Curso
Conceitos de Data Warehousing
4 h
48.4K
Este tutorial pressupõe que os participantes tenham o seguinte:
Os métodos de migração de dados incorporarão alguns serviços essenciais da AWS, incluindo:
O curso AWS Cloud Technology and Services deve ajudá-lo a começar se você for novo no AWS.
A maior parte do procedimento será realizada no console de gerenciamento do AWS. No entanto, as etapas abordadas no tutorial também podem ser executadas com a interface de linha de comando (CLI) do AWS ou com um kit de desenvolvimento de software (SDK) do AWS. Você pode realizar a migração de dados no ambiente de trabalho de sua escolha.
Ao se preparar para a migração de dados, é importante considerar os componentes das tabelas do DynamoDB e como elas diferem das dos bancos de dados relacionais:
O tutorial usará uma tabela Products simples para demonstrar a migração de dados. A seguir, você verá os dados no formato JSON:
{
"product_id": "P001",
"category": "Electronics",
"price": 700,
"product_name": "Phone"
},
{
"product_id": "P002",
"category": "Electronics",
"description": "The laptop is a Macbook.",
"price": 1000,
"product_name": "Laptop"
}Há dois fatos importantes a serem observados:
product_id servirá como chave primária.description.Esses dados são adicionados a uma tabela no DynamoDB como parte da configuração.
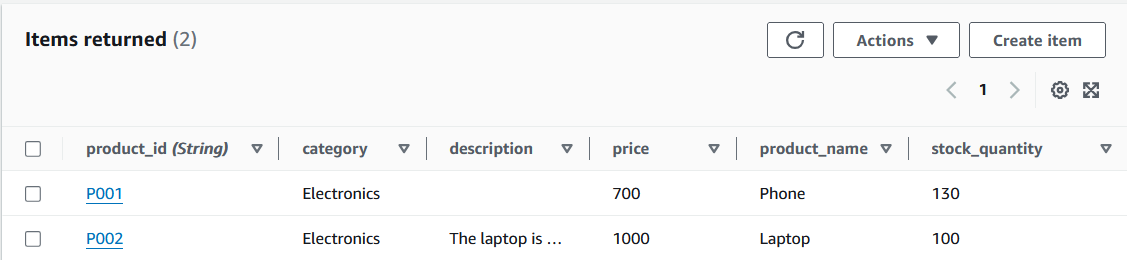
Itens da tabela DynamoDB. Imagem do autor
A próxima etapa é configurar uma tabela no Redshift que receberá os dados na tabela do DynamoDB.
1. Vá para o console do Redshift e selecione "Criar cluster".
O AWS permite que os usuários definam vários parâmetros antes de iniciar o cluster. Para o tutorial, a ênfase será colocada naqueles necessários para facilitar a migração de dados.
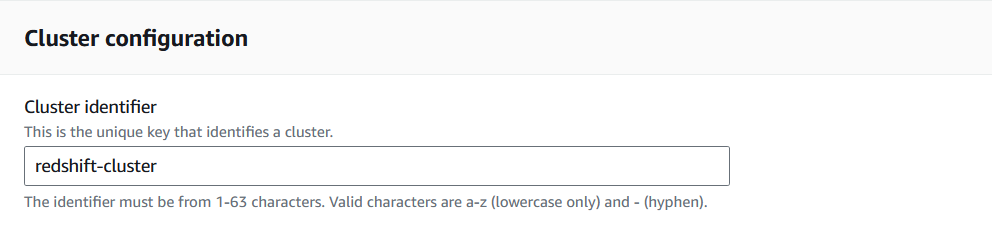
Criando um cluster do Redshift no Console do Redshift. Imagem do autor
2. Selecione o tipo de nó e o número de nós que se adequam ao volume de dados que será analisado.
Para migrar a tabela Products, você pode utilizar a capacidade mínima da CPU e ter apenas um nó.
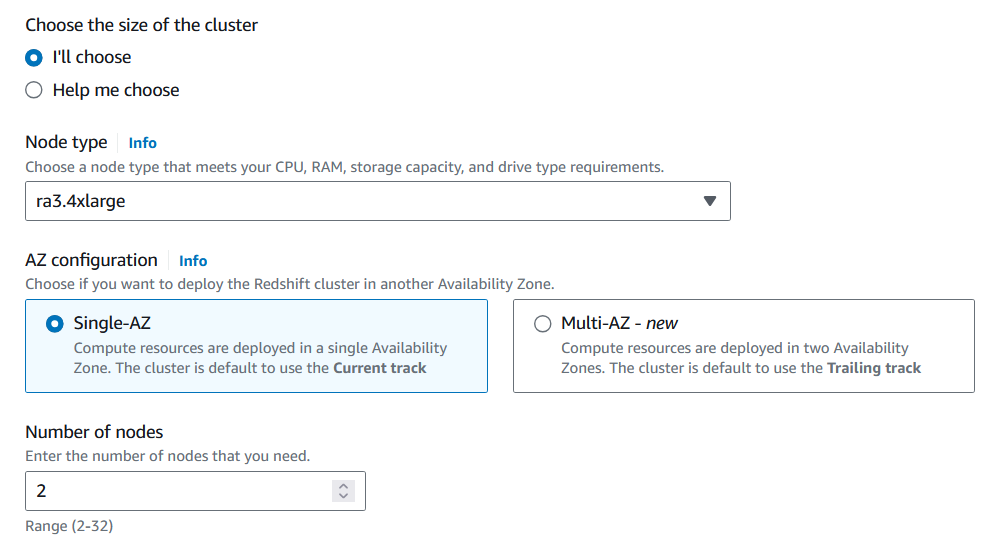
Personalizando a configuração do cluster do Redshift. Imagem do autor
3. Escolha o nome de usuário e a senha do administrador para esse cluster.
Armazene as credenciais em um local seguro, pois elas serão necessárias para acessar esse cluster por meio de outros serviços do AWS.
