
Curso
Conceitos de Grandes Modelos de Linguagem (LLMs)
2 h
99.8K
Comece a usar a API OpenAI e muito mais!
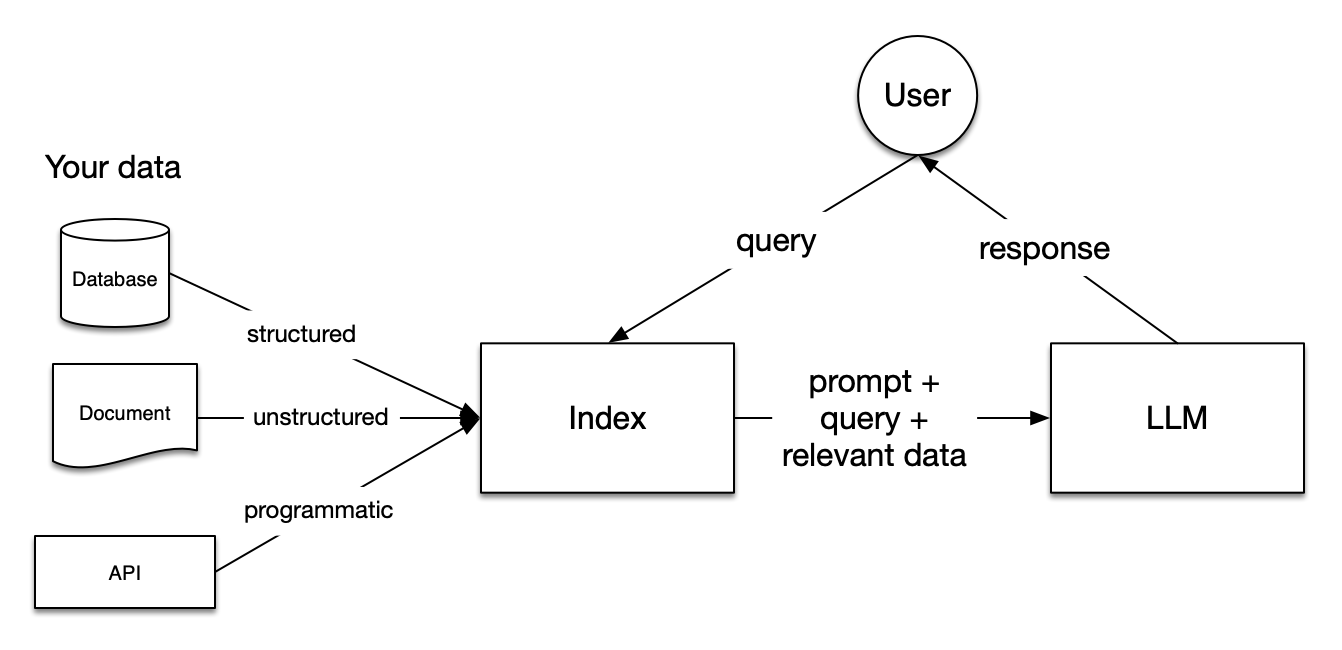
Imagem da documentação do LlamaIndex
Os pipelines do Retrieval Augmented Generation (RAG) incluem três etapas: Indexação, recuperação e geração.
A indexação é fundamental para que você obtenha respostas precisas e contextualizadas com LLMs. Primeiro, ele começa extraindo e limpando dados com diferentes formatos de arquivo, como documentos do Word, arquivos PDF ou arquivos HTML. Depois que os dados são limpos, eles são convertidos em texto simples padronizado. Para evitar limitações de contexto nos LLMs, o texto é dividido em partes menores. Esse processo é chamado de Chunking. Depois, cada bloco é transformado em um vetor numérico ou incorporação usando um modelo de incorporação. Por fim, um índice é criado para armazenar os blocos e suas correspondentes incorporações como pares de valores-chave.
Durante o estágio de recuperação, a consulta do usuário também é convertida em uma representação vetorial usando o mesmo modelo de incorporação. Em seguida, são calculadas as pontuações de similaridade entre o vetor de consulta e os blocos vetorizados. O sistema recupera os K blocos principais com a maior semelhança com a consulta do usuário.
