
Curso
Creación de agentes de IA con Google ADK
1 h
6.5K
El equipo de Gemini ha presentado recientemente presentó Gemini 2.5 Computer Use, un modelo especializado que puede ver una pantalla en directo y actuar en ella haciendo clic, escribiendo, desplazándose y navegando por la web como un operador humano.
En esta guía, omitiremos los puntos de referencia abstractos y crearemos algo práctico. Una aplicación Streamlit que utiliza Computer Use para controlar un navegador real, buscar ofertas de empleo en Google, aplicar un filtro y exportar los resultados a CSV sin necesidad de API de búsqueda de terceros.
En este tutorial, aprenderás a:
Al final, tendrás un agente de búsqueda de empleo que seleccionará ofertas de trabajo adecuadas para ti.
Si deseas obtener más información sobre Gemini 2.5, te recomiendo que consultes nuestro tutorial de Gemini 2.5 Pro, que cubre características, pruebas, acceso, benchmarks y más.
Gemini 2.5 Computer Use es un modelo y una herramienta especializados (vista previa) de la API de Gemini que te permite crear agentes de control de navegador. En lugar de llamar a API específicas del sitio, el modelo funciona a partir de capturas de pantalla. Puede ver lo que hay en la página y luego actuar emitiendo acciones de interfaz de usuario como navigate, click_at, scroll_document, etc.
El código del cliente recibe esas acciones propuestas, las ejecuta y envía una nueva combinación de captura de pantalla y URL para que el modelo pueda decidir el siguiente paso.
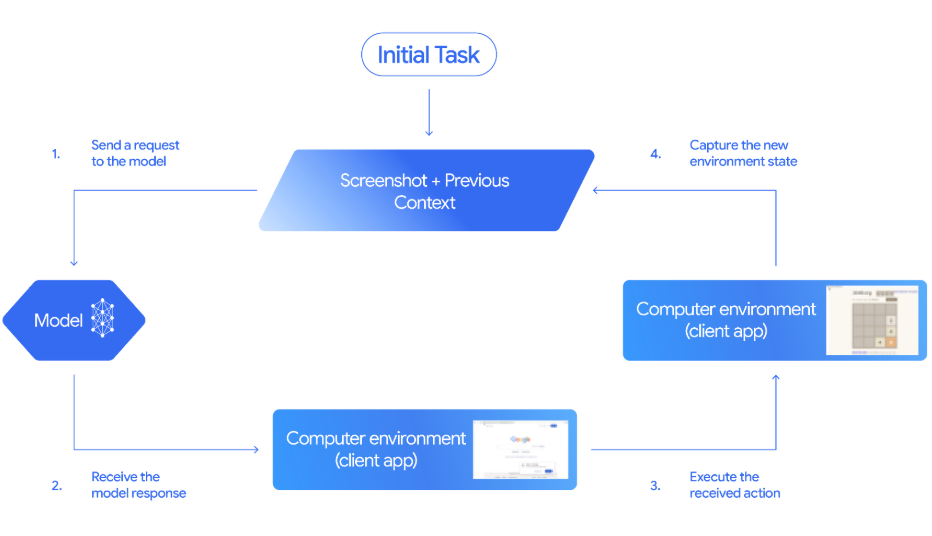
Fuente: Documentación de Gemini
Así es como funciona el bucle del agente anterior de principio a fin:
click_at o type_text_at) y una decisión de seguridad.FunctionResponse » que contiene una captura de pantalla nueva y la URL actual.see–decide–act–observe » hasta que se complete la tarea, se produzca un error o el usuario o el modelo decidan detenerlo.En esta sección, crearemos un agente de búsqueda de trabajos impulsado por Streamlitque maneja un navegador real usando Gemini 2.5 Computer Use y Playwright, y luego exporta los resultados a CSV.
Así es como funciona:
En segundo plano, la aplicación aplica una lista de dominios permitidos para garantizar una navegación segura, admite la confirmación humana opcional para pasos arriesgados y utiliza el bucle de uso del ordenador para facilitar la depuración.
