
Cours
Concepts MLOps
2 h
42.6K

Dans ce tutoriel, nous allons apprendre à installer et à utiliser Jenkins, ainsi qu'à créer des agents et des pipelines et à les exécuter.
Plus précisément, nous allons :
Si vous avez besoin de rafraîchir vos connaissances, suivez une formation courte et directe sur les concepts MLOps pour apprendre à faire passer les modèles d'apprentissage automatique des blocs-notes Jupyter à des modèles fonctionnels en production qui génèrent une réelle valeur commerciale.
Jenkins est un serveur d'automatisation open-source qui joue un rôle important dans le processus de développement de l'apprentissage automatique en facilitant l'intégration continue (CI) et le déploiement continu (CD).
Écrit en Java, Jenkins permet d'automatiser le traitement des données, l'entraînement, l'évaluation et le déploiement des projets d'apprentissage automatique, ce qui en fait un outil essentiel pour les pratiques MLOps.
Les caractéristiques de Jenkins :
L'automatisation des tâches à l'aide de Jenkins n'est qu'une partie de l'écosystème MLOps. Vous pouvez découvrir d'autres tâches en lisant les 25 principaux outils MLOps que vous devez connaître en 2024 sur le blog. Il se compose d'outils pour le cursus des expériences, la gestion des métadonnées des modèles, l'orchestration des flux de travail, le versionnement des données et des pipelines, le déploiement des modèles, ainsi que le service et la surveillance des modèles en production.
Nous pouvons facilement installer Jenkins sur Linux et macOS. Cependant, son installation sous Windows nécessite plusieurs étapes. Ces étapes comprennent l'installation du kit de développement Java, la configuration de la politique de sécurité locale, l'installation de Jenkins avec un utilisateur de domaine et le démarrage du serveur Jenkins.
Commençons par installer Java. Nous devons nous rendre sur le site web d'Adoptium et télécharger la dernière version LTS de Windows 11.
Pourquoi devons-nous installer OpenJDK ? Jenkins est une application basée sur Java qui nécessite un environnement d'exécution Java (JRE) ou un kit de développement Java (JDK) pour fonctionner.
Source de l'image : Adoptium
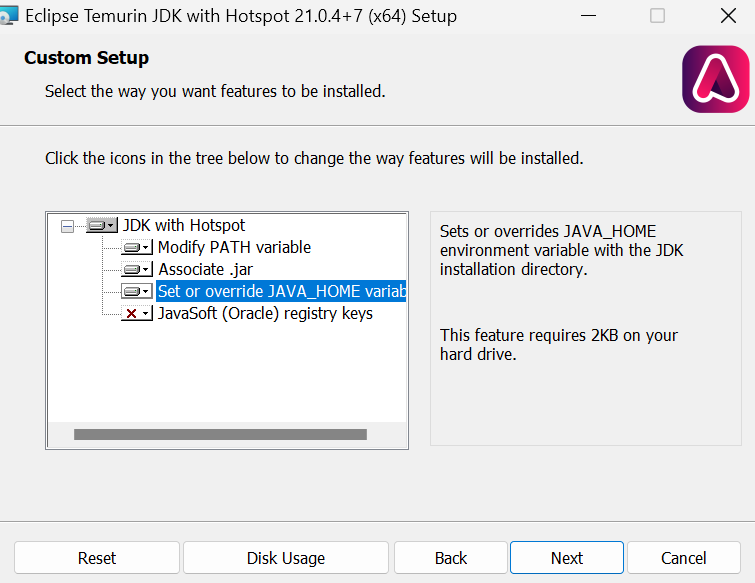
Installez OpenJDK avec les valeurs par défaut, sauf que nous devons cocher la case "Set or override JAVA_HOME variable".
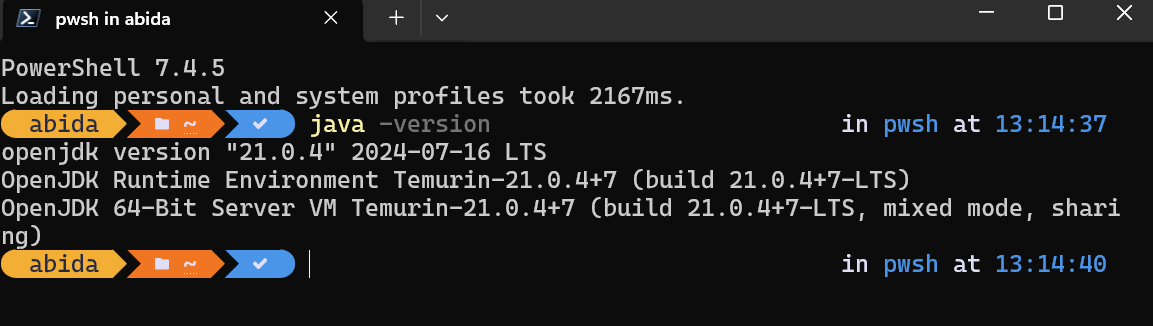
Une fois l'installation terminée, nous pouvons vérifier qu'elle s'est déroulée correctement en tapant java -version dans la fenêtre du terminal :
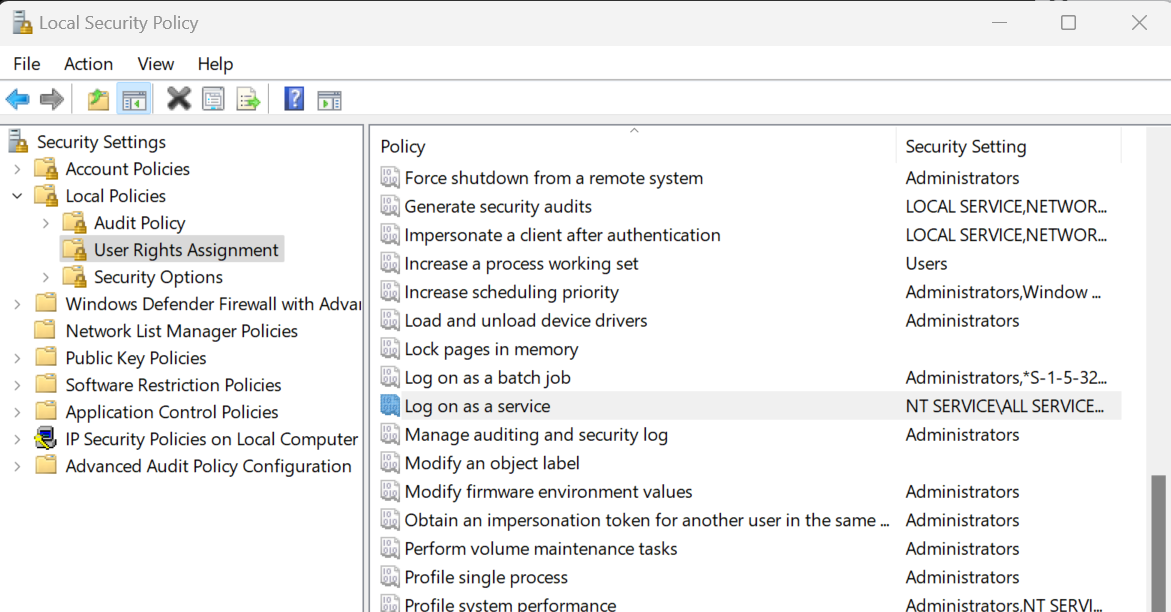
Pour installer Jenkins, vous devez modifier la "Politique de sécurité locale" afin d'autoriser l'accès des utilisateurs au programme d'installation. Pour ce faire, appuyez sur les touches Win + R de votre clavier, tapez "secpol.msc" et appuyez sur Entrée. Naviguez ensuite vers "Local Policies" > "User Rights Assignments" > "Log on as a service".
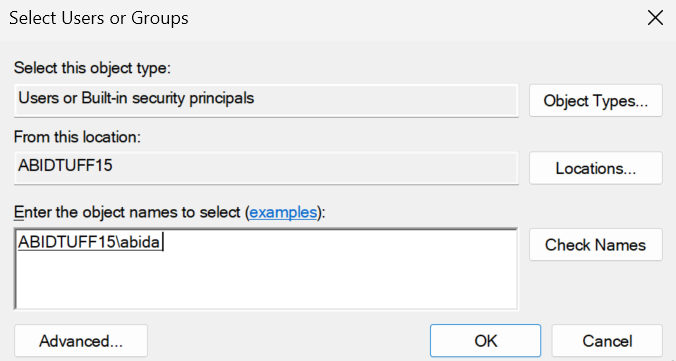
Nous serons redirigés vers une nouvelle fenêtre, où nous saisirons notre nom d'utilisateur Windows et cliquerons sur le bouton "Vérifier les noms". Ensuite, cliquez sur le bouton "OK" et quittez la fenêtre "Stratégie de sécurité locale".
Allez sur le site web jenkins.io et téléchargez le package Windows Installer pour Jenkins.
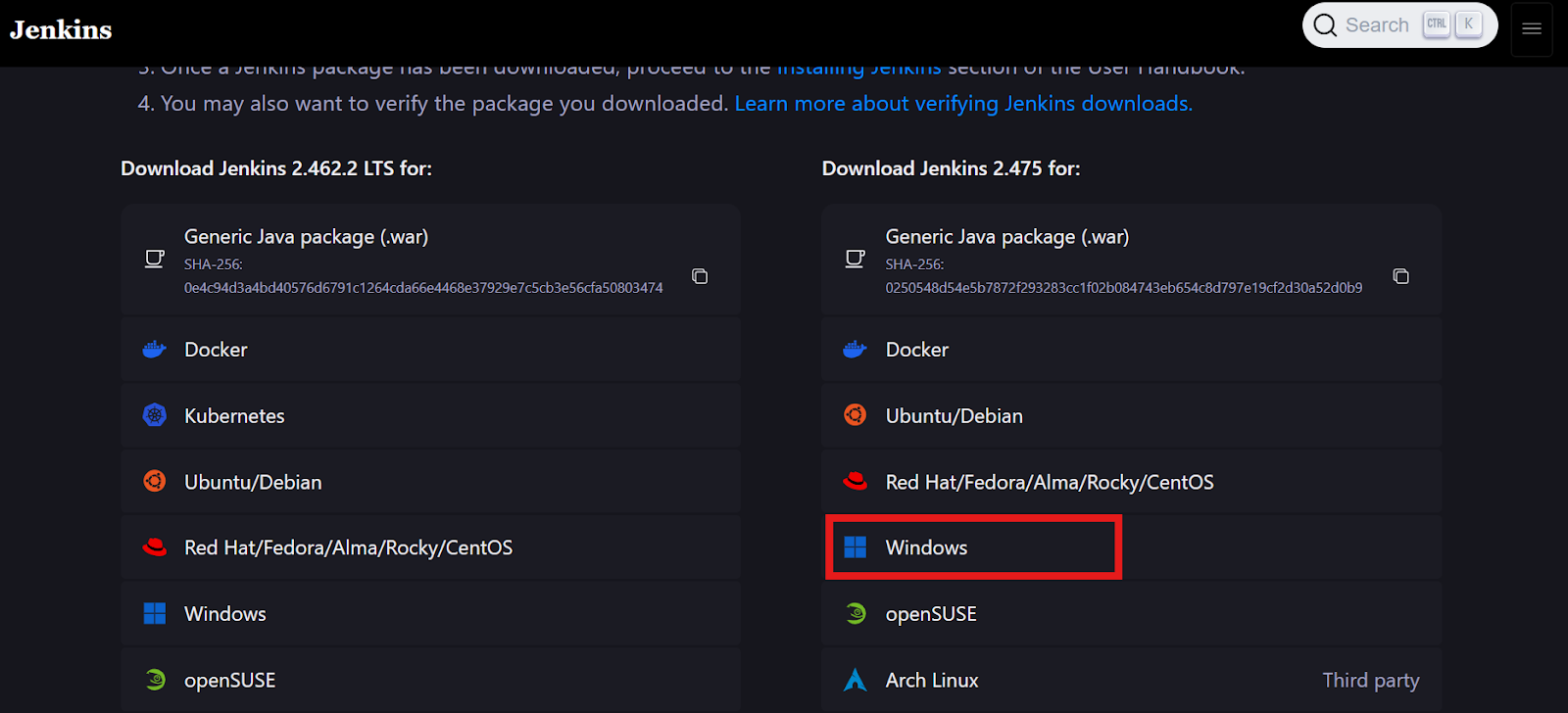
Source de l'image : jenkins.io
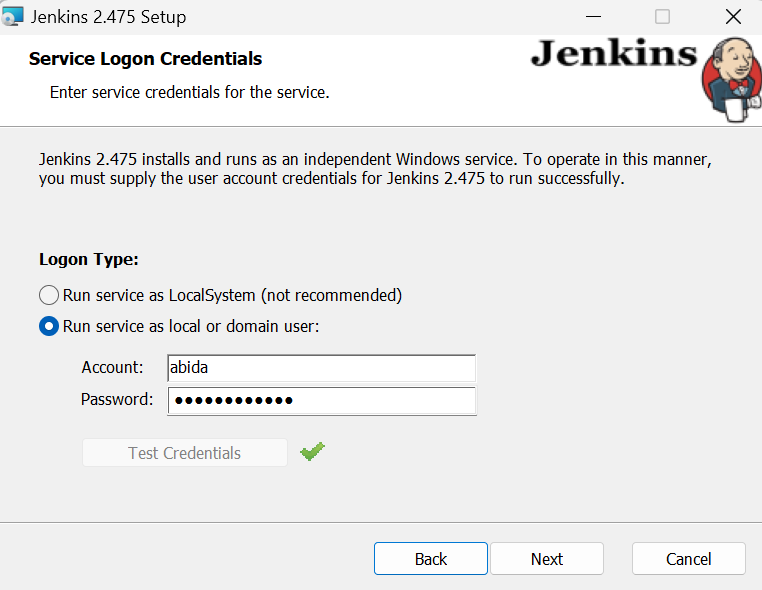
Lorsque vous arrivez à la fenêtre "Exécuter le service en tant qu'utilisateur local ou de domaine", saisissez votre nom d'utilisateur et votre mot de passe Windows, puis cliquez sur le bouton "Tester les informations d'identification". Si elle est approuvée, cliquez sur le bouton "Suivant".