A consulta do usuário e os blocos recuperados são alimentados em um modelo de prompt. O prompt aumentado obtido nas etapas anteriores é finalmente fornecido como entrada para o LLM.
Ao criar sistemas RAG, há desafios significativos que você pode encontrar em todas as três etapas explicadas anteriormente, como os seguintes:
A seguir, exploraremos estratégias para contornar essas limitações. Discutiremos três estratégias amplas: Transformações defragmentação, reclassificação e consulta. Além disso, mostraremos como essas estratégias podem ajudar a melhorar o desempenho do RAG, criando um sistema RAG que responde a perguntas sobre verbetes da Wikipédia usando o Llamaindex e a API OpenAI. Vamos mergulhar de cabeça!
Antes de explorar os truques para aprimorar o desempenho de um sistema RAG, precisamos estabelecer um desempenho de linha de base, criando um pipeline RAG simples. Vamos começar instalando os pacotes llama-index e openai.
!pip install llama-index
!pip install openaiO Llamaindex é uma estrutura de dados para aplicativos baseados em LLMs (Large Language Models). Ele permite a ingestão de diferentes tipos de fontes de dados externas, a criação de sistemas RAG (Retrieval Augmentation Generation) e a abstração de integrações com outros LLMs em poucas linhas de código. Além disso, ele fornece várias técnicas para gerar resultados mais precisos com LLMs.
Por padrão, ele usa o modelo gpt-3.5-turbo da OpenAI para geração de texto e o modelo text-embedding-ada-002 para recuperação e incorporação. Para usar esses modelos, você precisa criar uma conta gratuita na plataforma OpenAI e obter uma chave de API da OpenAI. Para obter a chave, visite a documentação da API da OpenAI.
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"Agora que nossos pacotes estão instalados, criaremos um sistema RAG que responde a perguntas com base nas páginas da Wikipedia de Emma Stone, Ryan Gosling e La La Land. Primeiro, precisamos instalar a biblioteca wikipedia para extrair as páginas da Wikipédia:
!pip install wikipediaEm seguida, você pode baixar facilmente os dados da Wikipedia:
# Import packages
from llama_index.core import (VectorStoreIndex,ServiceContext, download_loader)
# Download the documents from Wikipedia and load them
WikipediaReader = download_loader("WikipediaReader")
loader = WikipediaReader()
pages = ['Emma_Stone', 'La_La_Land', 'Ryan_Gosling']
documents = loader.load_data(pages=pages, auto_suggest=False, redirect = False)Depois que os dados são extraídos, podemos dividir os documentos em blocos de 256 caracteres sem sobreposição. Posteriormente, esses blocos são transformados em vetores numéricos usando o modelo de incorporação e indexados em um Vector Store.
# Initialize the gpt3.5 model
gpt3 = OpenAI(temperature=0, model="gpt-3.5-turbo-instruct", api_key=OPENAI_API_KEY)
# Initialize the embedding model
embed_model = OpenAIEmbedding(model= OpenAIEmbeddingModelType.TEXT_EMBED_ADA_002, api_key=OPENAI_API_KEY)
# Transform chunks into numerical vectors using the embedding model
service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 256, chunk_overlap=0, embed_model=embed_model)
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
retriever = index.as_retriever(similarity_top_k=3)Para reduzir o risco de alucinações, usamos o módulo PromptTemplate para garantir que as respostas do LLM sejam baseadas somente no contexto fornecido.
from llama_index.core.prompts import PromptTemplate
# Build a prompt template to only provide answers based on the loaded documents
template = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
"Don't give an answer unless it is supported by the context above.\n"
)
qa_template = PromptTemplate(template)Agora que configuramos nosso sistema RAG, podemos testá-lo com perguntas baseadas em documentos recuperados. Vamos testá-lo!
Consulta 1: "Qual é o enredo do filme que levou Emma Stone a ganhar seu primeiro Oscar?"
