
Kurs
KI-Agenten mit dem Google ADK entwickeln
1 Std.
6.5K
Das Gemini-Team hat kürzlich Gemini 2.5 Gemini 2.5 Computer Use, ein spezielles Modell, das einen Live-Bildschirm sehen und darauf reagieren kann, indem es wie ein Mensch klickt, tippt, scrollt und im Internet surft.
In dieser Anleitung lassen wir abstrakte Benchmarks mal beiseite und machen was Praktisches. Eine Streamlit-App, die Computer Use nutzt, um einen echten Browser zu steuern, bei Google nach Stellenangeboten zu suchen, einen Filter anzuwenden und die Ergebnisse ohne Such-APIs von Drittanbietern als CSV-Datei zu speichern.
In diesem Tutorial lernst du, wie du:
Am Ende hast du einen Job-Suchagenten, der dir passende Stellenanzeigen zusammenstellt.
Wenn du mehr über Gemini 2.5 erfahren möchtest, schau dir doch mal unser Tutorial zu Gemini 2.5 Pro an. Gemini 2.5 Pro-Tutorial, das Funktionen, Tests, Zugriff, Benchmarks und mehr abdeckt.
Gemini 2.5 Computer Use ist ein spezielles (Vorschau-)Modell und Tool in der Gemini API, mit dem du Browser-Steuerungsagenten erstellen kannst. Anstatt bestimmte APIs aufzurufen, nutzt das Modell Screenshots. Es kann sehen, was auf der Seite ist, und dann UI-Aktionen wie navigate, click_at, scroll_document usw. ausführen.
Der Client-Code kriegt die vorgeschlagenen Aktionen, macht sie und schickt dann eine neue Kombination aus Screenshot und URL zurück, damit das Modell den nächsten Schritt entscheiden kann.
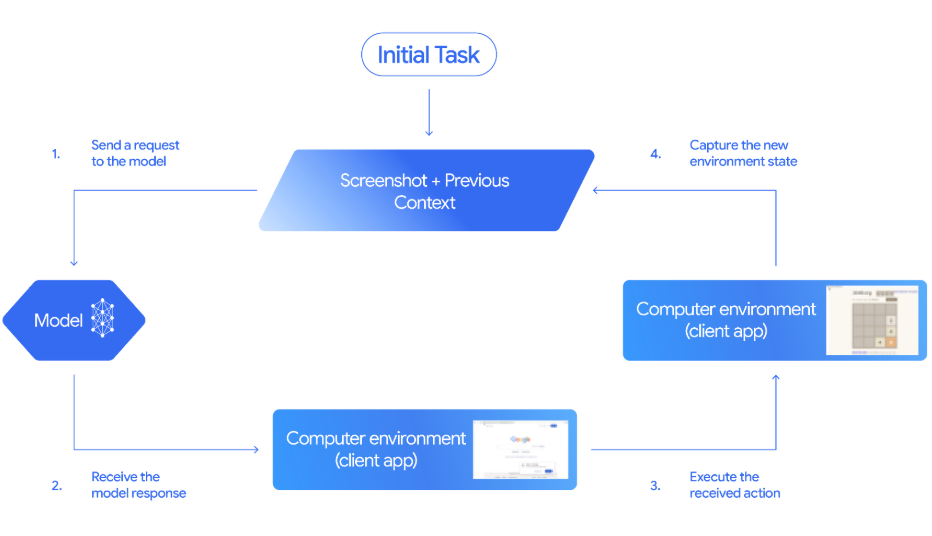
Quelle: Gemini-Dokumentation
So läuft die Agentenschleife von Anfang bis Ende ab:
click_at oder type_text_at) sowie einer Sicherheitsentscheidung.FunctionResponse ” senden, das einen neuen Screenshot und die aktuelle URL enthält.see–decide–act–observe “, bis die Aufgabe erledigt ist, ein Fehler auftritt oder der Benutzer oder das Modell entscheidet, den Vorgang zu beenden.In diesem Abschnitt erstellen wir ein Streamlit-basierten Jobsuchagenten erstellen, der einen echten Browser mit Gemini 2.5 Computer Use und Playwright steuert und die Ergebnisse dann in CSV exportiert.
So läuft's ab:
Im Hintergrund sorgt die App dafür, dass nur Domains auf einer Whitelist für die sichere Navigation zugelassen werden, unterstützt eine optionale manuelle Bestätigung für riskante Schritte und nutzt die Computernutzungsschleife für einfaches Debugging.