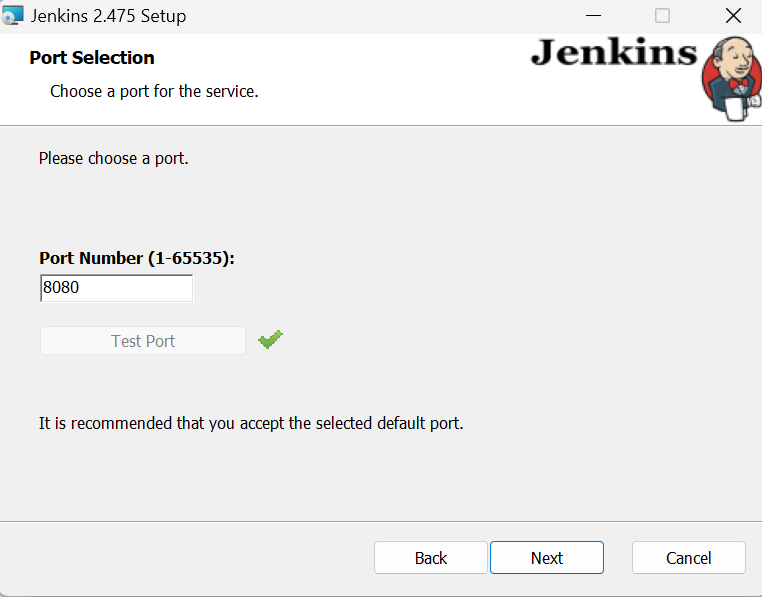
Conservez toutes les autres valeurs par défaut et terminez l'installation. L'installation peut prendre quelques minutes.
Le démarrage du serveur Jenkins est simple. Il suffit de cliquer sur la touche Windows et de rechercher "Services". Dans la fenêtre Services, recherchez Jenkins et cliquez sur le bouton de lecture en haut.
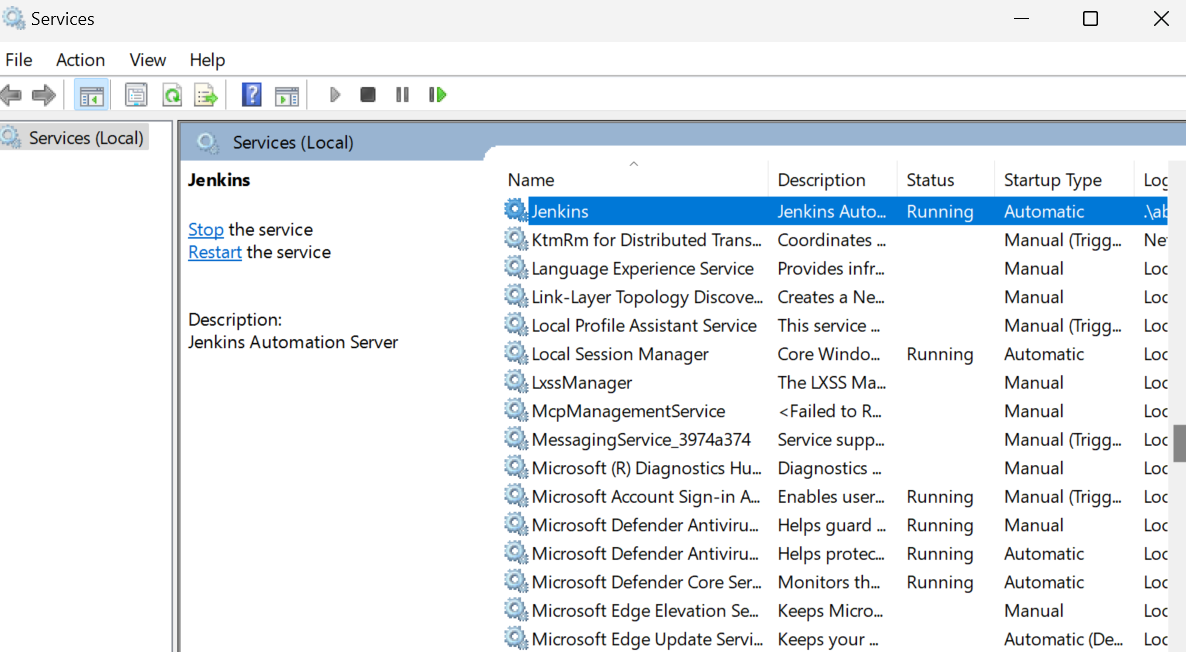
Par défaut, Jenkins s'exécute à l'adresse https://localhost:8080/. Il suffit de coller cette URL dans un navigateur pour accéder au tableau de bord. Pour entrer dans le tableau de bord Jenkins, vous devez saisir le mot de passe de l'administrateur.
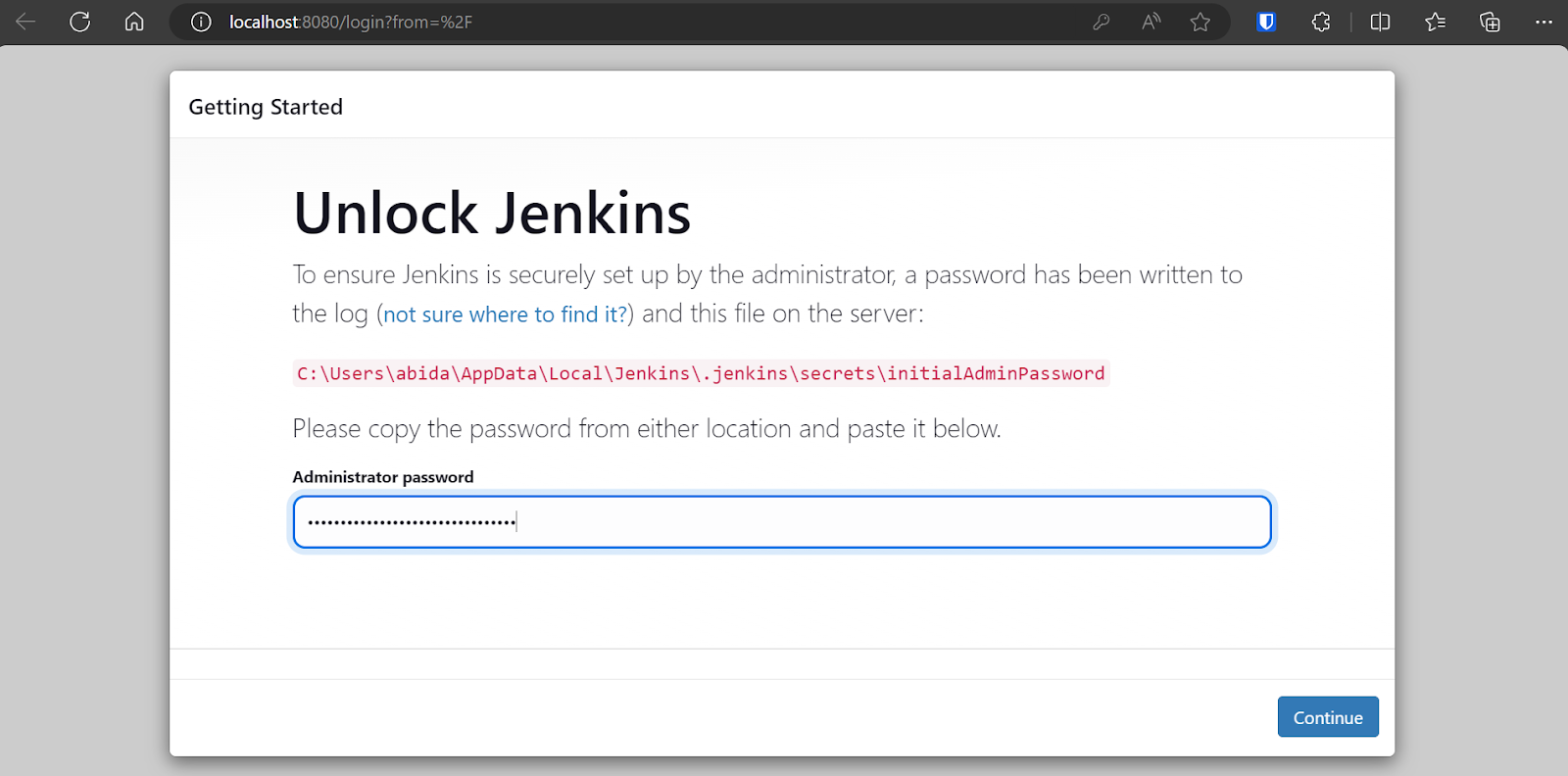
Pour obtenir le mot de passe par défaut de l'administrateur, accédez au répertoire Jenkins et localisez et ouvrez le fichier Jenkins.err.log.
