Si estás leyendo este artículo, probablemente ya hayas oído hablar de los grandes modelos lingüísticos (LLM). ¿Quién no lo ha hecho? Al fin y al cabo, los LLM están detrás de las herramientas superpopulares que alimentan la actual revolución de la IA generativa, como ChatGPT, Google Bard y DALL-E.
Para desplegar su magia, estas herramientas se basan en una potente tecnología que les permite procesar datos y generar contenidos precisos en respuesta a la pregunta formulada por el usuario. Aquí es donde entran en juego los LLM.
Este artículo pretende presentarte los LLM. Después de leer las siguientes secciones, sabremos qué son los LLM, cómo funcionan, los distintos tipos de LLM con ejemplos, así como sus ventajas y limitaciones.
Para los recién llegados al tema, nuestro Curso de Conceptos de Grandes Modelos Lingüísticos (LLMs) es un lugar perfecto para obtener una visión profunda de los LLMs. Sin embargo, si ya estás familiarizado con LLM y quieres ir un paso más allá aprendiendo a construir aplicaciones potentes con LLM, consulta nuestro artículo Cómo construir aplicaciones LLM con LangChain.
¡Empecemos!
¿Qué es un Gran Modelo Lingüístico?
Los LLM son sistemas de IA utilizados para modelar y procesar el lenguaje humano. Se llaman "grandes" porque este tipo de modelos suelen estar formados por cientos de millones o incluso miles de millones de parámetros que definen el comportamiento del modelo, los cuales se entrenan previamente utilizando un corpus masivo de datos de texto.
La tecnología subyacente de los LLM se llama red neuronal transformadora, denominada simplemente transformador. Como explicaremos con más detalle en la siguiente sección, un transformador es una arquitectura neuronal innovadora dentro del campo del aprendizaje profundo.
Presentados por los investigadores de Google en el famoso artículo Attention is All You Need (La atención es todo lo que necesitas ) en 2017, los transformadores son capaces de realizar tareas de lenguaje natural (PLN) con una precisión y velocidad sin precedentes. Con sus capacidades únicas, los transformadores han proporcionado un salto significativo en las capacidades de los LLM. Es justo decir que, sin los transformadores, la actual revolución de la IA generativa no sería posible.
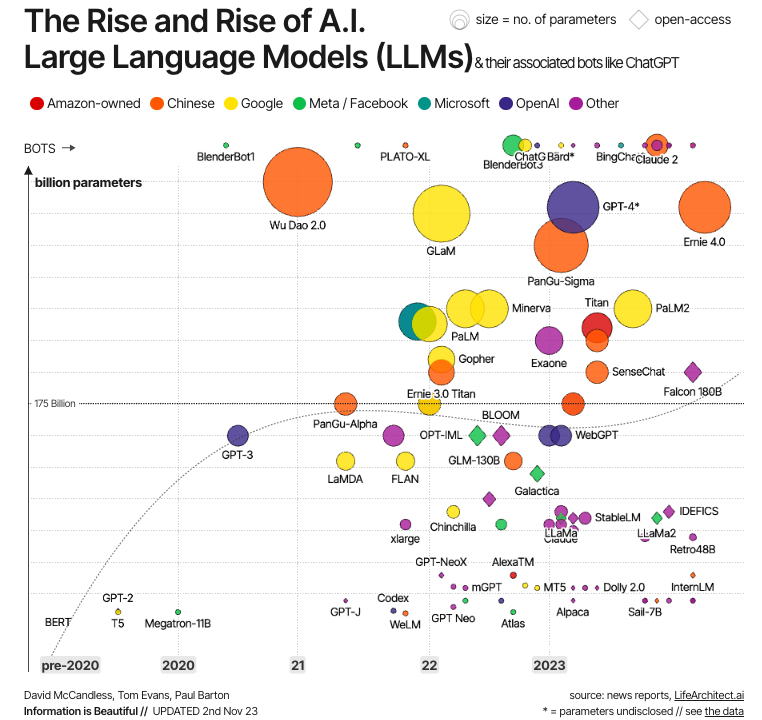
Fuente: La información es bella
Esta evolución se ilustra en el gráfico anterior. Como vemos, los primeros LLM modernos se crearon justo después del desarrollo de los transformadores, siendo los ejemplos más significativos BERT -el primer LLM desarrollado por Google para probar la potencia de los transformadores-, así como GPT-1 y GPT-2, los dos primeros modelos de la serie GPT creados por OpenAI. Pero no es hasta la década de 2020 cuando los LLM se convierten en la corriente principal, cada vez más grandes (en términos de parámetros) y, por tanto, más potentes, con ejemplos bien conocidos como GPT-4 y LLaMa.
