Curso
Introducción a Python
4 h
6.9M
En este tutorial, nos adentraremos en el funcionamiento del t-SNE, una potente técnica de reducción de la dimensionalidad y visualización de datos. Lo compararemos con otra técnica popular, el PCA, y demostraremos cómo realizar tanto el t-SNE como el PCA utilizando scikit-learn y plotly express en conjuntos de datos sintéticos y del mundo real.
t-SNE (t-distributed Stochastic Neighbor Embedding) es una técnica no supervisada de reducción no lineal de la dimensionalidad para la exploración de datos y la visualización de datos de alta dimensión. La reducción no lineal de la dimensionalidad significa que el algoritmo permite separar datos que no pueden separarse mediante una línea recta.

t-SNE te da una idea y te permite intuir cómo se organizan los datos en dimensiones superiores. Suele utilizarse para visualizar conjuntos de datos complejos en dos y tres dimensiones, lo que nos permite comprender mejor los patrones y relaciones subyacentes en los datos.
Sigue nuestro curso de Reducción de la dimensionalidad en Python para aprender a explorar datos de alta dimensión, selección de características y extracción de características.
Tanto el t-SNE como el PCA son técnicas de reducción dimensional que tienen mecanismos diferentes y funcionan mejor con distintos tipos de datos.
El PCA (análisis de componentes principales) es una técnica lineal que funciona mejor con datos que tienen una estructura lineal. Trata de identificar los componentes principales subyacentes en los datos. Para ello, proyéctalos en dimensiones inferiores, minimiza la varianza y preserva las grandes distancias entre pares. Lee nuestro tutorial sobre Análisis de componentes principales (PCA) para comprender el funcionamiento interno de los algoritmos con ejemplos en R.
Pero el t-SNE es una técnica no lineal que se centra en preservar las similitudes entre pares de puntos de datos en un espacio de dimensiones inferiores. El t-SNE se ocupa de preservar las pequeñas distancias entre pares, mientras que el PCA se centra en mantener las grandes distancias entre pares para maximizar la varianza.
En resumen, el PCA preserva la varianza de los datos, mientras que el t-SNE preserva las relaciones entre los puntos de datos en un espacio de menor dimensión, lo que lo convierte en un algoritmo bastante bueno para visualizar datos complejos de alta dimensión.
El algoritmo t-SNE halla la medida de similitud entre pares de instancias en un espacio de mayor y menor dimensión. Después, intenta optimizar dos medidas de similitud. Hace todo eso en tres pasos.
El proceso de optimización permite la creación de conglomerados y subconglomerados de puntos de datos similares en el espacio de dimensión inferior, que se visualizan para comprender la estructura y la relación en los datos de dimensión superior.
En el ejemplo de Python, generaremos datos de clasificación, realizaremos el PCA y el t-SNE, y visualizaremos los resultados. Para realizar la reducción de la dimensionalidad, utilizaremos Scikit-Learn, y para la visualización, utilizaremos Plotly Express.
Utilizaremos la función make_classification de Scikit-Learn para generar datos sintéticos con 6 características, 1500 muestras y 3 clases.
Después, trazaremos en 3D las tres primeras características de los datos utilizando la función Plotly Express scatter_3d.
import plotly.express as px
from sklearn.datasets import make_classification
X, y = make_classification(
n_features=6,
n_classes=3,
n_samples=1500,
n_informative=2,
random_state=5,
n_clusters_per_class=1,
)
fig = px.scatter_3d(x=X[:, 0], y=X[:, 1], z=X[:, 2], color=y, opacity=0.8)
fig.show()Tenemos un gráfico 3D de los datos; también puedes visualizar los datos en un gráfico 2D con la función Plotly Express scatter.