Algunos casos de uso responsable y políticas del sitio incluyen:
En primer lugar, asegúrate de tener instaladas las siguientes importaciones:
python -m venv .venv && source .venv/bin/activate
pip install streamlit google-genai playwright python-dotenv
playwright install chromiumLos comandos anteriores configuran un entorno virtual e instalan todas las dependencias básicas necesarias para compilar la aplicación, a saber Streamlit para la interfaz de usuario, google-genai para llamar a la API de Gemini y Playwright para la automatización del navegador y python-dotenv para cargar variables de entorno y Chromium para Playwright.
Ahora que ya tenemos las dependencias instaladas, lo siguiente es configurar la clave API de Gemini desde AI Studio.
Ahora, crea un archivo .env en la carpeta de tu proyecto y añade ahí tu clave API:
GOOGLE_API_KEY=YOUR_REAL_KEY
ALLOWED_HOSTS=google.comEl paquete python-dotenv cargará GOOGLE_API_KEY en tiempo de ejecución para que la aplicación pueda llamar al modelo Gemini 2.5 Computer Use.
Ahora, preparémonos para el tiempo de ejecución, que incluye importaciones, constantes, ID de modelo y autenticación. Esto garantiza que la aplicación se comunique con Gemini y que la navegación se mantenga de forma segura dentro de un dominio incluido en la lista de permitidos.
import os, io, time, csv, base64, urllib.parse
from typing import List, Dict, Tuple
import streamlit as st
from dotenv import load_dotenv
from playwright.sync_api import sync_playwright
from google import genai
from google.genai import types
from google.genai.types import Content, Part
W, H = 1440, 900
MODEL = "gemini-2.5-computer-use-preview-10-2025"
load_dotenv()
API_KEY = os.getenv("GOOGLE_API_KEY")
if not API_KEY:
st.stop()
ALLOWED_HOSTS = {h.strip().lower() for h in os.getenv("ALLOWED_HOSTS", "google.com").split(",") if h.strip()}
client = genai.Client(api_key=API_KEY)Empezamos importando las bibliotecas principales, como Streamlit, Playwright, google-genai y pequeñas utilidades (dotenv, os, io, csv, time, urllib) para la configuración y la E/S.
Una ventana gráfica fija (W, H = 1440 × 900) mantiene la coherencia de las capturas de pantalla y la asignación de coordenadas para el uso del ordenador, y el modelo de vista previa se establece en gemini-2.5-computer-use-preview-10-2025.
La clave API se carga con load_dotenv() y os.getenv("GOOGLE_API_KEY"). La navegación se configura mediante una lista de permitidos (por defecto, google.com) por motivos de seguridad.
Por último, genai.Client(api_key=API_KEY) inicializa el SDK de Gemini para que la aplicación pueda ejecutar el bucle del agente y mostrar los resultados en Streamlit.
Antes de pasar al núcleo de la aplicación, necesitamos configurar algunas funciones auxiliares. Ayudáis con las comprobaciones de seguridad, coordináis la conversión, ejecutáis acciones para las llamadas de función de Gemini, extraéis datos de SERP y exportáis los resultados en formato CSV.
Empezamos añadiendo un asistente de backend que permite un control seguro del navegador. Esto incluye una función de verificación de la lista de dominios permitidos para restringir la navegación, una función de conversión de coordenadas para asignar la parilla 0-999 del modelo a la ventana gráfica fija y una función de distribución de acciones que interpreta las llamadas a la función Computer Use y las ejecuta a través de Playwright.
def host_allowed(url: str) -> bool:
try:
netloc = urllib.parse.urlparse(url).netloc.lower()
return any(netloc.endswith(allowed) for allowed in ALLOWED_HOSTS)
except Exception:
return False
def denorm(v: int, size: int) -> int:
return int(v/1000*size)
def exec_calls(candidate, page, viewport, *, approve_all=False) -> List[Tuple[str, Dict]]:
W, H = viewport
results = []
for part in candidate.content.parts:
fc = getattr(part, "function_call", None)
if not fc:
continue
name, args = fc.name, (fc.args or {})
sd = args.get("safety_decision")
if sd and sd.get("decision") == "require_confirmation":
reason = sd.get("explanation", "Model flagged a risky action.")
