
Kurs
MLOps-Konzepte
2 Std.
42.6K

In diesem Tutorial lernen wir, wie man Jenkins installiert und verwendet und wie man Agenten und Pipelines erstellt und ausführt.
Konkret werden wir:
Wenn du dein Wissen auffrischen möchtest, dann nimm an einem kurzen und unkomplizierten Kurs zu MLOps-Konzepten teil, in dem du lernst, wie du Machine-Learning-Modelle von Jupyter-Notizbüchern zu funktionierenden Modellen in der Produktion bringst, die einen echten Geschäftswert generieren.
Jenkins ist ein Open-Source-Automatisierungsserver, der eine wichtige Rolle im Entwicklungsprozess für maschinelles Lernen spielt, indem er die kontinuierliche Integration (CI) und das kontinuierliche Deployment (CD) ermöglicht.
Jenkins ist in Java geschrieben und hilft dabei, die Datenverarbeitung, das Training, die Auswertung und den Einsatz von Machine Learning-Projekten zu automatisieren, was es zu einem unverzichtbaren Werkzeug für MLOps-Praktiken macht.
Jenkins Eigenschaften:
Die Aufgabenautomatisierung mit Jenkins ist nur ein Teil des MLOps-Ökosystems. Du kannst dich über weitere Aufgaben informieren , indem du den Blog 25 Top MLOps Tools You Need to Know in 2024 liest. Es besteht aus Werkzeugen für die Verfolgung von Experimenten, die Verwaltung von Modell-Metadaten, die Orchestrierung von Arbeitsabläufen, die Versionierung von Daten und Pipelines, die Bereitstellung von Modellen sowie die Überwachung von Serving und Modellen in der Produktion.
Wir können Jenkins ganz einfach auf Linux und macOS installieren. Für die Installation unter Windows sind jedoch mehrere Schritte erforderlich. Diese Schritte umfassen die Installation des Java Development Kit, die Einrichtung der lokalen Sicherheitsrichtlinie, die Installation von Jenkins mit einem Domänenbenutzer und den Start des Jenkins-Servers.
Beginnen wir mit der Installation von Java. Wir müssen auf die Adoptium-Website gehen und die neueste LTS-Version für Windows 11 herunterladen.
Warum müssen wir OpenJDK installieren? Jenkins ist eine Java-basierte Anwendung, für die eine Java-Laufzeitumgebung (JRE) oder ein Java Development Kit (JDK) erforderlich ist.
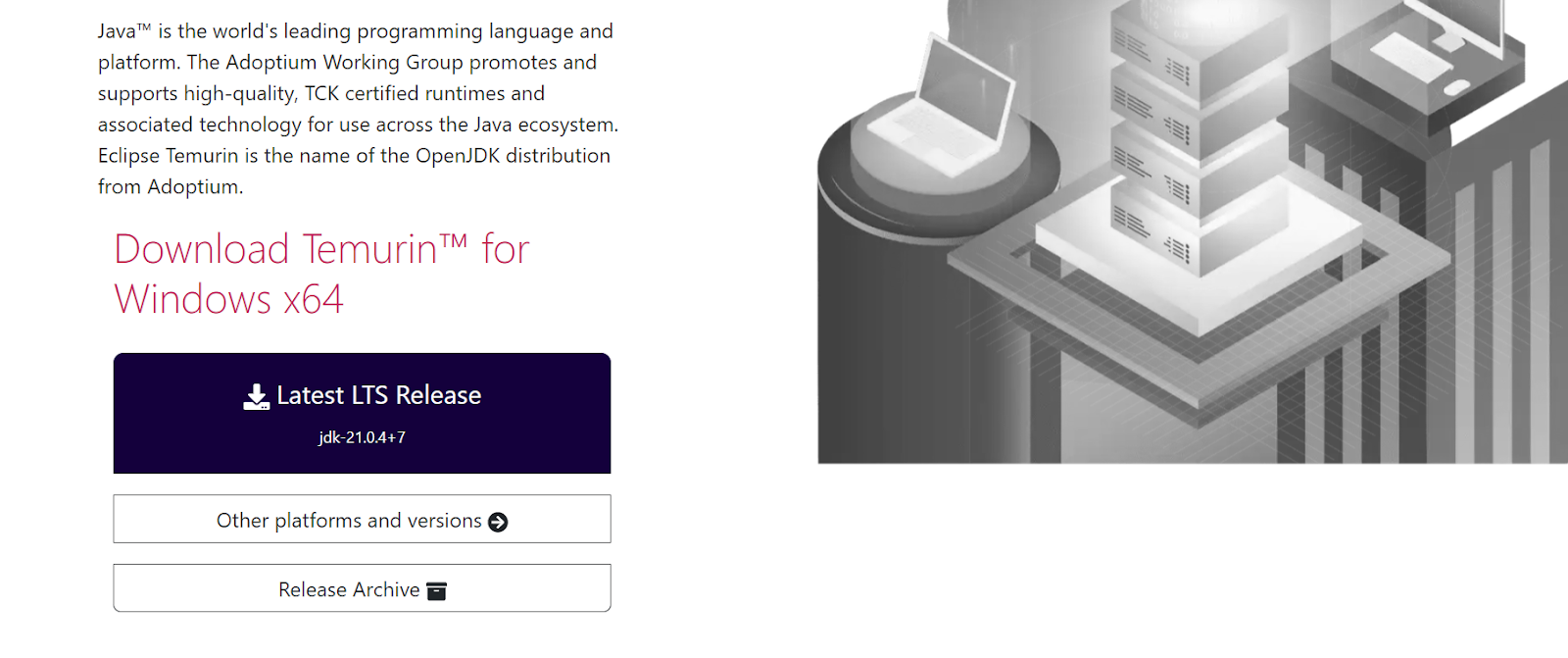
Bildquelle: Adoptium
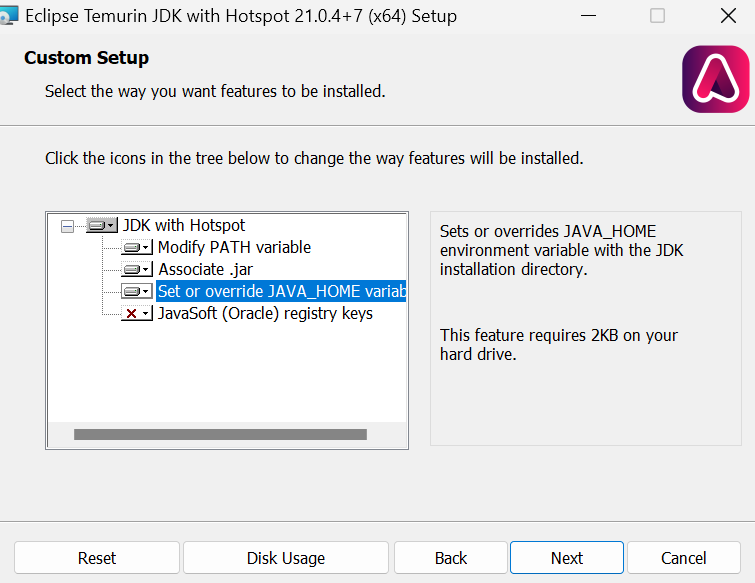
Installiere das OpenJDK mit den Standardwerten, außer dass wir das Häkchen bei "Set or override JAVA_HOME variable" setzen müssen.