¿Cómo funcionan los LLM?
La clave del éxito de los LLM modernos es la arquitectura del transformador. Antes de que los investigadores de Google desarrollaran los transformadores, modelar el lenguaje natural era una tarea muy difícil. A pesar del auge de las redes neuronales sofisticadas -es decir, redes neuronales recurrentes o convolucionales-, los resultados sólo fueron parcialmente satisfactorios.
El principal reto reside en la estrategia que utilizan estas redes neuronales para predecir la palabra que falta en una frase. Antes de los transformadores, las redes neuronales de última generación se basaban en la arquitectura codificador-decodificador, un mecanismo potente pero que consume mucho tiempo y recursos, inadecuado para la computación paralela, lo que limita las posibilidades de escalabilidad.
Los transformadores ofrecen una alternativa a las neuronas tradicionales para manejar datos secuenciales, concretamente texto (aunque los transformadores también se han utilizado con otros tipos de datos, como imágenes y audio, con resultados igualmente satisfactorios).
Componentes de los LLM
Los transformadores se basan en la misma arquitectura codificador-decodificador que las redes neuronales recurrentes y convolucionales. Una arquitectura neuronal de este tipo pretende descubrir relaciones estadísticas entre los tokens de un texto.
Esto se hace mediante una combinación de técnicas de incrustación. Las incrustaciones son las representaciones de tokens, como frases, párrafos o documentos, en un espacio vectorial de alta dimensión, donde cada dimensión corresponde a una característica o atributo aprendido de la lengua.
El proceso de incrustación tiene lugar en el codificador. Debido al enorme tamaño de los LLM, la creación de incrustaciones requiere una amplia formación y recursos considerables. Sin embargo, lo que diferencia a los transformadores de las redes neuronales anteriores es que el proceso de incrustación es altamente paralelizable, lo que permite un procesamiento más eficaz. Esto es posible gracias al mecanismo de atención.
Las redes neuronales recurrentes y convolucionales hacen sus predicciones de palabras basándose exclusivamente en palabras anteriores. En este sentido, pueden considerarse unidireccionales. En cambio, el mecanismo de atención permite a los transformadores predecir palabras bidireccionalmente, es decir, basándose tanto en las palabras anteriores como en las siguientes. El objetivo de la capa de atención, que se incorpora tanto en el codificador como en el descodificador, es captar las relaciones contextuales existentes entre las distintas palabras de la frase de entrada.
Para conocer en detalle cómo funciona la arquitectura codificador-decodificador en los transformadores, te recomendamos encarecidamente que leas nuestra Introducción al uso de transformadores y Cara de abrazo.
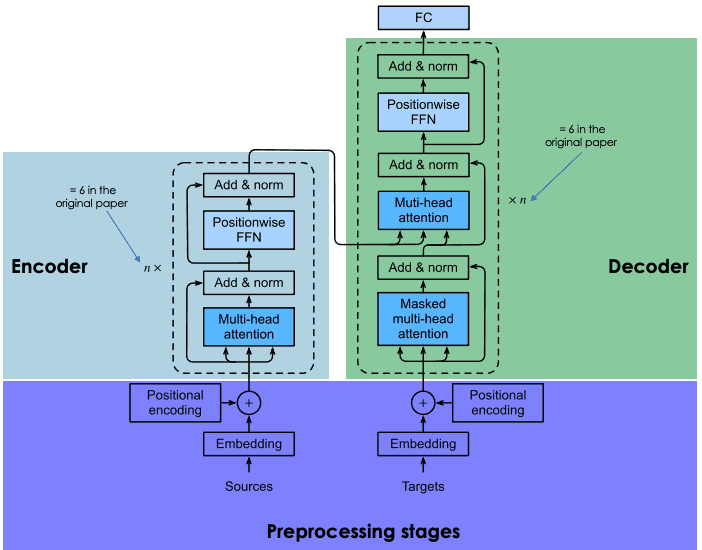
Explicación de la arquitectura de los transformadores
Formación de LLM
El entrenamiento de los transformadores implica dos pasos: el preentrenamiento y el ajuste.
