Die meisten LLM-Anbieter wie OpenAI und Anthropic bieten benutzerfreundliche APIs, um ihre Modelle in eigene KI-Anwendungen zu integrieren. Aber diese Benutzerfreundlichkeit hat ihren Preis: Du wirst nicht mehr in der Lage sein, vertraute Weboberflächen wie ChatGPT oder Claude zu nutzen. Deine App wird eigenständig sein und in einer Reihe von Skripten geschrieben.
Aus diesem Grund ist es wichtig zu lernen, wie du deinen Anwendungscode mit einer benutzerfreundlichen Oberfläche umhüllst, damit auch externe Nutzer und Stakeholder ohne technisches Know-how damit arbeiten können.
In diesem Tutorial lernst du, wie du Streamlit UIs für LLM-basierte Anwendungen mit LangChain erstellst. Das Tutorial wird praxisorientiert sein: Wir werden eine reale Datenbank mit der Geschichte des internationalen Fußballs nutzen, um einen Chatbot zu bauen, der Fragen zu historischen Spielen und Details zu internationalen Wettbewerben beantworten kann. Du kannst mit der App herumspielen oder sie unten in Aktion sehen:
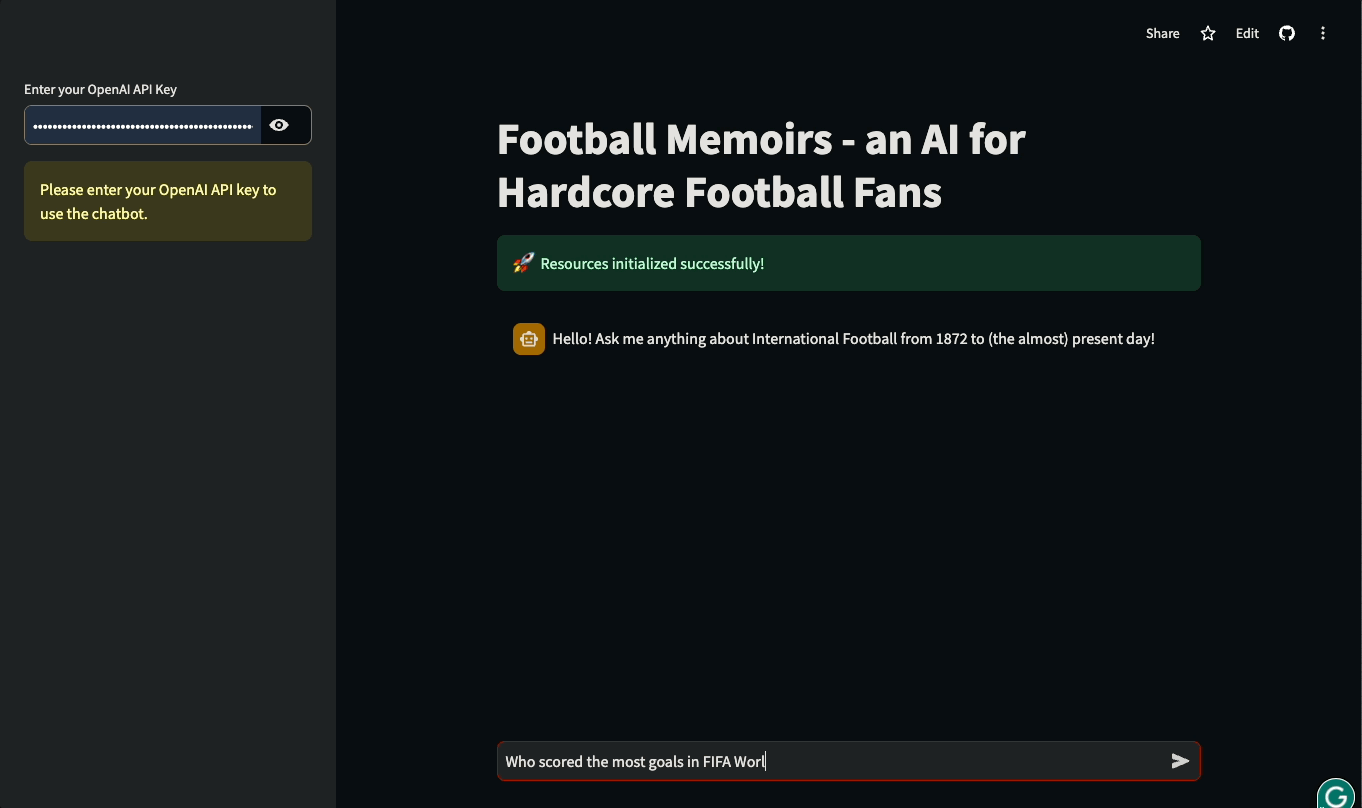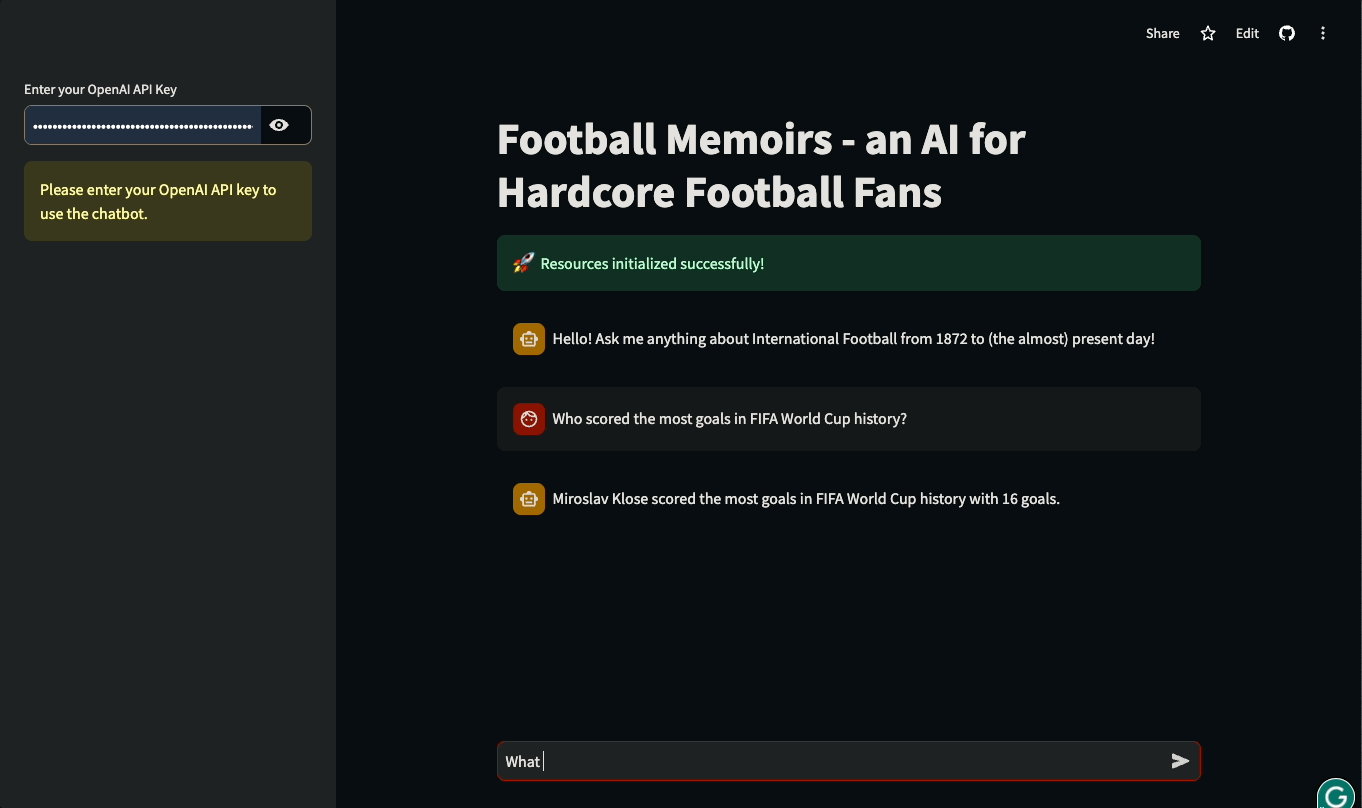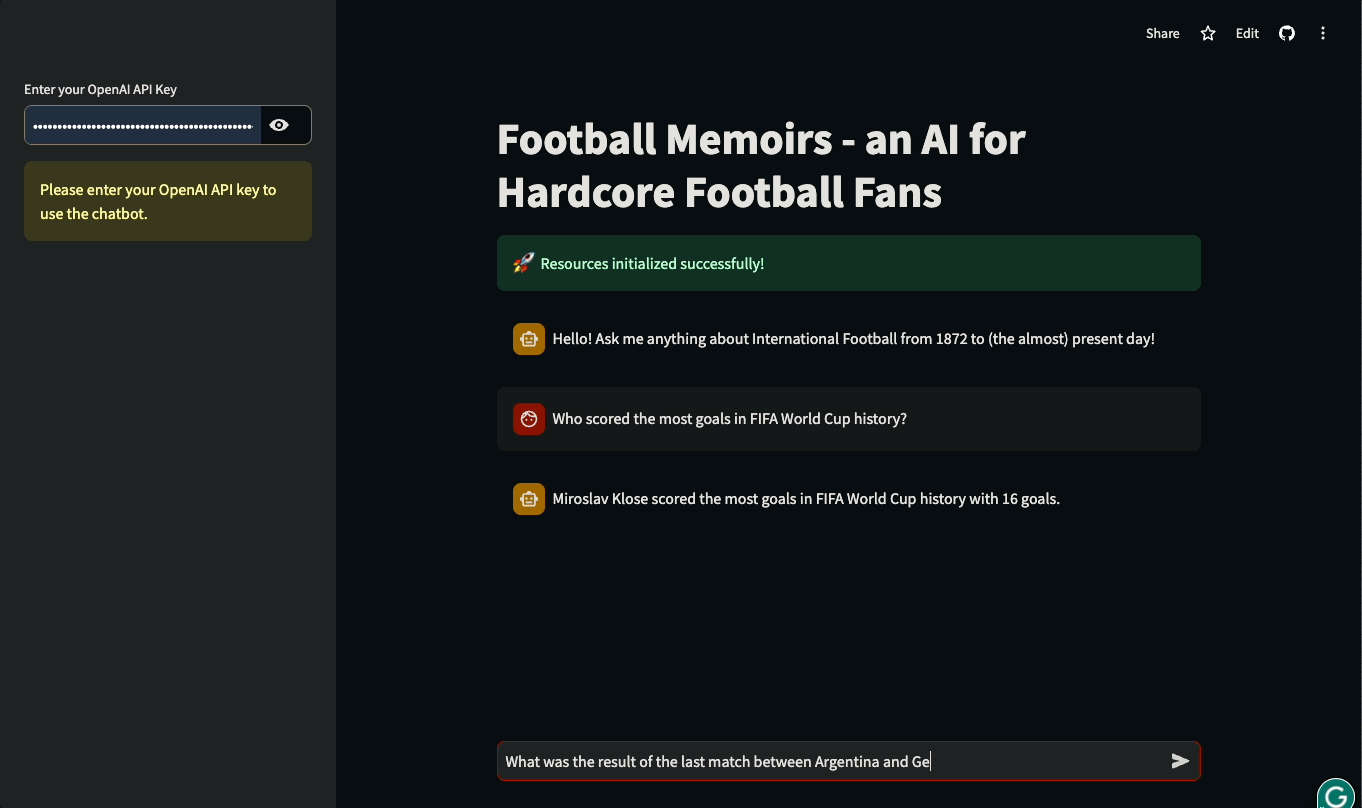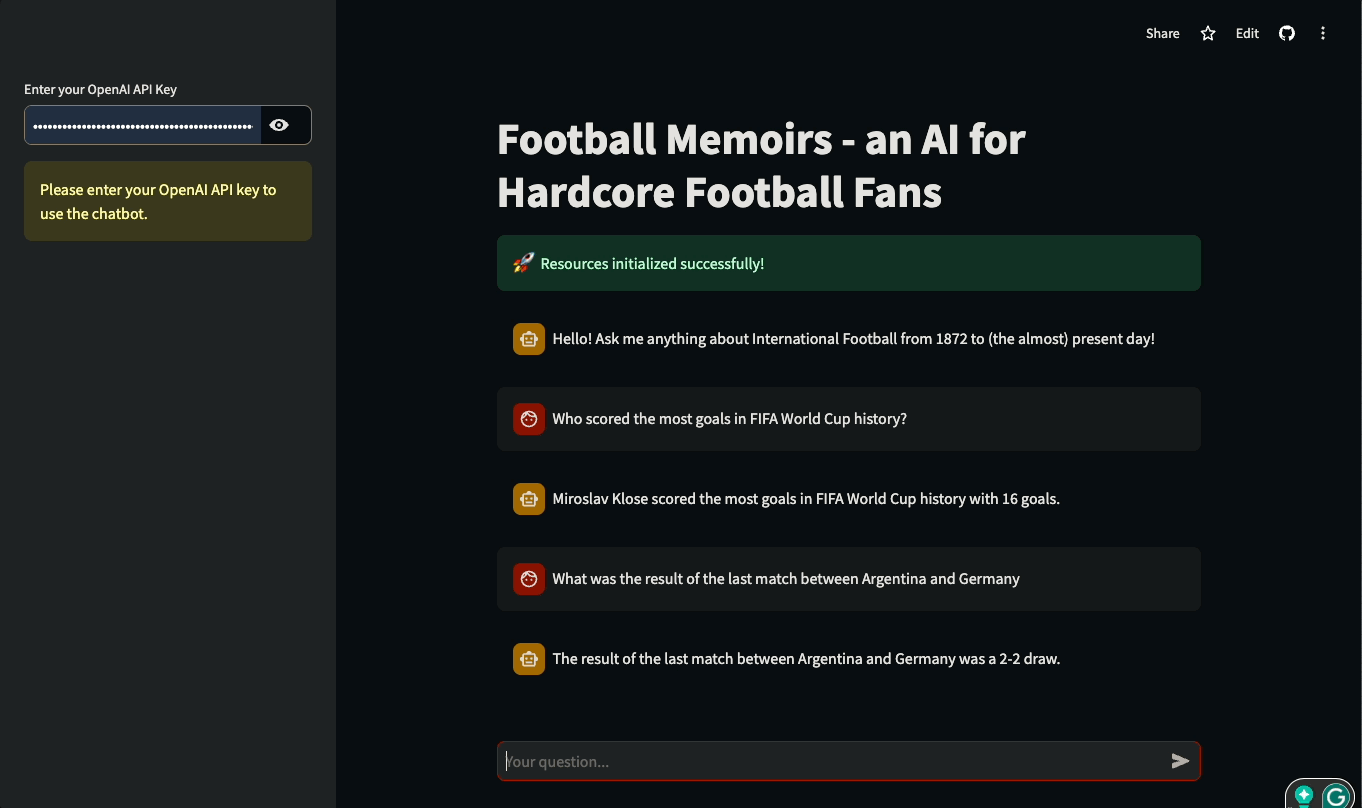