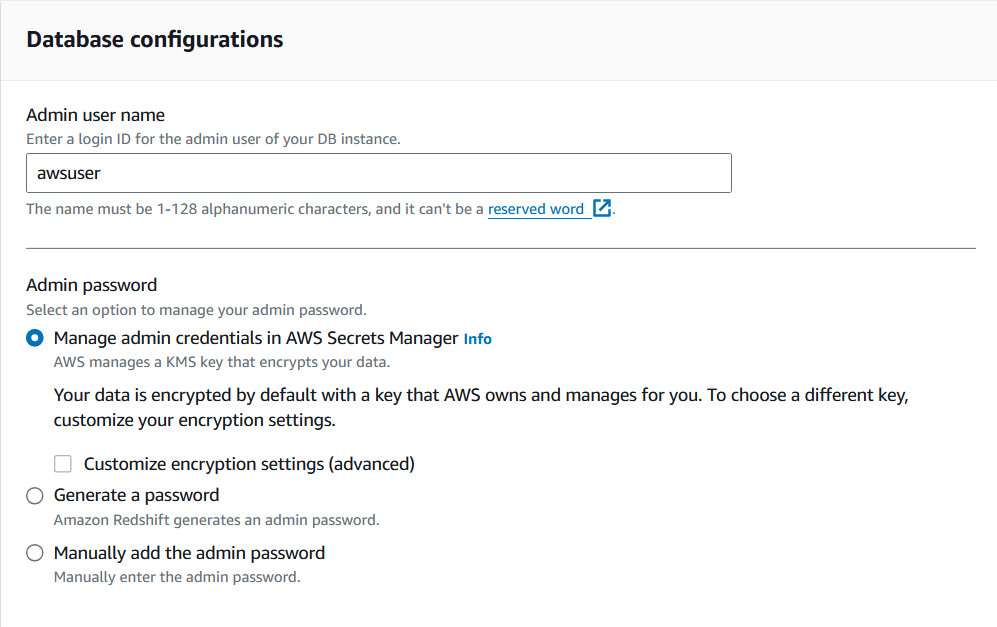
Personalizando a configuração do cluster do Redshift. Imagem do autor
4. Por fim, atribua uma função de IAM ao cluster.
A função IAM precisará de políticas que permitam que o cluster leia tabelas do DynamoDB e crie tabelas no Redshift.

Atribuir uma função de IAM ao cluster do Redshift. Imagem do autor
5. Depois que o cluster for criado, vá para o editor de consultas e crie a tabela que abrigará os dados da tabela do DynamoDB usando o comando CREATE:
CREATE TABLE Products (
product_id VARCHAR(50) PRIMARY KEY,
category VARCHAR(50),
description VARCHAR(100),
price INT,
product_name VARCHAR(50),
stock_quantity INT
);Modifique o comando acima com base nos dados de interesse e considere as restrições adicionais que podem precisar ser aplicadas.
É isso aí! Você está pronto para iniciar a transferência de dados.
O Amazon Redshift oferece o comando COPY, que insere dados de uma determinada fonte de dados do AWS em uma tabela.
1. Execute a migração de dados usando o comando COPY.
A sintaxe do comando é a seguinte:
COPY <table_name>
FROM <dynamo_db_table_path>
IAM_ROLE 'arn:aws:iam::<aws-account-id>:role/<role-name>'
REGION <region_name>';Para adicionar dados da tabela Products no DynamoDB à tabela Products no Redshift, o comando pode ser alterado para o seguinte:
COPY Products
FROM 'dynamodb://Products'
IAM_ROLE 'arn:aws:iam::<1234567890>:role/<dynamo_db_redshift_role>'
REGION ‘us-east-1’O comando COPY é um dos métodos mais simples para mover dados do DynamoDB para o Redshift. Ele exige uma configuração mínima e sua facilidade de uso o torna particularmente acessível para aqueles com menos experiência na criação de pipelines de ETL.
Além disso, como a transferência de dados é feita diretamente, não há necessidade de incorporar outros serviços do AWS.
A principal desvantagem desse método é que os usuários não podem configurar como os atributos na tabela do DynamoDB são mapeados para os campos na tabela do Redshift. Essa falta de flexibilidade permite que o comando COPY omita erroneamente ou mapeie de forma imprecisa os campos na tabela do Redshift.
Além disso, como o comando transfere todos os dados em um lote, essa operação pode ser ineficiente se alguns registros já tiverem sido transferidos para o Redshift anteriormente. Essa abordagem produziria transferências de dados redundantes para esses cenários, aumentando o tempo de processamento e os custos de armazenamento.
O AWS Glue é um serviço projetado para criar pipelines de extração, transformação e carregamento (ETL). Os usuários podem transferir dados do DynamoDB para o Redshift criando um trabalho de ETL.
Se você não conhece o Glue, considere seguir o tutorial Getting Started with AWS Glue.
Neste guia, leremos a tabela Products no DynamoDB, armazenaremos os resultados em um bucket S3 como um arquivo CSV e, em seguida, enviaremos esses dados para a tabela Products no Redshift.
