
Curso
Building AI Agents with Google ADK
1 h
6.5K
A equipe Gemini recentemente lançou o o Gemini 2.5 Computer Use, um modelo especializado que pode ver uma tela ao vivo e agir nela clicando, digitando, rolando e navegando na web como um operador humano.
Neste guia, vamos deixar de lado os benchmarks abstratos e criar algo prático. Um aplicativo Streamlit que usa o Computer Use para controlar um navegador de verdade, pesquisar vagas de emprego no Google, aplicar um filtro e exportar os resultados para CSV sem precisar de APIs de pesquisa de terceiros.
Neste tutorial, você vai aprender como:
No final, você vai ter um agente de busca de emprego que vai selecionar vagas precisas para você.
Se você quiser saber mais sobre o Gemini 2.5, recomendo dar uma olhada no nosso tutorial do Gemini 2.5 Pro, que fala sobre recursos, testes, acesso, benchmarks e muito mais.
O Gemini 2.5 Computer Use é um modelo e ferramenta especializados (pré-visualização) na API Gemini. API Gemini que permite criar agentes de controle de navegador. Em vez de chamar APIs específicas do site, o modelo funciona a partir de capturas de tela. Ele pode ver o que está na página e, em seguida, agir emitindo ações de interface do usuário, como navigate, click_at, scroll_document, etc.
O código do cliente pega essas ações sugeridas, faz o que tem que ser feito e manda de volta uma combinação nova de captura de tela e URL para que o modelo possa decidir o próximo passo.
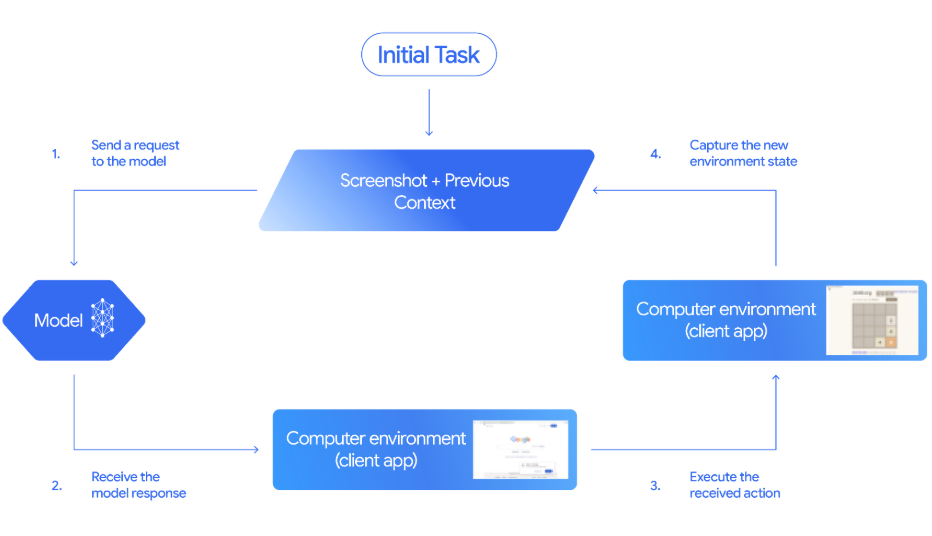
Fonte: Documentação Gemini
Veja como o ciclo do agente acima funciona do início ao fim:
click_at ou type_text_at) e uma decisão de segurança.FunctionResponse que tem uma captura de tela nova e a URL atual.see–decide–act–observe ” até que a tarefa seja concluída, ocorra um erro ou o usuário ou modelo decida parar.Nesta seção, vamos criar um Streamlitque aciona um navegador real usando Gemini 2.5 Computer Use e Playwright, e depois exporta os resultados para CSV.
Funciona assim:
Nos bastidores, o aplicativo usa uma lista de domínios permitidos para uma navegação segura, oferece a opção de confirmação humana para etapas arriscadas e usa o loop de uso do computador para facilitar a depuração.