Lass uns eintauchen und anfangen zu bauen!
Auffrischung der vorausgesetzten Konzepte
Wir werden eine Kombination aus verschiedenen Tools verwenden, um den Chatbot zu erstellen, den du oben gesehen hast, also gehen wir kurz auf den Zweck jedes Tools ein.
Streamlit
Das erste Tool ist Streamlitdas bei weitem beliebteste Framework, um Webanwendungen nur mit Python zu erstellen. Es hat über 35.000 Sterne und wird von den meisten Fortune 50-Unternehmen genutzt.
Streamlit bietet eine Vielzahl von eingebauten Web-Komponenten zur Anzeige von Daten und Medien sowie Elemente zur Aufnahme von Benutzereingaben. Mit dem Aufkommen der LLMs verfügen sie nun über Komponenten zur Anzeige von Chat-Nachrichten, die sowohl von Nutzern als auch von LLMs erstellt wurden, sowie über ein Texteingabefeld zum Schreiben von Prompts, das der Oberfläche von ChatGPT ähnelt.
Wenn du ganz neu bei Streamlit bist, lies unseren Einführungsartikel über das Framework.
LangChain
LLM-Anbieter haben zwar entwicklerfreundliche APIs, aber ihre Funktionalität ist nicht allumfassend. Sie in bestehende Open-Source-Tools zu integrieren, erfordert viel Zeit und Aufwand.