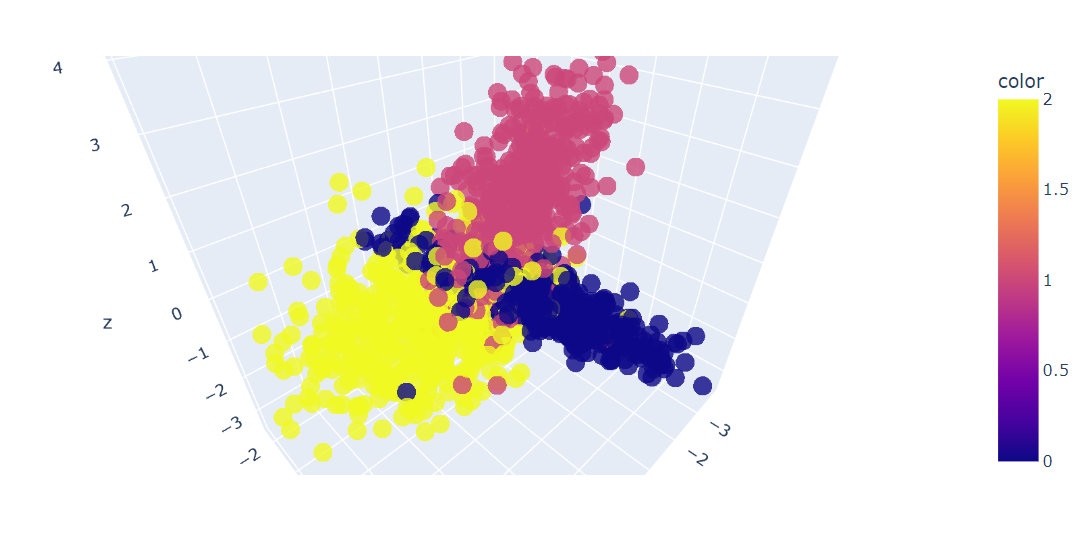
Ahora aplicaremos el algoritmo PCA al conjunto de datos para obtener dos componentes del PCA. El fit_transform aprende y transforma el conjunto de datos al mismo tiempo.
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)Ahora podemos visualizar los resultados al mostrar dos componentes del ACP en un gráfico de dispersión.
También hemos utilizado la función update_layout para añadir un título y renombrar el eje x y el eje y.
fig = px.scatter(x=X_pca[:, 0], y=X_pca[:, 1], color=y)
fig.update_layout(
title="PCA visualization of Custom Classification dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
fig.show()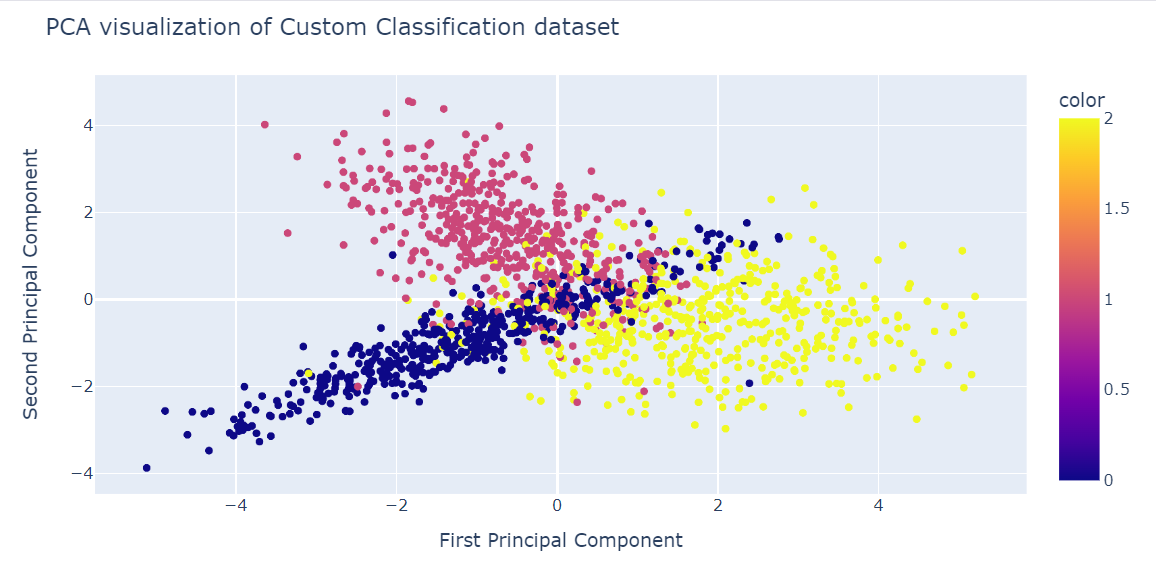
Ahora aplicaremos el algoritmo t-SNE al conjunto de datos y compararemos los resultados.
Tras ajustar y transformar los datos, mostraremos la divergencia de Kullback-Leibler (KL) entre la distribución de probabilidad de alta dimensión y la distribución de probabilidad de baja dimensión.
Una divergencia KL baja es señal de mejores resultados.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)
tsne.kl_divergence_1.1169137954711914De forma similar al PCA, visualizaremos dos componentes t-SNE en un gráfico de dispersión.
fig = px.scatter(x=X_tsne[:, 0], y=X_tsne[:, 1], color=y)
fig.update_layout(
title="t-SNE visualization of Custom Classification dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()El resultado es bastante mejor que el PCA. Podemos ver claramente tres grandes grupos.
