Curso
Conceptos de almacenamiento de datos
4 h
48.5K
Este tutorial asume que los participantes tienen lo siguiente:
Los métodos de migración de datos incorporarán algunos servicios básicos de AWS, entre ellos
El curso Tecnología y servicios en la nube de AWS debería ayudarte a empezar si eres nuevo en AWS.
La mayor parte del procedimiento se realizará en la consola de administración de AWS. Sin embargo, los pasos cubiertos en el tutorial también pueden ejecutarse con la interfaz de línea de comandos (CLI) de AWS o con un kit de desarrollo de software (SDK) de AWS. Puedes realizar la migración de datos en el entorno de trabajo que elijas.
Al preparar la migración de datos, es importante tener en cuenta los componentes de las tablas de DynamoDB y en qué se diferencian de los de las bases de datos relacionales:
El tutorial utilizará una sencilla tabla Products para demostrar la migración de datos. A continuación se muestran los datos en formato JSON:
{
"product_id": "P001",
"category": "Electronics",
"price": 700,
"product_name": "Phone"
},
{
"product_id": "P002",
"category": "Electronics",
"description": "The laptop is a Macbook.",
"price": 1000,
"product_name": "Laptop"
}Hay que tener en cuenta dos hechos importantes:
product_id servirá como clave primaria.description.Estos datos se añaden a una tabla en DynamoDB como parte de la configuración.
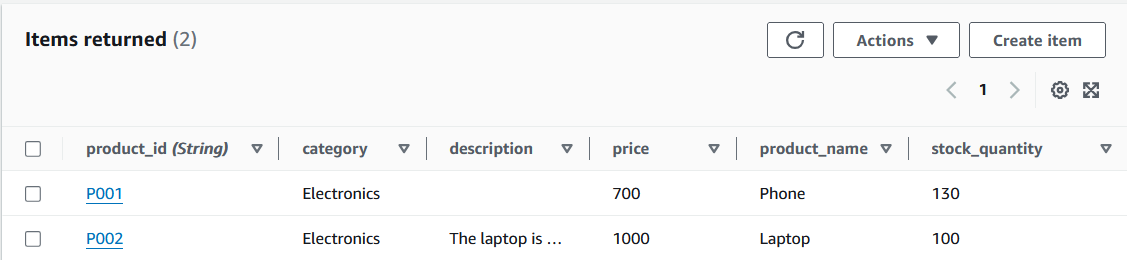
Elementos de la tabla DynamoDB. Imagen del autor
El siguiente paso es configurar una tabla en Redshift que recibirá los datos de la tabla de DynamoDB.
1. Ve a la consola de Redshift y selecciona "Crear clúster".
AWS permite a los usuarios definir varios parámetros antes de poner en marcha el clúster. Para el tutorial, se hará hincapié en los necesarios para facilitar la migración de datos.
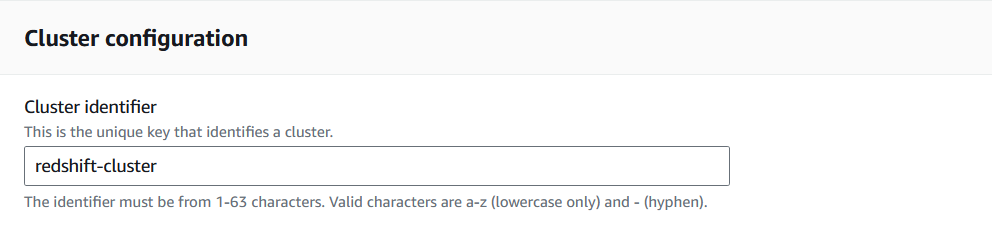
Creación de un clúster Redshift en la Consola Redshift. Imagen del autor
2. Selecciona el tipo de nodo y el número de nodos que se ajusten al volumen de datos que se van a analizar.
Para migrar la tabla Products, puedes utilizar una capacidad mínima de CPU y disponer de un solo nodo.
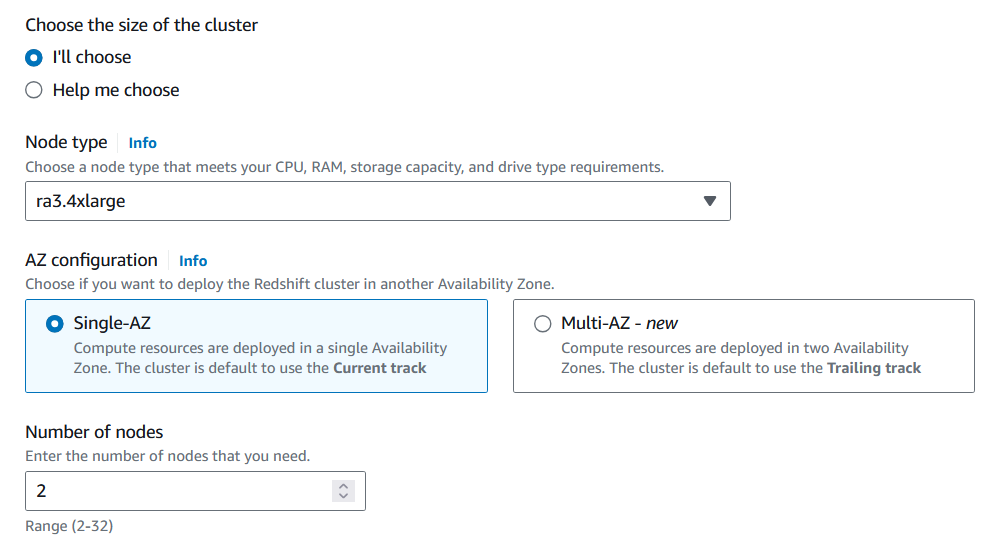
Personalizar la configuración del clúster Redshift. Imagen del autor
3. Elige el nombre de usuario y la contraseña de administrador para este cluster.
Guarda las credenciales en un lugar seguro, ya que serán necesarias para acceder a este clúster a través de otros servicios de AWS.
