
Kurs
Konzepte großer Sprachmodelle (LLMs)
2 Std.
99.8K
Benutze die OpenAI API und mehr!
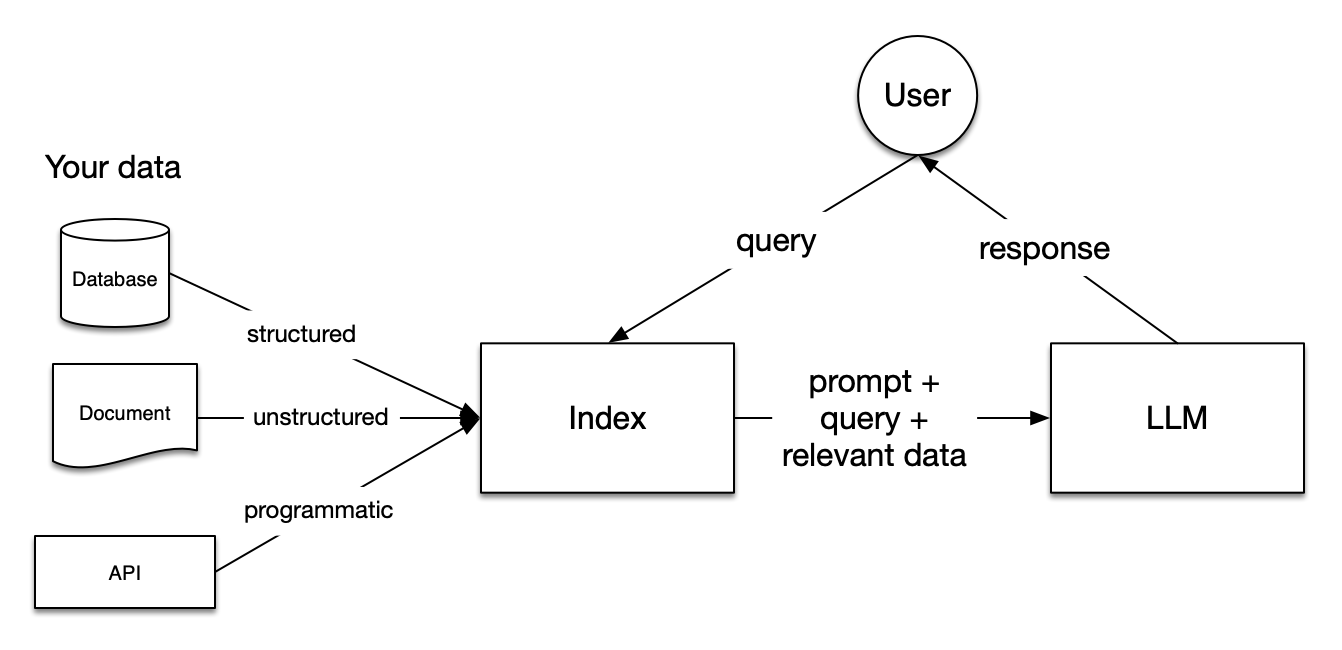
Bild aus der LlamaIndex Dokumentation
Retrieval Augmented Generation (RAG) Pipelines umfassen drei Schritte: Indizierung, Abruf und Generierung.
Die Indizierung ist grundlegend, um genaue und kontextbezogene Antworten mit LLMs zu erhalten. Zunächst werden Daten in verschiedenen Dateiformaten extrahiert und bereinigt, z. B. Word-Dokumente, PDF-Dateien oder HTML-Dateien. Sobald die Daten bereinigt sind, werden sie in standardisierten Klartext umgewandelt. Um Kontextbeschränkungen innerhalb von LLMs zu vermeiden, wird der Text in kleinere Abschnitte aufgeteilt. Dieser Prozess wird Chunking genannt. Danach wird jeder Chunk mit Hilfe eines Einbettungsmodells in einen numerischen Vektor oder eine Einbettung umgewandelt. Schließlich wird ein Index erstellt, in dem die Chunks und die zugehörigen Einbettungen als Schlüssel-Wert-Paare gespeichert werden.
In der Abrufphase wird die Benutzeranfrage ebenfalls in eine Vektordarstellung umgewandelt, wobei das gleiche Einbettungsmodell verwendet wird. Dann werden die Ähnlichkeitswerte zwischen dem Abfragevektor und den vektorisierten Chunks berechnet. Das System findet die K Chunks mit der größten Ähnlichkeit zur Nutzeranfrage.
