Curso
Introducción a Python
4 h
6.9M

Tableau ofrece varias opciones para aumentar y crear nuevos campos de datos. Puedes usar funciones aritméticas, lógicas, espaciales y de modelado predictivo con campos calculados. Tableau es una potente herramienta de inteligencia empresarial (BI), pero tiene limitaciones; ahí es donde el lenguaje Python viene al rescate.
Python es una programación popular entre la comunidad de datos. Puedes utilizarlo para extraer, limpiar, procesar y aplicar funciones estadísticas complejas en los datos. Te proporciona marcos de machine learning, orquestaciones de datos, multiprocesamiento y ricas bibliotecas para realizar casi cualquier tarea posible.
Python es un lenguaje polivalente, y usarlo con Tableau nos da libertad para realizar tareas muy complejas. En este tutorial, vamos a utilizar Python para extraer y limpiar los datos. A continuación, utilizaremos datos limpios para crear una visualización de datos en Tableau.
No utilizaremos Tabpy para crear un servidor Python de Tableau y ejecutar scripts Python dentro de Tableau. Primero extraeremos y limpiaremos los datos en Python (Jupyter Notebook) y luego utilizaremos Tableau para crear una visualización interactiva.
Goodreads Data Viz | Tableau Public
Este es un tutorial paso a paso basado en código sobre la API de Goodreads y la creación de visualizaciones complejas en Tableau. Consulta el siguiente enlace para acceder al código y al panel de Tableau.
En la primera parte del tutorial, aprenderemos a utilizar la API de Goodreads para acceder a datos públicos. En nuestro caso, nos centraremos en el perfil de usuario y lo convertiremos en un dataframe Pandas legible. Además, limpiaremos los datos y los exportaremos al formato de archivo CSV.
Utilizaremos el Workspace de DataCamp para ejecutar el código Python. Viene con los paquetes de Python necesarios para las tareas de ciencia de datos.
Si eres nuevo en Python y quieres configurar el entorno en tu equipo local, instala Anaconda. Instalará Python, Jupyter Notebook y los paquetes de Python necesarios.
Antes de empezar a escribir el código, tenemos que instalar el paquete xmltodict, ya que no forma parte de la pila de datos de Workspace ni de Anaconda. Utilizaremos `pip` para instalar el paquete de Python que falta.
Nota: El símbolo `!` solo funciona en Jupyter Notebooks. Nos permite acceder al terminal dentro de la celda de código Jupyter.
!pip install xmltodict
>>> Collecting xmltodict
>>> Using cached xmltodict-0.13.0-py2.py3-none-any.whl (10.0 kB)
>>> Installing collected packages: xmltodict
>>> Successfully installed xmltodict-0.13.0En el siguiente paso, importaremos los paquetes necesarios.
import pandas as pd
import xmltodict
import urllib.requestPara extraer los datos del usuario, necesitamos tanto el ID de usuario como el nombre de usuario. En esta sección, analizaremos el enlace del perfil del usuario (Abid).
Nota: Puedes utilizar el perfil de tu amigo o utilizar el enlace de tu perfil, y ejecutar este script.
Goodread_profile = "https://www.goodreads.com/user/show/73376016-abid"
user_id = ''.join(filter(lambda i: i.isdigit(), Goodread_profile))
user_name = Goodread_profile.split(user_id, 1)[1].split('-', 1)[1].replace('-', ' ')
user_id_name = user_id+'-'+user_name
print(user_id_name)
>>> 73376016-abidA finales de 2020, Goodreads dejará de proporcionar la API para desarrolladores. Puedes leer el informe completo aquí. Para superar este problema, utilizaremos claves de API de proyectos anteriores, como streamlit_goodreads_app. El proyecto explica cómo acceder a los datos de usuario de Goodreads utilizando la API.
Goodreads también te ofrece la opción de descargar los datos en formato de archivo CSV sin una clave de API, pero está limitada a un usuario, y no nos da la libertad de extraer datos en tiempo real.
En esta sección, crearemos funciones que tomarán user_id_name, version, shelf, per_page y apiKey.
