
Curso
Conceitos de MLOps
2 h
42.6K

Neste tutorial, você aprenderá a instalar e usar o Jenkins, bem como a criar agentes e pipelines e a executá-los.
Especificamente, nós iremos:
Se você precisa aprimorar seus conhecimentos, faça um curso curto e direto de Conceitos de MLOps para saber como transformar modelos de aprendizado de máquina de notebooks Jupyter em modelos funcionais em produção que geram valor comercial real.
O Jenkins é um servidor de automação de código aberto que desempenha uma função importante no processo de desenvolvimento de aprendizado de máquina, facilitando a integração contínua (CI) e a implantação contínua (CD).
Escrito em Java, o Jenkins ajuda a automatizar o processamento de dados, o treinamento, a avaliação e a implantação de projetos de aprendizado de máquina, tornando-o uma ferramenta essencial para as práticas de MLOps.
Recursos do Jenkins:
A automação de tarefas usando o Jenkins é apenas uma parte do ecossistema de MLOps. Você pode saber mais sobre outras tarefas lendo o blog 25 Top MLOps Tools You Need to Know in 2024. Ele consiste em ferramentas para rastreamento de experimentos, gerenciamento de metadados de modelos, orquestração de fluxo de trabalho, controle de versão de dados e pipeline, implantação de modelos e monitoramento de serviços e modelos na produção.
Você pode instalar facilmente o Jenkins no Linux e no macOS. No entanto, a instalação no Windows requer várias etapas. Essas etapas incluem a instalação do Java Development Kit, a configuração da política de segurança local, a instalação do Jenkins com um usuário de domínio e a inicialização do servidor Jenkins.
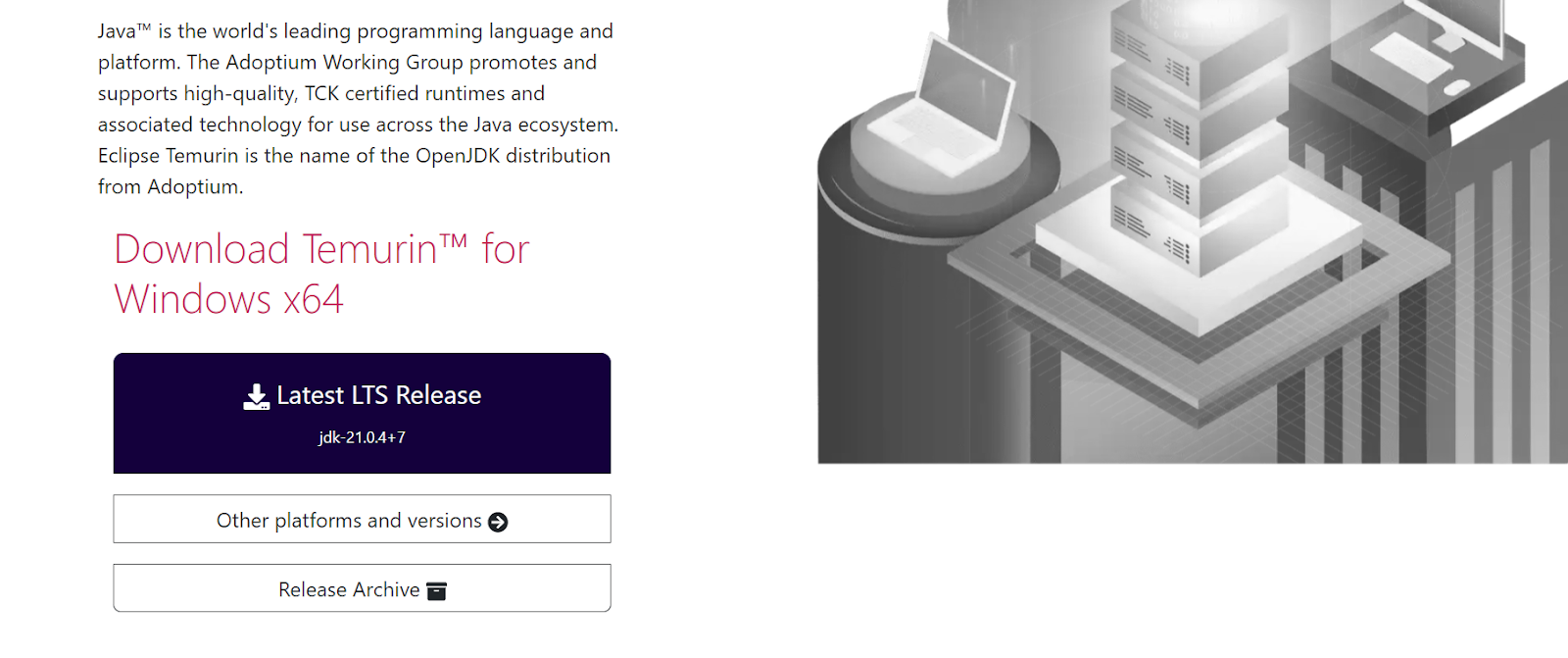
Vamos começar instalando o Java. Você precisa acessar o site da Adoptium e fazer o download da versão mais recente do LTS para o Windows 11.
Por que precisamos instalar o OpenJDK? O Jenkins é um aplicativo baseado em Java que requer um Java Runtime Environment (JRE) ou Java Development Kit (JDK) para ser executado.
Fonte da imagem: Adoção
Instale o OpenJDK com os valores padrão, exceto que você precisa marcar a opção "Set or override JAVA_HOME variable" (Definir ou substituir a variável JAVA_HOME).
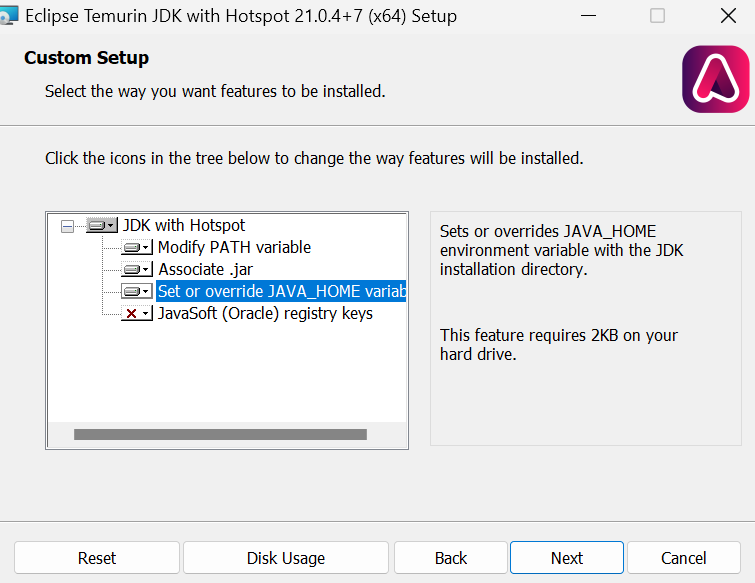
Após a conclusão da instalação, podemos verificar se ela foi instalada corretamente digitando java -version na janela do terminal:
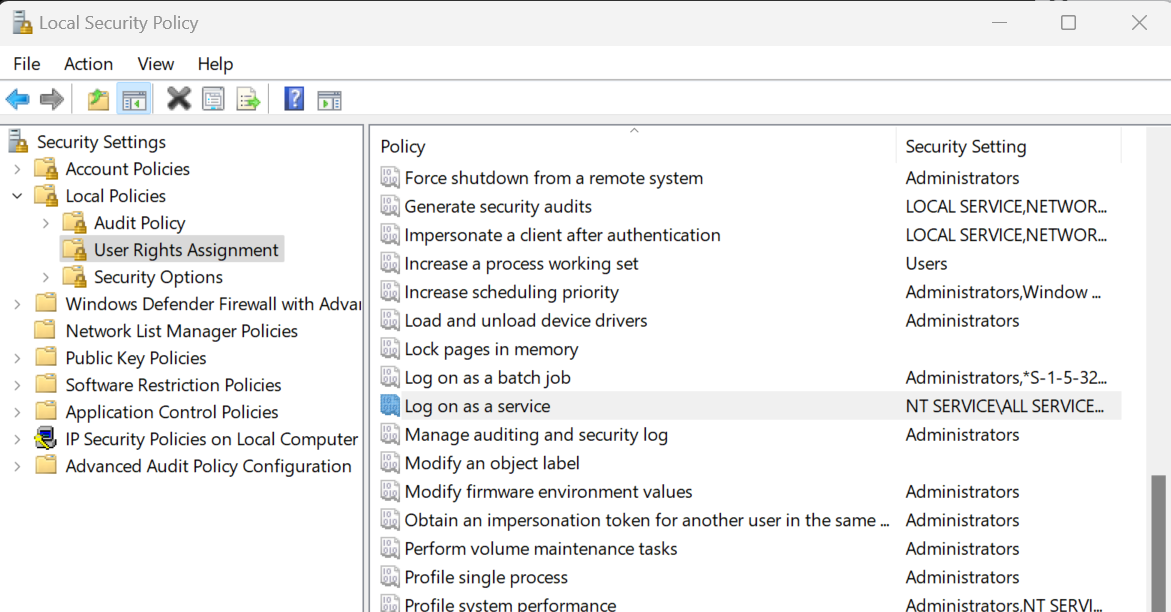
Para instalar o Jenkins, você precisa modificar a "Política de segurança local" para permitir o acesso de login do usuário ao instalador. Para fazer isso, pressione as teclas Win + R no teclado, digite "secpol.msc" e pressione Enter. Em seguida, navegue até "Políticas locais" > "Atribuições de direitos de usuário" > "Fazer logon como um serviço".
Seremos redirecionados para uma nova janela, onde digitaremos nosso nome de usuário do Windows e clicaremos no botão "Check Names" (Verificar nomes). Depois disso, pressione o botão "OK" e saia da janela "Local Security Policy".
Acesse o site jenkins.io e baixe o pacote do Windows Installer para o Jenkins.
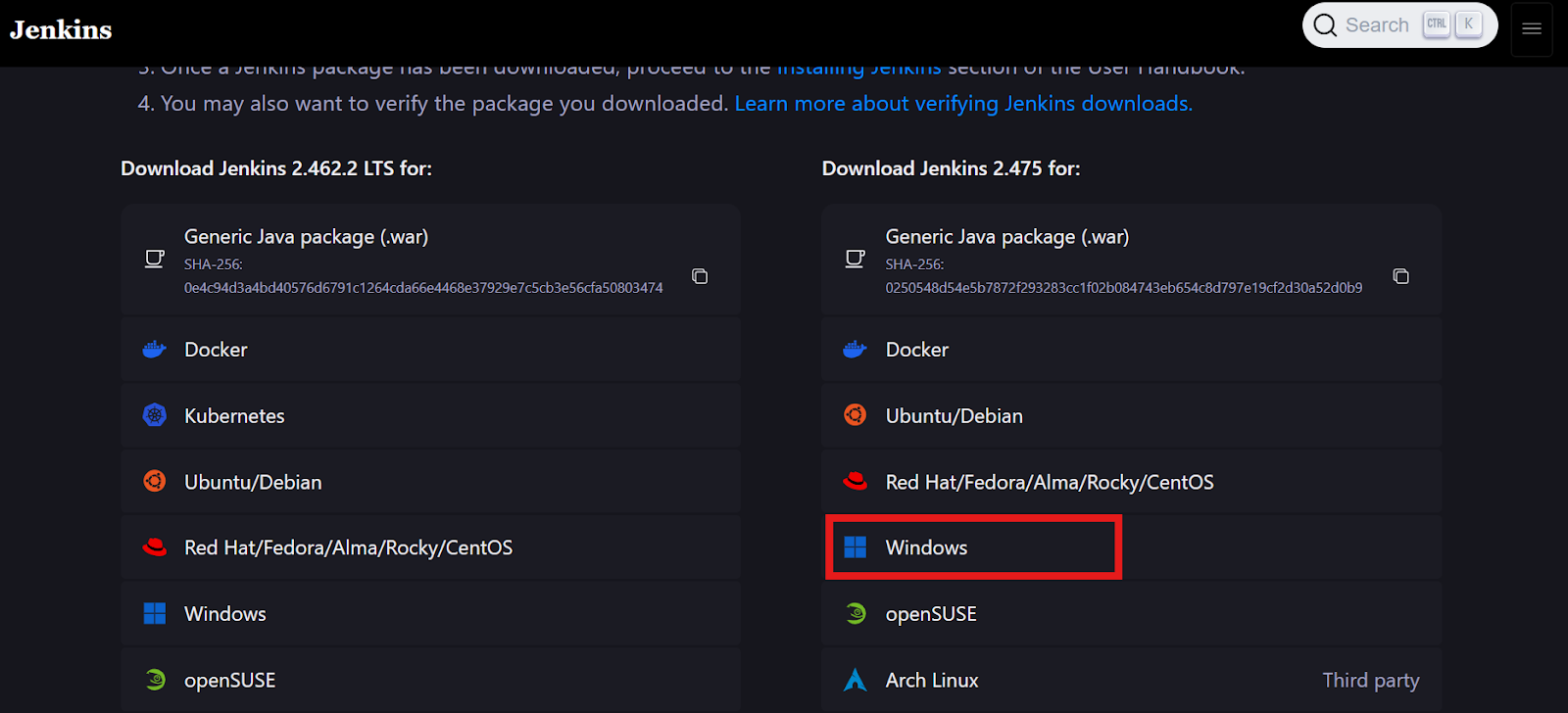
Fonte da imagem: jenkins.io
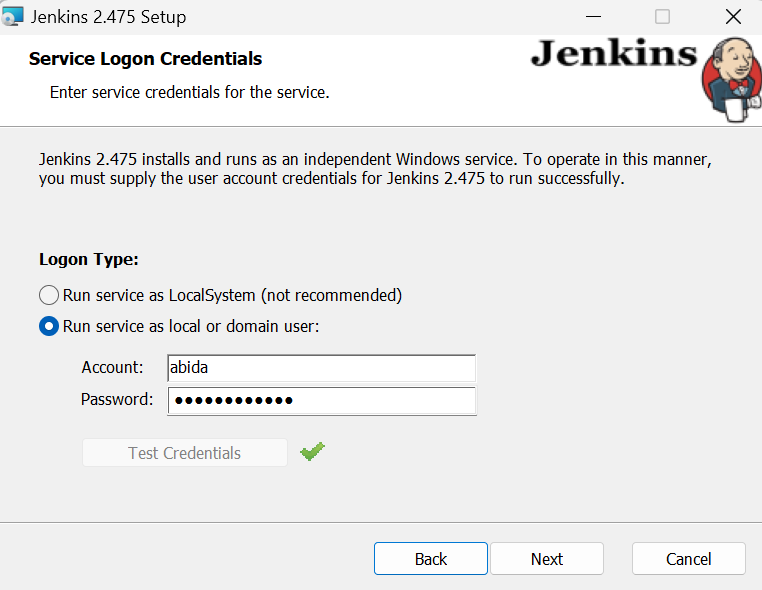
Quando chegarmos à janela que diz "Run service as a local or domain user" (Executar serviço como um usuário local ou de domínio), digite seu nome de usuário e senha do Windows e pressione o botão "Test Credentials" (Testar credenciais). Se for aprovado, clique no botão "Next" (Avançar).
Mantenha tudo o mais como padrão e conclua a instalação. Pode levar alguns minutos para você configurar.
Iniciar o servidor Jenkins é simples. Tudo o que você precisa fazer é clicar na tecla Windows e procurar por "Serviços". Na janela Serviços, procure por Jenkins e clique no botão de reprodução na parte superior.
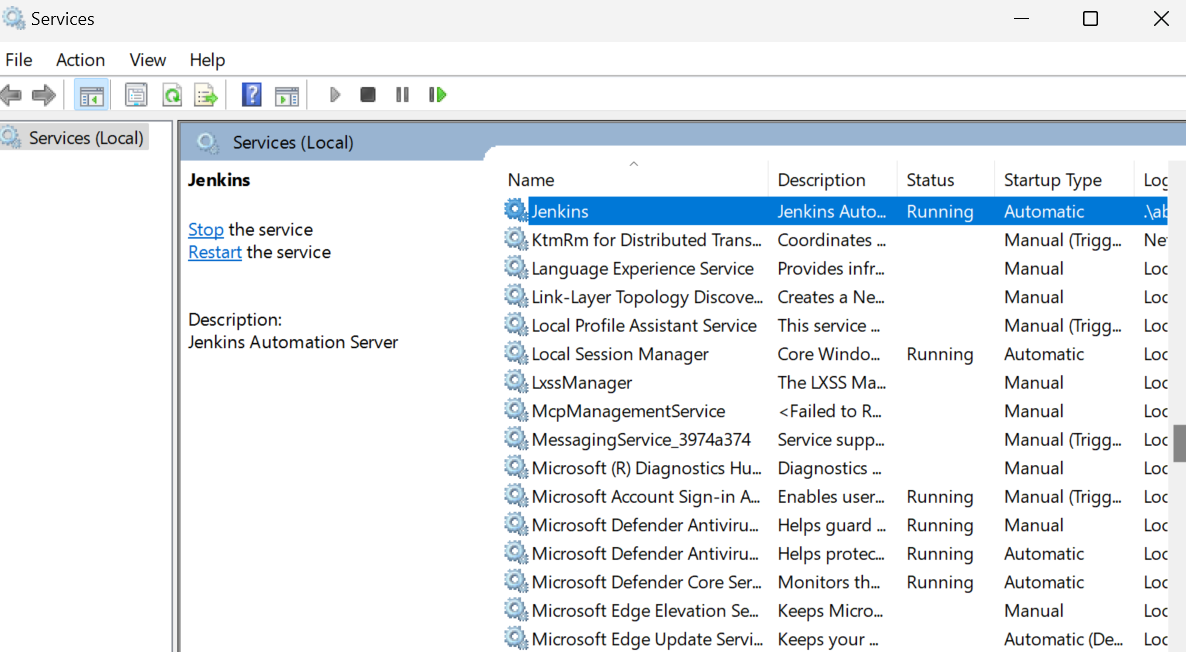
Por padrão, o Jenkins é executado em https://localhost:8080/. Basta colar esse URL em um navegador para acessar o painel. Para entrar no painel do Jenkins, você precisa digitar a senha de administrador.
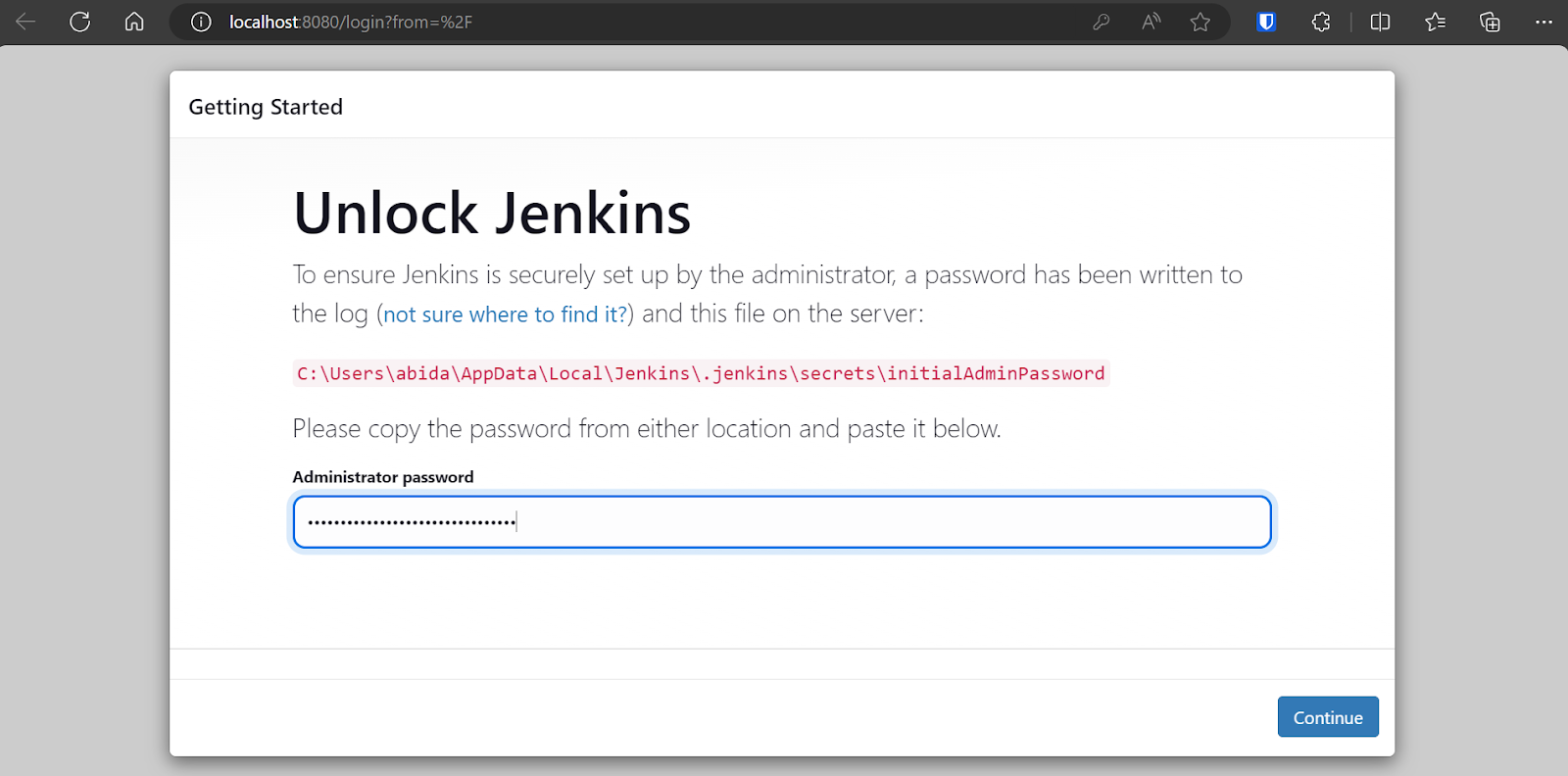
Para obter a senha padrão do administrador, navegue até o diretório Jenkins, localize e abra o arquivo Jenkins.err.log.
Role o arquivo de erro do Jenkins para baixo para encontrar a senha gerada. Copie-a e cole-a na caixa de entrada da senha do administrador.
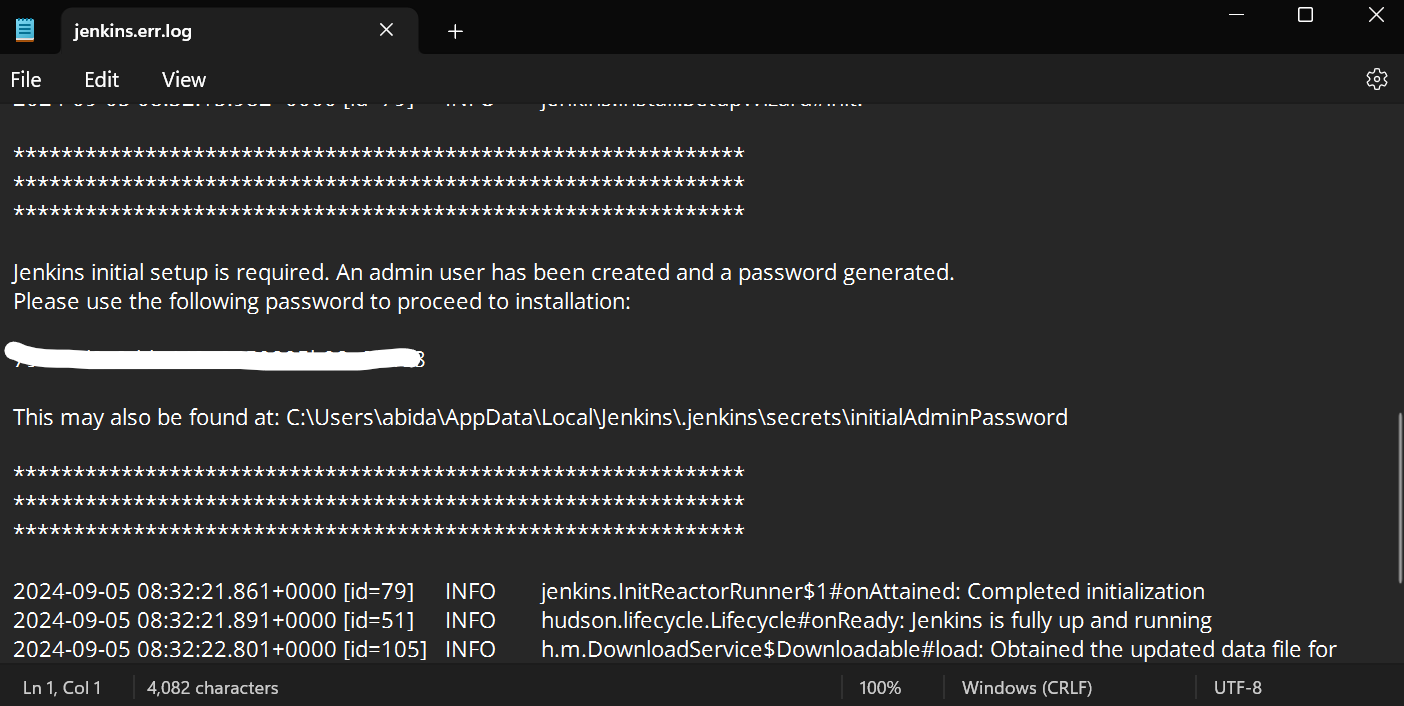
Depois disso, o servidor levará alguns minutos para instalar as ferramentas e extensões necessárias.
Quando a configuração do servidor estiver concluída, ele solicitará que você crie um novo usuário. Insira todas as informações necessárias e clique no botão "Save and Continue" (Salvar e continuar).
Seremos direcionados ao painel, onde criaremos, visualizaremos e executaremos vários pipelines do Jenkins.
Os agentes, também conhecidos como nós, são máquinas configuradas para executar trabalhos despachados pelo servidor mestre do Jenkins. Esses agentes fornecem o ambiente e a computação para executar pipelines. Um agente do Windows 11 está disponível por padrão, mas sempre podemos criar nosso próprio agente com opções personalizadas.
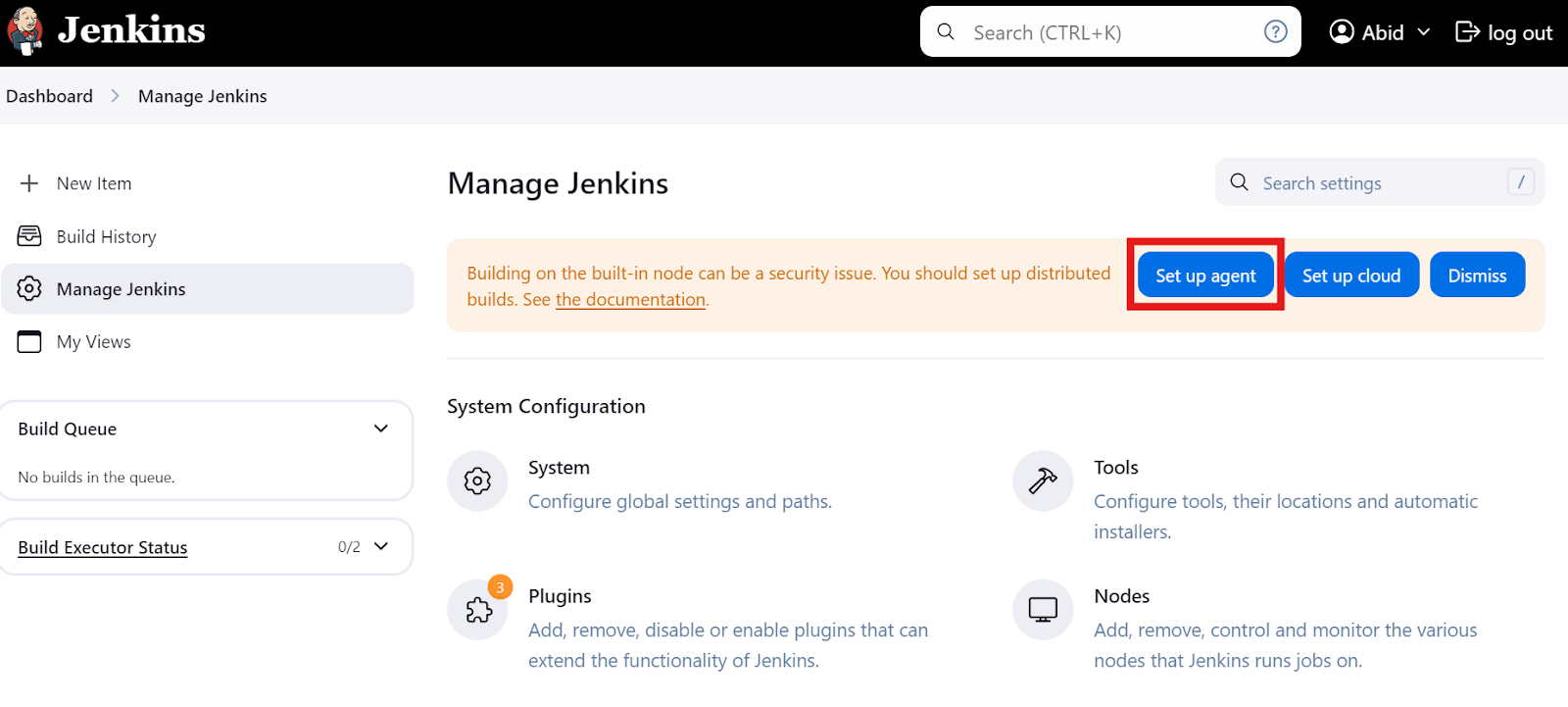
No painel principal, clique na opção "Manage Jenkins" (Gerenciar Jenkins) e, em seguida, clique no botão "Set up agent" (Configurar agente), conforme mostrado abaixo. Como alternativa, você pode clicar no botão "Nodes" (Nós) para criar e gerenciar agentes.
Digite o nome do agente e selecione o tipo "Permanent Agent" (Agente permanente).
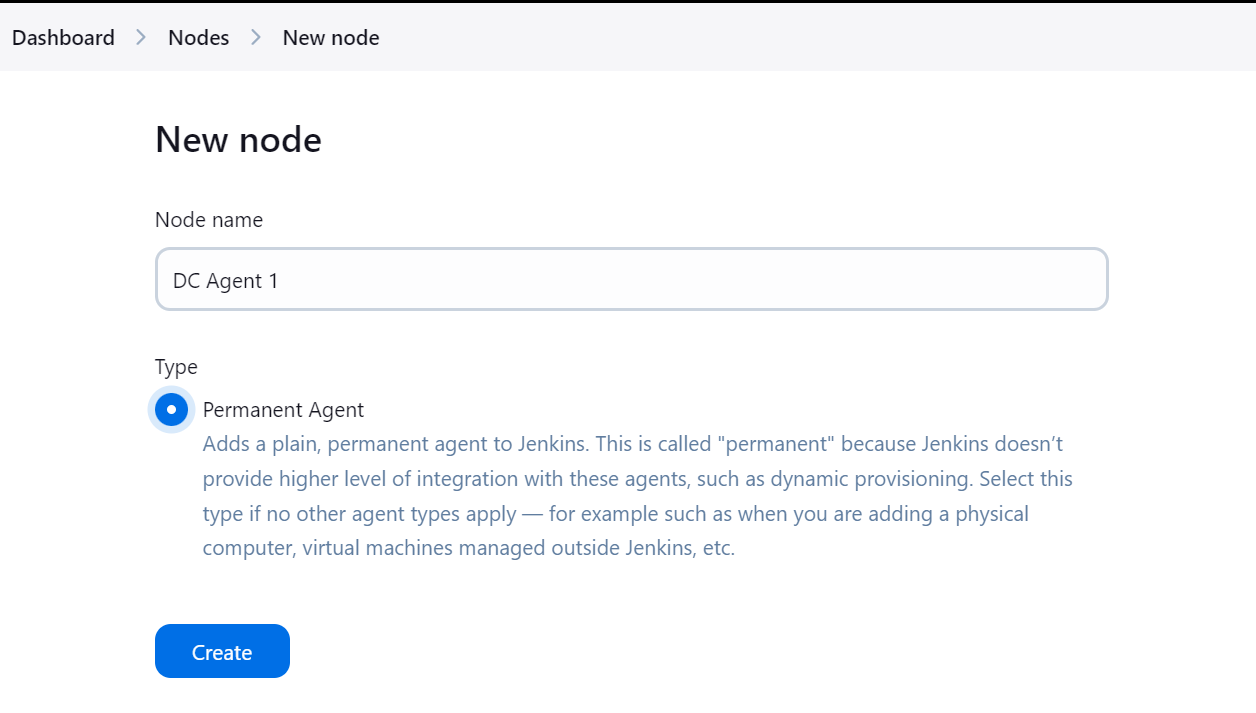
Certifique-se de que você forneça um diretório para o agente no qual todos os arquivos e logs serão salvos. Adicione um rótulo e mantenha o restante das configurações como padrão. Ao criar o pipeline, usaremos o rótulo do agente para executar as tarefas.
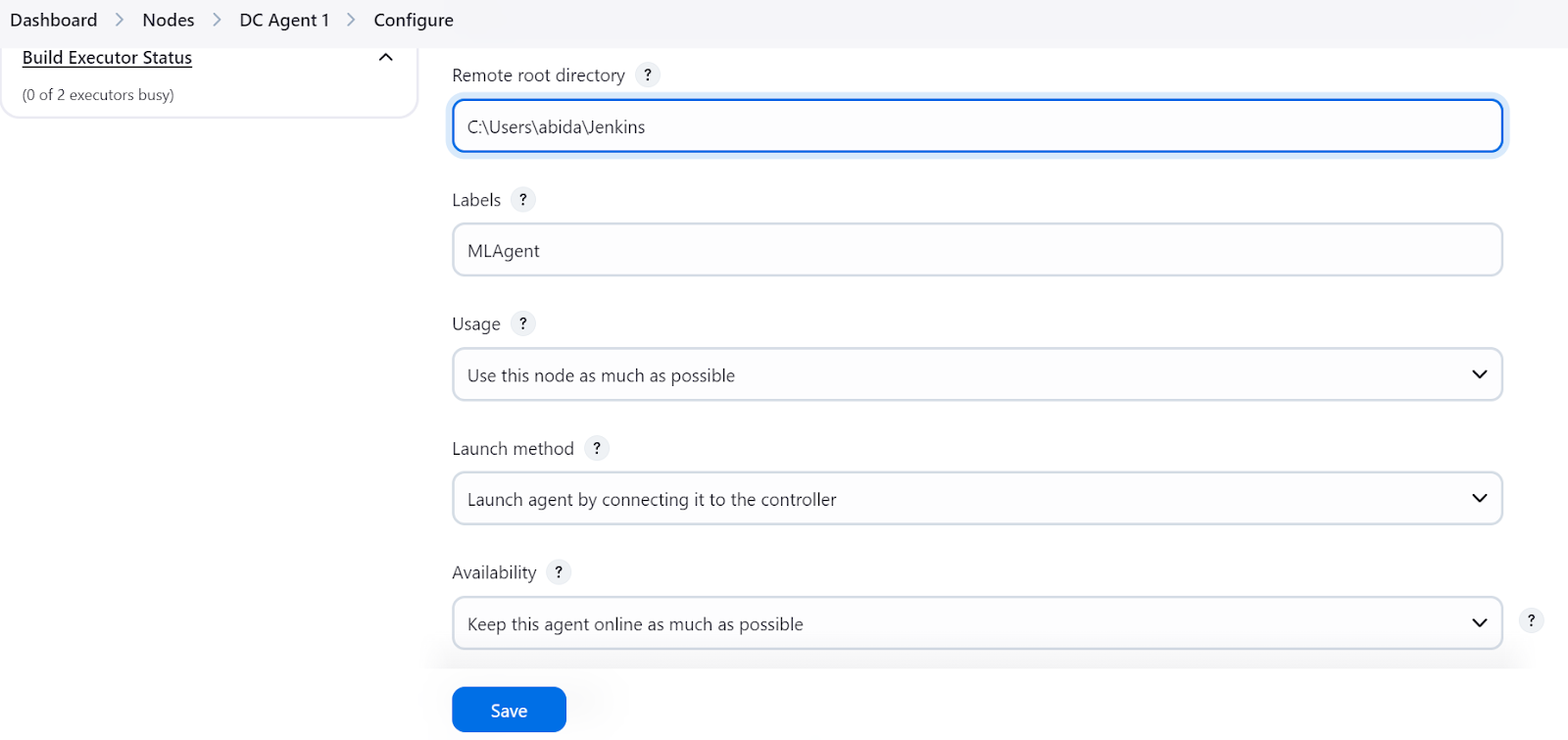
Quando o botão "Save" (Salvar) for pressionado, será exibido um prompt que nos instruirá a copiar e colar o comando apropriado no terminal, de acordo com o nosso sistema operacional.
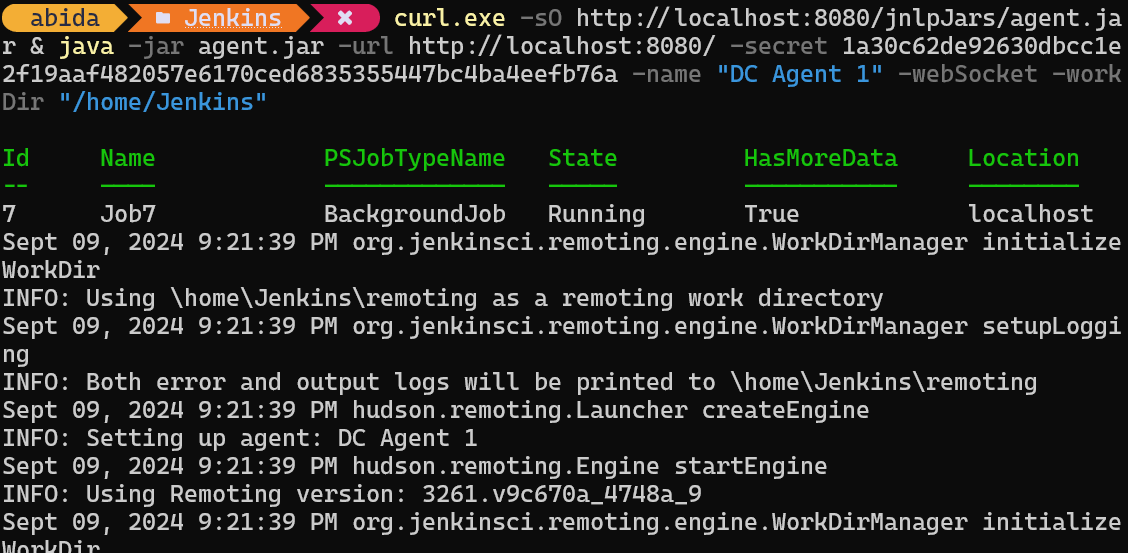
curl.exe -sO http://localhost:8080/jnlpJars/agent.jar & java -jar agent.jar -url http://localhost:8080/ -secret 1a30c62de92630dbcc1e2f19aaf482057e6170ced6835355447bc4ba4eefb76a -name "DC Agent 1" -webSocket -workDir "/home/Jenkins"Depois de colar e executar o comando no terminal, você verá uma mensagem de sucesso indicando que o nosso agente, no meu caso, DC Agent 1, está sendo executado em segundo plano.
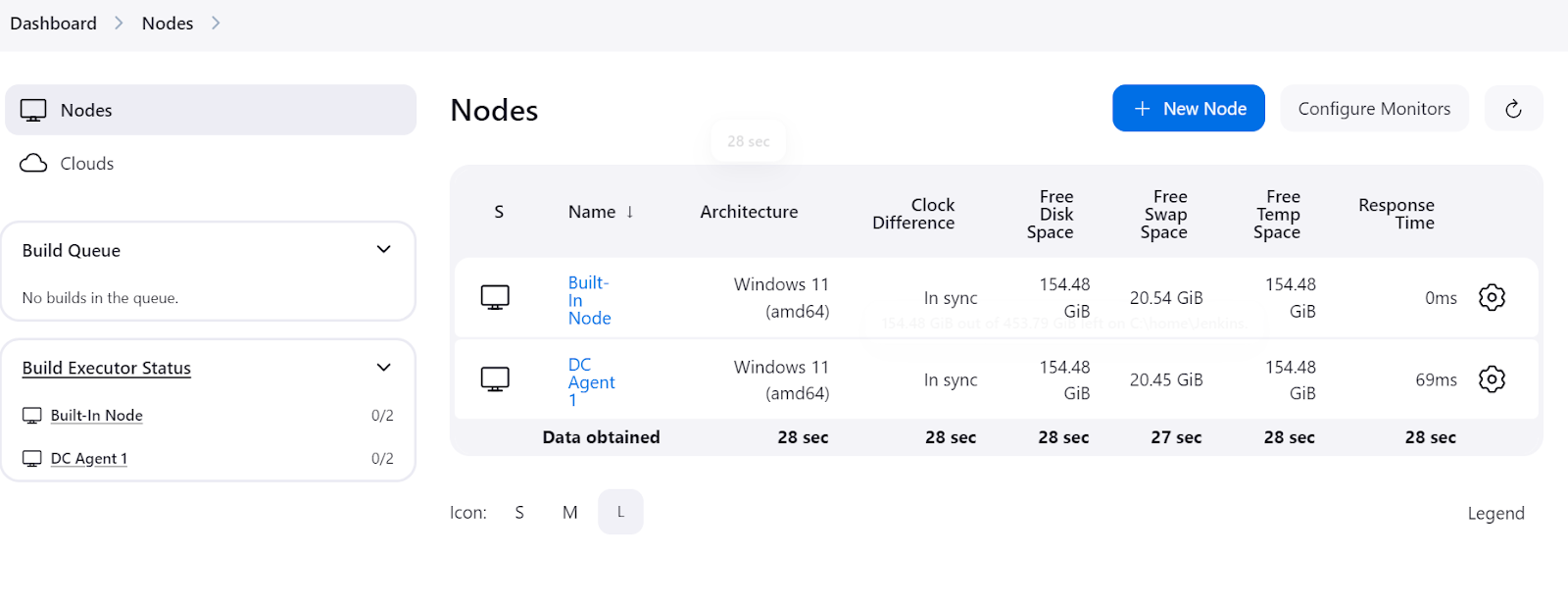
Para verificar se o agente está em execução e pronto para executar um trabalho, navegue até o painel do Jenkins, clique em "Manage Jenkins" (Gerenciar Jenkins) e, em seguida, clique no botão "Nodes" (Nós) para visualizar o status do agente.
Um pipeline Jenkins é uma série de etapas automatizadas que ajudam no treinamento, na avaliação e na implementação de modelos. Ele define esses processos usando um script de programação simples, facilitando o gerenciamento e a automação dos fluxos de trabalho do projeto.
Nesta seção, criaremos um exemplo de pipeline do Jenkins e usaremos o agente recém-criado como executor do pipeline.
No painel, clique no botão "Novo item", digite o nome do item, selecione a opção "Pipeline" e clique em "OK".
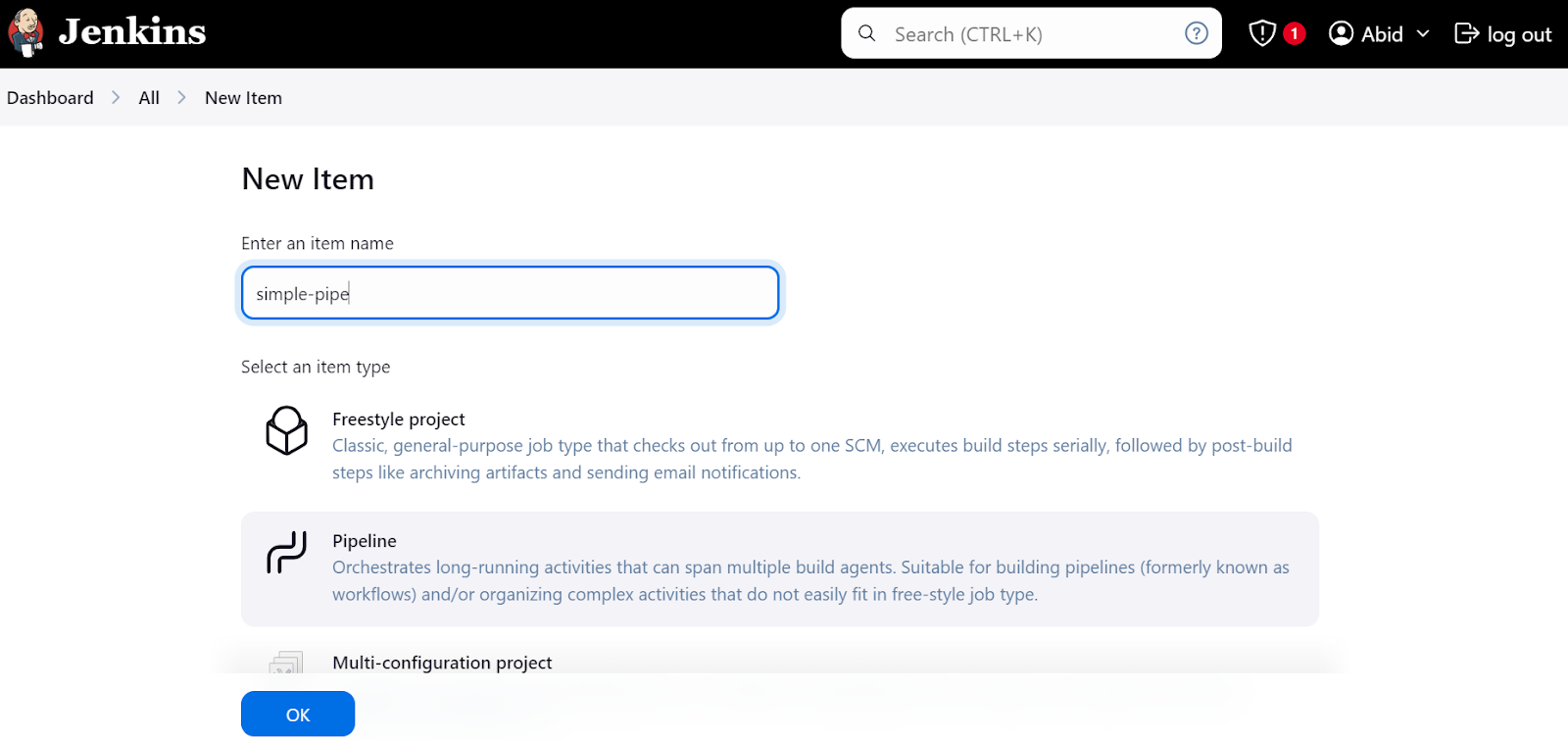
Depois disso, um prompt solicitará que você configure o pipeline. Role para baixo até a seção "Pipeline", onde precisamos escrever o script do pipeline do Jenkins.
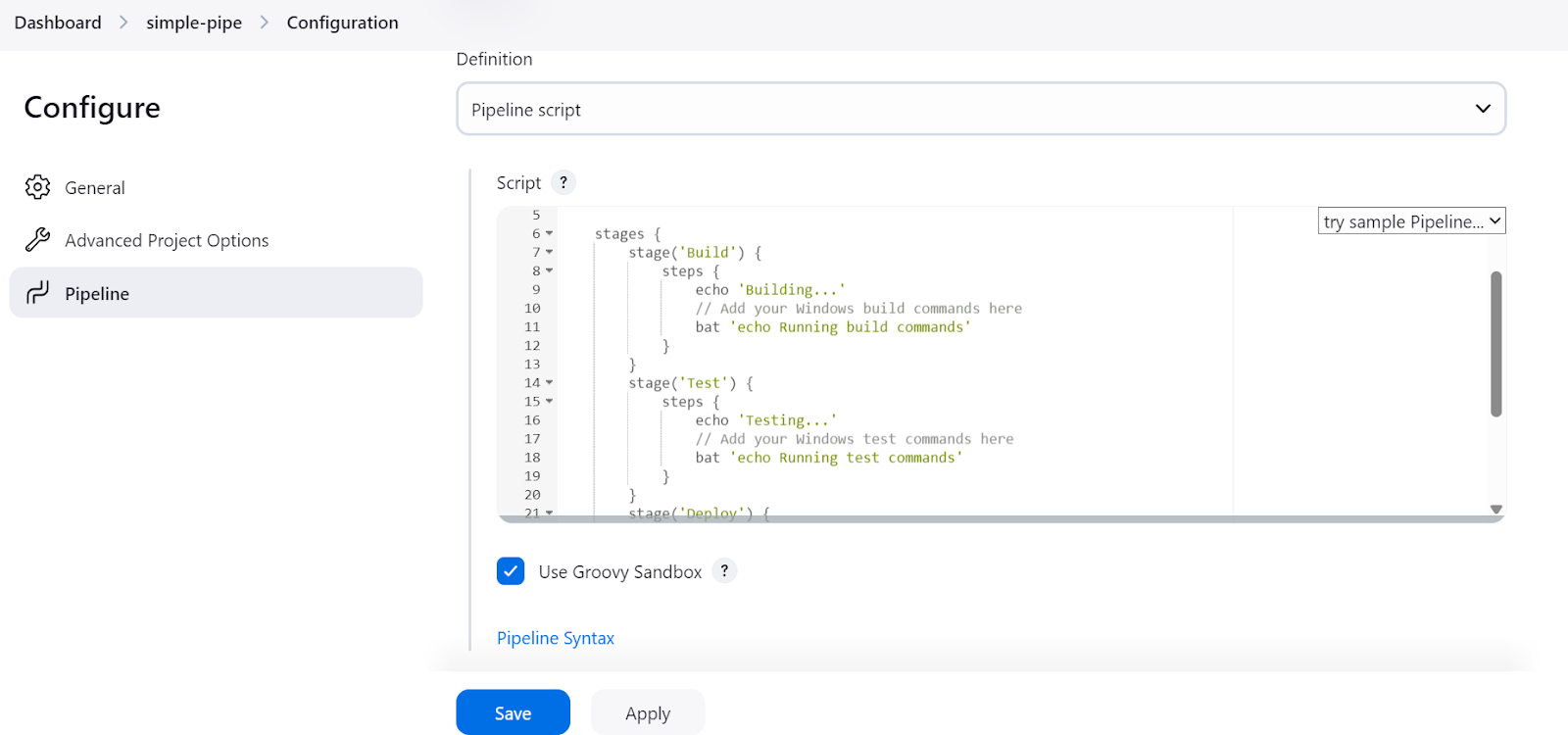
No script do pipeline do Jenkins, começamos configurando o ambiente e o agente. No nosso caso, estamos configurando o agent fornecendo a ele o rótulo do agente que definimos anteriormente.
Depois disso, escreveremos uma seção stages na qual todas as várias etapas do pipeline (Build, Test, Deploy) serão adicionadas. No nosso caso, estamos apenas imprimindo usando o comando echo e executando os comandos do terminal usando o comando bat.
bat é usado para o Windows 11sh é para LinuxÉ isso aí. É simples assim. Aqui está o código do script:
pipeline {
agent {
label 'MLAgent' // Ensure this label matches your Windows 11 agent
}
stages {
stage('Build') {
steps {
echo 'Building...'
// Add your Windows build commands here
bat 'echo Running build commands'
}
}
stage('Test') {
steps {
echo 'Testing...'
// Add your Windows test commands here
bat 'echo Running test commands'
}
}
stage('Deploy') {
steps {
echo 'Deploying...'
// Add your Windows deploy commands here
bat 'echo Running deploy commands'
}
}
}
}Depois de adicionar o script, clique nos botões "Apply" (Aplicar) e "Save" (Salvar).
Clique no botão "Build Now" para testar e executar o pipeline. Para ver seu status, clique no botão "Status".
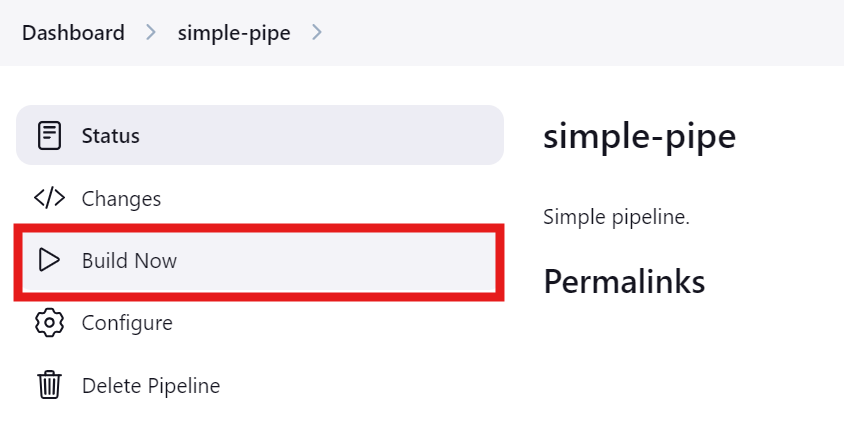
Após a conclusão da execução, podemos visualizar os registros clicando na execução específica no menu "Status".
Clique no link "Last build (#2)" e, em seguida, clique no botão "Console Output". Isso nos levará à janela de saída do console, onde podemos encontrar os logs e os resultados do pipeline.
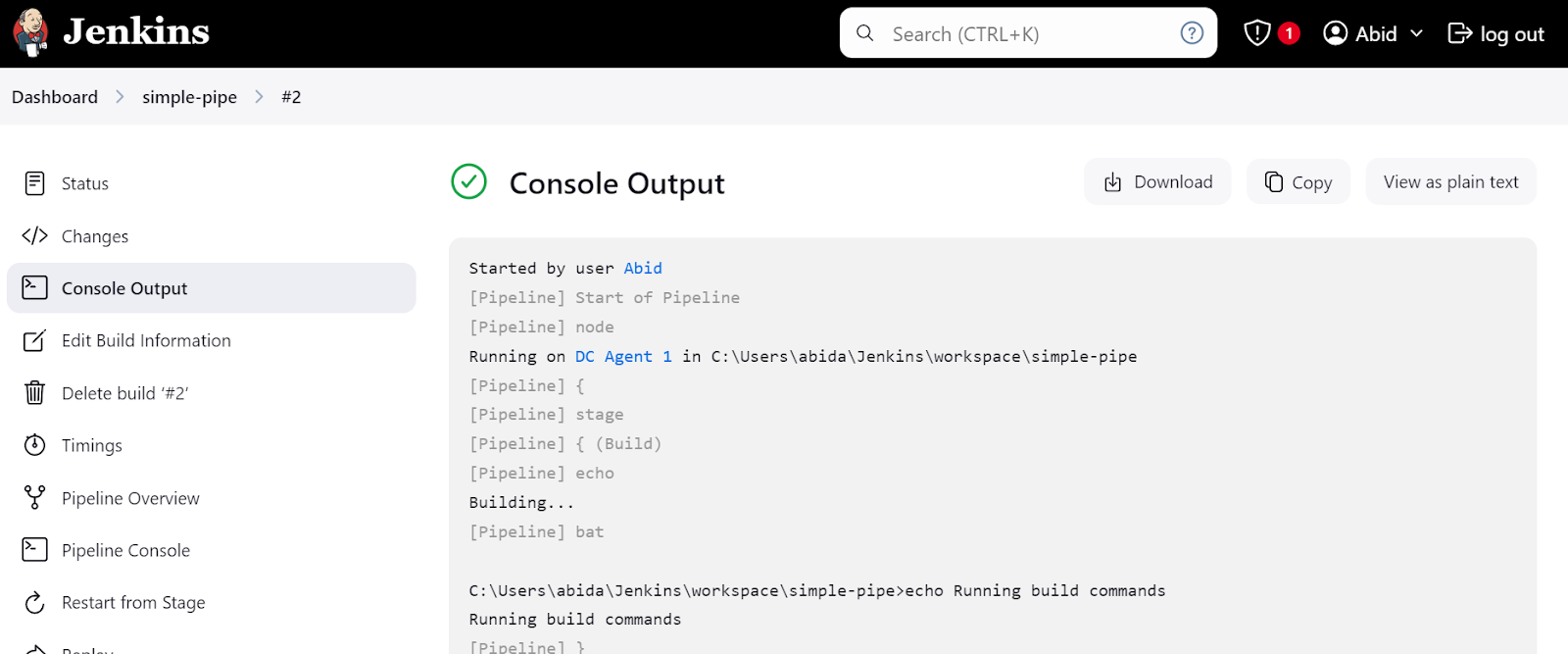
Você pode até clicar no botão "Console do pipeline" para visualizar detalhadamente cada etapa do pipeline. Isso inclui a saída, o tempo que levou para iniciar e terminar, os comandos do pipeline e os registros.
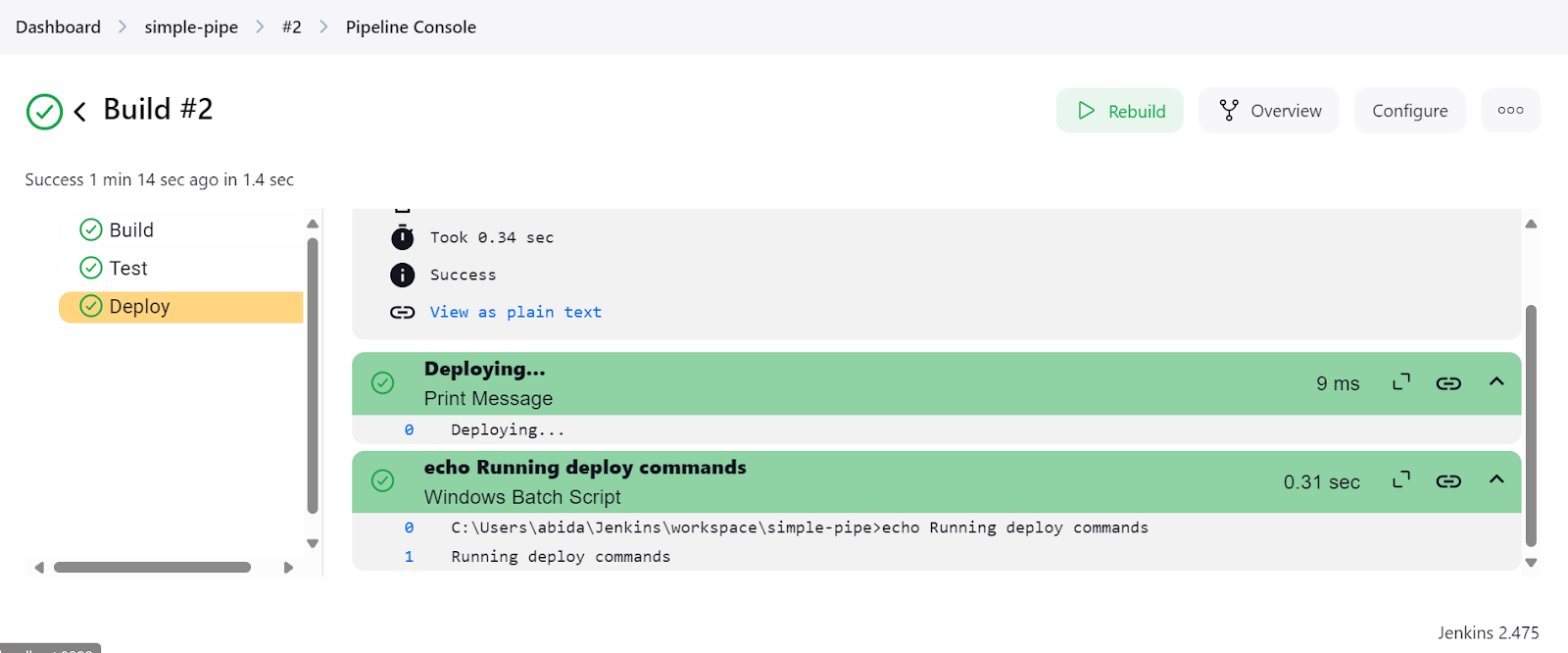
Depois de concluir a configuração da instalação do Jenkins, criar e executar pipelines foi fácil e rápido. Levei menos de uma hora para entender o script e como criar o meu próprio. Usarei o Jenkins em vez do GitHub Actions porque ele me oferece mais flexibilidade.
Author's opinion
Após a introdução inicial ao Jenkins, é hora de levarmos a sério e trabalharmos no projeto MLOps.
Criaremos dois pipelines: O primeiro pipeline será o CI, que carregará e processará os dados, treinará o modelo, avaliará o modelo e, em seguida, testará o servidor do modelo. Depois disso, ele iniciará o pipeline de CD, iniciando o servidor de inferência de modelo.
Para entender o processo em detalhes, faça o curso CI/CD para aprendizado de máquina, que ensina você a simplificar os processos de desenvolvimento de aprendizado de máquina.
Como em qualquer projeto, precisamos criar os arquivos do projeto, incluindo o carregamento de dados, o treinamento do modelo, a avaliação do modelo e os arquivos Python de serviço do modelo. Também precisamos de um arquivo requirements .txt para instalar os pacotes Python necessários.
Neste script, carregaremos um conjunto de dados do scikit-learn chamado Wine dataset e o converteremos em um DataFrame do pandas. Em seguida, dividiremos o conjunto de dados em conjuntos de treinamento e de teste. Por fim, salvaremos os dados processados como um arquivo pickle.
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
import joblib
def load_data():
# Load the wine dataset
wine = load_wine(as_frame=True)
data = pd.DataFrame(data=wine.data, columns=wine.feature_names)
data["target"] = wine.target
print(data.head())
return data
def split_data(data, target_column="target"):
X = data.drop(columns=[target_column])
y = data[target_column]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test
def save_preprocessed_data(X_train, X_test, y_train, y_test, file_path):
joblib.dump((X_train, X_test, y_train, y_test), file_path)
if __name__ == "__main__":
data = load_data()
X_train, X_test, y_train, y_test = split_data(data)
save_preprocessed_data(X_train, X_test, y_train, y_test, "preprocessed_data.pkl")Nesse arquivo, carregaremos os dados processados, treinaremos um classificador de floresta aleatória e salvaremos o modelo como um arquivo pickle.
from sklearn.ensemble import RandomForestClassifier
import joblib
def load_preprocessed_data(file_path):
return joblib.load(file_path)
def train_model(X_train, y_train):
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
return model
def save_model(model, file_path):
joblib.dump(model, file_path)
if __name__ == "__main__":
X_train, X_test, y_train, y_test = load_preprocessed_data("preprocessed_data.pkl")
model = train_model(X_train, y_train)
save_model(model, "model.pkl")Para avaliar o modelo, carregaremos o modelo e o conjunto de dados pré-processado, geraremos um relatório de classificação e imprimiremos a pontuação de precisão.
import joblib
from sklearn.metrics import accuracy_score, classification_report
def load_model(file_path):
return joblib.load(file_path)
def load_preprocessed_data(file_path):
return joblib.load(file_path)
def evaluate_model(model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return accuracy, report
if __name__ == "__main__":
X_train, X_test, y_train, y_test = load_preprocessed_data("preprocessed_data.pkl")
model = load_model("model.pkl")
accuracy, report = evaluate_model(model, X_test, y_test)
print(f"Model Accuracy: {accuracy}")
print(f"Classification Report:\n{report}")Para servir o modelo, usaremos o FastAPI para criar uma API REST em que os usuários possam inserir recursos e gerar previsões. Normalmente, os rótulos são genéricos. Para tornar as coisas mais interessantes, mudaremos as categorias de vinho para Verdante, Rubresco e Floralis.
Quando executamos esse arquivo, iniciamos o servidor FastAPI, que pode ser acessado por meio do comando curl ou usando a biblioteca requests em Python.
from typing import List
import joblib
import uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
# Define the labels corresponding to the target classes
LABELS = [
"Verdante", # A vibrant and fresh wine, inspired by its balanced acidity and crisp flavors.
"Rubresco", # A rich and robust wine, named for its deep, ruby color and bold taste profile.
"Floralis", # A fragrant and elegant wine, known for its floral notes and smooth finish.
]
class Features(BaseModel):
features: List[float]
def load_model(file_path):
return joblib.load(file_path)
model = load_model("model.pkl")
@app.post("/predict")
def predict(features: Features):
# Get the numerical prediction
prediction_index = model.predict([features.features])[0]
# Map the numerical prediction to the label
prediction_label = LABELS[prediction_index]
return {"prediction": prediction_label}
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=9000)Esse arquivo nos ajudará a baixar e instalar todos os pacotes necessários para executar os arquivos Python acima.
scikit-learn
pandas
fastapi
uvicornAgora, criaremos pipelines Jenkins de integração contínua. Assim como criamos um pipeline simples, criaremos um "MLOps-pipe" e escreveremos o script que abrange tudo, desde o processamento de dados até a avaliação do modelo.
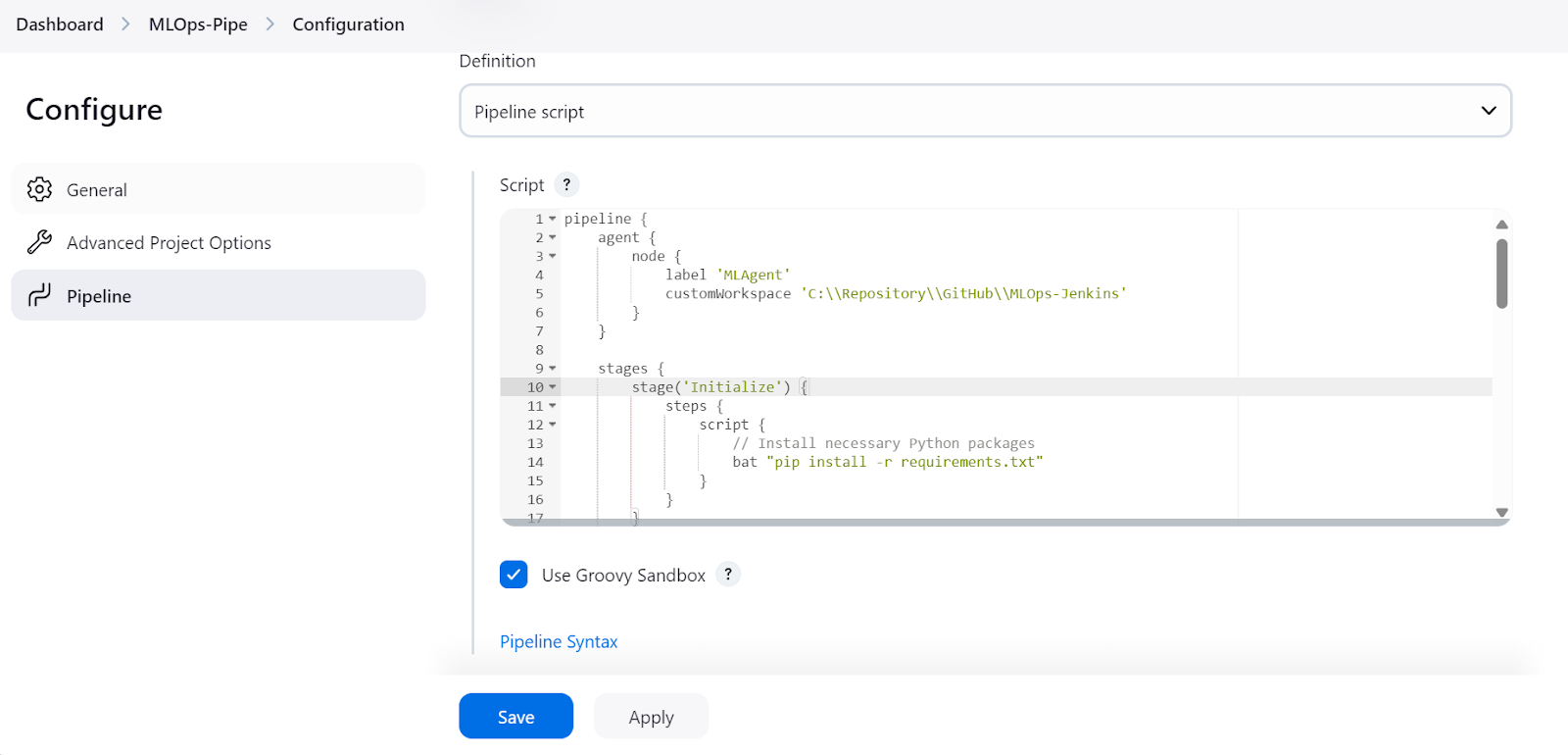
O script do pipeline MLOps consiste em:
agent com o label "MLAgent".Initialize).Load and Preprocess Data).Train Model).Evaluate Model).curl (Test Serve Model ).Observação: O comando start /B abre uma nova janela de terminal em segundo plano e executa o script de serviço de modelo. Além disso, esse script de pipeline do Jenkins só funcionará no Windows, e você precisará alterar os comandos para o Linux ou outros sistemas operacionais.
pipeline {
agent {
node {
label 'MLAgent'
customWorkspace 'C:\\Repository\\GitHub\\MLOps-Jenkins'
}
}
stages {
stage('Initialize') {
steps {
script {
// Install necessary Python packages
bat "pip install -r requirements.txt"
}
}
}
stage('Load and Preprocess Data') {
steps {
script {
// Run data loading script
bat "python data_loading.py"
}
}
}
stage('Train Model') {
steps {
script {
// Run model training script
bat "python model_training.py"
}
}
}
stage('Evaluate Model') {
steps {
script {
// Run model evaluation script
bat "python model_evaluation.py"
}
}
}
stage('Serve Model') {
steps {
script {
// Start FastAPI server in the background
bat 'start /B python model_serving.py'
// Wait for the server to start
sleep time: 10, unit: 'SECONDS'
}
}
}
stage('Test Serve Model') {
steps {
script {
// Test the server with sample values
bat '''
curl -X POST "http://127.0.0.1:9000/predict" ^
-H "Content-Type: application/json" ^
-d "{\\"features\\": [13.2, 2.77, 2.51, 18.5, 103.0, 1.15, 2.61, 0.26, 1.46, 3.0, 1.05, 3.33, 820.0]}"
'''
}
}
}
stage('Deploy Model') {
steps {
script {
// Trigger another Jenkins job for model serving
build job: 'ModelServingPipeline', wait: false
}
}
}
}
post {
always {
archiveArtifacts artifacts: '**.pkl', fingerprint: true
echo 'Pipeline execution complete.'
}
}
}Agora, criaremos um pipeline de implantação contínua para implantar e executar o servidor localmente.
O script do pipeline é simples. Começamos definindo o agente e alterando o diretório de trabalho para o nosso projeto. Depois disso, executamos o servidor indefinidamente.
Observação: Não é recomendável executar um servidor no Jenkins indefinidamente, pois os pipelines devem ter um início e um fim definidos. Para este exemplo, presumiremos que implantamos o aplicativo, mas, na prática, é melhor integrar o Docker e executar o aplicativo em um servidor Docker.
Se você estiver interessado em aprender a pensar como um engenheiro de aprendizado de máquina, considere fazer o curso Developing Machine Learning Models for Production with an MLOps Mindset, que permitirá que você treine, documente, mantenha e dimensione seus modelos de aprendizado de máquina em todo o seu potencial.
pipeline {
agent {
node {
label 'MLAgent'
customWorkspace 'C:/Repository/GitHub/MLOps-Jenkins/'
}
}
stages {
stage('Start FastAPI Server') {
steps {
script {
// Start the FastAPI server
bat 'python model_serving.py'
}
}
}
}
}Vá para o pipeline "MLOps-pipe" e clique no botão "Build Now" para iniciar o pipeline de CI/CD.
Quando o pipeline é executado com sucesso, ele gera dois artefatos: um para o modelo e outro para o conjunto de dados processados.
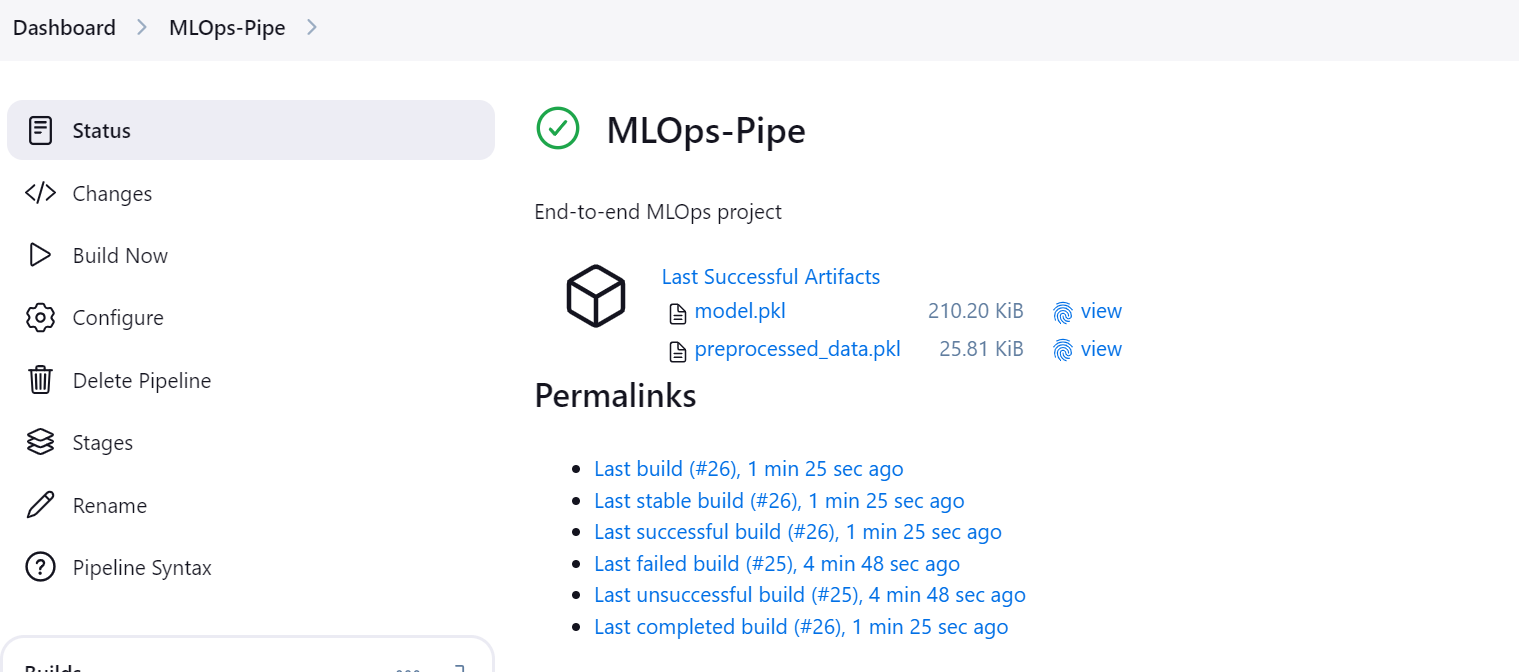
Clique no botão "Stages" (Estágios) no painel do Jenkins para visualizar o pipeline e ver todas as etapas.
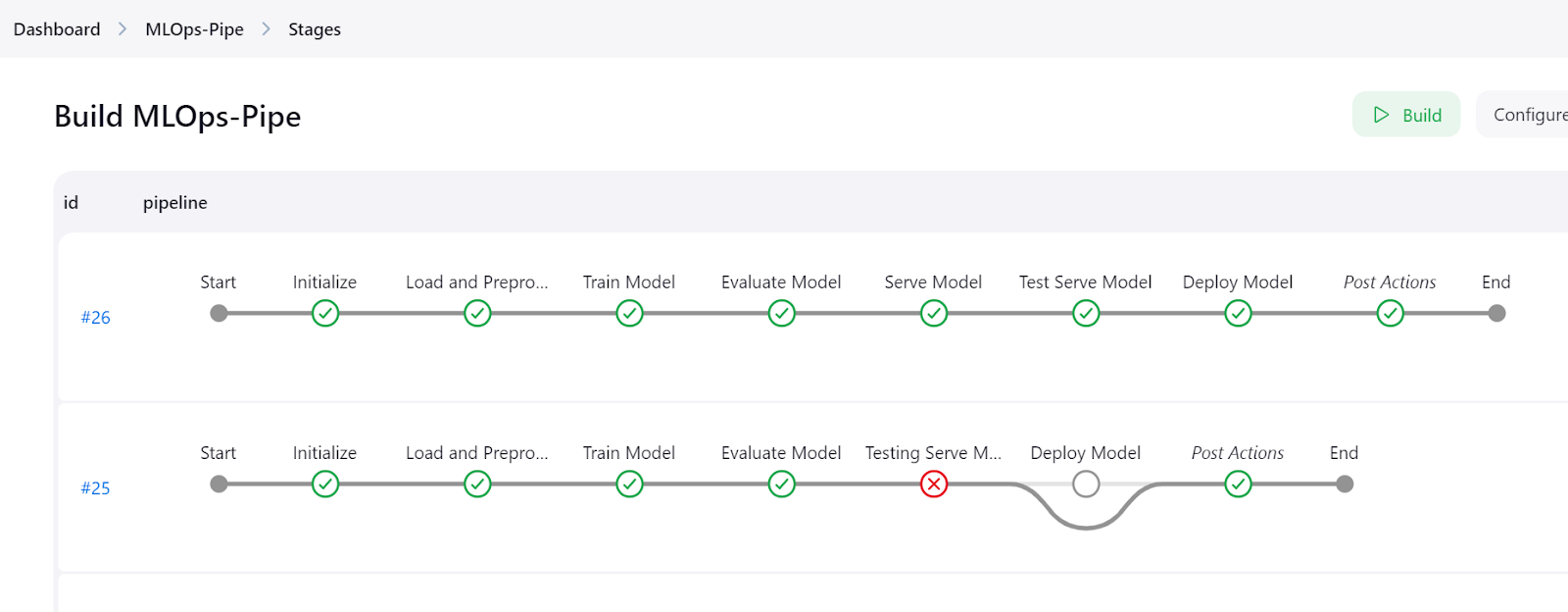
Para visualizar os registros detalhados de cada etapa, verifique o menu "Pipeline Console".
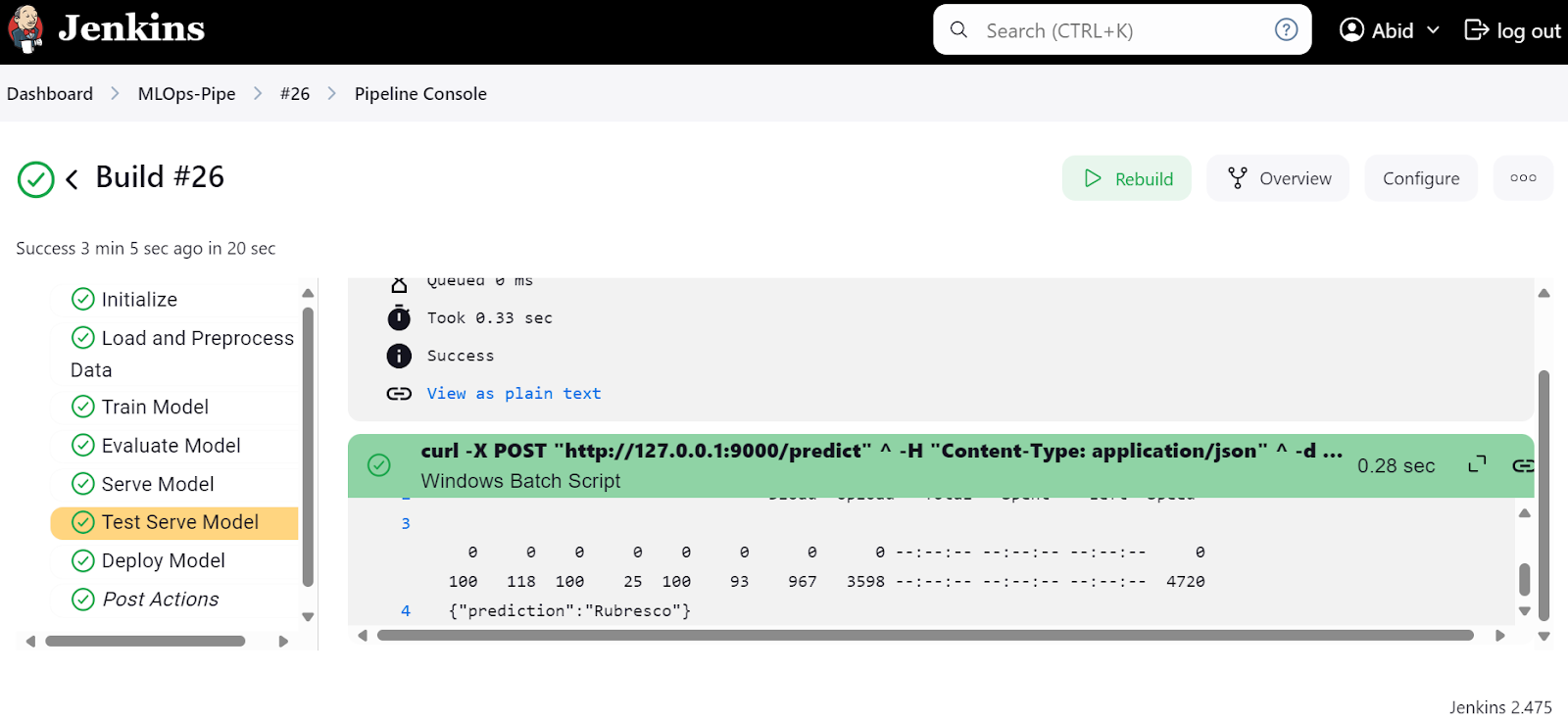
Também podemos verificar o "ModelServingPipeline" para verificar se o nosso servidor está sendo executado no URL local http://127.0.0.1:9000.
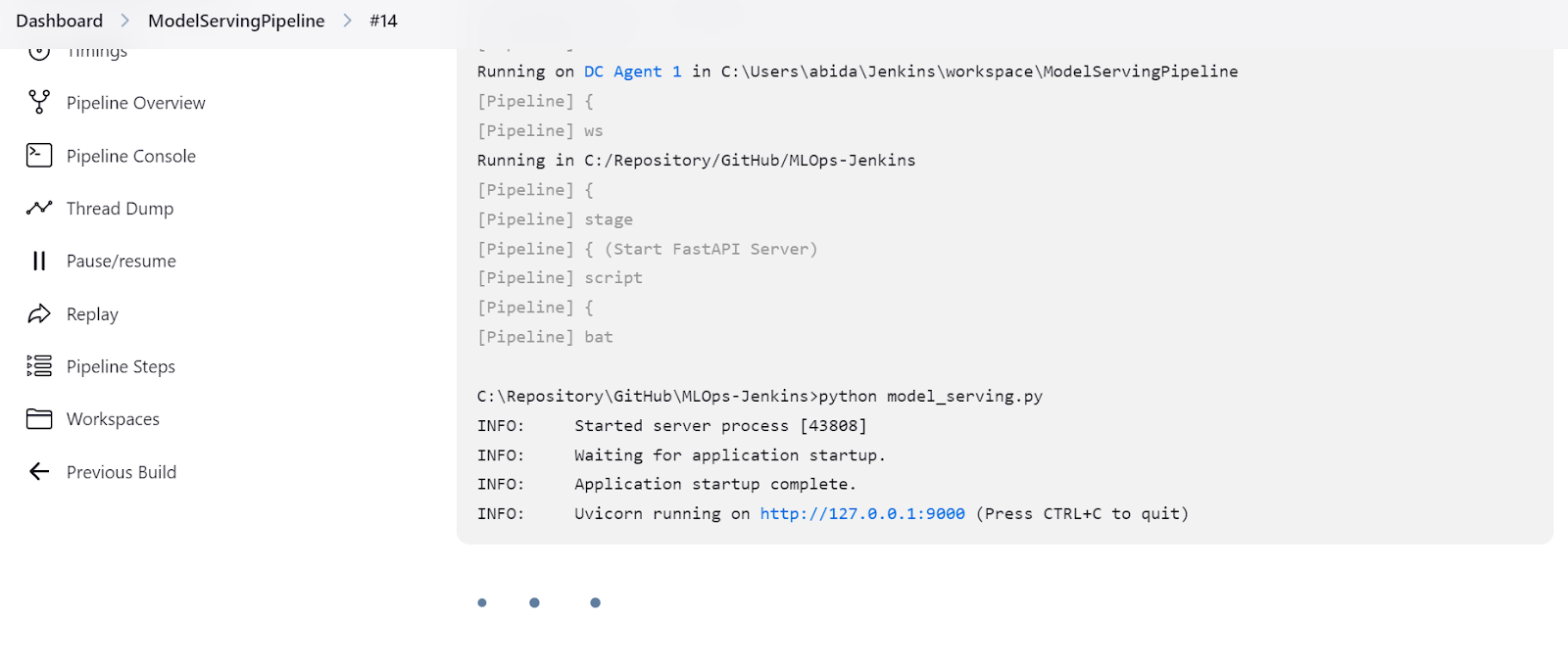
A FastAPI vem com a interface do usuário Swagger, que pode ser acessada adicionando /docs ao URL local: http://127.0.0.1:9000/docs.
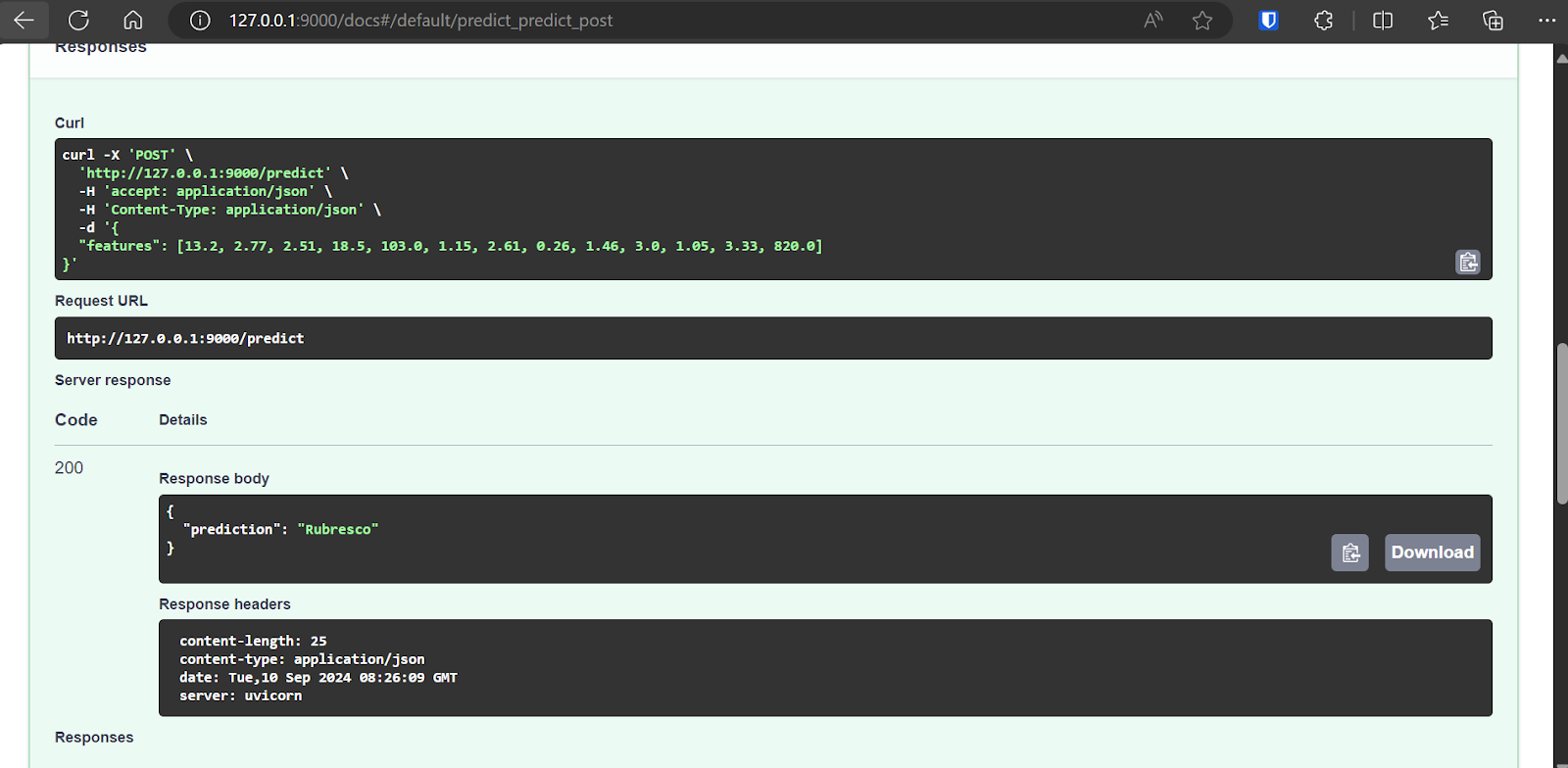
A interface do usuário do Swagger nos permite testar o aplicativo FastAPI no navegador. É simples, e podemos ver que nosso servidor modelo está funcionando bem. Os valores de amostra previstos sugerem que o tipo de vinho é Rubresco.
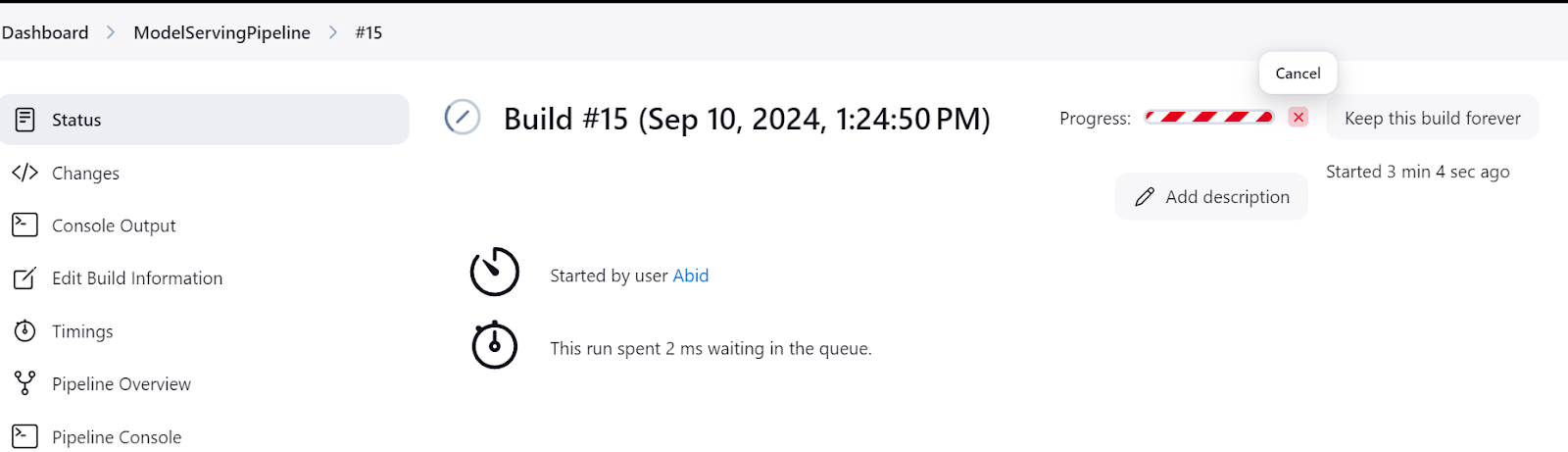
Certifique-se sempre de desligar o servidor de modelos depois que você terminar de fazer os experimentos. Você pode fazer isso acessando o menu "Status" no painel do Jenkins e, em seguida, clicando no botão de cruz, conforme mostrado abaixo:
Todo o código, os conjuntos de dados, os modelos e os metarquivos deste tutorial estão disponíveis no repositório do GitHub para você experimentarvocê: kingabzpro/MLOps-with-Jenkins.
O Jenkins é um ótimo servidor de automação para todos os tipos de tarefas de MLOps. Ele se destaca como uma excelente alternativa ao GitHub Actions, oferecendo mais recursos, maior controle e privacidade aprimorada.
Um dos aspectos mais atraentes do Jenkins é sua simplicidade na criação e execução de pipelines, tornando-o acessível tanto para iniciantes quanto para usuários experientes.
Se você estiver interessado em explorar recursos semelhantes usando o GitHub Actions, não perca o tutorial A Beginner's Guide to CI/CD for Machine Learning. Para aqueles que desejam aprofundar seus conhecimentos sobre MLOps, o curso Fully Automated MLOps é um recurso fantástico. Ele oferece insights abrangentes sobre a arquitetura de MLOps, técnicas de CI/CD/CM/CT e padrões de automação para implantar sistemas de ML que podem fornecer valor de forma consistente ao longo do tempo.
Saiba mais sobre MLOps com estes cursos!
Curso
Curso
Curso
blog
Karlijn Willems
15 min
Tutorial
Bex Tuychiev
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev
Tutorial
Javier Canales Luna