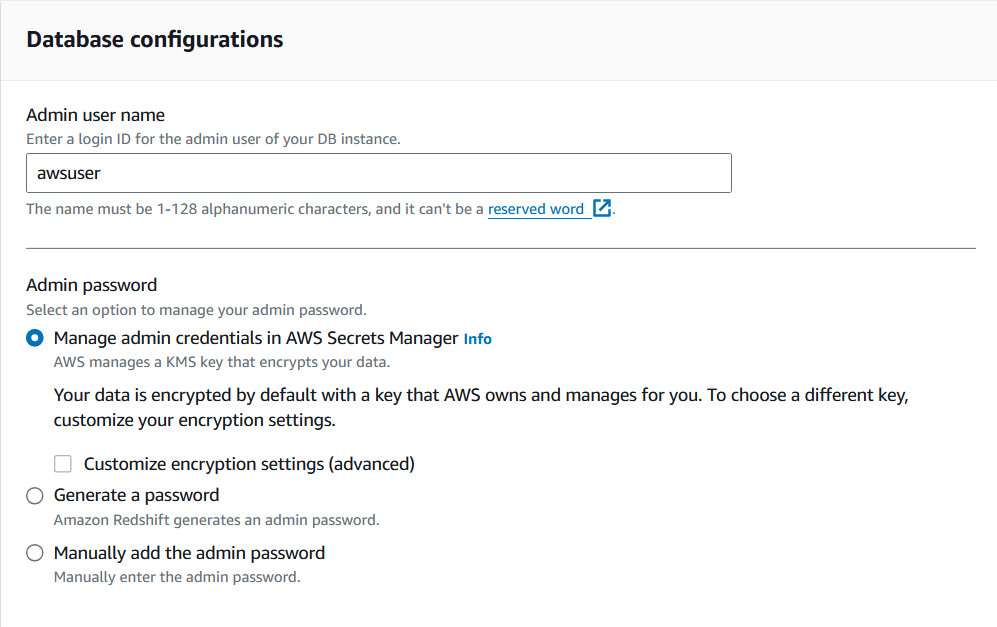
Personalizar la configuración del clúster Redshift. Imagen del autor
4. Por último, asigna un rol IAM al clúster.
El rol IAM necesitará políticas que permitan al clúster leer tablas de DynamoDB y crear tablas en Redshift.

Asignar un rol IAM al cluster Redshift. Imagen del autor
5. Una vez creado el clúster, ve al editor de consultas y crea la tabla que albergará los datos de la tabla DynamoDB mediante el comando CREATE:
CREATE TABLE Products (
product_id VARCHAR(50) PRIMARY KEY,
category VARCHAR(50),
description VARCHAR(100),
price INT,
product_name VARCHAR(50),
stock_quantity INT
);Modifica el comando anterior en función de los datos de interés y ten en cuenta las restricciones adicionales que pueda ser necesario aplicar.
Eso es. Estás listo para empezar a transferir datos.
Amazon Redshift ofrece el comando COPIAR, que introduce datos de una determinada fuente de datos de AWS en una tabla.
1. Ejecuta la migración de datos utilizando el comando COPY.
La sintaxis del comando es la siguiente:
COPY <table_name>
FROM <dynamo_db_table_path>
IAM_ROLE 'arn:aws:iam::<aws-account-id>:role/<role-name>'
REGION <region_name>';Para añadir datos de la tabla Productos de DynamoDB a la tabla Productos de Redshift, el comando puede modificarse de la siguiente manera
COPY Products
FROM 'dynamodb://Products'
IAM_ROLE 'arn:aws:iam::<1234567890>:role/<dynamo_db_redshift_role>'
REGION ‘us-east-1’El comando COPY es uno de los métodos más sencillos para mover datos de DynamoDB a Redshift. Requiere una configuración mínima, y su facilidad de uso lo hace especialmente accesible para quienes tienen menos experiencia en la construcción de canalizaciones ETL.
Además, como la transferencia de datos se realiza directamente, no es necesario incorporar otros servicios de AWS.
El principal inconveniente de este método es que los usuarios no pueden configurar cómo se asignan los atributos de la tabla DynamoDB a los campos de la tabla Redshift. Esta falta de flexibilidad hace posible que el comando COPY omita erróneamente o asigne de forma inexacta campos de la tabla de Redshift.
Además, dado que el comando transfiere todos los datos en un lote, esta operación puede resultar ineficaz si algunos registros ya se han transferido previamente a Redshift. Este planteamiento daría lugar a transferencias de datos redundantes para tales escenarios, aumentando el tiempo de procesamiento y los costes de almacenamiento.
AWS Glue es un servicio diseñado para crear canalizaciones de extracción, transformación y carga (ETL). Los usuarios pueden transferir datos de DynamoDB a Redshift creando un trabajo ETL.
Si eres nuevo en Glue, considera la posibilidad de seguir el tutorial Introducción a AWS Glue.
En esta guía, leeremos la tabla Products en DynamoDB, almacenaremos los resultados en un bucket S3 como archivo CSV y, a continuación, enviaremos esos datos a la tabla Products en Redshift.