Alguns casos de uso responsável e políticas do site incluem:
Primeiro, certifique-se de que você tem as seguintes importações instaladas:
python -m venv .venv && source .venv/bin/activate
pip install streamlit google-genai playwright python-dotenv
playwright install chromiumOs comandos acima configuram um ambiente virtual e instalam todas as dependências essenciais necessárias para construir o aplicativo, ou seja, Streamlit para a interface do usuário, google-genai para chamar a API Gemini, Playwright para automação do navegador e python-dotenv para carregar variáveis de ambiente e Chromium para o Playwright.
Agora que já instalamos as dependências, vamos configurar a chave API Gemini do AI Studio.
Agora, crie um arquivo .env na pasta do seu projeto e coloque sua chave API lá:
GOOGLE_API_KEY=YOUR_REAL_KEY
ALLOWED_HOSTS=google.comO pacote python-dotenv vai carregar GOOGLE_API_KEY na hora de rodar, pra que o aplicativo possa chamar o modelo Gemini 2.5 Computer Use.
Agora, vamos nos preparar para o tempo de execução, que inclui importações, constantes, ID do modelo e autenticação. Isso garante que o aplicativo se comunique com o Gemini e que a navegação permaneça segura dentro de um domínio permitido.
import os, io, time, csv, base64, urllib.parse
from typing import List, Dict, Tuple
import streamlit as st
from dotenv import load_dotenv
from playwright.sync_api import sync_playwright
from google import genai
from google.genai import types
from google.genai.types import Content, Part
W, H = 1440, 900
MODEL = "gemini-2.5-computer-use-preview-10-2025"
load_dotenv()
API_KEY = os.getenv("GOOGLE_API_KEY")
if not API_KEY:
st.stop()
ALLOWED_HOSTS = {h.strip().lower() for h in os.getenv("ALLOWED_HOSTS", "google.com").split(",") if h.strip()}
client = genai.Client(api_key=API_KEY)Começamos importando as bibliotecas principais, como Streamlit, Playwright, google-genai e pequenos utilitários (dotenv, os, io, csv, time, urllib) para configuração e E/S.
Uma janela de visualização fixa (W, H = 1440 × 900) mantém as capturas de tela e o mapeamento de coordenadas consistentes para o uso do computador, e o modelo de visualização é definido como gemini-2.5-computer-use-preview-10-2025.
A chave API é carregada com load_dotenv() e os.getenv("GOOGLE_API_KEY"). A navegação é configurada por uma lista de permissões (padrão google.com) por segurança.
Por fim, genai.Client(api_key=API_KEY) inicializa o Gemini SDK para que o aplicativo possa executar o loop do agente e renderizar os resultados no Streamlit.
Antes de entrarmos no cerne do aplicativo, precisamos configurar algumas funções auxiliares. Eles ajudam nas verificações de segurança, coordenam a conversão, executam ações para chamadas de função do Gemini, extraem dados do SERP e exportam os resultados como um CSV.
Começamos adicionando um auxiliar de back-end que permite o controle seguro do navegador. Isso inclui uma função de verificação da lista de domínios permitidos para restringir a navegação, uma função de conversão de coordenadas para mapear a grade 0–999 do modelo para a janela de visualização fixa e uma função de despachante de ações que interpreta as chamadas de função do Computer Use e as executa via Playwright.
def host_allowed(url: str) -> bool:
try:
netloc = urllib.parse.urlparse(url).netloc.lower()
return any(netloc.endswith(allowed) for allowed in ALLOWED_HOSTS)
except Exception:
return False
def denorm(v: int, size: int) -> int:
return int(v/1000*size)
def exec_calls(candidate, page, viewport, *, approve_all=False) -> List[Tuple[str, Dict]]:
W, H = viewport
results = []
for part in candidate.content.parts:
fc = getattr(part, "function_call", None)
if not fc:
continue
name, args = fc.name, (fc.args or {})
sd = args.get("safety_decision")
if sd and sd.get("decision") == "require_confirmation":
reason = sd.get("explanation", "Model flagged a risky action.")
