
Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
99.8K
¡Empieza a utilizar la API OpenAI y mucho más!
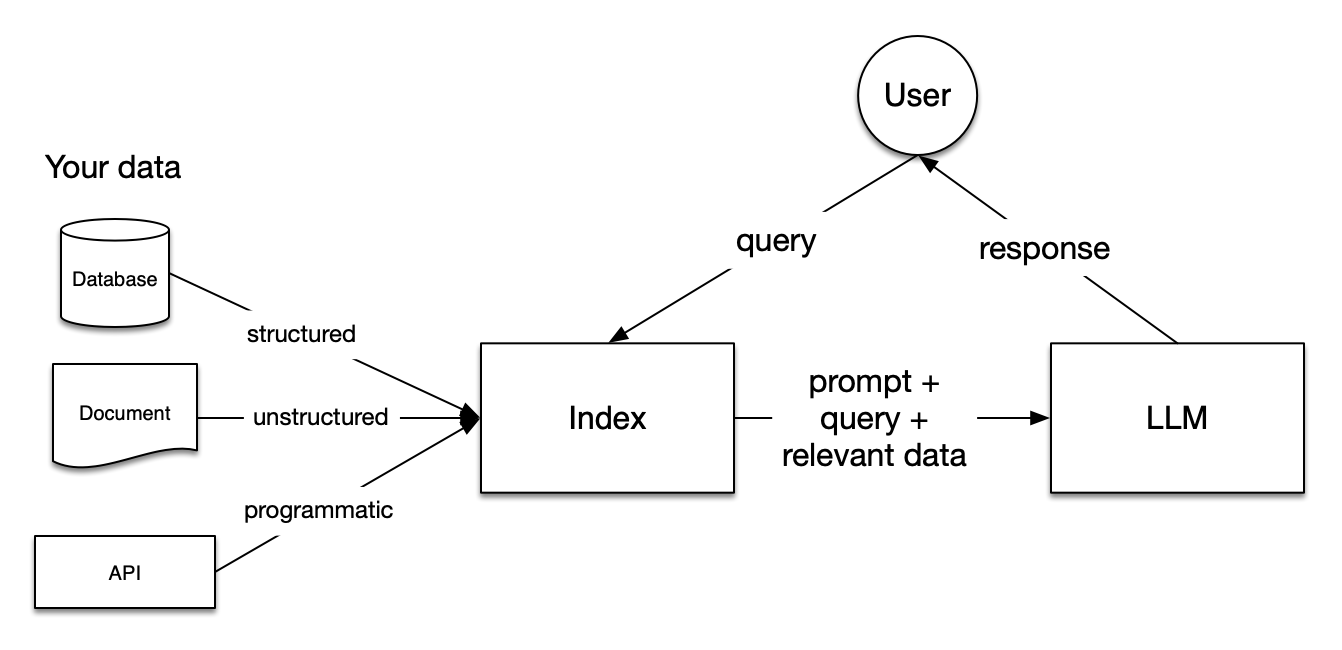
Imagen de la documentación de LlamaIndex
Los conductos de Generación Aumentada de Recuperación (RAG ) incluyen tres pasos: Indexación, Recuperación y Generación.
La indexación es fundamental para obtener respuestas precisas y contextualizadas con los LLM. Primero, empieza extrayendo y limpiando datos con distintos formatos de archivo, como documentos Word, archivos PDF o archivos HTML. Una vez depurados los datos, se convierten en texto plano normalizado. Para evitar las limitaciones de contexto dentro de los LLM, el texto se divide en trozos más pequeños. Este proceso se denomina Chunking. Después, cada trozo se transforma en un vector numérico o incrustación mediante un modelo de incrustación. Por último, se construye un índice para almacenar los trozos y sus correspondientes incrustaciones como pares clave-valor.
Durante la etapa de recuperación, la consulta del usuario también se convierte en una representación vectorial utilizando el mismo modelo de incrustación. A continuación, se calculan las puntuaciones de similitud entre el vector de consulta y los trozos vectorizados. El sistema recupera los K trozos con mayor similitud a la consulta del usuario.