Ein paar Beispiele für verantwortungsbewusste Nutzung und Website-Richtlinien sind:
Stell zuerst sicher, dass du die folgenden Importe installiert hast:
python -m venv .venv && source .venv/bin/activate
pip install streamlit google-genai playwright python-dotenv
playwright install chromiumDie oben genannten Befehle richten eine virtuelle Umgebung ein und installieren alle wichtigen Abhängigkeiten, die man zum Erstellen der App braucht, nämlich , die zum Erstellen der App nötig sind, nämlich Streamlit für die Benutzeroberfläche, google-genai zum Aufrufen der Gemini-API und Playwright für die Browser-Automatisierung und python-dotenv zum Laden von Umgebungsvariablen und Chromium für Playwright.
Jetzt, wo wir die Abhängigkeiten installiert haben, richten wir als Nächstes den Gemini-API-Schlüssel aus AI Studio ein.
Erstell jetzt eine Datei namens „ .env “ in deinem Projektordner und füge dort deinen API-Schlüssel hinzu:
GOOGLE_API_KEY=YOUR_REAL_KEY
ALLOWED_HOSTS=google.comDas Paket „ python-dotenv ” lädt „ GOOGLE_API_KEY ” zur Laufzeit, damit die App das Gemini 2.5-Computernutzungsmodell aufrufen kann.
Jetzt machen wir uns bereit für die Laufzeit, die Importe, Konstanten, Modell-ID und Authentifizierung umfasst. Dadurch wird sichergestellt, dass die App mit Gemini kommuniziert und die Navigation sicher innerhalb einer zugelassenen Domain bleibt.
import os, io, time, csv, base64, urllib.parse
from typing import List, Dict, Tuple
import streamlit as st
from dotenv import load_dotenv
from playwright.sync_api import sync_playwright
from google import genai
from google.genai import types
from google.genai.types import Content, Part
W, H = 1440, 900
MODEL = "gemini-2.5-computer-use-preview-10-2025"
load_dotenv()
API_KEY = os.getenv("GOOGLE_API_KEY")
if not API_KEY:
st.stop()
ALLOWED_HOSTS = {h.strip().lower() for h in os.getenv("ALLOWED_HOSTS", "google.com").split(",") if h.strip()}
client = genai.Client(api_key=API_KEY)Wir fangen damit an, die Kernbibliotheken wie Streamlit, Playwright, google-genai und kleine Hilfsprogramme (dotenv, os, io, csv, time, urllib) für die Konfiguration und E/A zu importieren.
Ein fester Viewport (W, H = 1440 × 900) sorgt dafür, dass Screenshots und Koordinatenabbildung für die Computernutzung einheitlich bleiben, und das Vorschaumodell ist auf „ gemini-2.5-computer-use-preview-10-2025 “ eingestellt.
Der API-Schlüssel wird mit load_dotenv() und os.getenv("GOOGLE_API_KEY") geladen. Die Navigation wird aus Sicherheitsgründen über eine Zulassungsliste (Standard: google.com) eingerichtet.
Schließlich wird mit „ genai.Client(api_key=API_KEY) “ das Gemini SDK gestartet, damit die App die Agentenschleife ausführen und die Ergebnisse in Streamlit anzeigen kann.
Bevor wir uns mit dem Kern der App beschäftigen, müssen wir ein paar Hilfsfunktionen einrichten. Sie helfen bei Sicherheitschecks, koordinieren die Konvertierung, führen Aktionen für Gemini-Funktionsaufrufe und SERP-Scraping durch und exportieren die Ergebnisse als CSV-Datei.
Wir fangen damit an, einen Backend-Helfer hinzuzufügen, der die sichere Browsersteuerung ermöglicht. Dazu gehören eine Funktion zur Überprüfung der Domänen-Zulassungsliste, um die Navigation einzuschränken, eine Koordinatenkonverterfunktion, um das 0–999-Raster des Modells auf den festen Ansichtsbereich abzubilden, und eine Aktionsverteilungsfunktion, die Computer-Use-Funktionsaufrufe interpretiert und über Playwright ausführt.
def host_allowed(url: str) -> bool:
try:
netloc = urllib.parse.urlparse(url).netloc.lower()
return any(netloc.endswith(allowed) for allowed in ALLOWED_HOSTS)
except Exception:
return False
def denorm(v: int, size: int) -> int:
return int(v/1000*size)
def exec_calls(candidate, page, viewport, *, approve_all=False) -> List[Tuple[str, Dict]]:
W, H = viewport
results = []
for part in candidate.content.parts:
fc = getattr(part, "function_call", None)
if not fc:
continue
name, args = fc.name, (fc.args or {})
sd = args.get("safety_decision")
if sd and sd.get("decision") == "require_confirmation":
reason = sd.get("explanation", "Model flagged a risky action.")