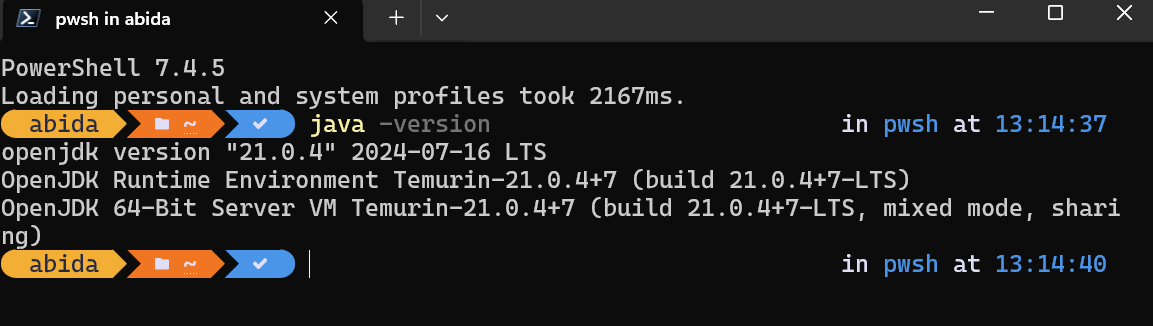
Nachdem die Installation abgeschlossen ist, können wir überprüfen, ob sie korrekt installiert wurde, indem wir java -version in das Terminalfenster eingeben:
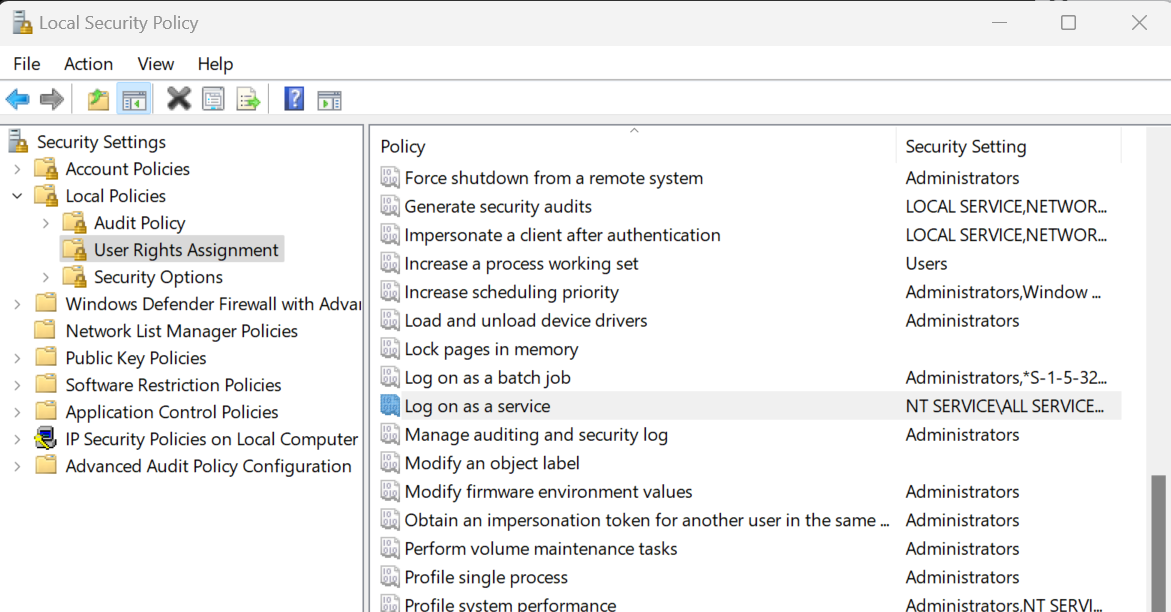
Um Jenkins zu installieren, musst du die "Lokale Sicherheitsrichtlinie" ändern, um den Benutzer-Login-Zugriff für den Installer zu ermöglichen. Drücke dazu die Tasten Win + R auf deiner Tastatur, gib "secpol.msc" ein und drücke die Eingabetaste. Navigiere dann zu "Lokale Richtlinien" > "Zuweisung von Benutzerrechten" > "Als Dienst anmelden".
Wir werden zu einem neuen Fenster weitergeleitet, in dem wir unseren Windows-Benutzernamen eingeben und auf die Schaltfläche "Namen prüfen" klicken. Danach drückst du auf "OK" und verlässt das Fenster "Lokale Sicherheitsrichtlinie".
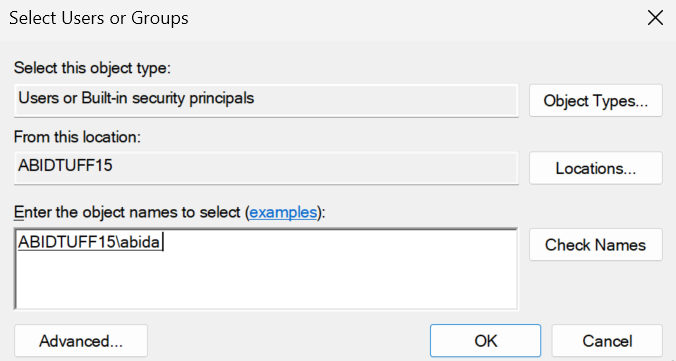
Gehe auf die jenkins.io Website und lade das Windows Installer Paket für Jenkins herunter.