1. Ve a la consola de S3 y crea un bucket para alojar el archivo CSV.

Consola AWS S3. Imagen del autor
2. Navega hasta la consola de AWS Glue y, en el panel de la izquierda, selecciona "Trabajos ETL" para comenzar a crear tu trabajo.

Consola AWS Glue. Imagen del autor
3. Selecciona el modo para crear un trabajo ETL.
AWS ofrece tres modos de creación de empleo: ETL visual, Cuaderno y Editor de scripts. Cada modo se adapta a distintos niveles de experiencia, permitiendo a los usuarios elegir su método preferido, ya sea una interfaz de arrastrar y soltar (ETL Visual), un entorno de desarrollo interactivo (Cuaderno) o codificación en bruto (Editor de Script).
Los trabajos de cola pueden codificarse manualmente utilizando Python o Spark. Para los que dominan menos estos lenguajes, ETL Visual es una opción adecuada, ya que permite a los usuarios configurar sus trabajos con sólo hacer clic.
El trabajo Glue de este tutorial se escribirá en un editor de código en Python, pero para los interesados en la opción ETL Visual, consulta la documentación de AWS.
4. Asigna un rol IAM a este trabajo.
El rol IAM necesitará acceso a DynamoDB, Redshift y S3 para que este tutorial se ejecute correctamente.
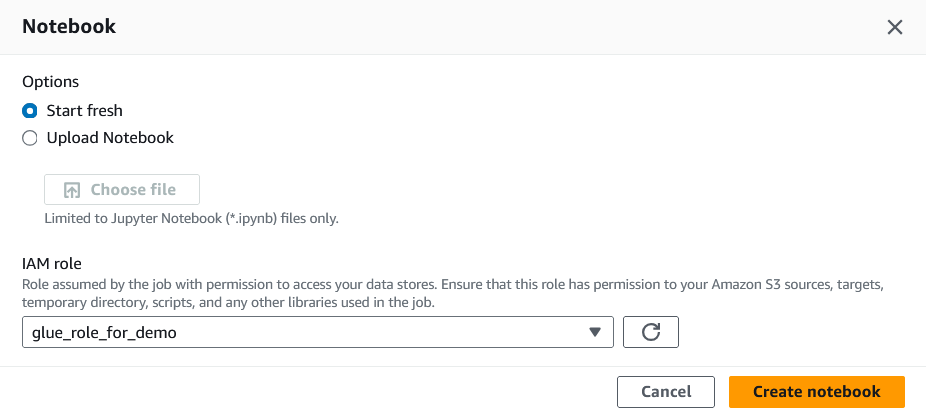
Asignar un rol IAM al trabajo Glue. Imagen del autor
5. Tras crear el trabajo, pasa a la pestaña "Detalles del trabajo" y rellena las propiedades básicas.
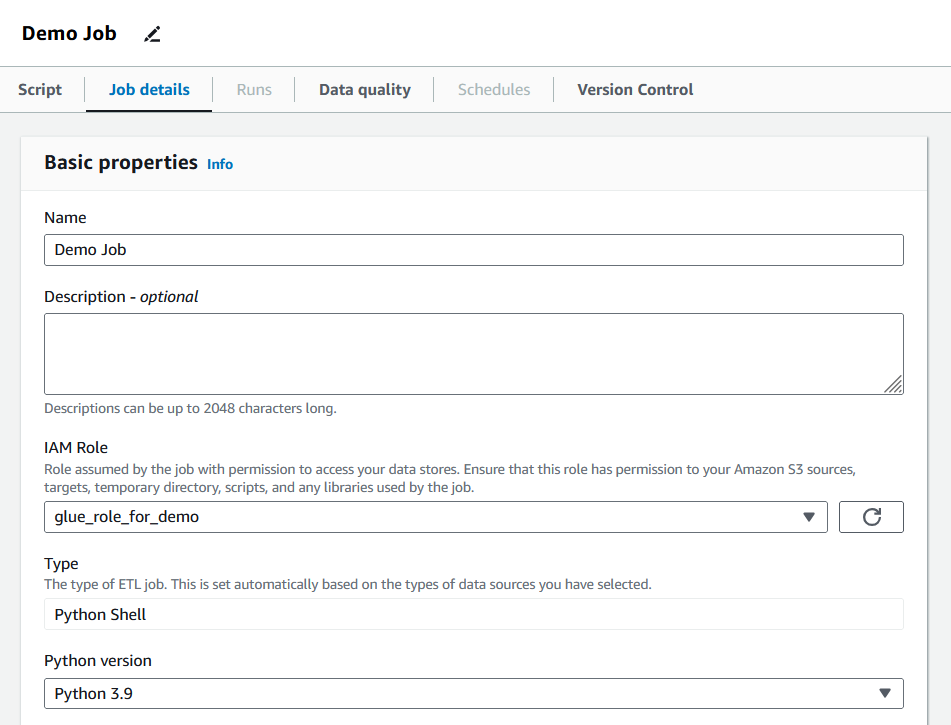
Detalles del trabajo de Pegamento de Relleno. Imagen del autor
En esta sección, los usuarios pueden definir las unidades de proceso de datos (DPU) asignadas, el número de reintentos y el periodo de tiempo de espera del trabajo. El trabajo de este tutorial mantendrá los valores por defecto, pero se recomienda que los usuarios ajusten estos parámetros para que se adapten a las necesidades del trabajo en cuestión.
