
Cours
Créer des agents IA avec Google ADK
1 h
6.5K
L'équipe Gemini a récemment présenté Gemini 2.5 Computer Use, un modèle spécialisé capable de visualiser un écran en direct et d'agir dessus en cliquant, en tapant, en faisant défiler et en naviguant sur le Web comme le ferait un opérateur humain.
Dans ce guide, nous éviterons les benchmarks abstraits et nous construirons quelque chose de pratique. Une application Streamlit qui utilise Computer Use pour contrôler un navigateur réel, rechercher des offres d'emploi sur Google, appliquer un filtre et exporter les résultats au format CSV sans aucune API de recherche tierce.
Dans ce tutoriel, vous apprendrez à :
À la fin, vous disposerez d'un agent de recherche d'emploi qui sélectionnera pour vous des offres d'emploi pertinentes.
Si vous souhaitez en savoir plus sur Gemini 2.5, je vous recommande de consulter notre tutoriel Gemini 2.5 Pro, qui couvre les fonctionnalités, les tests, l'accès, les benchmarks et bien plus encore.
Gemini 2.5 Computer Use est un modèle et un outil spécialisé (aperçu) dans l'API Gemini qui vous permet de créer des agents de contrôle de navigateur. Au lieu d'utiliser des API spécifiques au site, le modèle fonctionne à partir de captures d'écran. Il est possiblede consulter le contenu de la page à l'adresse , puis d'agir en émettant des actions d'interface utilisateur telles que navigate, click_at, scroll_document, etc.
Le code client reçoit ces actions proposées, les exécute et renvoie une nouvelle combinaison d'une capture d'écran et d'une URL afin que le modèle puisse déterminer la prochaine étape.
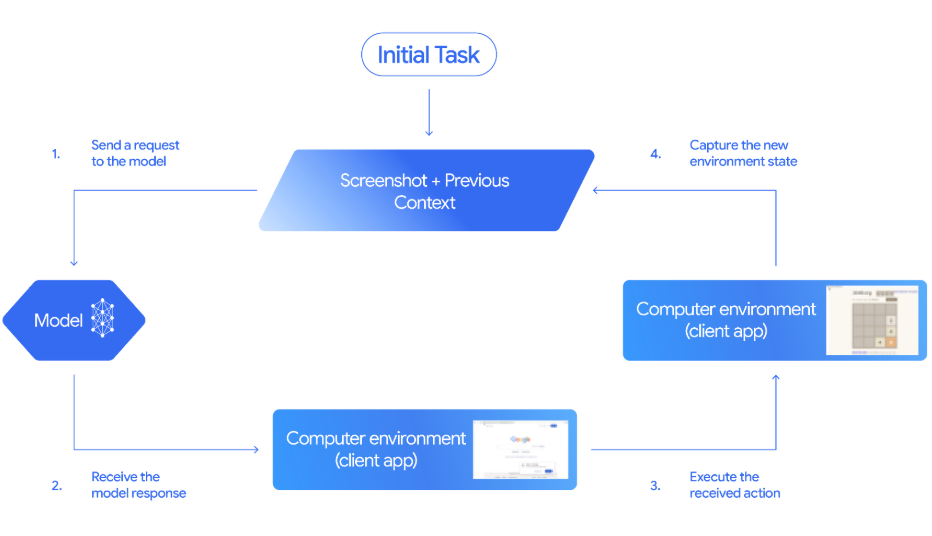
Source : Documentation Gemini
Voici comment fonctionne la boucle d'agent ci-dessus de bout en bout :
click_at ou type_text_at) ainsi qu'une décision de sécurité.FunctionResponse ) contenant une nouvelle capture d'écran et l'URL actuelle.see–decide–act–observe s jusqu'à ce que la tâche soit terminée, qu'une erreur se produise ou que l'utilisateur ou le modèle choisisse d'arrêter.Dans cette section, nous allons créer un agent de recherche d'emploi alimenté par Streamlitagent de recherche d'emploi alimenté par Streamlit qui pilote un navigateur réel à l'aide de Gemini 2.5 Computer Use et Playwright, puis exportera les résultats au format CSV.
Voici comment cela fonctionne :
En arrière-plan, l'application impose un domaine autorisé pour une navigation sécurisée, prend en charge la confirmation humaine facultative pour les étapes à risque et utilise la boucle d'utilisation de l'ordinateur pour faciliter le débogage.