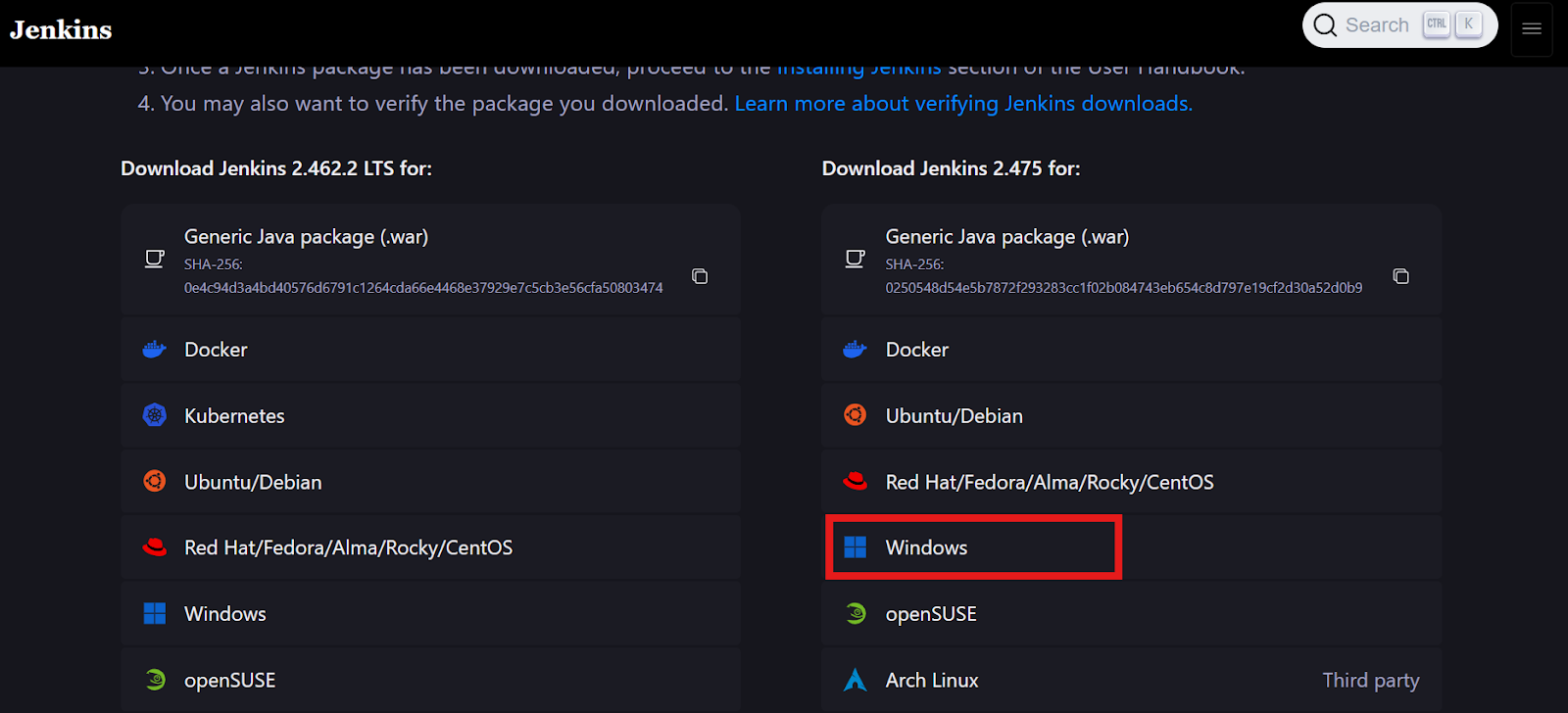
Bildquelle: jenkins.io
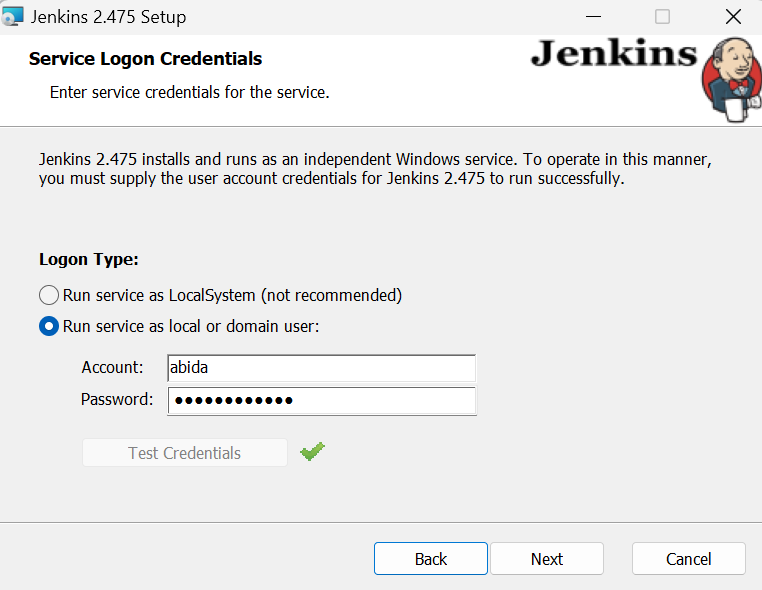
Wenn das Fenster "Dienst als lokaler oder Domänenbenutzer ausführen" erscheint, gibst du deinen Windows-Benutzernamen und dein Passwort ein und klickst dann auf die Schaltfläche "Anmeldeinformationen testen". Wenn sie genehmigt ist, klicke auf die Schaltfläche "Weiter".
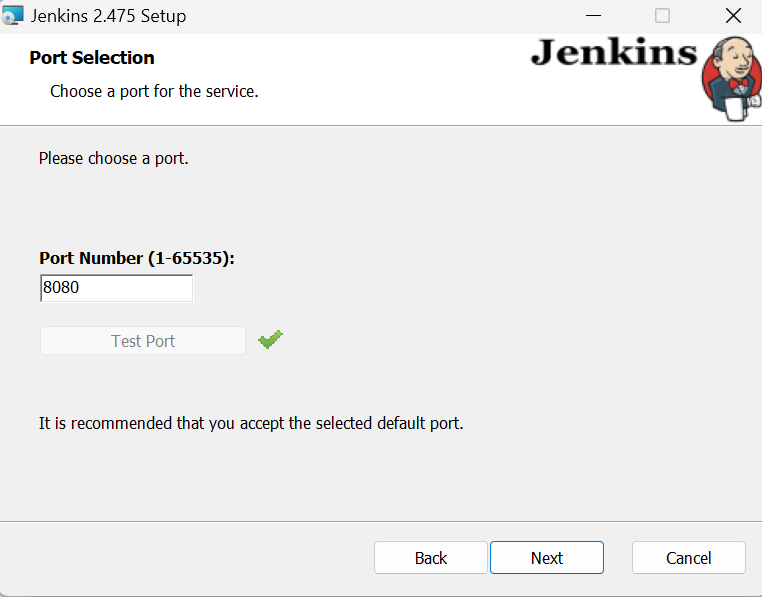
Behalte alles andere als Standard und beende die Installation. Es kann ein paar Minuten dauern, bis es eingerichtet ist.
Der Start des Jenkins-Servers ist ganz einfach. Alles, was wir tun müssen, ist auf die Windows-Taste zu klicken und nach "Dienste" zu suchen. Suche im Dienste-Fenster nach Jenkins und klicke oben auf die Schaltfläche "Abspielen".
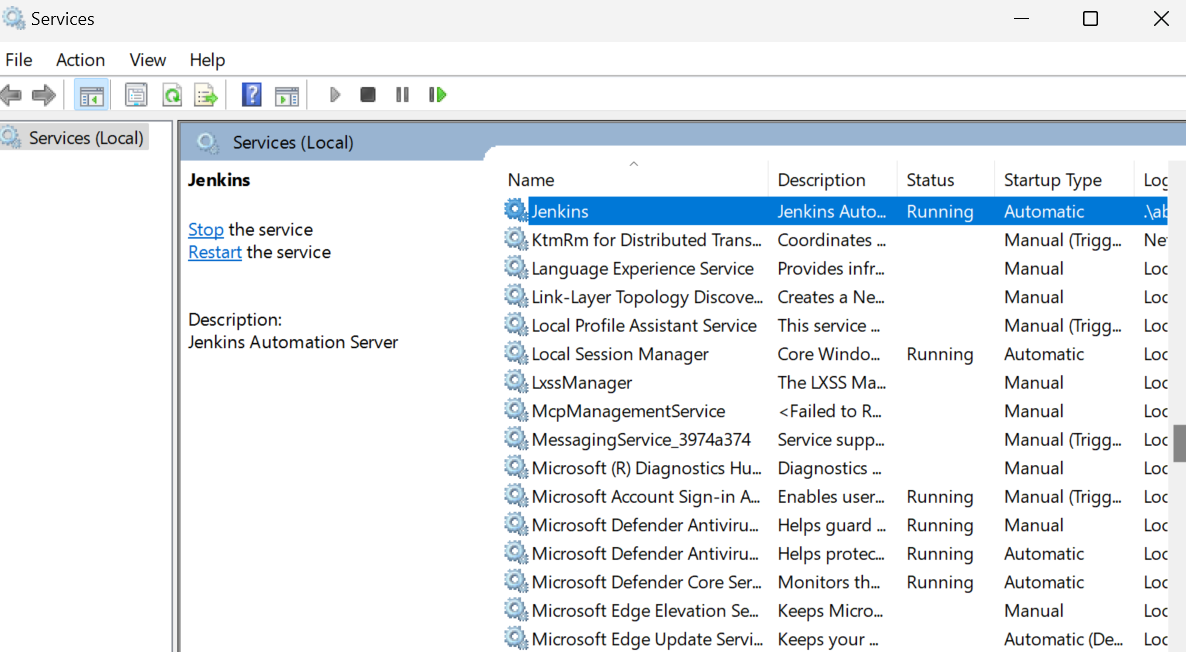
Standardmäßig läuft Jenkins unter https://localhost:8080/. Füge diese URL einfach in einen Browser ein, um auf das Dashboard zuzugreifen. Um das Jenkins Dashboard zu betreten, musst du das Administrator-Passwort eingeben.