1. Vá para o console do S3 e crie um bucket para armazenar o arquivo CSV.

Console do AWS S3. Imagem do autor
2. Navegue até o console do AWS Glue e, no painel esquerdo, selecione "ETL jobs" para começar a criar seu trabalho.

Console do AWS Glue. Imagem do autor
3. Selecione o modo de criação de um trabalho de ETL.
A AWS oferece três modos de criação de empregos: Visual ETL, Notebook e editor de scripts. Cada modo atende a diferentes níveis de especialização, permitindo que os usuários escolham seu método preferido, seja uma interface de arrastar e soltar (Visual ETL), um ambiente de desenvolvimento interativo (Notebook) ou codificação bruta (Script Editor).
Os trabalhos do Glue podem ser codificados manualmente usando Python ou Spark. Para aqueles com menos proficiência nessas linguagens, o Visual ETL é uma opção adequada, pois permite que os usuários configurem seus trabalhos apenas com um clique.
O trabalho do Glue neste tutorial será escrito em um editor de código em Python, mas se você estiver interessado na opção Visual ETL, consulte a documentação do AWS.
4. Atribua uma função de IAM a esse trabalho.
A função IAM precisará acessar o DynamoDB, o Redshift e o S3 para que este tutorial seja executado com êxito.
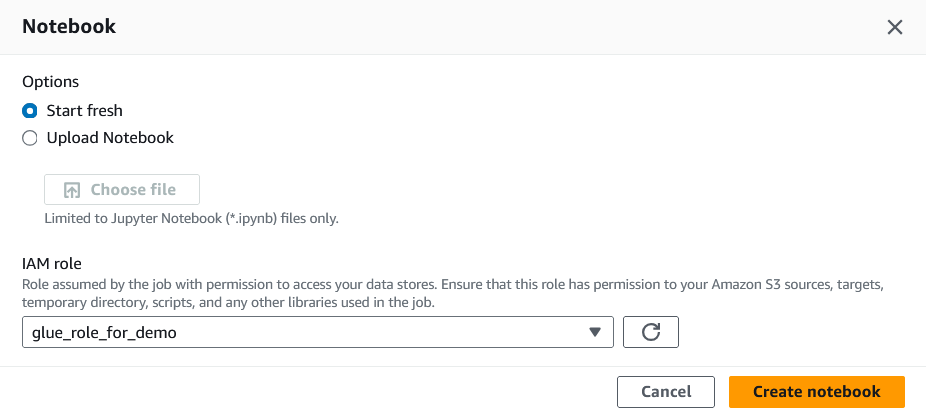
Atribuição de uma função IAM ao trabalho Glue. Imagem do autor
5. Depois de criar o trabalho, vá para a guia "Job details" (Detalhes do trabalho) e preencha as propriedades básicas.
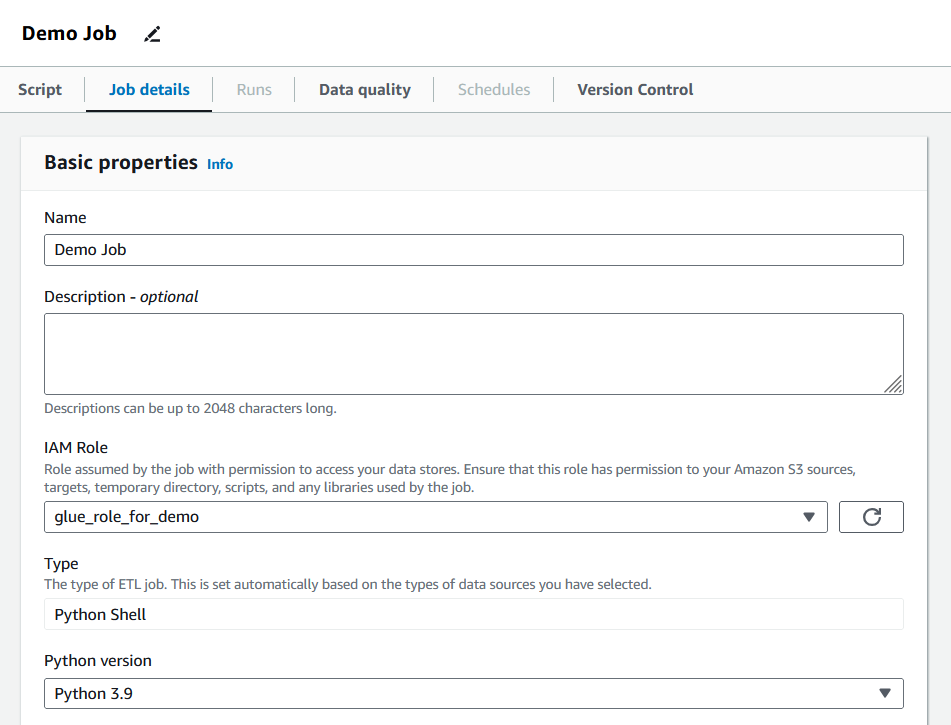
Detalhes do trabalho de preenchimento de cola. Imagem do autor
Nessa seção, os usuários podem definir as unidades de processamento de dados (DPUs) alocadas, o número de novas tentativas e o período de tempo limite do trabalho. O trabalho para este tutorial manterá os valores padrão, mas é recomendável que os usuários ajustem esses parâmetros para atender às necessidades do trabalho em questão.