6. Cambia a la pestaña "Guión" y escribe tu lógica.
El trabajo ETL que migra los datos de la tabla Products ejecutará el siguiente código:
import boto3
import csv
import time
import os
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.context import SparkContext
from awsglue.utils import getResolvedOptions
import sys
# initialize Glue context
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# initialize DynamoDB client and scan the table
dynamodb = boto3.client('dynamodb', region_name=os.getenv('AWS_REGION'))
response = dynamodb.scan(TableName=os.getenv('DYNAMODB_TABLE'))
# extract and write data to a CSV file
items = response['Items']
csv_file = '/tmp/products.csv'
# write each row in the table
with open(csv_file, mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['product_id', 'category', 'description', 'product_name', 'stock_quantity', 'price'])
for item in items:
writer.writerow([
item.get('product_id', {}).get('S', ''),
item.get('category', {}).get('S', ''),
item.get('description', {}).get('S', ''),
item.get('product_name', {}).get('S', ''),
item.get('stock_quantity', {}).get('N', 0),
item.get('price', {}).get('N', 0)
])
# upload the csv file to S3
s3 = boto3.client('s3', region_name=os.getenv('AWS_REGION'))
bucket_name = os.getenv('S3_BUCKET_NAME')
s3_key = 'products/products.csv'
s3.upload_file(csv_file, bucket_name, s3_key)
# wait for the file to upload before continuing
time.sleep(10)
# load data into Redshift using the COPY command
redshift = boto3.client('redshift', region_name=os.getenv('AWS_REGION'))
copy_command = f"""
COPY Products FROM 's3://{bucket_name}/{s3_key}'
IAM_ROLE 'arn:aws:iam::{os.getenv('AWS_ACCOUNT_ID')}:role/{os.getenv('REDSHIFT_ROLE')}'
FORMAT AS CSV
IGNOREHEADER 1;
"""
cluster_id = os.getenv('REDSHIFT_CLUSTER_ID')
database = os.getenv('REDSHIFT_DATABASE')
db_user = os.getenv('REDSHIFT_DB_USER')
# execute the copy statement
response = redshift.execute_statement(
ClusterIdentifier=cluster_id,
Database=database,
DbUser=db_user,
Sql=copy_command
)
# Commit the job
job.commit()Vamos a desglosar paso a paso lo que consigue este script:
awsglue para preparar el trabajo para su ejecuciónboto3, el SDK de Python para AWSboto3COPY que inserte los datos del archivo CSV en la tabla RedshiftNota: El fragmento de código de ejemplo describe una forma de facilitar la migración de datos. AWS Glue promueve la flexibilidad, ofreciendo múltiples formas de construir una canalización ETL. Así, los usuarios pueden crear un trabajo específicamente adaptado a sus necesidades.
7. Una vez escrito el código, guarda los cambios y pulsa el botón "Ejecutar" para ejecutar el trabajo.
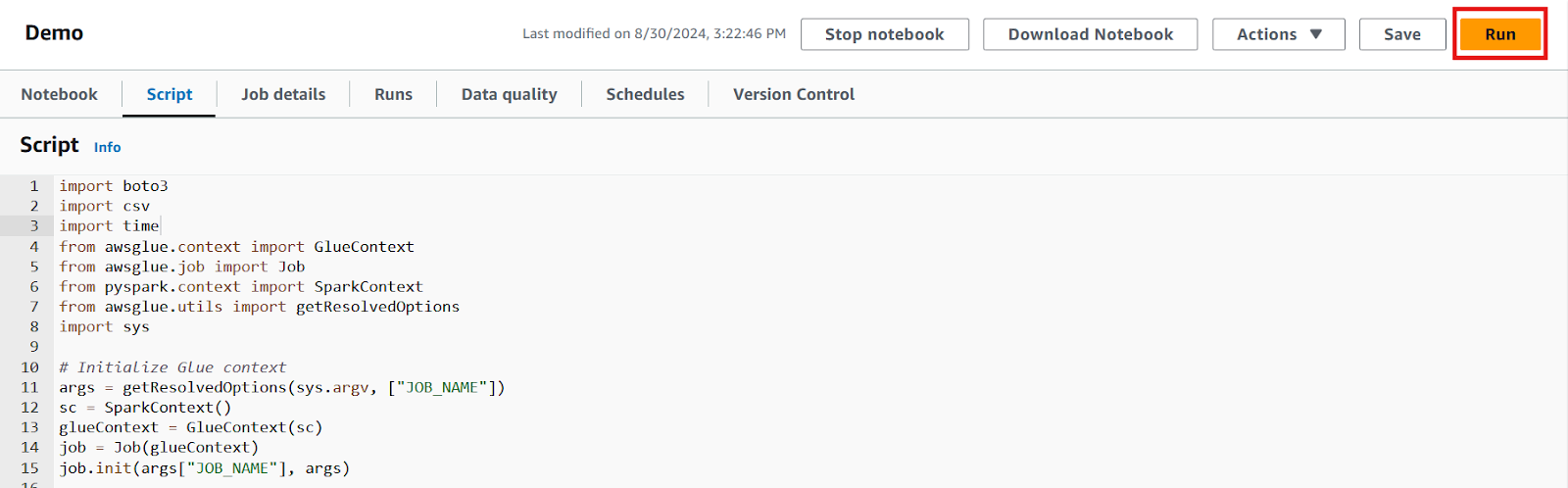
Editor de guiones para el trabajo Pegamento. Imagen del autor
8. Controla el progreso del trabajo en la pestaña "Ejecuciones", donde se mostrará cualquier error o problema.
Comprueba el estado del trabajo y revisa los registros para asegurarte de que todo se ha ejecutado como se esperaba.

Pestaña Ejecuciones de Pegamento AWS mostrando un trabajo completado. Imagen del autor
Una vez que el trabajo se ha realizado correctamente, puede ejecutarse bajo demanda o programarse según sea necesario, haciendo que tu proceso de migración de datos sea más eficaz y automatizado.
AWS Glue ofrece amplias opciones de personalización, lo que permite a los usuarios adaptar sus trabajos a sus necesidades. También ofrece programar estos trabajos a intervalos periódicos (por ejemplo, diariamente), lo que permite su automatización. Además, Glue está integrado con muchos otros servicios, lo que facilita las interacciones con fuentes de datos distintas de DynamoDB si es necesario.
Configurar un trabajo ETL en Glue suele exigir esfuerzo y tiempo de configuración. Aunque no es obligatorio tener conocimientos de programación para utilizar este servicio, sería necesario aprovechar ciertas características que ofrece Glue, como la biblioteca AWSGlue y un SDK.
Además, es poco probable que las tareas de Pegamento se ejecuten correctamente al primer intento, por lo que los usuarios deben estar preparados para dedicar tiempo a solucionar problemas. Por último, los trabajos de encolado pueden acumular costes rápidamente si no se gestionan adecuadamente, por lo que es esencial aprovisionar sólo los recursos necesarios.
DynamoDB Streams es una función que rastrea los cambios realizados en las tablas de DynamoDB en tiempo real. Al aprovechar DynamoDB Streams, los usuarios pueden actualizar automáticamente su tabla Redshift cada vez que se realice un cambio en la fuente de datos en DynamoDB.
Lee la documentación de AWS para obtener más información sobre cómo utilizar DynamoDB Streams.
Esta solución requerirá acceso a AWS DynamoDB, Redshift y Lambda. En este enfoque, se activará una función Lambda cuando se añada o modifique un elemento en la tabla Products de DynamoDB.
Estos son los pasos:
1. Ve a la consola Lambda y selecciona "Crear función".

Consola AWS Lamba. Imagen del autor
2. Proporciona la información básica de la función, incluyendo el lenguaje de programación y el rol IAM.
El rol debe tener acceso a Lambda, DynamoDB y Redshift.
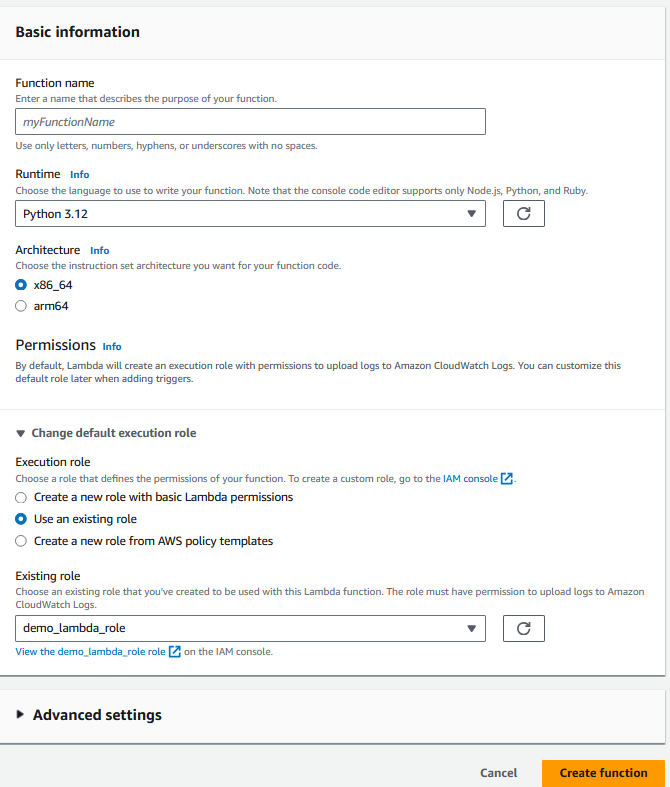
Configurar la función Lambda. Imagen del autor
3. Tras crear la función, añade la tabla DynamoDB (la tabla Products en nuestro caso) como desencadenante.
Ahora el diagrama debería tener el siguiente aspecto:
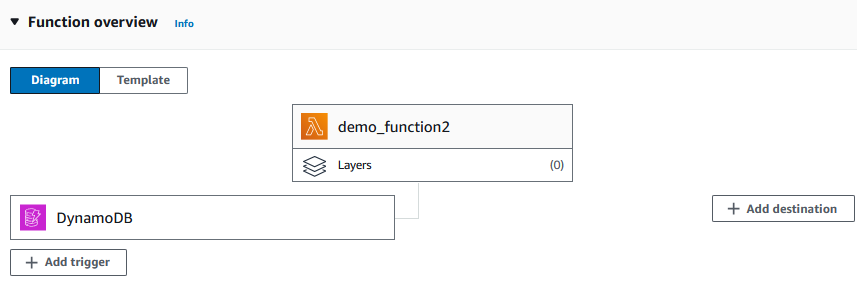
Añadir un activador a la función Lambda. Imagen del autor
4. Cambia a la pestaña de configuración y asigna la cantidad necesaria de memoria y tiempo de ejecución para la función, ya que los valores por defecto suelen ser insuficientes.

Configurar el activador de la función Lambda. Imagen del autor
5. En la pestaña "Código", escribe la lógica de la migración de datos en el idioma que elijas.
El siguiente fragmento es un ejemplo de cómo puede ser una función Lambda en Python:
import boto3
import os
import json
def lambda_handler(event, context):
# Initialize the Redshift Data API client
redshift_client = boto3.client('redshift-data')
# Redshift cluster details
cluster_id = os.environ['REDSHIFT_CLUSTER_ID']
database = os.environ['REDSHIFT_DB_NAME']
user = os.environ['REDSHIFT_USER']
# IAM role ARN that has access to Redshift Data API
role_arn = os.environ['REDSHIFT_ROLE_ARN']
# Process DynamoDB stream records
for record in event['Records']:
if record['eventName'] in ['INSERT', 'MODIFY']:
new_image = record['dynamodb']['NewImage']
product_id = new_image['product_id']['S']
category = new_image['category']['S']
description = new_image['description']['S']
price = float(new_image['price']['N'])
product_name = new_image['product_name']['S']
stock_quantity = int(new_image['stock_quantity']['N'])
# SQL query to insert data into Redshift
query = f"""
INSERT INTO products (product_id, category, description, price, product_name, stock_quantity)
VALUES ('{product_id}', '{category}', '{description}', {price}, '{product_name}', {stock_quantity});
"""
# Execute the query using Redshift Data API
response = redshift_client.execute_statement(
ClusterIdentifier=cluster_id,
Database=database,
DbUser=user,
Sql=query
)
# Log the statement ID for tracking
print(f'Started SQL statement with ID: {response["Id"]}')
return {
'statusCode': 200,
'body': 'SQL statements executed successfully'
}En términos sencillos, la función lee el registro de elementos añadidos o modificados registrados por DynamoDB Streams y los aplica a la tabla de Redshift ejecutando una consulta SQL con un cliente API de Redshift.
Por seguridad, los valores clave (por ejemplo, el ID del clúster de Redshift) se almacenan en variables de entorno en lugar de codificarse en el script.
Obtén más información sobre el uso de variables de entorno en Lambda en la documentación de AWS.
6. Una vez terminado el código, despliega la función y pruébala para comprobar si hay algún error.
Dependiendo del caso de uso, valdría la pena diseñar tus propios casos de prueba para la función.
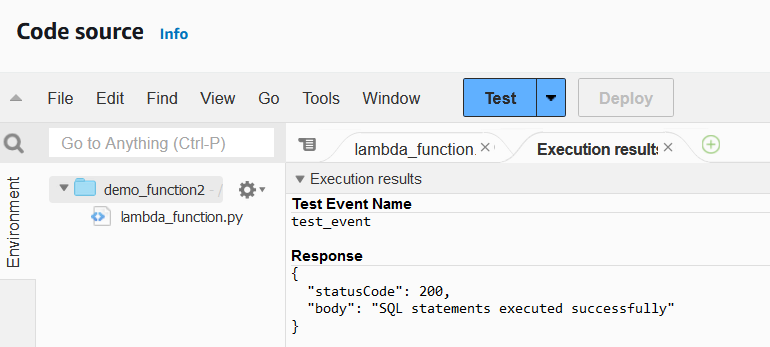
Función lambda ejecutando resultados. Imagen del autor
Cuando la función Lambda esté operativa, tendremos que configurar la tabla DynamoDB para que ejecute esta función cada vez que se añada o modifique un elemento de la tabla.
7. Selecciona la tabla DynamoDB y pasa a la pestaña "Exportaciones y flujos".

Consola DynamoDB Pestaña Exportaciones y flujos. Imagen del autor
8. Desplázate hasta los detalles del flujo de DynamoDB y selecciona "Activar".
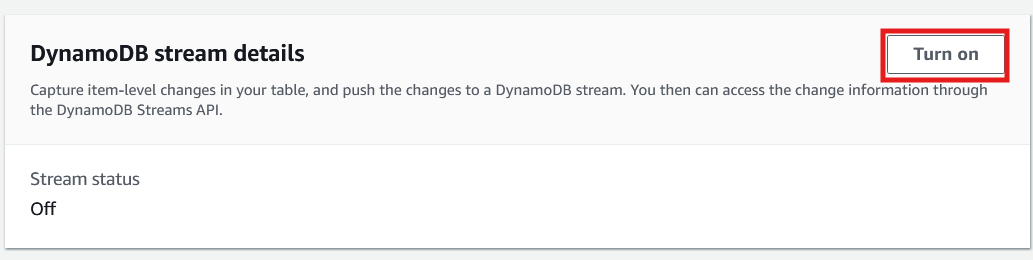
Consola DynamoDB Pestaña Exportaciones y flujos. Imagen del autor
9. Cuando se te solicite, selecciona el tipo de información que debe registrarse en los Streams de DynamoDB.
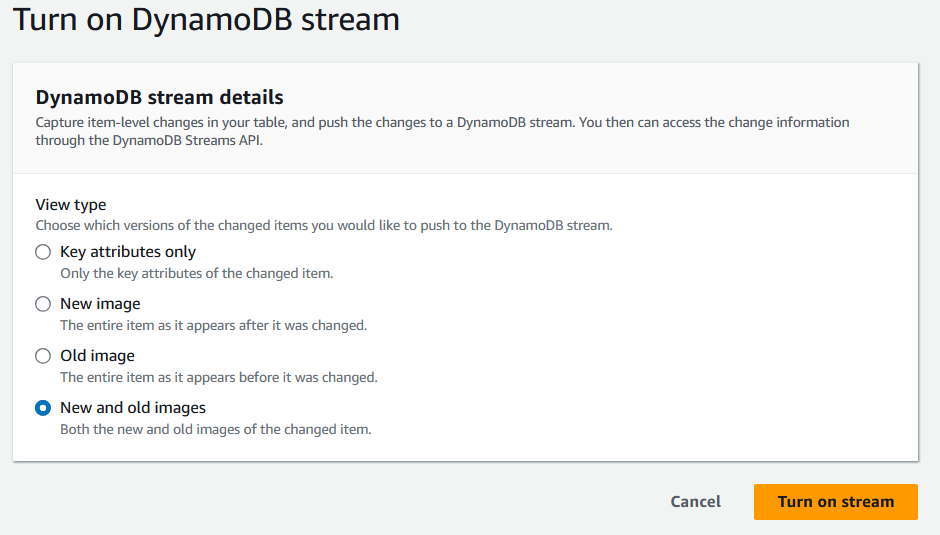
Pantalla de detalles del flujo DynamoDB. Imagen del autor
10. Después de activar el flujo, desplázate hacia abajo en la misma página para crear el activador.
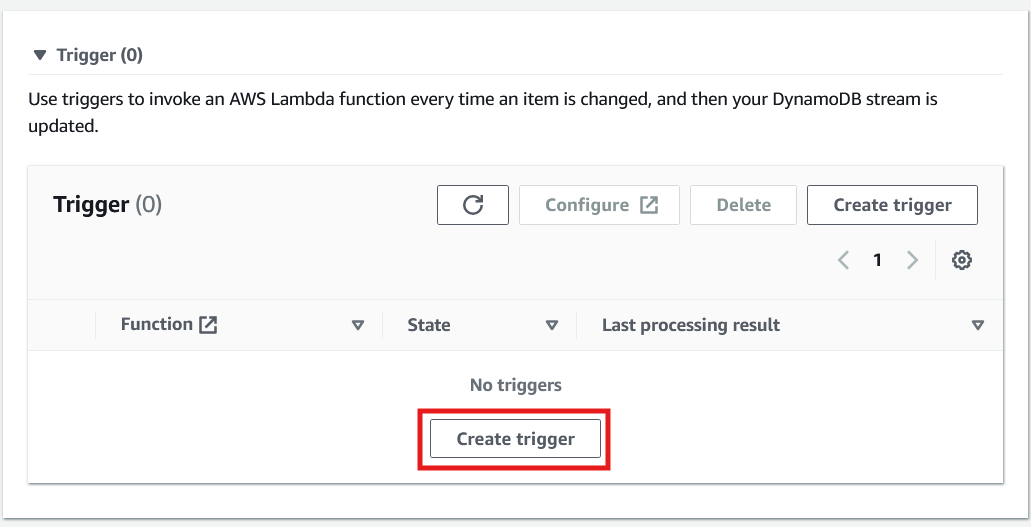
Creación de un activador para invocar una función Lambda en DynamoDB. Imagen del autor
11. Por último, al configurar el activador, selecciona la función Lambda que se ha creado antes de seleccionar "Crear activador".
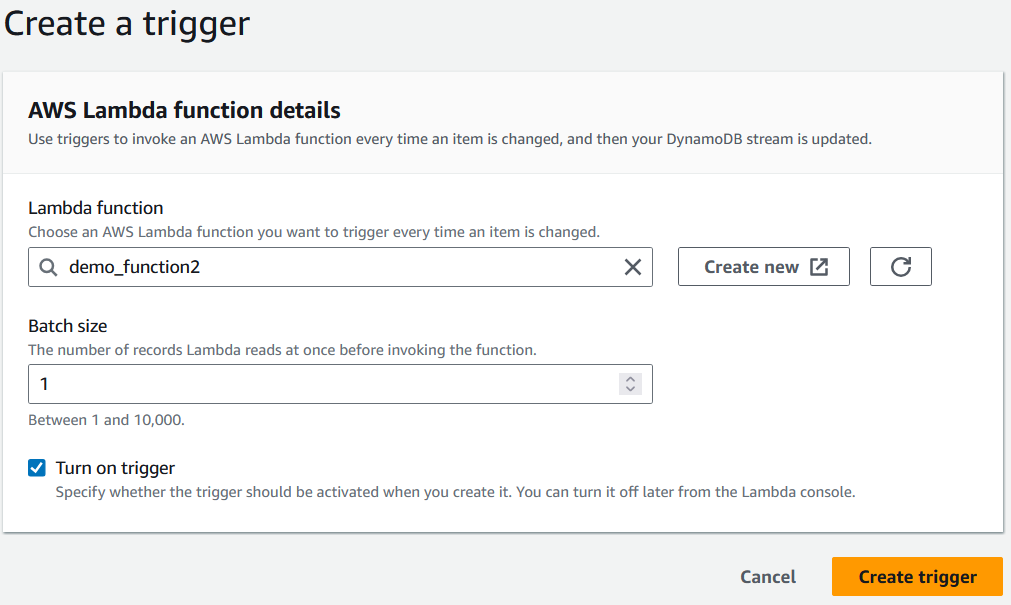
Seleccionar una función Lambda para activar. Imagen del autor
La implementación de esta solución aplicará automáticamente cualquier cambio realizado en la tabla de DynamoDB a la tabla en Redshift, garantizando la coherencia de los datos en tiempo real.
Los flujos de DynamoDB crean una sincronización en tiempo real entre DynamoDB y Redshift. Esto permite a los usuarios mantener actualizadas sus tablas Redshift sin intervención manual.
Así, las tablas de Redshift pueden actualizarse con frecuencia, lo que puede, a su vez, potenciar aplicaciones que requieren un alto rendimiento de los datos (por ejemplo, cuadros de mando en tiempo real). Esta solución también reduce el riesgo de error humano en cada iteración.
Configurar esta solución requiere configurar varios servicios de AWS, lo que puede llevar mucho tiempo.
Dado que Lambda es una herramienta de Función como Servicio (FaaS), los usuarios necesitarán un buen dominio de un lenguaje de programación. Además, como cada iteración de sincronización de datos requiere varias llamadas a la API, el coste total puede acumularse rápidamente, sobre todo con actualizaciones frecuentes. Por último, esta solución es más viable para pequeños cambios en las tablas de Redshift que para migraciones de tablas completas.
La validación de los datos es un paso esencial después de crear la solución de migración de datos. Incluso cuando los servicios de AWS funcionan sin problemas, podría haber errores en el proceso de migración que no se tienen en cuenta. Estos problemas pueden derivarse de discrepancias lógicas, asignación incorrecta de atributos o transferencias de datos incompletas.
Los datos migrados deben estar libres de cualquiera de estos errores para que cualquier análisis posterior en Redshift tenga éxito.
Esta sección explora algunas comprobaciones y técnicas para examinar los datos migrados, utilizando como ejemplo la tabla Products.
Asegúrate de que todas las columnas de la tabla de DynamoDB están presentes en la tabla de Redshift y de que se les han asignado los tipos de datos correctos.
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = Products;Confirma que se ha completado la transferencia de datos comparando el recuento de filas de la tabla de Redshift con el de la fuente de datos.
SELECT COUNT(*) FROM your_table_name;Una alternativa a identificar las columnas y los tipos de datos sería simplemente previsualizar los datos. Los usuarios pueden hojear la vista previa para detectar cualquier discrepancia o anomalía.
SELECT product_id, category, price FROM your_table_name LIMIT 5;Validar los datos creando vistas previas o realizando recuentos no es suficiente para todos los conjuntos de datos. Cuando sea necesario evaluar los datos en función de criterios más complejos, los usuarios pueden crear vistas.
Por ejemplo, supongamos que la mesa Products nunca debe tener pocas existencias de productos electrónicos. Este resultado puede controlarse mediante la siguiente consulta.
CREATE OR REPLACE VIEW low_stock_electronics AS
SELECT
Product_id, product_name, category, stock_quantity, price,
FROM
your_table_name
WHERE
stock_quantity < 50 AND
Category = ‘Electronics;Optimizar el rendimiento de las consultas es esencial para extraer información de los conocimientos de forma eficaz y a bajo coste. Escribir consultas que conserven memoria y reduzcan el tiempo de ejecución será especialmente importante a medida que el conjunto de datos aumente de tamaño con cada migración.
Esta sección explora algunos métodos para mejorar la optimización de las consultas, utilizando como referencia la tabla Products.
En Redshift, las claves de distribución determinan cómo se distribuyen los datos entre las notas de un clúster. Seleccionar la clave de distribución adecuada en una tabla puede reducir el tiempo de ejecución de las consultas.
Por ejemplo, si la tabla Products se va a unir con otras tablas en el campo product_id, sería beneficioso utilizar product_id como clave de distribución al crear la tabla.
CREATE TABLE products (
product_id VARCHAR(100),
category VARCHAR(100),
description VARCHAR(100),
price INT,
stock_quantity INT
)
DISTKEY(product_id);Seleccionar la clave de ordenación adecuada refuerza las operaciones SQL habituales, como los filtros y las uniones. En Redshift, los usuarios pueden seleccionar manualmente una clave de ordenación o hacer que se seleccione una clave de ordenación por ellos. Las claves de ordenación se dividen en dos categorías: claves de ordenación compuestas y claves de ordenación intercaladas. La mejor clave de ordenación depende de las consultas que haya que realizar sobre los datos.
CREATE TABLE products (
product_id VARCHAR(100),
category VARCHAR(100),
description VARCHAR(100),
price INT,
stock_quantity INT
)
COMPOUND SORTKEY(category, product_id);Para más información sobre las claves de clasificación, visita la documentación de AWS.
La compresión consiste en codificar los datos dados con menos bits. El resultado es una tabla que utiliza menos espacio de almacenamiento, pero conserva toda la información.
Para quienes no estén seguros de qué tipo de compresión es mejor para sus datos, Redshift puede realizar un análisis de compresión para encontrar la mejor codificación para cada campo con el siguiente comando:
ANALYZE COMPRESSION <table_name>;La migración de datos de DynamoDB a Redshift permite a los usuarios aprovechar las capacidades OLAP de Redshift para realizar análisis de datos más complejos.
Este tutorial explora tres métodos de migración diferentes, cada uno con ventajas e inconvenientes únicos.Al seleccionar el mejor enfoque, evalúa cuidadosamente tus necesidades de análisis, las limitaciones de los datos y las consideraciones presupuestarias para garantizar la solución más eficaz para tu caso de uso específico.
Un gran paso siguiente es empezar el curso Introducción a Redshift, para aprender o refrescar conceptos básicos. El curso de Gestión de Costes y Seguridad de AWS es otra gran alternativa para aprender conceptos que cualquier persona que trabaje con AWS debería dominar.
Nuestros programas de certificación te ayudan a destacar y a demostrar que tus aptitudes están preparadas para el trabajo a posibles empleadores.

¡Aprende más sobre AWS y la ingeniería de datos con estos cursos!
Curso
Curso
Curso
blog
Mike Shakhomirov
11 min
blog
Joleen Bothma
12 min
blog
DataCamp Team
12 min
Tutorial
Tim Lu
Tutorial
Oluseye Jeremiah