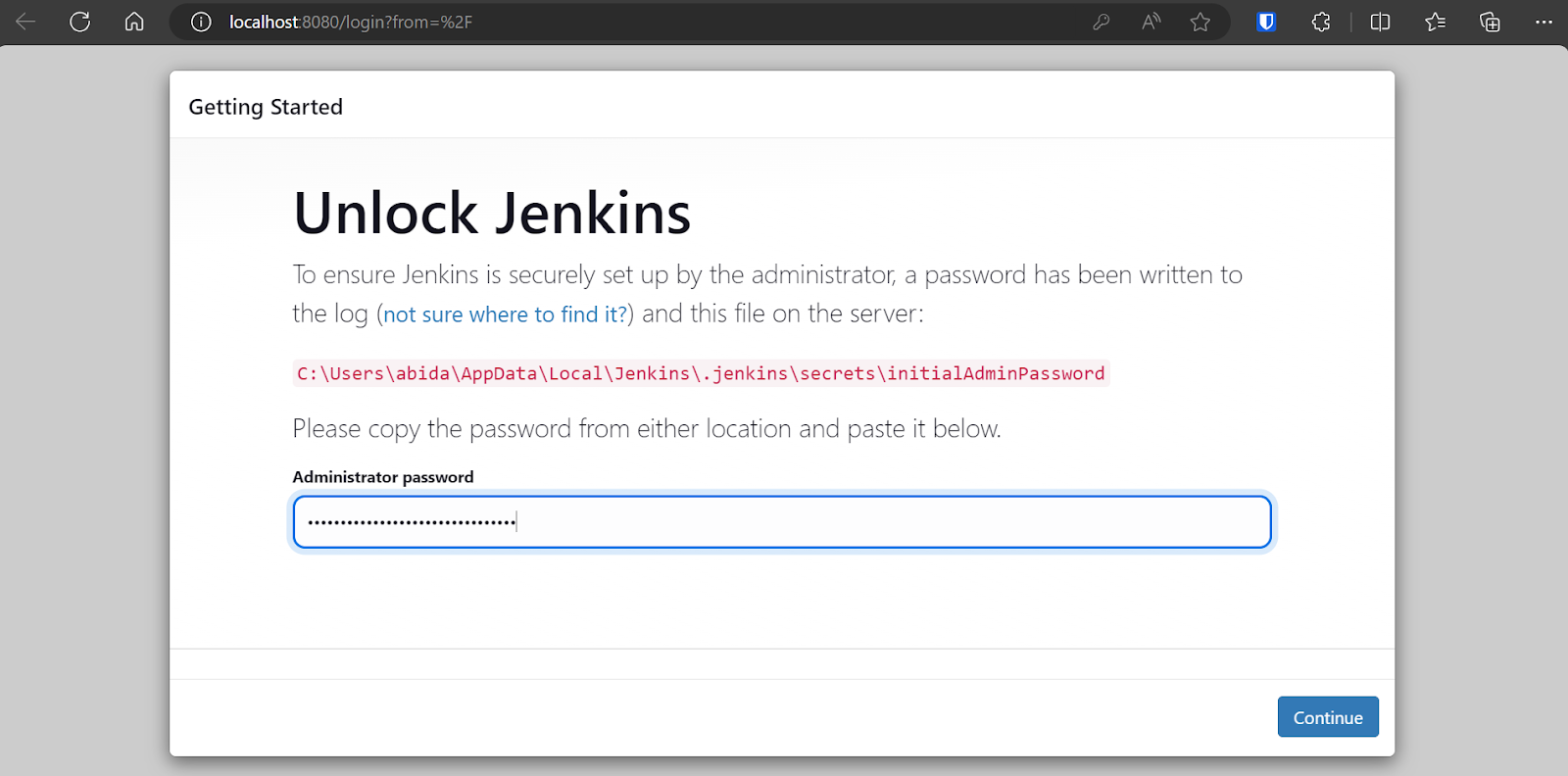
Um das Standard-Administratorkennwort zu erhalten, navigieren Sie zum Verzeichnis Jenkins, suchen und öffnen Sie die Datei Jenkins.err.log.
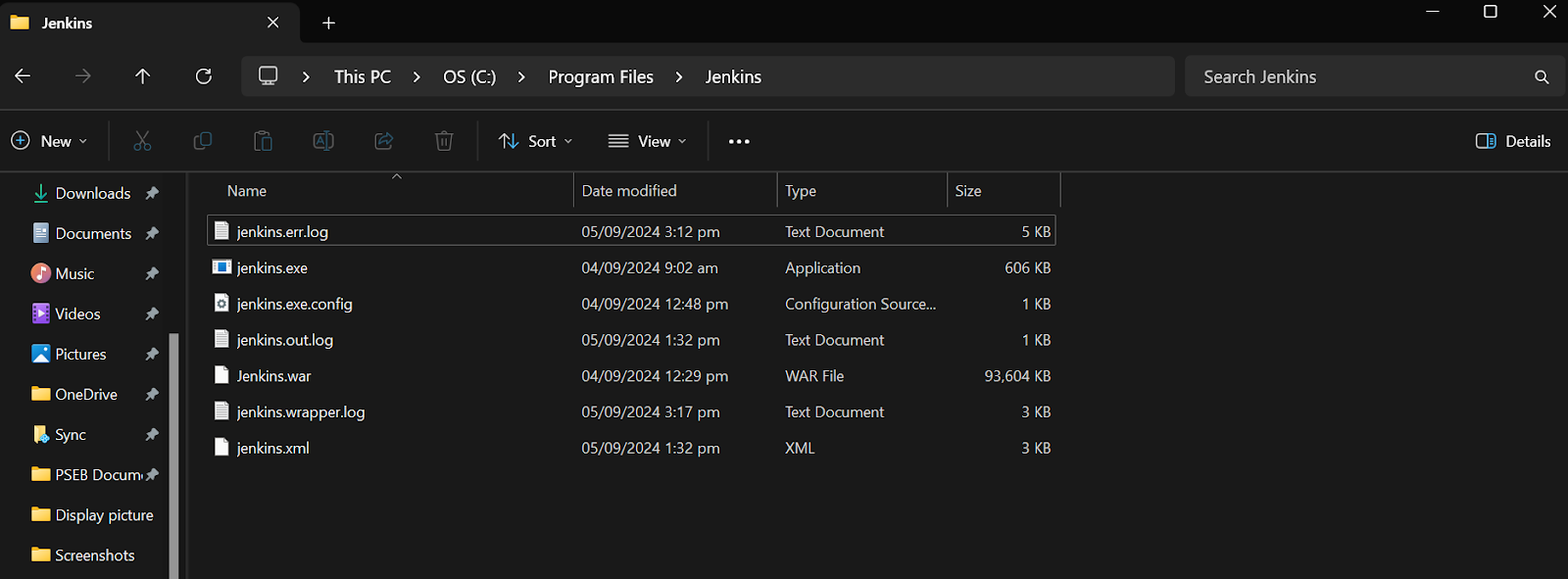
Scrolle in der Jenkins-Fehlerdatei nach unten, um das generierte Passwort zu finden. Kopiere es und füge es in das Eingabefeld für das Administrator-Passwort ein.
