La plupart des fournisseurs de LLM, comme OpenAI et Anthropic, proposent des API conviviales pour intégrer leurs modèles dans des applications d'IA personnalisées. Mais cette convivialité a un coût : vous ne pourrez plus utiliser des interfaces web familières comme ChatGPT ou Claude. Votre application sera autonome et écrite en plusieurs scripts.
C'est pourquoi il est essentiel d'apprendre à envelopper le code de votre application d'une interface utilisateur conviviale afin que les utilisateurs externes et les parties prenantes sans connaissances techniques puissent interagir avec elle.
Dans ce tutoriel, vous apprendrez à construire des interfaces utilisateur Streamlit pour des applications basées sur LLM et construites avec LangChain. Le tutoriel sera pratique : nous utiliserons une base de données réelle de l'histoire du football international pour construire un chatbot qui peut répondre à des questions sur les matchs historiques et les détails des compétitions internationales. Vous pouvez jouer avec l'application ou la regarder en action ci-dessous :
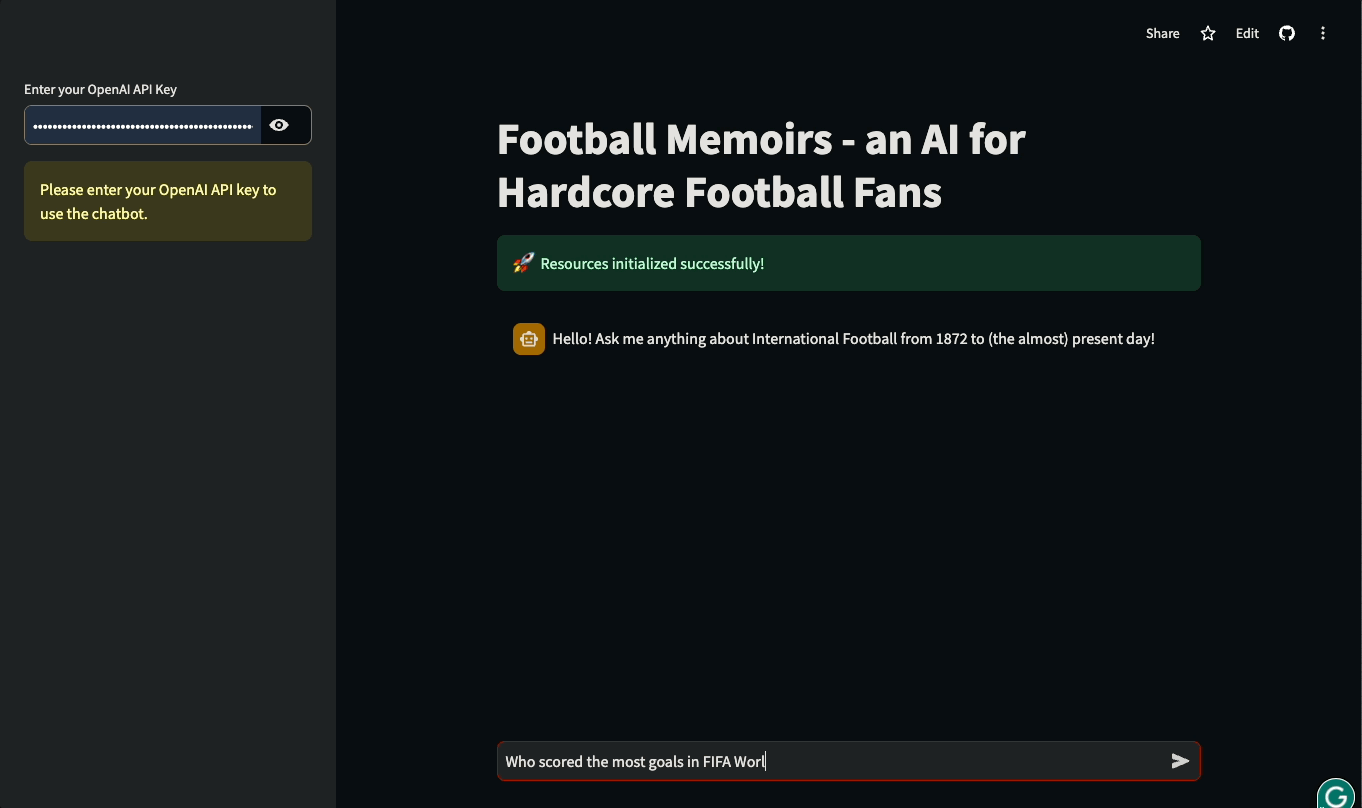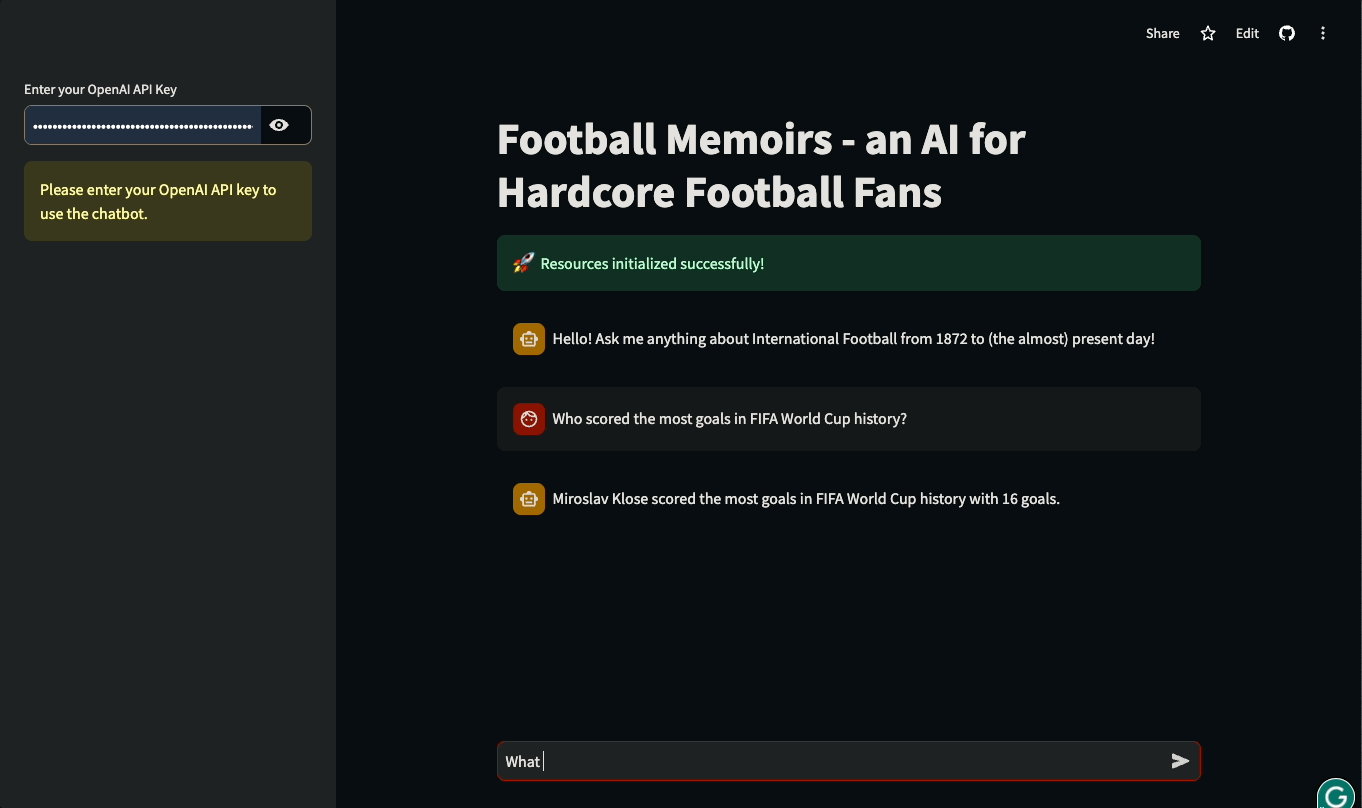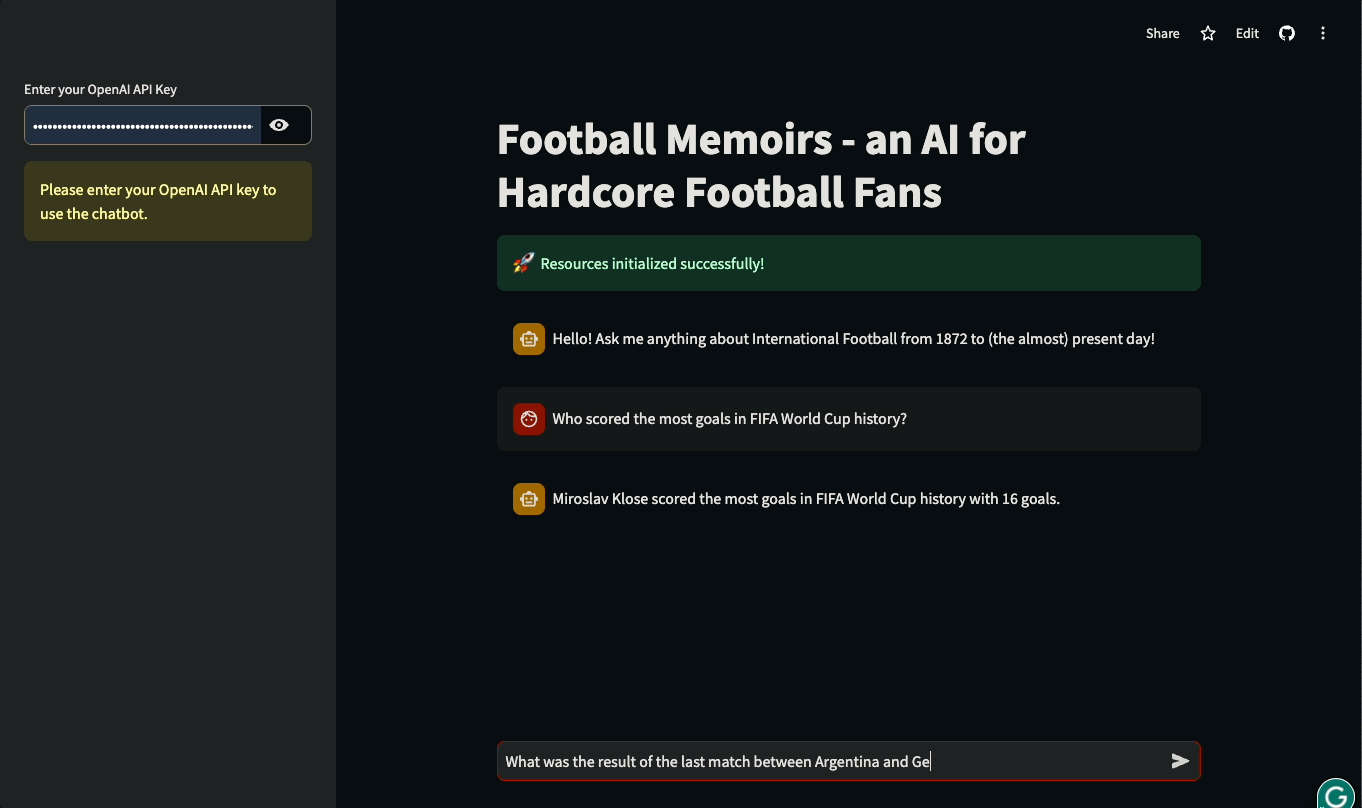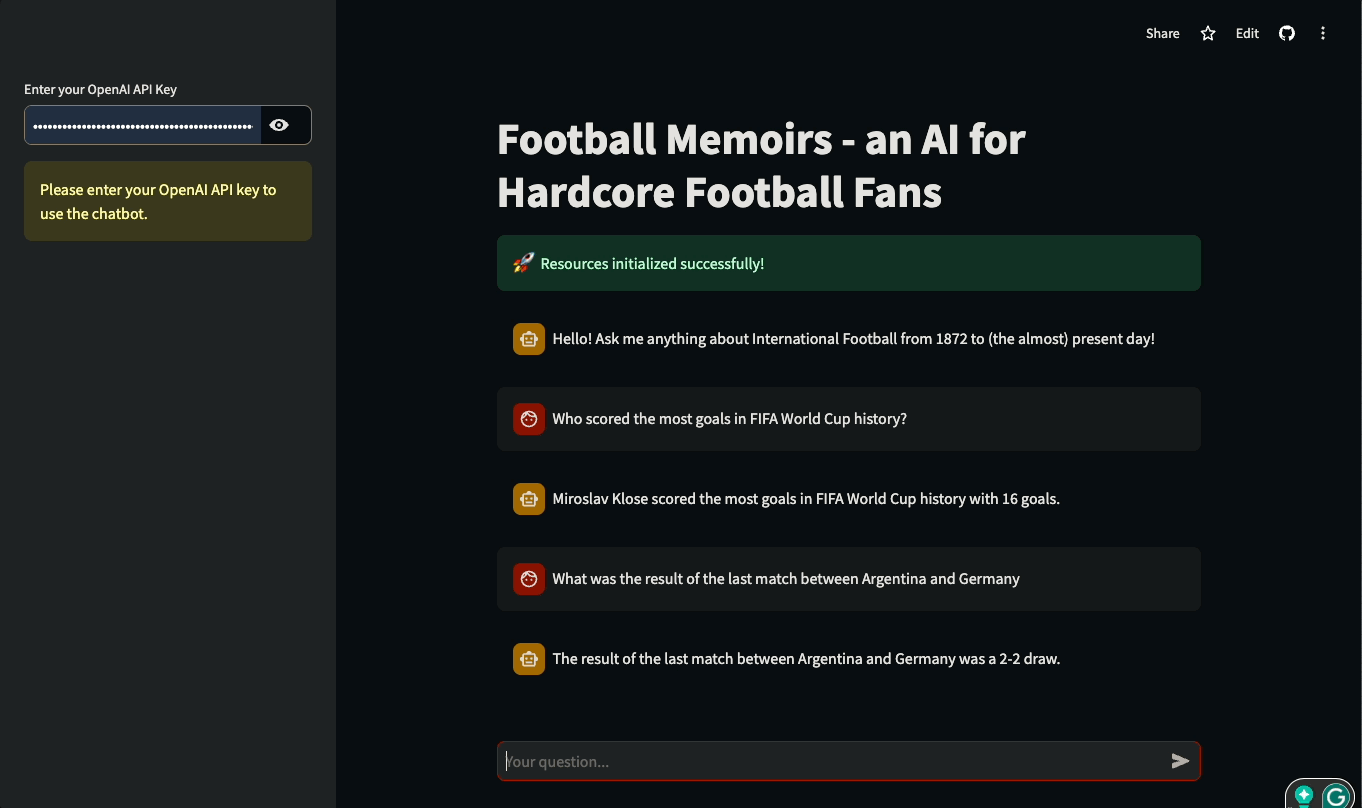
Plongeons dans l'aventure et commençons à construire !
Concepts préalables Remise à niveau
Nous utiliserons une combinaison de différents outils pour construire le chatbot que vous avez vu ci-dessus, alors passons brièvement en revue les objectifs de chacun.
Streamlit
Le premier outil est Streamlitqui est de loin le framework le plus populaire pour construire des applications web en utilisant uniquement Python. Il compte plus de 35 000 étoiles et est utilisé par la plupart des entreprises du classement Fortune 50.
Streamlit offre un riche ensemble de composants web intégrés pour afficher des données et des médias, ainsi que des éléments pour recueillir les données de l'utilisateur. Avec l'essor des LLM, ils disposent désormais de composants permettant d'afficher les messages de chat produits à la fois par les utilisateurs et les LLM, ainsi que d'un champ de saisie de texte pour la rédaction de messages-guides, ressemblant à l'interface de ChatGPT.