log_box.warning(f"[SAFETY requires confirmation] {reason}")
if not approve_all:
st.stop()
results.append((name, {"safety_acknowledgement": "true"}))
if name == "navigate":
target = args.get("url", "")
if target and not host_allowed(target):
log_box.error(f"[BLOCKED] Non-allowlisted host: {target}")
results.append((name, {"error": "blocked_by_allowlist"}))
continue
try:
if name == "open_web_browser":
pass
elif name == "navigate":
page.goto(args["url"], timeout=30000)
elif name == "search":
page.goto("https://www.google.com", timeout=30000)
elif name == "click_at":
page.mouse.click(denorm(args["x"], W), denorm(args["y"], H))
elif name == "hover_at":
page.mouse.move(denorm(args["x"], W), denorm(args["y"], H))
elif name == "type_text_at":
x, y = denorm(args["x"], W), denorm(args["y"], H)
page.mouse.click(x, y)
if args.get("clear_before_typing", True):
page.keyboard.press("Meta+A"); page.keyboard.press("Backspace")
page.keyboard.type(args["text"])
if args.get("press_enter", True):
page.keyboard.press("Enter")
elif name == "scroll_document":
page.mouse.wheel(0, 800 if args["direction"] == "down" else -800)
elif name == "key_combination":
page.keyboard.press(args["keys"])
page.wait_for_load_state("networkidle", timeout=10000)
results.append((name, {}))
time.sleep(0.6)
except Exception as e:
results.append((name, {"error": str(e)}))
return resultsVamos entender como cada função se encaixa no pipeline:
host_allowed() função: Essa função analisa a URL de destino, coloca o nome do host em minúsculas e vê se ela termina com algum domínio em ALLOWED_HOSTS que tá listado no arquivo .env. denorm() função: Esse utilitário transforma as coordenadas do ponteiro em unidades de pixel reais para a janela de visualização atual. É essencial para cliques, passagens do mouse e digitação precisos, principalmente quando você muda o tamanho da tela ou usa o modo sem monitor.exec_calls() função: Por fim, a função execute calls verifica a resposta do modelo em busca de chamadas de função e envia cada uma delas para o Playwright. Ele bloqueia chamadas de navegação para hosts que não estão na lista de permissões, faz as ações que são suportadas, espera a rede ficar parada para estabilizar a página e registra o resultado de cada ação (incluindo erros). Esses resultados são então usados na próxima etapa para construir um FunctionResponses e ao modelo.Juntas, essas funções reforçam os limites, mantêm a matemática dos ponteiros precisa e registram resultados detalhados.
Depois de fazer as coisas, o agente precisa de feedback pra decidir o que fazer depois e mandar resultados úteis. Essa etapa oferece três funções auxiliares, como segue:
def fr_from(page, results):
shot = page.screenshot(type="png")
url = page.url
frs = []
for name, result in results:
frs.append(types.FunctionResponse(
name=name,
response={"url": url, **result},
parts=[types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(mime_type="image/png", data=shot)
)]
))
return frs, shot
def scrape_google_serp(page, max_items=10):
items = []
anchors = page.locator('div#search a:has(h3)')
count = min(anchors.count(), max_items)
for i in range(count):
a = anchors.nth(i)
title = a.locator('h3').inner_text()
link = a.get_attribute('href')
snippet = ""
snips = page.locator('div#search .VwiC3b')
if snips.count() > i:
snippet = snips.nth(i).inner_text()
items.append({"title": title, "link": link, "snippet": snippet})
return items
def to_csv_download(rows: List[Dict], name="results.csv"):
if not rows:
return None
out = io.StringIO()
writer = csv.DictWriter(out, fieldnames=["keyword", "title", "link", "snippet"])
writer.writeheader(); writer.writerows(rows)
b = out.getvalue().encode("utf-8")
href = f"data:text/csv;base64,{base64.b64encode(b).decode()}"
st.download_button("Download CSV", data=b, file_name=name, mime="text/csv")Vamos ver como cada função auxiliar pós-ação funciona:
fr_from() função: Isso captura uma nova imagem PNG e a URL atual, e depois cria um FunctionResponse para cada ação executada. Isso coloca um contexto visual para a próxima rodada de inferências e mantém um registro auditável do que rolou.scrape_google_serp() função: Depois, a gente pega os títulos, links e trechos da primeira página de resultados do Google usando seletores resilientes como a:has(h3) para títulos/links e .VwiC3b para trechos. O scraper capta os resultados em max_items e devolve linhas limpas e estruturadas, prontas para análise ou exportação.to_csv_download() função: Essa função gera um CSV na memória com cabeçalhos consistentes e o expõe por meio da função ` download_button() ` do Streamlit.Agora que já temos todas as funções auxiliares prontas, podemos criar uma aplicação Streamlit em torno delas.
