
Cours
Concepts des grands modèles de langage (LLM)
2 h
99.8K
Commencez à utiliser l'API OpenAI et plus encore !
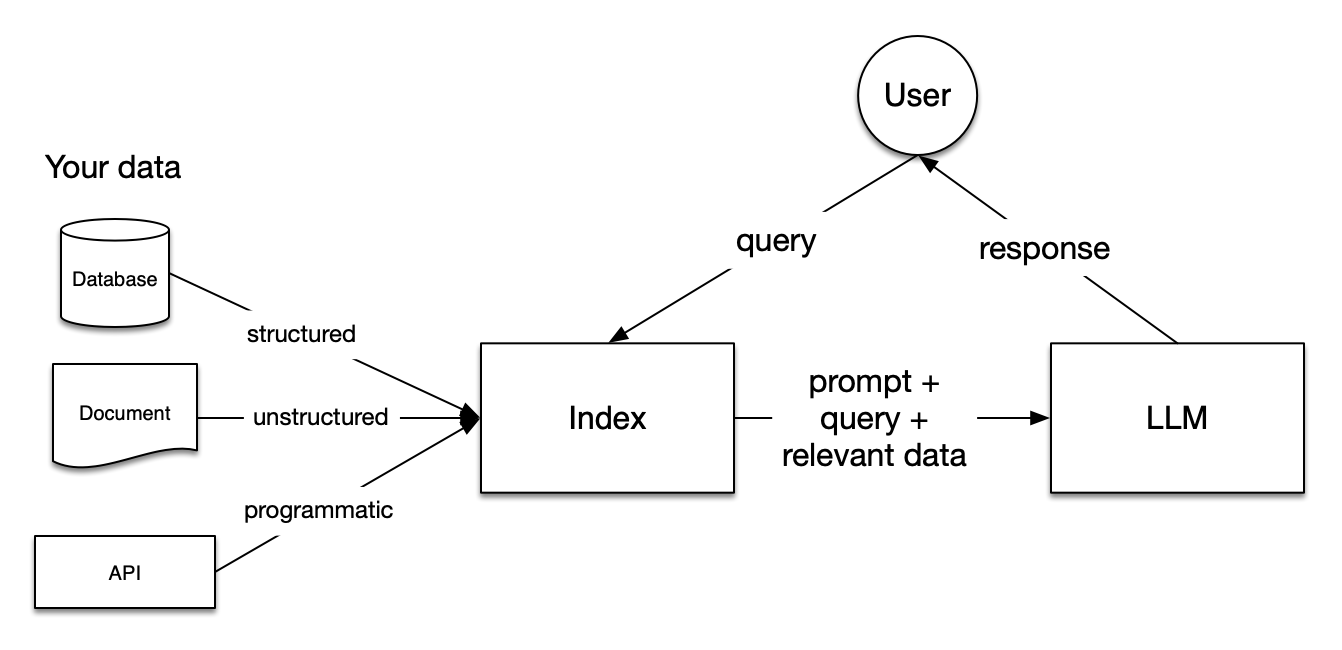
Image de LlamaIndex Documentation
Les pipelines RAG (Retrieval Augmented Generation) comprennent trois étapes : Indexation, recherche et génération.
L'indexation est fondamentale pour obtenir des réponses précises et contextuelles avec les LLM. Il commence par extraire et nettoyer les données dans différents formats de fichiers, tels que les documents Word, les fichiers PDF ou les fichiers HTML. Une fois les données nettoyées, elles sont converties en texte clair normalisé. Pour éviter les limitations de contexte dans les LLM, le texte est divisé en plus petits morceaux. Ce processus est appelé Chunking. Ensuite, chaque morceau est transformé en un vecteur numérique ou en un modèle d'intégration à l'aide d'un modèle d'intégration. Enfin, un index est créé pour stocker les morceaux et leurs encastrements correspondants sous forme de paires clé-valeur.
Au cours de la phase de recherche, la requête de l'utilisateur est également convertie en une représentation vectorielle à l'aide du même modèle d'intégration. Ensuite, les scores de similarité entre le vecteur de la requête et les morceaux vectorisés sont calculés. Le système extrait les K premiers morceaux présentant la plus grande similitude avec la requête de l'utilisateur.
