Programa
Engenheiro de dados Em Python
40 h
Os lagos de dados são o padrão ouro para o armazenamento de grandes quantidades de dados estruturados e não estruturados, mas geralmente enfrentam problemas de inconsistência de dados, evolução de esquemas e problemas de desempenho. O Delta Lake resolve esses desafios adicionando transações ACID, aplicação de esquema e processamento de dados escalonável sobre o Apache Spark.
Neste tutorial, explicarei os conceitos básicos do Delta Lake, incluindo sua arquitetura, recursos e configuração, juntamente com exemplos práticos para ajudar você a começar.

O Delta Lake é umacamada de armazenamento de código aberto projetada para se integrar ao Apache Spark, o que o torna a solução preferida das equipes que usam o ecossistema do Spark. Ele introduz transações ACID (Atomicidade, Consistência, Isolamento, Durabilidade) em ambientes de Big Data.
Ao permitir o gerenciamento robusto de metadados, o controle de versões e a aplicação de esquemas, o Delta Lake aprimora os data lakehouses e garante alta qualidade de dados para cargas de trabalho de análise e aprendizado de máquina.
O Delta Lake aprimora as arquiteturas de dados tradicionais, especialmente a arquitetura Lambda, ao unificando o processamento de dados em lote e de streaming em uma única estrutura compatível com ACID.
As plataformas de dados que usam o Delta Lake geralmente seguem uma arquitetura de medalhãoque organiza nossos dados em três camadas lógicas definidas da seguinte forma:
As tabelas Gold podem ser consumidas por ferramentas de business intelligence, permitindo análises em tempo real e apoiando a tomada de decisões.
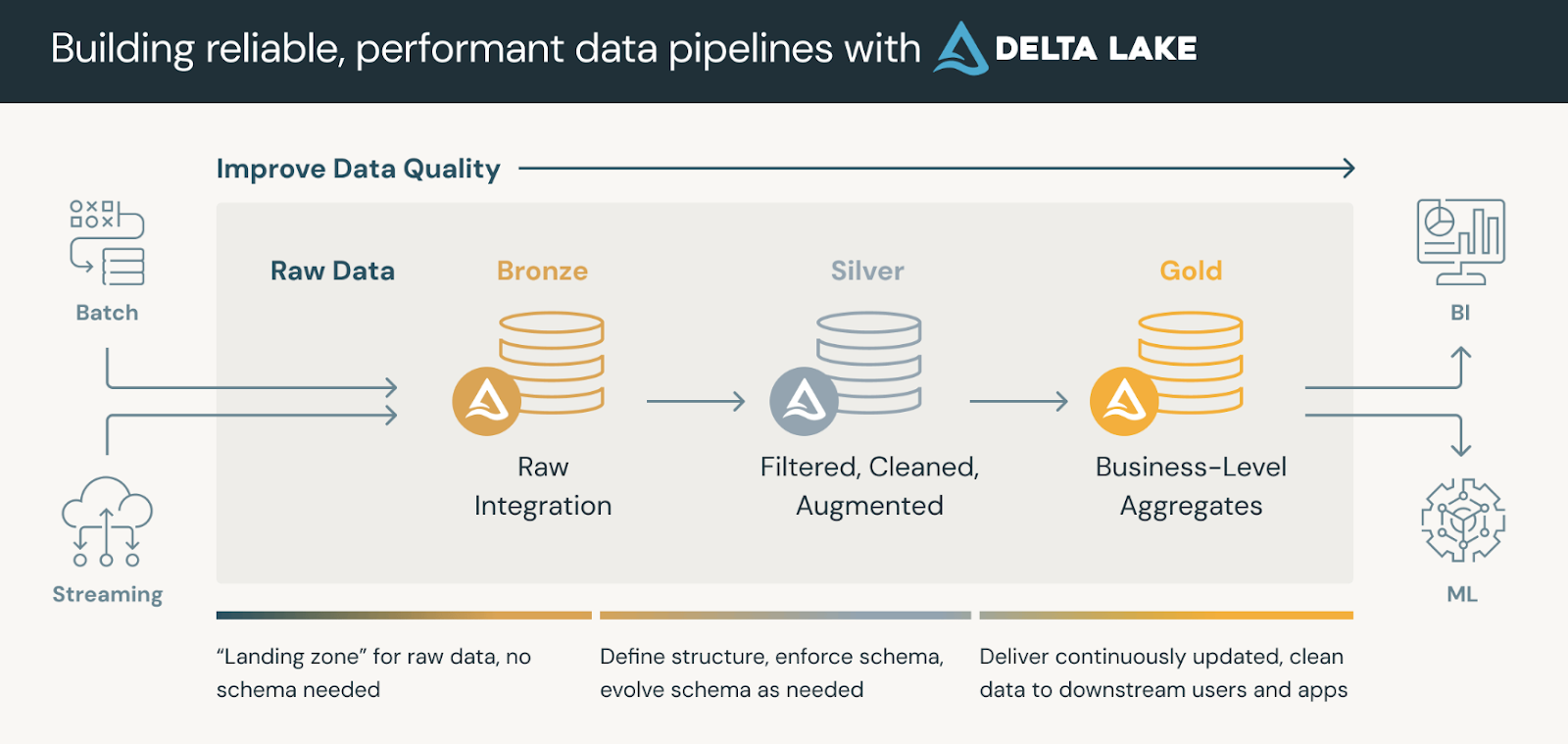
A arquitetura do medalhão. Fonte da imagem: Databricks
O Delta Lake foi desenvolvido com base no Apache Parquet, um formato de armazenamento de ar de colunaque permite consultas eficientes, compactação e evolução de esquemas. No entanto, o que diferencia o Delta Lake dos data lakes padrão baseados em Parquet é o DeltaLog, um registro de transações quemantém um histórico de todas as alterações feitas em um conjunto de dados.
Os principais componentes do formato de arquivo Delta Lake incluem:
_delta_log/ ):Como você pode ver, sem o DeltaLog, os data lakes padrão baseados em Parquet não têm transações ACID e não podem lidar com modificações simultâneas com segurança. O formato de arquivo do Delta Lake permite que o streaming e o processamento em lote coexistam, mantendo a consistência. Por fim, recursos como mesclagem na leitura, compactação e consultas de metadados otimizadas tornam as tabelas Delta altamente eficientes para análises em grande escala.
Vamos nos aprofundar na configuração do Delta Lake! Vou dividi-lo em duas etapas simples:
Para começar, verifique se você tem um ambiente do Apache Spark. Em seguida, instale o
Pacote Delta Lake (se você estiver usando Python) com o seguinte comando:
pip install pyspark delta-sparkO comando acima instala o pacote delta-spark, que equipa sua sessão do Spark com as integrações necessárias do Delta Lake.
Depois de instalar o pacote, configure sua sessão do Spark para usar o Delta Lake com
essas configurações:
from pyspark.sql import SparkSession
# Initialize a SparkSession with Delta support
spark = SparkSession.builder \
.appName("DeltaLakePractice") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
# Check if Spark is working
print("Spark Session Created Successfully!")Aqui, a sessão do Spark é definida com duas configurações essenciais. O primeiro permite que você
Delta Lake SQL extensions e o segundo define Delta Lake como o padrão
garantindo que seus dados em formato Delta sejam tratados corretamente.
Agora, vamos ver o básico. O Delta Lake permite que você crie tabelas compatíveis com ACID usando uma API DataFrame simples.
Crie uma tabela Delta gravando um DataFrame no formato Delta:
# Sample DataFrame creation
data = [("Alice", 34), ("Bob", 45), ("Cathy", 29)]
columns = ["name", "age"]
df = spark.createDataFrame(data, columns)
# Save the DataFrame as a Delta table (overwrite mode replaces any existing data)
df.write.format("delta").mode("overwrite").save("/path/to/delta/table")O trecho de código acima cria um DataFrame básico e o grava em um caminho especificado usando o formato Delta. O uso do site mode("overwrite") garante que todos os dados existentes sejam substituídos.