Essa etapa conecta a interface do usuário do Streamlit ao loop do agente de uso do computador. Ele mostra a interface, controla como o usuário interage com o agente e garante que o resultado seja do jeito que eles querem.
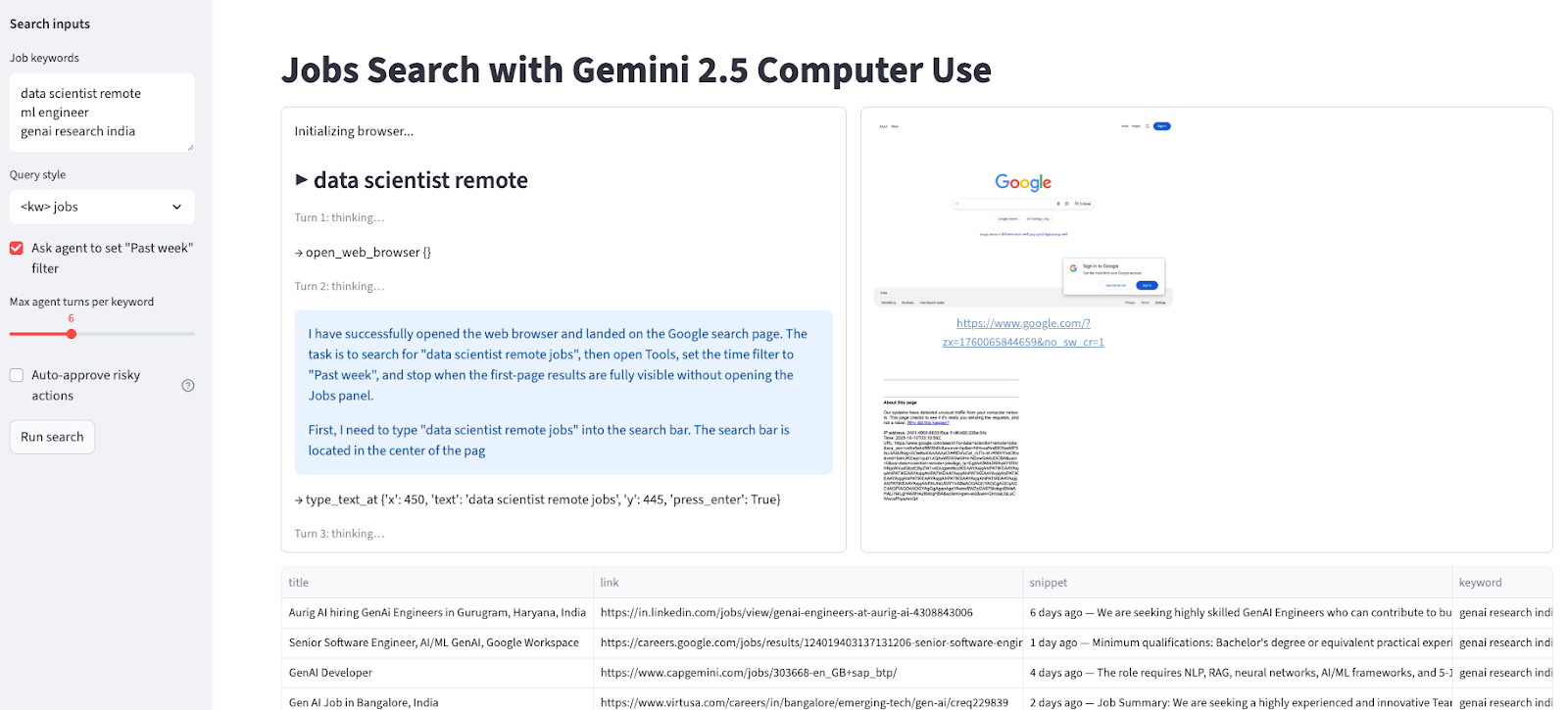
st.set_page_config(page_title="Jobs Search with Gemini Computer Use", layout="wide")
st.title("Jobs Search with Gemini 2.5 Computer Use")
with st.sidebar:
st.markdown("**Search inputs**")
default_kw = "data scientist remote\nml engineer \ngenai research india"
kw_text = st.text_area("Job keywords", value=default_kw, height=120)
query_mode = st.selectbox("Query style", ["<kw> jobs", 'site:linkedin.com/jobs "<kw>"'], index=0)
use_past_week = st.checkbox('Ask agent to set "Past week" filter', value=True)
turns = st.slider("Max agent turns per keyword", 3, 12, 6)
auto_confirm = st.checkbox("Auto-approve risky actions", value=False, help="If model requests confirmation (e.g., CAPTCHA), auto-approve instead of pausing.")