La requête de l'utilisateur et les morceaux récupérés sont introduits dans un modèle d'invite. L'invite augmentée obtenue lors des étapes précédentes est finalement donnée en entrée au LLM.
Lorsque vous construisez des systèmes RAG, vous pouvez être confronté à des défis importants au cours des trois étapes expliquées précédemment, tels que les suivants :
Vous trouverez ci-dessous des stratégies pour contourner ces limitations. Nous examinerons trois grandes stratégies : Chunking, Re-Ranking, et Query Transformations. En outre, nous montrerons comment ces stratégies peuvent contribuer à améliorer les performances des RAG en construisant un système RAG qui répond aux questions sur les entrées de Wikipédia à l'aide de Llamaindex et de l'API OpenAI . Plongeons dans l'aventure !
Avant d'explorer les astuces permettant d'améliorer les performances d'un système RAG, nous devons établir une performance de base en créant un simple pipeline RAG. Commençons par installer les paquets llama-index et openai.
!pip install llama-index
!pip install openaiLlamaindex est un cadre de données pour les applications basées sur les grands modèles linguistiques (LLM). Il permet d'ingérer différents types de sources de données externes, de construire des systèmes de génération d'augmentation de la recherche (RAG) et d'abstraire les intégrations avec d'autres LLM en quelques lignes de code. En outre, il fournit plusieurs techniques pour générer des résultats plus précis avec les LLM.
Par défaut, il utilise le modèle OpenAI gpt-3.5-turbo pour la génération de texte et le modèle text-embedding-ada-002 pour la recherche et l'intégration. Pour utiliser ces modèles, il est nécessaire de créer un compte gratuit sur la plateforme OpenAI et d'obtenir une clé API OpenAI. Pour obtenir la clé, veuillez consulter la documentation de l'API OpenAI.
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"Maintenant que nos paquets sont installés, nous allons construire un système RAG qui répondra à des questions basées sur les pages Wikipédia d'Emma Stone, Ryan Gosling et La La Land. Tout d'abord, nous devons installer la bibliothèque wikipedia pour extraire les pages de Wikipedia :
!pip install wikipediaEnsuite, nous pouvons facilement télécharger les données de Wikipedia :
# Import packages
from llama_index.core import (VectorStoreIndex,ServiceContext, download_loader)
# Download the documents from Wikipedia and load them
WikipediaReader = download_loader("WikipediaReader")
loader = WikipediaReader()
pages = ['Emma_Stone', 'La_La_Land', 'Ryan_Gosling']
documents = loader.load_data(pages=pages, auto_suggest=False, redirect = False)Une fois les données extraites, nous pouvons diviser les documents en morceaux de 256 caractères sans chevauchement. Ensuite, ces morceaux sont transformés en vecteurs numériques à l'aide du modèle d'intégration et indexés dans un magasin de vecteurs.
# Initialize the gpt3.5 model
gpt3 = OpenAI(temperature=0, model="gpt-3.5-turbo-instruct", api_key=OPENAI_API_KEY)
# Initialize the embedding model
embed_model = OpenAIEmbedding(model= OpenAIEmbeddingModelType.TEXT_EMBED_ADA_002, api_key=OPENAI_API_KEY)
# Transform chunks into numerical vectors using the embedding model
service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 256, chunk_overlap=0, embed_model=embed_model)
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
retriever = index.as_retriever(similarity_top_k=3)Pour réduire le risque d'hallucinations, nous utilisons le module PromptTemplate pour garantir que les réponses du LLM sont basées uniquement sur le contexte fourni.
from llama_index.core.prompts import PromptTemplate
# Build a prompt template to only provide answers based on the loaded documents
template = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
"Don't give an answer unless it is supported by the context above.\n"
)
qa_template = PromptTemplate(template)Maintenant que nous avons mis en place notre système RAG, nous pouvons le tester avec des questions basées sur les documents récupérés. Mettons-le à l'épreuve !
Question 1 : "Quelle est l'intrigue du film qui a permis à Emma Stone de remporter son premier Oscar ?
Cette première requête est un défi car elle demande au modèle d'examiner différents éléments d'information :
# Create a prompt for the model
question = "What is the plot of the film that led Emma Stone to win her first Academy Award?"