log_box.warning(f"[SAFETY requires confirmation] {reason}")
if not approve_all:
st.stop()
results.append((name, {"safety_acknowledgement": "true"}))
if name == "navigate":
target = args.get("url", "")
if target and not host_allowed(target):
log_box.error(f"[BLOCKED] Non-allowlisted host: {target}")
results.append((name, {"error": "blocked_by_allowlist"}))
continue
try:
if name == "open_web_browser":
pass
elif name == "navigate":
page.goto(args["url"], timeout=30000)
elif name == "search":
page.goto("https://www.google.com", timeout=30000)
elif name == "click_at":
page.mouse.click(denorm(args["x"], W), denorm(args["y"], H))
elif name == "hover_at":
page.mouse.move(denorm(args["x"], W), denorm(args["y"], H))
elif name == "type_text_at":
x, y = denorm(args["x"], W), denorm(args["y"], H)
page.mouse.click(x, y)
if args.get("clear_before_typing", True):
page.keyboard.press("Meta+A"); page.keyboard.press("Backspace")
page.keyboard.type(args["text"])
if args.get("press_enter", True):
page.keyboard.press("Enter")
elif name == "scroll_document":
page.mouse.wheel(0, 800 if args["direction"] == "down" else -800)
elif name == "key_combination":
page.keyboard.press(args["keys"])
page.wait_for_load_state("networkidle", timeout=10000)
results.append((name, {}))
time.sleep(0.6)
except Exception as e:
results.append((name, {"error": str(e)}))
return resultsVeamos cómo encaja cada función en el proceso:
host_allowed() función: Esta función analiza la URL de destino, normaliza el nombre de host a minúsculas y comprueba si termina con algún dominio de ALLOWED_HOSTS incluido en el archivo .env. denorm() función: Esta utilidad convierte las coordenadas del puntero en unidades de píxeles reales para la ventana gráfica actual. Es fundamental para realizar clics, desplazamientos y escrituras precisos, especialmente cuando cambias el tamaño de la pantalla o trabajas sin monitor.exec_calls() función: Por último, la función execute calls analiza la respuesta del modelo en busca de llamadas a funciones y envía cada una de ellas a Playwright. Bloquea las llamadas de navegación a hosts que no están en la lista de permitidos, ejecuta las acciones compatibles, espera a que la red esté inactiva para estabilizar la página y registra el resultado de cada acción (incluidos los errores). Estos resultados se utilizan en el siguiente paso para construir un FunctionResponses encia con el modelo.En conjunto, estas funciones hacen cumplir los límites, mantienen la precisión de las operaciones matemáticas con punteros y registran resultados granulares.
Después de ejecutar acciones, el agente necesita retroalimentación para decidir el siguiente paso y devolver resultados útiles. Este paso proporciona tres funciones auxiliares, que son las siguientes:
def fr_from(page, results):
shot = page.screenshot(type="png")
url = page.url
frs = []
for name, result in results:
frs.append(types.FunctionResponse(
name=name,
response={"url": url, **result},
parts=[types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(mime_type="image/png", data=shot)
)]
))
return frs, shot
def scrape_google_serp(page, max_items=10):
items = []
anchors = page.locator('div#search a:has(h3)')
count = min(anchors.count(), max_items)
for i in range(count):
a = anchors.nth(i)
title = a.locator('h3').inner_text()
link = a.get_attribute('href')
snippet = ""
snips = page.locator('div#search .VwiC3b')
if snips.count() > i:
snippet = snips.nth(i).inner_text()
items.append({"title": title, "link": link, "snippet": snippet})
return items
def to_csv_download(rows: List[Dict], name="results.csv"):
if not rows:
return None
out = io.StringIO()
writer = csv.DictWriter(out, fieldnames=["keyword", "title", "link", "snippet"])
writer.writeheader(); writer.writerows(rows)
b = out.getvalue().encode("utf-8")
href = f"data:text/csv;base64,{base64.b64encode(b).decode()}"
st.download_button("Download CSV", data=b, file_name=name, mime="text/csv")Veamos cómo funciona cada función auxiliar post-action:
fr_from() función: Esto captura una nueva captura de pantalla PNG y la URL actual, y luego crea un FunctionResponse para cada acción ejecutada. Esto incorpora un contexto visual para la siguiente ronda de inferencias y conserva un registro auditable de lo que ha sucedido.scrape_google_serp() función: A continuación, extraemos títulos, enlaces y fragmentos de la primera página de resultados de Google utilizando selectores resilientes como a:has(h3) para títulos/enlaces y .VwiC3b para fragmentos. El rascador captura los resultados en max_items y devuelve filas limpias y estructuradas, listas para su análisis o exportación.to_csv_download() función: Esta función genera un CSV en memoria con encabezados coherentes y lo expone a través de la función « download_button() » (Generar CSV) de Streamlit.Ahora que ya tenemos todas las funciones auxiliares en su sitio, podemos crear una aplicación Streamlit en torno a ellas.