Voici quelques exemples d'utilisation responsable et de politiques de site :
Tout d'abord, veuillez vous assurer que les importations suivantes sont installées :
python -m venv .venv && source .venv/bin/activate
pip install streamlit google-genai playwright python-dotenv
playwright install chromiumLes commandes ci-dessus permettent de configurer un environnement virtuel et d'installer toutes les dépendances essentielles nécessaires à la construction de l'application, à savoir Streamlit pour l'interface utilisateur, google-genai pour appeler l'API Gemini, et Playwright pour l'automatisation du navigateur, et python-dotenv pour charger les variables d'environnement et Chromium pour Playwright.
Maintenant que les dépendances sont installées, nous allons configurer la clé API Gemini à partir d'AI Studio.
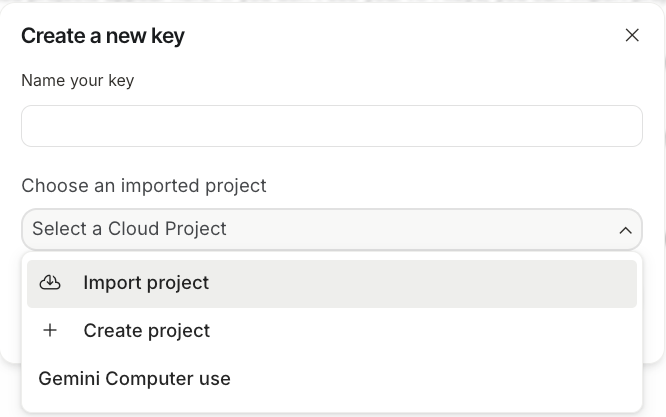
Veuillez maintenant créer un fichier .env dans le dossier de votre projet et y ajouter votre clé API :
GOOGLE_API_KEY=YOUR_REAL_KEY
ALLOWED_HOSTS=google.comLe package python-dotenv chargera GOOGLE_API_KEY lors de l'exécution afin que l'application puisse appeler le modèle Gemini 2.5 Computer Use.
Maintenant, préparons-nous pour l'exécution, qui comprend les importations, les constantes, l'ID du modèle et l'authentification. Cela garantit que l'application communique avec Gemini et que la navigation reste sécurisée au sein d'un domaine autorisé.
import os, io, time, csv, base64, urllib.parse
from typing import List, Dict, Tuple
import streamlit as st
from dotenv import load_dotenv
from playwright.sync_api import sync_playwright
from google import genai
from google.genai import types
from google.genai.types import Content, Part
W, H = 1440, 900
MODEL = "gemini-2.5-computer-use-preview-10-2025"
load_dotenv()
API_KEY = os.getenv("GOOGLE_API_KEY")
if not API_KEY:
st.stop()
ALLOWED_HOSTS = {h.strip().lower() for h in os.getenv("ALLOWED_HOSTS", "google.com").split(",") if h.strip()}
client = genai.Client(api_key=API_KEY)Nous commençons par importer les bibliothèques principales telles que Streamlit, Playwright, google-genai, ainsi que de petits utilitaires (dotenv, os, io, csv, time, urllib) pour la configuration et les E/S.
Une fenêtre d'affichage fixe (W, H = 1440 × 900) permet de garantir la cohérence des captures d'écran et du mappage des coordonnées pour l'utilisation de l'ordinateur, et le modèle d'aperçu est défini sur gemini-2.5-computer-use-preview-10-2025.
La clé API est chargée avec load_dotenv() et os.getenv("GOOGLE_API_KEY"). La navigation est configurée par une liste blanche (google.com par défaut) pour des raisons de sécurité.
Enfin, l'genai.Client(api_key=API_KEY) initialise le SDK Gemini afin que l'application puisse exécuter la boucle de l'agent et afficher les résultats dans Streamlit.
Avant de passer au cœur de l'application, nous devons configurer quelques fonctions d'aide. Ils contribuent aux contrôles de sécurité, coordonnent la conversion, exécutent des actions pour les appels de fonction Gemini, le scraping SERP et exportent les résultats au format CSV.