La consulta del usuario y los trozos recuperados se introducen en una plantilla de consulta. El indicador aumentado obtenido en los pasos anteriores se da finalmente como entrada al LLM.
Al construir sistemas GAR, hay retos importantes que puedes encontrar en los tres pasos explicados anteriormente, como los siguientes:
A continuación, exploraremos estrategias para sortear estas limitaciones. Discutiremos tres estrategias generales: Chunking, Re-Ranking y Transformaciones de Consulta. Además, mostraremos cómo estas estrategias pueden ayudar a mejorar el rendimiento de la RAG construyendo un sistema RAG que responda a preguntas sobre entradas de Wikipedia utilizando Llamaindex y la API OpenAI . ¡Vamos a sumergirnos!
Antes de explorar los trucos para mejorar el rendimiento de un sistema RAG, necesitamos establecer un rendimiento de referencia estableciendo una tubería RAG sencilla. Empecemos instalando los paquetes llama-index y openai.
!pip install llama-index
!pip install openaiLlamaindex es un marco de datos para aplicaciones basadas en Grandes Modelos Lingüísticos (LLM). Permite ingerir distintos tipos de fuentes de datos externas, construir sistemas de Generación de Aumento de la Recuperación (RAG) y abstraer las integraciones con otros LLM en unas pocas líneas de código. Además, proporciona varias técnicas para generar resultados más precisos con los LLM.
Por defecto, utiliza el modelo OpenAI gpt-3.5-turbo para la generación de texto y el modelo text-embedding-ada-002 para la recuperación y las incrustaciones. Para utilizar estos modelos, es necesario crear una cuenta gratuita en la plataforma OpenAI y obtener una clave API OpenAI. Para obtener la clave, visita la documentación de la API de OpenAI.
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"Ahora que ya tenemos instalados nuestros paquetes, vamos a construir un sistema RAG que responda a preguntas basadas en las páginas de Wikipedia de Emma Stone, Ryan Gosling y La La Land. En primer lugar, tenemos que instalar la biblioteca wikipedia para extraer las páginas de Wikipedia:
!pip install wikipediaDespués, podemos descargar fácilmente los datos de Wikipedia:
# Import packages
from llama_index.core import (VectorStoreIndex,ServiceContext, download_loader)
# Download the documents from Wikipedia and load them
WikipediaReader = download_loader("WikipediaReader")
loader = WikipediaReader()
pages = ['Emma_Stone', 'La_La_Land', 'Ryan_Gosling']
documents = loader.load_data(pages=pages, auto_suggest=False, redirect = False)Una vez extraídos los datos, podemos dividir los documentos en trozos de 256 caracteres sin solapamientos. Después, estos trozos se transforman en vectores numéricos mediante el modelo de incrustación y se indexan en un Almacén de Vectores.
# Initialize the gpt3.5 model
gpt3 = OpenAI(temperature=0, model="gpt-3.5-turbo-instruct", api_key=OPENAI_API_KEY)
# Initialize the embedding model
embed_model = OpenAIEmbedding(model= OpenAIEmbeddingModelType.TEXT_EMBED_ADA_002, api_key=OPENAI_API_KEY)
# Transform chunks into numerical vectors using the embedding model
service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 256, chunk_overlap=0, embed_model=embed_model)
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
retriever = index.as_retriever(similarity_top_k=3)Para reducir el riesgo de alucinaciones, utilizamos el módulo PromptTemplate para garantizar que las respuestas del LLM se basan únicamente en el contexto proporcionado.
from llama_index.core.prompts import PromptTemplate
# Build a prompt template to only provide answers based on the loaded documents
template = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
"Don't give an answer unless it is supported by the context above.\n"
)
qa_template = PromptTemplate(template)Ahora que hemos configurado nuestro sistema GAR, podemos probarlo con preguntas basadas en documentos recuperados. ¡Pongámoslo a prueba!
Consulta 1: "¿Cuál es el argumento de la película que llevó a Emma Stone a ganar su primer Oscar?"