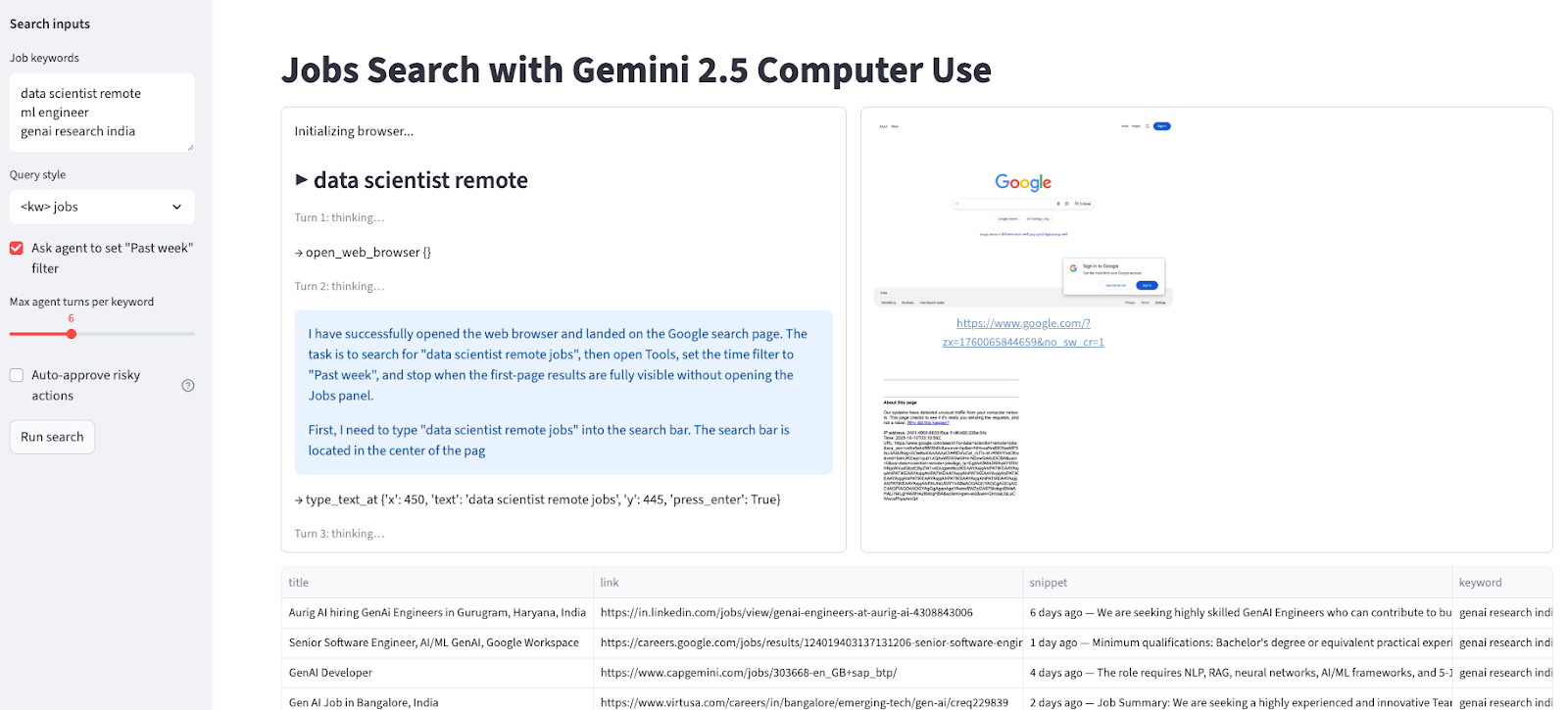
Este paso conecta la interfaz de usuario de Streamlit con el bucle del agente de uso del ordenador. Renderiza la interfaz, gestiona la forma en que el usuario interactúa con el agente y garantiza que el resultado se ajuste a tus necesidades.