Nous commençons par ajouter un assistant backend qui permet un contrôle sécurisé du navigateur. Cela comprend une fonction de vérification de la liste blanche des domaines pour restreindre la navigation, une fonction de conversion de coordonnées pour mapper la grille 0-999 du modèle à la fenêtre d'affichage fixe, et une fonction de répartition des actions qui interprète les appels de fonction Computer Use et les exécute via Playwright.
def host_allowed(url: str) -> bool:
try:
netloc = urllib.parse.urlparse(url).netloc.lower()
return any(netloc.endswith(allowed) for allowed in ALLOWED_HOSTS)
except Exception:
return False
def denorm(v: int, size: int) -> int:
return int(v/1000*size)
def exec_calls(candidate, page, viewport, *, approve_all=False) -> List[Tuple[str, Dict]]:
W, H = viewport
results = []
for part in candidate.content.parts:
fc = getattr(part, "function_call", None)
if not fc:
continue
name, args = fc.name, (fc.args or {})
sd = args.get("safety_decision")
if sd and sd.get("decision") == "require_confirmation":
reason = sd.get("explanation", "Model flagged a risky action.")
log_box.warning(f"[SAFETY requires confirmation] {reason}")
if not approve_all:
st.stop()
results.append((name, {"safety_acknowledgement": "true"}))
if name == "navigate":
target = args.get("url", "")
if target and not host_allowed(target):
log_box.error(f"[BLOCKED] Non-allowlisted host: {target}")
results.append((name, {"error": "blocked_by_allowlist"}))
continue
try:
if name == "open_web_browser":
pass
elif name == "navigate":
page.goto(args["url"], timeout=30000)
elif name == "search":
page.goto("https://www.google.com", timeout=30000)
elif name == "click_at":
page.mouse.click(denorm(args["x"], W), denorm(args["y"], H))
elif name == "hover_at":
page.mouse.move(denorm(args["x"], W), denorm(args["y"], H))
elif name == "type_text_at":
x, y = denorm(args["x"], W), denorm(args["y"], H)
page.mouse.click(x, y)
if args.get("clear_before_typing", True):
page.keyboard.press("Meta+A"); page.keyboard.press("Backspace")
page.keyboard.type(args["text"])
if args.get("press_enter", True):
page.keyboard.press("Enter")
elif name == "scroll_document":
page.mouse.wheel(0, 800 if args["direction"] == "down" else -800)
elif name == "key_combination":
page.keyboard.press(args["keys"])
page.wait_for_load_state("networkidle", timeout=10000)
results.append((name, {}))
time.sleep(0.6)
except Exception as e:
results.append((name, {"error": str(e)}))
return resultsComprenons comment chaque fonction s'intègre dans le pipeline :
host_allowed() fonction : Cette fonction analyse l'URL cible, normalise le nom d'hôte en minuscules et vérifie s'il se termine par un domaine figurant dans ALLOWED_HOSTS répertorié dans le fichier .env. denorm() fonction : Cet utilitaire convertit les coordonnées du pointeur en unités de pixels réelles pour la fenêtre d'affichage actuelle. Il est essentiel pour effectuer des clics, des survols et des saisies précis, en particulier lorsque vous modifiez la taille de l'écran ou utilisez un mode sans affichage.exec_calls() fonction : Enfin, la fonction execute calls analyse la réponse du modèle à la recherche d'appels de fonction et les transmet à Playwright. Il bloque les appels de navigation vers les hôtes non autorisés, exécute les actions prises en charge, attend que le réseau soit inactif pour stabiliser la page et enregistre le résultat de chaque action (y compris les erreurs). Ces résultats sont ensuite utilisés dans l'étape suivante pour établir l'FunctionResponses s vers le modèle.Ensemble, ces fonctions renforcent les limites, garantissent la précision des calculs de pointeurs et enregistrent des résultats détaillés.
Après avoir exécuté des actions, l'agent a besoin d'un retour d'information pour décider de la prochaine étape et fournir des résultats utiles. Cette étape fournit trois fonctions d'aide comme suit :
def fr_from(page, results):
shot = page.screenshot(type="png")
url = page.url
frs = []
for name, result in results:
frs.append(types.FunctionResponse(
name=name,
response={"url": url, **result},
parts=[types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(mime_type="image/png", data=shot)
)]
))
return frs, shot
def scrape_google_serp(page, max_items=10):
items = []
anchors = page.locator('div#search a:has(h3)')
count = min(anchors.count(), max_items)
for i in range(count):
a = anchors.nth(i)
title = a.locator('h3').inner_text()
link = a.get_attribute('href')
snippet = ""
snips = page.locator('div#search .VwiC3b')
if snips.count() > i:
snippet = snips.nth(i).inner_text()
items.append({"title": title, "link": link, "snippet": snippet})
return items
def to_csv_download(rows: List[Dict], name="results.csv"):
if not rows:
return None
out = io.StringIO()
writer = csv.DictWriter(out, fieldnames=["keyword", "title", "link", "snippet"])
writer.writeheader(); writer.writerows(rows)
b = out.getvalue().encode("utf-8")
href = f"data:text/csv;base64,{base64.b64encode(b).decode()}"
st.download_button("Download CSV", data=b, file_name=name, mime="text/csv")Examinons le fonctionnement de chaque fonction d'aide post-action :
fr_from() fonction : Cette fonction capture une nouvelle capture d'écran PNG et l'URL actuelle, puis crée un fichier FunctionResponse pour chaque action exécutée. Cela permet d'intégrer le contexte visuel pour le prochain tour d'inférence et de conserver une trace vérifiable de ce qui s'est produit.scrape_google_serp() fonction : Ensuite, nous extrayons les titres, les liens et les extraits de la première page de résultats de Google à l'aide de sélecteurs résilients tels que a:has(h3) pour les titres/liens et .VwiC3b pour les extraits. Le scraper extrait les résultats sur max_items et renvoie des lignes propres et structurées, prêtes à être analysées ou exportées.to_csv_download() fonction : Cette fonction génère un fichier CSV en mémoire avec des en-têtes cohérents et l'expose via la fonction download_button() de Streamlit.Maintenant que toutes les fonctions d'aide sont en place, nous pouvons créer une application Streamlit autour d'elles.