Aus diesem Grund ist das LangChain-Framework geboren worden. Es vereint fast alle wichtigen LLMs unter einer einheitlichen Syntax und bietet Hilfsprogramme, um die Entwicklung komplexer KI-Anwendungen zu vereinfachen. LangChain bietet eine breite Palette von Tools und Komponenten, mit denen Entwickler leistungsstarke KI-Systeme mit weniger Code und größerer Flexibilität erstellen können.
Zu den wichtigsten Funktionen von LangChain gehören:
- Nahtlose Integration mit verschiedenen LLM-Anbietern
- Integrierte Unterstützung für zeitnahe Entwicklung und Verwaltung
- Tools für die Speicher- und Zustandsverwaltung in der Konversations-KI
- Dienstprogramme zum Laden, Transformieren und Vektorisieren von Daten
- Komponenten zum Aufbau von Ketten und Agenten für die Automatisierung komplexer Aufgaben
Im Tutorial werden wir LangChain nutzen, um uns in die GPT-Modelle von OpenAI zu integrieren, unsere Konversationshistorie zu verwalten und unsere Retrieval-Pipeline für den Zugriff auf die Fußballdatenbank zu erstellen.
Lies unseren Einsteigerhandbuch über LangChain für die Grundlagen.
Graphdatenbanken, Neo4j und AuraDB
Die zweitbeliebteste Datenbankstruktur (nach der tabellarischen) ist ein Diagramm. Graphdatenbanken werden aufgrund ihrer Fähigkeit, vernetzte Informationen zu speichern, immer häufiger eingesetzt. Unsere internationale Fußballdatenbank ist ein perfektes Beispiel dafür.
Graphdatenbanken bestehen aus Knoten und den Beziehungen zwischen ihnen. Wenn wir zum Beispiel die Schlüsselbegriffe des Fußballs als Knotenpunkte eines Graphen betrachten, stellt die Art und Weise, wie sie miteinander in Beziehung stehen, die Beziehungen zwischen den Knotenpunkten dar. In diesem Fall sind Knotenpunkte Spieler, Spiele, Mannschaften, Wettbewerbe und so weiter. Die Beziehungen würden sein:
- Spieler SPIELT IN einem Spiel
- Teams nehmen an einem Spiel teil
- Das Spiel ist TEIL eines Wettbewerbs
Dann könnten Knoten und Beziehungen Eigenschaften wie diese haben:
- Spieler: Alter, Position, Nationalität
- Spiel: Heimmannschaft, Auswärtsmannschaft, Ergebnis, Spielort
- PLAYS IN (Verhältnis): Anzahl der erzielten Tore, Anzahl der gespielten Minuten
und so weiter.
Neo4j ist das beliebteste Verwaltungssystem für solche Graphdatenbanken. Seine Abfragesprache, Cypherist SQL sehr ähnlich, wurde aber speziell dafür entwickelt, komplexe Graphenstrukturen zu durchlaufen. LangChain wird den offiziellen Python-Client von Neo4j verwenden, um Cypher-Abfragen gegen unsere Graphdatenbank zu erstellen und auszuführen. Schau dir unser Neo4j-Anleitung um mehr zu erfahren.
Apropos, unsere Datenbank wird auf einer Cloud-Instanz von Aura DB gehostet. Aura DB ist Teil von Neo4j und bietet eine sichere Plattform zur Verwaltung von Graphdatenbanken in der Cloud.
Abruf Erweiterte Erzeugung
LLMs werden für den Umgang mit riesigen Datenmengen geschult, aber sie haben keinen Zugang zu privaten Datenbanken von Unternehmen. Aus diesem Grund ist der beliebteste Anwendungsfall von LLMs in Unternehmen Retrieval Augmented Generation (RAG).
Bei RAG wird das LLM mit relevanten Informationen aus einer Wissensbasis oder Datenbank ergänzt, bevor eine Antwort generiert wird. Dieser Prozess umfasst in der Regel die folgenden Schritte:
- Abfrageverständnis: Das System analysiert die Anfrage des Nutzers, um seine Absicht und die wichtigsten Elemente zu verstehen.
- Information Retrieval: Auf der Grundlage der Abfrageanalyse werden relevante Informationen aus der angeschlossenen Datenbank oder Wissensbasis abgerufen.
- Context augmentation: Die abgerufenen Informationen werden zu der an den LLM gesendeten Eingabeaufforderung hinzugefügt, so dass er einen spezifischen, aktuellen und relevanten Kontext erhält.
- Antwortgenerierung: Der LLM generiert eine Antwort, die sowohl auf seinem vortrainierten Wissen als auch auf dem zusätzlich bereitgestellten Kontext basiert.
- Ausgabeveredelung: Die generierte Antwort kann weiterverarbeitet oder gefiltert werden, um Genauigkeit und Relevanz sicherzustellen.
RAG ermöglicht es LLMs, auf spezifische, aktuelle und geschützte Informationen zuzugreifen und diese zu nutzen, wodurch sie für spezielle Anwendungen nützlicher werden und gleichzeitig ihre allgemeinen Sprachverständnisfähigkeiten behalten.
In unserem Fall werden wir RAG nutzen, um unser LLM mit Informationen aus unserer Fußballdatenbank zu ergänzen, damit es spezifische Fragen zu Spielern, Spielen und Wettbewerben beantworten kann, auf die es sonst keinen Zugriff hätte.
Mit unserem angeleiteten Projekt zum Aufbau eines RAG-Chatbots für die technische Dokumentation kannst du praktische Erfahrungen mit der Implementierung von RAG sammeln.
Die Daten verstehen
Bevor wir mit dem Aufbau beginnen, wollen wir uns unsere Graphdatenbank genauer ansehen. Unten ist das Diagrammschema visualisiert:

Der Graph hat sechs Knotentypen: Spieler, Mannschaft, Spiel, Turnier, Stadt und Land. Diese Knoten sind durch verschiedene Beziehungen miteinander verbunden, wie z.B. Team PLAYED_HOME in einem Spiel oder Player SCORED_FOR a Team. Dieses Schema basiert auf den Daten, die in dem folgenden Kaggle-Datensatz:
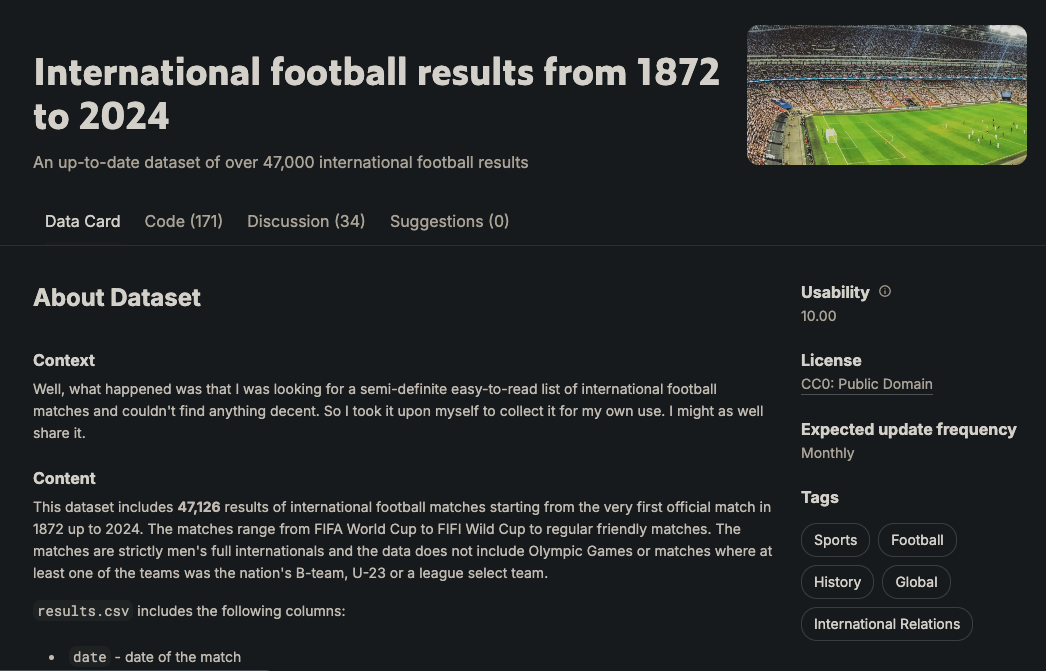
Sie enthält mehr als 47.000 Spiele, ihre Ergebnisse, die in jedem Spiel erzielten Tore, wer sie geschossen hat und einige zusätzliche Eigenschaften wie Torminuten, Eigentore und Spielorte.