La función toma las entradas del usuario para preparar la URL y luego descarga los datos utilizando urllib.request. Por último, obtenemos los datos en formato XML.
apiKey = "ZRnySx6awjQuExO9tKEJXw"
version = "2"
shelf = "read"
per_page = "200"
def get_user_data(user_id, apiKey, version, shelf, per_page):
api_url_base = "https://www.goodreads.com/review/list"
final_url = (
api_url_base
+ user_id
+ ".xml?key="
+ apiKey
+ "&v="
+ version
+ "&shelf="
+ shelf
+ "&per_page="
+ per_page
)
contents = urllib.request.urlopen(final_url).read()
return contents
contents = get_user_data(user_id_name,apiKey,version, shelf, per_page)
print(contents[0:100])
>>> b'<?xml version="1.0" encoding="UTF-8"?>\n<GoodreadsResponse>\n <Request>\n <authentication>true</aut'Nuestros datos iniciales están en formato XML, y no hay forma directa de convertirlos en una base de datos estructurada. Así que los transformaremos en JSON utilizando el paquete xmltodict de Python.
Los datos XML se convierten en formato JSON anidado, y para mostrar la primera entrada de los datos de reseñas de libros, utilizaremos corchetes para acceder a los datos encapsulados.
Puedes experimentar con los metadatos y explorar más opciones, pero en este tutorial nos centraremos en los datos de reseñas de usuarios.
contents_json = xmltodict.parse(contents)
print(contents_json["GoodreadsResponse"]["reviews"]["review"][:1])
>>> [{'id': '4626706284', 'book': {'id': {'@type': 'integer', '#text': '57771224'}, 'isbn': '1250809606', 'isbn13': '9781250809605', 'text_reviews_count': {'@type': 'integer', '#text': '150'}, 'uri': 'kca://book/amzn1.gr.book.v3.tcNoY0o7ErAhczdQ', 'title': 'Good Intentions', 'title_without_series': 'Good Intentions', 'image_url': .........Para convertir el tipo de datos JSON en un dataframe Pandas, utilizaremos la función json_normalize. Los datos de las reseñas están presentes en el tercer nivel, y para acceder a ellos, accederemos a GoodreadsResponse, reseñas y reseña.
Antes de mostrar el dataframe, filtraremos los datos irrelevantes eliminando los libros a los que les falte la columna date_updated.
Aprende diferentes formas de ingesta de archivos CSV, hojas de cálculo, JSON, bases de datos SQL y API utilizando Pandas en el curso Ingesta de datos optimizada con pandas.
df = pd.json_normalize(contents_json["GoodreadsResponse"]["reviews"]["review"])
df = df[df["date_updated"].notnull()]
df.head()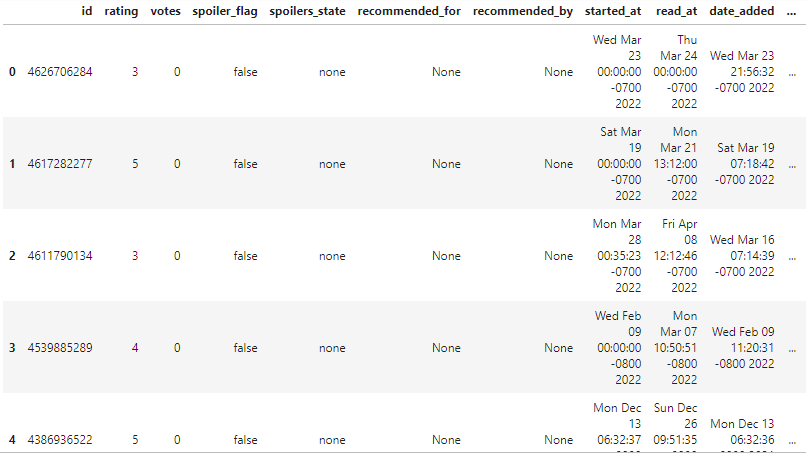
El dataframe sin procesar parece razonablemente limpio, pero aún tenemos que reducir el número de columnas.