Danach braucht der Server ein paar Minuten, um die notwendigen Tools und Erweiterungen zu installieren.
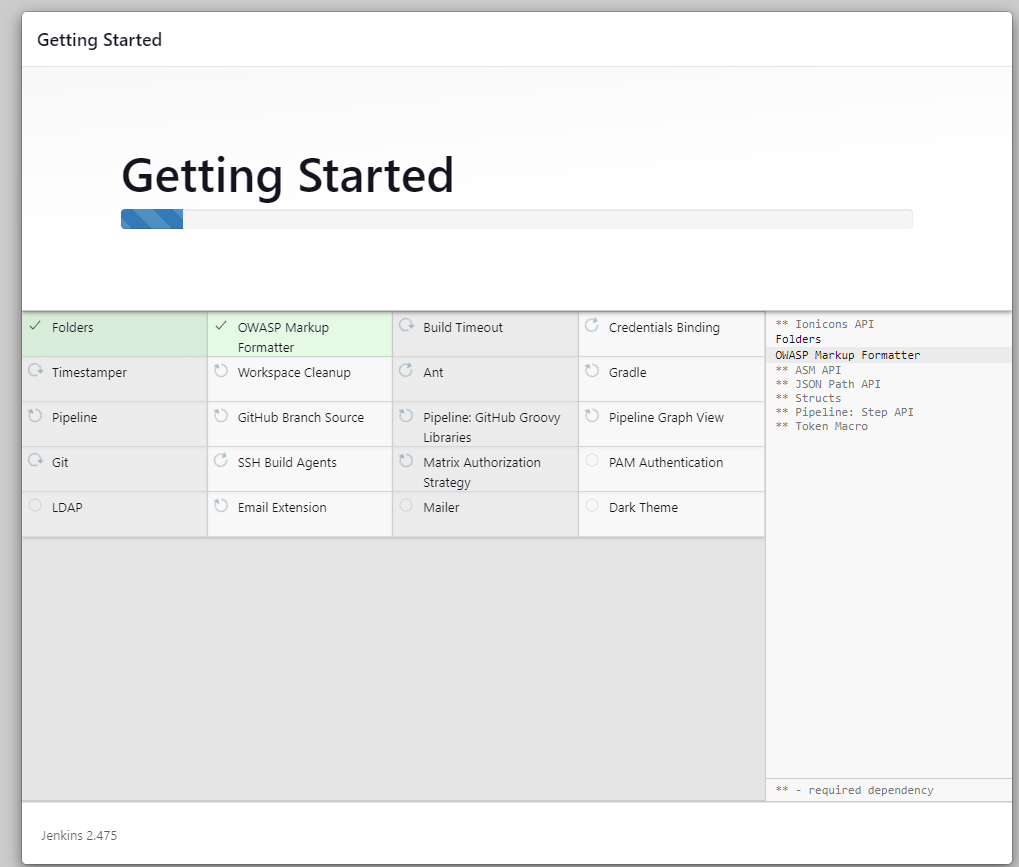
Sobald die Servereinrichtung abgeschlossen ist, werden wir aufgefordert, einen neuen Benutzer anzulegen. Gib alle erforderlichen Informationen ein und klicke auf die Schaltfläche "Speichern und weiter".
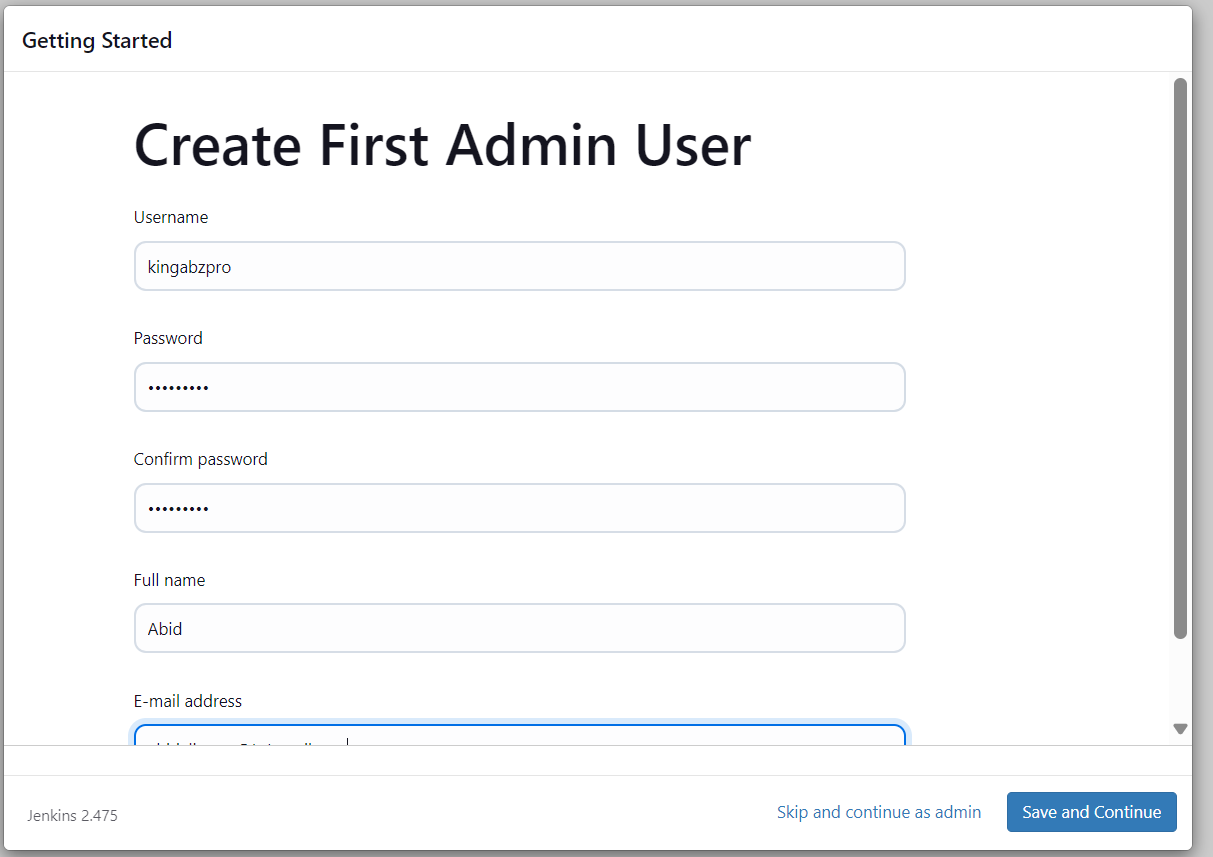
Wir werden zum Dashboard weitergeleitet, wo wir verschiedene Jenkins-Pipelines erstellen, anzeigen und ausführen können.