Essa primeira consulta é desafiadora porque exige que o modelo examine diferentes informações:
# Create a prompt for the model
question = "What is the plot of the film that led Emma Stone to win her first Academy Award?"
# Retrieve the context from the model
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
# Generate the response
response = gpt3.complete(prompt)
print(str(response))Saída:
The plot of the film that made Emma Stone win her first Academy Award is not explicitly mentioned in the provided context.Consulta 2: "Compare as famílias de Emma Stone e Ryan Gosling"
Essa segunda consulta é ainda mais desafiadora do que a pergunta anterior, pois pede que você selecione os blocos relevantes referentes às famílias dos dois atores.
# Create a prompt for the model
question = "Compare the families of Emma Stone and Ryan Gosling"
# Retrieve the context from the model
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
# Generate the response
response = gpt3.complete(prompt)
print(str(response))Recebemos o seguinte resultado:
Based on the context provided, it is not possible to compare the families of Emma Stone and Ryan Gosling as the information focuses on their professional collaboration and experiences while working on the film "La La Land." There is no mention of their personal family backgrounds or relationships in the context provided.Como você pode ver, recebemos respostas abaixo da média em ambos os casos. Nas seções a seguir, vamos explorar maneiras de melhorar o desempenho desse sistema RAG!
Podemos começar personalizando o tamanho e a sobreposição dos pedaços. Como dissemos acima, os documentos são divididos em blocos com uma sobreposição específica. Por padrão, o LlamaIndex utiliza 1024 como tamanho de bloco padrão e 20 como sobreposição de bloco padrão. Além desses hiperparâmetros, o sistema recupera os dois principais blocos por padrão.
Por exemplo, podemos fixar o tamanho do bloco em 512, a sobreposição de blocos em 50 e aumentar os principais blocos recuperados:
# modify default values of chunk size and chunk overlap
service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 512, chunk_overlap=50, embed_model=embed_model)
# build index
index = VectorStoreIndex.from_documents(
documents, service_context=service_context_gpt3
)
# returns the engine for the index
query_engine = index.as_query_engine(similarity_top_k=4)Consulta 1: "Qual é o enredo do filme que levou Emma Stone a ganhar seu primeiro Oscar?"
# generate the response
response = query_engine.query("What is the plot of the film that led Emma Stone to win her first Academy Award?")
print(response)Saída:
The film that made Emma Stone win her first Academy Award is a romantic musical called La La Land.Em comparação com a resposta anterior, ela é um pouco melhor. Ele reconheceu La La Land como o filme que levou Emma Stone a ganhar seu primeiro Oscar, mas não foi capaz de descrever o enredo do filme.
Consulta 2: "Compare as famílias de Emma Stone e Ryan Gosling"
# generate the response
response = query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Saída:
Emma Stone has expressed her close relationship with her family and mentioned being blessed with great family and people around her. She has also shared about her mother's battle with breast cancer and their celebration by getting matching tattoos. On the other hand, there is no specific information provided about Ryan Gosling's family or his personal relationships in the context.Novamente, o resultado do pipeline RAG melhorou, mas ainda não capta informações sobre a família de Ryan Gosling.
À medida que o conjunto de dados aumenta em tamanho e complexidade, a seleção de informações relevantes para retornar respostas personalizadas a consultas complexas torna-se crucial. Para esse fim, uma família de técnicas chamada Re-Ranking permite que você entenda quais partes são importantes no texto. Eles reordenam e filtram os documentos, classificando os mais relevantes primeiro.
Há duas abordagens principais para a reclassificação:
Antes de aplicar essas abordagens de reclassificação, vamos avaliar o que o sistema RAG de linha de base retorna como os três principais blocos para nossa segunda consulta:
# Retrieve the top three chunks for the second query
retriever = index.as_retriever(similarity_top_k=3)
query = "Compare the families of Emma Stone and Ryan Gosling"
nodes = retriever.retrieve(query)
# Print the chunks
for node in nodes:
print('----------------------------------------------------')
display_source_node(node, source_length = 500)Este é o resultado antes da reclassificação; cada bloco tem um Node ID com uma pontuação de similaridade.