log_box.warning(f"[SAFETY requires confirmation] {reason}")
if not approve_all:
st.stop()
results.append((name, {"safety_acknowledgement": "true"}))
if name == "navigate":
target = args.get("url", "")
if target and not host_allowed(target):
log_box.error(f"[BLOCKED] Non-allowlisted host: {target}")
results.append((name, {"error": "blocked_by_allowlist"}))
continue
try:
if name == "open_web_browser":
pass
elif name == "navigate":
page.goto(args["url"], timeout=30000)
elif name == "search":
page.goto("https://www.google.com", timeout=30000)
elif name == "click_at":
page.mouse.click(denorm(args["x"], W), denorm(args["y"], H))
elif name == "hover_at":
page.mouse.move(denorm(args["x"], W), denorm(args["y"], H))
elif name == "type_text_at":
x, y = denorm(args["x"], W), denorm(args["y"], H)
page.mouse.click(x, y)
if args.get("clear_before_typing", True):
page.keyboard.press("Meta+A"); page.keyboard.press("Backspace")
page.keyboard.type(args["text"])
if args.get("press_enter", True):
page.keyboard.press("Enter")
elif name == "scroll_document":
page.mouse.wheel(0, 800 if args["direction"] == "down" else -800)
elif name == "key_combination":
page.keyboard.press(args["keys"])
page.wait_for_load_state("networkidle", timeout=10000)
results.append((name, {}))
time.sleep(0.6)
except Exception as e:
results.append((name, {"error": str(e)}))
return resultsSchauen wir mal, wie jede Funktion in die Pipeline passt:
host_allowed() Funktion: Diese Funktion analysiert die Ziel-URL, schreibt den Hostnamen klein und checkt, ob er mit einer Domain aus ALLOWED_HOSTS endet, die in der Datei .env aufgeführt ist. denorm() Funktion: Dieses Tool wandelt die Zeigerkoordinaten in tatsächliche Pixeleinheiten für den aktuellen Ansichtsbereich um. Das ist echt wichtig für präzise Klicks, Hover-Bewegungen und die Eingabe, vor allem wenn du die Bildschirmgröße änderst oder ohne Monitor arbeitest.exec_calls() Funktion: Schließlich checkt die Funktion „execute calls“ ( )die Antwort des Modells auf Funktionsaufrufe und schickt jeden einzelnen an Playwright. Es blockiert Aufrufe an nicht zugelassene Hosts, macht die unterstützten Aktionen, wartet, bis das Netzwerk ruhig ist, um die Seite zu stabilisieren, und speichert das Ergebnis jeder Aktion (auch Fehler). Diese Ergebnisse werden dann im nächsten Schritt genutzt, um die Rückkopplung „ FunctionResponses “ zum Modell zu erstellen.Zusammen sorgen diese Funktionen dafür, dass Grenzen eingehalten werden, die Zeigermathematik genau bleibt und detaillierte Ergebnisse protokolliert werden.
Nachdem der Agent was gemacht hat, braucht er Feedback, um zu entscheiden, was als Nächstes passiert, und um nützliche Ergebnisse zu liefern. Dieser Schritt bietet drei Hilfsfunktionen wie folgt:
def fr_from(page, results):
shot = page.screenshot(type="png")
url = page.url
frs = []
for name, result in results:
frs.append(types.FunctionResponse(
name=name,
response={"url": url, **result},
parts=[types.FunctionResponsePart(
inline_data=types.FunctionResponseBlob(mime_type="image/png", data=shot)
)]
))
return frs, shot
def scrape_google_serp(page, max_items=10):
items = []
anchors = page.locator('div#search a:has(h3)')
count = min(anchors.count(), max_items)
for i in range(count):
a = anchors.nth(i)
title = a.locator('h3').inner_text()
link = a.get_attribute('href')
snippet = ""
snips = page.locator('div#search .VwiC3b')
if snips.count() > i:
snippet = snips.nth(i).inner_text()
items.append({"title": title, "link": link, "snippet": snippet})
return items
def to_csv_download(rows: List[Dict], name="results.csv"):
if not rows:
return None
out = io.StringIO()
writer = csv.DictWriter(out, fieldnames=["keyword", "title", "link", "snippet"])
writer.writeheader(); writer.writerows(rows)
b = out.getvalue().encode("utf-8")
href = f"data:text/csv;base64,{base64.b64encode(b).decode()}"
st.download_button("Download CSV", data=b, file_name=name, mime="text/csv")Schauen wir mal, wie die einzelnen Post-Action-Hilfsfunktionen funktionieren:
fr_from() Funktion: Das macht einen neuen PNG-Screenshot und speichert die aktuelle URL, dann erstellt es für jede ausgeführte Aktion einen „ FunctionResponse “. Das gibt einen visuellen Kontext für den nächsten Inferenzschritt und sorgt dafür, dass man nachverfolgen kann, was passiert ist.scrape_google_serp() Funktion: Als Nächstes holen wir Titel, Links und Snippets von der ersten Ergebnisseite von Google raus, indem wir robuste Selektoren wie a:has(h3) für Titel/Links und .VwiC3b für Snippets nutzen. Der Scraper sammelt die Ergebnisse unter max_items und liefert saubere, strukturierte Zeilen, die du direkt analysieren oder exportieren kannst.to_csv_download() Funktion: Diese Funktion macht eine CSV-Datei im Speicher mit einheitlichen Überschriften und zeigt sie über die Streamlit-Funktion „ download_button() “ an.Jetzt haben wir alle Hilfsfunktionen, die wir brauchen, und können als Nächstes eine Streamlit-App drum herum bauen.