Agenten, auch Knoten genannt, sind Maschinen, die so eingerichtet sind, dass sie Aufträge ausführen, die vom Jenkins-Masterserver gesendet werden. Diese Agenten stellen die Umgebung und die Rechenleistung für den Betrieb von Pipelines bereit. Ein Windows 11-Agent ist standardmäßig verfügbar, aber wir können jederzeit einen eigenen Agenten mit angepassten Optionen erstellen.
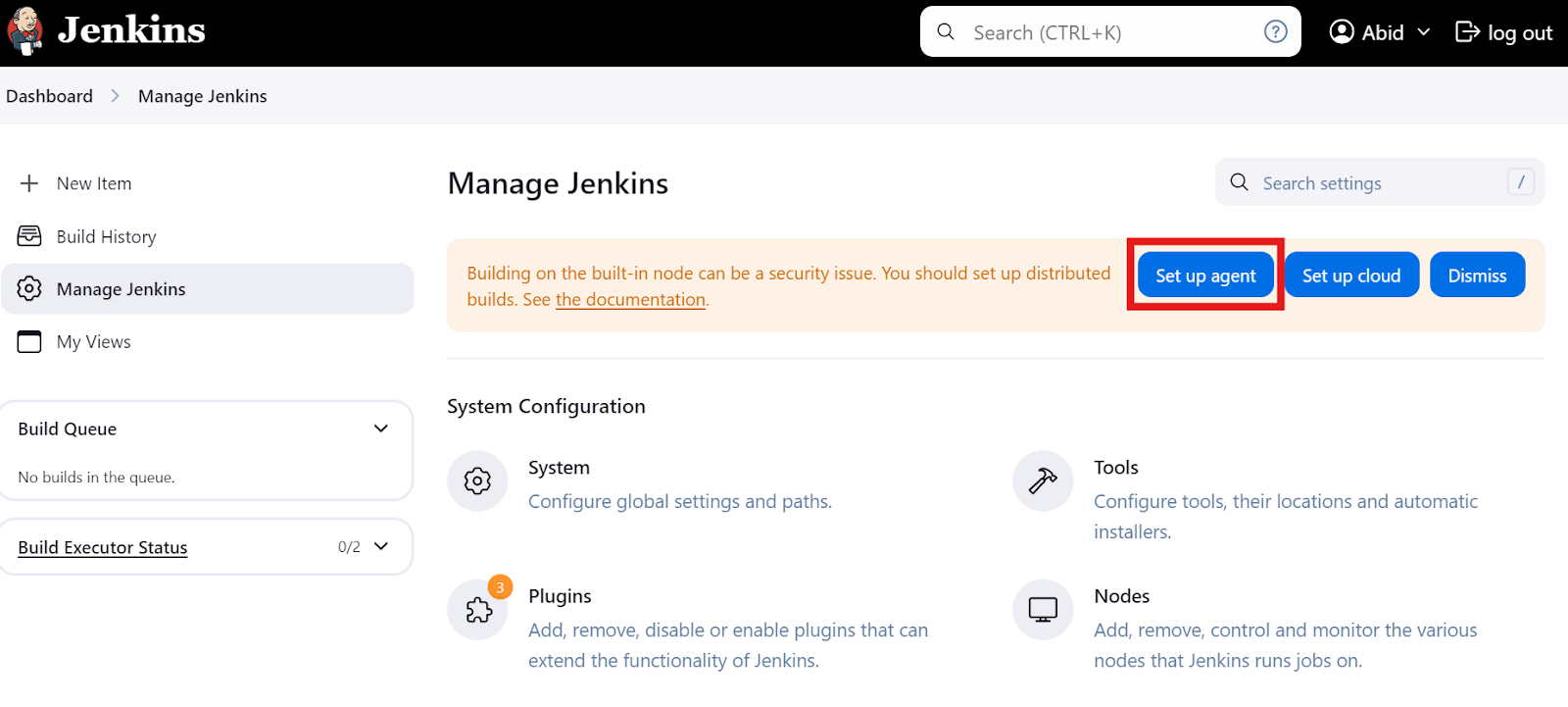
Klicke auf dem Haupt-Dashboard auf die Option "Jenkins verwalten" und dann auf die Schaltfläche "Agent einrichten" (siehe unten). Alternativ kannst du auch auf die Schaltfläche "Knoten" klicken, um Agenten zu erstellen und zu verwalten.
Gib den Namen des Agenten ein und wähle den Typ "Permanenter Agent".
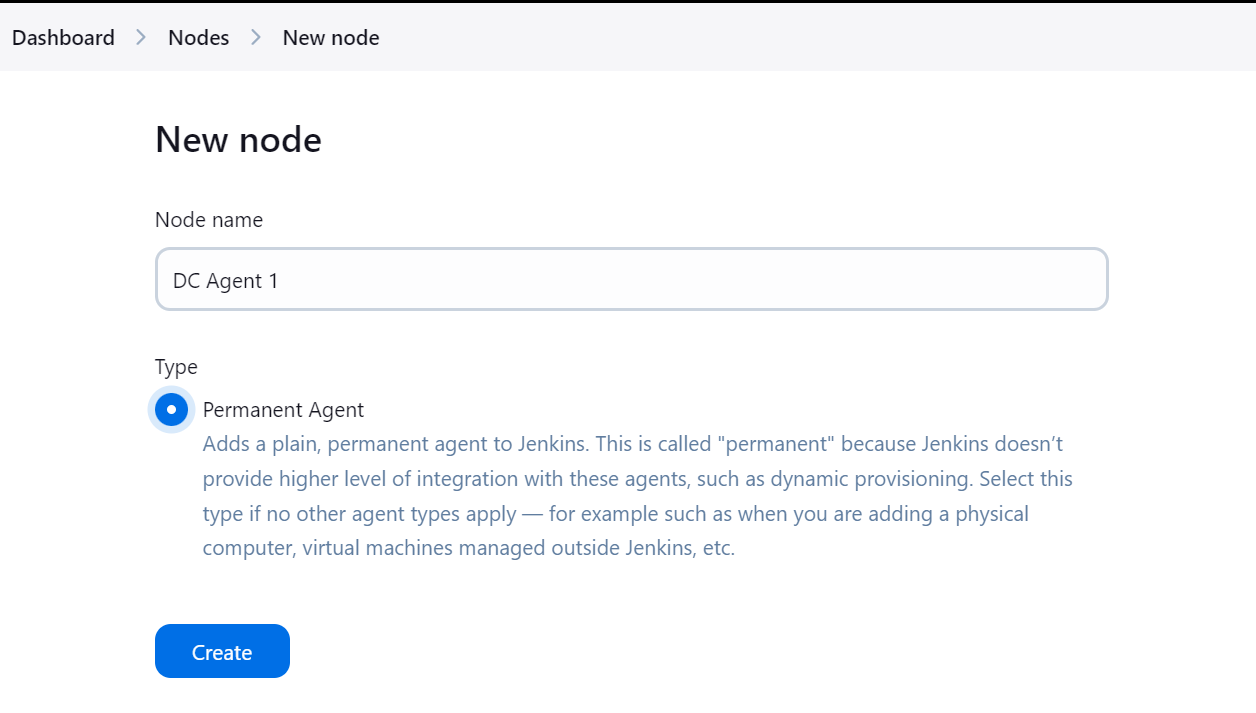
Bitte stelle sicher, dass du ein Verzeichnis für den Agenten angibst, in dem alle Dateien und Protokolle gespeichert werden sollen. Füge ein Etikett hinzu und behalte die restlichen Einstellungen als Standard bei. Beim Erstellen der Pipeline verwenden wir das Agentenlabel, um die Aufgaben auszuführen.
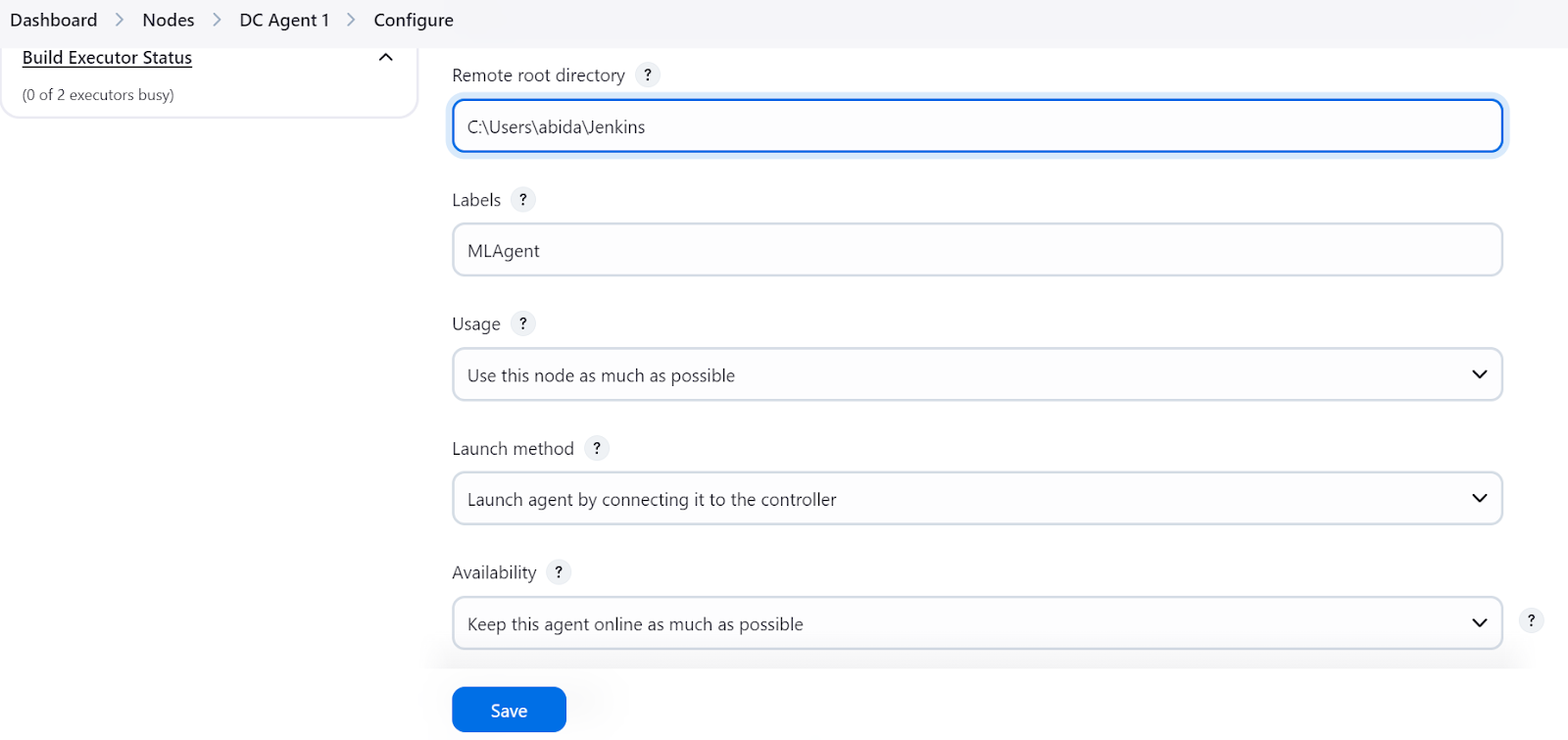
Wenn du auf die Schaltfläche "Speichern" drückst, erscheint eine Eingabeaufforderung, die uns anweist, den entsprechenden Befehl zu kopieren und in das Terminal einzufügen, je nachdem, welches Betriebssystem wir verwenden.
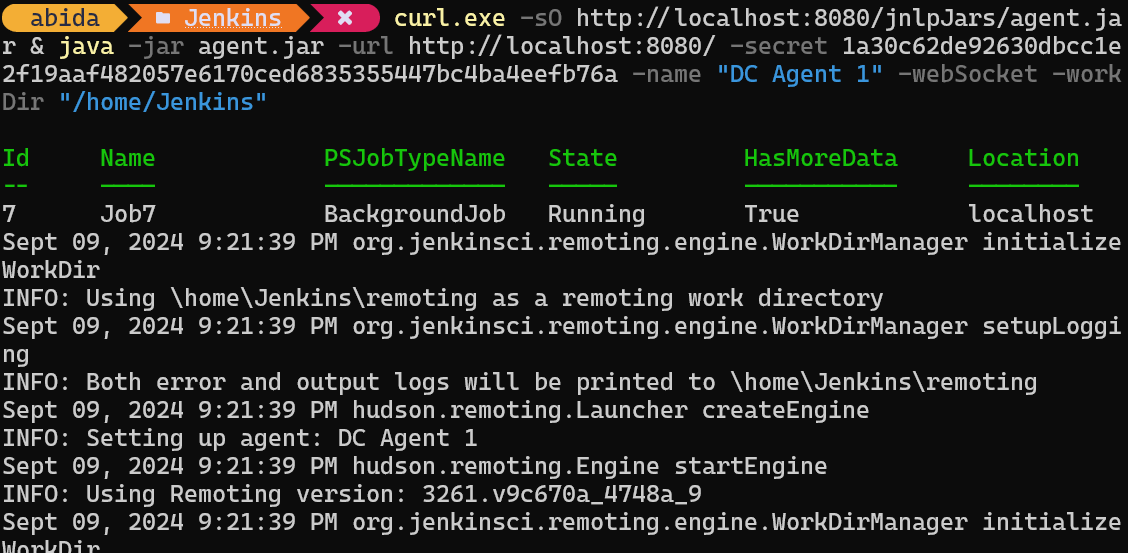
curl.exe -sO http://localhost:8080/jnlpJars/agent.jar & java -jar agent.jar -url http://localhost:8080/ -secret 1a30c62de92630dbcc1e2f19aaf482057e6170ced6835355447bc4ba4eefb76a -name "DC Agent 1" -webSocket -workDir "/home/Jenkins"Nachdem wir den Befehl im Terminal eingefügt und ausgeführt haben, sehen wir eine Erfolgsmeldung, die anzeigt, dass unser Agent, in meinem Fall DC Agent 1, im Hintergrund läuft.