Como podemos ver, hay 61 columnas.
df.shape
(200, 61)Eliminemos las vacías.
df.dropna(axis=1, how='all', inplace=True)
df.shape
(200, 58)Hemos eliminado correctamente 3 columnas a las que les faltaban los valores.
Ahora comprobaremos todos los nombres de columna utilizando `df.columns` y seleccionaremos las columnas más útiles.
final_df = df[
[
"rating",
"started_at",
"read_at",
"date_added",
"book.title",
"book.average_rating",
'book.ratings_count',
"book.publication_year",
"book.authors.author.name"
]
]
final_df.head()Como podemos observar, el dataframe final está limpio y tiene los campos de datos relevantes.
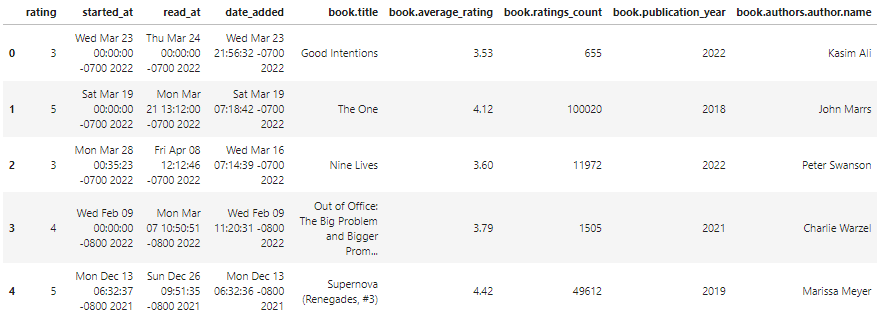
En la última sección, exportaremos el dataframe a un archivo CSV compatible con Tableau. En la función to_csv, añade el nombre del archivo con el tipo de extensión y elimina el índice cambiando el argumento de índice a False.
final_df.to_csv("abid_goodreads_clean_data.csv",index=False)El archivo CSV se mostrará en el directorio actual.
Archivo CSV limpio de Goodreads