6. Vá para a guia "Script" e escreva sua lógica.
O trabalho de ETL que migra os dados da tabela Products executará o seguinte código:
import boto3
import csv
import time
import os
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.context import SparkContext
from awsglue.utils import getResolvedOptions
import sys
# initialize Glue context
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# initialize DynamoDB client and scan the table
dynamodb = boto3.client('dynamodb', region_name=os.getenv('AWS_REGION'))
response = dynamodb.scan(TableName=os.getenv('DYNAMODB_TABLE'))
# extract and write data to a CSV file
items = response['Items']
csv_file = '/tmp/products.csv'
# write each row in the table
with open(csv_file, mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['product_id', 'category', 'description', 'product_name', 'stock_quantity', 'price'])
for item in items:
writer.writerow([
item.get('product_id', {}).get('S', ''),
item.get('category', {}).get('S', ''),
item.get('description', {}).get('S', ''),
item.get('product_name', {}).get('S', ''),
item.get('stock_quantity', {}).get('N', 0),
item.get('price', {}).get('N', 0)
])
# upload the csv file to S3
s3 = boto3.client('s3', region_name=os.getenv('AWS_REGION'))
bucket_name = os.getenv('S3_BUCKET_NAME')
s3_key = 'products/products.csv'
s3.upload_file(csv_file, bucket_name, s3_key)
# wait for the file to upload before continuing
time.sleep(10)
# load data into Redshift using the COPY command
redshift = boto3.client('redshift', region_name=os.getenv('AWS_REGION'))
copy_command = f"""
COPY Products FROM 's3://{bucket_name}/{s3_key}'
IAM_ROLE 'arn:aws:iam::{os.getenv('AWS_ACCOUNT_ID')}:role/{os.getenv('REDSHIFT_ROLE')}'
FORMAT AS CSV
IGNOREHEADER 1;
"""
cluster_id = os.getenv('REDSHIFT_CLUSTER_ID')
database = os.getenv('REDSHIFT_DATABASE')
db_user = os.getenv('REDSHIFT_DB_USER')
# execute the copy statement
response = redshift.execute_statement(
ClusterIdentifier=cluster_id,
Database=database,
DbUser=db_user,
Sql=copy_command
)
# Commit the job
job.commit()Vamos detalhar o que esse script realiza passo a passo:
awsglue para configurar o trabalho para execuçãoboto3, o SDK do Python para AWSboto3COPY que insira os dados do arquivo CSV na tabela do Redshift.Observação: O trecho de código de exemplo descreve uma maneira de facilitar a migração de dados. O AWS Glue promove a flexibilidade, oferecendo várias maneiras de criar um pipeline de ETL. Assim, os usuários podem criar um trabalho especificamente adaptado às suas necessidades.
7. Depois que o código for escrito, salve as alterações e clique no botão "Run" (Executar) para executar o trabalho.
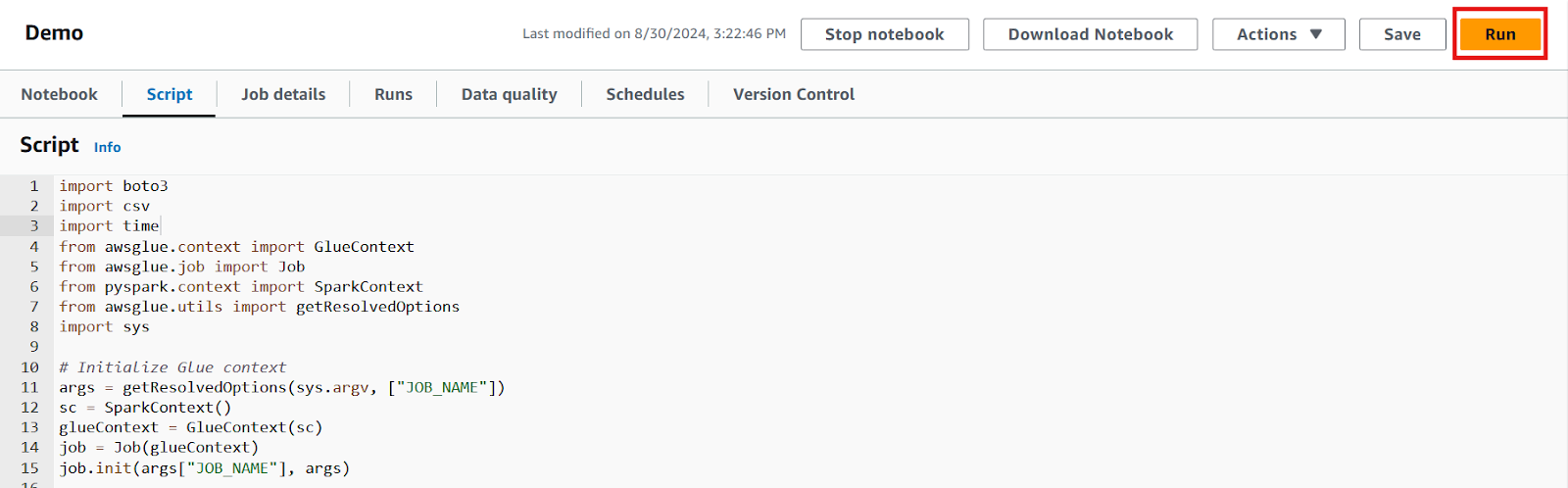
Editor de scripts para o trabalho Glue. Imagem do autor
8. Monitore o progresso do trabalho na guia "Runs" (Execuções), onde todos os erros ou problemas serão exibidos.
Verifique o status do trabalho e examine os registros para garantir que tudo foi executado conforme o esperado.