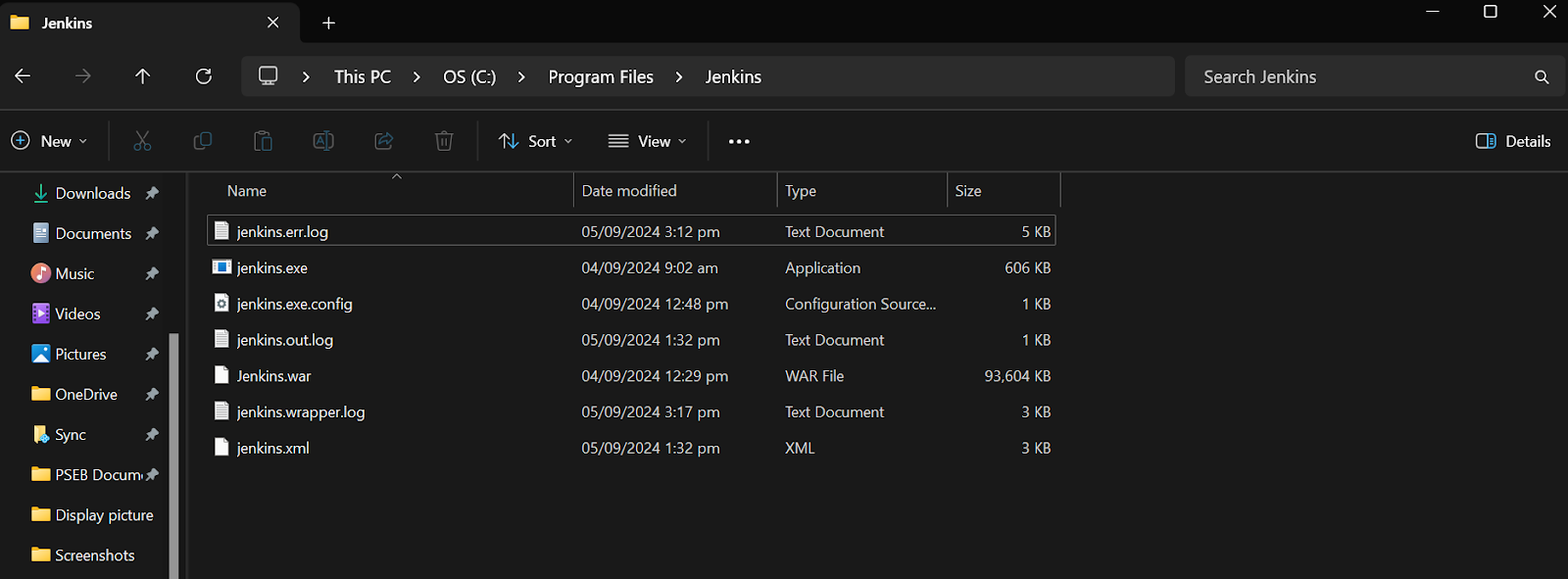
Faites défiler le fichier d'erreur Jenkins pour trouver le mot de passe généré. Copiez-le et collez-le dans le champ de saisie du mot de passe de l'administrateur.
Ensuite, le serveur prendra quelques minutes pour installer les outils et les extensions nécessaires.
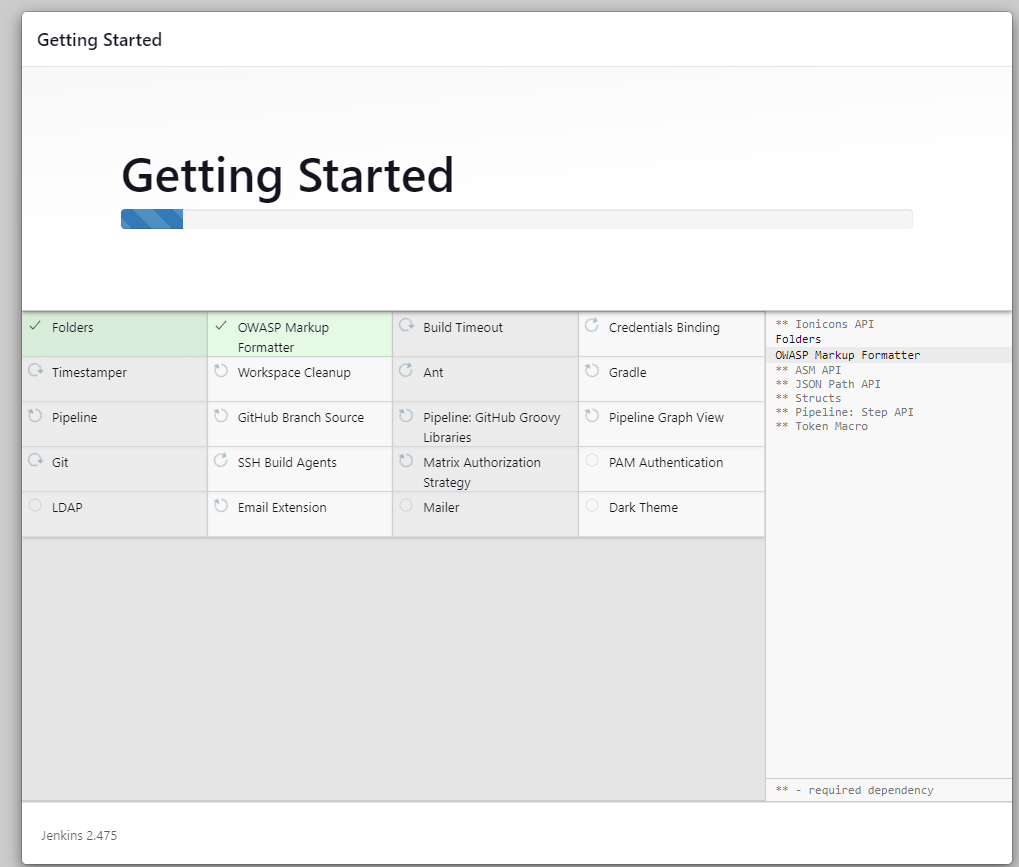
Une fois l'installation du serveur terminée, il vous sera demandé de créer un nouvel utilisateur. Saisissez toutes les informations nécessaires et cliquez sur le bouton "Enregistrer et continuer".
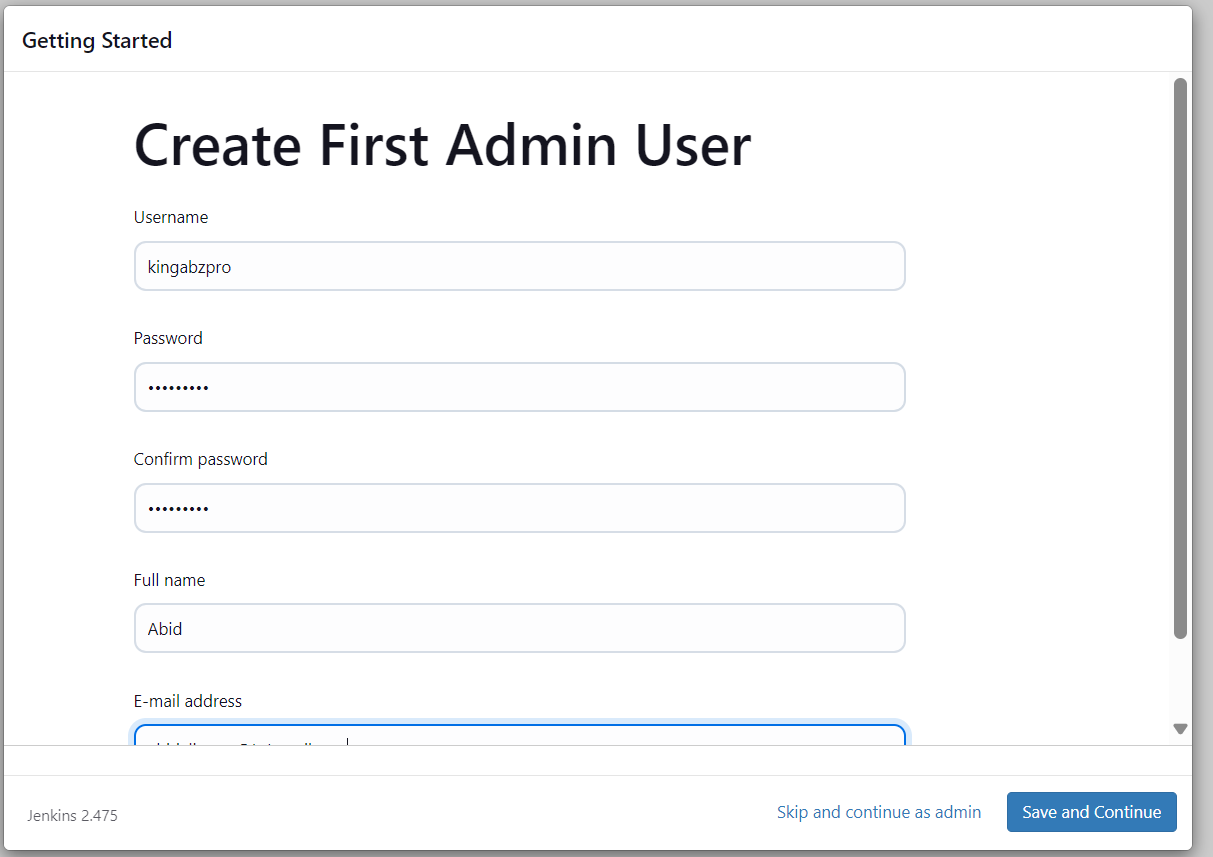
Nous serons dirigés vers le tableau de bord, où nous créerons, visualiserons et exécuterons divers pipelines Jenkins.
Les agents, également appelés nœuds, sont des machines configurées pour exécuter des tâches envoyées par le serveur principal de Jenkins. Ces agents fournissent l'environnement et le calcul nécessaires à l'exécution des pipelines. Un agent Windows 11 est disponible par défaut, mais nous pouvons toujours créer notre propre agent avec des options personnalisées.
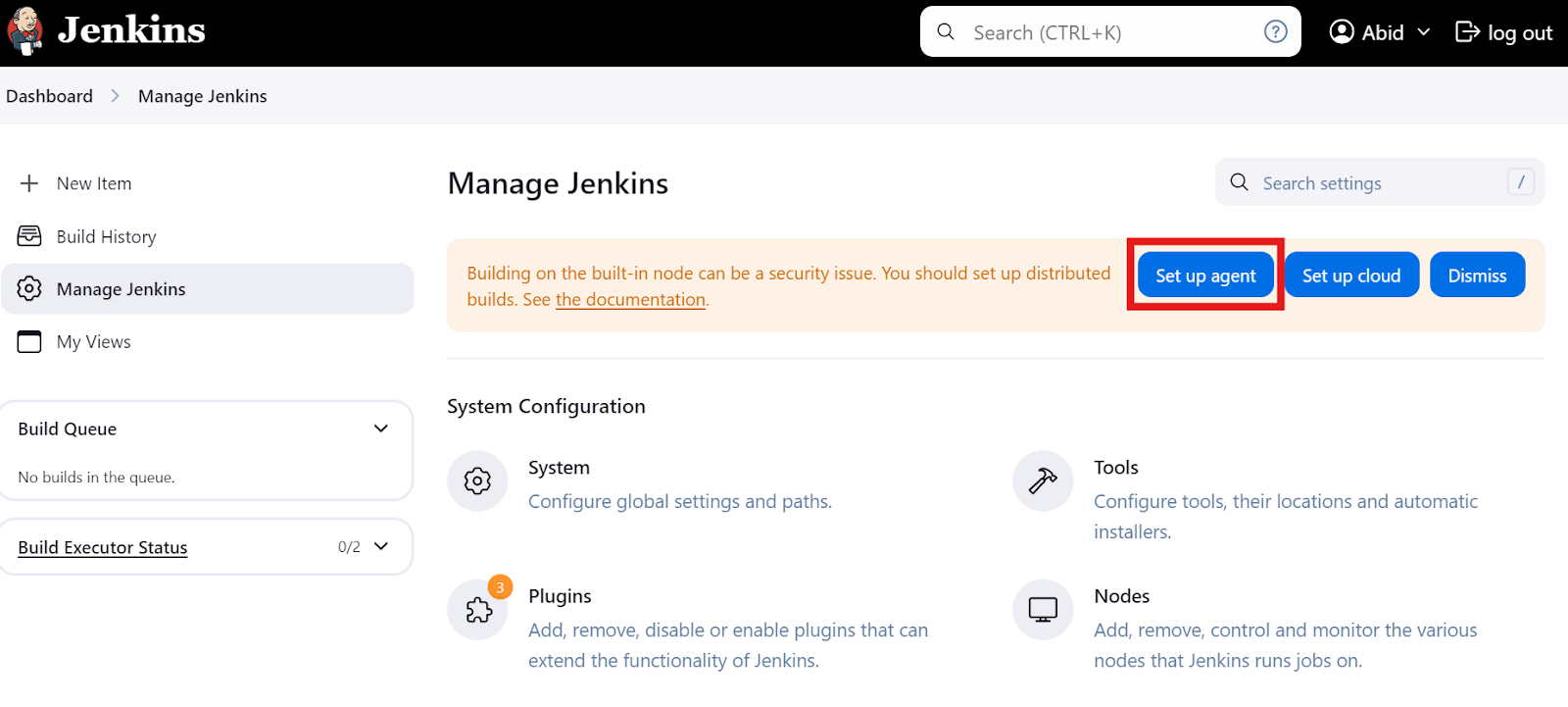
Sur le tableau de bord principal, cliquez sur l'option "Gérer Jenkins", puis sur le bouton "Configurer un agent", comme indiqué ci-dessous. Vous pouvez également cliquer sur le bouton "Nœuds" pour créer et gérer des agents.