También puedes consultar Python Jupyter Notebook: Ingesta de datos mediante la API de Goodreads. Te ayudará a depurar tu código y, si quieres saltarte la parte de programación en Python, puedes descargar el archivo haciendo clic en el botón Copy & Edit y ejecutando el script.
En la segunda parte, utilizaremos datos limpios y crearemos visualizaciones de datos sencillas y complejas en Tableau. Nuestro objetivo es trazar gráficos interactivos que nos ayuden a comprender el comportamiento de lectura de libros del usuario.
Conectaremos el archivo CSV seleccionando la opción de archivo Text y seleccionando el archivo abid_goodreads_clean_data.csv. Después, cambiaremos los campos de datos Started At, Read at y Date Added por Dater & Time, como se muestra a continuación.
Nota: Es una práctica recomendada modificar tus campos de datos al principio.
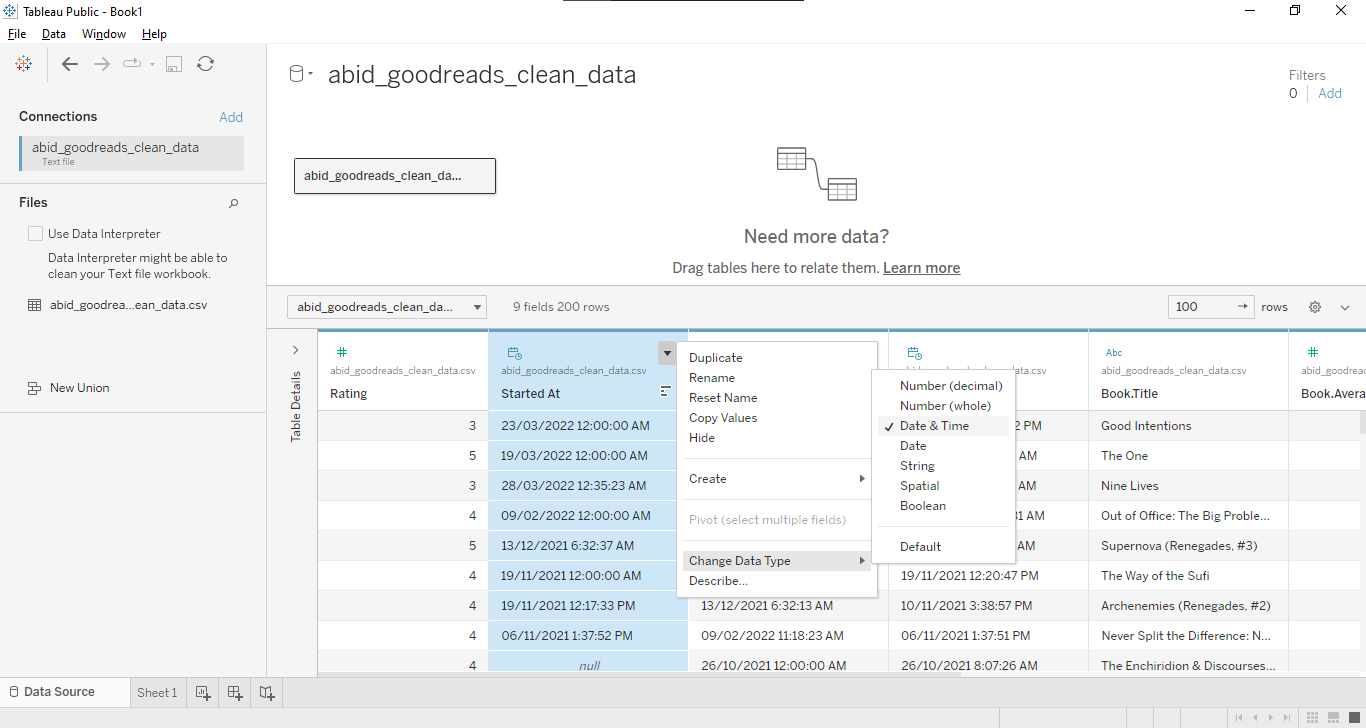
Conexión de datos y modificación de tipos de datos
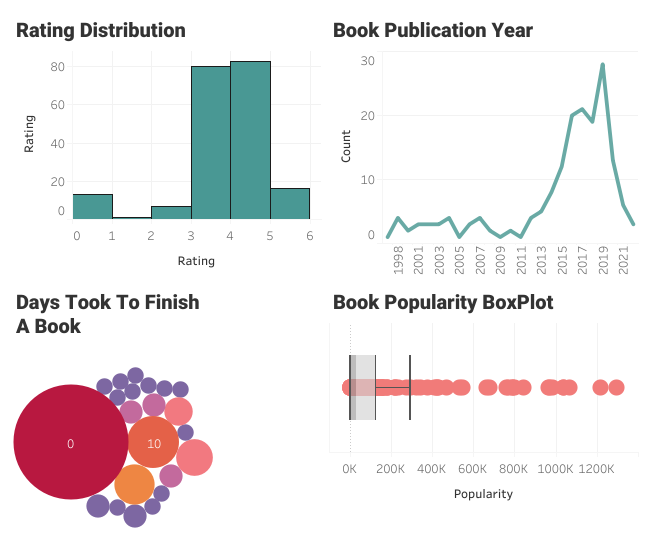
En esta sección, crearemos el histograma de valoraciones de libros del usuario.
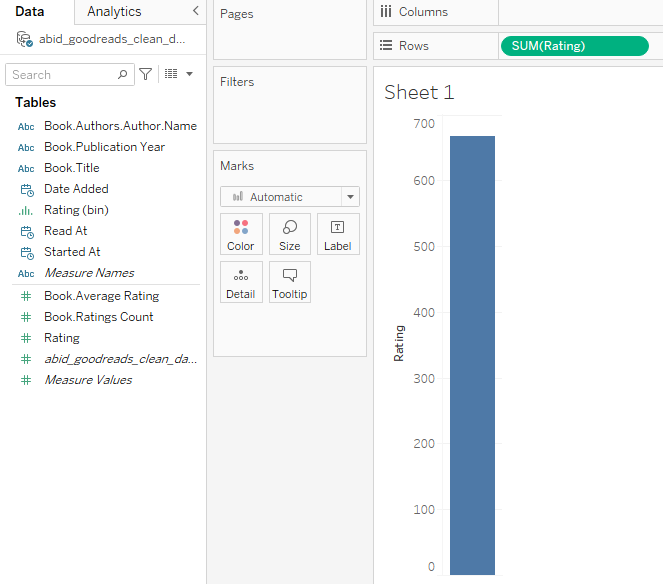
Histograma de valoraciones del usuario parte 1
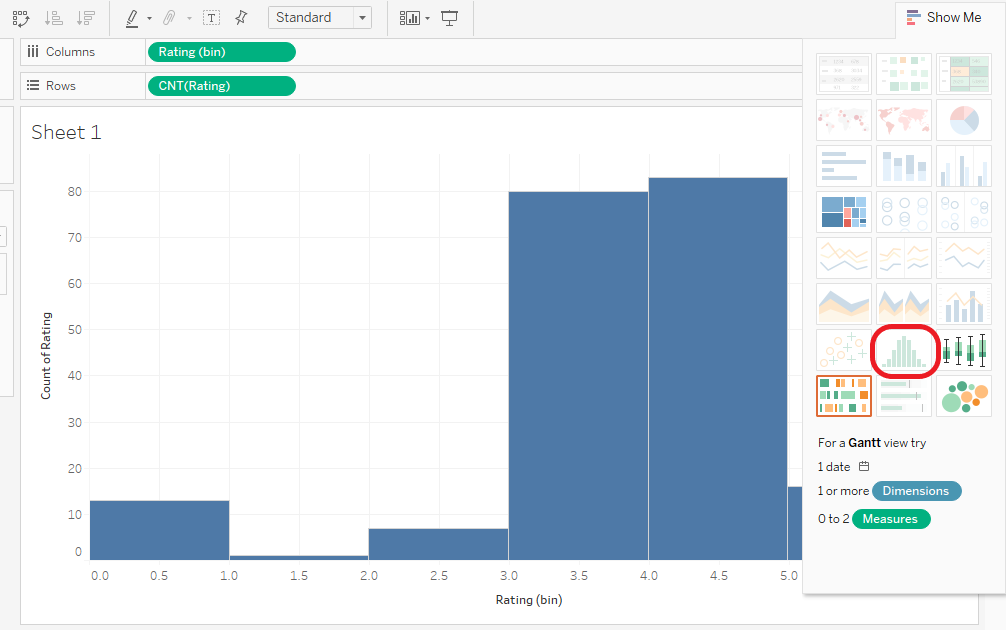
Histograma de valoraciones del usuario parte 2
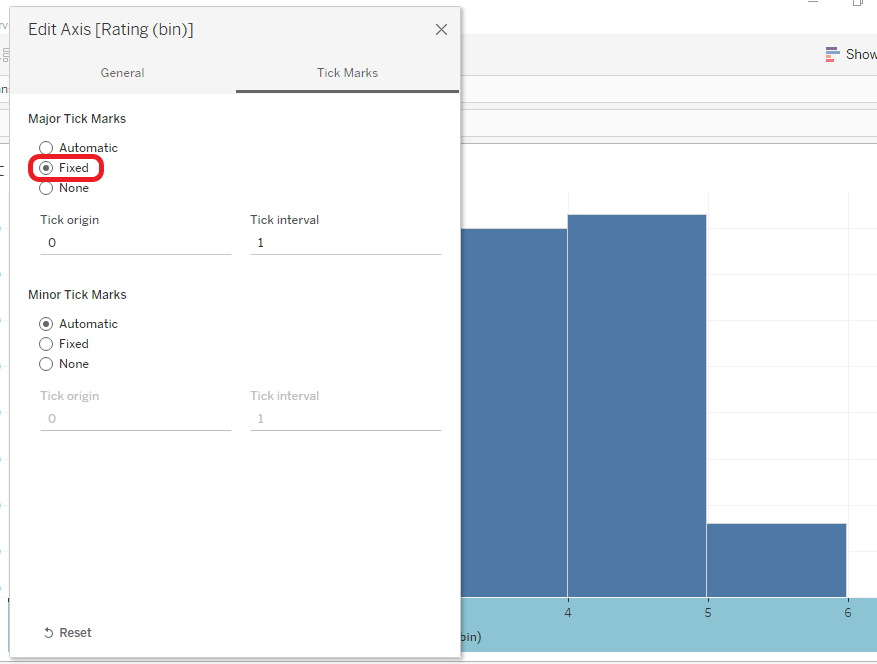
Histograma de valoraciones del usuario parte 3
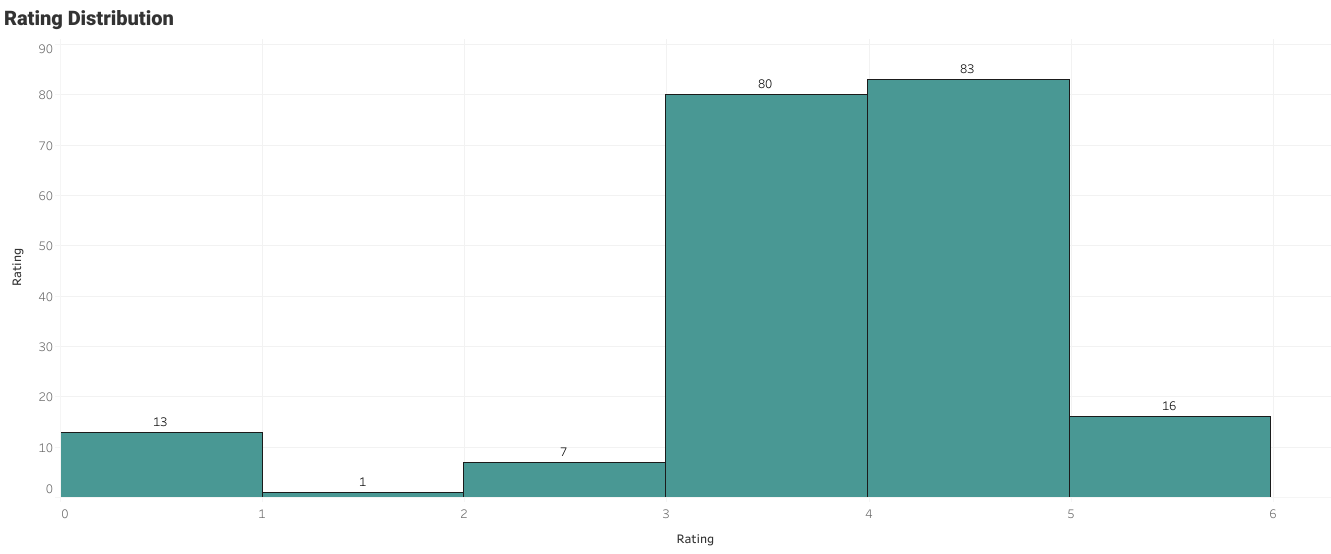
Histograma de valoraciones del usuario parte 4
Normalmente, el usuario había dado valoraciones entre 3 y 4. Las valoraciones cero son los libros que no están valorados.
Para trazar un gráfico de líneas:
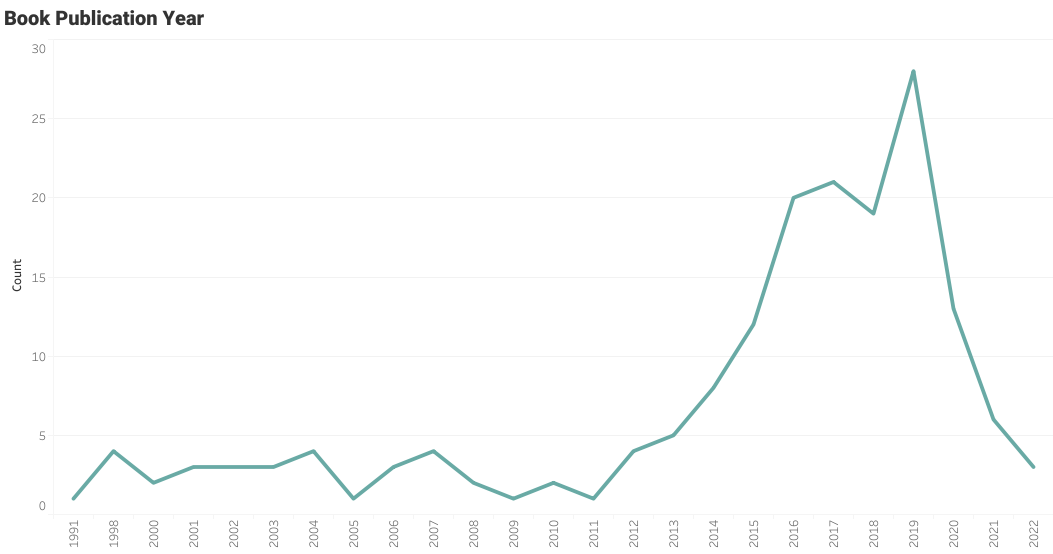
Gráfico de líneas de año de publicación de libro
El usuario ha leído algunos libros antiguos, pero está especialmente interesado en los libros publicados entre los años 2015 y 2020.
Si te sientes abrumado y quieres aprender los fundamentos de Tableau, puede que te resulte útil el tutorial de Tableau para principiantes de Eugenia Anello.
Para trazar el gráfico de caja y bigotes:

Gráfico de caja de número de reseñas por libro
Parece que el usuario lee menos libros populares y unos cuantos libros famosos. Significa que el usuario tiene un gusto único basado en el contenido, no en la popularidad.
Hemos creado una visualización sencilla pero sorprendente para conocer el comportamiento de lectura de los libros de los usuarios. A continuación, aprenderemos una visualización de datos más compleja, que incluye la creación de un nuevo campo calculado, la edición de bins y la creación de varias capas.
En los gráficos de burbujas, las etiquetas representan el número de días que tardó un usuario en terminar un libro, y el tamaño de la burbuja representa el número de casos. No tenemos un campo de datos para la duración, pero podemos crearlo utilizando Started At y Read At.
En el primer paso, tenemos que crear un nuevo campo calculado haciendo clic en la flecha hacia abajo del panel Data y seleccionando Create Calculated Field.
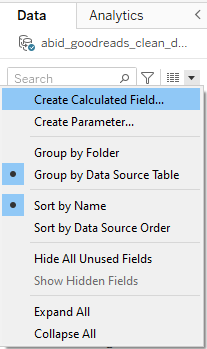
Creación de campo calculado
Aparecerá la nueva ventana y tendrás que:
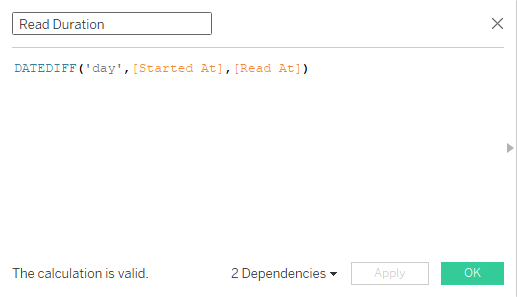
Duración de la lectura en días
El campo de datos Read Duration es continuo, y para trazar la visualización de burbujas empaquetadas, tenemos que dividir el campo de datos en fragmentos menores conocidos como bins.
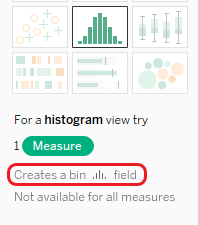
Crea un campo de bin
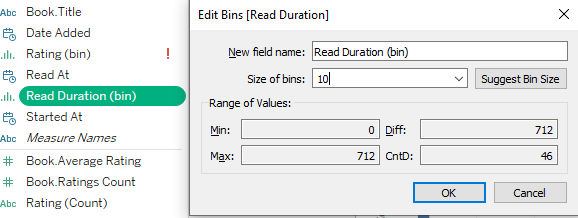
Edición de bins
Hemos recorrido un duro camino, y ahora es el momento de ver los frutos de nuestro trabajo.
