A maioria dos provedores de LLM, como OpenAI e Anthropic, oferece APIs fáceis de usar para integrar seus modelos a aplicativos de IA personalizados. Mas essa facilidade de uso tem um custo: você não poderá mais usar interfaces da Web conhecidas, como o ChatGPT ou o Claude. Seu aplicativo será autônomo e escrito em vários scripts.
Por esse motivo, é fundamental aprender a envolver o código do aplicativo com uma interface de usuário amigável para que os usuários externos e as partes interessadas sem conhecimento técnico possam interagir com ele.
Neste tutorial, você aprenderá a criar UIs Streamlit para aplicativos baseados em LLM criados com LangChain. O tutorial será prático: usaremos um banco de dados real da história do futebol internacional para criar um chatbot que possa responder a perguntas sobre partidas históricas e detalhes de competições internacionais. Você pode brincar com o aplicativo ou assisti-lo em ação abaixo:
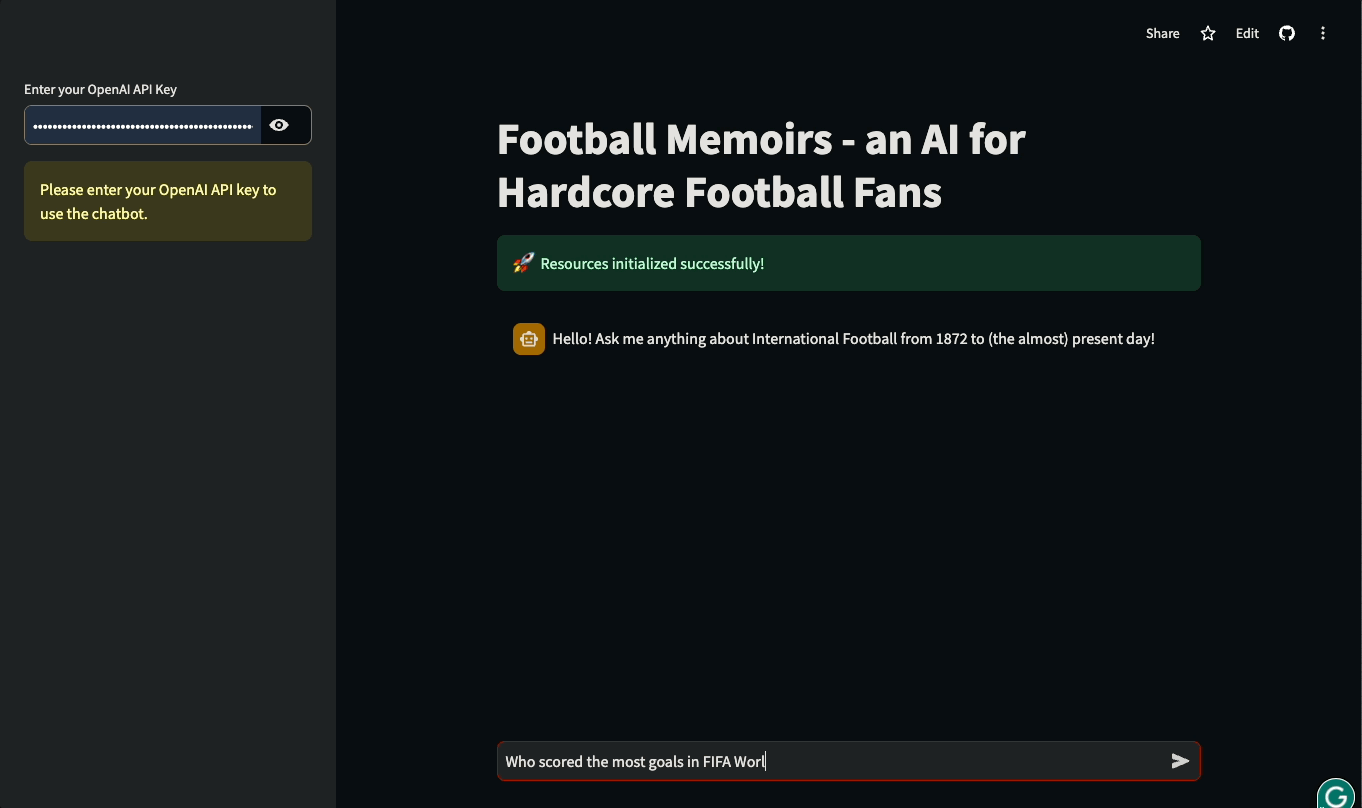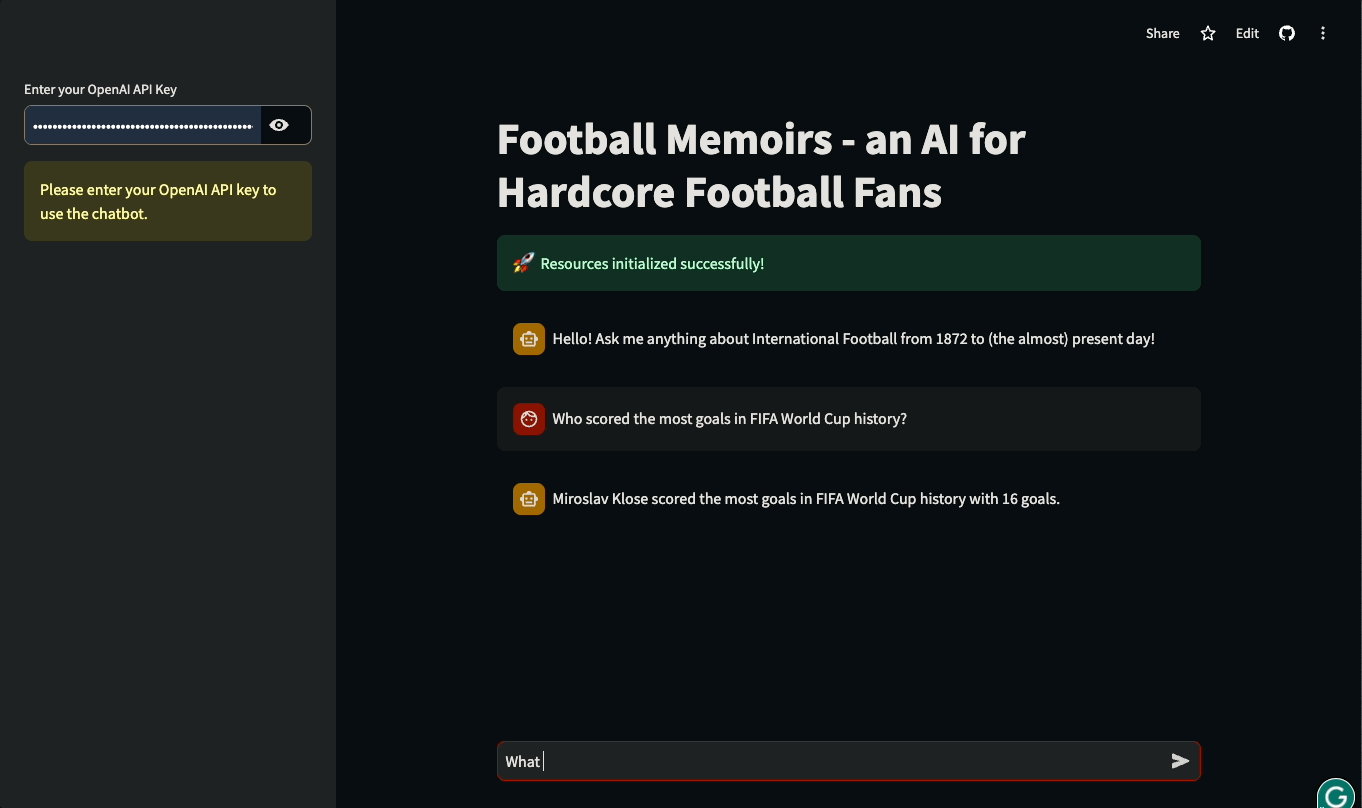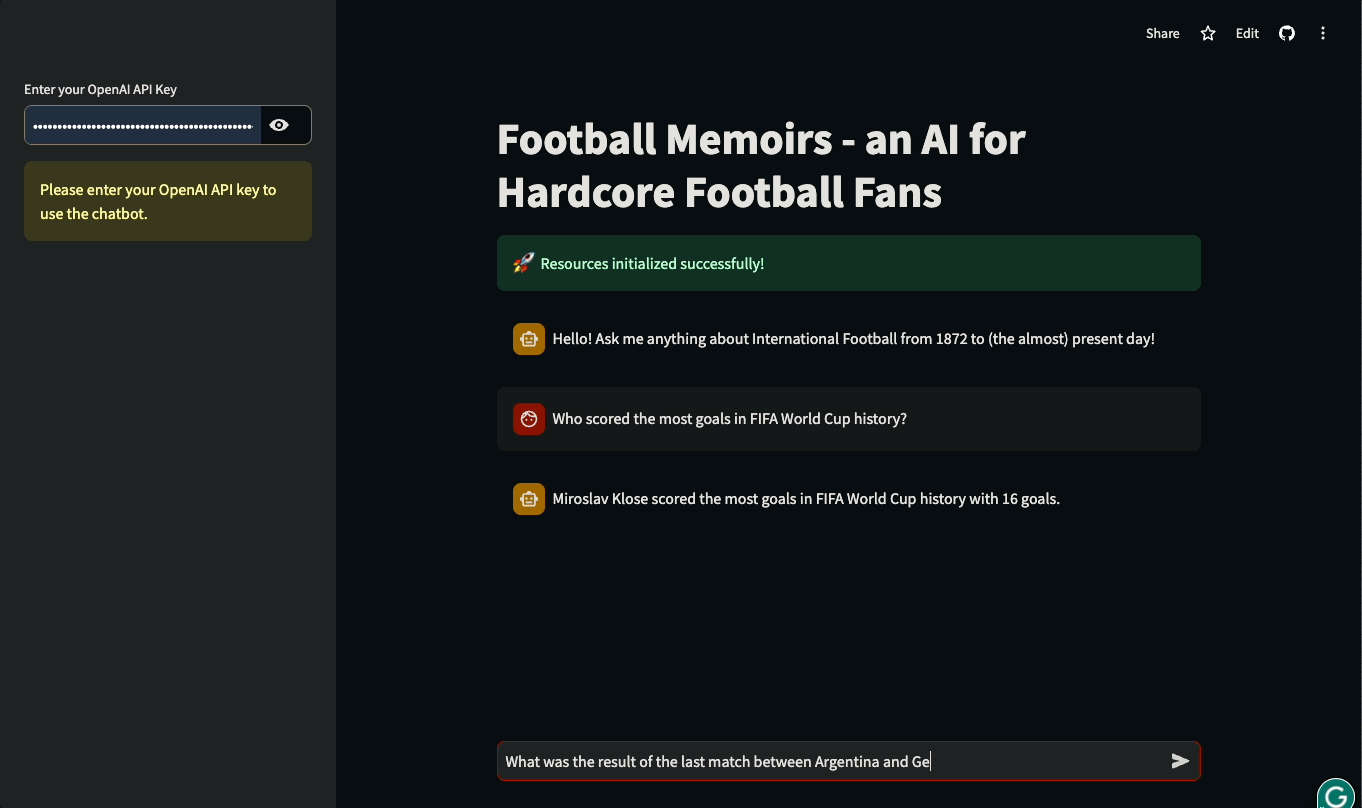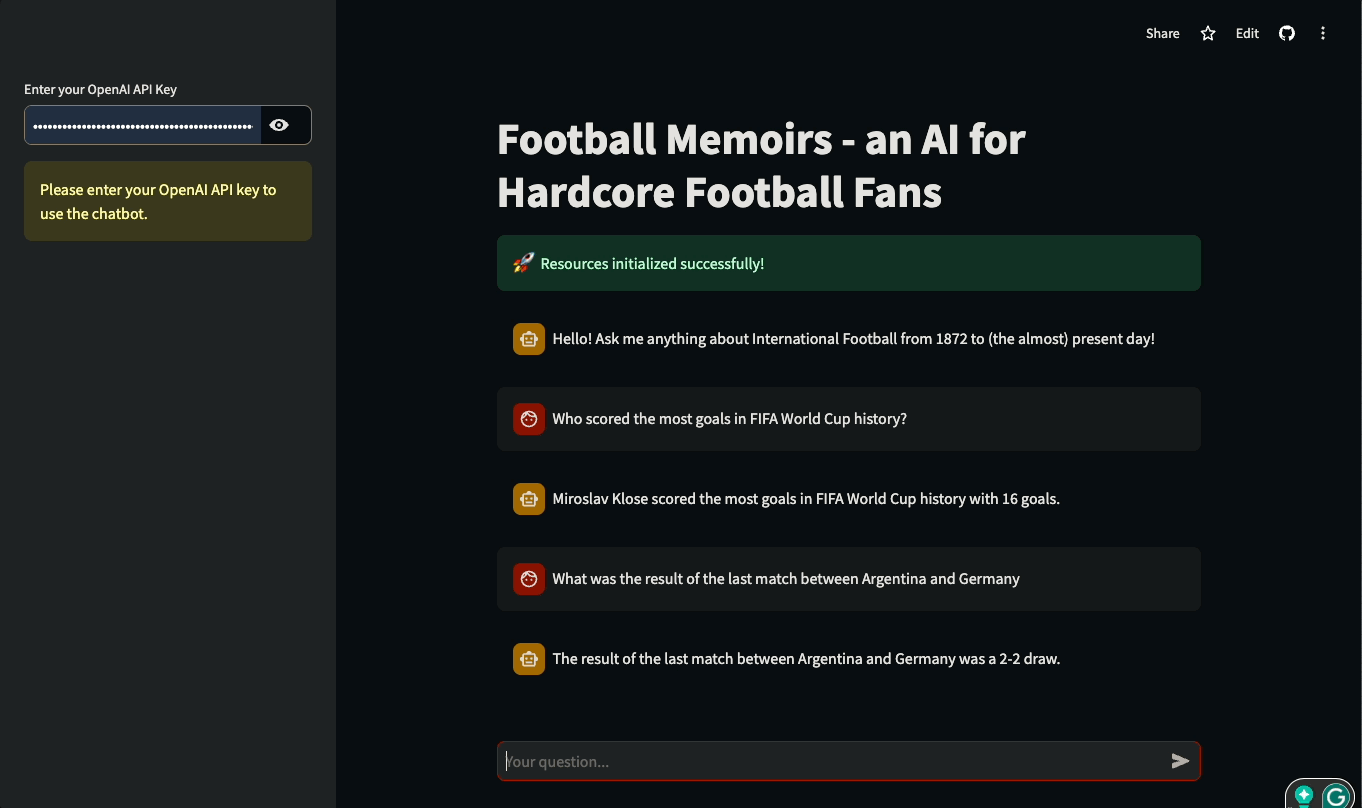
Vamos mergulhar de cabeça e começar a construir!
Atualização de conceitos de pré-requisito
Usaremos uma combinação de diferentes ferramentas para criar o chatbot que você viu acima, portanto, vamos analisar brevemente as finalidades de cada uma delas.
Streamlit
A primeira ferramenta é o Streamlitque é, de longe, a estrutura mais popular para criar aplicativos da Web usando apenas Python. Ele tem mais de 35 mil estrelas e é usado pela maioria das empresas da Fortune 50.
