Curso
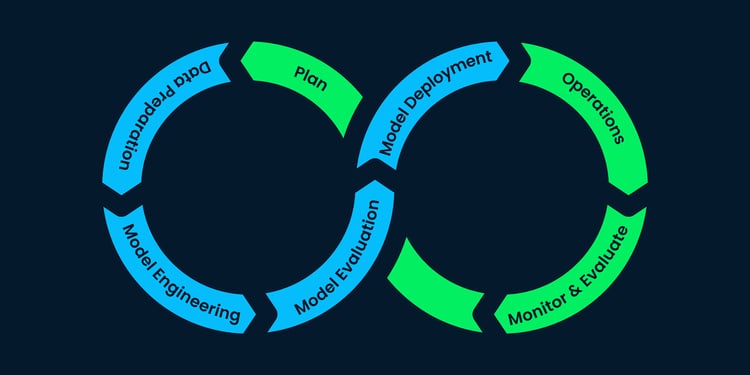
Conceptos de MLOps
2 h
42.6K

En este tutorial, aprenderemos a instalar y utilizar Jenkins, así como a crear agentes y pipelines y a ejecutarlos.
En concreto, lo haremos:
Si necesitas refrescar tus conocimientos, sigue un curso breve y sencillo de Conceptos MLOps para aprender a llevar los modelos de aprendizaje automático de los cuadernos Jupyter a modelos operativos en producción que generen un valor empresarial real.
Jenkins es un servidor de automatización de código abierto que desempeña un papel importante en el proceso de desarrollo del aprendizaje automático al facilitar la integración continua (IC) y el despliegue continuo (DC).
Escrito en Java, Jenkins ayuda a automatizar el procesamiento de datos, la formación, la evaluación y el despliegue de proyectos de aprendizaje automático, lo que lo convierte en una herramienta esencial para las prácticas de MLOps.
Características de Jenkins:
La automatización de tareas mediante Jenkins es sólo una parte del ecosistema MLOps. Puedes conocer otras tareas leyendo el blog 25 Top MLOps Tools You Need to Know in 2024. Consta de herramientas para el seguimiento de experimentos, la gestión de metadatos de modelos, la orquestación de flujos de trabajo, el versionado de datos y canalizaciones, el despliegue de modelos y la monitorización de servicios y modelos en producción.
Podemos instalar Jenkins fácilmente en Linux y macOS. Sin embargo, instalarlo en Windows requiere varios pasos. Estos pasos incluyen la instalación del kit de desarrollo de Java, la configuración de la política de seguridad local, la instalación de Jenkins con un usuario de dominio y el inicio del servidor Jenkins.
Empecemos por instalar Java. Tenemos que ir al sitio web de Adoptium y descargar la última versión LTS de Windows 11.
¿Por qué necesitamos instalar OpenJDK? Jenkins es una aplicación basada en Java que requiere un entorno de ejecución Java (JRE) o un kit de desarrollo Java (JDK) para ejecutarse.
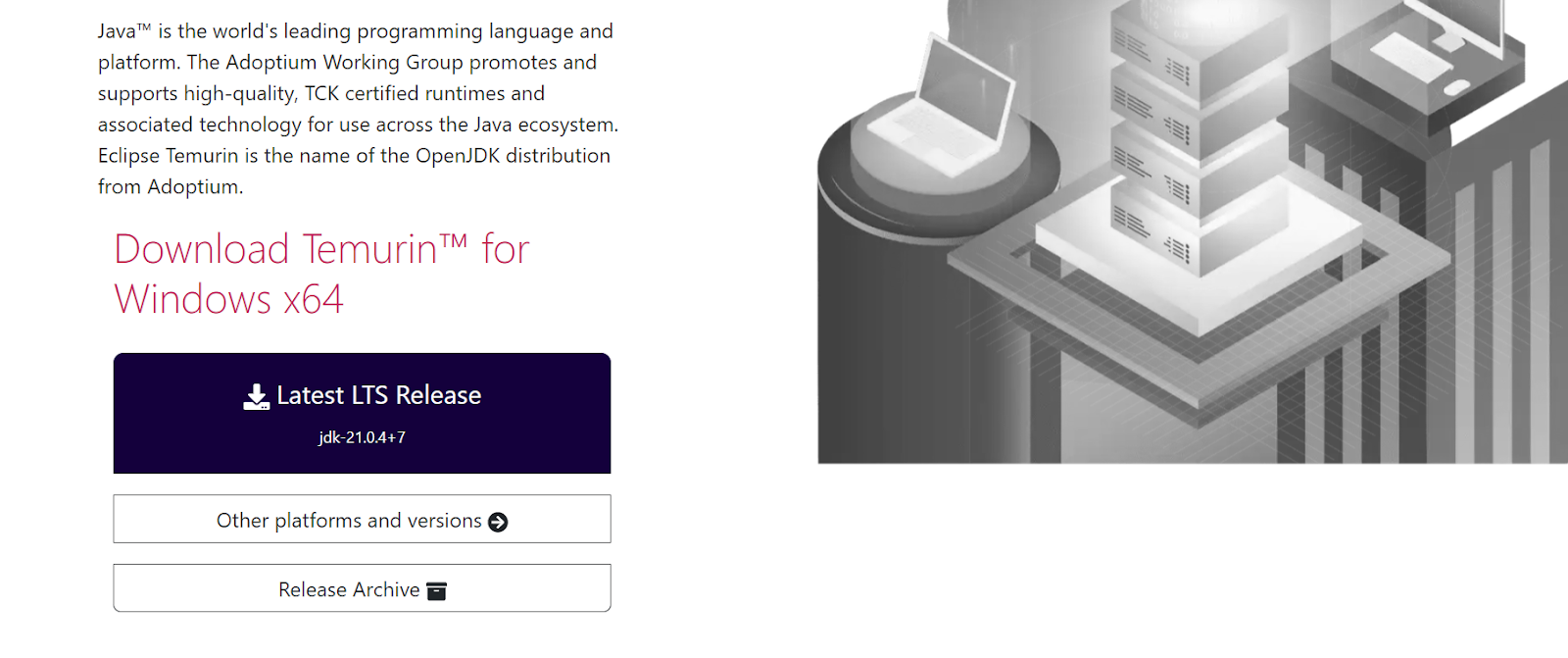
Fuente de la imagen: Adoptium
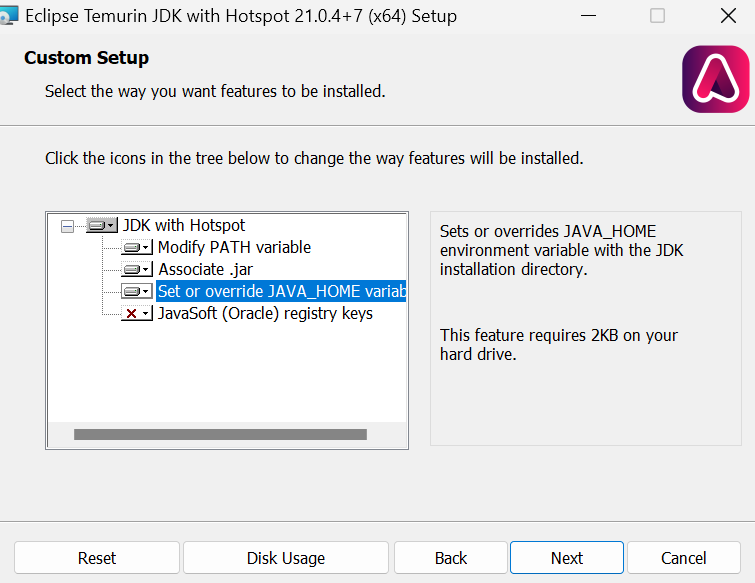
Instala el OpenJDK con los valores por defecto, excepto que tenemos que marcar la casilla "Establecer o anular la variable JAVA_HOME".
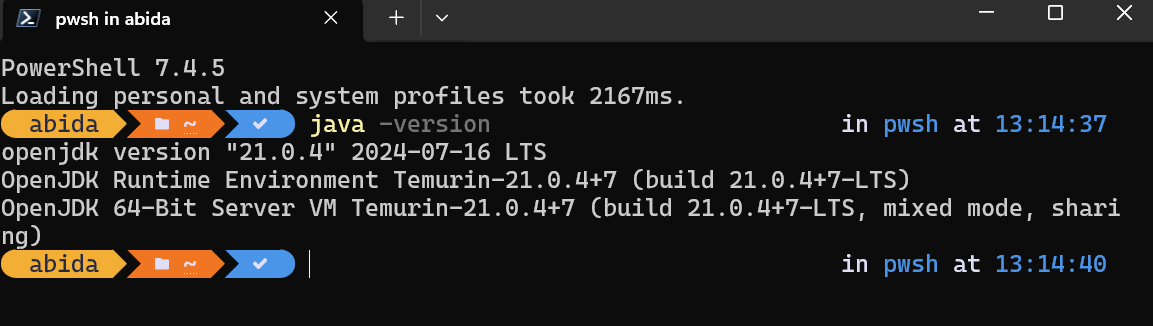
Una vez finalizada la instalación, podemos comprobar si se ha instalado correctamente escribiendo java -version en la ventana del terminal:
Para instalar Jenkins, tienes que modificar la "Política de seguridad local" para permitir el acceso de los usuarios al instalador. Para ello, pulsa las teclas Win + R de tu teclado, escribe "secpol.msc" y pulsa Intro. A continuación, ve a "Políticas locales" > "Asignación de derechos de usuario" > "Iniciar sesión como servicio".
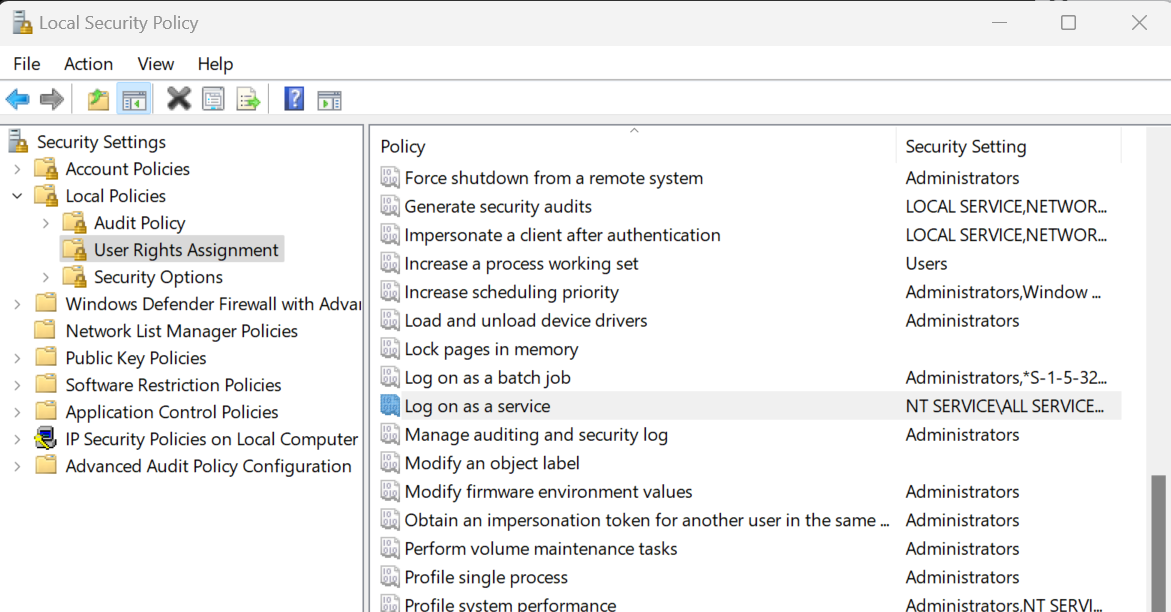
Se nos redirigirá a una nueva ventana, donde escribiremos nuestro nombre de usuario de Windows y haremos clic en el botón "Comprobar nombres". Después, pulsa el botón "Aceptar" y sal de la ventana "Política de seguridad local".
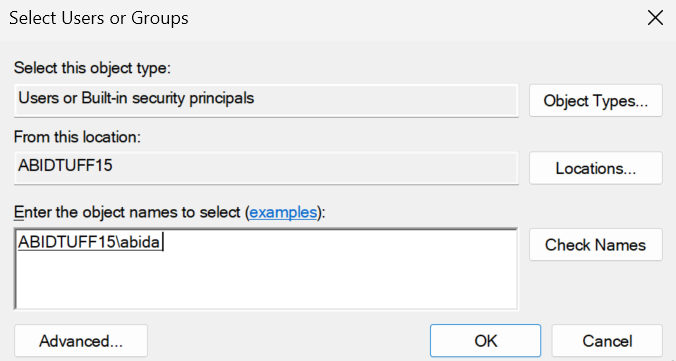
Ve al sitio web jenkins.io y descarga el paquete Windows Installer para Jenkins.
Fuente de la imagen: jenkins.io
Cuando lleguemos a la ventana que dice "Ejecutar servicio como usuario local o de dominio", escribe tu nombre de usuario y contraseña de Windows, y pulsa el botón "Probar credenciales". Si se aprueba, haz clic en el botón "Siguiente".
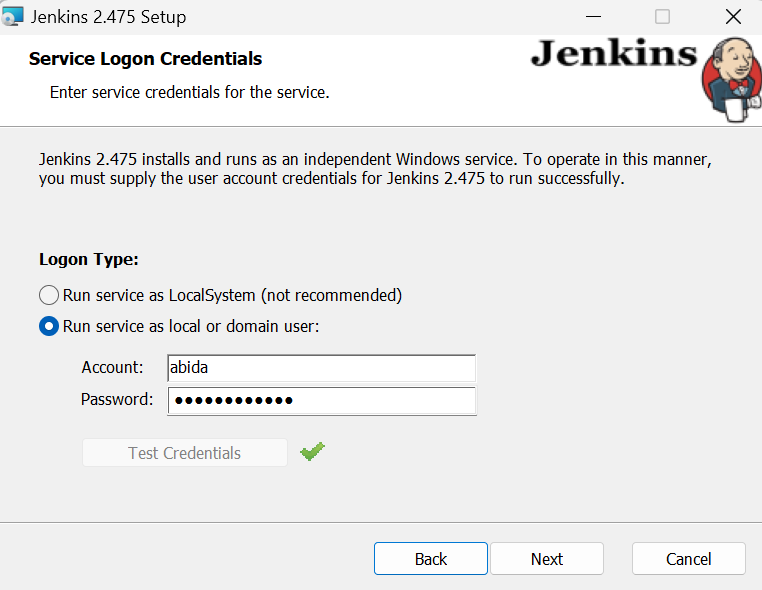
Mantén todo lo demás por defecto y termina la instalación. Puede que tarde unos minutos en configurarse.
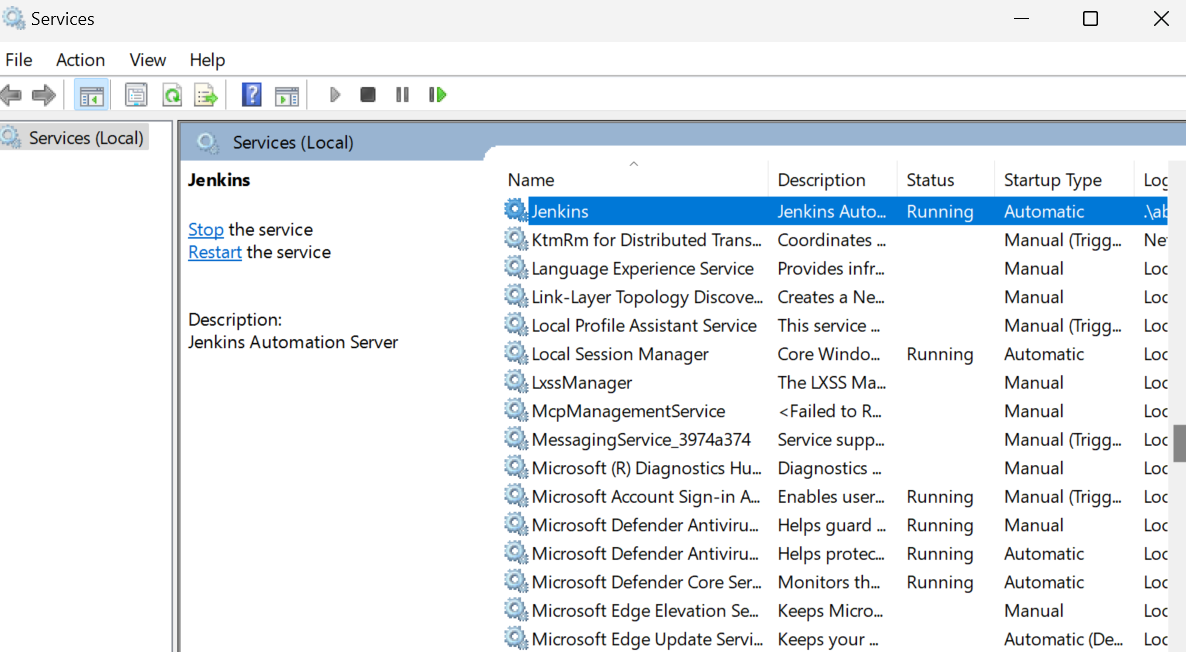
Iniciar el servidor Jenkins es sencillo. Sólo tenemos que hacer clic en la tecla de Windows y buscar "Servicios". En la ventana Servicios, busca Jenkins y haz clic en el botón de reproducción de la parte superior.
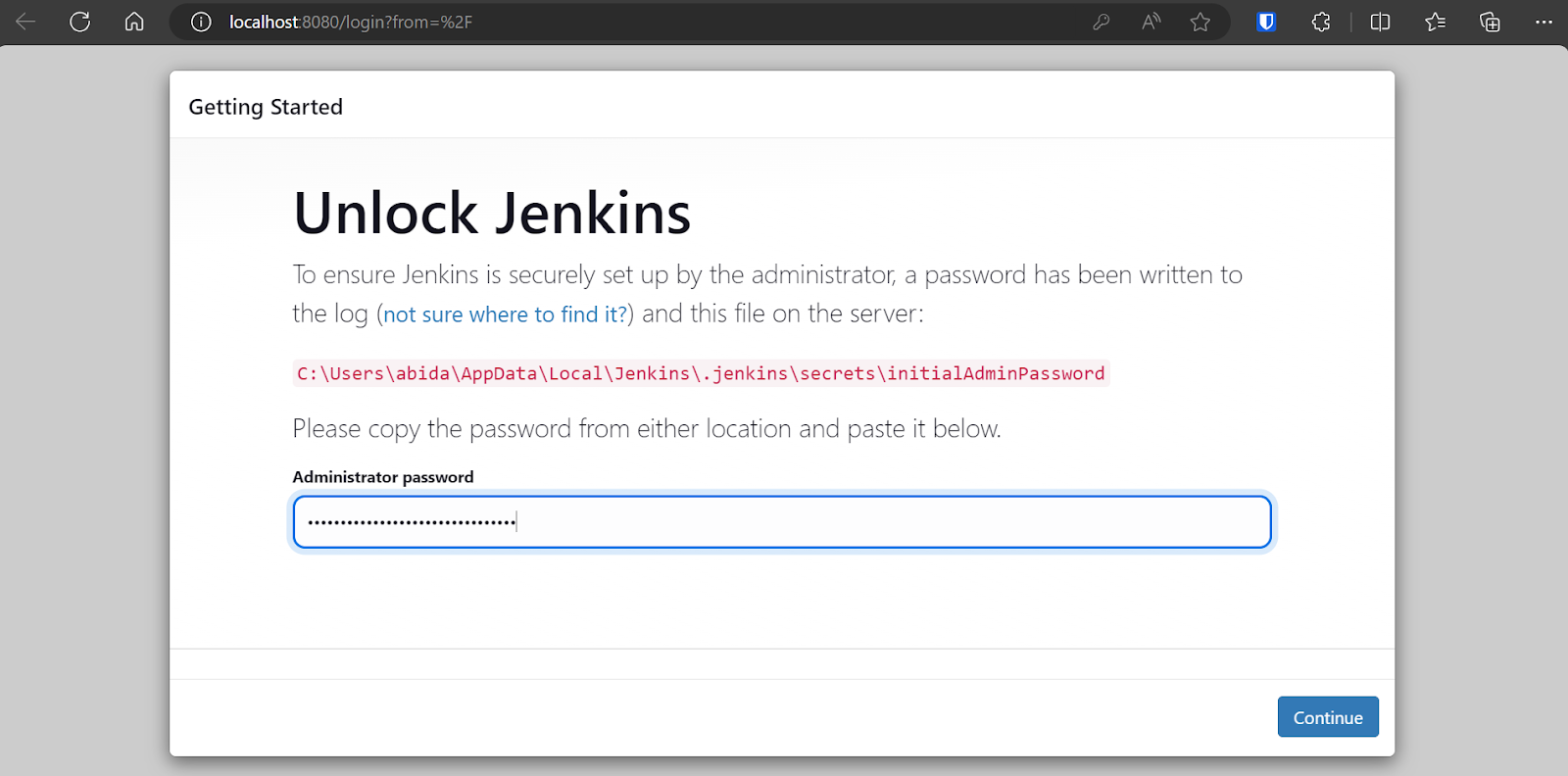
Por defecto, Jenkins se ejecuta en https://localhost:8080/. Sólo tienes que pegar esa URL en un navegador para acceder al panel de control. Para entrar en el panel de Jenkins, tienes que escribir la contraseña de administrador.
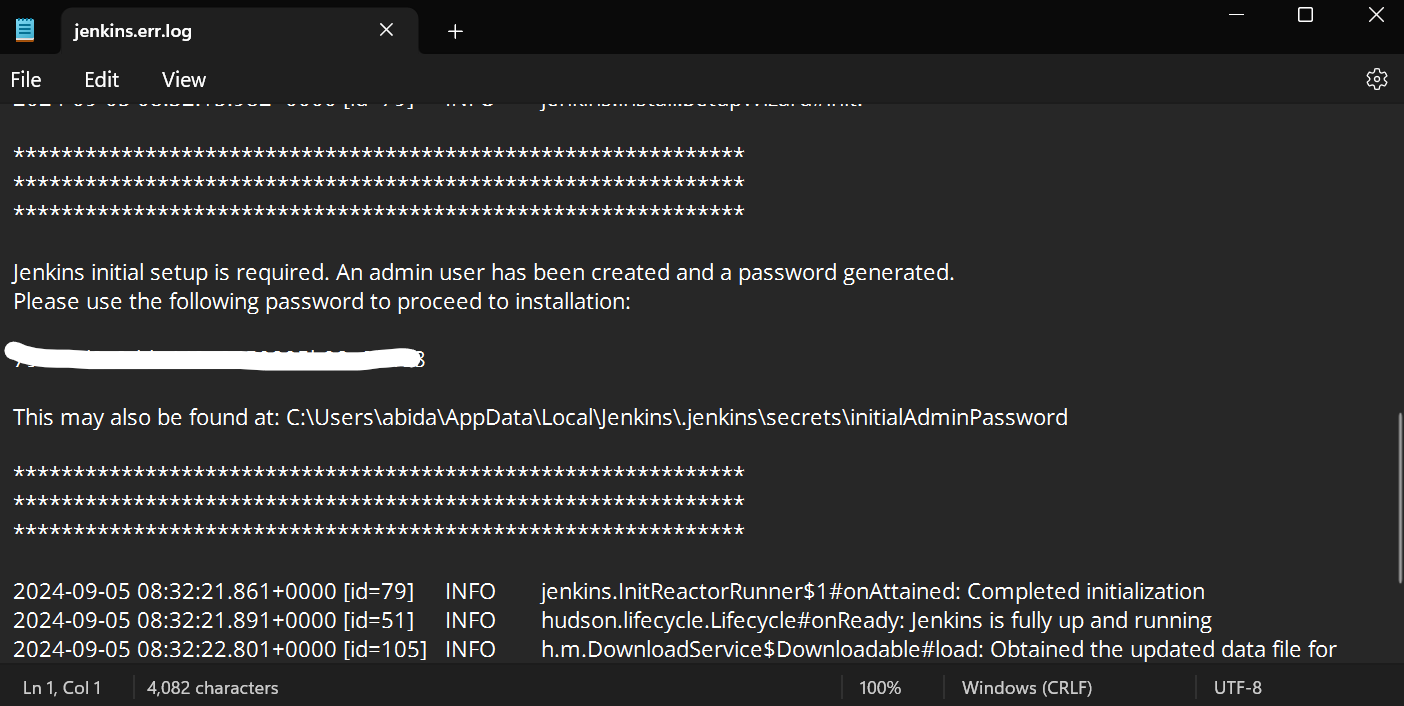
Para obtener la contraseña de administrador por defecto, navega hasta el directorio Jenkins y localiza y abre el archivo Jenkins.err.log.
Desplázate hacia abajo en el archivo de error Jenkins para encontrar la contraseña generada. Cópiala y pégala en la casilla de introducción de la contraseña de administrador.
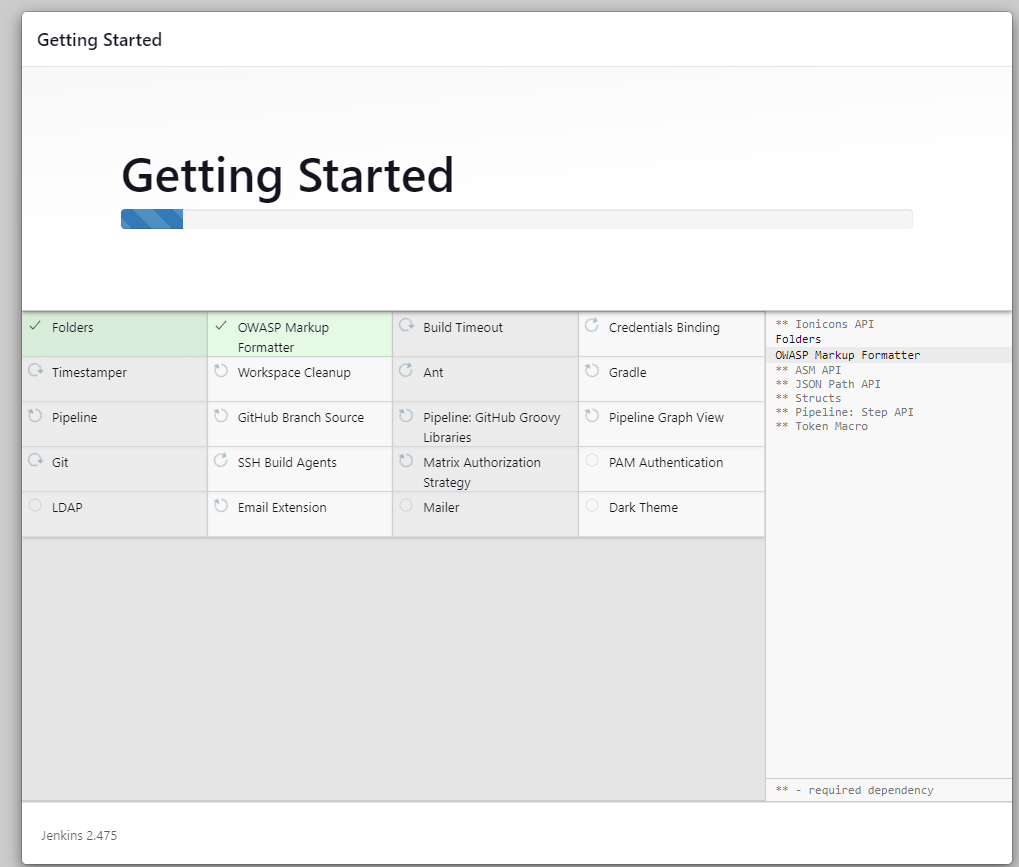
Después, el servidor tardará unos minutos en instalar las herramientas y extensiones necesarias.
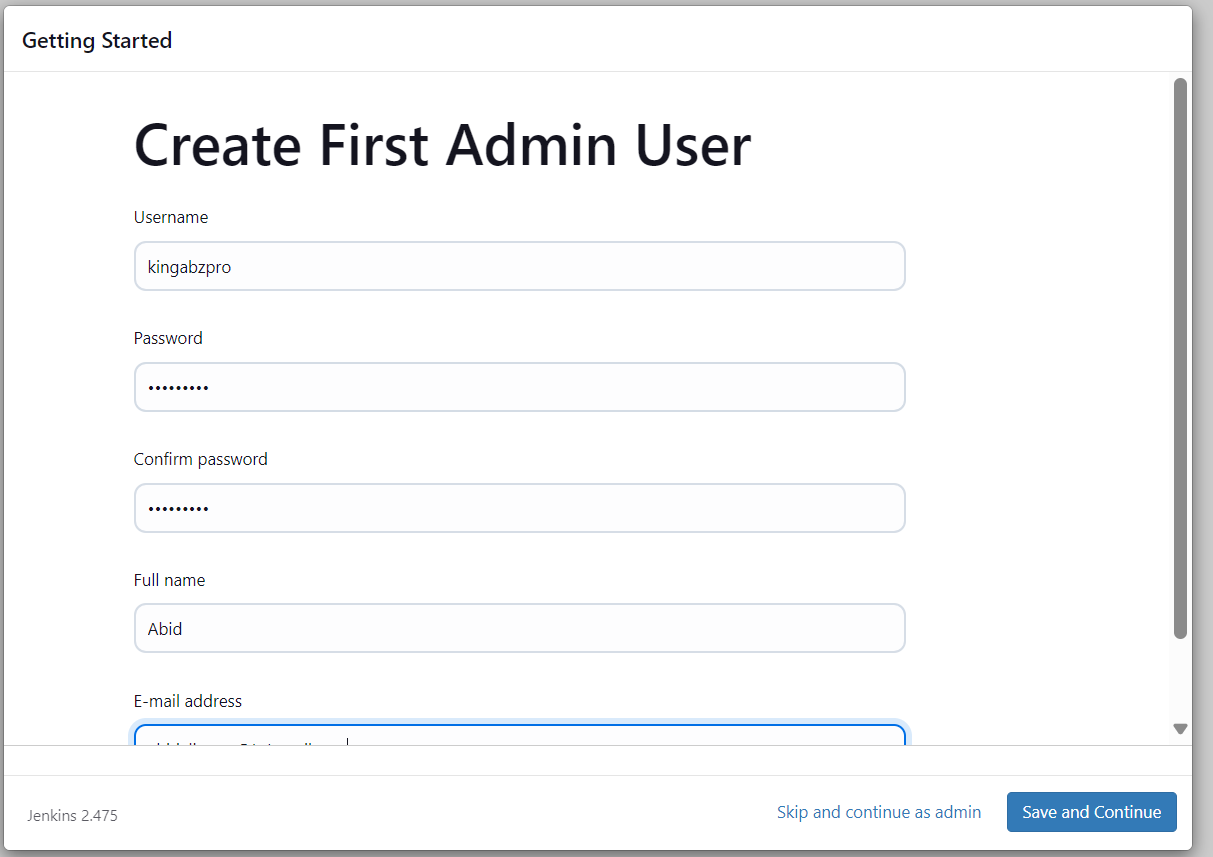
Una vez finalizada la configuración del servidor, nos pedirá que creemos un nuevo usuario. Introduce toda la información necesaria y pulsa el botón "Guardar y continuar".
Se nos dirigirá al panel de control, donde crearemos, veremos y ejecutaremos varias canalizaciones Jenkins.
Los agentes, también conocidos como nodos, son máquinas configuradas para ejecutar trabajos enviados por el servidor maestro Jenkins. Estos agentes proporcionan el entorno y el cálculo para ejecutar las canalizaciones. Un agente de Windows 11 está disponible por defecto, pero siempre podemos crear nuestro propio agente con opciones personalizadas.
En el panel principal, haz clic en la opción "Gestionar Jenkins" y luego en el botón "Configurar agente", como se muestra a continuación. También puedes hacer clic en el botón "Nodos" para crear y gestionar agentes.
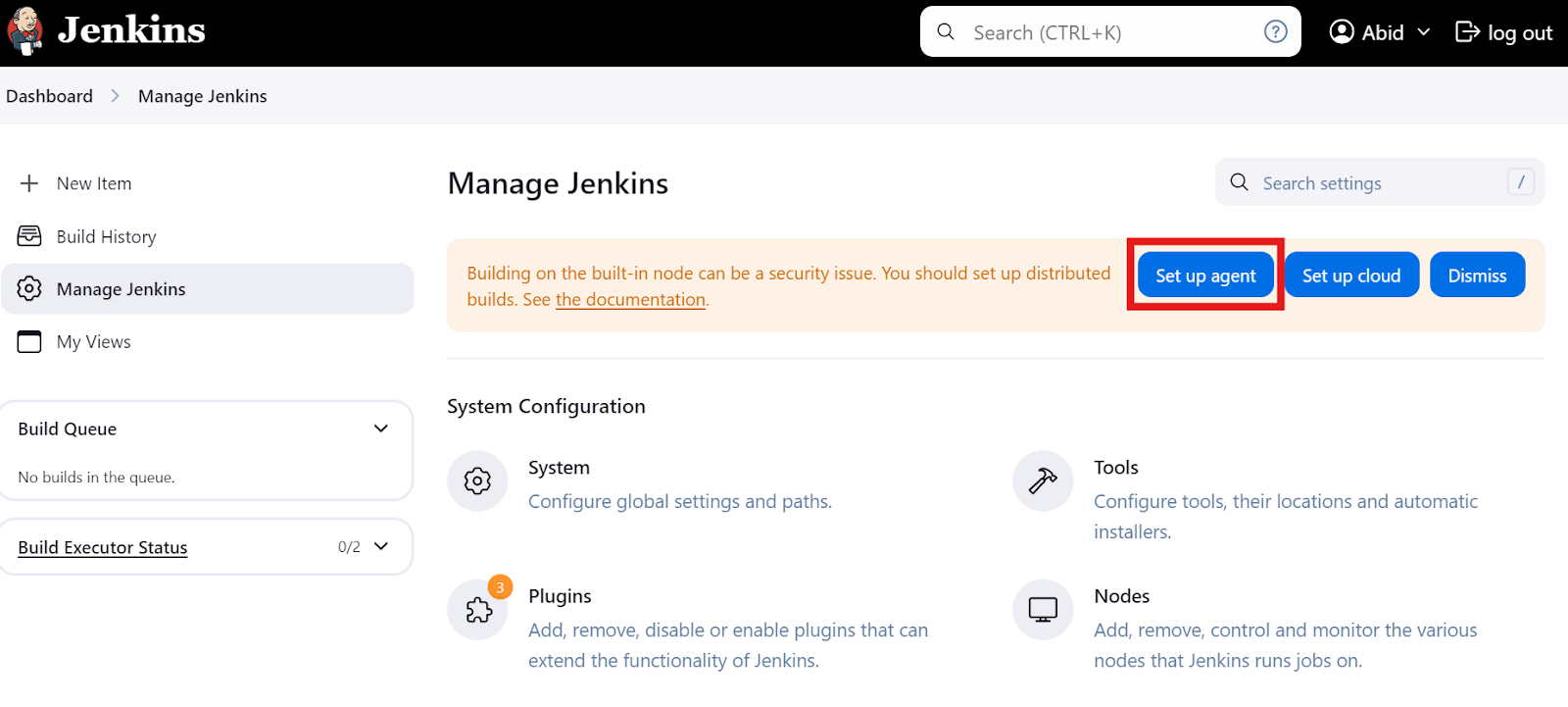
Escribe el nombre del agente y selecciona el tipo "Agente permanente".
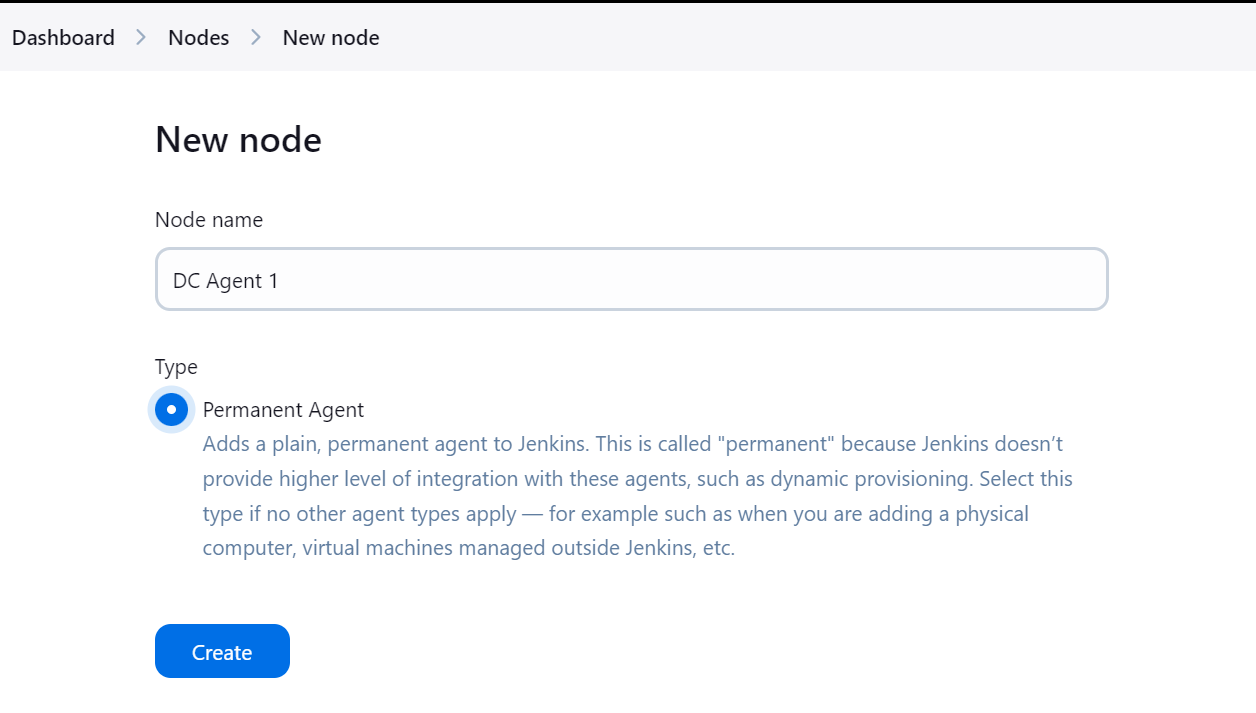
Asegúrate de proporcionar un directorio para el agente donde se guardarán todos los archivos y registros. Añade una etiqueta y mantén el resto de la configuración por defecto. Al crear la canalización, utilizaremos la etiqueta agente para ejecutar las tareas.
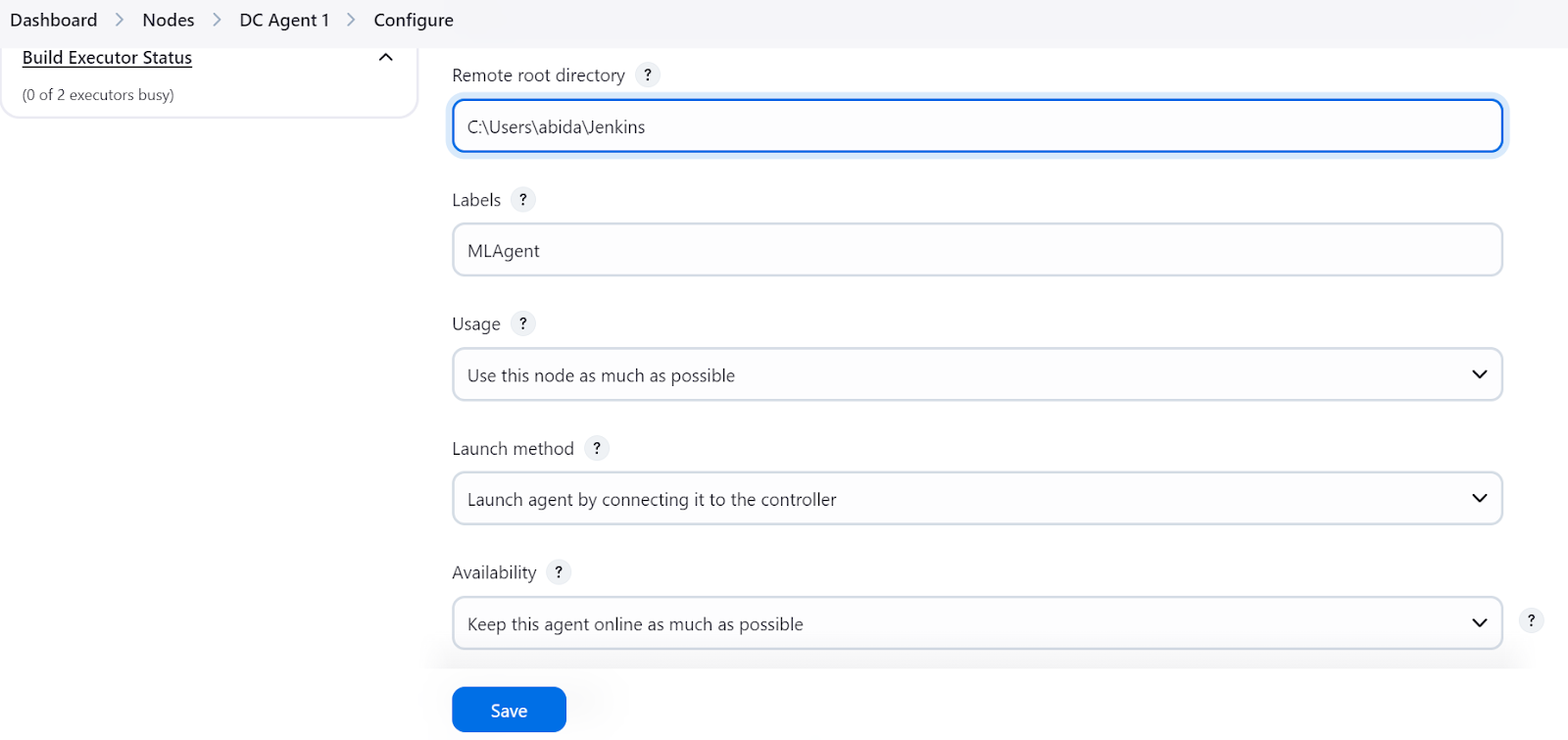
Al pulsar el botón "Guardar", aparecerá un aviso indicándonos que copiemos y peguemos el comando adecuado en el terminal en función de nuestro sistema operativo.
curl.exe -sO http://localhost:8080/jnlpJars/agent.jar & java -jar agent.jar -url http://localhost:8080/ -secret 1a30c62de92630dbcc1e2f19aaf482057e6170ced6835355447bc4ba4eefb76a -name "DC Agent 1" -webSocket -workDir "/home/Jenkins"Tras pegar y ejecutar el comando en el terminal, veremos un mensaje de éxito que indica que nuestro agente, en mi caso, DC Agent 1, se está ejecutando en segundo plano.
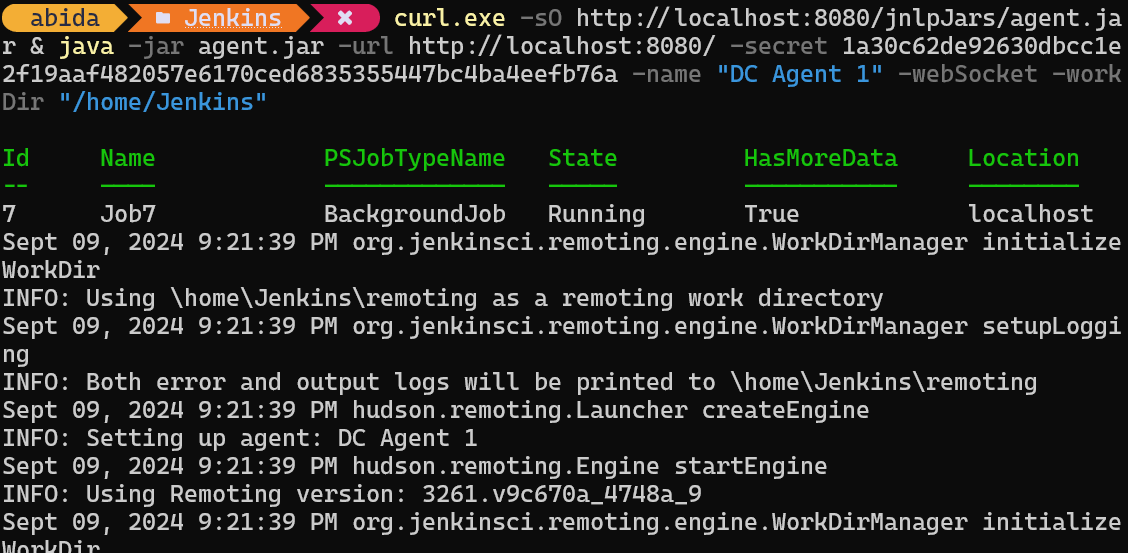
Para comprobar si el agente se está ejecutando y está listo para ejecutar un trabajo, navega al panel de Jenkins, haz clic en "Gestionar Jenkins" y, a continuación, haz clic en el botón "Nodos" para ver el estado del agente.
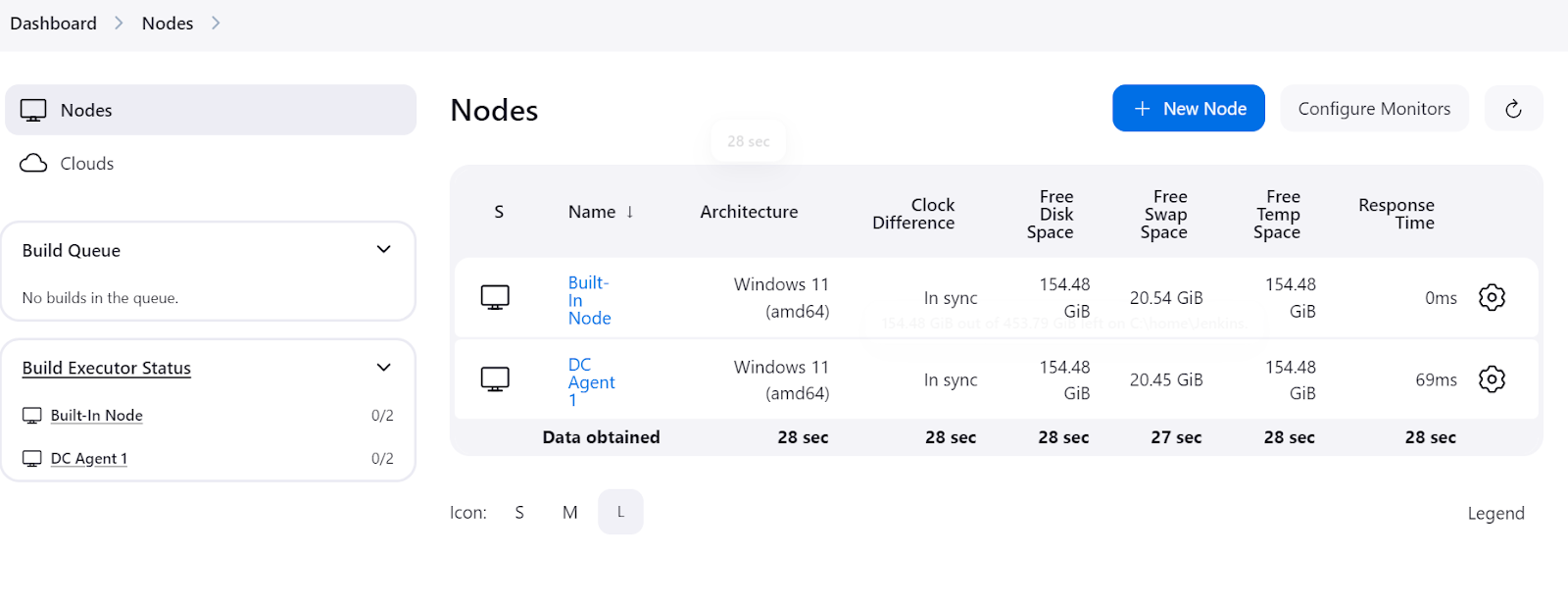
Una canalización Jenkins es una serie de pasos automatizados que ayudan a entrenar, evaluar y desplegar modelos. Define estos procesos mediante un sencillo script de programación, facilitando la gestión y automatización de los flujos de trabajo de los proyectos.
En esta sección, crearemos una canalización Jenkins de muestra y utilizaremos nuestro agente recién creado como ejecutor de la canalización.
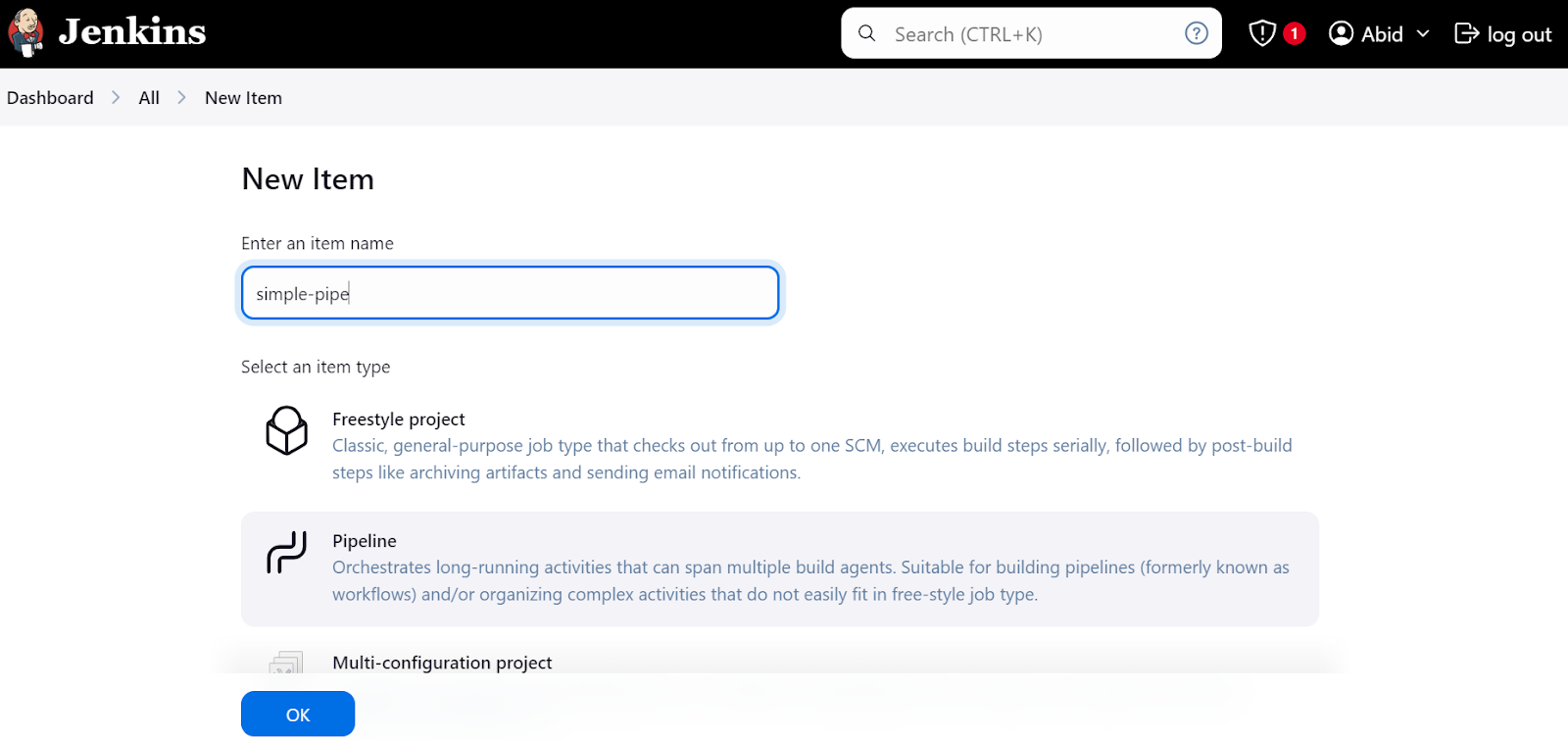
En el panel de control, haz clic en el botón "Nuevo elemento", escribe el nombre del elemento, selecciona la opción "Tubería" y haz clic en "Aceptar".
Después, un aviso nos pedirá que configuremos la tubería. Desplázate hacia abajo hasta la sección "Canalización", donde tenemos que escribir el script de canalización de Jenkins.
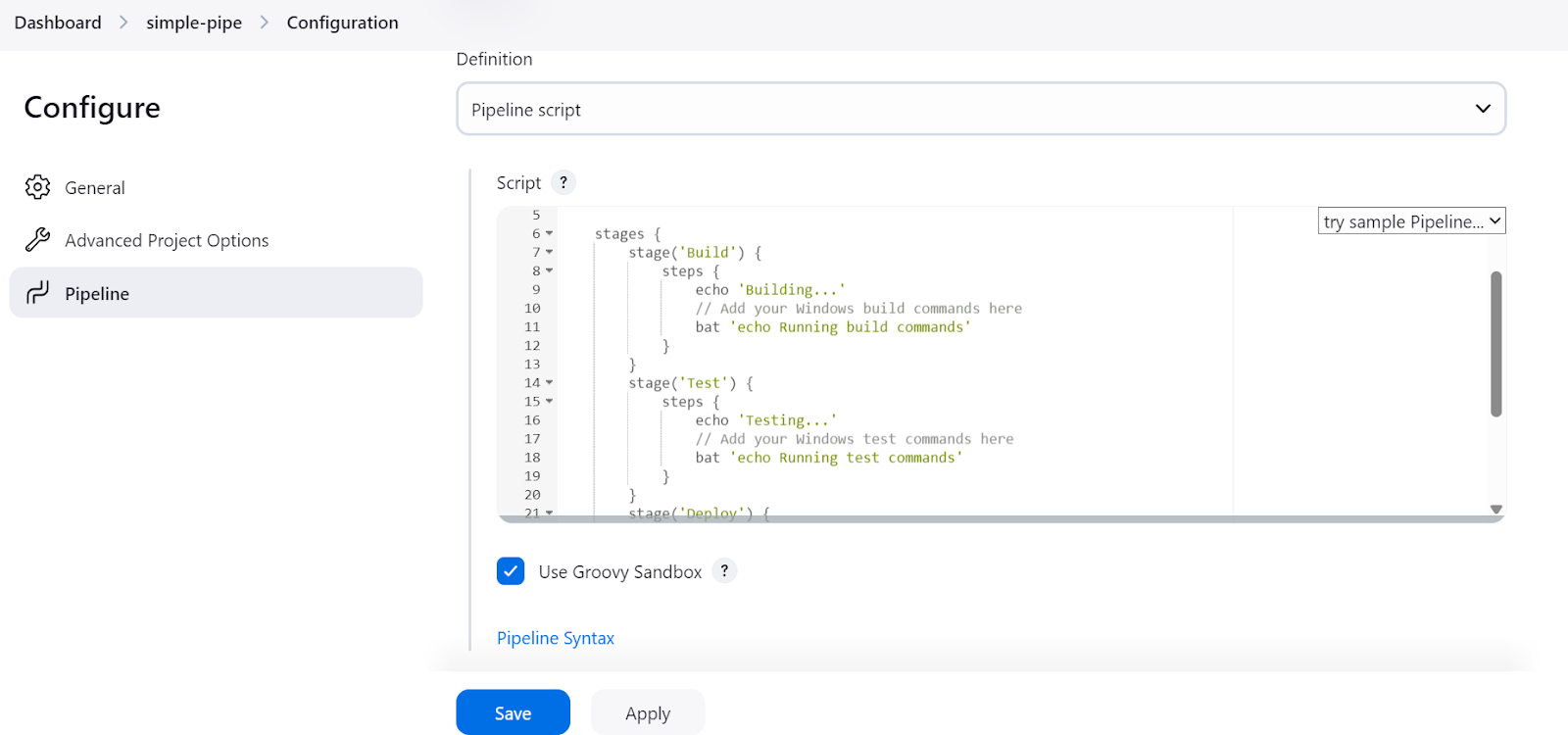
En el script del canal Jenkins, empezamos configurando el entorno y el agente. En nuestro caso, estamos configurando el agent proporcionándole la etiqueta del agente que hemos definido antes.
Después, escribiremos una sección stages en la que se añadirán los distintos pasos de la tubería (Build, Test, Deploy). En nuestro caso, sólo imprimimos utilizando el comando echo y ejecutamos los comandos del terminal utilizando el comando bat.
bat se utiliza para Windows 11sh es para LinuxYa está. Es así de sencillo. Aquí tienes el código del script:
pipeline {
agent {
label 'MLAgent' // Ensure this label matches your Windows 11 agent
}
stages {
stage('Build') {
steps {
echo 'Building...'
// Add your Windows build commands here
bat 'echo Running build commands'
}
}
stage('Test') {
steps {
echo 'Testing...'
// Add your Windows test commands here
bat 'echo Running test commands'
}
}
stage('Deploy') {
steps {
echo 'Deploying...'
// Add your Windows deploy commands here
bat 'echo Running deploy commands'
}
}
}
}Después de añadir el script, haz clic en los botones "Aplicar" y "Guardar".
Pulsa el botón "Construir ahora" para probar y ejecutar la canalización. Para ver su estado, haz clic en el botón "Estado".
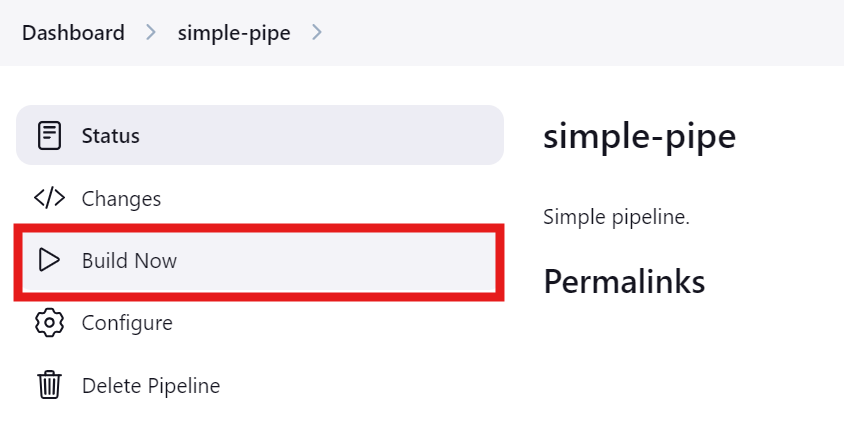
Una vez finalizada la ejecución, podemos ver los registros haciendo clic en la ejecución concreta en el menú "Estado".
Haz clic en el enlace "Última compilación (nº 2)" y luego en el botón "Salida de la consola". Esto nos llevará a la ventana de salida de la consola, donde podemos encontrar los registros y resultados de la tubería.
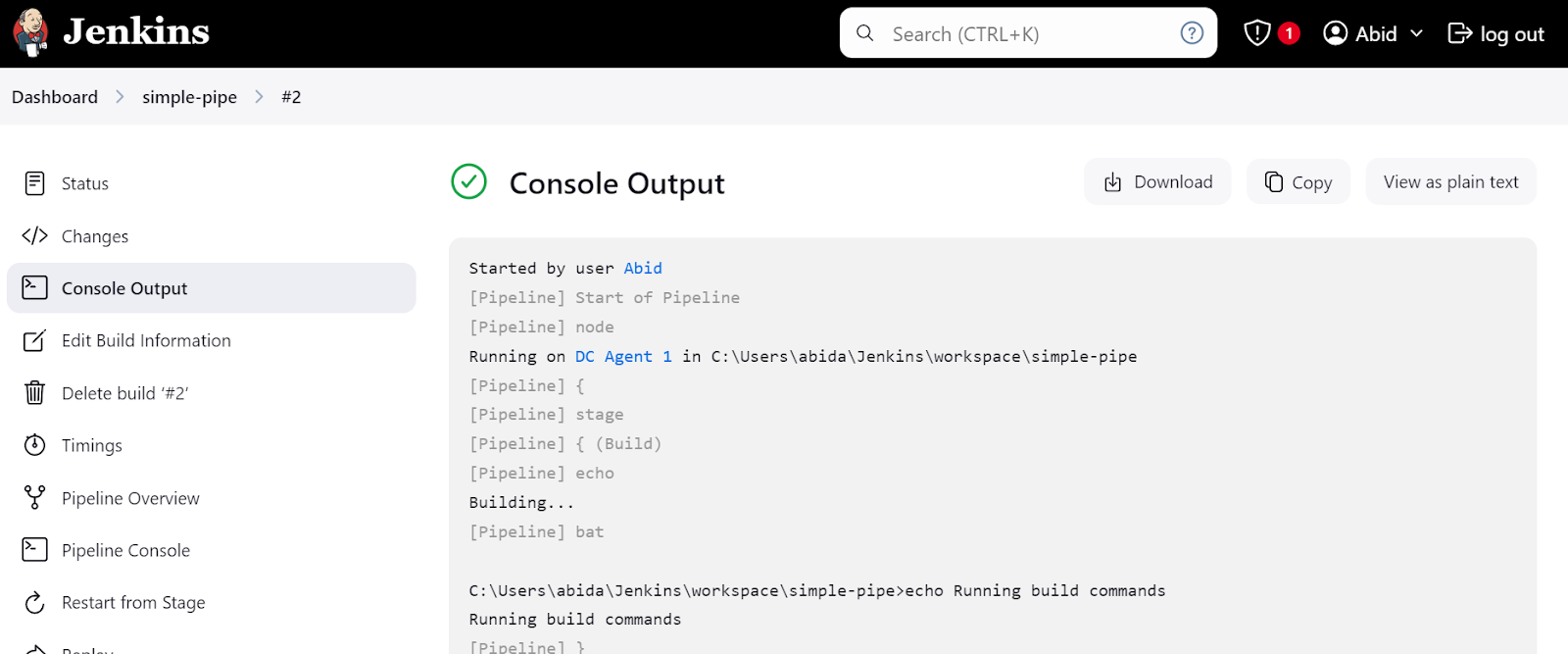
Incluso podemos hacer clic en el botón "Consola de la tubería" para ver en detalle cada paso de la tubería. Esto incluye la salida, el tiempo que tardó en empezar y terminar, los comandos de la tubería y los registros.
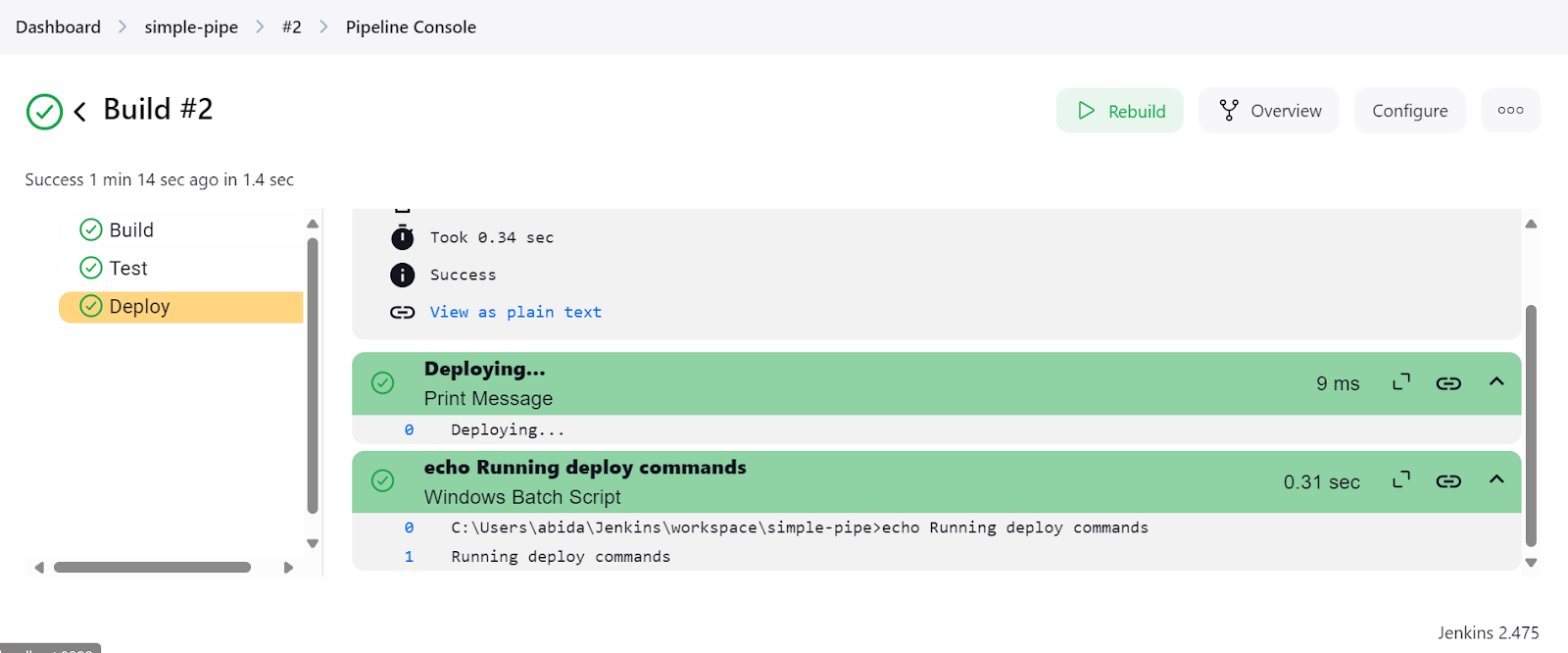
Tras completar la configuración de la instalación de Jenkins, crear y ejecutar canalizaciones fue fácil y rápido. Tardé menos de una hora en entender el guión y cómo crear el mío propio. Utilizaré Jenkins en lugar de GitHub Actions porque me ofrece más flexibilidad.
Author's opinion
Tras la introducción inicial a Jenkins, ha llegado el momento de ponernos serios y trabajar en el proyecto MLOps.
Crearemos dos tuberías: El primer pipeline será CI, que cargará y procesará los datos, entrenará el modelo, evaluará el modelo y luego probará el servidor del modelo. Después, iniciará la canalización de CD, poniendo en marcha el servidor de inferencia de modelos.
Para comprender el proceso en detalle, sigue el curso CI/CD para Aprendizaje Automático, que te enseña a agilizar los procesos de desarrollo del aprendizaje automático.
Como en cualquier proyecto, tenemos que crear los archivos del proyecto, incluidos los archivos Python de carga de datos, entrenamiento del modelo, evaluación del modelo y servicio del modelo. También necesitamos un archivo requirements .txt para instalar los paquetes de Python necesarios.
En este script, cargaremos un conjunto de datos de scikit-learn llamado conjunto de datos Vino y lo convertiremos en un DataFrame de pandas. A continuación, dividiremos el conjunto de datos en conjuntos de entrenamiento y conjuntos de prueba. Por último, guardaremos los datos procesados como un archivo pickle.
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
import joblib
def load_data():
# Load the wine dataset
wine = load_wine(as_frame=True)
data = pd.DataFrame(data=wine.data, columns=wine.feature_names)
data["target"] = wine.target
print(data.head())
return data
def split_data(data, target_column="target"):
X = data.drop(columns=[target_column])
y = data[target_column]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test
def save_preprocessed_data(X_train, X_test, y_train, y_test, file_path):
joblib.dump((X_train, X_test, y_train, y_test), file_path)
if __name__ == "__main__":
data = load_data()
X_train, X_test, y_train, y_test = split_data(data)
save_preprocessed_data(X_train, X_test, y_train, y_test, "preprocessed_data.pkl")En este archivo, cargaremos los datos procesados, entrenaremos un clasificador de bosque aleatorio y guardaremos el modelo como un archivo pickle.
from sklearn.ensemble import RandomForestClassifier
import joblib
def load_preprocessed_data(file_path):
return joblib.load(file_path)
def train_model(X_train, y_train):
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
return model
def save_model(model, file_path):
joblib.dump(model, file_path)
if __name__ == "__main__":
X_train, X_test, y_train, y_test = load_preprocessed_data("preprocessed_data.pkl")
model = train_model(X_train, y_train)
save_model(model, "model.pkl")Para evaluar el modelo, cargaremos tanto el modelo como el conjunto de datos preprocesados, generaremos un informe de clasificación e imprimiremos la puntuación de precisión.
import joblib
from sklearn.metrics import accuracy_score, classification_report
def load_model(file_path):
return joblib.load(file_path)
def load_preprocessed_data(file_path):
return joblib.load(file_path)
def evaluate_model(model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return accuracy, report
if __name__ == "__main__":
X_train, X_test, y_train, y_test = load_preprocessed_data("preprocessed_data.pkl")
model = load_model("model.pkl")
accuracy, report = evaluate_model(model, X_test, y_test)
print(f"Model Accuracy: {accuracy}")
print(f"Classification Report:\n{report}")Para servir el modelo, utilizaremos FastAPI para crear una API REST en la que los usuarios puedan introducir características y generar predicciones. Normalmente, las etiquetas son genéricas. Para hacer las cosas más interesantes, cambiaremos las categorías de vino a Verdante, Rubresco y Floralis.
Cuando ejecutamos este archivo, lanzamos el servidor FastAPI, al que podemos acceder mediante el comando curl o utilizando la biblioteca requests en Python.
from typing import List
import joblib
import uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
# Define the labels corresponding to the target classes
LABELS = [
"Verdante", # A vibrant and fresh wine, inspired by its balanced acidity and crisp flavors.
"Rubresco", # A rich and robust wine, named for its deep, ruby color and bold taste profile.
"Floralis", # A fragrant and elegant wine, known for its floral notes and smooth finish.
]
class Features(BaseModel):
features: List[float]
def load_model(file_path):
return joblib.load(file_path)
model = load_model("model.pkl")
@app.post("/predict")
def predict(features: Features):
# Get the numerical prediction
prediction_index = model.predict([features.features])[0]
# Map the numerical prediction to the label
prediction_label = LABELS[prediction_index]
return {"prediction": prediction_label}
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=9000)Este archivo nos ayudará a descargar e instalar todos los paquetes necesarios para ejecutar los archivos Python anteriores.
scikit-learn
pandas
fastapi
uvicornAhora crearemos canalizaciones Jenkins de integración continua. Al igual que creamos una tubería sencilla, crearemos una "tubería MLOps" y escribiremos el guión que abarca desde el procesamiento de datos hasta la evaluación del modelo.
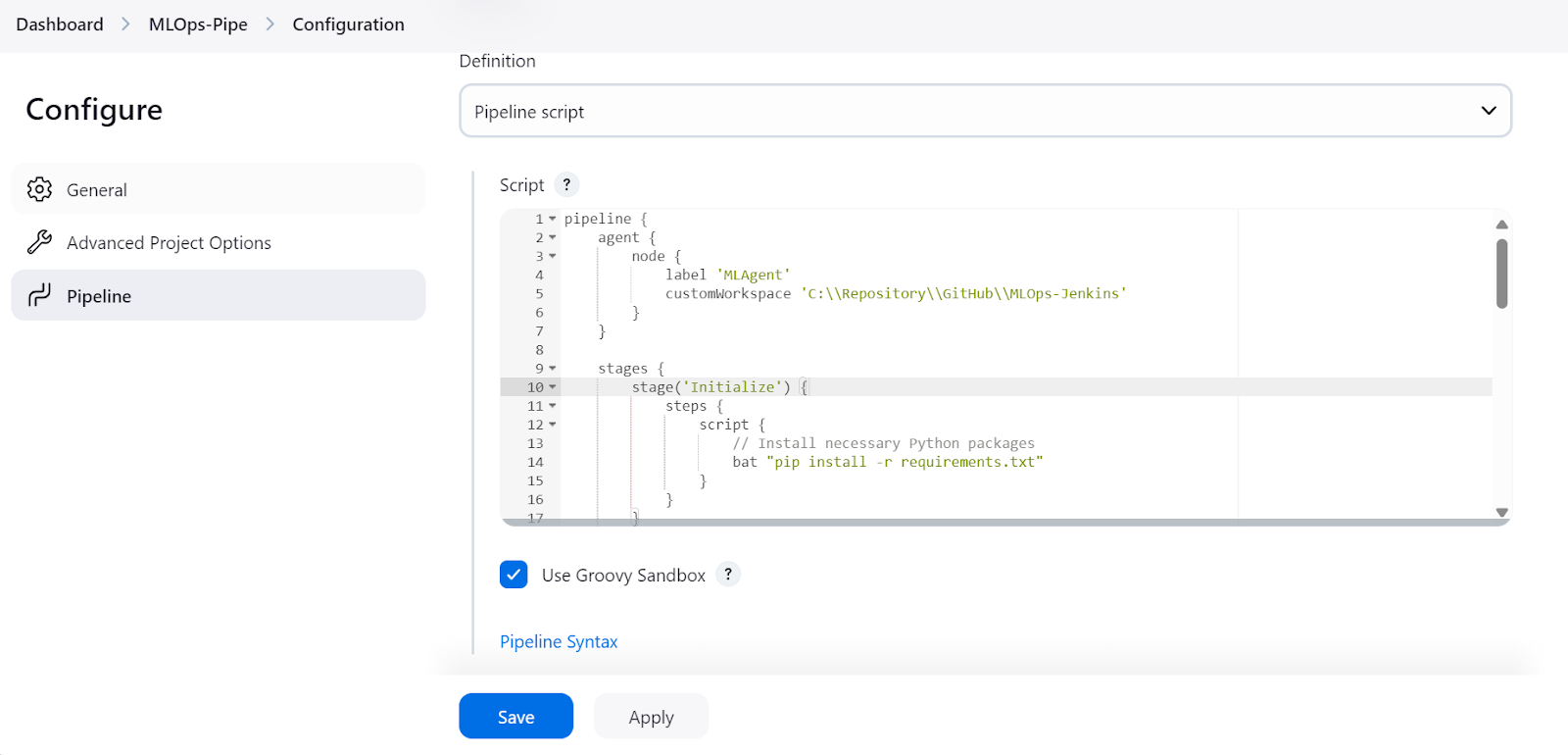
El guión del conducto MLOps consta de:
agent con el label "MLAgent".Initialize).Load and Preprocess Data).Train Model).Evaluate Model).curl (Test Serve Model ).Nota: El comando start /B lanza una nueva ventana de terminal en segundo plano y ejecuta el script de servicio al modelo. Además, este script de canalización Jenkins sólo funcionará en Windows, y tendremos que cambiar los comandos para Linux u otros sistemas operativos.
pipeline {
agent {
node {
label 'MLAgent'
customWorkspace 'C:\\Repository\\GitHub\\MLOps-Jenkins'
}
}
stages {
stage('Initialize') {
steps {
script {
// Install necessary Python packages
bat "pip install -r requirements.txt"
}
}
}
stage('Load and Preprocess Data') {
steps {
script {
// Run data loading script
bat "python data_loading.py"
}
}
}
stage('Train Model') {
steps {
script {
// Run model training script
bat "python model_training.py"
}
}
}
stage('Evaluate Model') {
steps {
script {
// Run model evaluation script
bat "python model_evaluation.py"
}
}
}
stage('Serve Model') {
steps {
script {
// Start FastAPI server in the background
bat 'start /B python model_serving.py'
// Wait for the server to start
sleep time: 10, unit: 'SECONDS'
}
}
}
stage('Test Serve Model') {
steps {
script {
// Test the server with sample values
bat '''
curl -X POST "http://127.0.0.1:9000/predict" ^
-H "Content-Type: application/json" ^
-d "{\\"features\\": [13.2, 2.77, 2.51, 18.5, 103.0, 1.15, 2.61, 0.26, 1.46, 3.0, 1.05, 3.33, 820.0]}"
'''
}
}
}
stage('Deploy Model') {
steps {
script {
// Trigger another Jenkins job for model serving
build job: 'ModelServingPipeline', wait: false
}
}
}
}
post {
always {
archiveArtifacts artifacts: '**.pkl', fingerprint: true
echo 'Pipeline execution complete.'
}
}
}Ahora, crearemos una canalización de despliegue continuo para desplegar y ejecutar el servidor localmente.
El guión de la tubería es sencillo. Comenzamos definiendo el agente y cambiando el directorio de trabajo a nuestro proyecto. Después, hacemos funcionar el servidor indefinidamente.
Nota: No se recomienda ejecutar un servidor en Jenkins indefinidamente, ya que los pipelines deben tener un inicio y un final definidos. Para este ejemplo, supondremos que hemos desplegado la aplicación, pero en la práctica, es mejor integrar Docker y ejecutar la aplicación en un servidor Docker.
Si te interesa aprender a pensar como un ingeniero de aprendizaje automático, considera la posibilidad de realizar el curso Desarrollo de modelos de aprendizaje automático para producción con una mentalidad MLOps, que te permitirá entrenar, documentar, mantener y escalar tus modelos de aprendizaje automático hasta su máximo potencial.
pipeline {
agent {
node {
label 'MLAgent'
customWorkspace 'C:/Repository/GitHub/MLOps-Jenkins/'
}
}
stages {
stage('Start FastAPI Server') {
steps {
script {
// Start the FastAPI server
bat 'python model_serving.py'
}
}
}
}
}Ve a la canalización "MLOps-pipe" y haz clic en el botón "Construir ahora" para iniciar la canalización CI/CD.
Una vez que el pipeline se ejecuta correctamente, genera dos artefactos: uno para el modelo y otro para el conjunto de datos procesado.
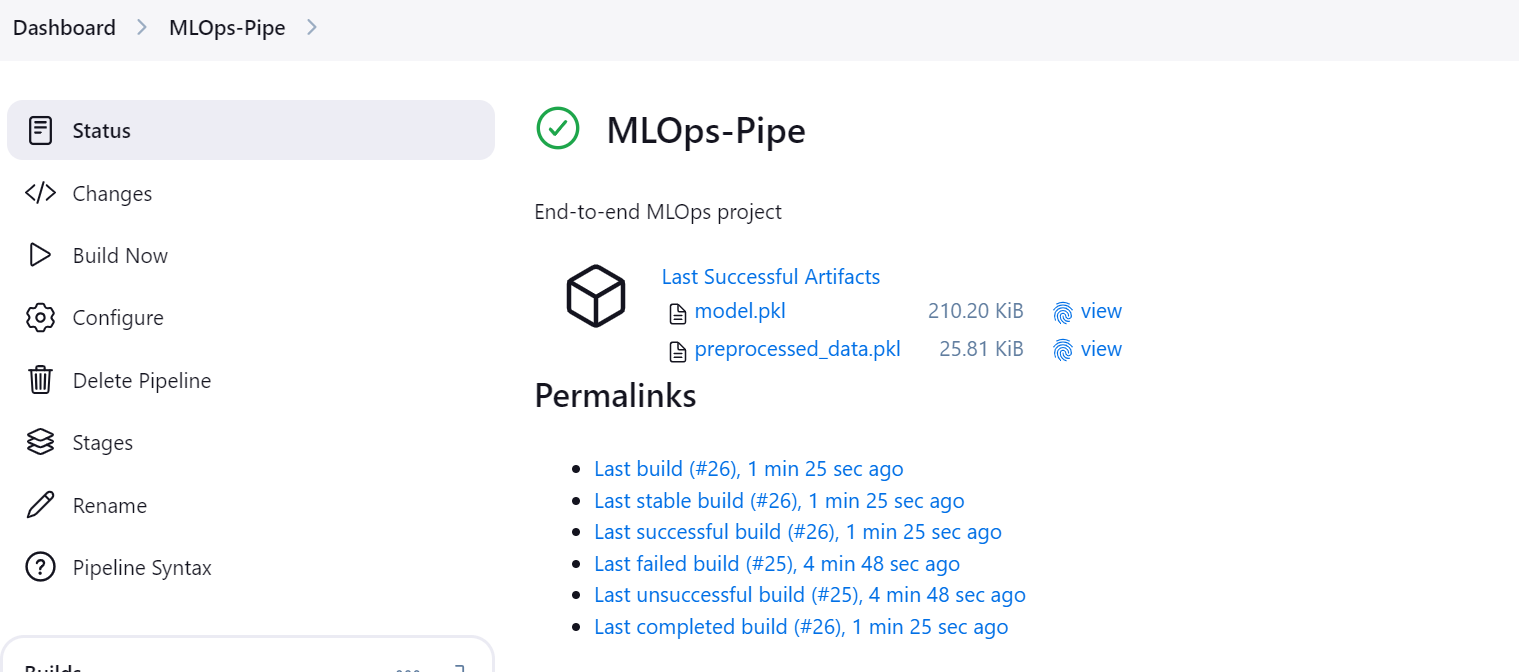
Haz clic en el botón "Etapas" del panel de Jenkins para visualizar el pipeline y ver todas las etapas.
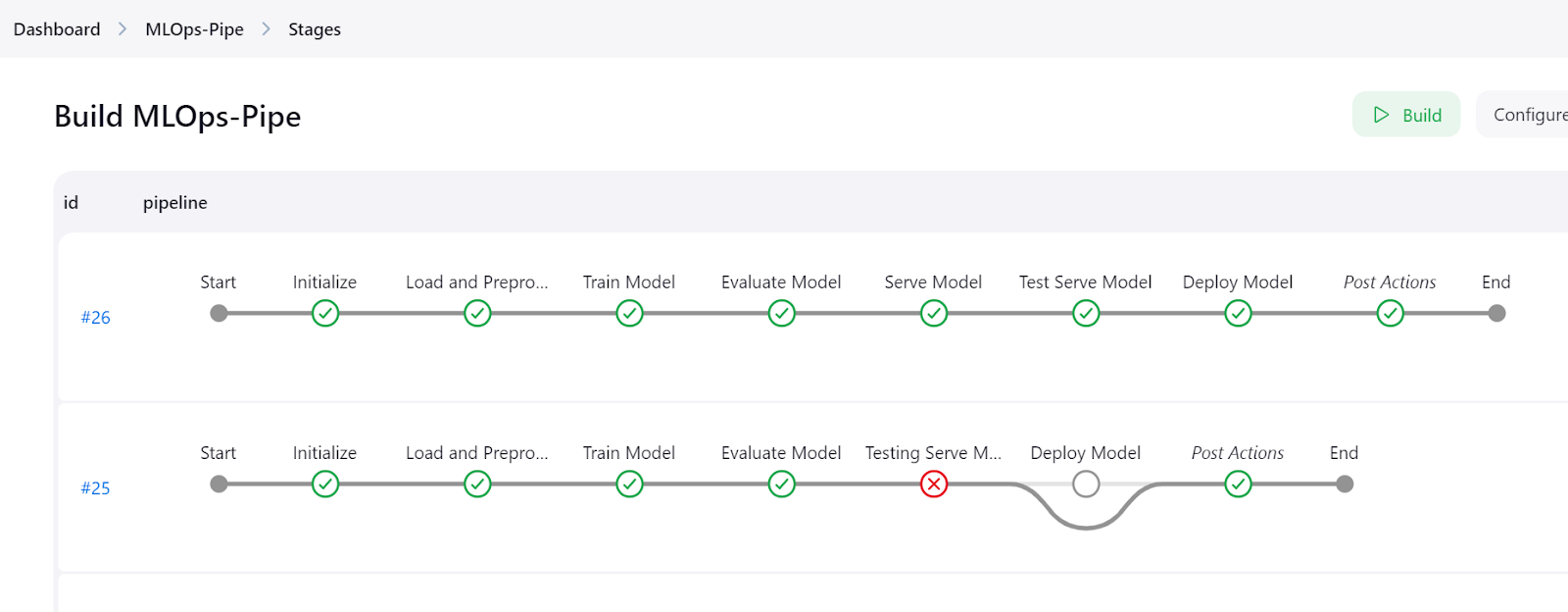
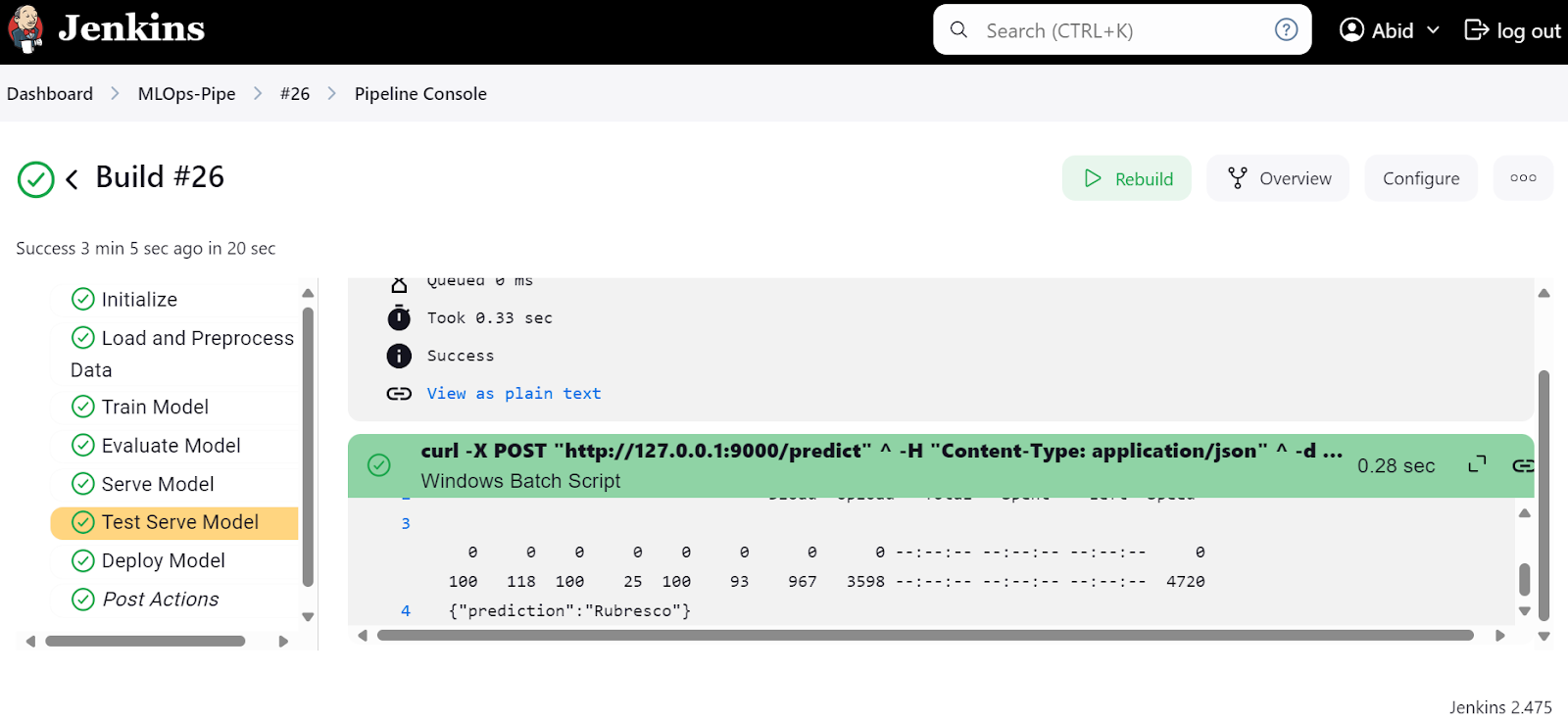
Para ver los registros detallados de cada paso, consulta el menú "Consola de tuberías".
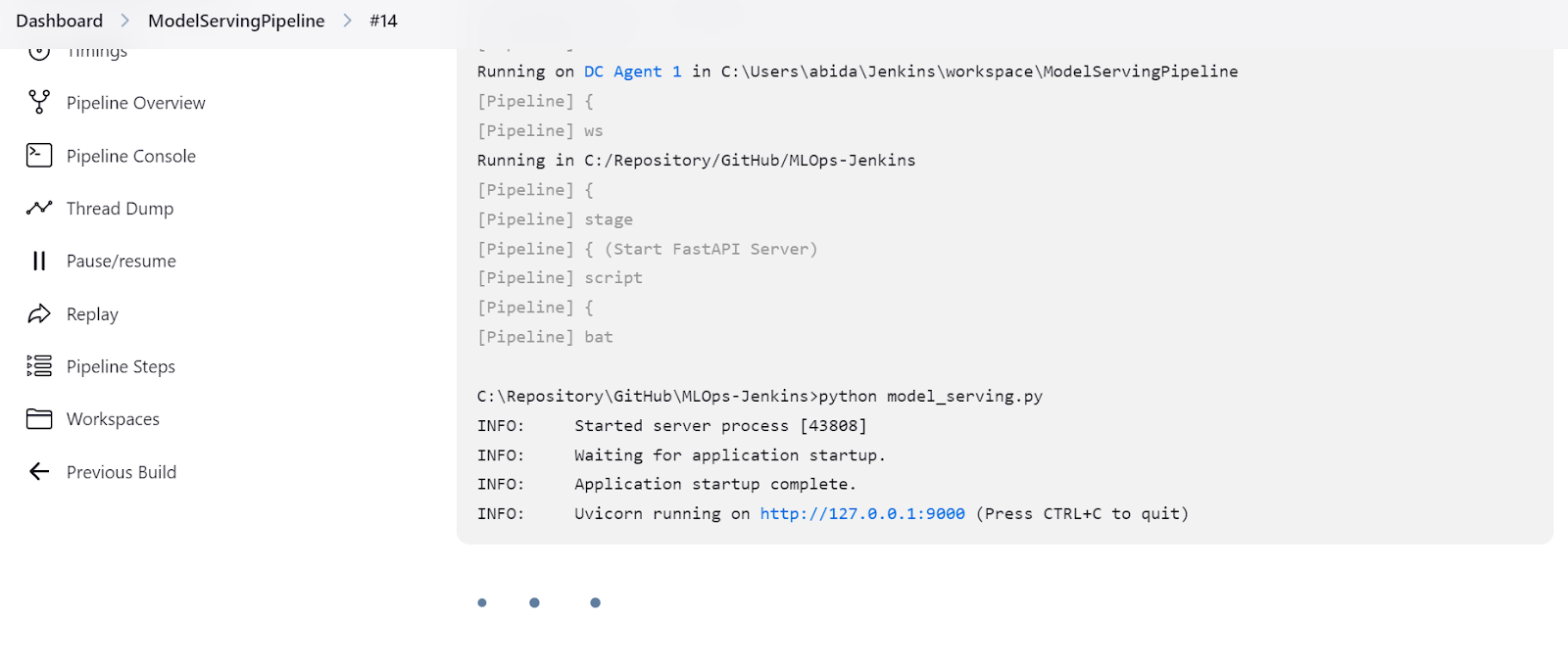
También podemos comprobar el "ModelServingPipeline" para verificar que nuestro servidor se está ejecutando en la URL local http://127.0.0.1:9000.
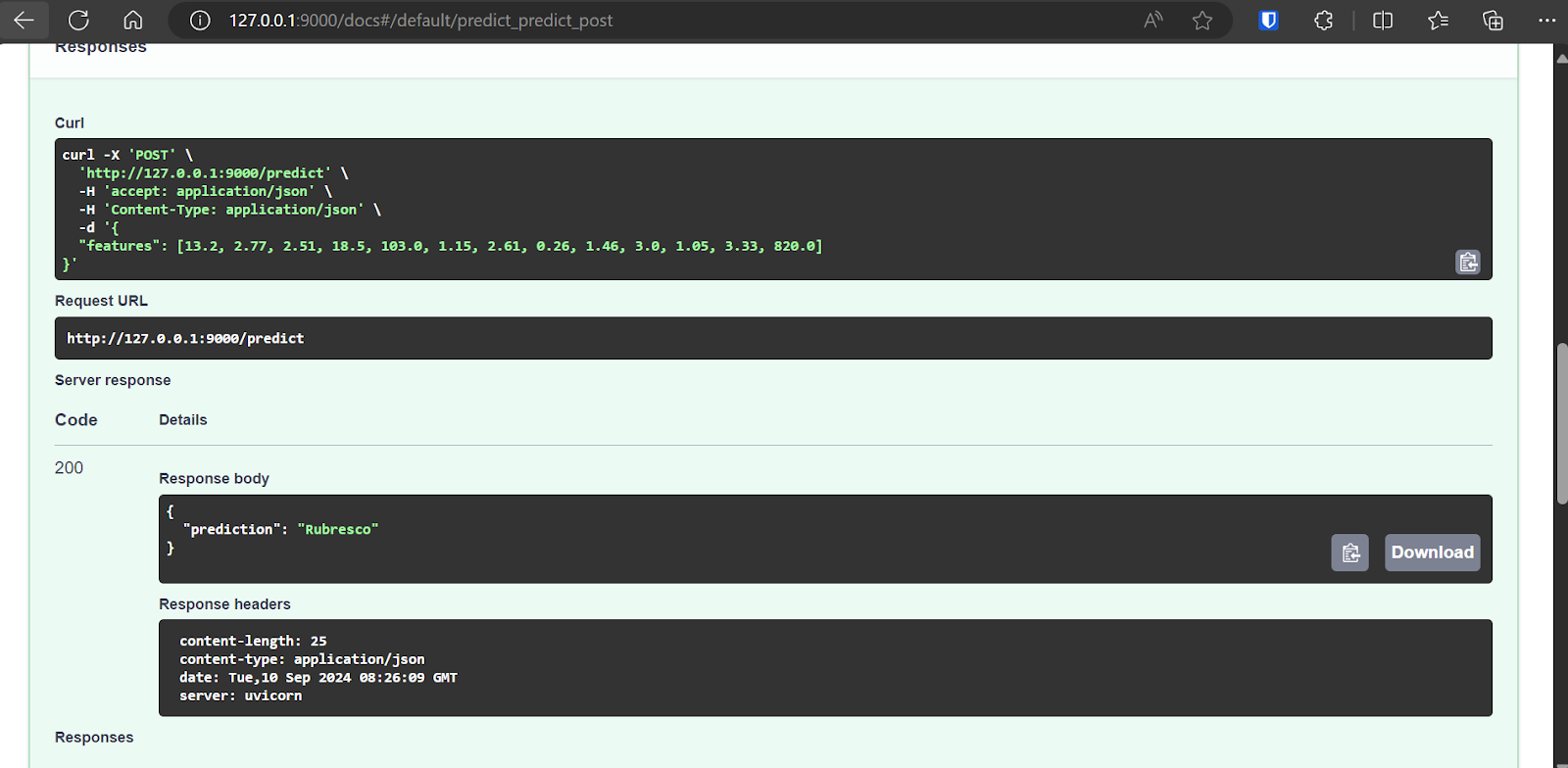
La FastAPI viene con Swagger UI, a la que se puede acceder añadiendo /docs a la URL local: http://127.0.0.1:9000/docs.
La Swagger UI nos permite probar la aplicación FastAPI en el navegador. Es sencillo, y podemos ver que nuestro servidor modelo funciona correctamente. Los valores predichos de la muestra sugieren que el tipo de vino es Rubresco.
Asegúrate siempre de apagar el servidor modelo cuando hayas terminado de experimentar. Puedes hacerlo yendo al menú "Estado" del panel de control de Jenkins y haciendo clic en el botón de la cruz, como se muestra a continuación:
Todo el código, los conjuntos de datos, los modelos y los metaficheros de este tutorial están disponibles en el repositorio de GitHub para que puedas try: kingabzpro/MLOps-with-Jenkins.
Jenkins es un gran servidor de automatización para todo tipo de tareas MLOps. Destaca como una excelente alternativa a las Acciones de GitHub al ofrecer más funciones, un mayor control y una privacidad mejorada.
Uno de los aspectos más atractivos de Jenkins es su sencillez a la hora de crear y ejecutar canalizaciones, lo que lo hace accesible tanto para principiantes como para usuarios experimentados.
Si te interesa explorar capacidades similares utilizando las Acciones de GitHub, no te pierdas el tutorial Guía para principiantes sobre CI/CD para el aprendizaje automático. Para quienes deseen profundizar en el conocimiento de los MLOps, el curso MLOps Totalmente Automatizados es un recurso fantástico. Ofrece una visión completa de la arquitectura MLOps, las técnicas CI/CD/CM/CT y los patrones de automatización para desplegar sistemas ML que puedan aportar valor de forma consistente a lo largo del tiempo.
¡Aprende más sobre MLOps con estos cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
Tutorial
DataCamp Team
Tutorial
Bex Tuychiev
Tutorial
Olivia Smith
Tutorial
Abid Ali Awan