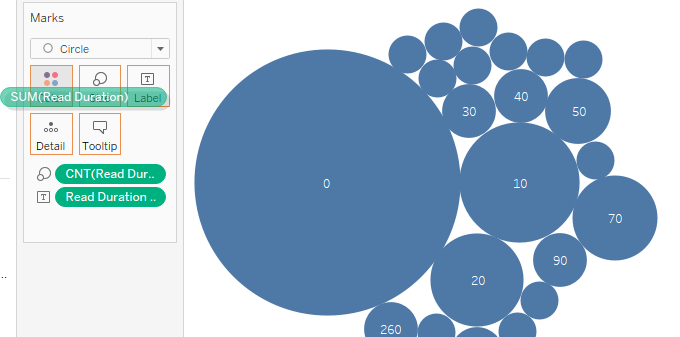
Gráfico de burbujas empaquetadas monocromo
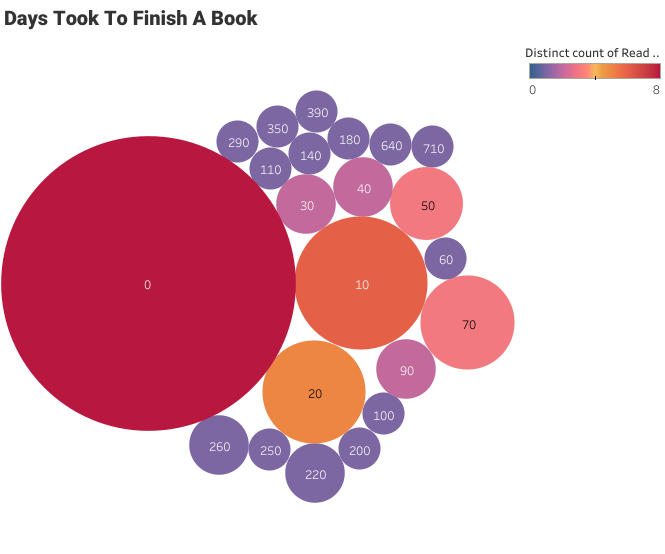
Gráfico de burbujas empaquetadas
El usuario tardó menos de un día en terminar la mayoría de los libros. También puedes ver algunos valores atípicos por encima de 300.
También podemos crear un panel de Tableau combinando estas visualizaciones. Aprende a crear un panel de Tableau en este tutorial.
En este tutorial, hemos aprendido la importancia de Python y cómo utilizarlo con Tableau. En la primera sección, extrajimos los datos de usuario de Goodreads utilizando la API para desarrolladores y convertimos los datos XML en un dataframe Pandas limpio y estructurado. En la segunda parte, utilizamos datos limpios para crear visualizaciones de datos sencillas y complejas.
La combinación de Python con Tableau abre todo un nuevo mundo de posibilidades. Puedes integrar pipelines de datos, implementar modelos de machine learning, ejecutar análisis estadísticos complejos y realizar diversas tareas que son imposibles solo con Tableau.
Puedes ejecutar el código Python en el Workspace de DataCamp de forma gratuita, que incluye todos los paquetes necesarios para ejecutar este ejemplo. Para crear la visualización de Tableau, hemos utilizado una versión gratuita de Tableau llamada Tableau Public.
Si eres nuevo en Python y quieres aprender más sobre las funcionalidades y la sintaxis, consulta el curso Introducción a la ciencia de datos en Python. Además, puedes dominar los fundamentos de la visualización y la personalización de Tableau con el programa de habilidades Fundamentos de Tableau. Consta de 5 cursos que abarcan una introducción a Tableau, análisis de datos, creación de paneles interactivos, trabajo en un caso práctico y conexión de varias fuentes de datos.
Cursos de Tableau y Python en DataCamp
Curso
Curso
Curso
Tutorial
Joleen Bothma
Tutorial
Moez Ali
Tutorial
Elena Kosourova
Tutorial
Kevin Babitz
Tutorial
Karlijn Willems