Cette étape permet de connecter l'interface utilisateur Streamlit à la boucle de l'agent Computer Use. Il affiche l'interface, gère la manière dont l'utilisateur interagit avec l'agent et s'assure que le résultat correspond à ses besoins.
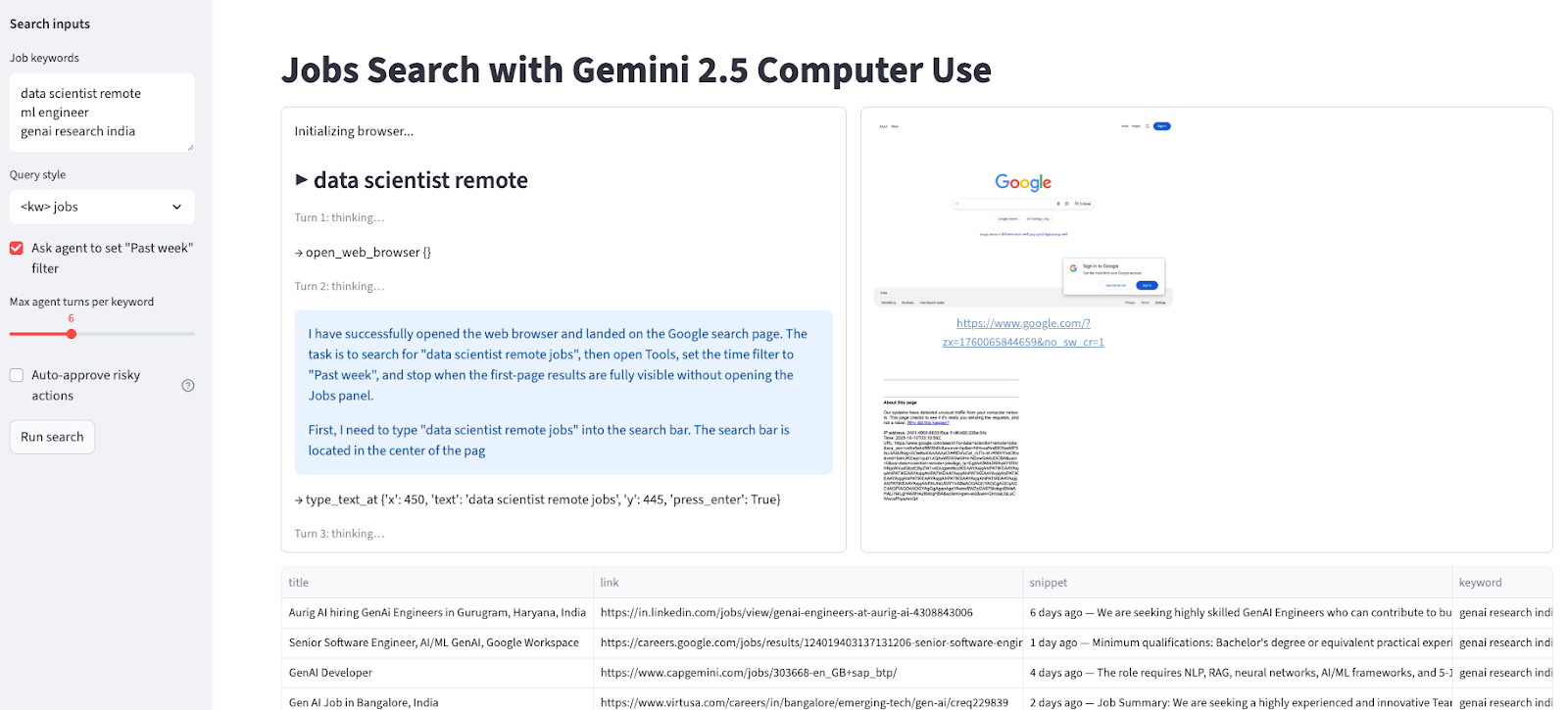
st.set_page_config(page_title="Jobs Search with Gemini Computer Use", layout="wide")
st.title("Jobs Search with Gemini 2.5 Computer Use")
with st.sidebar:
st.markdown("**Search inputs**")
default_kw = "data scientist remote\nml engineer \ngenai research india"
kw_text = st.text_area("Job keywords", value=default_kw, height=120)
query_mode = st.selectbox("Query style", ["<kw> jobs", 'site:linkedin.com/jobs "<kw>"'], index=0)
use_past_week = st.checkbox('Ask agent to set "Past week" filter', value=True)
turns = st.slider("Max agent turns per keyword", 3, 12, 6)
auto_confirm = st.checkbox("Auto-approve risky actions", value=False, help="If model requests confirmation (e.g., CAPTCHA), auto-approve instead of pausing.")
run_btn = st.button("Run search")
log_col, shot_col = st.columns([0.45, 0.55])
log_box = log_col.container(height=520)
shot_box = shot_col.container(height=520)
table_box = st.container()
if run_btn:
keywords = [k.strip() for k in kw_text.splitlines() if k.strip()]
all_rows = []
log_box.write("Initializing browser...")
pw = sync_playwright().start()
browser = pw.chromium.launch(headless=False)
ctx = browser.new_context(viewport={"width": W, "height": H})
page = ctx.new_page()
try:
for kw in keywords:
log_box.subheader(f"▶ {kw}")
page.goto("https://www.google.com", timeout=30000)
initial_shot = page.screenshot(type="png")
base_query = f'{kw} jobs' if query_mode == "<kw> jobs" else f'site:linkedin.com/jobs "{kw}"'
goal = (
f'Search Google for "{base_query}". '
f'{"Open Tools and set time filter to Past week. " if use_past_week else ""}'