Si vous êtes totalement novice en matière de Streamlit, lisez notre article d'introduction sur le framework.
LangChain
Bien que les fournisseurs de LLM disposent d'API conviviales pour les développeurs, leur fonctionnalité n'est pas exhaustive. Leur intégration aux outils open-source existants nécessite beaucoup de temps et d'efforts.
C'est pourquoi le LangChain est né. Il rassemble presque tous les principaux LLM sous une syntaxe unifiée et fournit des utilitaires pour simplifier le processus de construction d'applications complexes d'IA. LangChain offre une large gamme d'outils et de composants qui permettent aux développeurs de créer de puissants systèmes d'intelligence artificielle avec moins de code et plus de flexibilité.
Voici quelques-unes des principales caractéristiques de LangChain :
- Intégration transparente avec différents fournisseurs de LLM
- Support intégré pour une ingénierie et une gestion rapides
- Outils pour la gestion de la mémoire et de l'état dans l'IA conversationnelle
- Utilitaires pour le chargement, la transformation et la vectorisation des données
- Composants pour la construction de chaînes et d'agents pour l'automatisation de tâches complexes
Dans ce tutoriel, nous utiliserons LangChain pour intégrer les modèles GPT d'OpenAI, gérer notre historique de conversation et construire notre pipeline de recherche pour accéder à la base de données de football.
Lisez notre guide du débutant sur LangChain pour en savoir plus.
Bases de données graphiques, Neo4j et AuraDB
Le graphique est la deuxième structure de base de données la plus répandue (après le tableau). Les bases de données graphiques sont de plus en plus adoptées en raison de leur capacité innée à stocker des informations interconnectées. Notre base de données sur le football international en est un parfait exemple.
Les bases de données graphiques sont constituées de nœuds et de relations entre eux. Par exemple, si nous considérons les termes clés du football comme les nœuds d'un graphique, la manière dont ils sont liés les uns aux autres représente les relations entre les nœuds. Dans ce cas, les nœuds sont des joueurs, des matchs, des équipes, des compétitions, etc. Les relations seraient les suivantes :
- Le joueur joue dans un match
- Les équipes PARTICIPENT à un match
- Le match fait partie d'une compétition
Ensuite, les nœuds et les relations pourraient avoir des propriétés telles que :
- Joueur : âge, fonction, nationalité
- Match : équipe à domicile, équipe à l'extérieur, score, lieu
- JOUE (relation) : nombre de buts marqués, nombre de minutes jouées
et ainsi de suite.
Neo4j est le système de gestion le plus populaire pour de telles bases de données graphiques. Son langage de requête, Cypherest très similaire à SQL, mais il est spécialement conçu pour parcourir des structures graphiques complexes. LangChain utilisera le client Python officiel de Neo4j sous le capot pour générer et exécuter des requêtes Python contre notre base de données de graphes. Consultez notre tutoriel Neo4j pour en savoir plus.
À ce propos, notre base de données est hébergée sur une instance cloud d'Aura DB. Aura DB fait partie de Neo4j et fournit une plateforme sécurisée pour gérer les bases de données de graphes sur le cloud.
Récupération Génération augmentée
Les LLM sont formés à l'utilisation de grandes quantités de données, mais ils n'ont pas accès aux bases de données privées détenues par les entreprises. C'est pourquoi le cas d'utilisation le plus courant des LLM dans l'entreprise est le suivant Génération Augmentée de Récupération (RAG).
Dans le RAG, le LLM est complété par des informations pertinentes extraites d'une base de connaissances ou d'une base de données avant de générer une réponse. Ce processus comporte généralement les étapes suivantes :
- Comprendre les requêtes: Le système analyse la requête de l'utilisateur pour en comprendre l'intention et les éléments clés.
- Recherche d'informations: En fonction de l'analyse de la requête, les informations pertinentes sont extraites de la base de données ou de la base de connaissances connectée.
- Augmentation du contexte: Les informations récupérées sont ajoutées à l'invite envoyée au LLM, lui fournissant un contexte spécifique, actualisé et pertinent.
- Génération de réponses: Le LLM génère une réponse basée à la fois sur ses connaissances pré-entraînées et sur le contexte supplémentaire fourni.
- Raffinement des sorties: La réponse générée peut être traitée ou filtrée pour en garantir l'exactitude et la pertinence.
Le RAG permet aux LLM d'accéder à des informations spécifiques, actuelles et exclusives et de les utiliser, ce qui les rend plus utiles pour des applications spécialisées tout en conservant leurs capacités de compréhension de la langue générale.
Dans notre cas, nous utiliserons RAG pour compléter notre LLM avec des informations provenant de notre base de données sur le football, ce qui lui permettra de répondre à des questions spécifiques sur les joueurs, les matchs et les compétitions auxquelles il n'aurait pas accès autrement.
Vous pouvez acquérir une expérience pratique de la mise en œuvre de RAG en utilisant notre projet guidé sur la construction d'un chatbot RAG pour la documentation technique.
Comprendre les données
Examinons de plus près notre base de données graphique avant de commencer à la construire. Vous trouverez ci-dessous la visualisation du schéma du graphique :

Le graphe comporte six types de nœuds : joueur, équipe, match, tournoi, ville et pays. Ces nœuds sont reliés par plusieurs relations, telles que Team PLAYED_HOME dans un match ou Player SCORED_FOR a Team. Ce schéma est basé sur les données disponibles dans l'ensemble de données Kaggle suivant jeu de données Kaggle suivant:
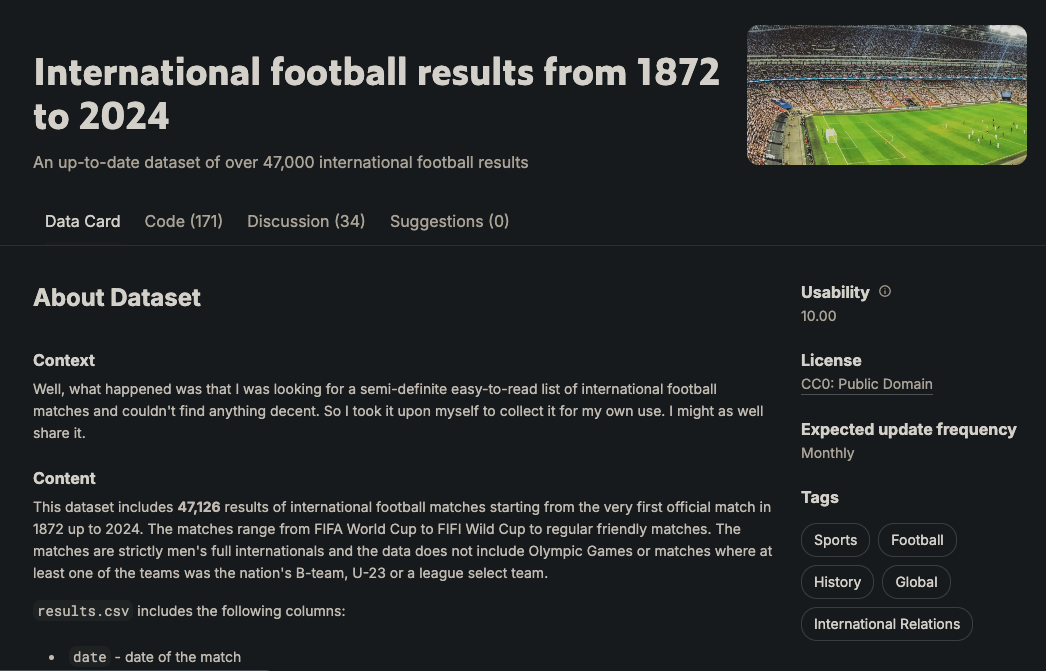
Il contient plus de 47 000 matchs, leurs résultats, les buts marqués lors de chaque match, qui les a marqués, et quelques propriétés supplémentaires comme les minutes de but, les buts contre son camp, et les lieux des matchs.