st.set_page_config(page_title="Jobs Search with Gemini Computer Use", layout="wide")
st.title("Jobs Search with Gemini 2.5 Computer Use")
with st.sidebar:
st.markdown("**Search inputs**")
default_kw = "data scientist remote\nml engineer \ngenai research india"
kw_text = st.text_area("Job keywords", value=default_kw, height=120)
query_mode = st.selectbox("Query style", ["<kw> jobs", 'site:linkedin.com/jobs "<kw>"'], index=0)
use_past_week = st.checkbox('Ask agent to set "Past week" filter', value=True)
turns = st.slider("Max agent turns per keyword", 3, 12, 6)
auto_confirm = st.checkbox("Auto-approve risky actions", value=False, help="If model requests confirmation (e.g., CAPTCHA), auto-approve instead of pausing.")
run_btn = st.button("Run search")
log_col, shot_col = st.columns([0.45, 0.55])
log_box = log_col.container(height=520)
shot_box = shot_col.container(height=520)
table_box = st.container()
if run_btn:
keywords = [k.strip() for k in kw_text.splitlines() if k.strip()]
all_rows = []
log_box.write("Initializing browser...")
pw = sync_playwright().start()
browser = pw.chromium.launch(headless=False)
ctx = browser.new_context(viewport={"width": W, "height": H})
page = ctx.new_page()
try:
for kw in keywords:
log_box.subheader(f"▶ {kw}")
page.goto("https://www.google.com", timeout=30000)
initial_shot = page.screenshot(type="png")
base_query = f'{kw} jobs' if query_mode == "<kw> jobs" else f'site:linkedin.com/jobs "{kw}"'
goal = (
f'Search Google for "{base_query}". '
f'{"Open Tools and set time filter to Past week. " if use_past_week else ""}'
'Stop when first-page results are fully visible; do NOT open the Jobs panel.'
)
contents = [Content(role="user", parts=[Part(text=goal), Part.from_bytes(data=initial_shot, mime_type="image/png")])]
cfg = types.GenerateContentConfig(
tools=[types.Tool(computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER
))]
)
for turn in range(turns):
log_box.caption(f"Turn {turn+1}: thinking…")
resp = client.models.generate_content(model=MODEL, contents=contents, config=cfg)
cand = resp.candidates[0]
contents.append(cand.content)
narr = " ".join([p.text for p in cand.content.parts if getattr(p, "text", None)])
if narr:
log_box.info(narr[:400])
fcs = [p.function_call for p in cand.content.parts if getattr(p, "function_call", None)]
if not fcs:
log_box.success("Agent stopped proposing actions.")
break
for fc in fcs:
log_box.write(f"→ {fc.name} {fc.args or {}}")
results = exec_calls(cand, page, (W, H), approve_all=auto_confirm)
frs, shot = fr_from(page, results)
contents.append(Content(role="user", parts=[Part(function_response=fr) for fr in frs]))
shot_box.image(shot, caption=page.url, width='stretch')
rows = scrape_google_serp(page)
for r in rows:
r["keyword"] = kw
all_rows.extend(rows)
log_box.success(f"{kw}: collected {len(rows)} results")
if all_rows:
table_box.dataframe(all_rows, width='stretch')
to_csv_download(all_rows, name="jobs_google_results.csv")
else:
st.warning("No rows collected. Try fewer keywords or fewer turns.")
finally:
browser.close()
pw.stop()Veamos en detalle cómo funciona este proceso:
Para ejecutar esta aplicación, simplemente ejecuta el siguiente comando bash en tu terminal:
python -m streamlit run app.pyConsejo: Inicia siempre Streamlit desde tu venv para evitar problemas de «ModuleNotFoundError».
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Dimitri Didmanidze
Tutorial
Tutorial
Matt Crabtree
Tutorial
Arunn Thevapalan
Tutorial
Moez Ali