A guia AWS Glue Runs mostrando um trabalho concluído. Imagem do autor
Quando o trabalho for bem-sucedido, ele poderá ser executado sob demanda ou programado conforme necessário, tornando o processo de migração de dados mais eficiente e automatizado.
O AWS Glue oferece amplas opções de personalização, permitindo que os usuários personalizem seus trabalhos para atender às suas necessidades. Ele também oferece a possibilidade de agendar esses trabalhos em intervalos periódicos (por exemplo, diariamente), permitindo a automação. Além disso, o Glue está integrado a muitos outros serviços, facilitando as interações com outras fontes de dados além do DynamoDB, se necessário.
A configuração de um trabalho de ETL no Glue geralmente exige esforço e tempo de configuração. Embora o conhecimento de programação não seja obrigatório para usar esse serviço, você precisará aproveitar determinados recursos oferecidos pelo Glue, como a biblioteca AWSGlue e um SDK.
Além disso, é improvável que os trabalhos do Glue sejam executados com êxito na primeira tentativa, portanto, os usuários devem estar preparados para passar algum tempo solucionando problemas. Por fim, os trabalhos de colagem podem acumular custos rapidamente se não forem gerenciados adequadamente, o que torna essencial que você forneça apenas os recursos necessários.
O DynamoDB Streams é um recurso que rastreia as alterações feitas nas tabelas do DynamoDB em tempo real. Ao aproveitar o DynamoDB Streams, os usuários podem atualizar automaticamente sua tabela Redshift sempre que uma alteração for feita na fonte de dados no DynamoDB.
Leia a documentação da AWS para obter mais informações sobre como usar o DynamoDB Streams.
Essa solução exigirá acesso ao AWS DynamoDB, Redshift e Lambda. Nessa abordagem, uma função Lambda será acionada quando um item for adicionado ou modificado na tabela Products no DynamoDB.
Aqui estão as etapas:
1. Vá para o console do Lambda e selecione "Criar função".

Console do AWS Lamba. Imagem do autor
2. Forneça as informações básicas da função, incluindo a linguagem de programação e a função do IAM.
A função deve ter acesso ao Lambda, DynamoDB e Redshift.
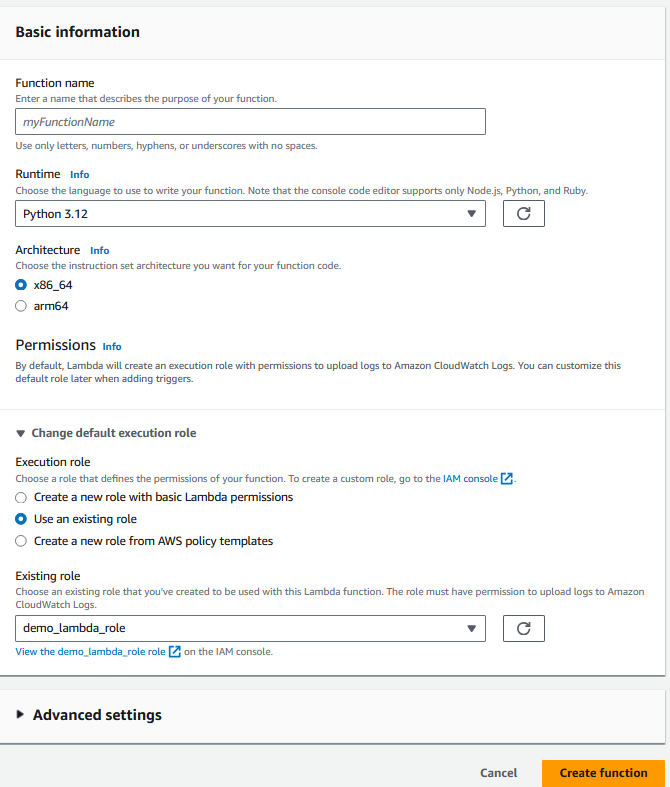
Configurando a função Lambda. Imagem do autor
3. Depois de criar a função, adicione a tabela do DynamoDB (a tabela Products, no nosso caso) como um acionador.
O diagrama agora deve se parecer com o seguinte:
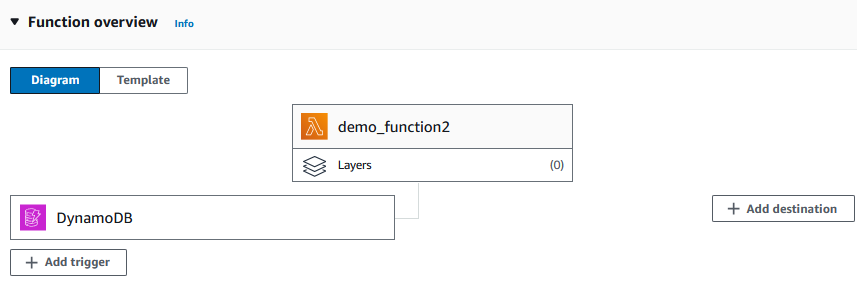
Adicionando um acionador à função Lambda. Imagem do autor
4. Vá para a guia de configuração e aloque a quantidade necessária de memória e tempo de execução para a função, pois os valores padrão geralmente são insuficientes.

