grundfunktionen hinausgehen.
Wir werden insbesondere untersuchen, wie du auf frühere Versionen deiner Daten zurückblicken, Schemaänderungen automatisch verwalten und Transaktionen mit mehreren Operationen atomar durchführen kannst.
Mit der Zeitreisefunktion von Delta Lake kannst du auf frühere Versionen deiner Tabelle zugreifen. Jeder Schreibvorgang auf eine Delta-Tabelle erzeugt eine neue Version, so dass du einen früheren Stand deiner Daten abfragen kannst. Ich habe diese Funktion genutzt, um Datenänderungen zu überprüfen, Probleme zu beheben oder einen früheren Snapshot wiederherzustellen, wenn etwas schief gelaufen ist.
# Querying an earlier version (version 0) of the Delta table:
historical_df = spark.read.format("delta") \
.option("versionAsOf", 0) \
.load("/path/to/delta/table")
historical_df.show()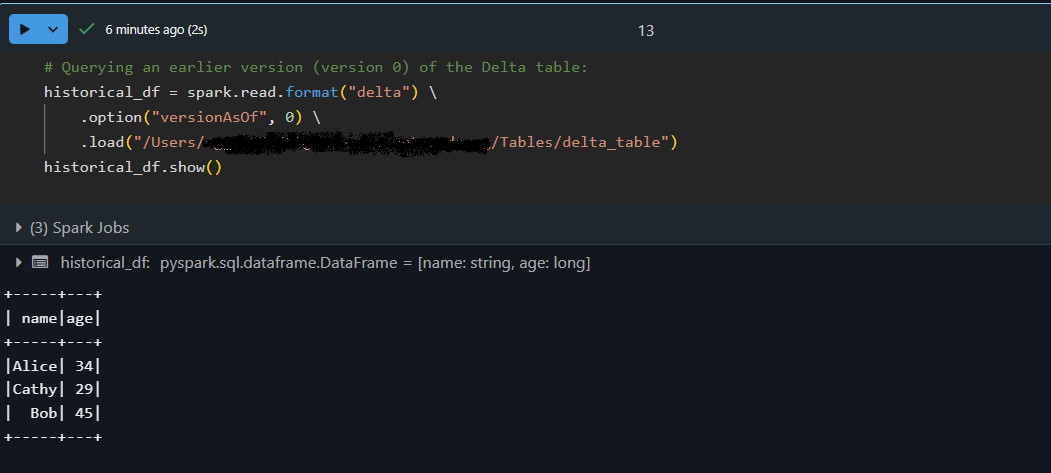
Wenn sich die Datensätze weiterentwickeln, können neue Spalten hinzugefügt werden. Delta Lake kanndas Schema automatischweiterentwickeln, indem es neue Felder in eine bestehende Tabelle einfügt und gleichzeitig die Konsistenzder Daten gewährleistet . Das bedeutet, dass du deine Tabelle nicht neu erstellen oder manuell anpassen musst, wenn sich deine Datenstruktur ändert.
Fügen wir Daten mit einem aktualisierten Schema hinzu, indem wir die automatische Schemaentwicklung nutzen:
# Create a DataFrame with an additional "country" column:
new_data = [("Alice", 34, "USA"), ("Bob", 45, "Canada")]
columns = ["name", "age", "country"]
new_df = spark.createDataFrame(new_data, columns)
# Append the new data to the Delta table with schema evolution enabled:
new_df.write.format("delta") \
.mode("append") \
.option("mergeSchema", "true") \
.save("/path/to/delta/table")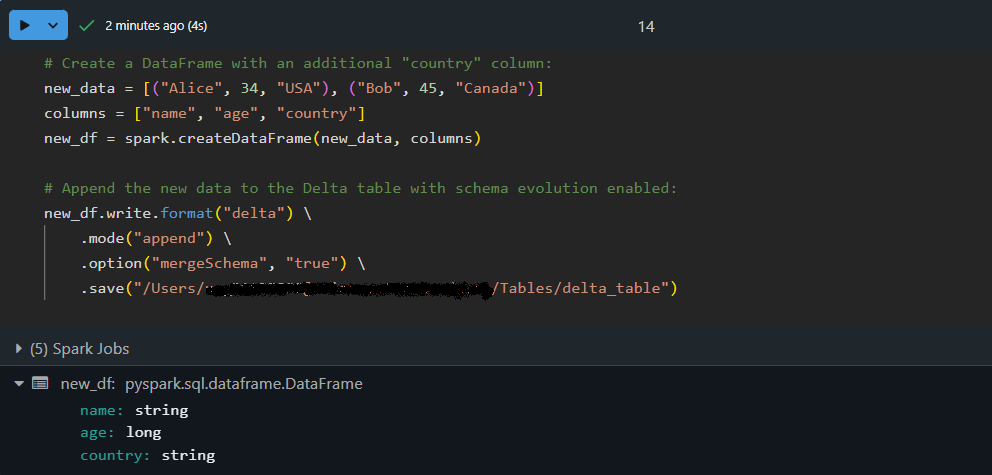
Hier enthält der DataFrame new_df eine zusätzliche Spalte, country. Mit option("mergeSchema", "true") aktualisiert die Delta Lake-Engine automatisch das Schema der Tabelle, um die neue Spalte aufzunehmen und die Daten sicheranzuhängen !
Die ACID-Transaktionen von Delta Lake garantieren, dass komplexe Operationen zuverlässig ausgeführt werden - auch bei hoher Parallelität. Das bedeutet, dass eine Reihe von Vorgängen (z. B. Aktualisierungen und Einfügungen) als eine Einheit behandelt werden. Wenn ein Teil der Transaktion fehlschlägt, werden keine Änderungen vorgenommen, damit deine Daten konsistentbleiben .
Lass uns eine atomare Transaktion mit einer MERGE Operation durchführen:
-- Execute a MERGE statement in SQL to update or insert data atomically:
MERGE INTO delta./path/to/delta/table AS target
USING (SELECT 'Alice' AS name, 35 AS age, 'USA' AS country) AS source
ON target.name = source.name AND target.country IS NULL
WHEN MATCHED THEN
UPDATE SET target.age = source.age, target.country = source.country
WHEN NOT MATCHED THEN
INSERT (name, age, country) VALUES (source.name, source.age, source.country)
Im obigen Beispiel sucht die Anweisung MERGE nach Zeilen in der Zieltabelle, in denen der Name übereinstimmt und das Länderfeld NULL ist. Wenn eine Übereinstimmung gefunden wird, wird dieZeile aktualisiert; andernfalls wird ein neuer Datensatz eingefügt .
Beachte, dass die Bedingung target.country IS NULL dazu führen kann, dass eine neue Zeile eingefügt wird, obwohl es bereits eine Zeile für "Alice" in der Tabelle gibt, anstatt eine Zeile mit einem Nicht-Null-Land zu aktualisieren. Dieses Beispiel zeigt, wie wichtig es ist, die Abgleichskriterien für Transaktionen sorgfältig zu definieren.
Hier sind die besten Praktiken, die ich bei der Arbeit mit Delta Lake befolge. Diese können dir helfen, effiziente, wartbare Datenpipelines aufzubauen.
Die Partitionierung deiner Delta-Tabellen kann die Abfrageleistung erheblich verbessern, wenn du mit großen Datenmengen.
Tipp: Wenn du deinen DataFrame schreibst, verwende die Option .partitionBy("column_name") , um deine Daten in kleinere, besser handhabbare Teile zu zerlegen (z. B. nach Datum oder Kategorie). Dieser Ansatz reduziert die Menge der Daten, die bei typischen Abfragen durchsucht werden.
Delta Lake verwendet ein Transaktionsprotokoll (das _delta_log), um Metadaten für alle Operationen auf deiner Tabelle.
Tipp: Planen Sie regelmäßige Wartungsarbeiten (z. B. den Befehl VACUUM ), um veraltete Datendateien zu entfernen und die Metadaten zu optimieren. Dies führt zu einer schnelleren Abfrageleistung und einer einfacheren Verwaltung großer Datensätze.
Z-Ordering ist eine Datenclustertechnik, die die Daten auf der Festplatte organisiert, um die Abfrageeffizienz zu verbessern, insbesondere wenn nach bestimmten Spalten gefiltert wird:
OPTIMIZE delta./path/to/delta/table
ZORDER BY (name, age);Der obige SQL-Befehl weist Delta Lake an, die Daten auf der Grundlage der Spalten name und age physisch neu anzuordnen. Durch die Zusammenführung ähnlicher Werte werden Abfragen, die auf diese Spalten filtern,weniger Daten scannen und schneller ausgeführt.
Bei der Arbeit mit Delta Lake stößt man gelegentlich auf Straßensperren. DerSchlüssel zu liegt darin, diese Herausforderungen als Chance zu sehen, dein Verständnis zu vertiefen und die Technologie zu beherrschen. Hier sind einige meiner praktischen Erkenntnisse und Tipps, um dich wieder auf den Lernpfad zu bringen.
Es können Probleme auftreten, wie z. B. Schemafehlanpassungen oder Probleme bei der Partitionsausrichtung . Wenn zum Beispiel die eingehenden Daten nicht mit dem Schema der Tabelle übereinstimmen ( ), können bei Schreibvorgängen Fehler auftreten. Ziehe in Betracht, Optionen wie mergeSchema zu nutzen, damit sich der Delta Lake anpassen kann.
Wenn deine Abfrageleistung sinkt, überprüfe außerdem, ob deine Daten optimal partitioniert sind oder ob ein Wartungsbefehl wie VACUUM helfen könnte, veraltete Dateien zu entfernen.
Wenn etwas nicht so funktioniert wie erwartet, mach dir keine Sorgen - das ist Teil des Prozesses! Ein guter erster Schritt ist die Überprüfung des Transaktionsprotokolls (zu finden im Verzeichnis _delta_log ). Dieses Protokoll bietet einen detaillierten Verlauf der Transaktionen und kann dir helfen, herauszufinden, wann und wo die Dinge aus dem Ruder gelaufen sind.
Wenn dir Ungereimtheiten oder unerwartete Änderungen auffallen, kannst du auch eine Zeitreise machen, um verschiedene Versionen der Tabellen zu vergleichen. Dieser Ansatz hilft dir, das Problem einzugrenzen und die Ereignisse zu verstehen, die zu dem Fehler geführt haben.
Delta Lake bietet eine Vielzahl von Vorteilen - von robusten ACID-Transaktionen und effizientem Metadatenmanagement bis hin zu Funktionen wie Zeitreisen und Schemaevolution -, mit denen dubelastbare und skalierbare Datenpipelines aufbauen kannst. Die Integration mit Apache Spark bedeutet, dass Delta Lake die perfekte Ergänzung zur Optimierung deiner Arbeitsabläufe sein könnte, wenn du bereits in das Spark-Ökosystem investiert hast.
Diejenigen, die ihr Verständnis vertiefen wollen, sollten sich weitere Ressourcen auf DataCamp ansehen:
Viel Spaß beim Lernen und viel Erfolg auf deiner Datenreise!
Lerne mehr über Data Engineering mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nathaniel Taylor-Leach