Les données sont à l'origine au format CSV, mais j'ai pu les intégrer dans une instance d'Aura DB en utilisant le pilote Python de Neo4j et des requêtes Cypher (voir le code dans notre tutoriel Neo4j).
L'objectif de notre application (jeu de mots) est de générer des requêtes Cypher basées sur les entrées de l'utilisateur, d'exécuter les requêtes sur notre base de données graphique et de présenter les résultats dans un format lisible par l'homme.
Alors, construisons-le enfin.
Construire un Chatbot Graph RAG avec LangChain
Nous allons aborder ce problème étape par étape, de la création d'un environnement de travail au déploiement de l'appli à l'aide de Streamlit Cloud.
1. Mise en place de l'environnement
Commençons par créer un nouvel environnement Conda avec Python 3.9 et activons-le :
$ conda create -n football_chatbot python=3.9 -y
$ conda activate football_chatbotNous devons installer les bibliothèques suivantes :
$ pip install streamlit langchain langchain-openai langchain_community neo4jMaintenant, créons notre répertoire de travail et remplissons sa structure :
$ mkdir football_chatbot; cd football_chatbot
$ mkdir .streamlit
$ touch {.streamlit/secrets.toml,app.py}Nous écrirons notre application dans le répertoireapp.py, tandis que le répertoiresecrets.toml dans le répertoire.streamlit servira de fichier d'identification. Ouvrez-le et collez les trois secrets suivants :
NEO4J_URI = "neo4j+s://eed9dd8f.databases.neo4j.io"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "ivbSF02UWzHeHuzBIePyOH5cQ4LdyRxLeNbWvdpPA4k"Ces informations d'identification vous permettent d'accéder à l'instance Aura DB qui stocke la base de données du football. Si vous souhaitez créer votre propre instance avec les mêmes données, consultez notre tutoriel sur Neo4jqui couvre exactement cette étape.
2. Importer les bibliothèques et charger les secrets
Travaillons maintenant sur le fichierapp.py. En haut, importez les modules et paquets nécessaires et chargez les secrets à l'aide de st.secrets:
import streamlit as st
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
# Load secrets
neo4j_uri = st.secrets["NEO4J_URI"]
neo4j_user = st.secrets["NEO4J_USER"]
neo4j_password = st.secrets["NEO4J_PASSWORD"]Voici ce que fait chaque classe :
Neo4jGraph: Une classe abrégée pour se connecter aux bases de données Neo4j existantes et les interroger avec Cypher.GraphCypherQAChain: une classe complète permettant d'effectuer des RAG sur des bases de données de graphes. En passant notre graphe chargé avec Neo4jGraph, nous pouvons générer des requêtes Cypher en utilisant le langage naturel à l'aide de cette classe.ChatOpenAI: Permet d'accéder à l'API "Chat Completions" d'OpenAI.
3. Ajouter l'authentification
Pour éviter les utilisations malveillantes et les coûts élevés, nous devrions ajouter une authentification qui demande le jeton de l'API OpenAI de l'utilisateur. Pour ce faire, vous pouvez ajouter un formulaire de mot de passe dans la barre latérale gauche à l'aide de l' élément st.sidebar:
# Set the app title
st.title("Football Memoirs - an AI for Hardcore Football Fans")
# Sidebar for API key input
with st.sidebar:
openai_api_key = st.text_input("Enter your OpenAI API Key", type="password")
st.warning("Please enter your OpenAI API key to use the chatbot.")Dès que l'utilisateur charge notre application, le champ de saisie lui est présenté et rien d'autre ne s'affiche (à l'exception du titre de l'application) jusqu'à ce qu'il fournisse sa clé.
4. Connectez-vous à la base de données Neo4j et initialisez une chaîne d'assurance qualité.
Après avoir récupéré la clé API OpenAI de l'utilisateur, nous pouvons initialiser nos ressources : le graphe Neo4j et la classe de chaîne QA :
# Initialize connections and models
@st.cache_resource(show_spinner=False)
def init_resources(api_key):
graph = Neo4jGraph(
url=neo4j_uri,
username=neo4j_user,
password=neo4j_password,
enhanced_schema=True,
)
graph.refresh_schema()
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(api_key=api_key, model="gpt-4o"),
graph=graph,
verbose=True,
show_intermediate_steps=True,
allow_dangerous_requests=True,
)
return graph, chainLa fonctioninit_resources() accepte la clé API comme argument et établit une connexion avec la base de données graphique. Ensuite, il rafraîchit le schéma du graphe (structure) afin que le LLM puisse disposer d'informations actualisées sur la structure de la base de données lorsqu'il formule des requêtes Cypher. Enfin, il initialise la chaîne GraphCypherQAChain avec le graphe et le modèle OpenAI, renvoyant les objets graphe et chaîne pour une utilisation ultérieure dans l'application.
Il convient de noter l'utilisation du décorateurst.cache_resource(). Ce décorateur met en cache les instances du graphe et de la chaîne, ce qui améliore les performances. Nous n'avons pas besoin de créer de nouvelles instances à chaque fois qu'un utilisateur charge l'application, la mise en cache est donc une approche efficace.
Exécutons l'initialisateur avec une vérification de la clé API :
# Initialize resources only if API key is provided
if openai_api_key:
with st.spinner("Initializing resources..."):
graph, chain = init_resources(openai_api_key)
st.success("Resources initialized successfully!", icon="🚀")5. Ajouter l'historique des messages à Streamlit
Dès que les ressources sont disponibles, nous devons activer l'historique des messages en utilisant l'état de session de Streamlit. Nous voulons également afficher un message AI initial informant l'utilisateur de ce que fait le robot.
Pour ce faire, nous créons une nouvelle clé messages dans st.session_state et lui attribuons la valeur d'une liste à un seul élément. L'élément est un dictionnaire à deux clés :
role: A qui appartient le messagecontent: Le contenu du message
# Initialize message history
if "messages" not in st.session_state:
st.session_state.messages = [
{
"role": "assistant",
"content": "Hello! Ask me anything about International Football from 1872 to (the almost) present day!",
}
]S'il existe déjà un historique des messages à l'intérieur st.session_state.messagesnous les affichons avec st.chat_message et st.markdown composants :
# Display chat history
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])6. Afficher les composants du chat
Nous définissons maintenant une fonction, query_graph, qui exécutera la chaîne à l'aide d'une invite fournie par l'utilisateur. La méthode .invoke() de la chaîne accepte un dictionnaire avec une paire clé/valeur de requête/de demande et renvoie un autre dictionnaire en sortie. Nous voulons sa clé result:
def query_graph(query):
try:
result = chain.invoke({"query": query})["result"]
return result
except Exception as e:
st.error(f"An error occurred: {str(e)}")
return "I'm sorry, I encountered an error while processing your request."Maintenant, affichons un champ de saisie au bas de la page à l'aide du composant st.chat_input pour afficher un champ de saisie au bas de la page :
# Accept user input
if prompt := st.chat_input("Your question..."):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)Dès que l'invite est fournie, nous la stockons en tant que message d'utilisateur dans l'historique des messages et l'affichons à l'écran. Ensuite, avec une autre vérification de la clé API, nous exécutons la fonction query_graph, en transmettant l'invite :
if prompt := st.chat_input("Your question..."):
...
# Generate answer if API key is provided
if openai_api_key:
with st.spinner("Thinking..."):
response = query_graph(prompt)
with st.chat_message("assistant"):
st.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response})
else:
st.error("Please enter your OpenAI API key in the sidebar to use the chatbot.")Nous ajoutons un widget spinner pendant que la requête Cypher et la réponse finale sont générées. Ensuite, nous affichons le message et l'ajoutons à l'historique des messages.