Depois que uma tabela Delta for criada, leia seus dados da seguinte forma:
# Load the Delta table from a specified path
delta_df = spark.read.format("delta").load("/path/to/delta/table")
delta_df.show()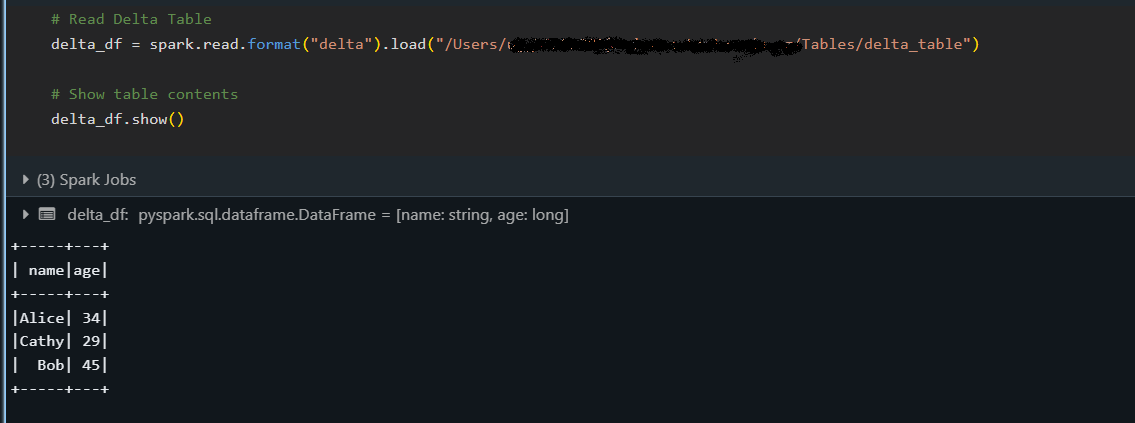
O snippet acima carrega a tabela Delta em um DataFrame e exibe seu conteúdo com o método show(), confirmando que os dados foram lidos corretamente.
O Delta Lake oferece suporte a vários modos de gravação, permitindo que você adicione novos registros de forma incremental (append) ou substitua dados existentes (overwrite), mantendo as garantias de ACID.
Anexar novos dados a uma tabela Delta existente:
# New data to append
new_data = [("David", 40)]
new_df = spark.createDataFrame(new_data, columns)
# Append data to the existing Delta table
new_df.write.format("delta").mode("append").save("/path/to/delta/table")O modo "append" é usado para adicionar novas linhas à tabela sem afetar os dados existentes.
Substituir toda a tabela Delta com dados atualizados:
# Updated data for overwrite
updated_data = [("Alice", 35), ("Bob", 46), ("Cathy", 30)]
updated_df = spark.createDataFrame(updated_data, columns)
# Overwrite the current contents of the Delta table
updated_df.write.format("delta").mode("overwrite").save("/path/to/delta/table")Ao usar o modo "overwrite", você substitui o conteúdo da tabela Delta inteiramente pelo novo DataFrame atualizado. novo DataFrame atualizado.
Esta seção aborda algumas das poderosas funcionalidades do Delta Lake além das operações básicas.
Em particular, exploraremos como você pode analisar versões anteriores dos seus dados, gerenciar automaticamente as alterações de esquema e executar transações de várias operações atomicamente.
O recurso de viagem no tempo do Delta Lake permite que você acesse versões anteriores da sua tabela. Cada operação de gravação em uma tabela Delta cria uma nova versão para que você possa consultar um estado anterior dos seus dados. Usei esse recurso para auditar alterações de dados, depurar problemas ou restaurar um snapshot anterior se algo der errado.