Die Daten liegen ursprünglich im CSV-Format vor, aber ich konnte sie mithilfe des Neo4j-Python-Treibers und Cypher-Abfragen in eine Aura-DB-Instanz einlesen (siehe den Code in unserem Neo4j-Anleitung).
Das Ziel unserer App (Wortspiel beabsichtigt) ist es, Cypher-Abfragen auf der Grundlage von Benutzereingaben zu erstellen, die Abfragen gegen unsere Graphdatenbank laufen zu lassen und die Ergebnisse in einem für Menschen lesbaren Format zu präsentieren.
Also, lass es uns endlich bauen.
Einen Graph RAG Chatbot in LangChain bauen
Wir werden dieses Problem Schritt für Schritt angehen, von der Erstellung einer Arbeitsumgebung bis zur Bereitstellung der App mit Streamlit Cloud.
1. Richte die Umgebung ein
Beginnen wir damit, eine neue Conda-Umgebung mit Python 3.9 zu erstellen und sie zu aktivieren:
$ conda create -n football_chatbot python=3.9 -y
$ conda activate football_chatbotWir müssen die folgenden Bibliotheken installieren:
$ pip install streamlit langchain langchain-openai langchain_community neo4jErstellen wir nun unser Arbeitsverzeichnis und füllen seine Struktur auf:
$ mkdir football_chatbot; cd football_chatbot
$ mkdir .streamlit
$ touch {.streamlit/secrets.toml,app.py}Wir schreiben unsere Anwendung in das Verzeichnis app.py, während secrets.toml im Verzeichnis.streamlit als unsere Anmeldedatei dient. Öffne es und füge die folgenden drei Geheimnisse ein:
NEO4J_URI = "neo4j+s://eed9dd8f.databases.neo4j.io"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "ivbSF02UWzHeHuzBIePyOH5cQ4LdyRxLeNbWvdpPA4k"Mit diesen Zugangsdaten hast du Zugriff auf die Aura DB-Instanz, in der die Fußballdatenbank gespeichert ist. Wenn du deine eigene Instanz mit denselben Daten erstellen möchtest, schau dir unser Tutorial zu Neo4jnach, in dem genau dieser Schritt beschrieben wird.
2. Bibliotheken importieren und die Geheimnisse laden
Arbeiten wir nun an der Dateiapp.py. Oben importierst du die notwendigen Module und Pakete und lädst die Secrets mit st.secrets:
import streamlit as st
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
# Load secrets
neo4j_uri = st.secrets["NEO4J_URI"]
neo4j_user = st.secrets["NEO4J_USER"]
neo4j_password = st.secrets["NEO4J_PASSWORD"]Hier ist, was jede Klasse macht:
Neo4jGraph: Eine Shorthand-Klasse, um sich mit bestehenden Neo4j-Datenbanken zu verbinden und sie mit Cypher abzufragen.GraphCypherQAChain: eine allumfassende Klasse, um Graph RAG auf Graphdatenbanken durchzuführen. Indem wir unseren mit geladenen Graphen anNeo4jGraph übergeben, können wir mit dieser Klasse Cypher-Abfragen in natürlicher Sprache erstellen.ChatOpenAI: Ermöglicht den Zugriff auf die Chat Completions API von OpenAI.
3. Authentifizierung hinzufügen
Um böswillige Nutzung und hohe Kosten zu verhindern, sollten wir eine Authentifizierung hinzufügen, die das OpenAI API-Token des Nutzers abfragt. Dies kannst du erreichen, indem du mit dem Element st.sidebar ein Passwortformular in die linke Seitenleiste einfügst:
# Set the app title
st.title("Football Memoirs - an AI for Hardcore Football Fans")
# Sidebar for API key input
with st.sidebar:
openai_api_key = st.text_input("Enter your OpenAI API Key", type="password")
st.warning("Please enter your OpenAI API key to use the chatbot.")Sobald der Nutzer unsere App lädt, wird ihm das Eingabefeld präsentiert und nichts anderes angezeigt (außer dem Titel der App), bis er seinen Schlüssel eingibt.
4. Verbinde dich mit der Neo4j-Datenbank und initialisiere eine QA-Kette
Nachdem wir den OpenAI-API-Schlüssel des Nutzers erhalten haben, können wir unsere Ressourcen initialisieren: den Neo4j-Graphen und die QA-Kettenklasse:
# Initialize connections and models
@st.cache_resource(show_spinner=False)
def init_resources(api_key):
graph = Neo4jGraph(
url=neo4j_uri,
username=neo4j_user,
password=neo4j_password,
enhanced_schema=True,
)
graph.refresh_schema()
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(api_key=api_key, model="gpt-4o"),
graph=graph,
verbose=True,
show_intermediate_steps=True,
allow_dangerous_requests=True,
)
return graph, chainDie Funktioninit_resources() nimmt den API-Schlüssel als Argument entgegen und stellt eine Verbindung mit der Graphdatenbank her. Anschließend wird das Graphenschema (Struktur) aktualisiert, damit der LLM bei der Formulierung von Cypher-Abfragen über aktuelle Informationen über die Datenbankstruktur verfügt. Zum Schluss wird die GraphCypherQAChain mit dem Graphen und dem OpenAI-Modell initialisiert und gibt sowohl den Graphen als auch die Kettenobjekte zur weiteren Verwendung in der Anwendung zurück.
Erwähnenswert ist die Verwendung des st.cache_resource() Dekorators. Dieser Dekorator speichert den Graphen und die Ketteninstanzen, was die Leistung verbessert. Wir müssen nicht jedes Mal neue Instanzen erstellen, wenn ein Nutzer die App lädt, daher ist das Caching ein effizienter Ansatz.
Lass uns den Initialisierer mit einer API-Schlüsselprüfung ausführen:
# Initialize resources only if API key is provided
if openai_api_key:
with st.spinner("Initializing resources..."):
graph, chain = init_resources(openai_api_key)
st.success("Resources initialized successfully!", icon="🚀")5. Nachrichtenverlauf zu Streamlit hinzufügen
Sobald die Ressourcen verfügbar sind, müssen wir die Nachrichtenhistorie mithilfe des Sitzungsstatus von Streamlit aktivieren. Wir wollen auch eine erste KI-Nachricht anzeigen, die den Nutzer darüber informiert, was der Bot tut.
Dazu erstellen wir einen neuen messages Schlüssel in st.session_state und setzen seinen Wert auf eine Liste mit einem einzelnen Element. Das Element ist ein Wörterbuch mit zwei Schlüsseln:
role: Für wen die Nachricht bestimmt istcontent: Der Inhalt der Nachricht
# Initialize message history
if "messages" not in st.session_state:
st.session_state.messages = [
{
"role": "assistant",
"content": "Hello! Ask me anything about International Football from 1872 to (the almost) present day!",
}
]Falls es bereits einen Nachrichtenverlauf im Inneren gibt st.session_state.messagesvorhanden ist, zeigen wir sie mit st.chat_message und st.markdown Komponenten:
# Display chat history
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])6. Chat-Komponenten anzeigen
Jetzt definieren wir eine Funktion, query_graph, die die Kette mit einer vom Benutzer angegebenen Eingabeaufforderung ausführt. Die Methode .invoke() der Kette akzeptiert ein Wörterbuch mit dem Schlüssel-Werte-Paar der Abfrage und gibt ein anderes Wörterbuch als Ausgabe zurück. Wir wollen seinen result Schlüssel:
def query_graph(query):
try:
result = chain.invoke({"query": query})["result"]
return result
except Exception as e:
st.error(f"An error occurred: {str(e)}")
return "I'm sorry, I encountered an error while processing your request."Zeigen wir nun ein Eingabefeld am unteren Rand der Seite an, indem wir die st.chat_input Komponente:
# Accept user input
if prompt := st.chat_input("Your question..."):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)Sobald die Eingabeaufforderung vorliegt, speichern wir sie als Benutzernachricht im Nachrichtenverlauf und zeigen sie auf dem Bildschirm an. Dann führen wir mit einer weiteren API-Schlüsselprüfung die Funktion query_graph aus und übergeben die Eingabeaufforderung:
if prompt := st.chat_input("Your question..."):
...