C'est tout ! L'application est maintenant prête :
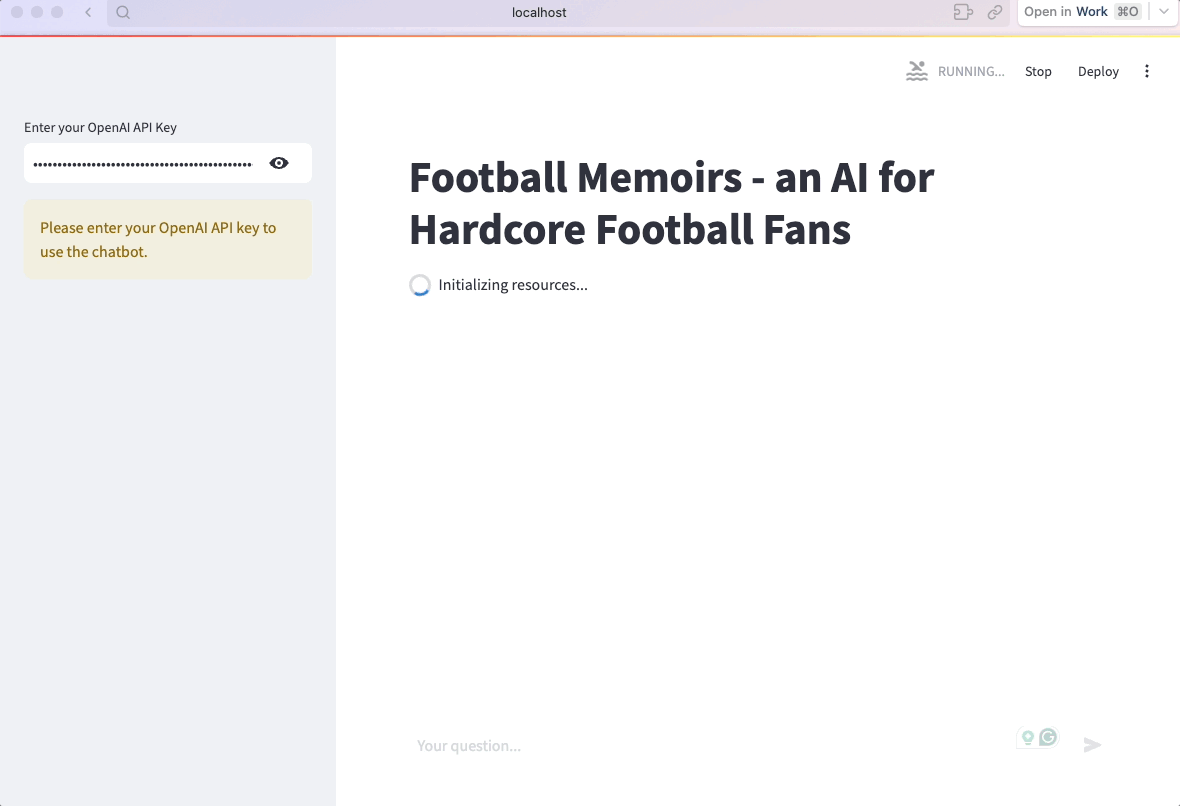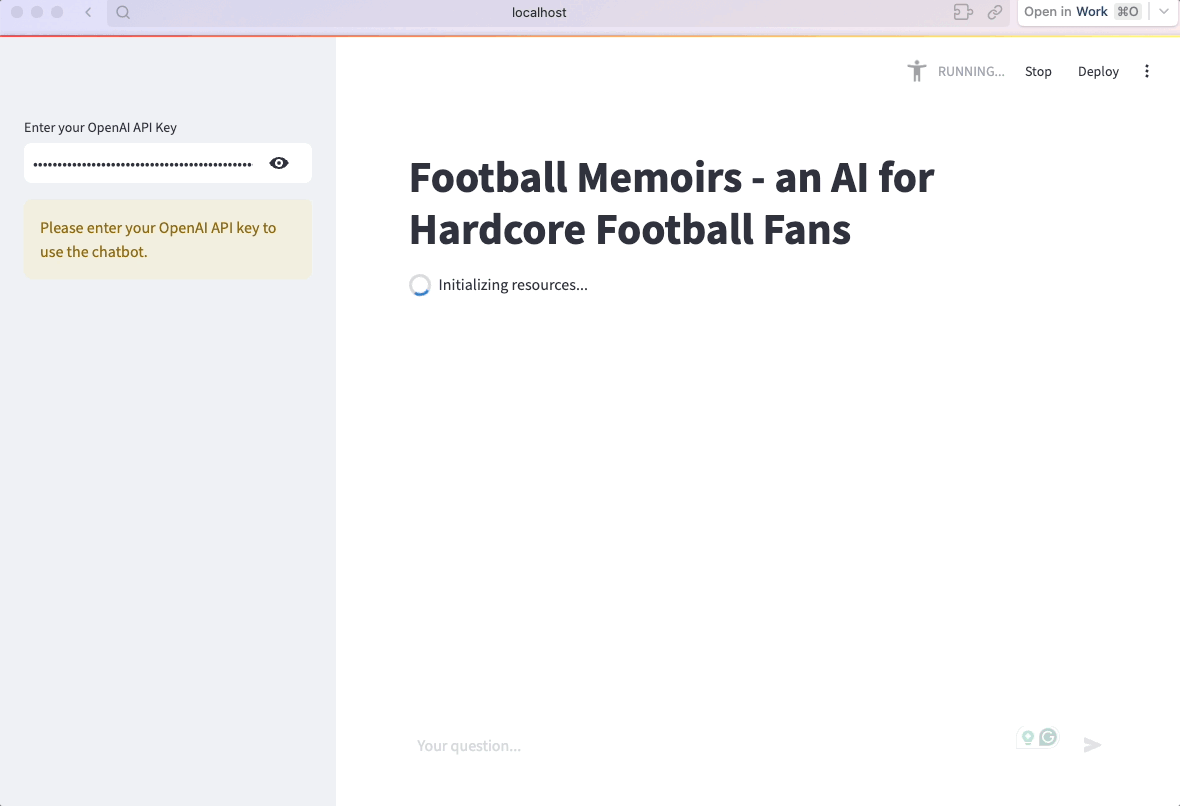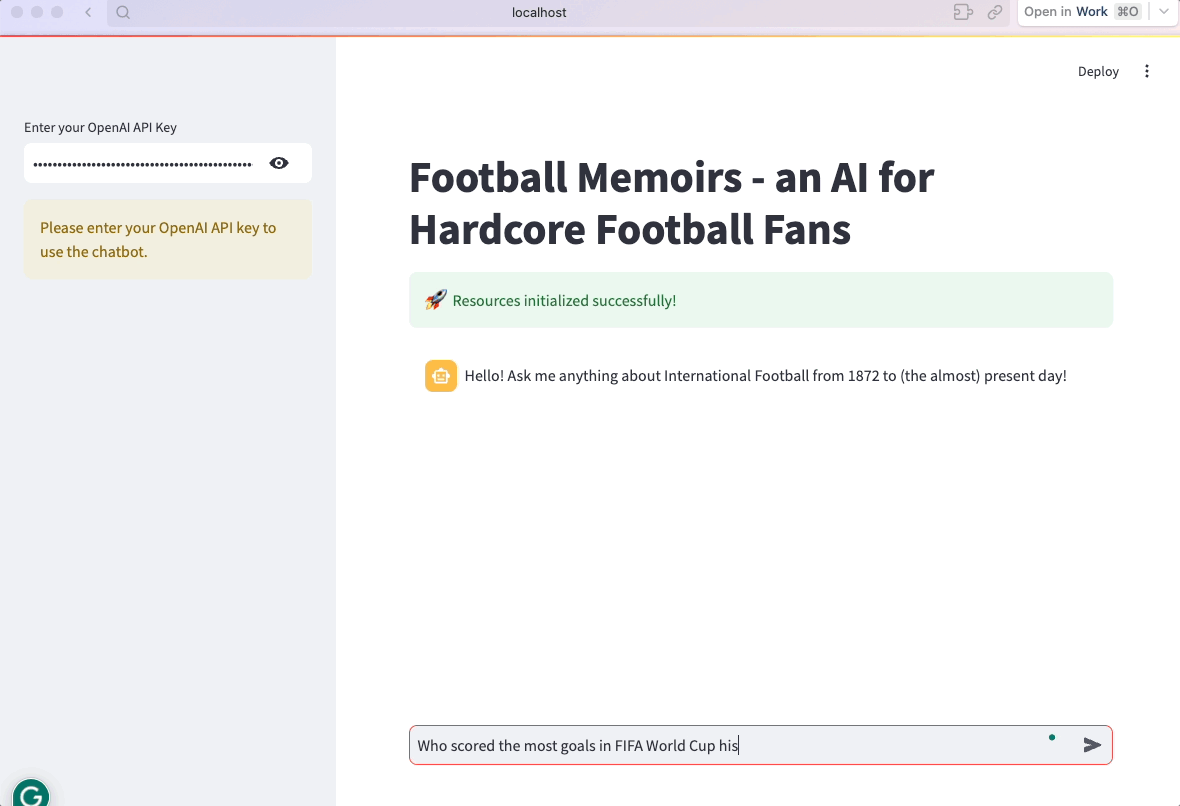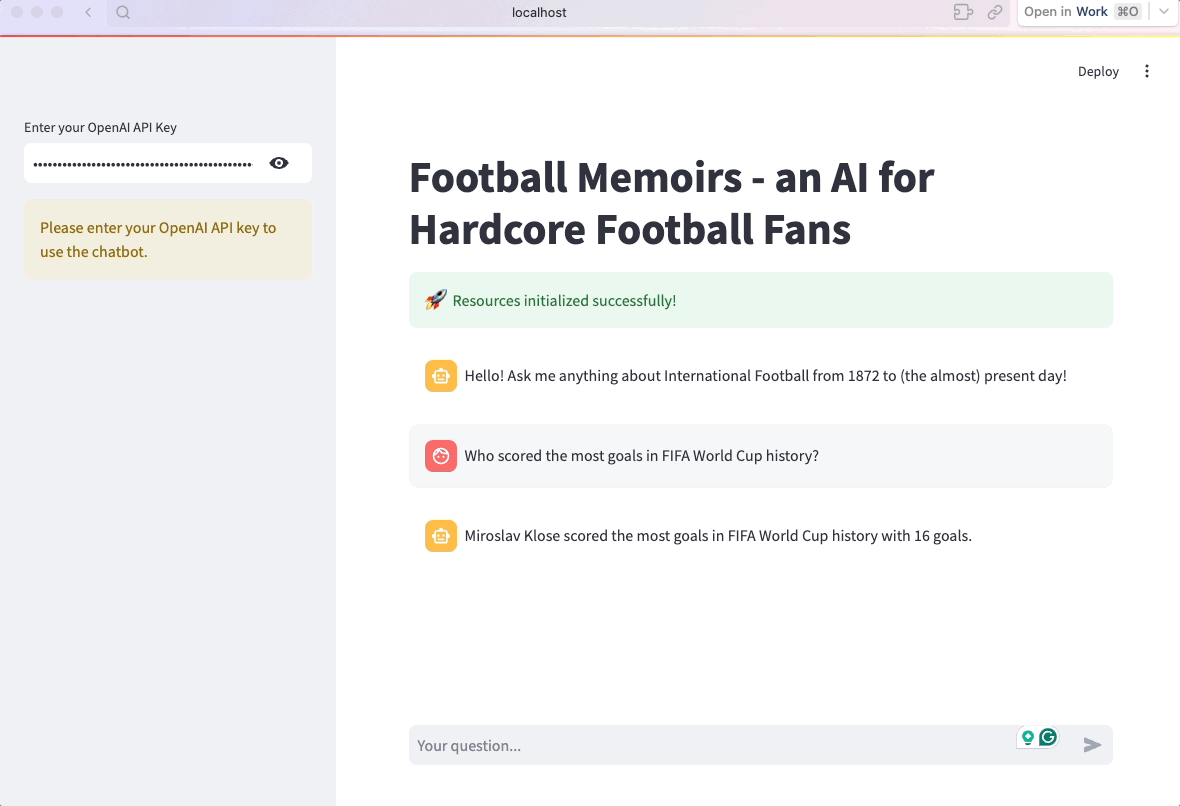
7. Optimiser et organiser le code
L'application est prête, mais elle est écrite dans un seul fichier sans structure optimisée. Réorganisons-le et rendons-le modulaire :
$ cd football_chatbot
$ rm -rf . # Start from scratch
$ mkdir .streamlit
$ touch {.streamlit/secrets.toml,.gitignore,app.py,chat_utils.py,graph_utils.py,README.MD,requirements.txt}Cette fois, notre structure de répertoire contient quelques fichiers supplémentaires :
.
├── .git
├── .gitignore
├── .streamlit
├── README.md
├── app.py
├── chat_utils.py
├── graph_utils.py
├── requirements.txtMaintenant, à l'intérieur de graph_utils.pycollez le code organisé suivant :
# graph_utils.py
import streamlit as st
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
@st.cache_resource(show_spinner=False)
def init_resources(api_key):
graph = Neo4jGraph(
url=st.secrets["NEO4J_URI"],
username=st.secrets["NEO4J_USER"],
password=st.secrets["NEO4J_PASSWORD"],
enhanced_schema=True,
)
graph.refresh_schema()
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(api_key=api_key, model="gpt-4o"),
graph=graph,
verbose=True,
show_intermediate_steps=True,
allow_dangerous_requests=True,
)
return graph, chain
def query_graph(chain, query):
result = chain.invoke({"query": query})["result"]
return resultIci, la différence se situe au niveau de la fonctionquery_graph. En particulier, il n'y a pas de gestion des erreurs ni d'affichage à l'aide de la fonction st.error. Nous déplacerons cette partie dans le fichier principal app.py.