run_btn = st.button("Run search")
log_col, shot_col = st.columns([0.45, 0.55])
log_box = log_col.container(height=520)
shot_box = shot_col.container(height=520)
table_box = st.container()
if run_btn:
keywords = [k.strip() for k in kw_text.splitlines() if k.strip()]
all_rows = []
log_box.write("Initializing browser...")
pw = sync_playwright().start()
browser = pw.chromium.launch(headless=False)
ctx = browser.new_context(viewport={"width": W, "height": H})
page = ctx.new_page()
try:
for kw in keywords:
log_box.subheader(f"▶ {kw}")
page.goto("https://www.google.com", timeout=30000)
initial_shot = page.screenshot(type="png")
base_query = f'{kw} jobs' if query_mode == "<kw> jobs" else f'site:linkedin.com/jobs "{kw}"'
goal = (
f'Search Google for "{base_query}". '
f'{"Open Tools and set time filter to Past week. " if use_past_week else ""}'
'Stop when first-page results are fully visible; do NOT open the Jobs panel.'
)
contents = [Content(role="user", parts=[Part(text=goal), Part.from_bytes(data=initial_shot, mime_type="image/png")])]
cfg = types.GenerateContentConfig(
tools=[types.Tool(computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER
))]
)
for turn in range(turns):
log_box.caption(f"Turn {turn+1}: thinking…")
resp = client.models.generate_content(model=MODEL, contents=contents, config=cfg)
cand = resp.candidates[0]
contents.append(cand.content)
narr = " ".join([p.text for p in cand.content.parts if getattr(p, "text", None)])
if narr:
log_box.info(narr[:400])
fcs = [p.function_call for p in cand.content.parts if getattr(p, "function_call", None)]
if not fcs:
log_box.success("Agent stopped proposing actions.")
break
for fc in fcs:
log_box.write(f"→ {fc.name} {fc.args or {}}")
results = exec_calls(cand, page, (W, H), approve_all=auto_confirm)
frs, shot = fr_from(page, results)
contents.append(Content(role="user", parts=[Part(function_response=fr) for fr in frs]))
shot_box.image(shot, caption=page.url, width='stretch')
rows = scrape_google_serp(page)
for r in rows:
r["keyword"] = kw
all_rows.extend(rows)
log_box.success(f"{kw}: collected {len(rows)} results")
if all_rows:
table_box.dataframe(all_rows, width='stretch')
to_csv_download(all_rows, name="jobs_google_results.csv")
else:
st.warning("No rows collected. Try fewer keywords or fewer turns.")
finally:
browser.close()
pw.stop()Vamos entender esse pipeline em detalhes:
Pra rodar esse app, é só executar o seguinte comando bash no seu terminal:
python -m streamlit run app.pyDica: Sempre inicie o Streamlit a partir do seu venv para evitar problemas de “ModuleNotFoundError”.
Cursos mais populares do DataCamp
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
Tutorial
Tutorial
Dimitri Didmanidze
Tutorial
Moez Ali
Tutorial
Matt Crabtree
Tutorial
Bex Tuychiev