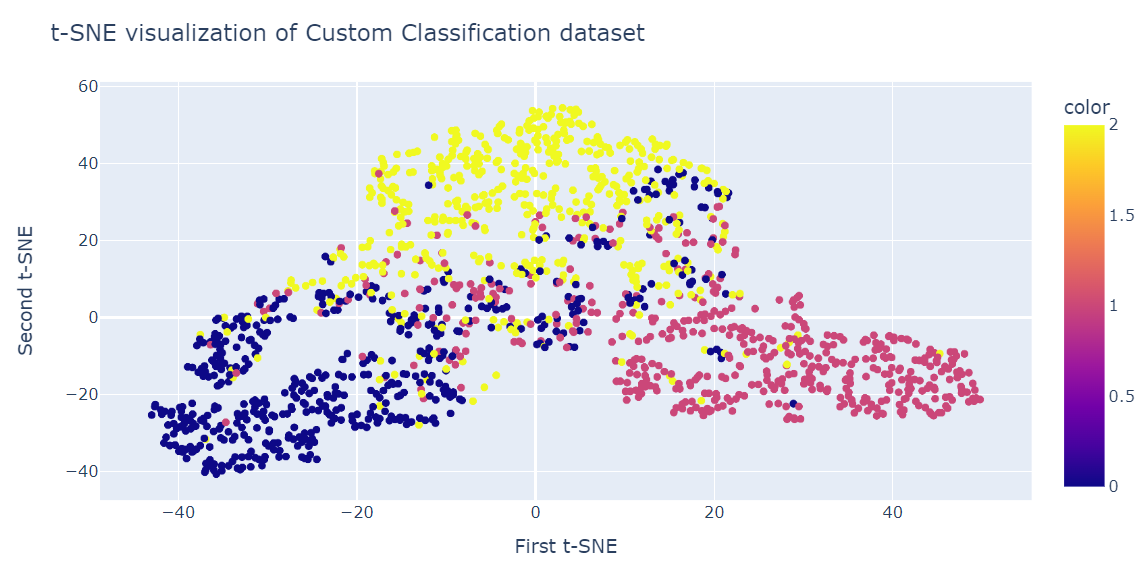
En esta sección, utilizaremos el conjunto de datos reales de rotación de clientes de una empresa de telecomunicaciones iraní. El conjunto de datos contiene información sobre la actividad de los clientes, como fallos en las llamadas y duración de la suscripción, y una etiqueta de churn.
El churn es el porcentaje de clientes que dejan de utilizar un servicio concreto durante un periodo de tiempo determinado.
Nota: El código fuente y el conjunto de datos de ambos ejemplos están disponibles en este cuaderno de trabajo de DataLab; si quieres retocar y ejecutar el código, haz una copia y ¡listo!
Cargaremos el conjunto de datos utilizando pandas y mostraremos las tres primeras filas.
import pandas as pd
df = pd.read_csv("data/customer_churn.csv")
df.head(3)
Después, haremos lo siguiente:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = df.drop('Churn', axis=1)
y = df['Churn']
scaler = StandardScaler()
X_norm = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(
X_norm, y, random_state=13, test_size=0.25, shuffle=True
)
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train)
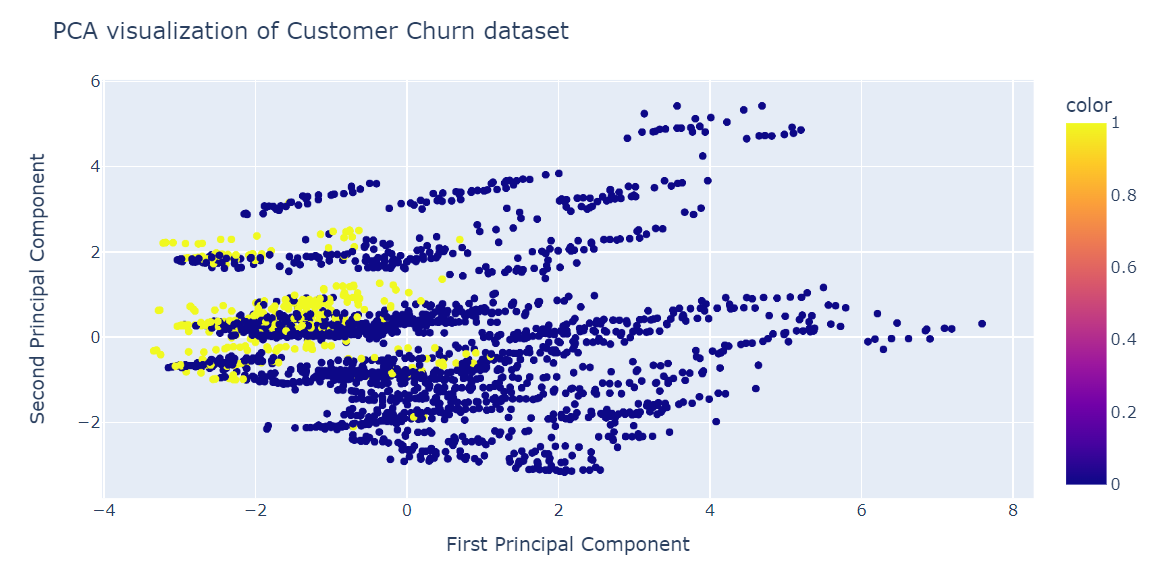
pca.score(X_test)-17.04482851288105Ahora visualizaremos el resultado del ACP utilizando el gráfico de dispersión Plotly Express.