O Streamlit oferece um conjunto avançado de componentes da Web incorporados para exibir dados e mídia, bem como elementos para receber entradas do usuário. Com o surgimento dos LLMs, eles agora têm componentes para exibir mensagens de bate-papo produzidas por usuários e LLMs e um campo de entrada de texto para escrever prompts, semelhante à interface do ChatGPT.
Se você é completamente novo no Streamlit, leia nosso artigo introdutório sobre a estrutura.
LangChain
Embora os fornecedores de LLM tenham APIs amigáveis ao desenvolvedor, sua funcionalidade não é abrangente. Integrá-los às ferramentas de código aberto existentes requer tempo e esforço significativos.
É por isso que a estrutura estrutura LangChain nasceu. Ele reúne quase todos os principais LLMs em uma sintaxe unificada e oferece utilitários para simplificar o processo de criação de aplicativos complexos de IA. A LangChain oferece uma ampla variedade de ferramentas e componentes que permitem que os desenvolvedores criem sistemas avançados de IA com menos código e maior flexibilidade.
Alguns dos principais recursos do LangChain incluem:
- Integração perfeita com vários provedores de LLM
- Suporte integrado para engenharia e gerenciamento imediatos
- Ferramentas para gerenciamento de memória e estado em IA conversacional
- Utilitários para carregamento, transformação e vetorização de dados
- Componentes para criar cadeias e agentes para automação de tarefas complexas
No tutorial, usaremos o LangChain para fazer a integração com os modelos GPT da OpenAI, gerenciar nosso histórico de conversas e construir nosso pipeline de recuperação para acessar o banco de dados de futebol.
Leia nosso guia para iniciantes sobre LangChain para que você saiba o básico.
Bancos de dados gráficos, Neo4j e AuraDB
A segunda estrutura de banco de dados mais popular (depois da tabular) é um gráfico. Bancos de dados gráficos estão sempre aumentando em termos de adoção devido à sua capacidade inata de armazenar informações interconectadas. Nosso banco de dados de futebol internacional é um exemplo perfeito.
Os bancos de dados de gráficos são compostos de nós e das relações entre eles. Por exemplo, se considerarmos os principais termos do futebol como nós de um gráfico, a forma como eles se relacionam entre si representa as relações entre os nós. Nesse caso, os nós são jogadores, partidas, equipes, competições e assim por diante. As relações seriam:
- O jogador JOGA em uma partida
- As equipes PARTICIPAM de uma partida
- A partida é PARTE de uma competição
Então, os nós e os relacionamentos poderiam ter propriedades como:
- Jogador: idade, posição, nacionalidade
- Jogo: time da casa, time visitante, placar, local
- JOGOS EM (relação): número de gols marcados, número de minutos jogados
e assim por diante.
Neo4j é o sistema de gerenciamento mais popular para esses bancos de dados de gráficos. Sua linguagem de consulta, Cypheré muito semelhante ao SQL, mas foi projetada especificamente para atravessar estruturas gráficas complexas. O LangChain usará o cliente Python oficial do Neo4j para gerar e executar consultas Cypher em nosso banco de dados de gráficos. Confira nosso tutorial do Neo4j para saber mais.
Por falar nisso, nosso banco de dados está hospedado em uma instância de nuvem do Aura DB. Aura DB faz parte do Neo4j e oferece uma plataforma segura para gerenciar bancos de dados gráficos na nuvem.
Recuperação Geração aumentada
Os LLMs são treinados em grandes quantidades de dados, mas não têm acesso a bancos de dados privados de propriedade de empresas. Por esse motivo, o caso de uso mais popular de LLMs na empresa é Geração Aumentada de Recuperação (RAG).
No RAG, o LLM é aumentado com informações relevantes recuperadas de uma base de conhecimento ou banco de dados antes de gerar uma resposta. Normalmente, esse processo envolve as seguintes etapas:
- Compreensão da consulta: O sistema analisa a consulta do usuário para entender sua intenção e seus principais elementos.
- Recuperação de informações: Com base na análise da consulta, as informações relevantes são recuperadas do banco de dados conectado ou da base de conhecimento.
- Aumento de contexto: As informações recuperadas são adicionadas ao prompt enviado ao LLM, fornecendo a ele um contexto específico, atualizado e relevante.
- Geração de respostas: O LLM gera uma resposta com base em seu conhecimento pré-treinado e no contexto adicional fornecido.
- Refinamento de saída: A resposta gerada pode ser processada ou filtrada posteriormente para garantir a precisão e a relevância.
O RAG permite que os LLMs acessem e utilizem informações específicas, atuais e exclusivas, tornando-os mais úteis para aplicativos especializados e, ao mesmo tempo, mantendo seus recursos gerais de compreensão da linguagem.
No nosso caso, usaremos o RAG para aumentar nosso LLM com informações do nosso banco de dados de futebol, permitindo que ele responda a perguntas específicas sobre jogadores, partidas e competições às quais não teria acesso de outra forma.
Você pode adquirir experiência prática na implementação do RAG usando nosso projeto guiado sobre a criação de um chatbot RAG para documentação técnica.
Entendendo os dados
Vamos dar uma olhada mais de perto em nosso banco de dados gráfico antes de começarmos a construir. Abaixo você vê o esquema do gráfico visualizado:

O gráfico tem seis tipos de nós: jogador, equipe, partida, torneio, cidade e país. Esses nós são conectados por vários relacionamentos, como Equipe JOGOU_HOME em uma partida ou Jogador PONTUOU_PARA uma equipe. Esse esquema é baseado nos dados disponíveis no seguinte conjunto de dados do Kaggle:
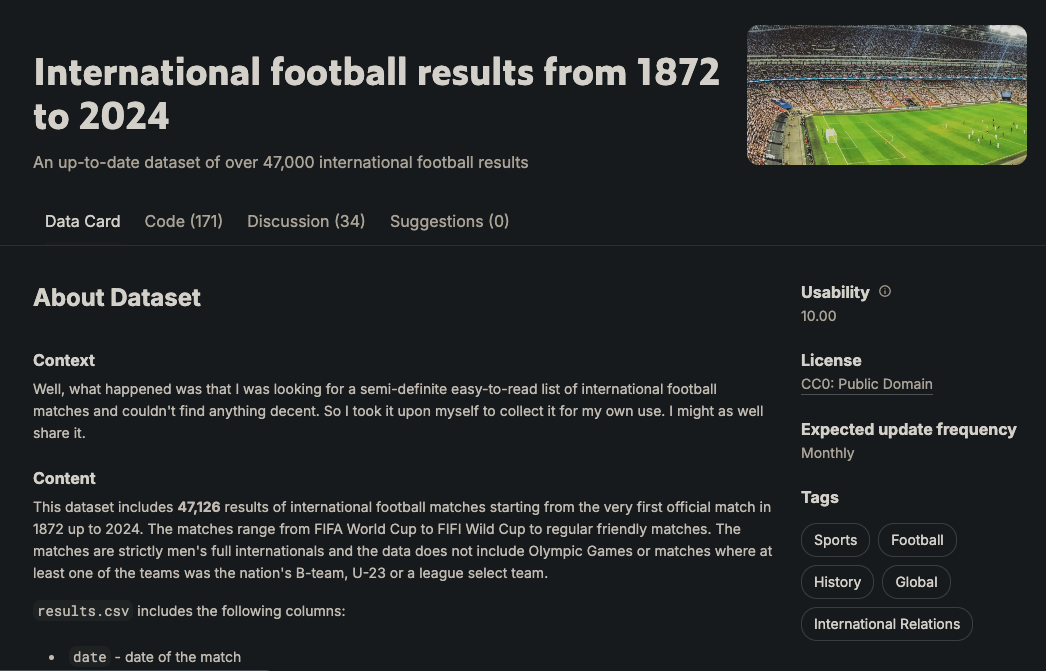
Ele contém mais de 47 mil partidas, seus resultados, os gols marcados em cada partida, quem os marcou e algumas propriedades adicionais, como minutos de gol, gols contra e locais de jogos.
Os dados estão originalmente no formato CSV, mas consegui ingeri-los em uma instância do Aura DB usando o driver Neo4j Python e as consultas Cypher (consulte o código em nosso tutorial do Neo4j).
O objetivo do nosso aplicativo (com trocadilho) é gerar consultas Cypher com base na entrada do usuário, executar as consultas em nosso banco de dados de gráficos e apresentar os resultados em um formato legível por humanos.
Então, vamos finalmente construí-lo.
Criando um chatbot Graph RAG em LangChain
Vamos abordar esse problema passo a passo, desde a criação de um ambiente de trabalho até a implementação do aplicativo usando o Streamlit Cloud.
1. Configure o ambiente
Vamos começar criando um novo ambiente Conda com o Python 3.9 e ativando-o. Você pode usar o Conda para criar um novo ambiente com o Python 3.9:
$ conda create -n football_chatbot python=3.9 -y
$ conda activate football_chatbotVocê precisará instalar as seguintes bibliotecas:
$ pip install streamlit langchain langchain-openai langchain_community neo4jAgora, vamos criar nosso diretório de trabalho e preencher sua estrutura:
$ mkdir football_chatbot; cd football_chatbot
$ mkdir .streamlit
$ touch {.streamlit/secrets.toml,app.py}Escreveremos nosso aplicativo em app.py enquanto secrets.toml dentro do diretório.streamlit servirá como nosso arquivo de credenciais. Abra-o e cole os três segredos a seguir:
NEO4J_URI = "neo4j+s://eed9dd8f.databases.neo4j.io"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "ivbSF02UWzHeHuzBIePyOH5cQ4LdyRxLeNbWvdpPA4k"Essas credenciais dão a você acesso à instância do Aura DB que armazena o banco de dados de futebol. Se você quiser criar sua própria instância com os mesmos dados, consulte nosso tutorial sobre o Neo4jque aborda exatamente essa etapa.
2. Importar bibliotecas e carregar os segredos
Agora, vamos trabalhar no arquivoapp.py. Na parte superior, importe os módulos e pacotes necessários e carregue os segredos usando st.secrets:
import streamlit as st
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
# Load secrets
neo4j_uri = st.secrets["NEO4J_URI"]
neo4j_user = st.secrets["NEO4J_USER"]
neo4j_password = st.secrets["NEO4J_PASSWORD"]Aqui está o que cada classe faz:
Neo4jGraph: Uma classe abreviada para você se conectar a bancos de dados Neo4j existentes e consultá-los com o Cypher.GraphCypherQAChainRAG: uma classe abrangente para executar o RAG de gráficos em bancos de dados de gráficos. Ao passar nosso gráfico carregado com Neo4jGraph, podemos gerar consultas Cypher usando linguagem natural com essa classe.ChatOpenAI: Dá acesso à API de conclusões de bate-papo da OpenAI.
3. Adicionar autenticação
Para evitar o uso mal-intencionado e os altos custos, devemos adicionar uma autenticação que solicite o token da API OpenAI do usuário. Para isso, você pode adicionar um formulário de senha à barra lateral esquerda usando o elemento st.sidebar:
# Set the app title
st.title("Football Memoirs - an AI for Hardcore Football Fans")
# Sidebar for API key input
with st.sidebar:
openai_api_key = st.text_input("Enter your OpenAI API Key", type="password")
st.warning("Please enter your OpenAI API key to use the chatbot.")Assim que o usuário carregar nosso aplicativo, ele verá o campo de entrada e nada mais será mostrado (exceto o título do aplicativo) até que ele forneça sua chave.
4. Conecte-se ao banco de dados Neo4j e inicialize uma cadeia de controle de qualidade
Depois de recuperar a chave da API OpenAI do usuário, podemos inicializar nossos recursos: o gráfico Neo4j e a classe de cadeia de QA:
# Initialize connections and models
@st.cache_resource(show_spinner=False)
def init_resources(api_key):
graph = Neo4jGraph(
url=neo4j_uri,
username=neo4j_user,
password=neo4j_password,
enhanced_schema=True,
)
graph.refresh_schema()
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(api_key=api_key, model="gpt-4o"),
graph=graph,
verbose=True,
show_intermediate_steps=True,
allow_dangerous_requests=True,
)
return graph, chainA funçãoinit_resources() aceita a chave da API como argumento e estabelece uma conexão com o banco de dados de gráficos. Em seguida, ele atualiza o esquema gráfico (estrutura) para que o LLM possa ter informações atualizadas sobre a estrutura do banco de dados ao formular consultas Cypher. Por fim, ele inicializa o GraphCypherQAChain com o gráfico e o modelo OpenAI, retornando os objetos do gráfico e da cadeia para uso posterior no aplicativo.
Vale a pena observar o uso do decoradorst.cache_resource(). Esse decorador armazena em cache as instâncias do gráfico e da cadeia, o que melhora o desempenho. Não precisamos criar novas instâncias sempre que um usuário carregar o aplicativo, portanto, armazená-las em cache é uma abordagem eficiente.
Vamos executar o inicializador com uma verificação de chave de API:
# Initialize resources only if API key is provided
if openai_api_key:
with st.spinner("Initializing resources..."):
graph, chain = init_resources(openai_api_key)
st.success("Resources initialized successfully!", icon="🚀")5. Adicionar histórico de mensagens ao Streamlit
Assim que os recursos estiverem disponíveis, precisaremos ativar o histórico de mensagens usando o estado da sessão do Streamlit. Também queremos exibir uma mensagem inicial de IA informando o usuário sobre o que o bot faz.
Para isso, criamos uma nova chave messages em st.session_state e definimos seu valor como uma lista com um único elemento. O elemento é um dicionário com duas chaves:
role: A quem pertence a mensagemcontent: O conteúdo da mensagem
# Initialize message history
if "messages" not in st.session_state:
st.session_state.messages = [
{
"role": "assistant",
"content": "Hello! Ask me anything about International Football from 1872 to (the almost) present day!",
}
]Caso você já tenha um histórico de mensagens dentro de st.session_state.messagesnós os exibimos com st.chat_message e st.markdown componentes:
# Display chat history
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])6. Exibir componentes de bate-papo
Agora, definimos uma função, query_graph, que executará a cadeia usando um prompt fornecido pelo usuário. O método .invoke() da cadeia aceita um dicionário com um par de valores-chave de consulta e prompt e retorna outro dicionário como saída. Queremos sua chave result:
def query_graph(query):
try:
result = chain.invoke({"query": query})["result"]
return result
except Exception as e:
st.error(f"An error occurred: {str(e)}")
return "I'm sorry, I encountered an error while processing your request."Agora, vamos exibir um campo de entrada na parte inferior da página usando o componente st.chat_input componente:
# Accept user input
if prompt := st.chat_input("Your question..."):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)Assim que o prompt é fornecido, nós o armazenamos como uma mensagem do usuário no histórico de mensagens e o exibimos na tela. Em seguida, com outra verificação de chave de API, executamos a função query_graph, passando o prompt:
if prompt := st.chat_input("Your question..."):
...
# Generate answer if API key is provided
if openai_api_key:
with st.spinner("Thinking..."):
response = query_graph(prompt)
with st.chat_message("assistant"):
st.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response})
else:
st.error("Please enter your OpenAI API key in the sidebar to use the chatbot.")Adicionamos um widget de spinner enquanto a consulta Cypher e a resposta final estão sendo geradas. Em seguida, exibimos a mensagem e a anexamos ao histórico de mensagens.