Esta primera consulta es un reto porque requiere que el modelo analice distintos datos:
# Create a prompt for the model
question = "What is the plot of the film that led Emma Stone to win her first Academy Award?"
# Retrieve the context from the model
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
# Generate the response
response = gpt3.complete(prompt)
print(str(response))Salida:
The plot of the film that made Emma Stone win her first Academy Award is not explicitly mentioned in the provided context.Consulta 2: "Compara las familias de Emma Stone y Ryan Gosling"
Esta segunda consulta es aún más desafiante que la anterior, ya que pide seleccionar los trozos relevantes relativos a las familias de los dos actores.
# Create a prompt for the model
question = "Compare the families of Emma Stone and Ryan Gosling"
# Retrieve the context from the model
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
# Generate the response
response = gpt3.complete(prompt)
print(str(response))Recibimos la siguiente salida:
Based on the context provided, it is not possible to compare the families of Emma Stone and Ryan Gosling as the information focuses on their professional collaboration and experiences while working on the film "La La Land." There is no mention of their personal family backgrounds or relationships in the context provided.Como puedes ver, hemos recibido respuestas mediocres en ambos casos. En las secciones siguientes, ¡exploremos formas de mejorar el rendimiento de este sistema RAG!
Podemos empezar personalizando el tamaño de los trozos y el solapamiento de los trozos. Como hemos dicho antes, los documentos se dividen en trozos con un solapamiento específico. Por defecto, LlamaIndex utiliza 1024 como tamaño de trozo por defecto y 20 como solapamiento de trozo por defecto. Además de estos hiperparámetros, el sistema recupera por defecto los 2 trozos superiores.
Por ejemplo, podemos fijar el tamaño de los trozos en 512, el solapamiento de los trozos en 50 y aumentar los trozos máximos recuperados:
# modify default values of chunk size and chunk overlap
service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 512, chunk_overlap=50, embed_model=embed_model)
# build index
index = VectorStoreIndex.from_documents(
documents, service_context=service_context_gpt3
)
# returns the engine for the index
query_engine = index.as_query_engine(similarity_top_k=4)Consulta 1: "¿Cuál es el argumento de la película que llevó a Emma Stone a ganar su primer Oscar?"
# generate the response
response = query_engine.query("What is the plot of the film that led Emma Stone to win her first Academy Award?")
print(response)Salida:
The film that made Emma Stone win her first Academy Award is a romantic musical called La La Land.Comparada con la respuesta anterior, es ligeramente mejor. Reconoció con éxito a La La Land como la película que llevó a Emma Stone a ganar su primer Oscar, pero no fue capaz de describir el argumento de la película.
Consulta 2: "Compara las familias de Emma Stone y Ryan Gosling"
# generate the response
response = query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Salida:
Emma Stone has expressed her close relationship with her family and mentioned being blessed with great family and people around her. She has also shared about her mother's battle with breast cancer and their celebration by getting matching tattoos. On the other hand, there is no specific information provided about Ryan Gosling's family or his personal relationships in the context.De nuevo, el resultado de la canalización RAG mejoró, pero sigue sin captar información sobre la familia de Ryan Gosling.
A medida que el conjunto de datos crece en tamaño y complejidad, la selección de la información relevante para devolver respuestas adaptadas a consultas complejas se vuelve crucial. Para ello, una familia de técnicas llamada Re-Ranking te permite comprender qué trozos son importantes dentro del texto. Reordenan y filtran los documentos, clasificando primero los más relevantes.
Hay dos enfoques principales para el Re-Ranking:
Antes de aplicar estos enfoques de Re-Ranking, evaluemos lo que el sistema RAG de referencia devuelve como los tres trozos principales para nuestra segunda consulta:
# Retrieve the top three chunks for the second query
retriever = index.as_retriever(similarity_top_k=3)
query = "Compare the families of Emma Stone and Ryan Gosling"
nodes = retriever.retrieve(query)
# Print the chunks
for node in nodes:
print('----------------------------------------------------')
display_source_node(node, source_length = 500)Este es el resultado antes de la Re-Ranificación; cada trozo tiene un Node ID con una puntuación de similitud.