Formación previa
En esta fase, los transformadores se entrenan con grandes cantidades de datos de texto sin procesar. Internet es la principal fuente de datos.
El entrenamiento se realiza mediante técnicas de aprendizaje no supervisado, un tipo innovador de entrenamiento que no requiere la acción humana para etiquetar los datos.
El objetivo del preentrenamiento es aprender los patrones estadísticos de la lengua. La estrategia más moderna para conseguir una mayor precisión de los transformadores es hacer que el modelo sea más grande (esto puede conseguirse aumentando el número de parámetros) y aumentar el tamaño de los datos de entrenamiento. Como resultado, los LLM más avanzados vienen con miles de millones de parámetros (por ejemplo, el PaLM 2 tiene 340.000 millones de parámetros, y se calcula que el GPT-4 tiene alrededor de 1,8 billones de parámetros) y se han entrenado con un corpus de datos gigantesco.
Esta tendencia crea problemas de accesibilidad. Dado el tamaño del modelo y los datos de entrenamiento, el proceso de preentrenamiento suele ser largo y costoso, lo que sólo puede permitirse un grupo reducido de empresas.
Ajuste fino
El preentrenamiento permite a un transformador adquirir una comprensión básica del lenguaje, pero no es suficiente para realizar tareas prácticas específicas con gran precisión.
Para evitar iteraciones largas y costosas en el proceso de entrenamiento, los transformadores aprovechan las técnicas de aprendizaje por transferencia para separar la fase de (pre)entrenamiento de la fase de ajuste. Esto permite a los desarrolladores elegir modelos preentrenados y afinarlos basándose en una base de datos más reducida y específica del dominio. En muchos casos, el proceso de ajuste se lleva a cabo con la ayuda de revisores humanos, utilizando una técnica llamada Aprendizaje por Refuerzo a partir de la Retroalimentación Humana.
El proceso de entrenamiento en dos pasos permite adaptar el LLM a una amplia gama de tareas posteriores. Dicho de otro modo, esta característica convierte a los LLM en el modelo base de un sinfín de aplicaciones construidas sobre ellos.
Multimodalidad de los LLM
Los primeros LLM modernos eran modelos texto a texto (es decir, recibían una entrada de texto y generaban una salida de texto). Sin embargo, en los últimos años, los desarrolladores han creado los llamados LLM multimodales. Estos modelos combinan datos de texto con otros tipos de información, como imágenes, audio y vídeo. La combinación de distintos tipos de datos ha permitido la creación de sofisticados modelos para tareas específicas, como DALL-E. de OpenAI para la generación de imágenes, y AudioCraft de Meta para la generación de música y audio.
¿Para qué se utilizan los LLM?
Impulsados por transformadores, los LLM modernos han alcanzado un rendimiento puntero en múltiples tareas de PNL. Éstas son algunas de las tareas en las que los LLM han proporcionado resultados únicos:
- Generación de texto. Los LLM como ChatGPT son capaces de crear textos largos, complejos y de apariencia humana en cuestión de segundos.
- Traducción. Cuando los LLM están entrenados en varias lenguas, pueden realizar operaciones de traducción de alto nivel. Con la multimodalidad, las posibilidades son infinitas. Por ejemplo, el modelo SeamlessM4T de Meta puede realizar traducciones de voz a texto, de voz a voz, de texto a voz y de texto a texto de hasta 100 idiomas, dependiendo de la tarea.
- Análisis del sentimiento. Con los LLM se pueden realizar todo tipo de análisis de sentimientos, desde predicciones positivas y negativas de críticas de películas u opiniones sobre campañas de marketing.
- IA conversacional. Como tecnología subyacente de los chatbots modernos, los LLM son excelentes para interrogar, responder y mantener conversaciones incluso en tareas complejas.
- Autocompletar. Los LLM pueden utilizarse para tareas de autocompletar, por ejemplo, en correos electrónicos o servicios de mensajería. Por ejemplo, el BERT de Google impulsa la herramienta de autocompletar de Gmail.