# Generate answer if API key is provided
if openai_api_key:
with st.spinner("Thinking..."):
response = query_graph(prompt)
with st.chat_message("assistant"):
st.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response})
else:
st.error("Please enter your OpenAI API key in the sidebar to use the chatbot.")Wir fügen ein Spinner-Widget hinzu, während die Cypher-Abfrage und die endgültige Antwort erstellt werden. Dann zeigen wir die Nachricht an und fügen sie dem Nachrichtenverlauf hinzu.
Das war's! Die App ist jetzt fertig:
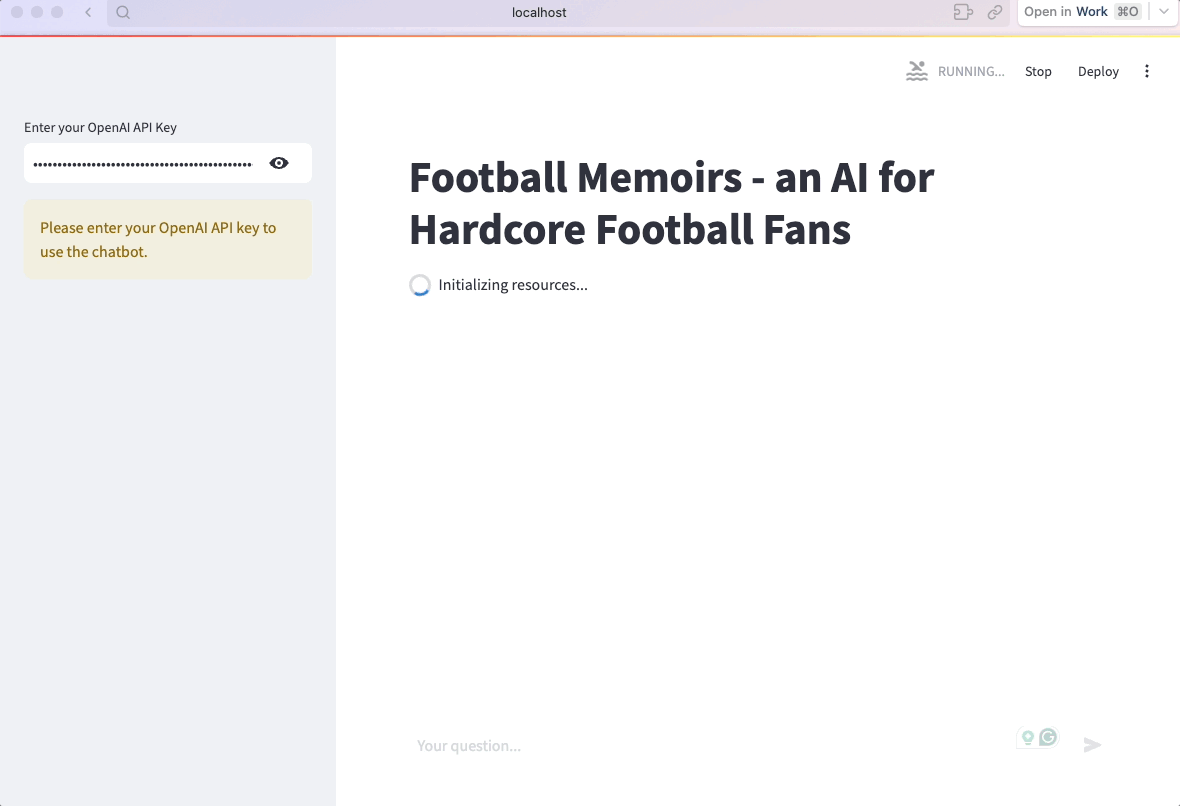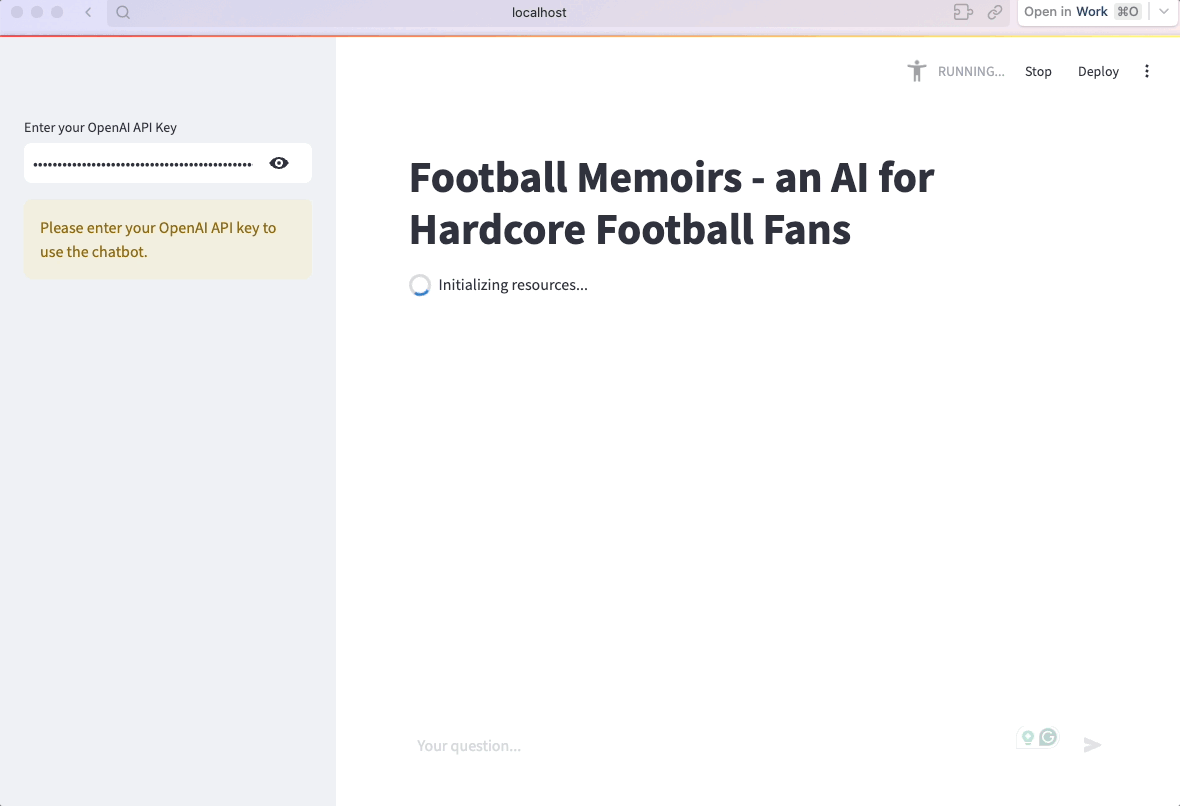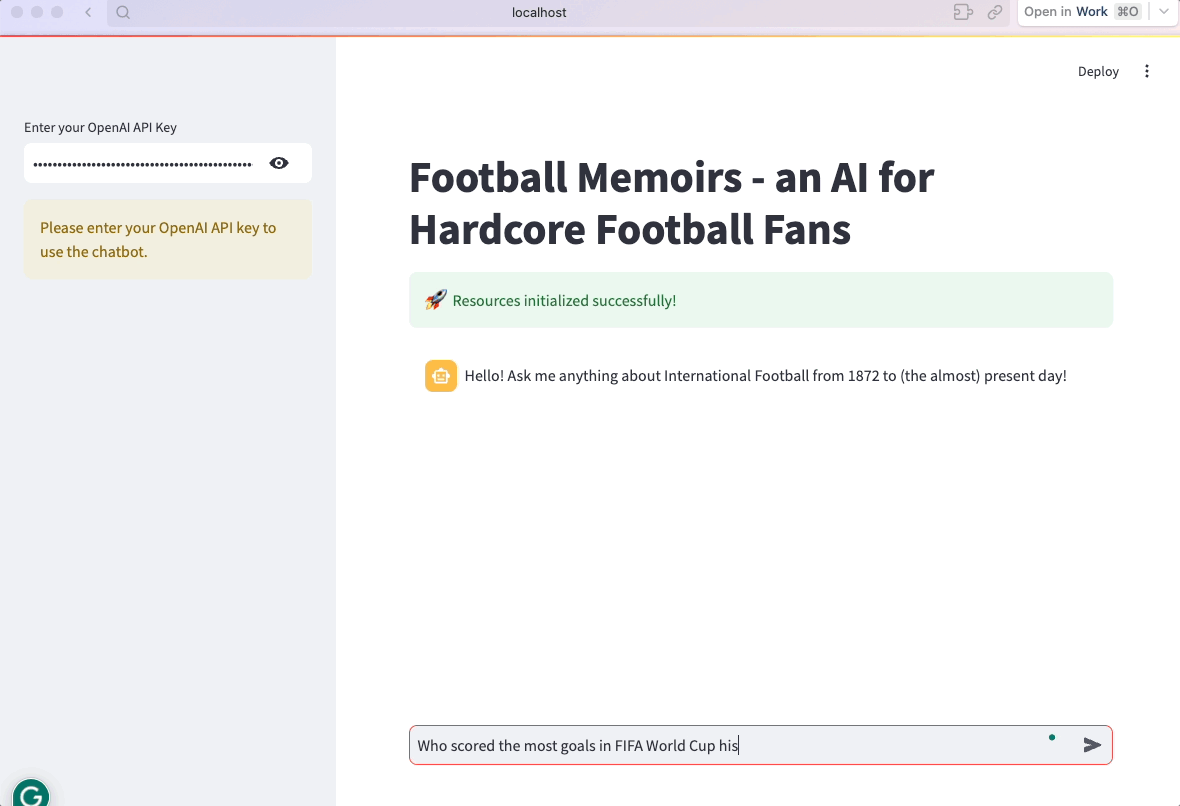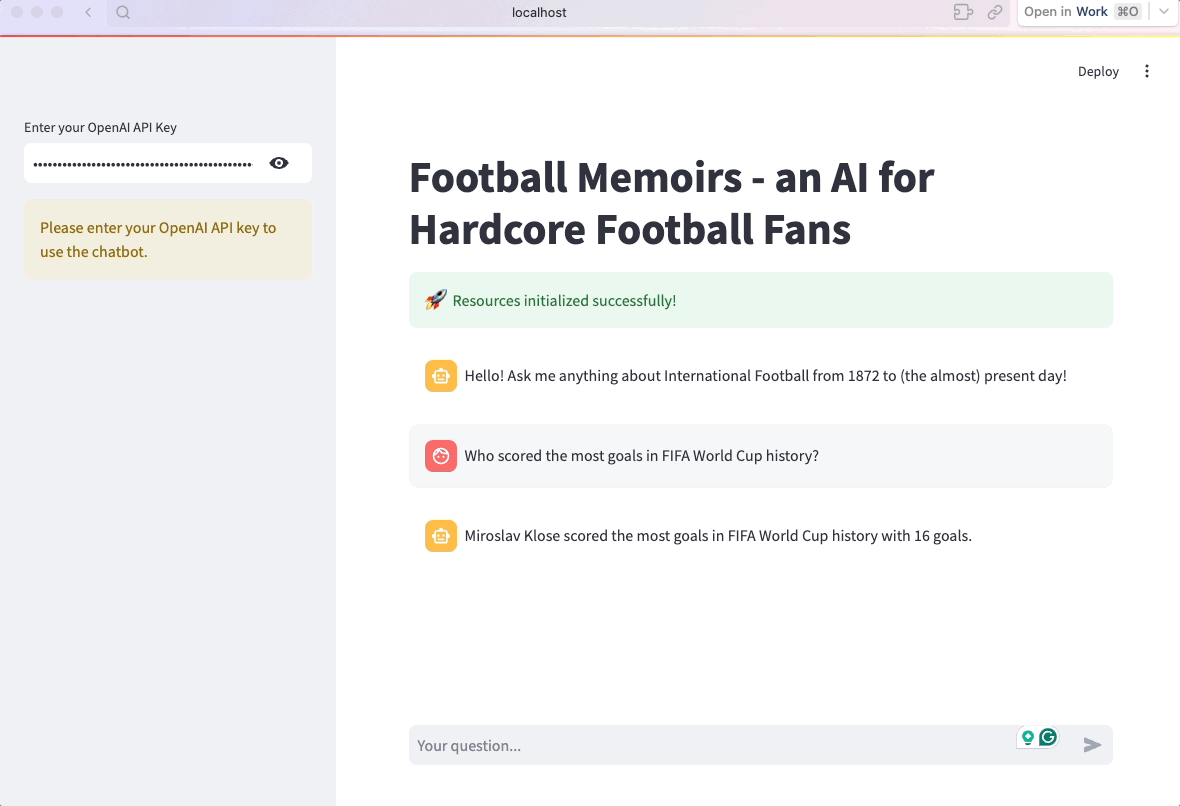
7. Optimiere und organisiere den Code
Die App ist fertig, aber sie ist in einer einzigen Datei ohne optimierte Struktur geschrieben. Wir sollten sie überarbeiten und modular gestalten:
$ cd football_chatbot
$ rm -rf . # Start from scratch
$ mkdir .streamlit
$ touch {.streamlit/secrets.toml,.gitignore,app.py,chat_utils.py,graph_utils.py,README.MD,requirements.txt}Dieses Mal enthält unsere Verzeichnisstruktur ein paar mehr Dateien:
.
├── .git
├── .gitignore
├── .streamlit
├── README.md
├── app.py
├── chat_utils.py
├── graph_utils.py
├── requirements.txtJetzt, innerhalb graph_utils.pyfügst du den folgenden organisierten Code ein:
# graph_utils.py
import streamlit as st
from langchain.chains import GraphCypherQAChain
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
@st.cache_resource(show_spinner=False)
def init_resources(api_key):
graph = Neo4jGraph(
url=st.secrets["NEO4J_URI"],
username=st.secrets["NEO4J_USER"],
password=st.secrets["NEO4J_PASSWORD"],
enhanced_schema=True,
)
graph.refresh_schema()
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(api_key=api_key, model="gpt-4o"),
graph=graph,
verbose=True,
show_intermediate_steps=True,
allow_dangerous_requests=True,