Die Benutzeranfrage und die abgerufenen Chunks werden in eine Prompt-Vorlage eingegeben. Der erweiterte Prompt aus den vorherigen Schritten wird schließlich als Eingabe für das LLM verwendet.
Beim Aufbau von RAG-Systemen kannst du in allen drei zuvor erläuterten Schritten auf erhebliche Herausforderungen stoßen, wie z.B. die folgenden:
Im Folgenden erkunden wir Strategien, um diese Einschränkungen zu umgehen. Wir werden drei große Strategien besprechen: Chunking, Re-Ranking und Abfrageumwandlungen. Außerdem werden wir zeigen, wie diese Strategien die Leistung von RAG verbessern können, indem wir ein RAG-System bauen, das Fragen zu Wikipedia-Einträgen mit Hilfe von Llamaindex und der OpenAI API beantwortet. Lass uns eintauchen!
Bevor wir die Tricks erforschen, mit denen wir die Leistung eines RAG-Systems verbessern können, müssen wir eine Basisleistung ermitteln, indem wir eine einfache RAG-Pipeline erstellen. Beginnen wir mit der Installation der Pakete llama-index und openai.
!pip install llama-index
!pip install openaiLlamaindex ist ein Daten-Framework für Anwendungen, die auf Large Language Models (LLMs) basieren. Es ermöglicht die Aufnahme verschiedener Arten von externen Datenquellen, den Aufbau von Retrieval Augmentation Generation (RAG) Systemen und die Abstraktion von Integrationen mit anderen LLMs in ein paar Zeilen Code. Außerdem bietet es verschiedene Techniken, um mit LLMs genauere Ergebnisse zu erzielen.
Standardmäßig verwendet es das OpenAI gpt-3.5-turbo Modell für die Texterstellung und das text-embedding-ada-002 Modell für das Retrieval und die Einbettung. Um diese Modelle zu nutzen, musst du ein kostenloses Konto auf der OpenAI-Plattform erstellen und einen OpenAI-API-Schlüssel erhalten. Um den Schlüssel zu erhalten, besuche bitte die OpenAI API-Dokumentation.
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"Jetzt, wo unsere Pakete installiert sind, werden wir ein RAG-System bauen, das Fragen auf der Grundlage der Wikipedia-Seiten von Emma Stone, Ryan Gosling und La La Land beantwortet. Zuerst müssen wir die Bibliothek wikipedia installieren, um die Wikipedia-Seiten zu extrahieren:
!pip install wikipediaDann können wir die Daten ganz einfach von Wikipedia herunterladen:
# Import packages
from llama_index.core import (VectorStoreIndex,ServiceContext, download_loader)
# Download the documents from Wikipedia and load them
WikipediaReader = download_loader("WikipediaReader")
loader = WikipediaReader()
pages = ['Emma_Stone', 'La_La_Land', 'Ryan_Gosling']
documents = loader.load_data(pages=pages, auto_suggest=False, redirect = False)Sobald die Daten extrahiert sind, können wir die Dokumente in Abschnitte von 256 Zeichen ohne Überschneidungen aufteilen. Später werden diese Chunks mithilfe des Einbettungsmodells in numerische Vektoren umgewandelt und in einem Vektorspeicher indiziert.
# Initialize the gpt3.5 model
gpt3 = OpenAI(temperature=0, model="gpt-3.5-turbo-instruct", api_key=OPENAI_API_KEY)
# Initialize the embedding model
embed_model = OpenAIEmbedding(model= OpenAIEmbeddingModelType.TEXT_EMBED_ADA_002, api_key=OPENAI_API_KEY)
# Transform chunks into numerical vectors using the embedding model
service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 256, chunk_overlap=0, embed_model=embed_model)
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
retriever = index.as_retriever(similarity_top_k=3)Um das Risiko von Halluzinationen zu verringern, verwenden wir das Modul PromptTemplate, um sicherzustellen, dass die Antworten des LLM nur auf dem angegebenen Kontext basieren.
from llama_index.core.prompts import PromptTemplate
# Build a prompt template to only provide answers based on the loaded documents
template = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
"Don't give an answer unless it is supported by the context above.\n"
)
qa_template = PromptTemplate(template)Jetzt, wo wir unser RAG-System eingerichtet haben, können wir es mit Fragen testen, die auf abgerufenen Dokumenten basieren. Lass uns das auf die Probe stellen!
Abfrage 1: "Was ist die Handlung des Films, mit dem Emma Stone ihren ersten Oscar gewonnen hat?"
Diese erste Abfrage ist eine Herausforderung, denn sie erfordert, dass das Modell verschiedene Informationen prüft:
# Create a prompt for the model
question = "What is the plot of the film that led Emma Stone to win her first Academy Award?"