Configurando o acionador para a função Lambda. Imagem do autor
5. Na guia "Code" (Código), escreva a lógica para a migração de dados no idioma que você escolher.
O trecho a seguir é um exemplo de como pode ser uma função Lambda em Python:
import boto3
import os
import json
def lambda_handler(event, context):
# Initialize the Redshift Data API client
redshift_client = boto3.client('redshift-data')
# Redshift cluster details
cluster_id = os.environ['REDSHIFT_CLUSTER_ID']
database = os.environ['REDSHIFT_DB_NAME']
user = os.environ['REDSHIFT_USER']
# IAM role ARN that has access to Redshift Data API
role_arn = os.environ['REDSHIFT_ROLE_ARN']
# Process DynamoDB stream records
for record in event['Records']:
if record['eventName'] in ['INSERT', 'MODIFY']:
new_image = record['dynamodb']['NewImage']
product_id = new_image['product_id']['S']
category = new_image['category']['S']
description = new_image['description']['S']
price = float(new_image['price']['N'])
product_name = new_image['product_name']['S']
stock_quantity = int(new_image['stock_quantity']['N'])
# SQL query to insert data into Redshift
query = f"""
INSERT INTO products (product_id, category, description, price, product_name, stock_quantity)
VALUES ('{product_id}', '{category}', '{description}', {price}, '{product_name}', {stock_quantity});
"""
# Execute the query using Redshift Data API
response = redshift_client.execute_statement(
ClusterIdentifier=cluster_id,
Database=database,
DbUser=user,
Sql=query
)
# Log the statement ID for tracking
print(f'Started SQL statement with ID: {response["Id"]}')
return {
'statusCode': 200,
'body': 'SQL statements executed successfully'
}Em termos simples, a função lê o log de itens adicionados ou modificados registrados pelo DynamoDB Streams e os aplica à tabela do Redshift executando uma consulta SQL com um cliente da API do Redshift.
Por segurança, os valores-chave (por exemplo, o ID do cluster do Redshift) são armazenados em variáveis ambientais em vez de serem codificados no script.
Saiba mais sobre o uso de variáveis ambientais no Lambda na documentação do AWS.
6. Depois de concluir o código, implemente a função e teste-a para verificar se há erros.
Dependendo do caso de uso, valeria a pena você criar seus próprios casos de teste para a função.
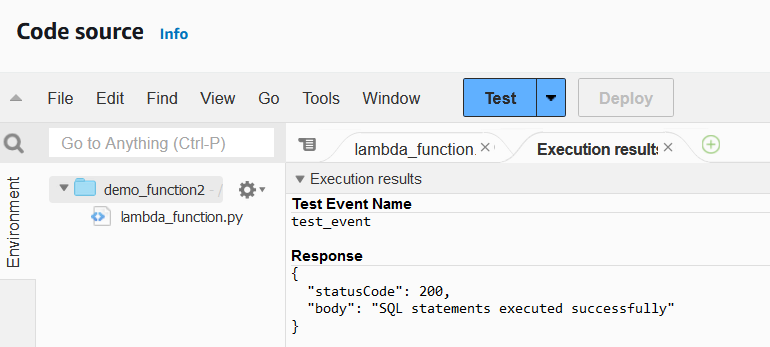
Função lambda executando resultados. Imagem do autor
Quando a função Lambda estiver operacional, precisaremos configurar a tabela do DynamoDB para executar essa função sempre que um item da tabela for adicionado ou modificado.
7. Selecione a tabela DynamoDB e mude para a guia "Exports and streams" (Exportações e fluxos).