)
return graph, chain
def query_graph(chain, query):
result = chain.invoke({"query": query})["result"]
return resultHier liegt der Unterschied in der Funktionquery_graph. Insbesondere gibt es keine Fehlerbehandlung und keine Anzeige mit der Funktion st.error. Wir werden diesen Teil in die Hauptdatei app.py verschieben.
Arbeiten wir nun an der chat_utils.py Datei:
# chat_utils.py
import streamlit as st
def initialize_chat_history():
if "messages" not in st.session_state:
st.session_state.messages = [
{
"role": "assistant",
"content": "Hello! Ask me anything about International Football from 1872 to (the almost) present day!",
}
]
def display_chat_history():
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])Zuerst erstellen wir zwei Funktionen:
initialize_chat_history: Aktiviere den Nachrichtenverlauf mit einer Standardnachricht, wenn er noch nicht verfügbar ist.display_chat_history: Alle Nachrichten im Nachrichtenverlauf anzeigen.
Wir erstellen eine weitere Funktion, um Aufforderungen und Antworten zu erstellen:
# chat_utils.py
def handle_user_input(openai_api_key, query_graph_func, chain):
if prompt := st.chat_input("Your question..."):
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
if openai_api_key:
with st.spinner("Thinking..."):
try:
response = query_graph_func(chain=chain, query=prompt)
except Exception as e:
st.error(f"An error occurred: {str(e)}")
response = "I'm sorry, I encountered an error while processing your request."
with st.chat_message("assistant"):
st.markdown(response)
st.session_state.messages.append({"role": "assistant", "content": response})
else:
st.error(
"Please enter your OpenAI API key in the sidebar to use the chatbot."
)Der Unterschied ist hier die Verwendung eines try-except Blocks um query_graph_func herum , um Fehler abzufangen und anzuzeigen. Der Rest der Funktionalität ist derselbe.