'Stop when first-page results are fully visible; do NOT open the Jobs panel.'
)
contents = [Content(role="user", parts=[Part(text=goal), Part.from_bytes(data=initial_shot, mime_type="image/png")])]
cfg = types.GenerateContentConfig(
tools=[types.Tool(computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER
))]
)
for turn in range(turns):
log_box.caption(f"Turn {turn+1}: thinking…")
resp = client.models.generate_content(model=MODEL, contents=contents, config=cfg)
cand = resp.candidates[0]
contents.append(cand.content)
narr = " ".join([p.text for p in cand.content.parts if getattr(p, "text", None)])
if narr:
log_box.info(narr[:400])
fcs = [p.function_call for p in cand.content.parts if getattr(p, "function_call", None)]
if not fcs:
log_box.success("Agent stopped proposing actions.")
break
for fc in fcs:
log_box.write(f"→ {fc.name} {fc.args or {}}")
results = exec_calls(cand, page, (W, H), approve_all=auto_confirm)
frs, shot = fr_from(page, results)
contents.append(Content(role="user", parts=[Part(function_response=fr) for fr in frs]))
shot_box.image(shot, caption=page.url, width='stretch')
rows = scrape_google_serp(page)
for r in rows:
r["keyword"] = kw
all_rows.extend(rows)
log_box.success(f"{kw}: collected {len(rows)} results")
if all_rows:
table_box.dataframe(all_rows, width='stretch')
to_csv_download(all_rows, name="jobs_google_results.csv")
else:
st.warning("No rows collected. Try fewer keywords or fewer turns.")
finally:
browser.close()
pw.stop()Examinons ce pipeline en détail :
Pour exécuter cette application, veuillez exécuter la commande bash suivante dans votre terminal :
python -m streamlit run app.pyConseil: Veuillez toujours lancer Streamlit depuis votre environnement virtualisé (venv) afin d'éviter les problèmes liés à l'erreur « ModuleNotFoundError ».
Meilleurs cours DataCamp
Cours
Cours
Cours
blog
Tutoriel
Matt Crabtree
Tutoriel
Mark Pedigo
Tutoriel
Adel Nehme
Tutoriel
Moez Ali