# Retrieve the context from the model
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
# Generate the response
response = gpt3.complete(prompt)
print(str(response))Sortie :
The plot of the film that made Emma Stone win her first Academy Award is not explicitly mentioned in the provided context.Question 2 : "Comparez les familles d'Emma Stone et de Ryan Gosling.
Cette deuxième question est encore plus difficile que la précédente puisqu'elle demande de sélectionner les morceaux pertinents concernant les familles des deux acteurs.
# Create a prompt for the model
question = "Compare the families of Emma Stone and Ryan Gosling"
# Retrieve the context from the model
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
# Generate the response
response = gpt3.complete(prompt)
print(str(response))Nous obtenons le résultat suivant :
Based on the context provided, it is not possible to compare the families of Emma Stone and Ryan Gosling as the information focuses on their professional collaboration and experiences while working on the film "La La Land." There is no mention of their personal family backgrounds or relationships in the context provided.Comme vous pouvez le constater, nous avons reçu des réponses médiocres dans les deux cas. Dans les sections suivantes, nous allons explorer les moyens d'améliorer les performances de ce système RAG !
Nous pouvons commencer par personnaliser la taille et le chevauchement des morceaux. Comme nous l'avons dit plus haut, les documents sont divisés en morceaux avec un chevauchement spécifique. Par défaut, LlamaIndex utilise 1024 comme taille de chunk par défaut et 20 comme chevauchement de chunk par défaut. En plus de ces hyperparamètres, le système récupère par défaut les deux premiers morceaux.
Par exemple, nous pouvons fixer la taille des morceaux à 512, le chevauchement des morceaux à 50 et augmenter le nombre de morceaux les plus récupérés :
# modify default values of chunk size and chunk overlap
service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 512, chunk_overlap=50, embed_model=embed_model)
# build index
index = VectorStoreIndex.from_documents(
documents, service_context=service_context_gpt3
)
# returns the engine for the index
query_engine = index.as_query_engine(similarity_top_k=4)Question 1 : "Quelle est l'intrigue du film qui a permis à Emma Stone de remporter son premier Oscar ?
# generate the response
response = query_engine.query("What is the plot of the film that led Emma Stone to win her first Academy Award?")
print(response)Sortie :
The film that made Emma Stone win her first Academy Award is a romantic musical called La La Land.Par rapport à la réponse précédente, elle est légèrement meilleure. Il a réussi à reconnaître La La Land comme le film qui a permis à Emma Stone de remporter son premier Oscar, mais il n'a pas été en mesure de décrire l'intrigue du film.
Question 2 : "Comparez les familles d'Emma Stone et de Ryan Gosling.
# generate the response
response = query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Sortie :
Emma Stone has expressed her close relationship with her family and mentioned being blessed with great family and people around her. She has also shared about her mother's battle with breast cancer and their celebration by getting matching tattoos. On the other hand, there is no specific information provided about Ryan Gosling's family or his personal relationships in the context.Là encore, le résultat du pipeline RAG s'est amélioré, mais il ne contient toujours pas d'informations sur la famille de Ryan Gosling.
Au fur et à mesure que la taille et la complexité de l'ensemble des données augmentent, il devient crucial de sélectionner les informations pertinentes afin de fournir des réponses personnalisées à des requêtes complexes. À cette fin, une famille de techniques appelée Re-Ranking vous permet de comprendre quels morceaux sont importants dans le texte. Ils réorganisent et filtrent les documents, en classant d'abord les plus pertinents.
Il existe deux approches principales pour le repositionnement :
Avant d'appliquer ces approches de reclassement, évaluons ce que le système RAG de base renvoie comme les trois premiers blocs pour notre deuxième requête :
# Retrieve the top three chunks for the second query
retriever = index.as_retriever(similarity_top_k=3)
query = "Compare the families of Emma Stone and Ryan Gosling"
nodes = retriever.retrieve(query)
# Print the chunks
for node in nodes:
print('----------------------------------------------------')
display_source_node(node, source_length = 500)Il s'agit de la sortie avant le reclassement ; chaque morceau a une adresse Node ID avec un score de similarité.