# Retrieve the context from the model
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
# Generate the response
response = gpt3.complete(prompt)
print(str(response))Output:
The plot of the film that made Emma Stone win her first Academy Award is not explicitly mentioned in the provided context.Abfrage 2: "Vergleiche die Familien von Emma Stone und Ryan Gosling"
Diese zweite Abfrage ist sogar noch anspruchsvoller als die vorherige, da sie die relevanten Chunks zu den Familien der beiden Akteure auswählen soll.
# Create a prompt for the model
question = "Compare the families of Emma Stone and Ryan Gosling"
# Retrieve the context from the model
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
# Generate the response
response = gpt3.complete(prompt)
print(str(response))Wir erhalten die folgende Ausgabe:
Based on the context provided, it is not possible to compare the families of Emma Stone and Ryan Gosling as the information focuses on their professional collaboration and experiences while working on the film "La La Land." There is no mention of their personal family backgrounds or relationships in the context provided.Wie du siehst, haben wir in beiden Fällen unzureichende Antworten erhalten. In den folgenden Abschnitten wollen wir herausfinden, wie wir die Leistung dieses RAG-Systems verbessern können!
Wir können damit beginnen, die Größe der Chunks und die Überlappung der Chunks anzupassen. Wie bereits erwähnt, werden die Dokumente in Chunks mit einer bestimmten Überlappung aufgeteilt. Standardmäßig verwendet LlamaIndex 1024 als Standardchunkgröße und 20 als Standardchunküberlappung. Zusätzlich zu diesen Hyperparametern ruft das System standardmäßig die obersten 2 Chunks ab.
Wir können zum Beispiel die Chunkgröße auf 512 und die Überlappung der Chunks auf 50 festlegen und die Anzahl der abgerufenen Chucks erhöhen:
# modify default values of chunk size and chunk overlap
service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 512, chunk_overlap=50, embed_model=embed_model)
# build index
index = VectorStoreIndex.from_documents(
documents, service_context=service_context_gpt3
)
# returns the engine for the index
query_engine = index.as_query_engine(similarity_top_k=4)Abfrage 1: "Was ist die Handlung des Films, mit dem Emma Stone ihren ersten Oscar gewonnen hat?"
# generate the response
response = query_engine.query("What is the plot of the film that led Emma Stone to win her first Academy Award?")
print(response)Output:
The film that made Emma Stone win her first Academy Award is a romantic musical called La La Land.Verglichen mit der vorherigen Antwort ist sie etwas besser. Sie erkannte La La Land erfolgreich als den Film, der Emma Stone ihren ersten Oscar einbrachte, aber sie war nicht in der Lage, die Handlung des Films zu beschreiben.
Abfrage 2: "Vergleiche die Familien von Emma Stone und Ryan Gosling"
# generate the response
response = query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Output:
Emma Stone has expressed her close relationship with her family and mentioned being blessed with great family and people around her. She has also shared about her mother's battle with breast cancer and their celebration by getting matching tattoos. On the other hand, there is no specific information provided about Ryan Gosling's family or his personal relationships in the context.Auch hier hat sich die Leistung der RAG-Pipeline verbessert, aber sie erfasst immer noch keine Informationen über Ryan Goslings Familie.
Je größer und komplexer der Datensatz wird, desto wichtiger wird die Auswahl relevanter Informationen, um maßgeschneiderte Antworten auf komplexe Abfragen zu erhalten. Zu diesem Zweck gibt es eine Reihe von Techniken namens Re-Ranking, mit denen du herausfinden kannst, welche Abschnitte im Text wichtig sind. Sie ordnen und filtern die Dokumente neu und ordnen die relevantesten Dokumente zuerst ein.
Es gibt zwei Hauptansätze für das Re-Ranking:
Bevor wir diese Re-Ranking-Ansätze anwenden, schauen wir uns an, was das RAG-Basissystem als die drei besten Chunks für unsere zweite Anfrage liefert:
# Retrieve the top three chunks for the second query
retriever = index.as_retriever(similarity_top_k=3)
query = "Compare the families of Emma Stone and Ryan Gosling"
nodes = retriever.retrieve(query)
# Print the chunks
for node in nodes:
print('----------------------------------------------------')
display_source_node(node, source_length = 500)Dies ist die Ausgabe vor dem Re-Ranking; jeder Chunk hat eine Node ID mit einer Ähnlichkeitsbewertung.