Guia Exportações e fluxos do console do DynamoDB. Imagem do autor
8. Role para baixo até os detalhes do fluxo do DynamoDB e selecione "Ativar".
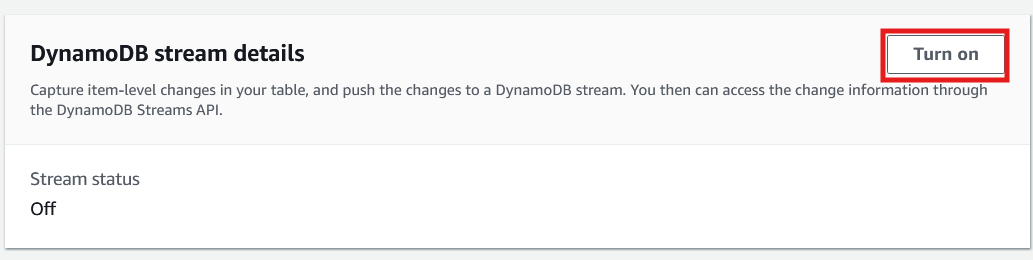
Guia Exportações e fluxos do console do DynamoDB. Imagem do autor
9. Quando solicitado, selecione o tipo de informação que deve ser registrada nos Streams do DynamoDB.
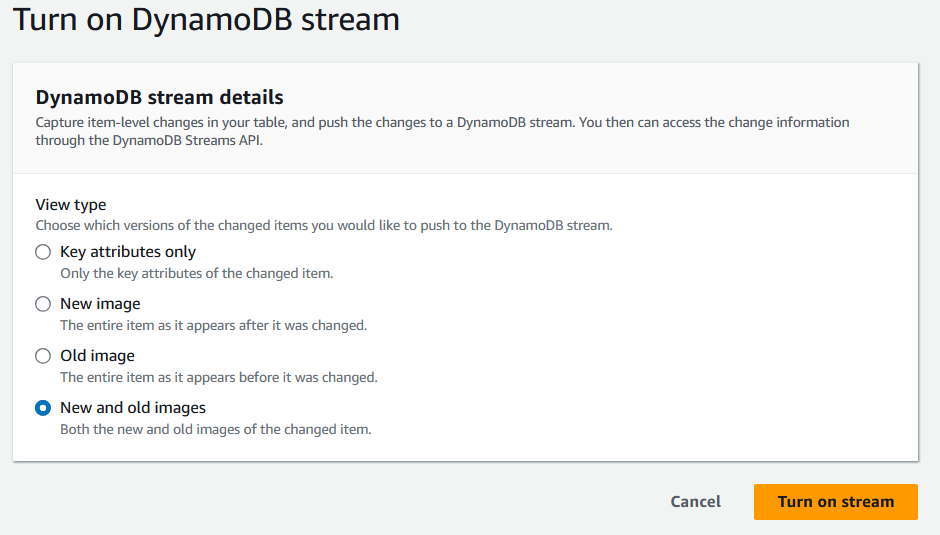
Tela de detalhes do fluxo do DynamoDB. Imagem do autor
10. Depois de ativar o fluxo, role a tela para baixo na mesma página para criar o acionador.
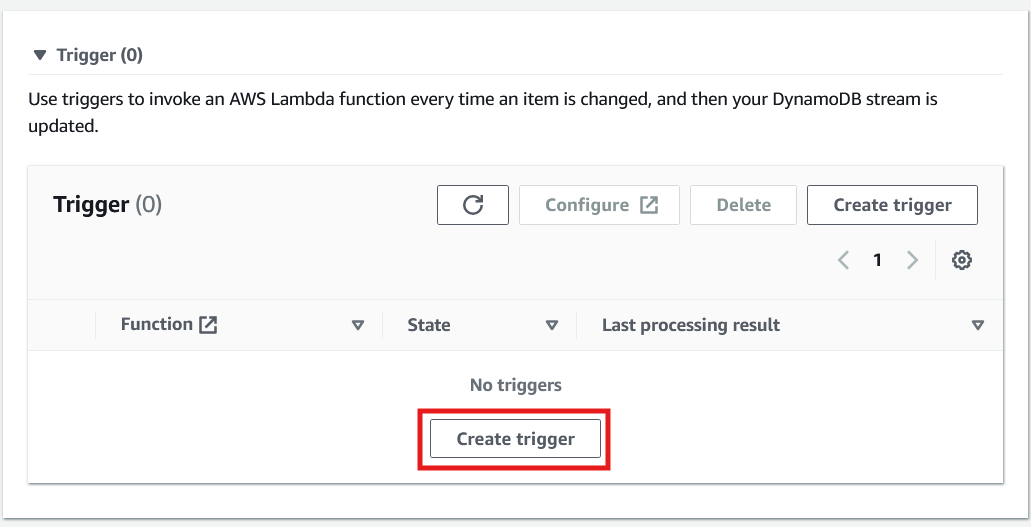
Criando um acionador para invocar uma função Lambda no DynamoDB. Imagem do autor
11. Por fim, ao configurar o acionador, selecione a função Lambda que foi criada antes de selecionar "Criar acionador".
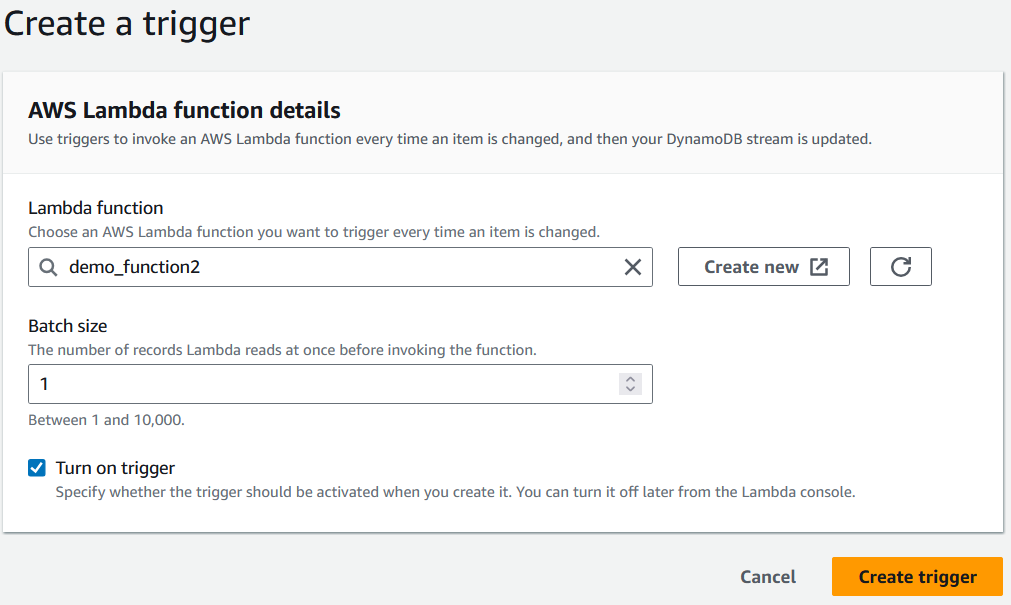
Selecionando uma função Lambda para acionar. Imagem do autor
A implementação dessa solução aplicará automaticamente todas as alterações feitas na tabela do DynamoDB à tabela no Redshift, garantindo a consistência dos dados em tempo real.
Os fluxos do DynamoDB criam sincronização em tempo real entre o DynamoDB e o Redshift. Isso permite que os usuários mantenham suas tabelas Redshift atualizadas sem intervenção manual.