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 0.8415899563985404
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 0.831147173341674
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles. Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 0.8289486590392277
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...Para recuperar os blocos relevantes, podemos usar um modelo de classificação de novo código aberto da Hugging Face, chamado de modelo bge-ranker-base.
Assim como a API da OpenAI, o uso do Hugging Face exige que você obtenha um token de acesso de usuário. Você pode criar um token de acesso de usuário a partir do Hugging Face seguindo esta documentação.
HF_TOKEN = userdata.get('HF_TOKEN')
os.environ['HF_TOKEN'] = HF_TOKENAntes de prosseguir, também precisamos instalar as bibliotecas necessárias para usar o modelo Re-Ranking:
%pip install llama-index-postprocessor-flag-embedding-reranker
!pip install git+https://github.com/FlagOpen/FlagEmbedding.gitPor fim, usamos o modelo bge-ranker-base para retornar os blocos mais relevantes.
# Import packages
from llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingReranker
from llama_index.core.schema import QueryBundle
# Re-Rank chunks based on the bge-reranker-base-model
reranker = FlagEmbeddingReranker(
top_n = 3,
model = "BAAI/bge-reranker-base",
)
# Return the updated chunks
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)Este é o resultado após o reenquadramento:
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 3.0143558979034424
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 2.2117154598236084
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 1.6185210943222046
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles.Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...Na saída, fica claro que o nó com ID 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f muda da segunda para a terceira posição. Além disso, vale a pena observar que há mais variabilidade nas pontuações de similaridade.
Agora que já usamos o Re-Ranking, vamos avaliar como é a resposta do RAG à consulta original:
# Initialize the query engine with Re-Ranking
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors=[reranker]
)
# Print the response from the model
response = query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Essa é a resposta fornecida após a aplicação do modelo de reclassificação:
Both Emma Stone and Ryan Gosling have close relationships with their families. Stone has expressed her gratitude for having a great family and people around her who keep her grounded. Gosling, on the other hand, has drawn from his own experiences as an aspiring artist, indicating a connection to his personal background.Há uma melhora significativa em comparação com as respostas anteriores, mas ainda está incompleta. Vamos avaliar como uma abordagem de reranking baseada em LLM pode ajudar a melhorar o desempenho do RAG.
Desta vez, podemos contar com um LLM como um Re-Ranker. Aqui, usamos o módulo RankGPT, que aproveita os recursos do modelo GPT para classificar documentos no sistema RAG. Para começar, instalamos os pacotes necessários:
%pip install llama-index-postprocessor-rankgpt-rerankUsamos a função RankGPTRerank para classificar novamente os blocos usando o modelo gpt-3.5-turbo-0125.
# Import packages
from llama_index.postprocessor.rankgpt_rerank import RankGPTRerank
# Re-Rank the top 3 chunks based on the gpt-3.5-turbo-0125 model
reranker = RankGPTRerank(
top_n = 3,
llm = OpenAI(model="gpt-3.5-turbo-0125"),
)
# Display the top 3 chunks based on RankGPT
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)Usando RankGPT, obtemos os seguintes blocos:
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 1.6185210943222046
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles.Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...
----------------------------------------------------
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 3.0143558979034424
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 2.2117154598236084
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...Como o RankGPT não classifica as passagens com base na pontuação de similaridade, as pontuações apresentadas na saída não são atualizadas. No resultado, podemos observar que o primeiro nó considerado mais relevante menciona Emma Stone e Ryan Gosling, enquanto os demais nós contêm mais detalhes sobre a vida de Emma Stone.
Agora, se imprimirmos a resposta do modelo com essa metodologia de reclassificação, obteremos o seguinte resultado:
Both Emma Stone and Ryan Gosling have close relationships with their families. Stone has expressed gratitude for having a great family and supportive people around her, while Gosling has drawn from his own experiences as an aspiring artist, indicating a connection to his family as well. Stone's family has played a significant role in her life, supporting her career pursuits and celebrating important milestones with her. Similarly, Gosling's experiences as an actor have likely been influenced by his family dynamics and relationships.A resposta é mais longa e contém mais detalhes do que a técnica anterior de reranking.