fig = px.scatter(x=X_train_pca[:, 0], y=X_train_pca[:, 1], color=y_train)
fig.update_layout(
title="PCA visualization of Customer Churn dataset",
xaxis_title="First Principal Component",
yaxis_title="Second Principal Component",
)
fig.show()El PCA no era bueno para crear conglomerados. Los datos de la dimensión baja parecen aleatorios. También podría significar que las características del conjunto de datos están muy sesgadas, o que no tiene una estructura de correlación fuerte.
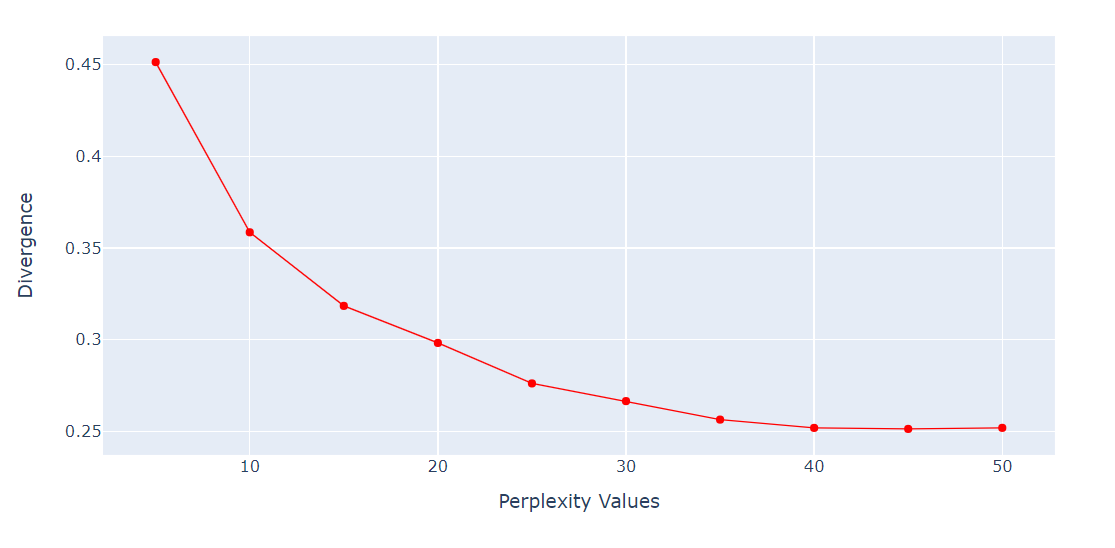
Para el algoritmo t-SNE, la perplejidad es un hiperparámetro muy importante. Controla el número efectivo de vecinos que considera cada punto durante el proceso de reducción de la dimensionalidad.
Ejecutaremos un bucle para obtener la métrica de divergencia KL en varias perplejidades de 5 a 55 con 5 puntos de diferencia. Después, mostraremos el resultado utilizando el gráfico de líneas de Plotly Express.
import numpy as np
perplexity = np.arange(5, 55, 5)
divergence = []
for i in perplexity:
model = TSNE(n_components=2, init="pca", perplexity=i)
reduced = model.fit_transform(X_train)
divergence.append(model.kl_divergence_)
fig = px.line(x=perplexity, y=divergence, markers=True)
fig.update_layout(xaxis_title="Perplexity Values", yaxis_title="Divergence")
fig.update_traces(line_color="red", line_width=1)
fig.show()La divergencia KL se ha vuelto constante después de 40 perplejidades. Por tanto, utilizaremos 40 de perplejidad en el algoritmo t-SNE.