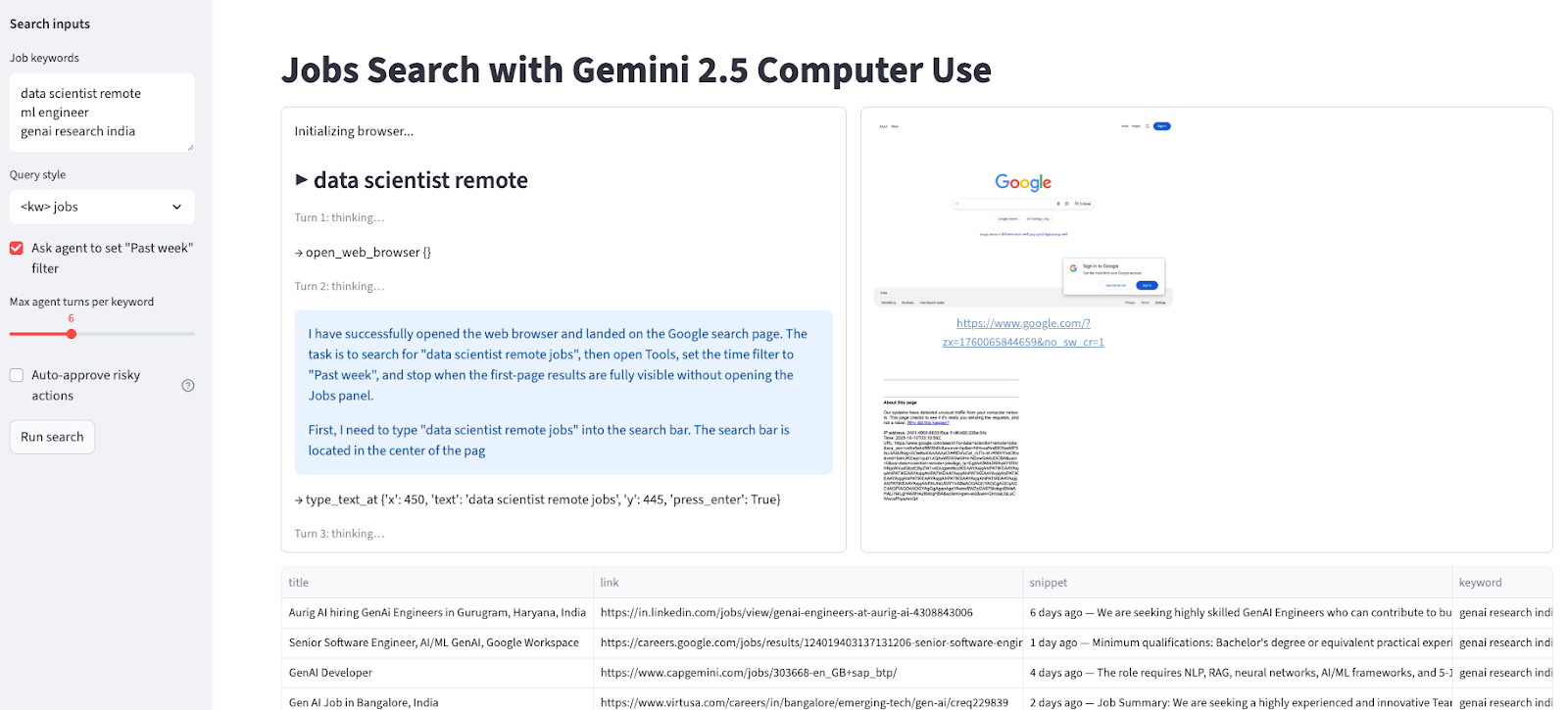
Dieser Schritt verbindet die Streamlit-Benutzeroberfläche mit der Schleife des Computer-Use-Agenten. Es zeigt die Benutzeroberfläche an, regelt, wie der Nutzer mit dem Agenten interagiert, und sorgt dafür, dass das Ergebnis den Bedürfnissen des Nutzers entspricht.