Zum Schluss, drinnen app.pysetzen wir alles zusammen:
import streamlit as st
from graph_utils import init_resources, query_graph
from chat_utils import initialize_chat_history, display_chat_history, handle_user_input
st.title("Football Memoirs - an AI for Hardcore Football Fans")
# Sidebar for API key input
with st.sidebar:
openai_api_key = st.text_input("Enter your OpenAI API Key", type="password")
st.warning("Please enter your OpenAI API key to use the chatbot.")Wir importieren die Funktionen aus anderen Dateien, legen den App-Titel fest und fügen das Eingabefeld für den API-Schlüssel in der linken Seitenleiste hinzu. Dann initialisieren wir nach einer API-Schlüsselprüfung die Ressourcen und zeigen den Chatverlauf und die Komponenten an:
# Initialize resources only if the API key is provided
if openai_api_key:
with st.spinner("Initializing resources..."):
graph, chain = init_resources(openai_api_key)
st.success("Resources initialized successfully!", icon="🚀")
# Initialize and display chat history
initialize_chat_history()
display_chat_history()
# Handle user input
handle_user_input(
openai_api_key=openai_api_key, query_graph_func=query_graph, chain=chain
)Jetzt ist die App bereit für den Einsatz!
8. Stelle die App in der Streamlit Cloud bereit
Die einfachste und problemloseste Methode zur Bereitstellung von Streamlit-Apps ist die Nutzung der Streamlit Cloud. Alle auf Streamlit Cloud gehosteten Apps sind kostenlos, solange du die Standardhardware verwendest.
Aber zuerst fügen wir diese beiden Zeilen zu unserer .gitignore Datei ein, damit unsere App-Geheimnisse nicht auf GitHub angezeigt werden:
*.toml
__pycache__Außerdem braucht jedes (gute) Repository eine README-Datei. Also, lass uns unsere schreiben:
# Football Memoirs - AI for Hardcore Football Fans
This Streamlit app uses a Neo4j graph database and OpenAI's GPT-4o model to answer questions about international football history from 1872 to the present day.
## Setup
1. Clone this repository
2. Install dependencies: pip install -r requirements.txt
3. Set up your .streamlit/secrets.toml file with the following keys:
- NEO4J_URI
- NEO4J_USER
- NEO4J_PASSWORD
4. Run the app: streamlit run app.py
## Deployment
To deploy this app on Streamlit Cloud:
1. Push your code to a GitHub repository
2. Connect your GitHub account to Streamlit Cloud
3. Create a new app in Streamlit Cloud and select your repository
4. Add your secrets in the Streamlit Cloud dashboard under the "Secrets" section
5. Deploy your appStreamlit Cloud Apps benötigen eine requirements.txt Datei, um Umgebungen mit Abhängigkeiten zu füllen. Füge diese zu deinen hinzu:
streamlit
langchain
langchain-community
langchain-openai
neo4jJetzt initialisieren wir git, machen unseren ersten Commit und pushen ihn in das Remote-Repository, das du für das Projekt erstellt haben solltest:
$ git init
$ git add .
$ git commit -m "Initial commit"
$ git remote add origin https://github.com/Username/repository.git
$ git push --set-upstream origin mainDann melde dich bei Streamlit Cloud an, besuche dein Dashboard und klicke auf "App erstellen":
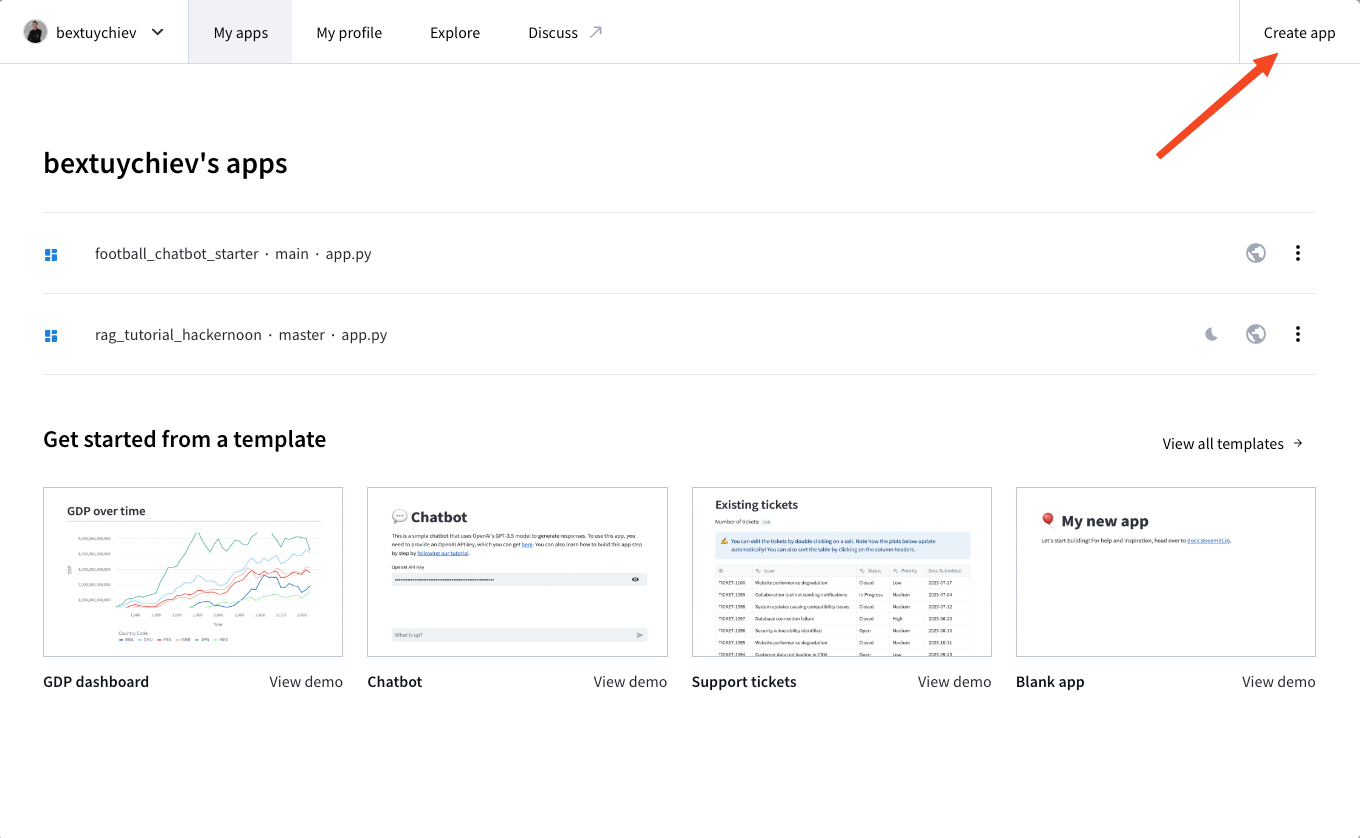
Dir werden die folgenden Optionen angezeigt:
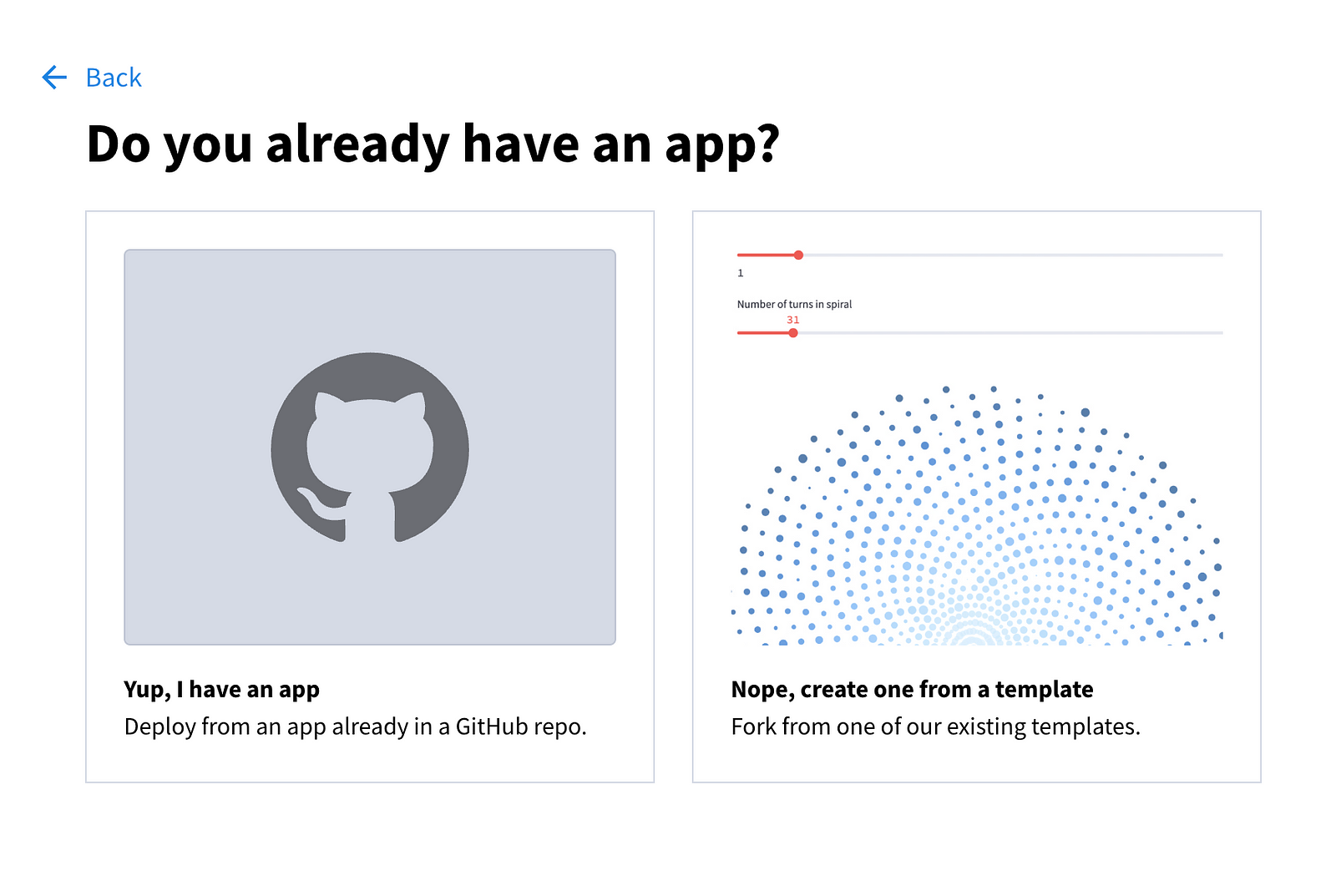
Wähle die erste Option und fülle die Felder auf der nächsten Seite aus.