Ventajas de los LLM
El LLM tiene un inmenso potencial para las organizaciones, como ilustra la adopción generalizada de ChatGPT, que, sólo unos meses después de su lanzamiento, se convirtió en la aplicación digital de mayor crecimiento de todos los tiempos.
Ya hay un buen número de aplicaciones empresariales de los LLM, y el número de casos de uso no hará sino aumentar a medida que estas herramientas se hagan más omnipresentes en todos los sectores e industrias. A continuación encontrarás una lista de algunas de las ventajas de los LLM:
- Creación de contenidos. Los LLM son potentes herramientas de IA generativa de todo tipo. Con sus capacidades, los LLM son grandes herramientas para generar contenidos (principalmente texto, pero, en combinación con otros modelos, también pueden generar imágenes, vídeos y audio). Dependiendo de los datos utilizados en el proceso de ajuste, los LLM pueden ofrecer contenidos precisos y específicos de cualquier sector que se te ocurra, desde el jurídico y el financiero hasta el sanitario y el de marketing.
- Mayor eficacia en las tareas de PNL. Como se ha explicado en la sección anterior, los LLM ofrecen un rendimiento único en muchas tareas de PNL. Son capaces de comprender el lenguaje humano e interactuar con los seres humanos con una precisión sin precedentes. Sin embargo, es importante tener en cuenta que estas herramientas no son perfectas y aún pueden arrojar resultados inexactos o incluso alucinaciones en general,
- Mayor eficacia. Una de las principales ventajas empresariales de los LLM es que son perfectos para realizar tareas monótonas que requieren mucho tiempo en cuestión de segundos. Aunque hay grandes perspectivas para las empresas que puedan beneficiarse de este salto en eficiencia, hay profundas implicaciones para los trabajadores y el mercado laboral que requieren consideración.
Retos y limitaciones de los LLM
Los LLM están a la vanguardia de la revolución de la IA generativa. Sin embargo, como siempre ocurre con las tecnologías emergentes, con el poder viene la responsabilidad. A pesar de las capacidades únicas del LLM, es importante tener en cuenta sus riesgos y retos potenciales.
A continuación encontrarás una lista de riesgos y retos asociados a la adopción generalizada de los LLM:
- Falta de transparencia. La opacidad algorítmica es una de las principales preocupaciones asociadas a los LLM. Estos modos suelen etiquetarse como modelos de "caja negra" debido a su complejidad, que hace imposible controlar su razonamiento y funcionamiento interno. Los proveedores de IA de LLM patentados suelen ser reacios a facilitar información sobre sus modelos, lo que dificulta mucho la supervisión y la rendición de cuentas.
- Monopolio LLM. Dados los considerables recursos necesarios para desarrollar, formar y hacer funcionar los LLM, el mercado está muy concentrado en un puñado de grandes empresas tecnológicas con los conocimientos y recursos necesarios. Afortunadamente, cada vez llegan al mercado más LLM de código abierto , lo que facilita a los desarrolladores, a los investigadores de IA y a la sociedad la comprensión y el funcionamiento de los LLM.
- Prejuicios y discriminación. Los modelos de LLM sesgados pueden dar lugar a decisiones injustas que a menudo exacerban la discriminación, especialmente contra los grupos minoritarios. De nuevo, la transparencia es esencial aquí para comprender mejor y abordar los posibles sesgos.
- Cuestiones de privacidad. Los LLM se entrenan con grandes cantidades de datos extraídos principalmente de forma indiscriminada de Internet. Normalmente, suele contener datos personales. Esto puede dar lugar a problemas y riesgos relacionados con la privacidad y la seguridad de los datos.
- Consideraciones éticas. En ocasiones, los LLM pueden dar lugar a decisiones que tienen graves implicaciones en nuestras vidas, con importantes repercusiones en nuestros derechos fundamentales. Exploramos la ética de la IA generativa en otro post.
- Consideraciones medioambientales. Los investigadores y los defensores del medio ambiente están expresando su preocupación por la huella medioambiental asociada a la formación y el funcionamiento de los LLM. Los LLM propietarios rara vez publican información sobre la energía y los recursos que consumen, ni sobre la huella medioambiental asociada, lo que resulta extremadamente problemático con la rápida adopción de estas herramientas.