st.set_page_config(page_title="Jobs Search with Gemini Computer Use", layout="wide")
st.title("Jobs Search with Gemini 2.5 Computer Use")
with st.sidebar:
st.markdown("**Search inputs**")
default_kw = "data scientist remote\nml engineer \ngenai research india"
kw_text = st.text_area("Job keywords", value=default_kw, height=120)
query_mode = st.selectbox("Query style", ["<kw> jobs", 'site:linkedin.com/jobs "<kw>"'], index=0)
use_past_week = st.checkbox('Ask agent to set "Past week" filter', value=True)
turns = st.slider("Max agent turns per keyword", 3, 12, 6)
auto_confirm = st.checkbox("Auto-approve risky actions", value=False, help="If model requests confirmation (e.g., CAPTCHA), auto-approve instead of pausing.")
run_btn = st.button("Run search")
log_col, shot_col = st.columns([0.45, 0.55])
log_box = log_col.container(height=520)
shot_box = shot_col.container(height=520)
table_box = st.container()
if run_btn:
keywords = [k.strip() for k in kw_text.splitlines() if k.strip()]
all_rows = []
log_box.write("Initializing browser...")
pw = sync_playwright().start()
browser = pw.chromium.launch(headless=False)
ctx = browser.new_context(viewport={"width": W, "height": H})
page = ctx.new_page()
try:
for kw in keywords:
log_box.subheader(f"▶ {kw}")
page.goto("https://www.google.com", timeout=30000)
initial_shot = page.screenshot(type="png")
base_query = f'{kw} jobs' if query_mode == "<kw> jobs" else f'site:linkedin.com/jobs "{kw}"'
goal = (
f'Search Google for "{base_query}". '
f'{"Open Tools and set time filter to Past week. " if use_past_week else ""}'
'Stop when first-page results are fully visible; do NOT open the Jobs panel.'
)
contents = [Content(role="user", parts=[Part(text=goal), Part.from_bytes(data=initial_shot, mime_type="image/png")])]
cfg = types.GenerateContentConfig(
tools=[types.Tool(computer_use=types.ComputerUse(
environment=types.Environment.ENVIRONMENT_BROWSER
))]
)
for turn in range(turns):
log_box.caption(f"Turn {turn+1}: thinking…")
resp = client.models.generate_content(model=MODEL, contents=contents, config=cfg)
cand = resp.candidates[0]
contents.append(cand.content)
narr = " ".join([p.text for p in cand.content.parts if getattr(p, "text", None)])
if narr:
log_box.info(narr[:400])
fcs = [p.function_call for p in cand.content.parts if getattr(p, "function_call", None)]
if not fcs:
log_box.success("Agent stopped proposing actions.")
break
for fc in fcs:
log_box.write(f"→ {fc.name} {fc.args or {}}")
results = exec_calls(cand, page, (W, H), approve_all=auto_confirm)
frs, shot = fr_from(page, results)
contents.append(Content(role="user", parts=[Part(function_response=fr) for fr in frs]))
shot_box.image(shot, caption=page.url, width='stretch')
rows = scrape_google_serp(page)
for r in rows:
r["keyword"] = kw
all_rows.extend(rows)
log_box.success(f"{kw}: collected {len(rows)} results")
if all_rows:
table_box.dataframe(all_rows, width='stretch')
to_csv_download(all_rows, name="jobs_google_results.csv")
else:
st.warning("No rows collected. Try fewer keywords or fewer turns.")
finally:
browser.close()
pw.stop()Schauen wir uns diese Pipeline mal genauer an:
Um diese App zu starten, gib einfach den folgenden Bash-Befehl in deinem Terminal ein:
python -m streamlit run app.pyTipp: Starte Streamlit immer über deine venv, um Probleme mit „ModuleNotFoundError” zu vermeiden.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
Tutorial
Mark Pedigo