Saisissez le nom de l'agent et sélectionnez le type "Agent permanent".
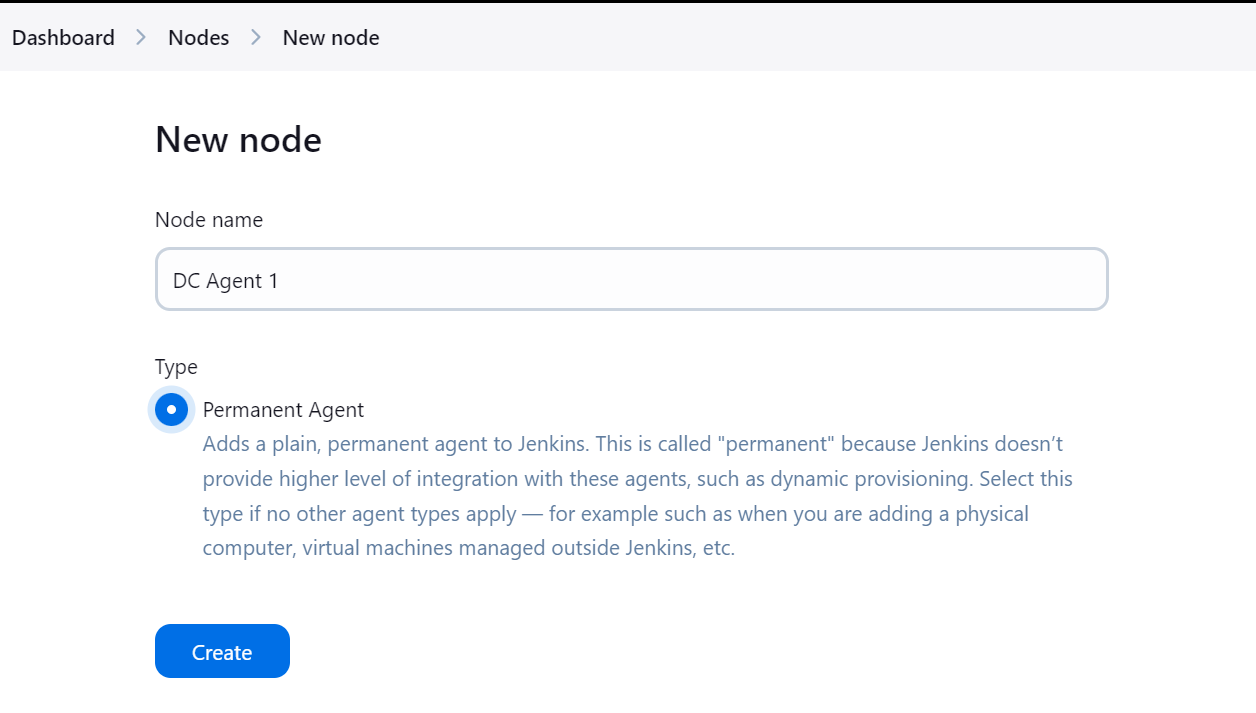
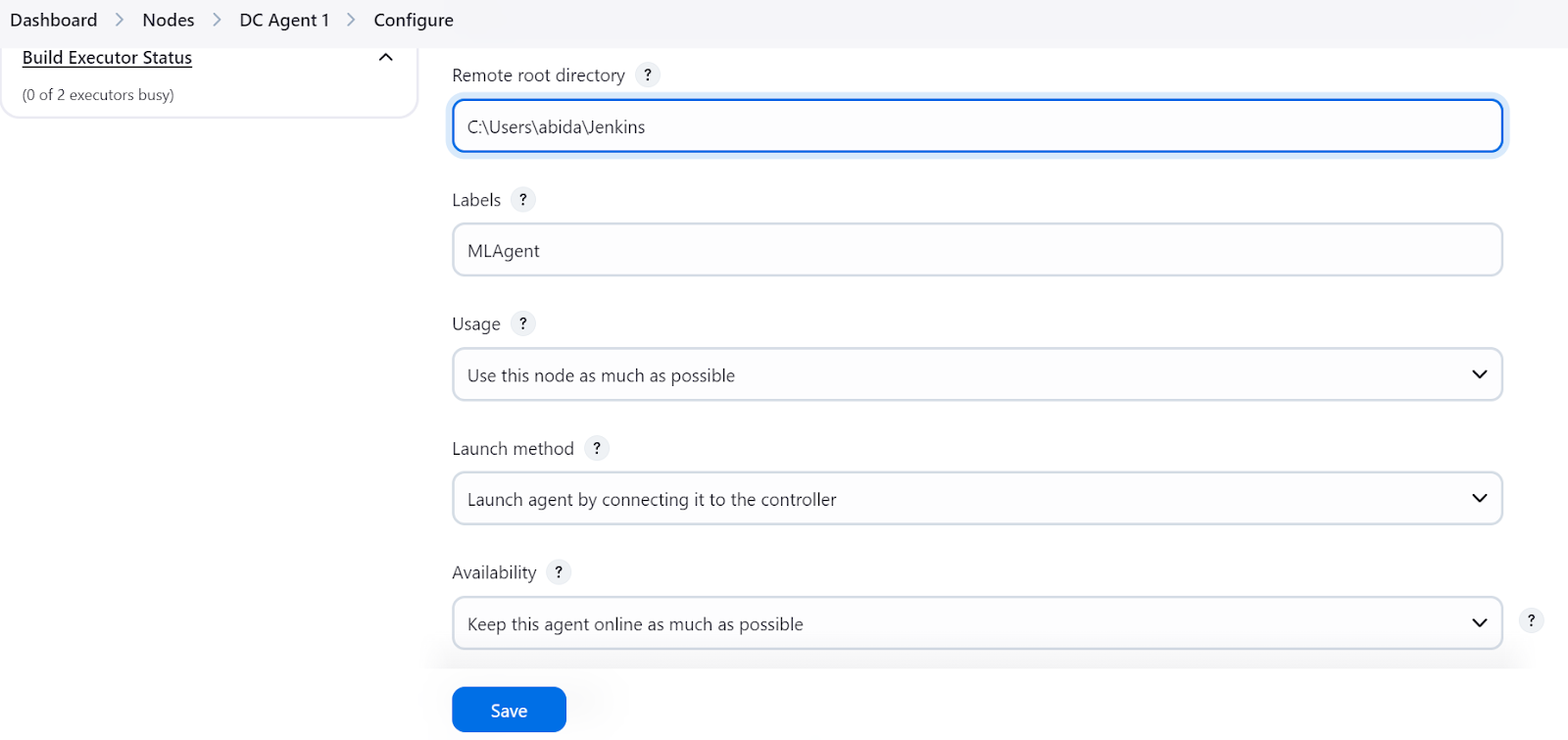
Veillez à fournir à l'agent un répertoire dans lequel tous les fichiers et journaux seront enregistrés. Ajoutez une étiquette et conservez les autres paramètres par défaut. Lors de la création du pipeline, nous utiliserons l'étiquette de l'agent pour exécuter les tâches.
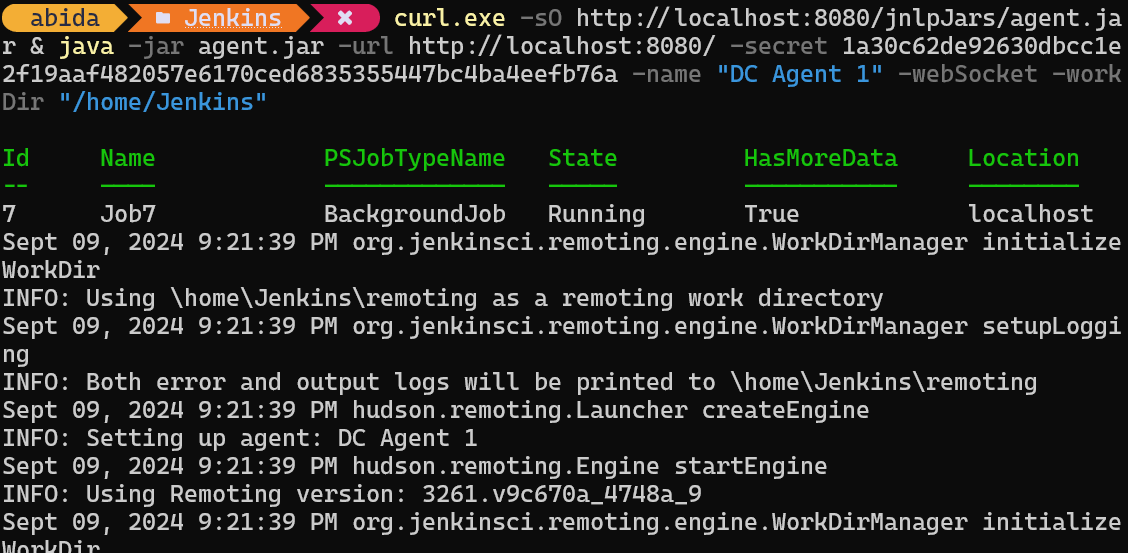
Lorsque vous appuyez sur le bouton "Enregistrer", une invite apparaît, nous demandant de copier et de coller la commande appropriée dans le terminal en fonction de notre système d'exploitation.
curl.exe -sO http://localhost:8080/jnlpJars/agent.jar & java -jar agent.jar -url http://localhost:8080/ -secret 1a30c62de92630dbcc1e2f19aaf482057e6170ced6835355447bc4ba4eefb76a -name "DC Agent 1" -webSocket -workDir "/home/Jenkins"Après avoir collé et exécuté la commande dans le terminal, nous verrons un message de succès indiquant que notre agent, dans mon cas, DC Agent 1, s'exécute en arrière-plan.
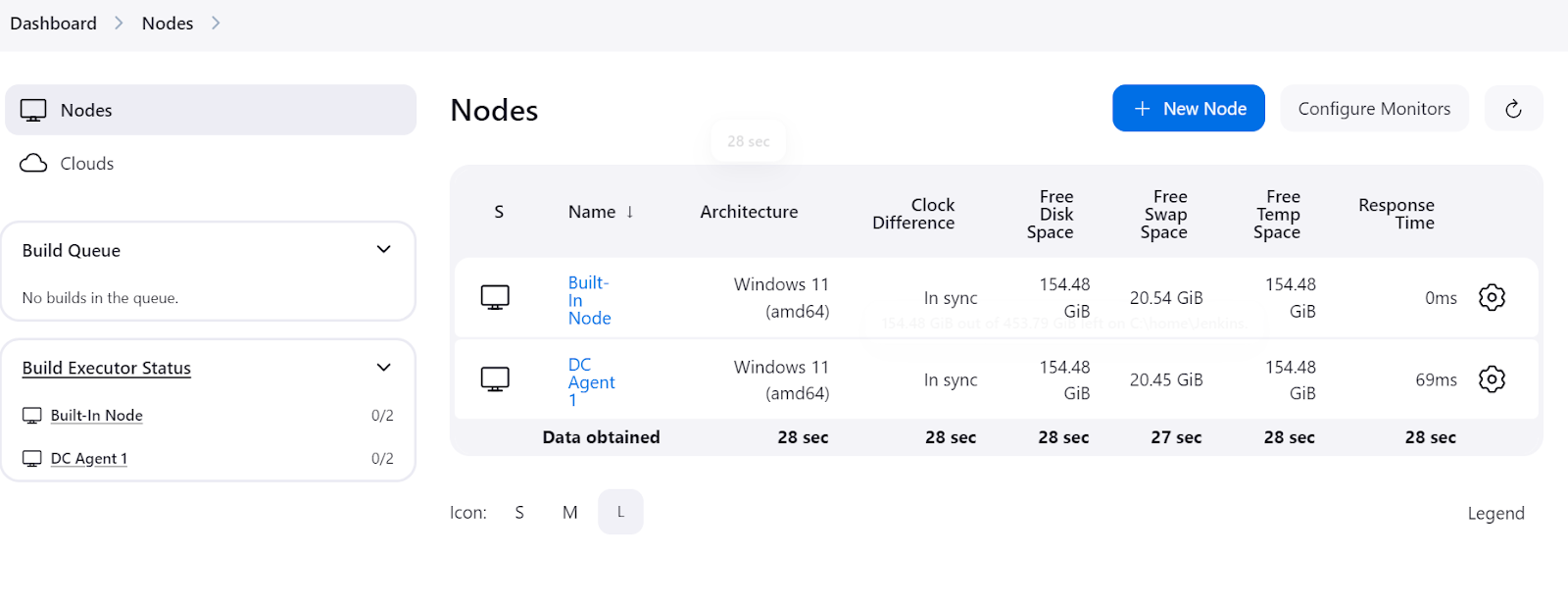
Pour vérifier si l'agent est en cours d'exécution et prêt à exécuter un travail, accédez au tableau de bord Jenkins, cliquez sur "Manage Jenkins", puis cliquez sur le bouton "Nodes" pour afficher l'état de l'agent.