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 0.8415899563985404
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 0.831147173341674
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles. Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 0.8289486590392277
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...Pour récupérer les morceaux pertinents, nous pouvons utiliser un modèle de reclassement open-source de Hugging Face, appelé le modèle bge-ranker-base.
Tout comme l'API OpenAI, l'utilisation de Hugging Face nécessite l'obtention d'un jeton d'accès utilisateur. Vous pouvez créer un jeton d'accès utilisateur à partir de Hugging Face en suivant cette documentation.
HF_TOKEN = userdata.get('HF_TOKEN')
os.environ['HF_TOKEN'] = HF_TOKENAvant d'aller plus loin, nous devons également installer les bibliothèques nécessaires à l'utilisation du modèle de reclassement :
%pip install llama-index-postprocessor-flag-embedding-reranker
!pip install git+https://github.com/FlagOpen/FlagEmbedding.gitEnfin, nous utilisons le modèle bge-ranker-base pour renvoyer les morceaux les plus pertinents.
# Import packages
from llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingReranker
from llama_index.core.schema import QueryBundle
# Re-Rank chunks based on the bge-reranker-base-model
reranker = FlagEmbeddingReranker(
top_n = 3,
model = "BAAI/bge-reranker-base",
)
# Return the updated chunks
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)Voici le résultat après le Re-Ranking :
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 3.0143558979034424
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 2.2117154598236084
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 1.6185210943222046
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles.Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...La sortie montre clairement que le nœud avec l'ID 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f passe de la deuxième à la troisième position. En outre, il convient de noter que les scores de similarité sont plus variables.
Maintenant que nous avons utilisé le Re-Ranking, évaluons la réponse du RAG à la requête originale :
# Initialize the query engine with Re-Ranking
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors=[reranker]
)
# Print the response from the model
response = query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Il s'agit de la réponse fournie après l'application du modèle de reclassement :
Both Emma Stone and Ryan Gosling have close relationships with their families. Stone has expressed her gratitude for having a great family and people around her who keep her grounded. Gosling, on the other hand, has drawn from his own experiences as an aspiring artist, indicating a connection to his personal background.Il y a une amélioration significative par rapport aux réponses précédentes, mais elle est encore incomplète. Évaluons comment une approche de reclassement basée sur le LLM peut contribuer à améliorer la performance du RAG.
Cette fois, nous pouvons compter sur un LLM comme Re-Ranker. Nous utilisons ici le module RankGPT, qui exploite les capacités du modèle GPT pour classer les documents dans le système RAG. Pour commencer, nous installons les paquets nécessaires :
%pip install llama-index-postprocessor-rankgpt-rerankNous utilisons la fonction RankGPTRerank pour reclasser les morceaux à l'aide du modèle gpt-3.5-turbo-0125.
# Import packages
from llama_index.postprocessor.rankgpt_rerank import RankGPTRerank
# Re-Rank the top 3 chunks based on the gpt-3.5-turbo-0125 model
reranker = RankGPTRerank(
top_n = 3,
llm = OpenAI(model="gpt-3.5-turbo-0125"),
)
# Display the top 3 chunks based on RankGPT
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)En utilisant RankGPT, nous obtenons les morceaux suivants :
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 1.6185210943222046
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles.Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...
----------------------------------------------------
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 3.0143558979034424
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 2.2117154598236084
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...Comme RankGPT ne trie pas les passages en fonction du score de similarité, les scores présentés dans le résultat ne sont pas mis à jour. Le résultat montre que le premier nœud considéré comme le plus pertinent mentionne à la fois Emma Stone et Ryan Gosling, tandis que les autres nœuds contiennent plus de détails sur la vie d'Emma Stone.
Maintenant, si nous imprimons la réponse du modèle avec cette méthodologie de reclassement, nous obtenons le résultat suivant :
Both Emma Stone and Ryan Gosling have close relationships with their families. Stone has expressed gratitude for having a great family and supportive people around her, while Gosling has drawn from his own experiences as an aspiring artist, indicating a connection to his family as well. Stone's family has played a significant role in her life, supporting her career pursuits and celebrating important milestones with her. Similarly, Gosling's experiences as an actor have likely been influenced by his family dynamics and relationships.La réponse est plus longue et contient plus de détails que la technique de Re-Ranking précédente.