É isso aí! Agora o aplicativo está pronto:
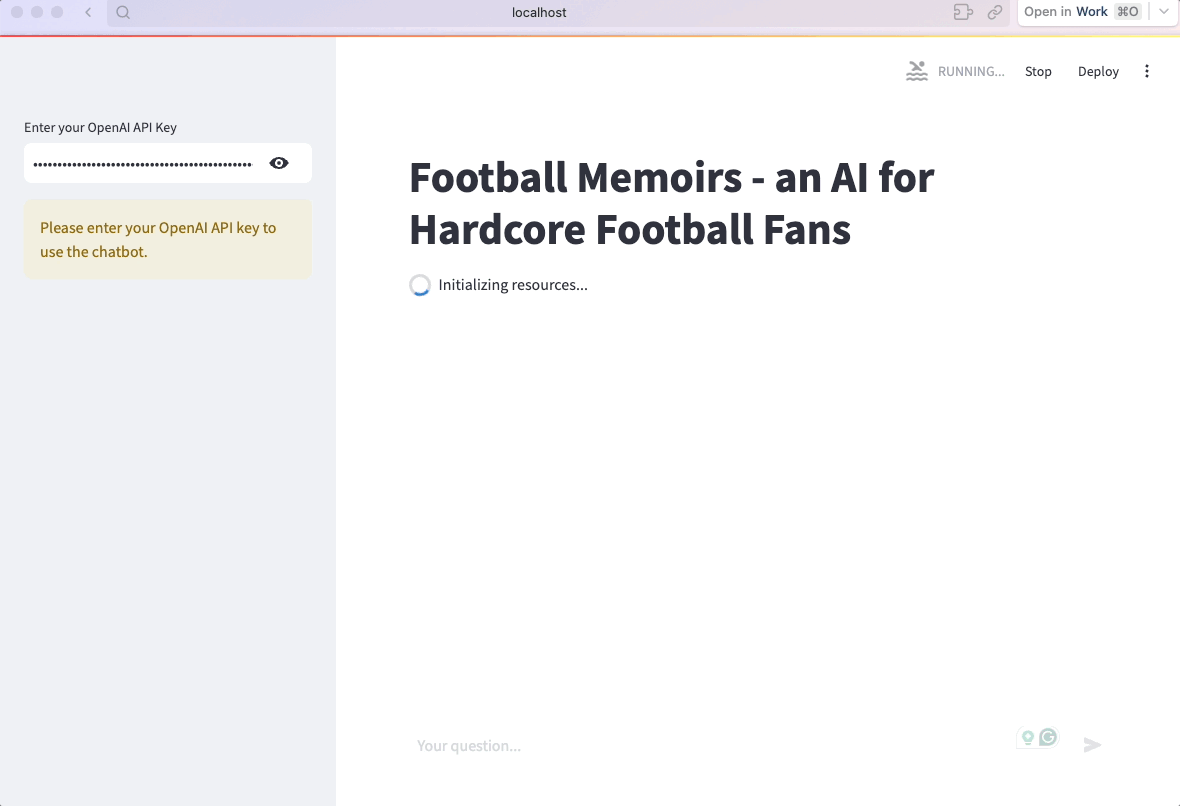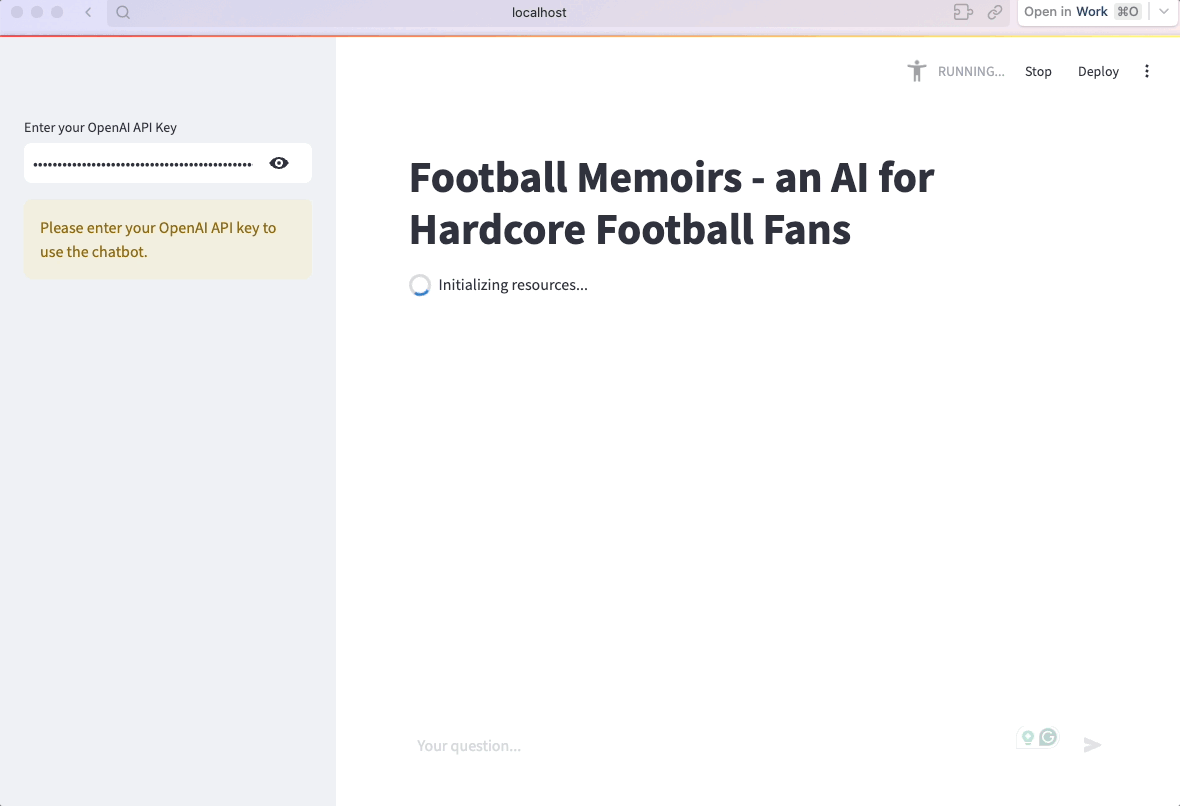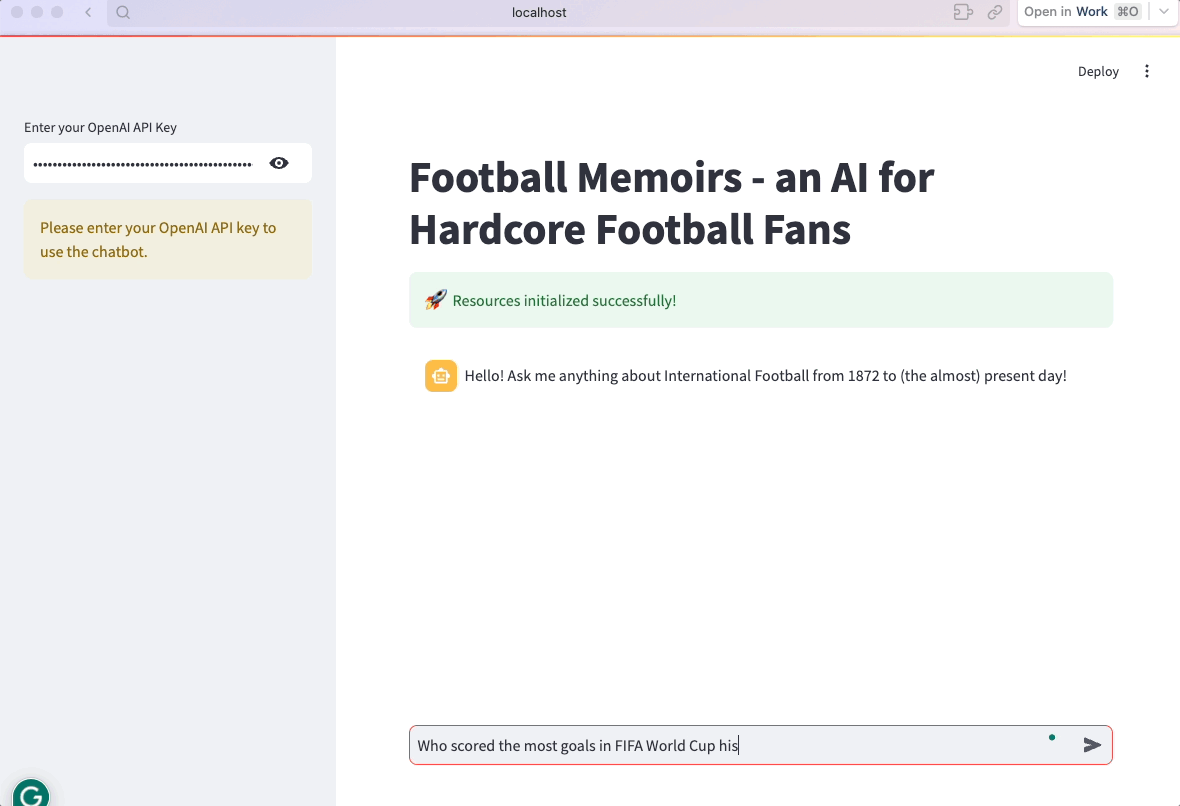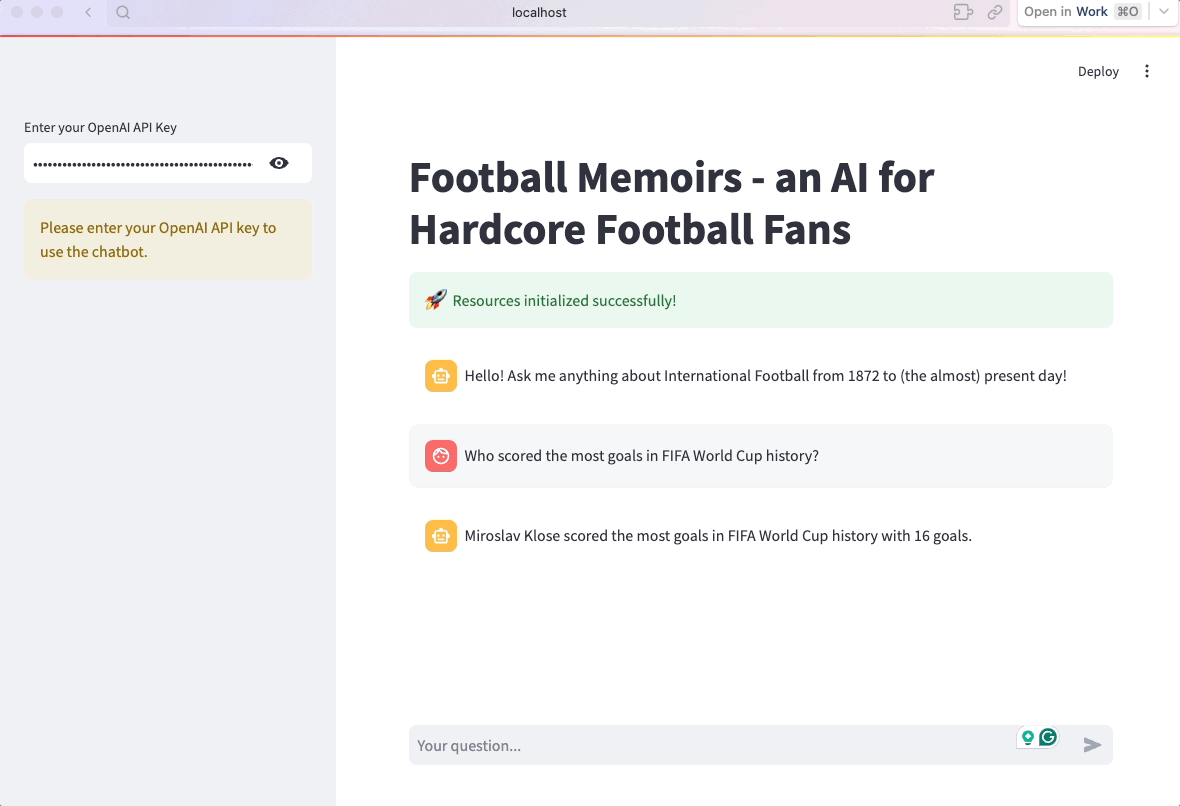
7. Otimizar e organizar o código
O aplicativo está pronto, mas está escrito em um único arquivo sem nenhuma estrutura otimizada. Vamos reformular e torná-lo modular:
$ cd football_chatbot
$ rm -rf . # Start from scratch
$ mkdir .streamlit
$ touch {.streamlit/secrets.toml,.gitignore,app.py,chat_utils.py,graph_utils.py,README.MD,requirements.txt}Desta vez, nossa estrutura de diretórios contém mais alguns arquivos:
.
├── .git
├── .gitignore
├── .streamlit
├── README.md
├── app.py
├── chat_utils.py
├── graph_utils.py
├── requirements.txtAgora, dentro de graph_utils.pycole o código organizado a seguir:
# graph_utils.py
import streamlit as st
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
@st.cache_resource(show_spinner=False)
def init_resources(api_key):
graph = Neo4jGraph(
url=st.secrets["NEO4J_URI"],
username=st.secrets["NEO4J_USER"],
password=st.secrets["NEO4J_PASSWORD"],
enhanced_schema=True,
)
graph.refresh_schema()
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(api_key=api_key, model="gpt-4o"),
graph=graph,
verbose=True,
show_intermediate_steps=True,
allow_dangerous_requests=True,
)
return graph, chain
def query_graph(chain, query):
result = chain.invoke({"query": query})["result"]
return resultAqui, a diferença está na funçãoquery_graph. Especificamente, ele não tem tratamento de erros e exibição usando a função st.error. Moveremos essa parte para o arquivo principal app.py.
Agora, vamos trabalhar no arquivo chat_utils.py arquivo:
# chat_utils.py
import streamlit as st
def initialize_chat_history():
if "messages" not in st.session_state:
st.session_state.messages = [
{
"role": "assistant",
"content": "Hello! Ask me anything about International Football from 1872 to (the almost) present day!",
}
]
def display_chat_history():
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])Primeiro, criamos duas funções:
initialize_chat_history: Ative o histórico de mensagens com uma mensagem padrão, se ela ainda não estiver disponível.display_chat_history: Mostrar todas as mensagens no histórico de mensagens.
Criamos outra função para lidar com os prompts e a geração de respostas:
# chat_utils.py
def handle_user_input(openai_api_key, query_graph_func, chain):
if prompt := st.chat_input("Your question..."):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
if openai_api_key:
with st.spinner("Thinking..."):
try:
response = query_graph_func(chain=chain, query=prompt)
except Exception as e:
st.error(f"An error occurred: {str(e)}")
response = "I'm sorry, I encountered an error while processing your request."
with st.chat_message("assistant"):
st.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response})
else:
st.error(
"Please enter your OpenAI API key in the sidebar to use the chatbot."
)A diferença aqui é o uso de um bloco try-except em torno de query_graph_func para capturar e exibir erros. O restante da funcionalidade é o mesmo.
Finalmente, dentro de app.pyvocê pode fazer tudo junto:
import streamlit as st
from graph_utils import init_resources, query_graph
from chat_utils import initialize_chat_history, display_chat_history, handle_user_input
st.title("Football Memoirs - an AI for Hardcore Football Fans")
# Sidebar for API key input
with st.sidebar:
openai_api_key = st.text_input("Enter your OpenAI API Key", type="password")
st.warning("Please enter your OpenAI API key to use the chatbot.")Importamos as funções de outros arquivos, definimos o título do aplicativo e adicionamos o campo de entrada da chave da API à barra lateral esquerda. Em seguida, com uma verificação de chave de API, inicializamos os recursos e exibimos o histórico e os componentes das mensagens de bate-papo:
# Initialize resources only if the API key is provided
if openai_api_key:
with st.spinner("Initializing resources..."):
graph, chain = init_resources(openai_api_key)
st.success("Resources initialized successfully!", icon="🚀")
# Initialize and display chat history
initialize_chat_history()
display_chat_history()
# Handle user input
handle_user_input(
openai_api_key=openai_api_key, query_graph_func=query_graph, chain=chain
)Agora, o aplicativo está pronto para ser implantado!
8. Implemente o aplicativo na Streamlit Cloud
O método mais fácil e descomplicado para implementar aplicativos Streamlit é usar o Streamlit Cloud. Todos os aplicativos hospedados no Streamlit Cloud são gratuitos, desde que você use o hardware padrão.
Mas, primeiro, vamos adicionar essas duas linhas ao nosso arquivo .gitignore para que os segredos do nosso aplicativo não sejam exibidos no GitHub:
*.toml
__pycache__Além disso, todo (bom) repositório precisa de um arquivo README. Então, vamos escrever o nosso:
# Football Memoirs - AI for Hardcore Football Fans
This Streamlit app uses a Neo4j graph database and OpenAI's GPT-4o model to answer questions about international football history from 1872 to the present day.
## Setup
1. Clone this repository
2. Install dependencies: pip install -r requirements.txt
3. Set up your .streamlit/secrets.toml file with the following keys:
- NEO4J_URI
- NEO4J_USER
- NEO4J_PASSWORD
4. Run the app: streamlit run app.py
## Deployment
To deploy this app on Streamlit Cloud:
1. Push your code to a GitHub repository
2. Connect your GitHub account to Streamlit Cloud
3. Create a new app in Streamlit Cloud and select your repository
4. Add your secrets in the Streamlit Cloud dashboard under the "Secrets" section
5. Deploy your appOs aplicativos do Streamlit Cloud precisam de um arquivorequirements.txt para preencher os ambientes com dependências. Adicione-os aos seus:
streamlit
langchain
langchain-community
langchain-openai
neo4jAgora, inicializamos o git, fazemos nosso primeiro commit e o enviamos para o repositório remoto que você deve ter criado para o projeto:
$ git init
$ git add .
$ git commit -m "Initial commit"
$ git remote add origin https://github.com/Username/repository.git
$ git push --set-upstream origin mainEm seguida, inscreva-se no Streamlit Cloud, acesse seu painel e clique em "Create app" (Criar aplicativo):
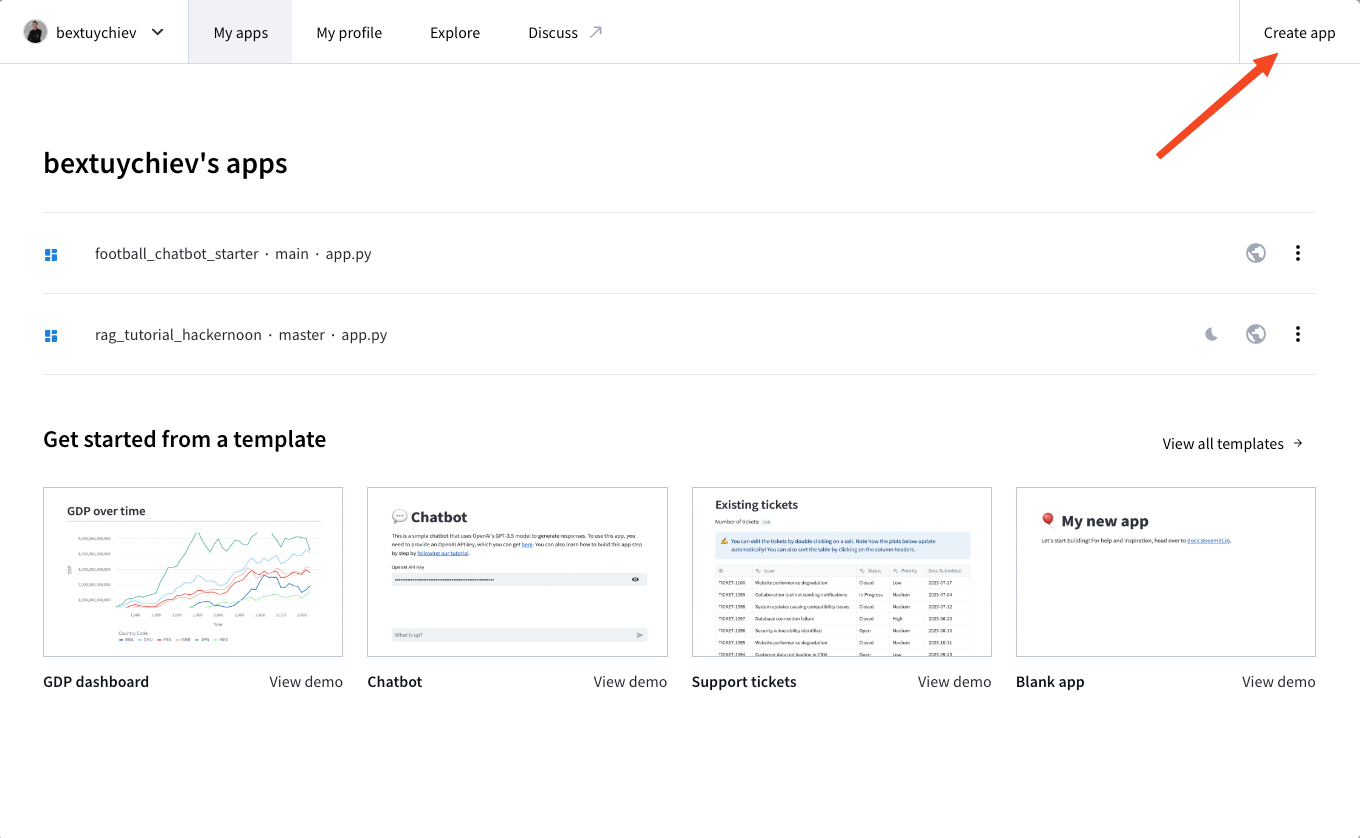
Você verá as seguintes opções:
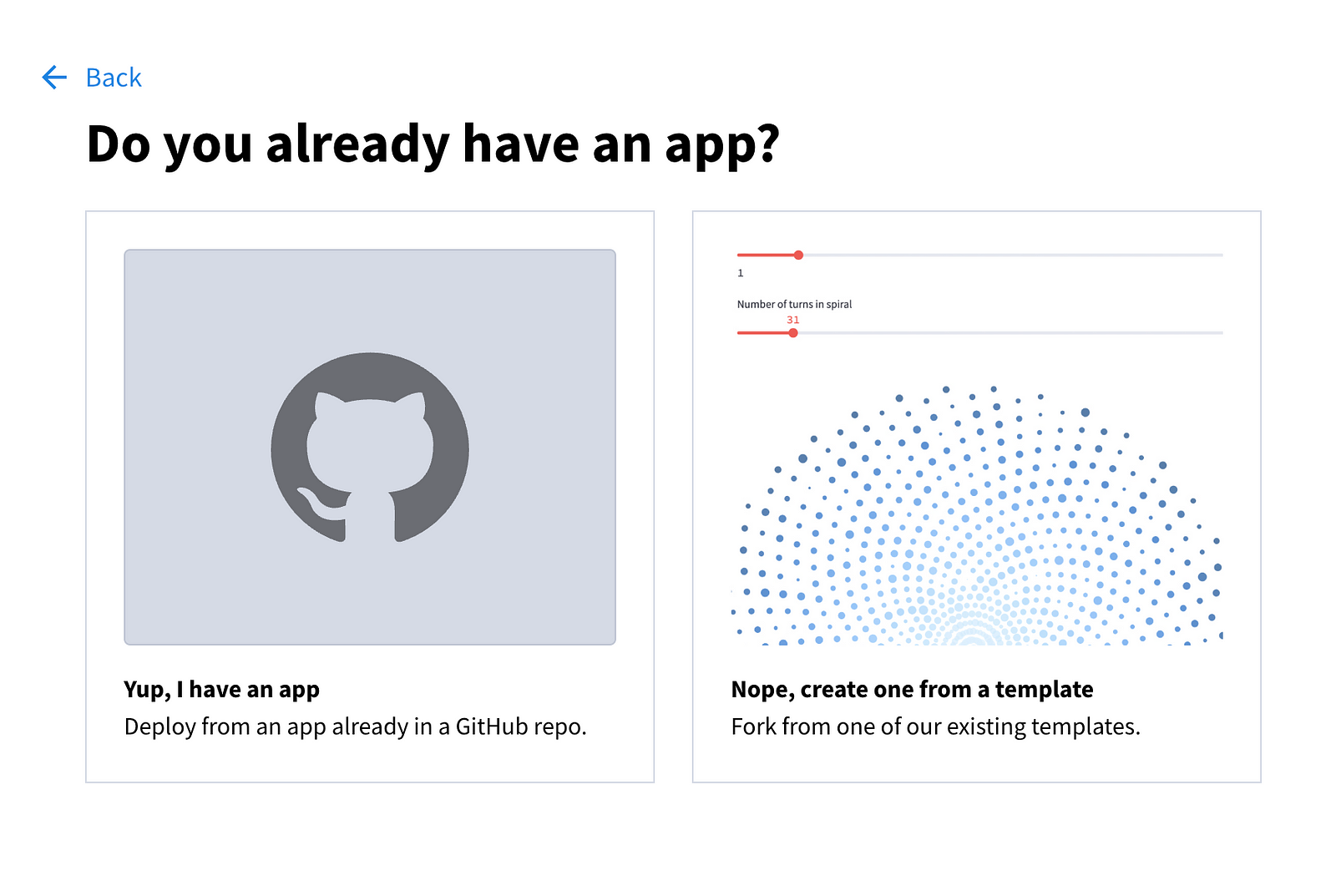
Escolha a primeira opção e preencha os campos na próxima página.
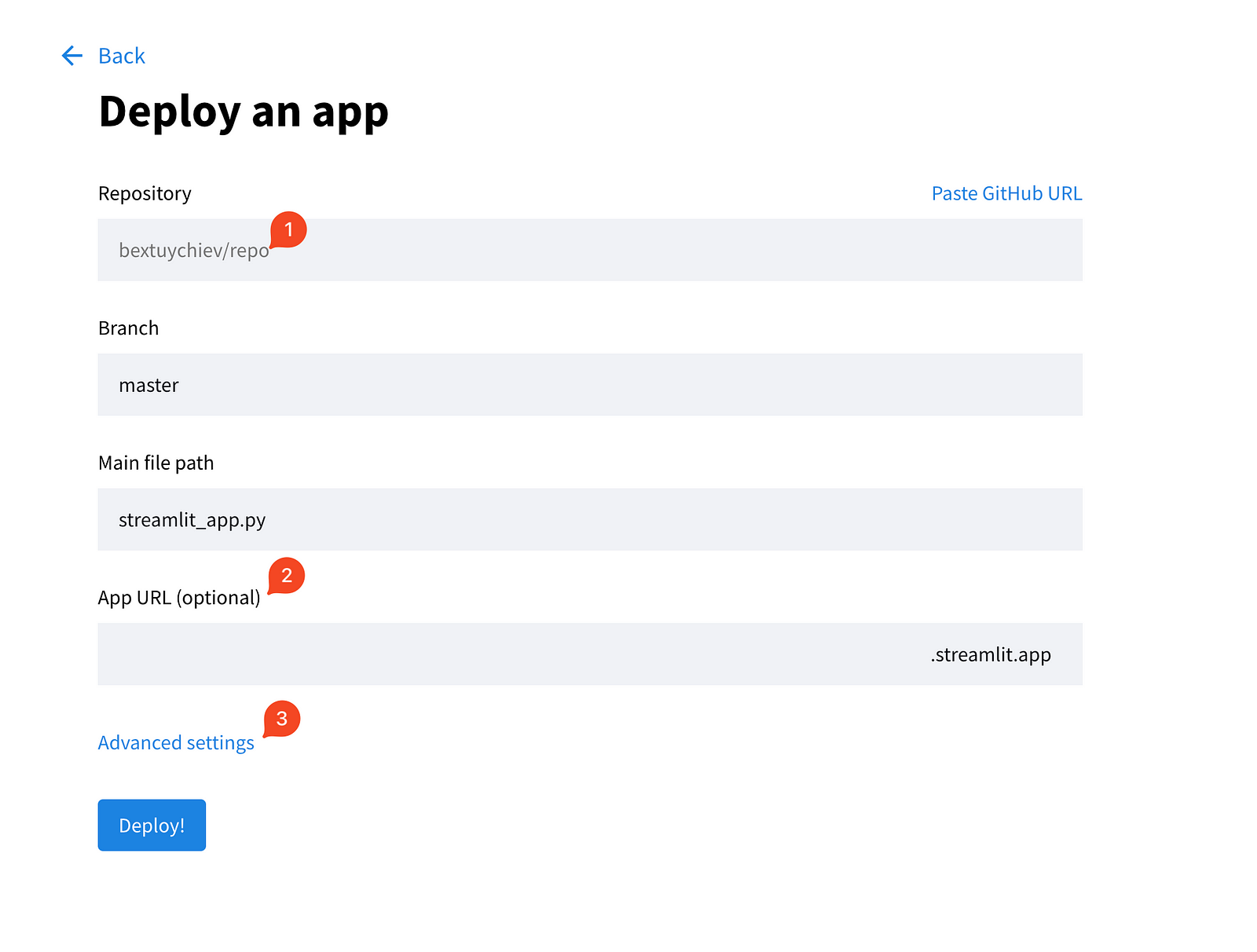
Além disso, expanda as configurações avançadas, que fornecem a você dois campos para escolher a versão do Python e colar as credenciais de que seu aplicativo precisa. É aqui que você copia/cola o conteúdo do arquivo local secrets.toml:
Salve os segredos e clique em "Deploy!". O aplicativo deverá estar operacional em alguns minutos!
Conclusão
Neste tutorial, criamos um chatbot de IA que responde a perguntas sobre a história do futebol internacional usando Streamlit, LangChain e um banco de dados de gráficos Neo4j. Nós cobrimos:
- Criando uma interface da Web fácil de usar com o Streamlit
- Integração dos modelos GPT da OpenAI com um banco de dados de gráficos usando LangChain
- Implementação do Retrieval Augmented Generation (RAG)
- Criação de uma base de código modular
- Implementação no Streamlit Cloud
Esse projeto serve como modelo para a criação de interfaces de usuário de IA de bate-papo. Embora a lógica do aplicativo seja diferente em cada projeto, os componentes da interface do usuário que usamos hoje serão usados na maioria deles de alguma forma.
Além disso, observe que a criação da interface do usuário é a parte mais fácil da criação de aplicativos de IA. A maior parte do seu tempo será gasta no aprimoramento do desempenho do aplicativo. Por exemplo, nosso pipeline de geração de Cypher ainda precisa de uma quantidade significativa de trabalho. Devido à falta de exemplos, à estrutura vaga do gráfico e às limitações dos LLMs, a precisão do nosso aplicativo não é aceitável para produção. Tenha esses aspectos em mente ao criar seus aplicativos.
Se você estiver interessado em saber mais sobre desenvolvimento de grandes modelos de linguagemconfira nossa trilha de habilidades, que aborda como criar LLMs com PyTorch e Hugging Face, usando as mais recentes técnicas de aprendizagem profunda e PNL.