# Querying an earlier version (version 0) of the Delta table:
historical_df = spark.read.format("delta") \
.option("versionAsOf", 0) \
.load("/path/to/delta/table")
historical_df.show()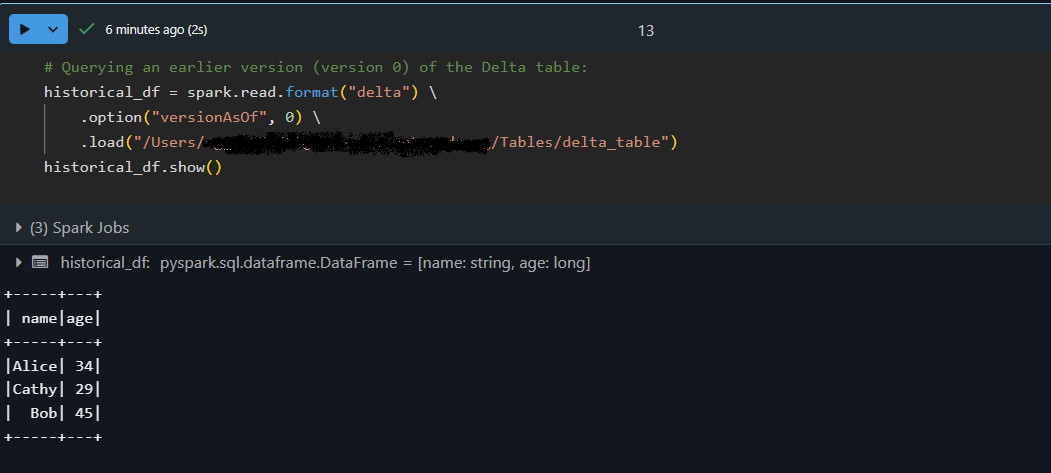
Conforme os conjuntos de dados evoluem, novas colunas podem ser adicionadas. O Delta Lake pode evoluir automaticamenteo esquema, mesclando novos campos em uma tabela existente e reforçando a consistênciados dados . Isso significa que você não precisa recriar ou ajustar manualmente a tabela sempre que a estrutura de dados for alterada.
Vamos anexar dados com um esquema atualizado usando a evolução automática do esquema:
# Create a DataFrame with an additional "country" column:
new_data = [("Alice", 34, "USA"), ("Bob", 45, "Canada")]
columns = ["name", "age", "country"]
new_df = spark.createDataFrame(new_data, columns)
# Append the new data to the Delta table with schema evolution enabled:
new_df.write.format("delta") \
.mode("append") \
.option("mergeSchema", "true") \
.save("/path/to/delta/table")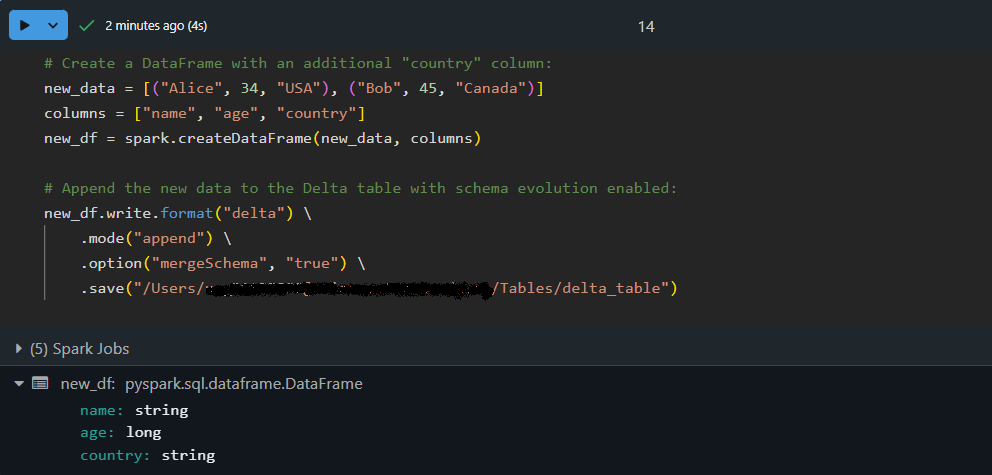
Aqui, o DataFrame new_df contém uma coluna extra, country. Ao usar option("mergeSchema", "true") , o mecanismo do Delta Lake atualiza automaticamente o esquema da tabela para acomodar a nova coluna e, ao mesmo tempo, anexar os dados com segurança!
As transações ACID do Delta Lake garantem que operações complexas sejam executadas de forma confiável, mesmo com alta simultaneidade. Isso significa que uma série de operações (como atualizações e inserções) são tratadas como uma única unidade. Se alguma parte datransação falhar, nenhuma alteração será aplicada, garantindo que seus dados permaneçam consistentes.
Vamos executar uma transação atômica com uma operação MERGE:
-- Execute a MERGE statement in SQL to update or insert data atomically:
MERGE INTO delta./path/to/delta/table AS target
USING (SELECT 'Alice' AS name, 35 AS age, 'USA' AS country) AS source
ON target.name = source.name AND target.country IS NULL
WHEN MATCHED THEN
UPDATE SET target.age = source.age, target.country = source.country
WHEN NOT MATCHED THEN
INSERT (name, age, country) VALUES (source.name, source.age, source.country)
No exemplo acima, o comando MERGE procura linhas na tabela de destino em que o nome corresponde e o campo country é NULL. Se for encontrada uma correspondência, ele atualiza alinha ; caso contrário, insere um novo registro .