Diferentes tipos y ejemplos de LLM
El diseño de los LLM los convierte en modelos extremadamente flexibles y adaptables. Esta modularidad se traduce, en particular, en distintos tipos de LLM:
- LLMs de tiro cero. Estos modelos son capaces de realizar una tarea sin haber recibido ningún ejemplo de entrenamiento. Por ejemplo, considera un LLM que sea capaz de comprender la nueva jerga basándose en las relaciones posicionales y semánticas de estas nuevas palabras con el resto del texto.
- LLM afinados. Es muy habitual que los desarrolladores tomen un LLM preentrenado y lo ajusten con nuevos datos para fines específicos. Para saber más sobre el ajuste fino LLM, lee nuestro artículo Ajuste fino LLaMA 2: Guía paso a paso para personalizar el Modelo de Lenguaje Grande.
- LLM de dominio específico. Estos modelos están diseñados específicamente para captar la jerga, los conocimientos y las particularidades de un campo o sector concreto, como el sanitario o el jurídico. Al desarrollar estos modelos, es importante elegir datos de entrenamiento curados, para que el modelo cumpla las normas del campo en cuestión.
Hoy en día, el número de LLM propietarios y de código abierto está creciendo rápidamente. Puede que ya hayas oído hablar de ChatGPT, pero ChatGPT no es un LLM, sino una aplicación construida sobre un LLM. En concreto, ChatGPT funciona con GPT-3.5, mientras que ChatGPT-Plus funciona con GPT-4, actualmente el LLM más potente. Para saber más sobre cómo utilizar los modelos GPT de OpenAI, lee nuestro artículo Utilizar GPT-3.5 y GPT-4 mediante la API de OpenAI en Python.
A continuación, puedes encontrar una lista de otros LLM populares:
- BERT. Google en 2018 y publicado en código abierto, BERT es uno de los primeros LLM modernos y uno de los más exitosos. Consulta nuestro artículo ¿Qué es el BERT? para saberlo todo sobre este LLM clásico.
- PaLM 2. Un LLM más avanzado que su predecesor PaLM, PaLM 2 es el LLM que impulsa Google Bard, el chatbot más ambicioso que compite con ChatGPT.
- LLaMa 2. Desarrollado por Meta, LLaMa 2 es uno de los LLM de código abierto más potentes del mercado. Para saber más sobre este y otros LLM de código abierto, te recomendamos que leas nuestro artículo dedicado con los 8 mejores LLM de código abierto.
Conclusión
Los LLM están impulsando el auge actual de la IA generativa. Las aplicaciones potenciales son tan amplias que es probable que todos los sectores e industrias, incluida la ciencia de los datos, se vean afectados por la adopción de los LLM en el futuro.
Las posibilidades son infinitas, pero también los riesgos y los retos. Con su carácter transformador y, los LLM han suscitado especulaciones sobre el futuro y sobre cómo afectará la IA al mercado laboral y a muchos otros aspectos de nuestras sociedades. Se trata de un debate importante que debe abordarse con firmeza y de forma colectiva, ya que hay mucho en juego.
DataCamp se esfuerza por proporcionar recursos completos y accesibles para que todo el mundo se mantenga al día del desarrollo de la IA. Compruébalo:
- Curso de Conceptos de Grandes Modelos Lingüísticos (LLM)
- Cómo crear aplicaciones LLM con LangChain
- Cómo entrenar un LLM con PyTorch: Guía paso a paso
- 8 mejores LLM de código abierto para 2024 y sus usos
- Llama.cpp Tutorial: Una Guía Completa para la Inferencia e Implementación Eficiente del LLM
- Introducción a LangChain para Ingeniería de Datos y Aplicaciones de Datos
- LlamaIndex: Un marco de datos para las aplicaciones basadas en grandes modelos lingüísticos (LLM)
- Cómo aprender IA desde cero en 2024: Guía completa del experto

Serie Code Along: Conviértete en desarrollador de IA
¡Construye sistemas de IA y desarrolla aplicaciones de IA utilizando OpenAI, LangChain, Pinecone y Hugging Face!