Assim, as tabelas do Redshift podem ser atualizadas com frequência, o que, por sua vez, pode alimentar aplicativos que exigem alta taxa de transferência de dados (por exemplo, painéis de controle em tempo real). Essa solução também reduz o risco de erro humano em cada iteração.
A configuração dessa solução requer a configuração de vários serviços do AWS, o que pode consumir muito tempo.
Como o Lambda é uma ferramenta de função como serviço (FaaS), os usuários precisarão ter um bom domínio de uma linguagem de programação. Além disso, como cada iteração de sincronização de dados requer várias chamadas de API, o custo geral pode se acumular rapidamente, especialmente com atualizações frequentes. Por fim, essa solução é mais viável para alterações menores nas tabelas do Redshift do que para migrações de tabelas completas.
A validação de dados é uma etapa essencial após a criação da solução de migração de dados. Mesmo quando os serviços do AWS são executados sem problemas, ainda pode haver erros no processo de migração que não foram contabilizados. Esses problemas podem se originar de discrepâncias lógicas, mapeamento incorreto de atributos ou transferências de dados incompletas.
Os dados migrados devem estar livres de qualquer um desses erros para que as análises subsequentes no Redshift sejam bem-sucedidas.
Esta seção explora algumas verificações e técnicas para examinar os dados migrados, usando a tabela Products como exemplo.
Certifique-se de que todas as colunas da tabela do DynamoDB estejam presentes na tabela do Redshift e que tenham sido atribuídos a elas os tipos de dados corretos.
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_name = Products;Confirme que a transferência de dados foi concluída comparando a contagem de linhas na tabela do Redshift com a da fonte de dados.
SELECT COUNT(*) FROM your_table_name;Uma alternativa para identificar as colunas e os tipos de dados seria simplesmente visualizar os dados. Os usuários podem passar os olhos pela visualização para detectar discrepâncias ou anomalias.
SELECT product_id, category, price FROM your_table_name LIMIT 5;A validação de dados por meio da criação de visualizações ou da realização de contagens não é suficiente para todos os conjuntos de dados. Quando houver necessidade de avaliar dados com base em critérios mais complexos, os usuários poderão criar exibições.
Por exemplo, suponha que a tabela Products nunca deve ter um estoque baixo de produtos eletrônicos. Esse resultado pode ser monitorado usando a seguinte consulta.
CREATE OR REPLACE VIEW low_stock_electronics AS
SELECT
Product_id, product_name, category, stock_quantity, price,
FROM
your_table_name
WHERE
stock_quantity < 50 AND
Category = ‘Electronics;A otimização do desempenho da consulta é essencial para que você possa extrair insights de forma eficiente e com baixo custo. A criação de consultas que conservem a memória e reduzam o tempo de execução será especialmente importante à medida que o conjunto de dados aumentar a cada migração.
Esta seção explora alguns métodos para melhorar a otimização de consultas, usando a tabela Products como referência.
No Redshift, as chaves de distribuição determinam como os dados são distribuídos entre as anotações em um cluster. A seleção da chave de distribuição correta em uma tabela pode reduzir o tempo de execução das consultas.
Por exemplo, se a tabela Products tiver que ser unida a outras tabelas no campo product_id, seria vantajoso usar product_id como uma chave de distribuição ao criar a tabela.
CREATE TABLE products (
product_id VARCHAR(100),
category VARCHAR(100),
description VARCHAR(100),
price INT,
stock_quantity INT
)
DISTKEY(product_id);A seleção da chave de classificação correta reforça as operações SQL comuns, como filtros e uniões. No Redshift, os usuários podem selecionar manualmente uma chave de classificação ou ter uma chave de classificação selecionada para eles. As chaves de classificação são chamadas em duas categorias: chaves de classificação compostas e chaves de classificação intercaladas. A melhor chave de classificação depende das consultas que precisam ser executadas nos dados.
CREATE TABLE products (
product_id VARCHAR(100),
category VARCHAR(100),
description VARCHAR(100),
price INT,
stock_quantity INT
)
COMPOUND SORTKEY(category, product_id);Para obter mais informações sobre as chaves de classificação, visite a documentação da AWS.
A compactação implica a codificação dos dados fornecidos com menos bits. Isso resulta em uma tabela que usa menos armazenamento, mas ainda retém todas as informações.
Para aqueles que não têm certeza de qual tipo de compactação é melhor para seus dados, o Redshift pode realizar uma análise de compactação para encontrar a melhor codificação para cada campo com o seguinte comando:
ANALYZE COMPRESSION <table_name>;A migração de dados do DynamoDB para o Redshift permite que os usuários aproveitem os recursos OLAP do Redshift para análises de dados mais complexas.
Ao selecionar a melhor abordagem, avalie cuidadosamente suas necessidades de análise, limitações de dados e considerações orçamentárias para garantir a solução mais eficaz para seu caso de uso específico.
Uma ótima próxima etapa é iniciar o curso Introdução ao Redshift, para que você aprenda ou atualize os conceitos básicos. O curso AWS Security and Cost Management é outra ótima alternativa para você aprender conceitos que qualquer pessoa que trabalhe com a AWS deve dominar.
Nossos programas de certificação ajudam você a se destacar e a provar que suas habilidades estão prontas para o trabalho para possíveis empregadores.

Saiba mais sobre a AWS e a engenharia de dados com estes cursos!
Curso
Curso
Curso
blog
Mike Shakhomirov
11 min
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Tim Lu
Tutorial
Bex Tuychiev