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 0.8415899563985404
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 0.831147173341674
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles. Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 0.8289486590392277
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...Um die relevanten Chunks zu finden, können wir ein quelloffenes Re-Ranking-Modell von Hugging Face verwenden, das sogenannte bge-ranker-base-Modell.
Genau wie bei der OpenAI API brauchst du für die Nutzung von Hugging Face ein Benutzerzugriffstoken. Du kannst ein Benutzerzugriffstoken von Hugging Face erstellen, indem du diese Dokumentation befolgst.
HF_TOKEN = userdata.get('HF_TOKEN')
os.environ['HF_TOKEN'] = HF_TOKENBevor wir weitermachen, müssen wir auch die notwendigen Bibliotheken für die Verwendung des Re-Ranking-Modells installieren:
%pip install llama-index-postprocessor-flag-embedding-reranker
!pip install git+https://github.com/FlagOpen/FlagEmbedding.gitSchließlich verwenden wir das bge-ranker-base Modell, um die relevantesten Chunks zurückzugeben.
# Import packages
from llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingReranker
from llama_index.core.schema import QueryBundle
# Re-Rank chunks based on the bge-reranker-base-model
reranker = FlagEmbeddingReranker(
top_n = 3,
model = "BAAI/bge-reranker-base",
)
# Return the updated chunks
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)Dies ist das Ergebnis nach dem Re-Ranking:
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 3.0143558979034424
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 2.2117154598236084
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 1.6185210943222046
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles.Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...Aus der Ausgabe ist ersichtlich, dass der Knoten mit der ID 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f von der zweiten in die dritte Position wechselt. Außerdem fällt auf, dass es innerhalb der Ähnlichkeitswerte eine größere Variabilität gibt.
Jetzt, wo wir das Re-Ranking angewendet haben, wollen wir auswerten, wie die RAG-Antwort auf die ursprüngliche Anfrage aussieht:
# Initialize the query engine with Re-Ranking
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors=[reranker]
)
# Print the response from the model
response = query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Das ist die Antwort, die nach Anwendung des Re-Ranking-Modells gegeben wird:
Both Emma Stone and Ryan Gosling have close relationships with their families. Stone has expressed her gratitude for having a great family and people around her who keep her grounded. Gosling, on the other hand, has drawn from his own experiences as an aspiring artist, indicating a connection to his personal background.Das ist eine deutliche Verbesserung im Vergleich zu früheren Antworten, aber sie ist immer noch unvollständig. Wir wollen nun untersuchen, wie ein LLM-basierter Re-Ranking-Ansatz die Leistung der RAG verbessern kann.
Dieses Mal können wir uns auf einen LLM als Re-Ranker verlassen. Hier verwenden wir das Modul RankGPT, das die Fähigkeiten des GPT-Modells nutzt, um Dokumente innerhalb des RAG-Systems zu bewerten. Um loszulegen, installieren wir die benötigten Pakete:
%pip install llama-index-postprocessor-rankgpt-rerankWir verwenden die Funktion RankGPTRerank, um die Chunks mit Hilfe des gpt-3.5-turbo-0125 Modells neu zu ranken.
# Import packages
from llama_index.postprocessor.rankgpt_rerank import RankGPTRerank
# Re-Rank the top 3 chunks based on the gpt-3.5-turbo-0125 model
reranker = RankGPTRerank(
top_n = 3,
llm = OpenAI(model="gpt-3.5-turbo-0125"),
)
# Display the top 3 chunks based on RankGPT
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)Durch die Verwendung von RankGPT erhalten wir die folgenden Chunks:
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 1.6185210943222046
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles.Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...
----------------------------------------------------
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 3.0143558979034424
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 2.2117154598236084
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...Da RankGPT die Passagen nicht nach dem Ähnlichkeitsscore sortiert, werden die in der Ausgabe angezeigten Scores nicht aktualisiert. Anhand der Ausgabe können wir feststellen, dass der erste Knoten, der als der relevanteste gilt, sowohl Emma Stone als auch Ryan Gosling erwähnt, während die übrigen Knoten mehr Details über Emma Stones Leben enthalten.
Wenn wir nun die Antwort des Modells mit dieser Re-Ranking-Methode ausdrucken, erhalten wir die folgende Ausgabe:
Both Emma Stone and Ryan Gosling have close relationships with their families. Stone has expressed gratitude for having a great family and supportive people around her, while Gosling has drawn from his own experiences as an aspiring artist, indicating a connection to his family as well. Stone's family has played a significant role in her life, supporting her career pursuits and celebrating important milestones with her. Similarly, Gosling's experiences as an actor have likely been influenced by his family dynamics and relationships.Die Antwort ist länger und enthält mehr Details als die vorherige Re-Ranking-Technik.
Die Abfragetransformation, auch Query Rewriting genannt, ist ein Ansatz, bei dem eine Abfrage in eine andere Abfrage umgewandelt wird, anstatt die rohe Abfrage zu verwenden, um die Top K Chunks zu finden. Wir werden die folgenden Techniken erforschen:
HyDE steht für Hypothetical Document Embeddings. Sie besteht aus zwei Schritten. Zuerst wird eine hypothetische Antwort auf eine Nutzeranfrage erstellt. Sobald die hypothetische Antwort/das hypothetische Dokument bestimmt ist, werden die Antwort und die Anfrage in Einbettungen umgewandelt. Dann sucht das System die Dokumente heraus, die den Einbettungen im Vektorraum am nächsten kommen. Lass es uns in Aktion sehen!
# Import packages
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
from llama_index.core.query_engine.transform_query_engine import (
TransformQueryEngine,
)
# build index and query engine for the index
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
query_engine = index.as_query_engine(similarity_top_k=4)
# HyDE setup
hyde = HyDEQueryTransform(include_original=True)
# Transform the query engine using HyDE
hyde_query_engine = TransformQueryEngine(query_engine, hyde)
# Print the response from the model
response = hyde_query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Das ist die Ausgabe:
Both Emma Stone and Ryan Gosling come from diverse family backgrounds. Ryan Gosling's parents were of part French Canadian descent, along with some German, English, Scottish, and Irish. He grew up in a family that practiced the Church of Jesus Christ of Latter-day Saints. On the other hand, Emma Stone was born and raised in Scottsdale, Arizona, without specific details provided about her family's ethnic background or religious affiliation.Im Vergleich zu den Re-Ranking-Methoden beobachten wir eine teilweise Verbesserung. Zuvor bezogen sich die Ergebnisse eher auf die Beziehung der Akteure zu ihren Familien. Jetzt konzentrieren sie sich mehr auf die Ursprünge.
Der mehrstufige Ansatz zur Umwandlung von Anfragen zerlegt die Anfrage des Nutzers in aufeinanderfolgende Teilfragen. Diese Methode kann bei der Bearbeitung komplexer Fragen hilfreich sein.
Wie wir festgestellt haben, tun sich LLMs oft schwer, wenn sie zwei Fakten vergleichen, auch wenn sie richtig antworten können, wenn die Frage nur ein bestimmtes Thema betrifft. Hier sehen wir mehrstufige Abfrageumwandlungen in Aktion.
# Multi-step query setup
step_decompose_transform_gpt3 = StepDecomposeQueryTransform(gpt3, verbose=True)
index_summary = "Breaks down the initial query"
# Return query engine for the index
multi_step_query_engine = MultiStepQueryEngine(
query_engine=query_engine,
query_transform=step_decompose_transform_gpt3,
index_summary=index_summary
)
# print the response from the model
response = multi_step_query_engine.query("Compare the families of Emma Stone and Ryan Gosling")Wir können die Zwischenfragen sehen, die es uns ermöglichen, das endgültige Ergebnis zu erreichen:
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is the family background of Emma Stone and Ryan Gosling?
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is the specific family background of Emma Stone?
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is Emma Stone's relationship with her family like?Dies ist die folgende Antwort auf die Benutzeranfrage:
Both Ryan Gosling and Emma Stone have strong family connections, with Emma Stone emphasizing the importance of her family in keeping her grounded. Ryan Gosling's family background includes a mix of French Canadian, German, English, Scottish, and Irish heritage.In diesem Fall war die mehrstufige Abfragetransformation hilfreich, um die Familien von Emma Stone und Ryan Gosling zu vergleichen.
In diesem Artikel hast du verschiedene Techniken zur Verbesserung der RAG-Leistung kennengelernt. Ob Chunking, Re-Ranking oder Query Transformations, die beste Vorgehensweise hängt oft vom Anwendungsfall und dem gewünschten Ergebnis für eine bestimmte Abfrage ab.
Wenn du tiefer in RAG einsteigen willst, empfehlen wir dir unsere Code-Alongs zu Retrieval Augmented Generation mit LlamaIndex und Retrieval Augmented Generation mit GPT und Milvus. Diese Videos zeigen, wie man LLM mit Vektordatenbanken kombiniert, indem man die Retrieval Augmented Generation in verschiedenen Anwendungsfällen einsetzt.
Setze deine KI-Reise heute fort!
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