La transformation des requêtes, également appelée réécriture des requêtes, est une approche qui convertit une requête en une autre requête plutôt que d'utiliser la requête brute pour extraire les k premiers morceaux. Nous allons explorer les techniques suivantes :
HyDE est l'abréviation de Hypothetical Document Embeddings. Elle se déroule en deux étapes. Tout d'abord, il crée une réponse hypothétique à une requête de l'utilisateur. Une fois la réponse ou le document hypothétique déterminé, la réponse et la requête sont transformées en "embeddings". Ensuite, le système récupère les documents les plus proches de l'intégration dans l'espace vectoriel. Voyons-le en action !
# Import packages
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
from llama_index.core.query_engine.transform_query_engine import (
TransformQueryEngine,
)
# build index and query engine for the index
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
query_engine = index.as_query_engine(similarity_top_k=4)
# HyDE setup
hyde = HyDEQueryTransform(include_original=True)
# Transform the query engine using HyDE
hyde_query_engine = TransformQueryEngine(query_engine, hyde)
# Print the response from the model
response = hyde_query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Voici le résultat :
Both Emma Stone and Ryan Gosling come from diverse family backgrounds. Ryan Gosling's parents were of part French Canadian descent, along with some German, English, Scottish, and Irish. He grew up in a family that practiced the Church of Jesus Christ of Latter-day Saints. On the other hand, Emma Stone was born and raised in Scottsdale, Arizona, without specific details provided about her family's ethnic background or religious affiliation.Par rapport aux méthodes de reclassement, nous observons une amélioration partielle. Auparavant, les résultats étaient davantage liés à la relation des acteurs avec leur famille. Aujourd'hui, ils se concentrent davantage sur les origines.
L'approche de transformation des requêtes en plusieurs étapes divise la requête de l'utilisateur en sous-questions séquentielles. Cette méthode peut s'avérer utile lorsque vous travaillez sur des questions complexes.
Comme nous l'avons remarqué, les LLM ont tendance à éprouver des difficultés lorsqu'il s'agit de comparer deux faits, même s'ils peuvent répondre correctement lorsque la question ne porte que sur un sujet spécifique. Ici, nous pouvons voir des transformations de requêtes en plusieurs étapes en action.
# Multi-step query setup
step_decompose_transform_gpt3 = StepDecomposeQueryTransform(gpt3, verbose=True)
index_summary = "Breaks down the initial query"
# Return query engine for the index
multi_step_query_engine = MultiStepQueryEngine(
query_engine=query_engine,
query_transform=step_decompose_transform_gpt3,
index_summary=index_summary
)
# print the response from the model
response = multi_step_query_engine.query("Compare the families of Emma Stone and Ryan Gosling")Nous pouvons voir les questions intermédiaires qui nous permettent d'atteindre le résultat final :
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is the family background of Emma Stone and Ryan Gosling?
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is the specific family background of Emma Stone?
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is Emma Stone's relationship with her family like?Il s'agit de la réponse suivante à la demande de l'utilisateur :
Both Ryan Gosling and Emma Stone have strong family connections, with Emma Stone emphasizing the importance of her family in keeping her grounded. Ryan Gosling's family background includes a mix of French Canadian, German, English, Scottish, and Irish heritage.Dans ce cas, l'utilisation d'une transformation de requête en plusieurs étapes pour comparer les familles d'Emma Stone et de Ryan Gosling s'est avérée utile.
Dans cet article, vous avez appris plusieurs techniques pour améliorer la performance des RAG. Qu'il s'agisse de regroupement, de reclassement ou de transformation des requêtes, la meilleure approche dépend souvent du cas d'utilisation et du résultat souhaité pour une requête donnée.
Si vous souhaitez approfondir la notion de RAG, nous vous recommandons de regarder nos codéveloppements sur la Génération Augmentée par Récupération avec LlamaIndex et la Génération Augmentée par Récupération avec GPT et Milvus. Ces vidéos montrent comment combiner LLM avec des bases de données vectorielles en utilisant la génération de recherche augmentée dans différents cas d'utilisation.
Poursuivez votre voyage dans l'IA dès aujourd'hui !
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach