Cursus
Ingénieur de données en Python
40 h
Les lacs de données sont la norme pour le stockage d'énormes quantités de données structurées et non structurées, mais ils sont souvent confrontés à l'incohérence des données, à l'évolution des schémas et à des problèmes de performance. Delta Lake résout ces problèmes en ajoutant des transactions ACID, l'application de schémas et un traitement évolutif des donnéesng au-dessus d'Apache Spark.
Dans ce tutoriel, j'expliquerai les bases de Delta Lake, y compris son architecture, ses fonctionnalités et sa configuration, avec des exemples pratiques pour vous aider à démarrer.

Delta Lake est unecouche de stockage open-source conçue pour s'intégrer à Apache Spark, ce qui en fait une solution privilégiée pour les équipes utilisant l'écosystème Spark. Il introduit les transactions ACID (Atomicité, Cohérence, Isolation, Durabilité) dans les environnements big data.
En permettant une gestion robuste des métadonnées, le contrôle des versions et l'application des schémas, Delta Lake améliore les entrepôts de données et garantit une qualité élevée des données pour les charges de travail d'analyse et d'apprentissage automatique.
Delta Lake améliore les architectures de données traditionnelles, en particulier l'architecture Lambda, en en unifiant le traitement des données par lots et en continu dans un cadre unique et conforme à la norme ACID.
Les plateformes de données qui utilisent Delta Lake suivent généralement une architecture en médaillonqui organise nos données en trois couches logiques définies comme suit :
Les tableaux d'or peuvent être consommés par des outils de veille stratégique, permettant des analyses en temps réel et soutenant la prise de décision.
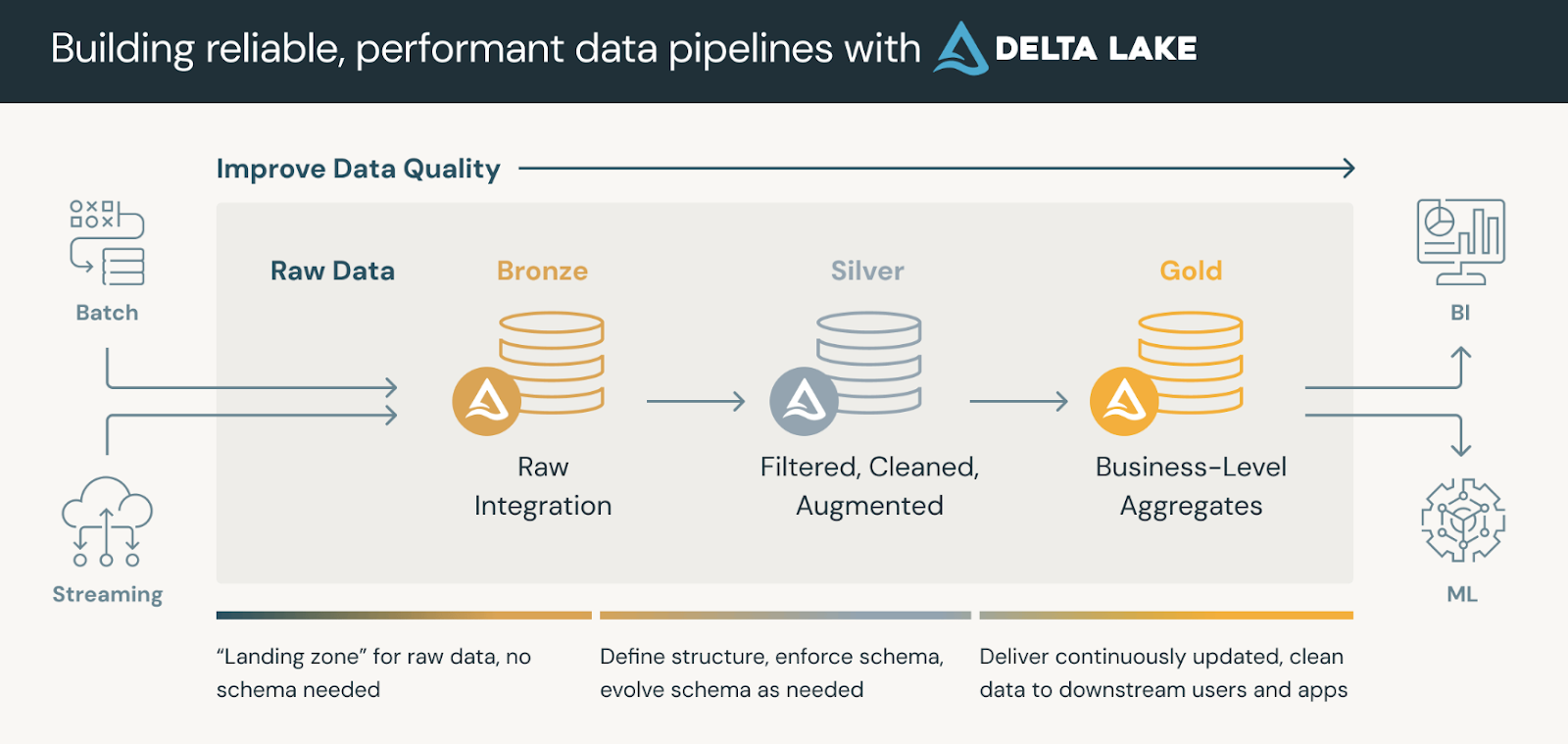
L'architecture du médaillon. Source de l'image : Bases de données
Delta Lake s'appuie sur Apache Parquet, un format de stockage de données en colonnesqui permet d'effectuer des recherches efficaces, de compresser les données et de faire évoluer les schémas. Cependant, ce qui différencie Delta Lake des lacs de données standard basés sur Parquet, c'est leDeltaLog( ), un journal des transactions quiconserve l'historique de toutes les modifications apportées à un ensemble de données.
Les principaux éléments du format de fichier du lac Delta sont les suivants :
_delta_log/ ):Comme vous pouvez le constater, sans le DeltaLog, les lacs de données standard basés sur Parquet ne disposent pas de transactions ACID et ne peuvent pas gérer des modifications simultanées en toute sécurité. Le format de fichier de Delta Lake permet de faire coexister le traitement en continu et le traitement par lots tout en maintenant la cohérence. Enfin, des fonctionnalités telles que la fusion à la lecture, le compactage et l'optimisation des requêtes de métadonnées rendent les tableaux Delta très efficaces pour les analyses à grande échelle.
Passons maintenant à la mise en place du lac Delta ! Je vais vous expliquer en deux étapes simples :
Pour commencer, assurez-vous que vous disposez d'un environnement Apache Spark. Installez ensuite le
Le paquet Delta Lake (si vous utilisez Python) avec la commande suivante :
pip install pyspark delta-sparkLa commande ci-dessus installe le paquet delta-spark, qui équipe votre session Spark des intégrations Delta Lake nécessaires.
Après avoir installé le package, configurez votre session Spark pour utiliser Delta Lake avec
ces paramètres :
from pyspark.sql import SparkSession
# Initialize a SparkSession with Delta support
spark = SparkSession.builder \
.appName("DeltaLakePractice") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
# Check if Spark is working
print("Spark Session Created Successfully!")Ici, la session Spark est mise en place avec deux configurations critiques. Le premier permet
Les extensions SQL de Delta Lake et la seconde définit Delta Lake comme l'extension par défaut.
en veillant à ce que vos données au format Delta soient correctement traitées.
Passons maintenant aux principes de base. Delta Lake vous permet de créer des tableaux conformes à la norme ACID à l'aide d'une simple API DataFrame.
Créez un tableau Delta en écrivant un DataFrame au format Delta :
# Sample DataFrame creation
data = [("Alice", 34), ("Bob", 45), ("Cathy", 29)]
columns = ["name", "age"]
df = spark.createDataFrame(data, columns)
# Save the DataFrame as a Delta table (overwrite mode replaces any existing data)
df.write.format("delta").mode("overwrite").save("/path/to/delta/table")L'extrait de code ci-dessus crée un DataFrame de base et l'écrit dans un chemin spécifié en utilisant le format Delta. L'utilisation de mode("overwrite") garantit que toutes les données existantes sont remplacées.
Une fois qu'un tableau Delta est créé, lisez ses données comme suit :
# Load the Delta table from a specified path
delta_df = spark.read.format("delta").load("/path/to/delta/table")
delta_df.show()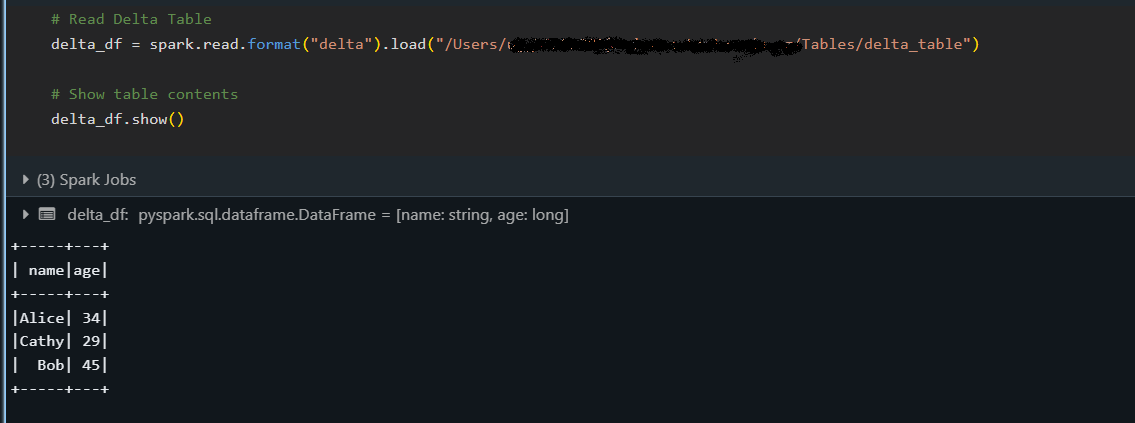
L'extrait ci-dessus charge le tableau Delta dans un DataFrame et affiche son contenu à l'aide de la méthode show(), confirmant ainsi que les données ont été correctement lues.
Delta Lake prend en charge plusieurs modes d'écriture, ce qui vous permet d'ajouter progressivement de nouveaux enregistrements (append) ou de remplacer des données existantes (overwrite) tout en maintenant les garanties ACID.
Ajouter de nouvelles données à un tableau Delta existant :
# New data to append
new_data = [("David", 40)]
new_df = spark.createDataFrame(new_data, columns)
# Append data to the existing Delta table
new_df.write.format("delta").mode("append").save("/path/to/delta/table")Le mode "append" est utilisé pour ajouter de nouvelles lignes au tableau sans affecter les données existantes.
Remplacer l'ensemble du tableau Delta par les données actualisées :
# Updated data for overwrite
updated_data = [("Alice", 35), ("Bob", 46), ("Cathy", 30)]
updated_df = spark.createDataFrame(updated_data, columns)
# Overwrite the current contents of the Delta table
updated_df.write.format("delta").mode("overwrite").save("/path/to/delta/table")L'utilisation du mode "overwrite" remplace entièrement le contenu du tableau Delta par le nouveau DataFrame mis à jour. nouveau DataFrame mis à jour.
Cette section couvre certaines des puissantes fonctionnalités du lac Delta au-delà des opérations de base.
Nous verrons notamment comment vous pouvez consulter les versions antérieures de vos données, gérer automatiquement les modifications de schéma et effectuer des transactions multi-opérations de manière atomique.
La fonction de voyage dans le temps de Delta Lake vous permet d'accéder aux versions précédentes de votre tableau. Chaque opération d'écriture sur un tableau Delta crée une nouvelle version afin que vous puissiez interroger un état antérieur de vos données. J'ai utilisé cette fonction pour vérifier les modifications de données, déboguer des problèmes ou restaurer un instantané précédent en cas de problème.
# Querying an earlier version (version 0) of the Delta table:
historical_df = spark.read.format("delta") \
.option("versionAsOf", 0) \
.load("/path/to/delta/table")
historical_df.show()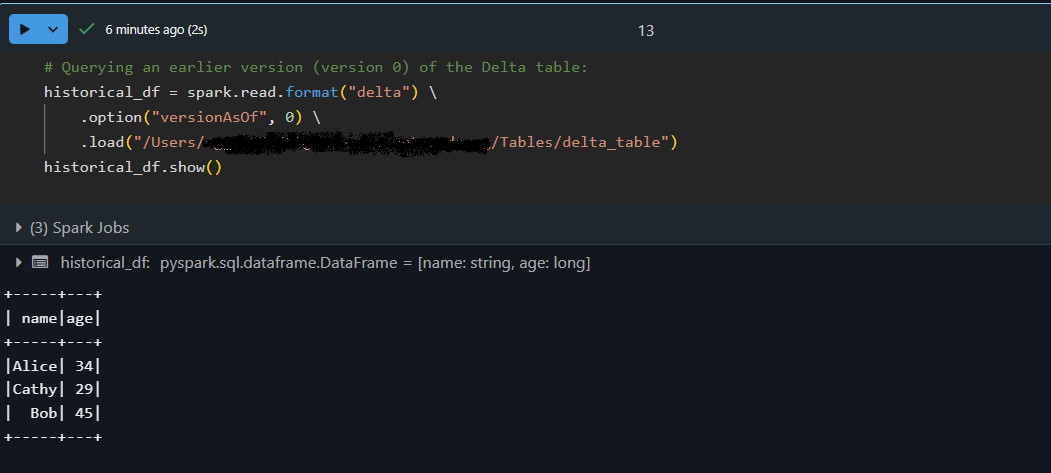
Au fur et à mesure que les ensembles de données évoluent, de nouvelles colonnes peuvent être ajoutées. Delta Lake peutfaire évoluer automatiquementle schéma , en fusionnant de nouveaux champs dans un tableau existant tout en assurant la cohérence desdonnées . Cela signifie que vous n'avez pas besoin de recréer ou d'ajuster manuellement vos tableaux chaque fois que votre structure de données change.
Ajoutons des données avec un schéma mis à jour en utilisant l'évolution automatique du schéma :
# Create a DataFrame with an additional "country" column:
new_data = [("Alice", 34, "USA"), ("Bob", 45, "Canada")]
columns = ["name", "age", "country"]
new_df = spark.createDataFrame(new_data, columns)
# Append the new data to the Delta table with schema evolution enabled:
new_df.write.format("delta") \
.mode("append") \
.option("mergeSchema", "true") \
.save("/path/to/delta/table")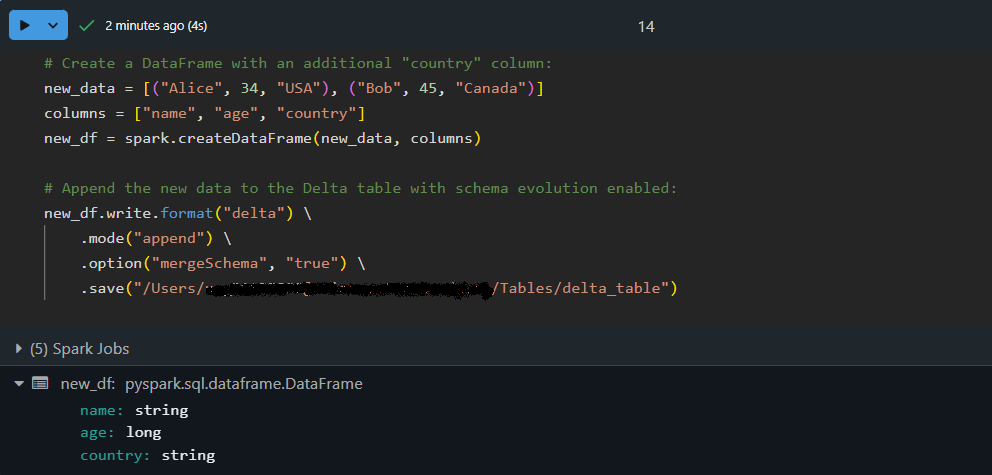
Ici, le DataFrame new_df contient une colonne supplémentaire, country. En utilisant option("mergeSchema", "true") , le moteur du lac Delta met automatiquement à jour le schéma du tableau pour prendre en compte la nouvelle colonne tout en ajoutant les données en toute sécurité !
Les transactions ACID de Delta Lake garantissent l'exécution fiable des opérations complexes sur le site, même en cas de forte concurrence. Cela signifie qu'une série d'opérations (telles que les mises à jour et les insertions) sont traitées comme une seule unité. Si une partie de latransaction échoue, aucune modification n'est appliquée, ce qui garantit la cohérence devos données.
Effectuons une transaction atomique avec une opération MERGE:
-- Execute a MERGE statement in SQL to update or insert data atomically:
MERGE INTO delta./path/to/delta/table AS target
USING (SELECT 'Alice' AS name, 35 AS age, 'USA' AS country) AS source
ON target.name = source.name AND target.country IS NULL
WHEN MATCHED THEN
UPDATE SET target.age = source.age, target.country = source.country
WHEN NOT MATCHED THEN
INSERT (name, age, country) VALUES (source.name, source.age, source.country)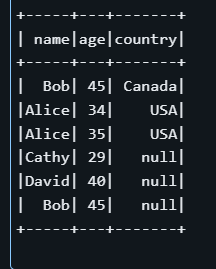
Dans l'exemple ci-dessus, l'instruction MERGE recherche dans le tableau cible les tableaux dont le nom correspond et dont le champ pays est NULL. Si une correspondance est trouvée, laligne est mise à jour; dans le cas contraire, un nouvel enregistrement est inséré .