A transformação de consultas, também chamada de reescrita de consultas, é uma abordagem que converte uma consulta em outra consulta, em vez de usar a consulta bruta para recuperar os principais blocos. Vamos explorar as seguintes técnicas:
HyDE significa Hypothetical Document Embeddings. Ele consiste em duas etapas. Primeiro, ele cria uma resposta hipotética para uma consulta do usuário. Depois que a resposta/documento hipotético é determinado, a resposta e a consulta são transformadas em embeddings. Em seguida, o sistema recupera os documentos mais próximos das incorporações no espaço vetorial. Vamos ver isso em ação!
# Import packages
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
from llama_index.core.query_engine.transform_query_engine import (
TransformQueryEngine,
)
# build index and query engine for the index
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
query_engine = index.as_query_engine(similarity_top_k=4)
# HyDE setup
hyde = HyDEQueryTransform(include_original=True)
# Transform the query engine using HyDE
hyde_query_engine = TransformQueryEngine(query_engine, hyde)
# Print the response from the model
response = hyde_query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Este é o resultado:
Both Emma Stone and Ryan Gosling come from diverse family backgrounds. Ryan Gosling's parents were of part French Canadian descent, along with some German, English, Scottish, and Irish. He grew up in a family that practiced the Church of Jesus Christ of Latter-day Saints. On the other hand, Emma Stone was born and raised in Scottsdale, Arizona, without specific details provided about her family's ethnic background or religious affiliation.Em comparação com os métodos de reranking, observamos uma melhoria parcial. Anteriormente, os resultados estavam mais relacionados ao relacionamento dos atores com suas famílias. Agora, eles se concentram mais nas origens.
A abordagem de transformação de consultas em várias etapas divide a consulta do usuário em subquestões sequenciais. Esse método pode ser útil quando você trabalha com perguntas complexas.
Como observamos, os LLMs tendem a ter dificuldades ao comparar dois fatos, mesmo que consigam responder corretamente quando a pergunta se refere apenas a um tópico específico. Aqui, podemos ver as transformações de consulta em várias etapas em ação.
# Multi-step query setup
step_decompose_transform_gpt3 = StepDecomposeQueryTransform(gpt3, verbose=True)
index_summary = "Breaks down the initial query"
# Return query engine for the index
multi_step_query_engine = MultiStepQueryEngine(
query_engine=query_engine,
query_transform=step_decompose_transform_gpt3,
index_summary=index_summary
)
# print the response from the model
response = multi_step_query_engine.query("Compare the families of Emma Stone and Ryan Gosling")Podemos ver as perguntas intermediárias que nos permitem chegar ao resultado final:
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is the family background of Emma Stone and Ryan Gosling?
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is the specific family background of Emma Stone?
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is Emma Stone's relationship with her family like?Esta é a seguinte resposta à consulta do usuário:
Both Ryan Gosling and Emma Stone have strong family connections, with Emma Stone emphasizing the importance of her family in keeping her grounded. Ryan Gosling's family background includes a mix of French Canadian, German, English, Scottish, and Irish heritage.Nesse caso, foi útil usar a transformação de consulta em várias etapas para comparar as famílias de Emma Stone e Ryan Gosling.
Neste artigo, você aprendeu várias técnicas para melhorar o desempenho do RAG. Seja Chunking, Re-Ranking ou Query Transformations, a melhor abordagem geralmente depende do caso de uso e do resultado desejado para uma determinada consulta.
Se você quiser se aprofundar no RAG, recomendamos que assista aos nossos code-alongs sobre Retrieval Augmented Generation com LlamaIndex e Retrieval Augmented Generation com GPT e Milvus. Esses vídeos mostram como combinar LLM com bancos de dados vetoriais usando a geração aumentada de recuperação em diferentes casos de uso.
Continue sua jornada de IA hoje mesmo!
Curso
Curso
Curso
blog
Nahla Davies
15 min
blog
Javier Canales Luna
12 min
blog
Austin Chia
Tutorial
Ryan Ong