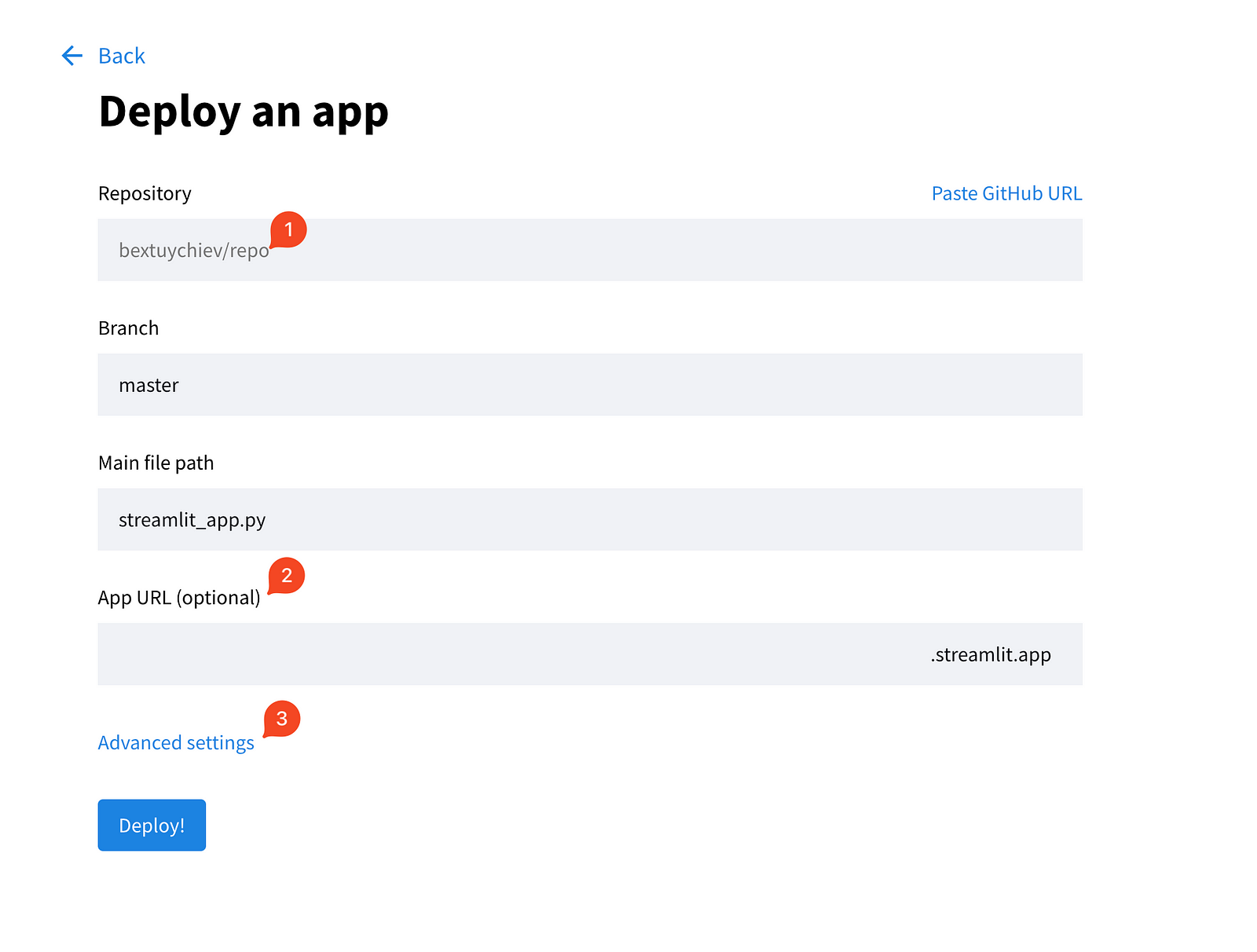
Erweitere außerdem die erweiterten Einstellungen, die dir zwei Felder zur Auswahl der Python-Version und zum Einfügen der für deine App erforderlichen Anmeldedaten bieten. Hier kopierst du den Inhalt der lokalen Datei secrets.toml und fügst ihn ein:
Speichere die Geheimnisse und klicke auf "Bereitstellen!". Die App sollte innerhalb von ein paar Minuten einsatzbereit sein!
Fazit
In diesem Tutorial haben wir einen KI-Chatbot gebaut, der mit Streamlit, LangChain und einer Neo4j-Graphdatenbank Fragen zur internationalen Fußballgeschichte beantwortet. Wir haben darüber berichtet:
- Erstellen einer benutzerfreundlichen Weboberfläche mit Streamlit
- Integration der GPT-Modelle von OpenAI mit einer Graphdatenbank unter Verwendung von LangChain
- Implementierung der Retrieval Augmented Generation (RAG)
- Aufbau einer modularen Codebasis
- Bereitstellung in der Streamlit Cloud
Dieses Projekt dient als Vorlage für die Erstellung von Chat-KI-Benutzeroberflächen. Während die Logik der App in jedem Projekt anders ist, werden die UI-Komponenten, die wir heute verwendet haben, in den meisten Projekten in irgendeiner Form eingesetzt.
Beachte auch, dass die Erstellung der Benutzeroberfläche der einfachste Teil der Entwicklung von KI-Anwendungen ist. Den größten Teil deiner Zeit wirst du damit verbringen, die Leistung der App zu verbessern. An unserer Pipeline zur Erzeugung von Cypher muss zum Beispiel noch viel gearbeitet werden. Aufgrund des Mangels an Beispielen, der vagen Graphenstruktur und der Einschränkungen der LLMs ist die Genauigkeit unserer App für die Produktion nicht akzeptabel. Behalte diese Aspekte bei der Entwicklung deiner Apps im Hinterkopf.
Wenn du mehr darüber erfahren möchtest Entwicklung großer Sprachmodelledann schau dir unseren Skill Track an, in dem du lernst, wie du mit PyTorch und Hugging Face LLMs mit den neuesten Deep Learning- und NLP-Techniken erstellst.