Remarquez que même s'il existe déjà une ligne pour "Alice" dans le tableau, la condition target.country IS NULL peut amener l'opération à insérer une nouvelle ligne plutôt que d'en mettre une à jour avec un pays non nul. Cet exemple démontre l'importance de définir avec soin les critères de correspondance dans les opérations transactionnelles.
Voici les meilleures pratiques que j'applique lorsque je travaille avec Delta Lake. Ils peuvent vous aider à créer des pipelines de données efficaces et faciles à maintenir.
Le partitionnement de vos tableaux Delta peut améliorer de manière significative les performances des requêtes lorsque vous de grands ensembles de données.
Conseil : Lorsque vous écrivez votre DataFrame, utilisez l'option .partitionBy("column_name") pour diviser vos données en morceaux plus petits et plus faciles à gérer (par exemple, par date ou par catégorie). Cette approche permet de réduire la quantité de données analysées lors derequêtes typiquessur le site .
Delta Lake utilise un journal des transactions ( _delta_log) pour conserver les métadonnées de toutes les opérations effectuées sur votre table. opérations effectuées sur votre tableau.
Conseil : Planifiez des opérations de maintenance périodiques (telles que la commande VACUUM ) pour supprimer les fichiers de données obsolètes et rationaliser les métadonnées. Cela permet d'accélérer les performances des requêtes et de faciliter la gestion des grands ensembles de données.
L'ordonnancement en Z est une technique de regroupement des données qui organise les données sur le disque afin d'améliorer l'efficacité des requêtes, en particulier lors du filtrage sur des colonnes spécifiques :
OPTIMIZE delta./path/to/delta/table
ZORDER BY (name, age);La commande SQL ci-dessus indique à Delta Lake de réorganiser physiquement les données en fonction des colonnes name et age. En regroupant les valeurs similaires, les requêtes qui filtrent sur ces colonnes analysent moins de données et s'exécutent plus rapidement.
Lorsque vous travaillez avec le lac Delta, vous pouvez parfois rencontrer des obstacles. Laclé est de considérer ces défis comme des opportunités d'approfondir votre compréhension et de maîtriser la technologie. Voici quelques-uns de mes points de vue et conseils pratiques pour vous remettre sur le cursus.
Vous pouvez rencontrer des problèmes tels que des incohérences de schéma ou des problèmes d'alignement de partition . Par exemple, si vos données entrantes ne correspondent pas au schéma du tableau, vous risquez de voir apparaître des erreurs lors des opérations d'écriture. Envisagez d'utiliser des options telles que mergeSchema pour permettre à Delta Lake de s'adapter.
De même, si les performances de vos requêtes diminuent, vérifiez si vos données sont partitionnées de manière optimale ou si une commande de maintenance telle que VACUUM peut vous aider à supprimer les fichiers obsolètes.
Si les choses ne fonctionnent pas comme prévu, ne vous inquiétez pas : cela fait partie du processus ! Une excellente première étape consiste à inspecter le journal des transactions (qui se trouve dans le répertoire _delta_log ). Ce journal offre un historique détaillé des transactions et peut vous aider à déterminer quand et où les choses ont dérapé .
En outre, si vous remarquez des incohérences ou des changements inattendus, essayez d'utiliser le voyage dans le temps pour comparer les différentes versions des tableaux. Cette approche vous aidera à isoler le problème et à comprendre les événements qui ont conduit à l'erreur.
Delta Lake offre de nombreux avantages - des transactions ACID robustes à la gestion efficace des métadonnées, en passant par des fonctionnalités telles que le voyage dans le temps et l'évolution des schémas - qui vous permettent de créer des pipelines de données résilients et évolutifs (). Son intégration avec Apache Spark signifie que Delta Lake pourrait être le complément idéal pour rationaliser vos flux de travail si vous êtes déjà investi dans l'écosystème Spark.
Pour ceux qui souhaitent approfondir leur compréhension, je vous encourage à explorer d'autres ressources sur DataCamp :
Bon apprentissage et bonne chance pour votre voyage dans le domaine des données !
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cursus
Cours
Cours