Observe que, mesmo que já exista uma linha para "Alice" na tabela, a condição target.country IS NULL pode fazer com que a operação insira uma nova linha em vez de atualizar uma com um país não nulo. Esse exemplo demonstra a importância de definir cuidadosamente os critérios de correspondência em operações transacionais.
Aqui estão as práticas recomendadas que sigo ao trabalhar com o Delta Lake. Eles podem ajudar você a criar pipelines de dados eficientes e passíveis de manutenção.
O particionamento de suas tabelas Delta pode melhorar significativamente o desempenho da consulta quando você lida com grandes conjuntos de dados. ao lidar com grandes conjuntos de dados.
Dica: Ao escrever seu DataFrame, use a opção .partitionBy("column_name") para dividir seus dados em partes menores e mais gerenciáveis (por exemplo, por data ou categoria). Essa abordagem reduz a quantidade de dados digitalizados durante asconsultas típicasdo site .
O Delta Lake usa um registro de transações ( _delta_log) para manter os metadados de todas as operações que você realiza na tabela. operações em sua tabela.
Dica: Programe operações de manutenção periódicas (como o comando VACUUM ) para remover arquivos de dados obsoletos e simplificar os metadados. Isso resulta em um desempenho de consulta mais rápido e em um gerenciamento mais fácil de grandes conjuntos de dados.
A ordenação em Z é uma técnica de agrupamento de dados que organiza os dados no disco para melhorar a eficiência da consulta, especialmente ao filtrar colunas específicas:
OPTIMIZE delta./path/to/delta/table
ZORDER BY (name, age);O comando SQL acima diz ao Delta Lake para reorganizar os dados fisicamente com base nas colunas name e age. Com a localização conjunta de valores semelhantes, as consultas que filtram essas colunas examinam menos dados e são executadas mais rapidamente.
Ao trabalhar com o Delta Lake, você pode ocasionalmente se deparar com obstáculos. A chave é tratar esses desafios como oportunidades para aprofundar seu conhecimento e dominar a tecnologia. Aqui estão alguns dos meus insights práticos e dicas para que você volte ao caminho certo.
Você pode encontrar problemas como incompatibilidades de esquema ou alinhamento de partição . Por exemplo, se os dados recebidos não corresponderem ao esquema da tabela, você poderá ver erros durante as operações de gravação. Considere o uso de opções como mergeSchema para permitir que o Delta Lake se ajuste.
Além disso, se o desempenho da consulta cair, verifique se os dados estão particionados de forma ideal ou se um comando de manutenção como VACUUM pode ajudar a remover arquivos obsoletos.
Quando as coisas não funcionarem conforme o esperado, não se preocupe - faz parte do processo! Uma ótima primeira etapa é inspecionar o log de transações (encontrado no diretório _delta_log ). Esse registro oferece um histórico detalhado das transações e pode ajudar você a identificar quando e onde as coisas saíram dos trilhos .
Além disso, se você notar inconsistências ou alterações inesperadas, tente usar a viagem no tempo para comparar diferentes versões da tabela. Essa abordagem ajudará você a isolar o problema e a entender os eventos que levaram ao erro.
O Delta Lake traz uma série de vantagens - desde transações ACID robustas e gerenciamento eficiente de metadados até recursos como viagem no tempo e evolução de esquema - que permitem que você crie pipelines de dados resilientes e dimensionáveis. Sua integração com o Apache Spark significa que o Delta Lake pode ser o complemento perfeito para otimizar seus fluxos de trabalho se você já tiver investido no ecossistema do Spark.
Para aqueles que desejam aprofundar seu conhecimento, incentivo você a explorar outros recursos no DataCamp:
Bom aprendizado e boa sorte em sua jornada de dados!
Saiba mais sobre engenharia de dados com estes cursos!
Programa
Curso
Curso
blog
Kurtis Pykes
7 min
blog
Tim Lu
12 min
blog
Bekhruz Tuychiev
15 min
Tutorial
Natassha Selvaraj
Tutorial
Abid Ali Awan
Tutorial
Kurtis Pykes