Un pipeline Jenkins est une série d'étapes automatisées qui facilitent la formation, l'évaluation et le déploiement des modèles. Il définit ces processus à l'aide d'un simple script de programmation, ce qui facilite la gestion et l'automatisation des flux de travail des projets.
Dans cette section, nous allons créer un exemple de pipeline Jenkins et utiliser notre agent nouvellement créé comme exécuteur de pipeline.
Dans le tableau de bord, cliquez sur le bouton "Nouvel élément", saisissez le nom de l'élément, sélectionnez l'option "Pipeline" et cliquez sur "OK".
Ensuite, une invite nous demandera de configurer le pipeline. Descendez jusqu'à la section "Pipeline", où nous devons écrire le script du pipeline Jenkins.
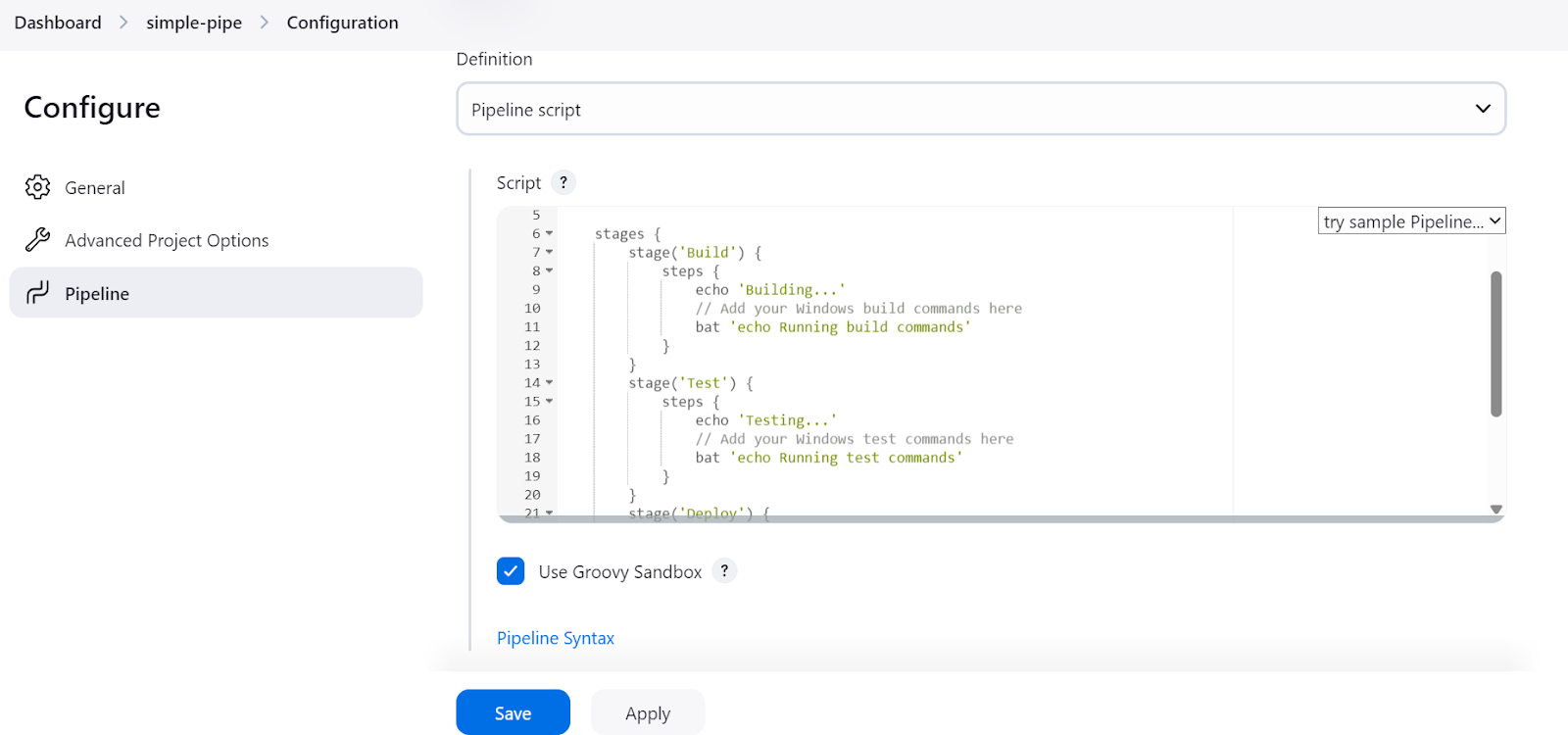
Dans le script du pipeline Jenkins, nous commençons par configurer l'environnement et l'agent. Dans notre cas, nous paramétrons le site agent en lui fournissant l'étiquette de l'agent que nous avons définie précédemment.
Ensuite, nous rédigerons une section stages dans laquelle seront ajoutées toutes les étapes de la filière (Build, Test, Deploy). Dans notre cas, nous nous contentons d'imprimer à l'aide de la commande echo et d'exécuter les commandes du terminal à l'aide de la commande bat.
bat est utilisé pour Windows 11sh est pour LinuxC'est tout. C'est aussi simple que cela. Voici le code du script :
pipeline {
agent {
label 'MLAgent' // Ensure this label matches your Windows 11 agent
}
stages {
stage('Build') {
steps {
echo 'Building...'
// Add your Windows build commands here
bat 'echo Running build commands'
}
}
stage('Test') {
steps {
echo 'Testing...'
// Add your Windows test commands here
bat 'echo Running test commands'
}
}
stage('Deploy') {
steps {
echo 'Deploying...'
// Add your Windows deploy commands here
bat 'echo Running deploy commands'
}
}
}
}Après avoir ajouté le script, cliquez sur les boutons "Appliquer" et "Enregistrer".
Cliquez sur le bouton "Build Now" pour tester et exécuter le pipeline. Pour connaître son statut, cliquez sur le bouton "Statut".
Une fois l'exécution terminée, vous pouvez consulter les journaux en cliquant sur l'exécution concernée dans le menu "Statut".
Cliquez sur le lien "Last build (#2)" et cliquez ensuite sur le bouton "Console Output". Cela nous amènera à la fenêtre de sortie de la console, où nous pourrons trouver les journaux et les résultats du pipeline.
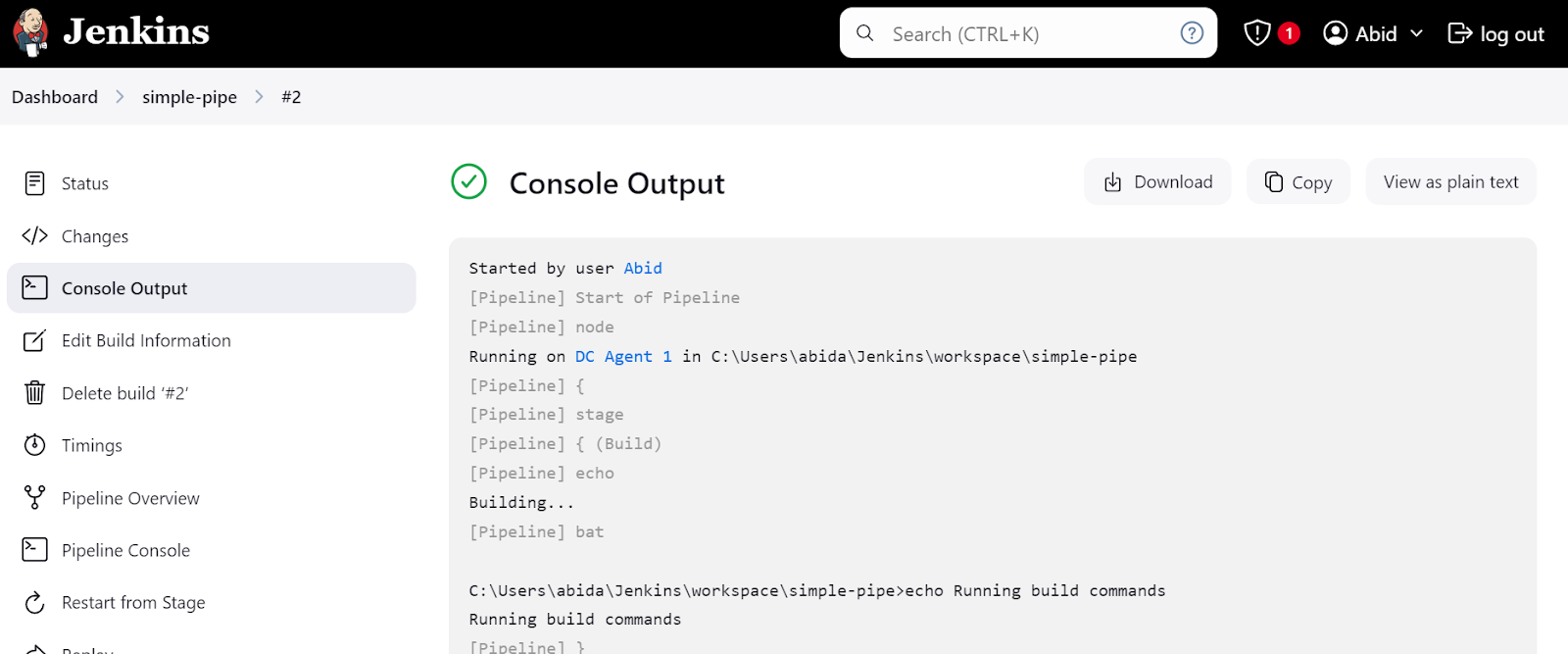
Nous pouvons même cliquer sur le bouton "Console du pipeline" pour visualiser en détail chaque étape du pipeline. Il s'agit de la sortie, du temps de démarrage et d'achèvement, des commandes de pipeline et des journaux.