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 0.8415899563985404
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 0.831147173341674
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles. Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 0.8289486590392277
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...Para recuperar los trozos relevantes, podemos utilizar un modelo de Re-Ranking de código abierto de Hugging Face, llamado modelo bge-ranker-base.
Al igual que la API OpenAI, para utilizar Cara de Abrazo es necesario obtener un token de acceso de usuario. Puedes crear un token de acceso de usuario desde Cara de Abrazo siguiendo esta documentación.
HF_TOKEN = userdata.get('HF_TOKEN')
os.environ['HF_TOKEN'] = HF_TOKENAntes de seguir adelante, también tenemos que instalar las bibliotecas necesarias para utilizar el modelo de Re-Ranking:
%pip install llama-index-postprocessor-flag-embedding-reranker
!pip install git+https://github.com/FlagOpen/FlagEmbedding.gitPor último, utilizamos el modelo bge-ranker-base para devolver los trozos más relevantes.
# Import packages
from llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingReranker
from llama_index.core.schema import QueryBundle
# Re-Rank chunks based on the bge-reranker-base-model
reranker = FlagEmbeddingReranker(
top_n = 3,
model = "BAAI/bge-reranker-base",
)
# Return the updated chunks
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)Este es el resultado tras la Re-Ranificación:
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 3.0143558979034424
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 2.2117154598236084
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 1.6185210943222046
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles.Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...De la salida se deduce que el nodo con ID 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f pasa de la segunda posición a la tercera. Además, cabe destacar que hay más variabilidad en las puntuaciones de similitud.
Ahora que hemos utilizado el Re-Ranking, evaluemos cómo es ahora la respuesta RAG a la consulta original:
# Initialize the query engine with Re-Ranking
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors=[reranker]
)
# Print the response from the model
response = query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Esta es la respuesta proporcionada tras aplicar el modelo de Re-Ranking:
Both Emma Stone and Ryan Gosling have close relationships with their families. Stone has expressed her gratitude for having a great family and people around her who keep her grounded. Gosling, on the other hand, has drawn from his own experiences as an aspiring artist, indicating a connection to his personal background.Hay una mejora significativa en comparación con las respuestas anteriores, pero sigue siendo incompleta. Evaluemos cómo un enfoque de Re-Ranking basado en LLM puede ayudar a mejorar el rendimiento del GAR.
Esta vez, podemos contar con un LLM como Re-Ranker. Aquí utilizamos el módulo RankGPT, que aprovecha las capacidades del modelo GPT para clasificar documentos dentro del sistema RAG. Para empezar, instalamos los paquetes necesarios:
%pip install llama-index-postprocessor-rankgpt-rerankUtilizamos la función RankGPTRerank para volver a clasificar los trozos utilizando el modelo gpt-3.5-turbo-0125.
# Import packages
from llama_index.postprocessor.rankgpt_rerank import RankGPTRerank
# Re-Rank the top 3 chunks based on the gpt-3.5-turbo-0125 model
reranker = RankGPTRerank(
top_n = 3,
llm = OpenAI(model="gpt-3.5-turbo-0125"),
)
# Display the top 3 chunks based on RankGPT
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)Utilizando RankGPT, obtenemos los siguientes trozos:
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 1.6185210943222046
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles.Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...
----------------------------------------------------
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 3.0143558979034424
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 2.2117154598236084
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...Como RankGPT no ordena los pasajes en función de la puntuación de similitud, las puntuaciones presentadas en la salida no se actualizan. A partir del resultado, podemos observar que el primer nodo considerado el más relevante menciona tanto a Emma Stone como a Ryan Gosling, mientras que los nodos restantes contienen más detalles sobre la vida de Emma Stone.
Ahora, si imprimimos la respuesta del modelo con esta Metodología de Re-Ranking, obtendremos el siguiente resultado:
Both Emma Stone and Ryan Gosling have close relationships with their families. Stone has expressed gratitude for having a great family and supportive people around her, while Gosling has drawn from his own experiences as an aspiring artist, indicating a connection to his family as well. Stone's family has played a significant role in her life, supporting her career pursuits and celebrating important milestones with her. Similarly, Gosling's experiences as an actor have likely been influenced by his family dynamics and relationships.La respuesta es más larga y contiene más detalles que la anterior técnica de Re-Ranking.