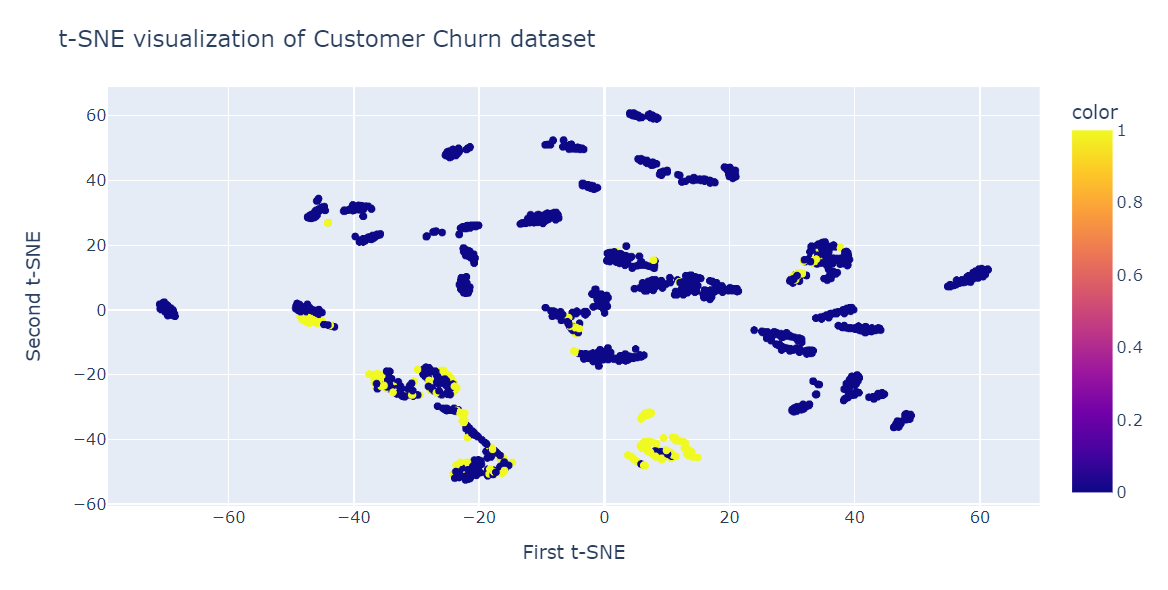
Ahora ajustaremos t-SNE y transformaremos los datos a dimensiones inferiores utilizando 40 de perplejidad para obtener la divergencia KL más baja.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2,perplexity=40, random_state=42)
X_train_tsne = tsne.fit_transform(X_train)
tsne.kl_divergence_0.258713960647583Ahora utilizaremos el gráfico de dispersión Plotly para visualizar los componentes y las clases objetivo.
fig = px.scatter(x=X_train_tsne[:, 0], y=X_train_tsne[:, 1], color=y_train)
fig.update_layout(
title="t-SNE visualization of Customer Churn dataset",
xaxis_title="First t-SNE",
yaxis_title="Second t-SNE",
)
fig.show()Como vemos, tenemos varios conglomerados y subconglomerados. Podemos utilizar esta información para comprender el patrón y elaborar una estrategia para retener a los clientes existentes.
Además de visualizar datos multidimensionales complejos, el t-SNE tiene otros usos, sobre todo en el ámbito médico.
t-SNE es una potente herramienta de visualización para revelar patrones y estructuras ocultos en conjuntos de datos complejos. Puedes utilizarlo para imágenes, audio, biológicos y datos individuales para identificar anomalías y patrones.
En esta entrada del blog, hemos aprendido sobre t-SNE, una popular técnica de reducción de la dimensionalidad que puede visualizar datos no lineales de alta dimensión en un espacio de baja dimensión. Hemos explicado la idea principal del t-SNE, cómo funciona y sus aplicaciones. Además, mostramos algunos ejemplos de aplicación del t-SNE a conjuntos de datos sintéticos y reales y cómo interpretar los resultados.
El t-SNE forma parte del aprendizaje no supervisado, y el siguiente paso natural es comprender el agrupamiento jerárquico, el PCA, la decorrelación y el descubrimiento de características interpretables. Aprende todos los temas con nuestro curso Aprendizaje no supervisado en Python.
Más información sobre Python
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Kevin Babitz
Tutorial
Elena Kosourova
Tutorial
Kevin Babitz
Tutorial
Natassha Selvaraj