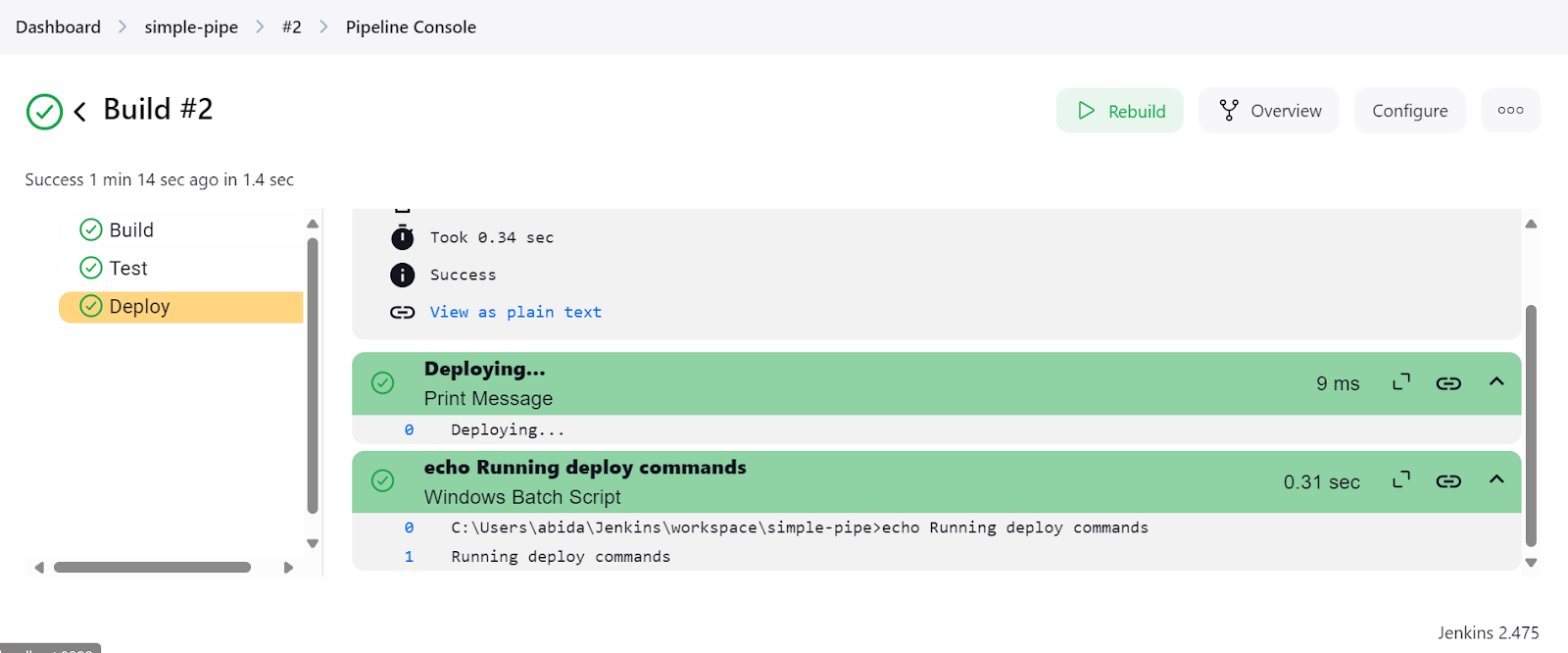
Une fois l'installation de Jenkins terminée, la création et l'exécution de pipelines ont été faciles et rapides. Il m'a fallu moins d'une heure pour comprendre le script et créer le mien. J'utiliserai Jenkins au lieu de GitHub Actions parce qu'il m'offre plus de flexibilité.
Author's opinion
Après l'introduction initiale à Jenkins, il est temps pour nous de passer aux choses sérieuses et de travailler sur le projet MLOps.
Nous allons créer deux pipelines : Le premier pipeline sera l'IC, qui chargera et traitera les données, entraînera le modèle, évaluera le modèle et testera le serveur du modèle. Ensuite, il lancera le pipeline CD, en démarrant le serveur d'inférence du modèle.
Pour comprendre le processus en détail, suivez le cours CI/CD pour l'apprentissage automatique, qui vous apprend à rationaliser les processus de développement de l'apprentissage automatique.
Comme pour tout projet, nous devons créer les fichiers du projet, y compris les fichiers Python de chargement des données, d'entraînement du modèle, d'évaluation du modèle et de service du modèle. Nous avons également besoin d'un fichier requirements .txt pour installer les paquets Python nécessaires.
Dans ce script, nous allons charger un jeu de données scikit-learn appelé le jeu de données Wine et le convertir en un DataFrame pandas. Ensuite, nous diviserons l'ensemble de données en ensembles de formation et de test. Enfin, nous enregistrerons les données traitées dans un fichier pickle.
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
import joblib
def load_data():
# Load the wine dataset
wine = load_wine(as_frame=True)
data = pd.DataFrame(data=wine.data, columns=wine.feature_names)
data["target"] = wine.target
print(data.head())
return data
def split_data(data, target_column="target"):
X = data.drop(columns=[target_column])
y = data[target_column]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test
def save_preprocessed_data(X_train, X_test, y_train, y_test, file_path):
joblib.dump((X_train, X_test, y_train, y_test), file_path)
if __name__ == "__main__":
data = load_data()
X_train, X_test, y_train, y_test = split_data(data)
save_preprocessed_data(X_train, X_test, y_train, y_test, "preprocessed_data.pkl")Dans ce fichier, nous chargerons les données traitées, nous entraînerons un classificateur de forêt aléatoire et nous enregistrerons le modèle sous la forme d'un fichier pickle.
from sklearn.ensemble import RandomForestClassifier
import joblib
def load_preprocessed_data(file_path):
return joblib.load(file_path)
def train_model(X_train, y_train):
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
return model
def save_model(model, file_path):
joblib.dump(model, file_path)
if __name__ == "__main__":
X_train, X_test, y_train, y_test = load_preprocessed_data("preprocessed_data.pkl")
model = train_model(X_train, y_train)
save_model(model, "model.pkl")Pour évaluer le modèle, nous chargerons à la fois le modèle et l'ensemble de données prétraitées, nous générerons un rapport de classification et nous imprimerons le score de précision.
import joblib
from sklearn.metrics import accuracy_score, classification_report
def load_model(file_path):
return joblib.load(file_path)
def load_preprocessed_data(file_path):
return joblib.load(file_path)
def evaluate_model(model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return accuracy, report
if __name__ == "__main__":
X_train, X_test, y_train, y_test = load_preprocessed_data("preprocessed_data.pkl")
model = load_model("model.pkl")
accuracy, report = evaluate_model(model, X_test, y_test)
print(f"Model Accuracy: {accuracy}")
print(f"Classification Report:\n{report}")Pour le service de modèle, nous utiliserons FastAPI pour créer une API REST où les utilisateurs peuvent saisir des caractéristiques et générer des prédictions. Normalement, les étiquettes sont génériques. Pour rendre les choses plus intéressantes, nous changerons les catégories de vins en Verdante, Rubresco et Floralis.
Lorsque nous exécutons ce fichier, nous lançons le serveur FastAPI, auquel nous pouvons accéder via la commande curl ou en utilisant la bibliothèque requests dans Python.
from typing import List
import joblib
import uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
# Define the labels corresponding to the target classes
LABELS = [
"Verdante", # A vibrant and fresh wine, inspired by its balanced acidity and crisp flavors.
"Rubresco", # A rich and robust wine, named for its deep, ruby color and bold taste profile.
"Floralis", # A fragrant and elegant wine, known for its floral notes and smooth finish.
]
class Features(BaseModel):
features: List[float]
def load_model(file_path):
return joblib.load(file_path)
model = load_model("model.pkl")
@app.post("/predict")
def predict(features: Features):
# Get the numerical prediction
prediction_index = model.predict([features.features])[0]
# Map the numerical prediction to the label
prediction_label = LABELS[prediction_index]
return {"prediction": prediction_label}
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=9000)Ce fichier nous aidera à télécharger et à installer tous les paquets nécessaires à l'exécution des fichiers Python ci-dessus.
scikit-learn
pandas
fastapi
uvicornNous allons maintenant créer des pipelines Jenkins d'intégration continue. Tout comme nous avons créé un simple pipeline, nous allons créer un "MLOps-pipe" et écrire le script qui couvre tout, du traitement des données à l'évaluation du modèle.
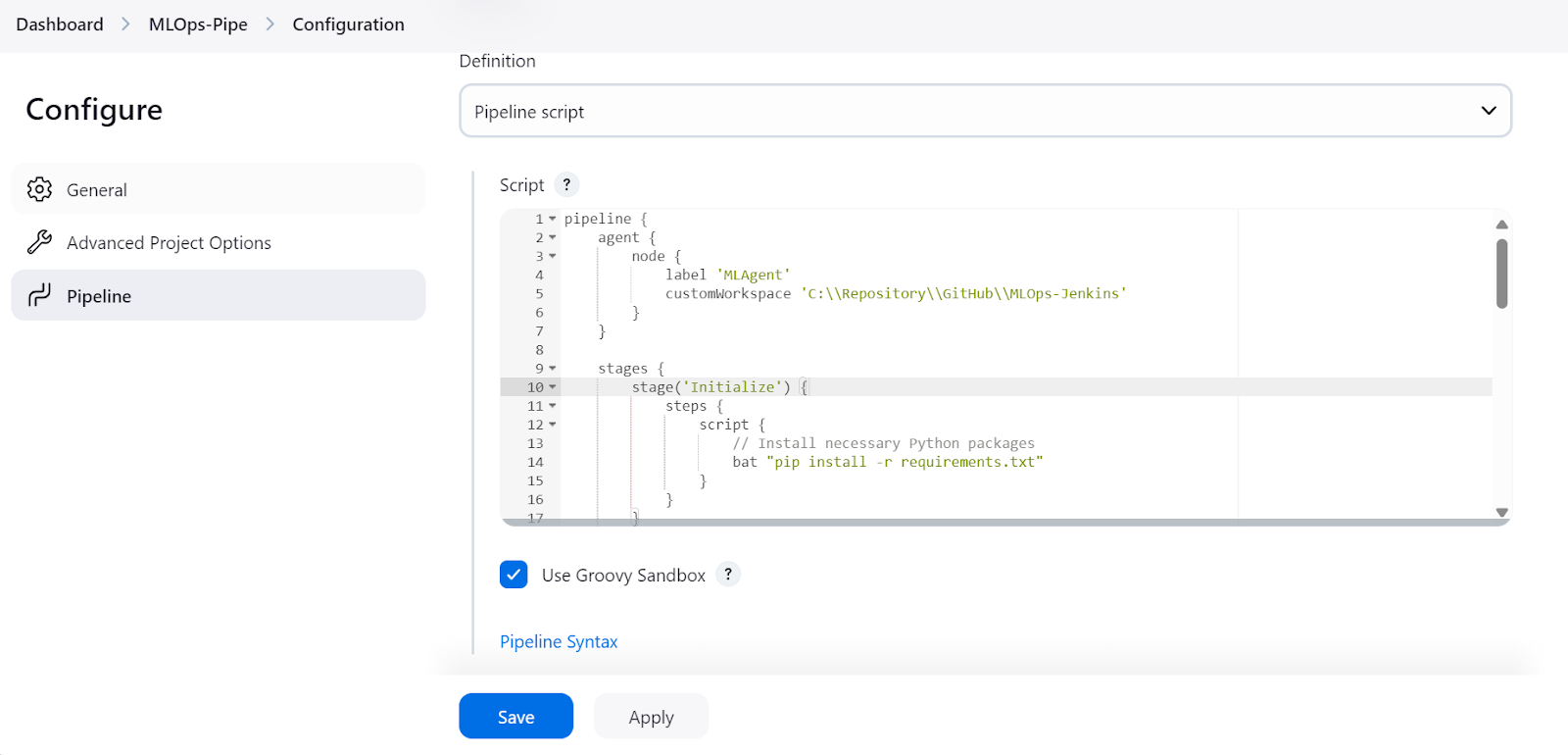
Le script du pipeline MLOps comprend les éléments suivants
agent avec le site label "MLAgent".Initialize).Load and Preprocess Data).Train Model).Evaluate Model).curl (Test Serve Model ).Note : La commande start /B lance une nouvelle fenêtre de terminal en arrière-plan et exécute le script de service de modèle. De plus, ce script du pipeline Jenkins ne fonctionne que sous Windows, et nous devons modifier les commandes pour Linux ou d'autres systèmes d'exploitation.
pipeline {
agent {
node {
label 'MLAgent'
customWorkspace 'C:\\Repository\\GitHub\\MLOps-Jenkins'
}
}
stages {
stage('Initialize') {
steps {
script {
// Install necessary Python packages
bat "pip install -r requirements.txt"
}
}
}
stage('Load and Preprocess Data') {
steps {
script {
// Run data loading script
bat "python data_loading.py"
}
}
}
stage('Train Model') {
steps {
script {
// Run model training script
bat "python model_training.py"
}
}
}
stage('Evaluate Model') {
steps {
script {
// Run model evaluation script
bat "python model_evaluation.py"
}
}
}
stage('Serve Model') {
steps {
script {
// Start FastAPI server in the background
bat 'start /B python model_serving.py'
// Wait for the server to start
sleep time: 10, unit: 'SECONDS'
}
}
}
stage('Test Serve Model') {
steps {
script {
// Test the server with sample values
bat '''
curl -X POST "http://127.0.0.1:9000/predict" ^
-H "Content-Type: application/json" ^
-d "{\\"features\\": [13.2, 2.77, 2.51, 18.5, 103.0, 1.15, 2.61, 0.26, 1.46, 3.0, 1.05, 3.33, 820.0]}"
'''
}
}
}
stage('Deploy Model') {
steps {
script {
// Trigger another Jenkins job for model serving
build job: 'ModelServingPipeline', wait: false
}
}
}
}
post {
always {
archiveArtifacts artifacts: '**.pkl', fingerprint: true
echo 'Pipeline execution complete.'