Travaillons maintenant sur le chat_utils.py fichier :
# chat_utils.py
import streamlit as st
def initialize_chat_history():
if "messages" not in st.session_state:
st.session_state.messages = [
{
"role": "assistant",
"content": "Hello! Ask me anything about International Football from 1872 to (the almost) present day!",
}
]
def display_chat_history():
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])Tout d'abord, nous créons deux fonctions :
initialize_chat_history: Activez l'historique des messages avec un message par défaut s'il n'est pas déjà disponible.display_chat_history: Afficher tous les messages dans l'historique des messages.
Nous créons une autre fonction pour gérer les invites et la génération des réponses :
# chat_utils.py
def handle_user_input(openai_api_key, query_graph_func, chain):
if prompt := st.chat_input("Your question..."):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
if openai_api_key:
with st.spinner("Thinking..."):
try:
response = query_graph_func(chain=chain, query=prompt)
except Exception as e:
st.error(f"An error occurred: {str(e)}")
response = "I'm sorry, I encountered an error while processing your request."
with st.chat_message("assistant"):
st.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response})
else:
st.error(
"Please enter your OpenAI API key in the sidebar to use the chatbot."
)La différence ici est l'utilisation d'un bloc try-except autour de query_graph_func pour détecter et afficher les erreurs. Le reste de la fonctionnalité est identique.
Enfin, à l'intérieur de app.pynous avons tout rassemblé :
import streamlit as st
from graph_utils import init_resources, query_graph
from chat_utils import initialize_chat_history, display_chat_history, handle_user_input
st.title("Football Memoirs - an AI for Hardcore Football Fans")
# Sidebar for API key input
with st.sidebar:
openai_api_key = st.text_input("Enter your OpenAI API Key", type="password")
st.warning("Please enter your OpenAI API key to use the chatbot.")Nous importons les fonctions d'autres fichiers, définissons le titre de l'application et ajoutons le champ de saisie de la clé API dans la barre latérale gauche. Ensuite, après vérification de la clé API, nous initialisons les ressources et affichons l'historique des messages de chat et les composants :
# Initialize resources only if the API key is provided
if openai_api_key:
with st.spinner("Initializing resources..."):
graph, chain = init_resources(openai_api_key)
st.success("Resources initialized successfully!", icon="🚀")
# Initialize and display chat history
initialize_chat_history()
display_chat_history()
# Handle user input
handle_user_input(
openai_api_key=openai_api_key, query_graph_func=query_graph, chain=chain
)L'application est maintenant prête à être déployée !
8. Déployer l'application dans le cloud Streamlit
La méthode la plus simple et la moins contraignante pour déployer les apps Streamlit consiste à utiliser Streamlit Cloud. Toutes les apps hébergées sur Streamlit Cloud sont gratuites tant que vous utilisez le matériel par défaut.
Mais tout d'abord, ajoutons ces deux lignes à notre fichier .gitignore afin que les secrets de notre application ne soient pas affichés sur GitHub :
*.toml
__pycache__De plus, tout (bon) dépôt a besoin d'un fichier README. Alors, écrivons les nôtres :
# Football Memoirs - AI for Hardcore Football Fans
This Streamlit app uses a Neo4j graph database and OpenAI's GPT-4o model to answer questions about international football history from 1872 to the present day.
## Setup
1. Clone this repository
2. Install dependencies: pip install -r requirements.txt
3. Set up your .streamlit/secrets.toml file with the following keys:
- NEO4J_URI
- NEO4J_USER
- NEO4J_PASSWORD
4. Run the app: streamlit run app.py
## Deployment
To deploy this app on Streamlit Cloud:
1. Push your code to a GitHub repository
2. Connect your GitHub account to Streamlit Cloud
3. Create a new app in Streamlit Cloud and select your repository
4. Add your secrets in the Streamlit Cloud dashboard under the "Secrets" section
5. Deploy your appLes apps Streamlit Cloud ont besoin d'un fichierrequirements.txt pour alimenter les environnements en dépendances. Ajoutez-les aux vôtres :
streamlit
langchain
langchain-community
langchain-openai
neo4jMaintenant, nous allons initialiser git, faire notre premier commit, et le pousser vers le dépôt distant que vous devriez avoir créé pour le projet :
$ git init
$ git add .
$ git commit -m "Initial commit"
$ git remote add origin https://github.com/Username/repository.git
$ git push --set-upstream origin mainEnsuite, inscrivez-vous à Streamlit Cloud, rendez-vous sur votre tableau de bord et cliquez sur "Créer une application" :
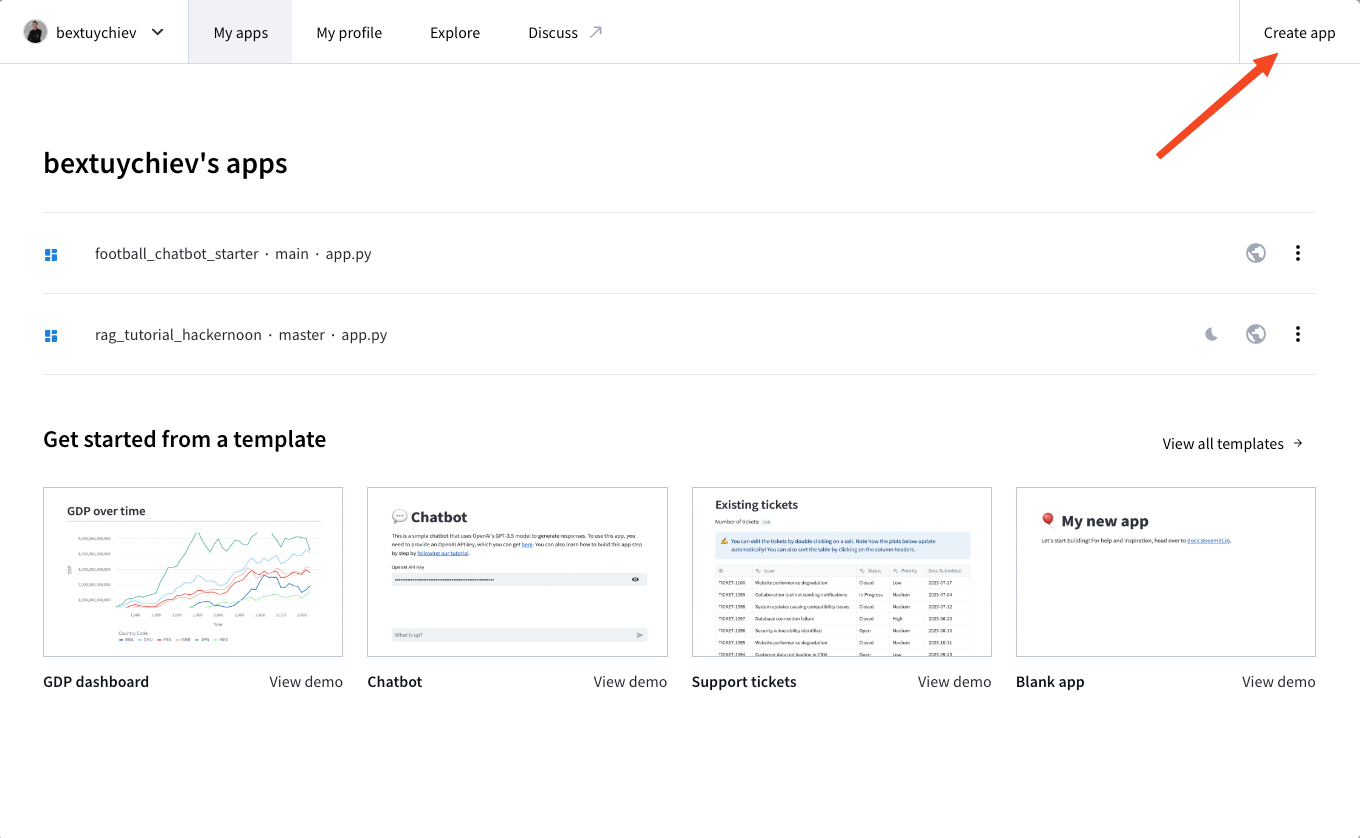
Les options suivantes vous sont proposées :
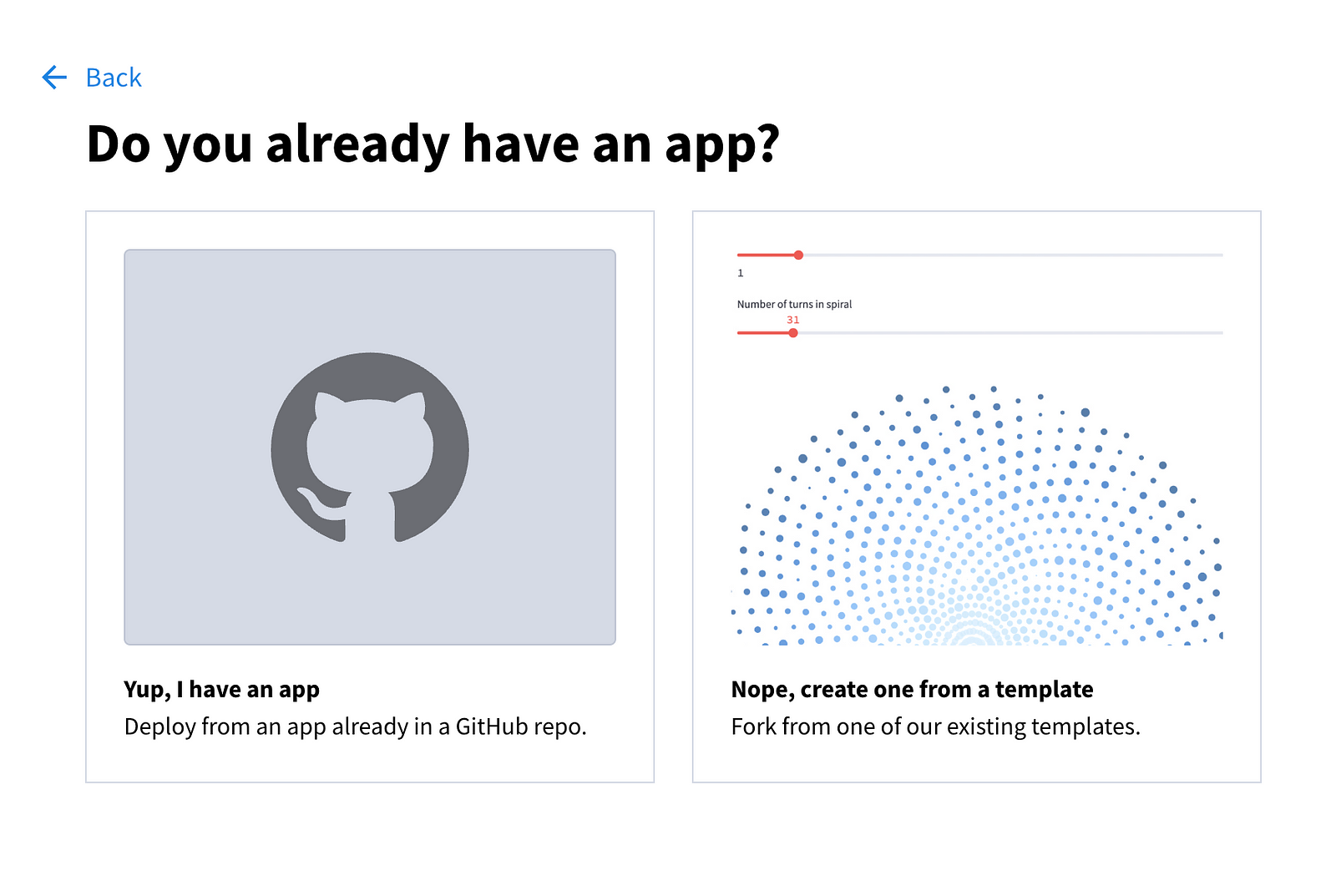
Choisissez la première option et remplissez les champs de la page suivante.
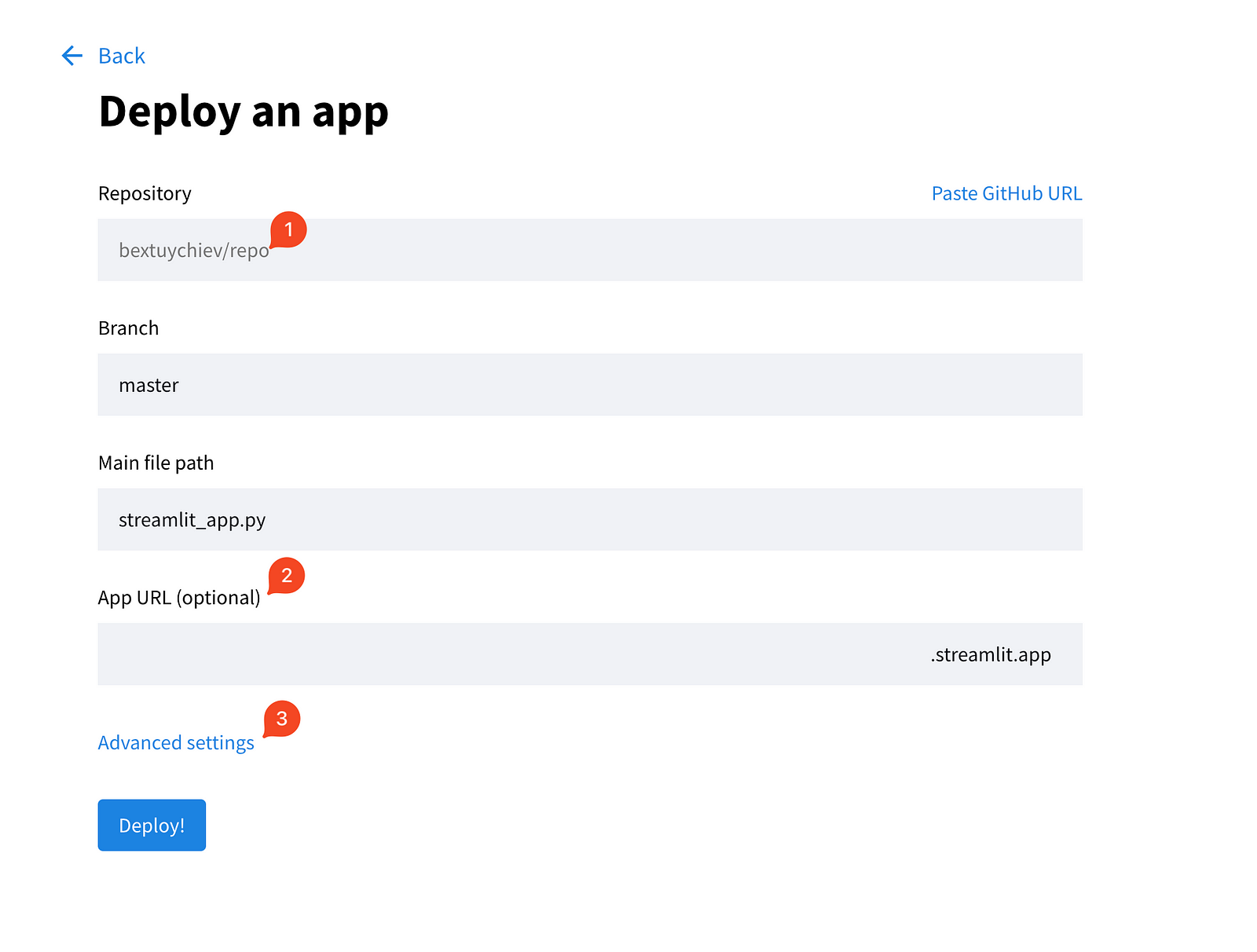
Développez également les paramètres avancés, qui vous offrent deux champs pour choisir la version de Python et coller les informations d'identification dont votre application a besoin. C'est ici que vous copiez/collez le contenu du fichier local secrets.toml:
Enregistrez les secrets et cliquez sur "Déployer". L'application devrait être opérationnelle en quelques minutes !
Conclusion
Dans ce tutoriel, nous avons construit un chatbot IA qui répond à des questions sur l'histoire du football international en utilisant Streamlit, LangChain et une base de données de graphes Neo4j. Nous avons couvert :
- Créer une interface web conviviale avec Streamlit
- Intégration des modèles GPT d'OpenAI avec une base de données de graphes à l'aide de LangChain
- Mise en œuvre de la Génération Augmentée de Récupération (GAR)
- Construire une base de code modulaire
- Déploiement dans le cloud Streamlit
Ce projet sert de modèle pour la création d'interfaces utilisateur d'IA de chat. Bien que la logique de l'application soit différente dans chaque projet, les composants de l'interface utilisateur que nous avons utilisés aujourd'hui seront utilisés dans la plupart d'entre eux d'une manière ou d'une autre.
Notez également que la construction de l'interface utilisateur est la partie la plus facile de la création d'applications d'IA. La majeure partie de votre temps sera consacrée à l'amélioration des performances de l'application. Par exemple, notre pipeline de génération Cypher nécessite encore beaucoup de travail. En raison du manque d'exemples, de la structure vague du graphe et des limites des LLM, la précision de notre application n'est pas acceptable pour la production. Gardez ces aspects à l'esprit lorsque vous créez vos applications.
Si vous souhaitez en savoir plus sur le développement de grands modèles de langage, consultez notre parcours de compétences, qui couvre la construction de LLM avec PyTorch et Hugging Face, en utilisant les dernières techniques d'apprentissage profond et de NLP.