La transformación de consultas, también llamada reescritura de consultas, es un enfoque que convierte una consulta en otra consulta en lugar de utilizar la consulta sin procesar para recuperar los k trozos principales. Vamos a explorar las siguientes técnicas:
HyDE significa Incrustación Hipotética de Documentos. Consta de dos pasos. En primer lugar, crea una respuesta hipotética a una consulta del usuario. Una vez determinada la respuesta/documento hipotético, la respuesta y la consulta se transforman en incrustaciones. A continuación, el sistema recupera los documentos más próximos a las incrustaciones en el espacio vectorial. ¡Veámoslo en acción!
# Import packages
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
from llama_index.core.query_engine.transform_query_engine import (
TransformQueryEngine,
)
# build index and query engine for the index
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
query_engine = index.as_query_engine(similarity_top_k=4)
# HyDE setup
hyde = HyDEQueryTransform(include_original=True)
# Transform the query engine using HyDE
hyde_query_engine = TransformQueryEngine(query_engine, hyde)
# Print the response from the model
response = hyde_query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Este es el resultado:
Both Emma Stone and Ryan Gosling come from diverse family backgrounds. Ryan Gosling's parents were of part French Canadian descent, along with some German, English, Scottish, and Irish. He grew up in a family that practiced the Church of Jesus Christ of Latter-day Saints. On the other hand, Emma Stone was born and raised in Scottsdale, Arizona, without specific details provided about her family's ethnic background or religious affiliation.En comparación con los métodos de Re-Ranking, observamos una mejora parcial. Anteriormente, los resultados se referían más a la relación de los actores con sus familias. Ahora, se centran más en los orígenes.
El enfoque de transformación de consultas en varios pasos divide la consulta del usuario en subpreguntas secuenciales. Este método puede ser útil cuando se trabaja con preguntas complejas.
Como hemos observado, los LLM tienden a tener dificultades cuando comparan dos hechos, aunque puedan responder correctamente cuando la pregunta se refiere sólo a un tema específico. Aquí podemos ver en acción las transformaciones de consulta en varios pasos.
# Multi-step query setup
step_decompose_transform_gpt3 = StepDecomposeQueryTransform(gpt3, verbose=True)
index_summary = "Breaks down the initial query"
# Return query engine for the index
multi_step_query_engine = MultiStepQueryEngine(
query_engine=query_engine,
query_transform=step_decompose_transform_gpt3,
index_summary=index_summary
)
# print the response from the model
response = multi_step_query_engine.query("Compare the families of Emma Stone and Ryan Gosling")Podemos ver las cuestiones intermedias que nos permiten llegar al resultado final:
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is the family background of Emma Stone and Ryan Gosling?
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is the specific family background of Emma Stone?
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is Emma Stone's relationship with her family like?Es la siguiente respuesta a la consulta del usuario:
Both Ryan Gosling and Emma Stone have strong family connections, with Emma Stone emphasizing the importance of her family in keeping her grounded. Ryan Gosling's family background includes a mix of French Canadian, German, English, Scottish, and Irish heritage.En este caso, fue útil utilizar una transformación de consulta de varios pasos para comparar las familias de Emma Stone y Ryan Gosling.
En este artículo, has aprendido varias técnicas para Mejorar el Rendimiento de los GAR. Ya sea Chunking, Re-Ranking o transformaciones de consulta, el mejor enfoque suele depender del caso de uso y del resultado que desees para una consulta determinada.
Si quieres profundizar en la RAG, te recomendamos que veas nuestros code-alongs sobre Generación Aumentada de Recuperación con LlamaIndex y Generación Aumentada de Recuperación con GPT y Milvus. Estos vídeos muestran cómo combinar LLM con bases de datos vectoriales utilizando la generación aumentada de recuperación en diferentes casos de uso.
¡Continúa hoy tu viaje por la IA!
Curso
Curso
Curso