}
}
}Nous allons maintenant créer un pipeline de déploiement continu pour déployer et exécuter le serveur localement.
Le script du pipeline est simple. Nous commençons par définir l'agent et changer le répertoire de travail pour notre projet. Ensuite, nous faisons fonctionner le serveur indéfiniment.
Note : Il n'est pas recommandé de faire fonctionner un serveur dans Jenkins indéfiniment, car les pipelines doivent avoir un début et une fin définis. Pour cet exemple, nous supposerons que nous avons déployé l'application, mais dans la pratique, il est préférable d'intégrer Docker et d'exécuter l'application sur un serveur Docker.
Si vous souhaitez apprendre à penser comme un ingénieur en apprentissage automatique, envisagez de suivre la formation Développer des modèles d'apprentissage automatique pour la production avec un état d'esprit MLOps, qui vous permettra de former, documenter, maintenir et développer vos modèles d'apprentissage automatique au maximum de leur potentiel.
pipeline {
agent {
node {
label 'MLAgent'
customWorkspace 'C:/Repository/GitHub/MLOps-Jenkins/'
}
}
stages {
stage('Start FastAPI Server') {
steps {
script {
// Start the FastAPI server
bat 'python model_serving.py'
}
}
}
}
}Allez dans le pipeline "MLOps-pipe" et cliquez sur le bouton "Build Now" pour lancer le pipeline CI/CD.
Une fois que le pipeline est exécuté avec succès, il génère deux artefacts : l'un pour le modèle et l'autre pour l'ensemble des données traitées.
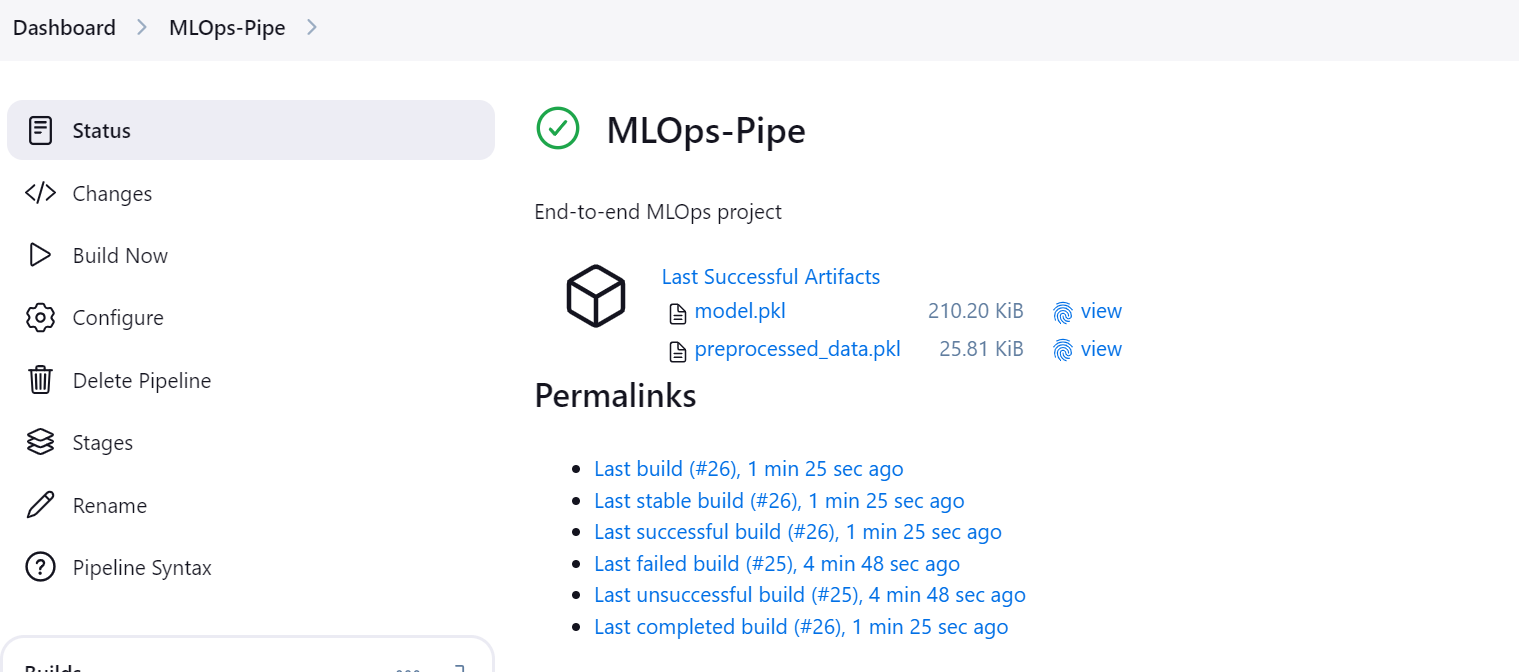
Cliquez sur le bouton "Stages" dans le tableau de bord Jenkins pour visualiser le pipeline et voir toutes les étapes.
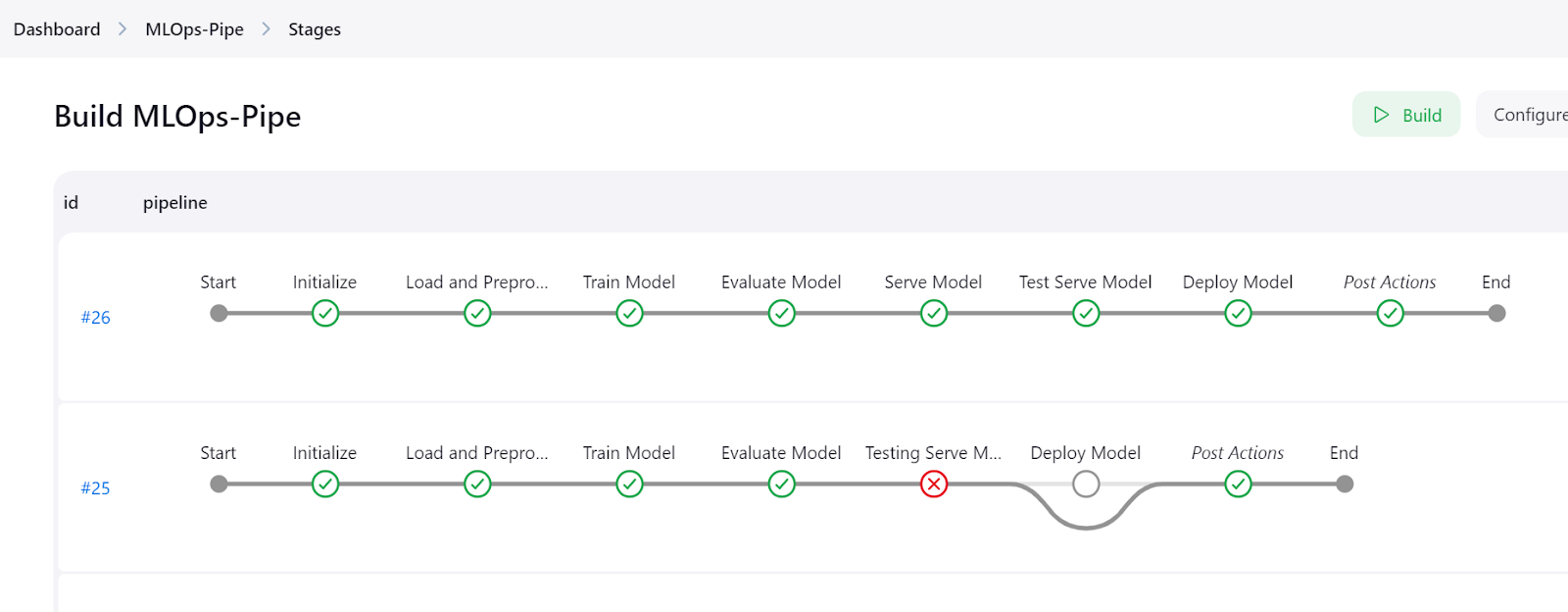
Pour consulter les journaux détaillés de chaque étape, consultez le menu "Console du pipeline".
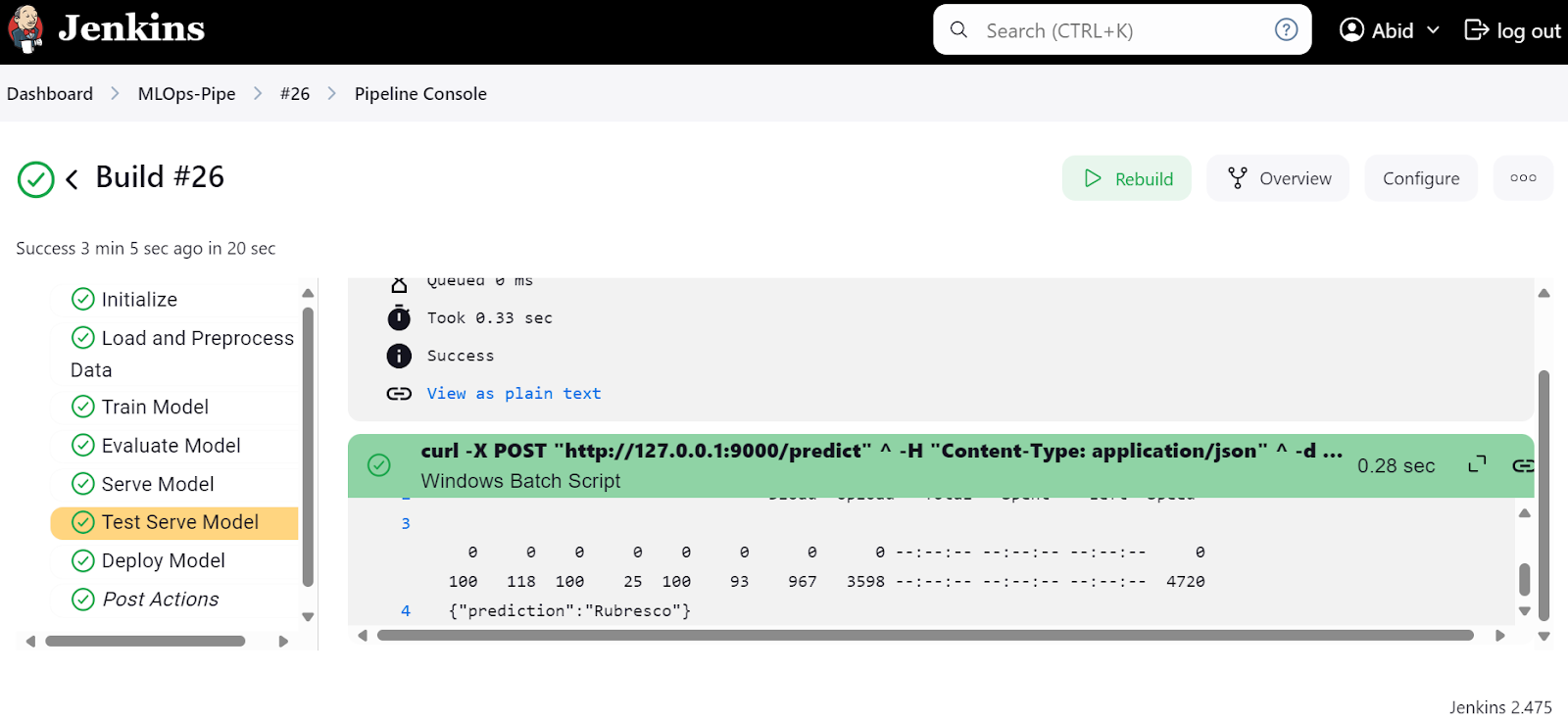
Nous pouvons également vérifier dans "ModelServingPipeline" que notre serveur fonctionne sur l'URL locale http://127.0.0.1:9000.
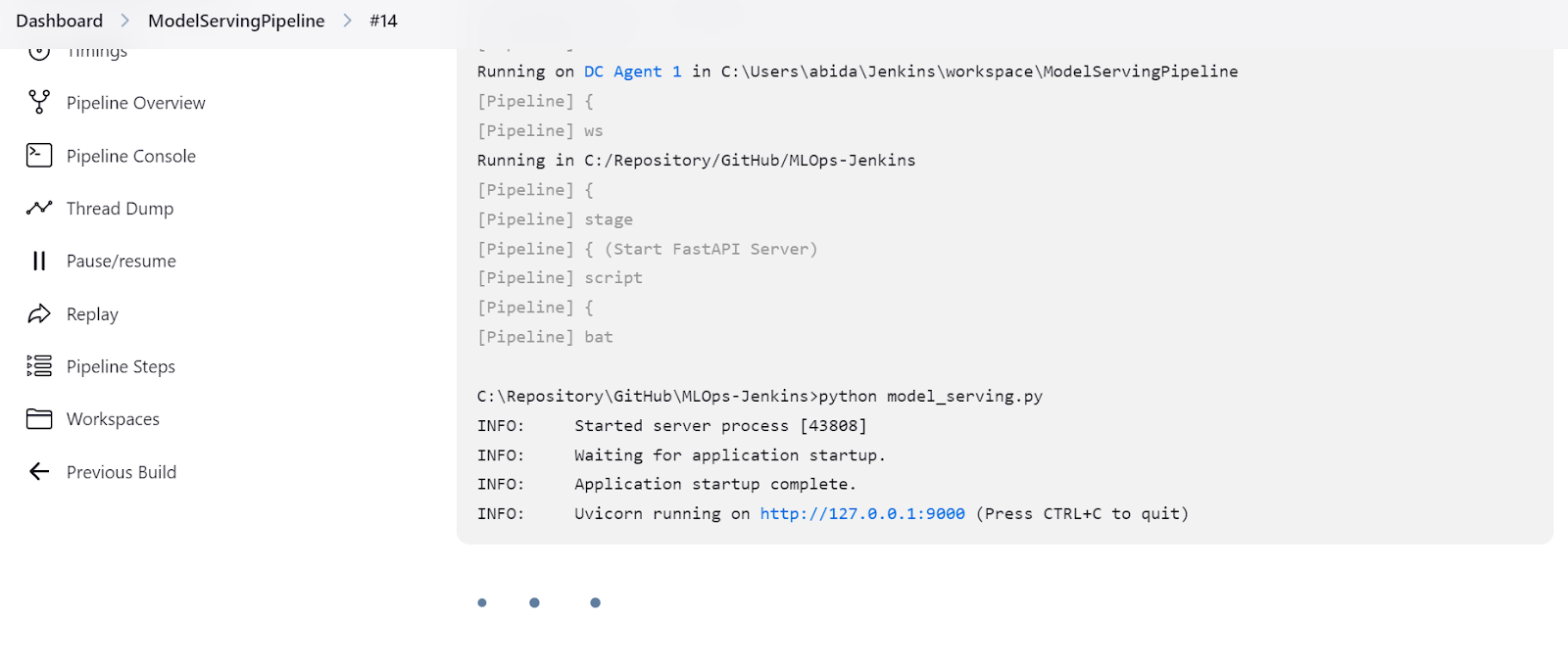
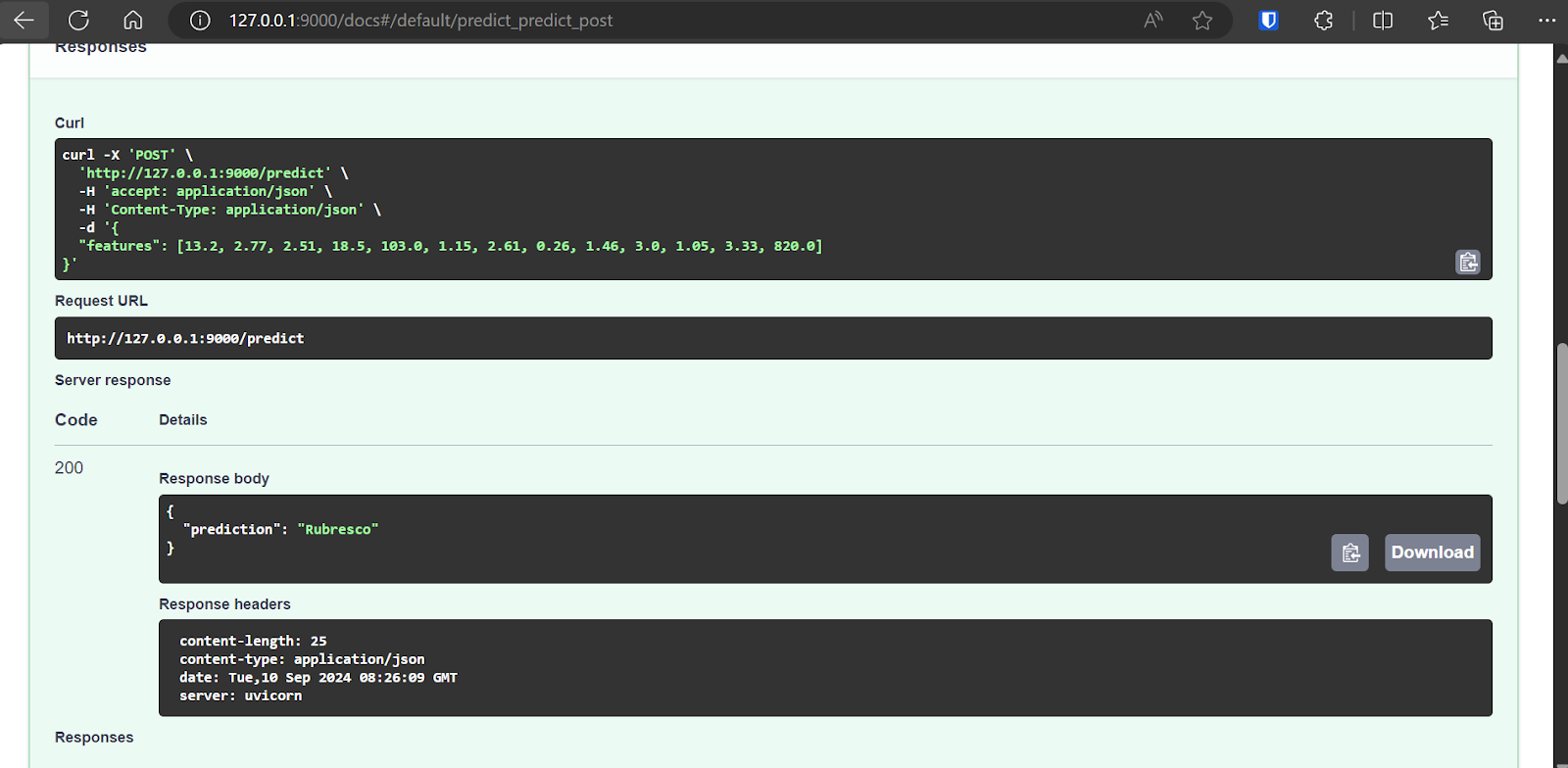
L'interface FastAPI est livrée avec une interface Swagger, à laquelle vous pouvez accéder en ajoutant /docs à l'URL locale : http://127.0.0.1:9000/docs.
L'interface Swagger nous permet de tester l'application FastAPI dans le navigateur. C'est simple, et nous pouvons voir que notre serveur modèle fonctionne bien. Les valeurs prédites de l'échantillon suggèrent que le type de vin est Rubresco.
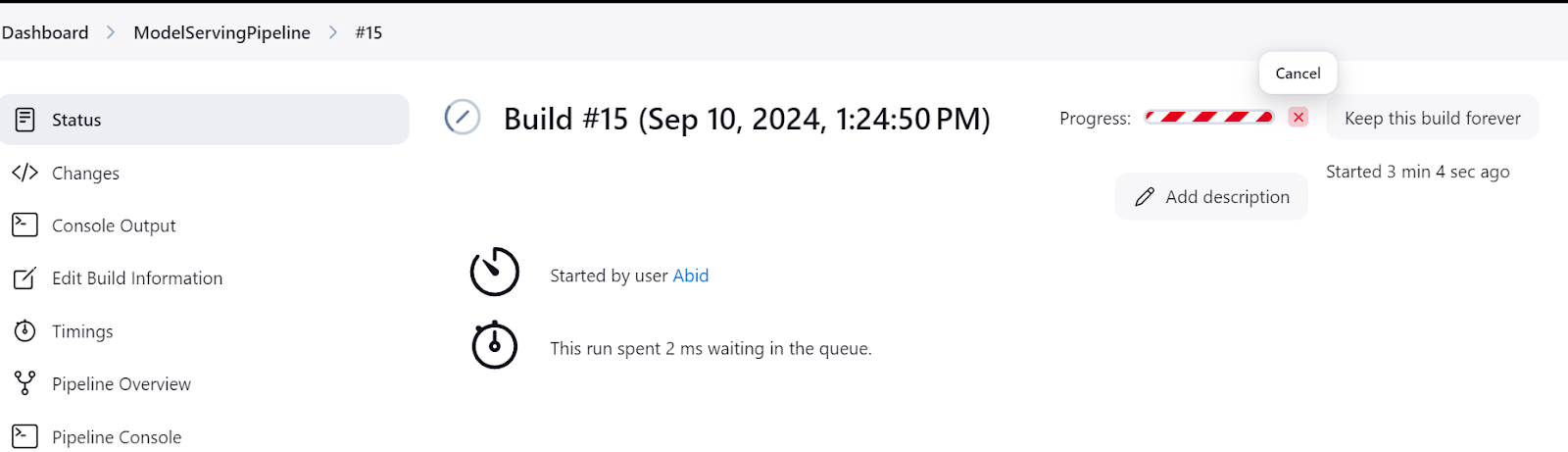
Veillez toujours à éteindre le serveur de modèles après avoir terminé vos expériences. Vous pouvez le faire en allant dans le menu "Status" du tableau de bord Jenkins et en cliquant sur le bouton "cross", comme indiqué ci-dessous :
L'ensemble du code, des ensembles de données, des modèles et des métafichiers de ce tutoriel est disponible sur le dépôt GitHub pour que vous puissiez l'utiliser : kingabzpro/MLOps-with-Jenkins.y : kingabzpro/MLOps-with-Jenkins.
Jenkins est un excellent serveur d'automatisation pour toutes sortes de tâches MLOps. Il s'agit d'une excellente alternative à GitHub Actions, car il offre plus de fonctionnalités, un meilleur contrôle et une plus grande confidentialité.
L'un des aspects les plus séduisants de Jenkins est sa simplicité de création et d'exécution des pipelines, ce qui le rend accessible aussi bien aux débutants qu'aux utilisateurs expérimentés.
Si vous souhaitez explorer des possibilités similaires en utilisant les Actions GitHub, ne manquez pas le tutoriel A Beginner's Guide to CI/CD for Machine Learning (Guide du débutant sur le CI/CD pour l'apprentissage automatique). Pour ceux qui souhaitent approfondir leur compréhension des MLOps, le cours Fully Automated MLOps est une ressource fantastique. Il offre un aperçu complet de l'architecture MLOps, des techniques CI/CD/CM/CT et des modèles d'automatisation pour déployer des systèmes ML capables de fournir une valeur constante au fil du temps.
Apprenez-en plus sur les MLOps grâce à ces cours !
Cours
Cours
Cours