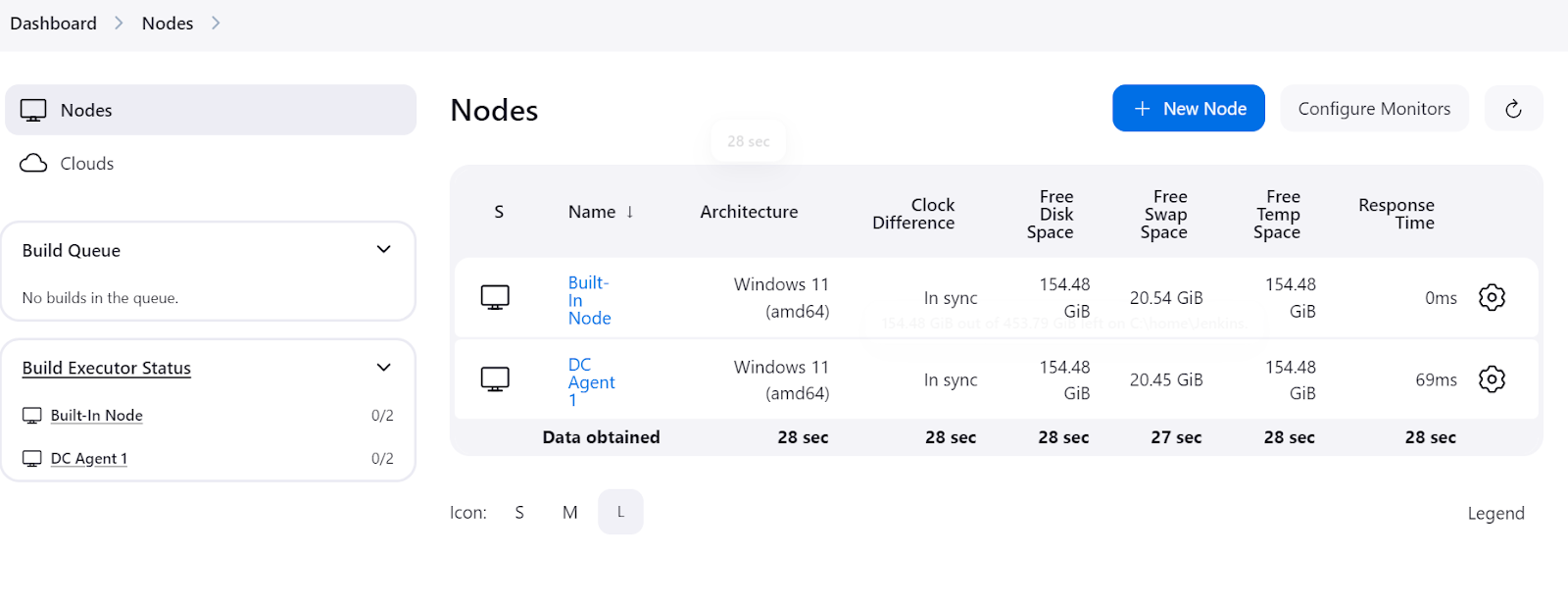
Um zu überprüfen, ob der Agent läuft und bereit ist, einen Auftrag auszuführen, navigiere zum Jenkins-Dashboard, klicke auf "Jenkins verwalten" und dann auf die Schaltfläche "Knoten", um den Status des Agenten anzuzeigen.
Eine Jenkins-Pipeline ist eine Reihe von automatisierten Schritten, die beim Training, der Bewertung und dem Einsatz von Modellen helfen. Sie definiert diese Prozesse mithilfe eines einfachen Programmierskripts und erleichtert so die Verwaltung und Automatisierung von Projektabläufen.
In diesem Abschnitt erstellen wir eine beispielhafte Jenkins-Pipeline und verwenden unseren neu erstellten Agenten als Pipeline-Ausführer.
Klicke auf dem Dashboard auf die Schaltfläche "Neuer Artikel", gib den Namen des Artikels ein, wähle die Option "Pipeline" und klicke auf "OK".
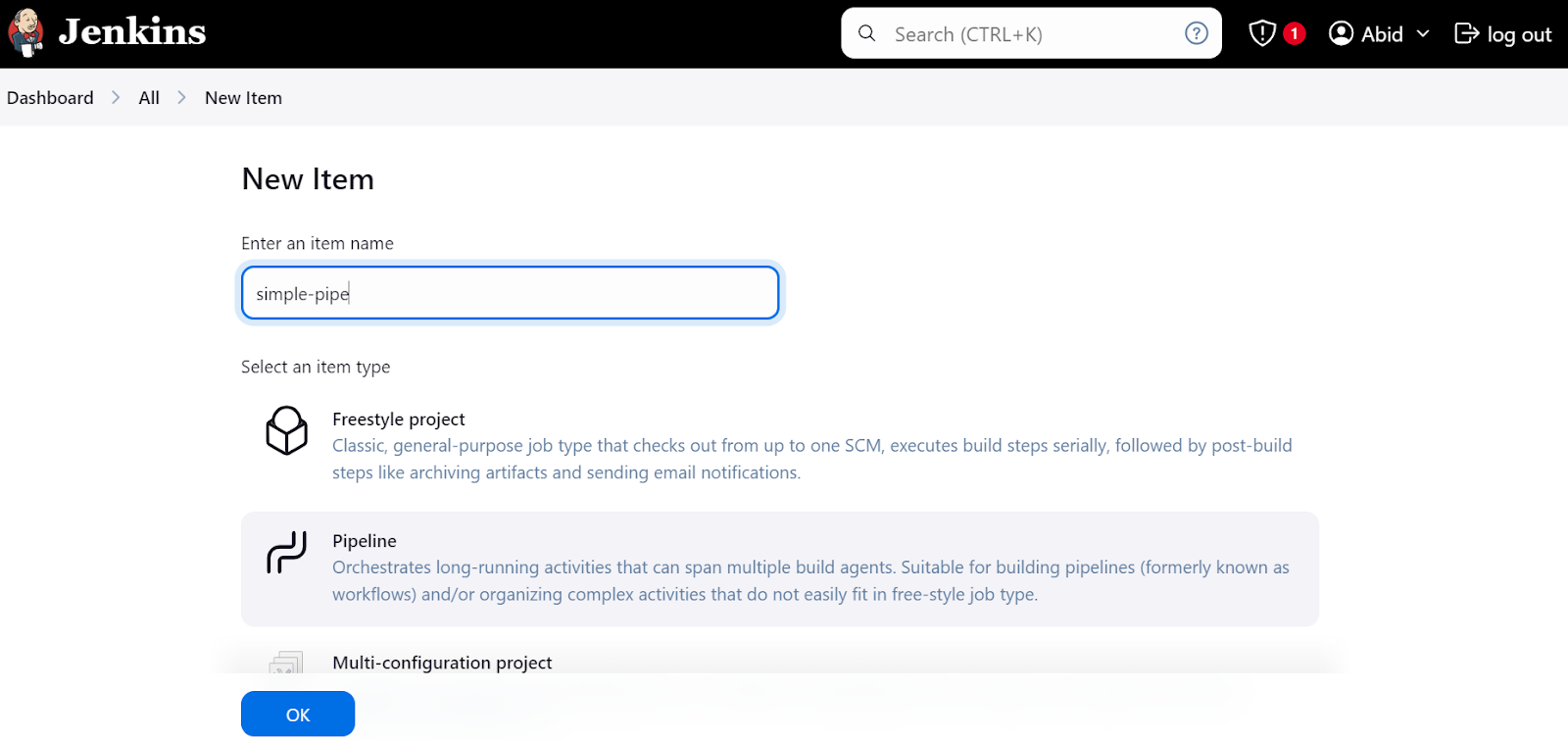
Danach werden wir aufgefordert, die Pipeline zu konfigurieren. Scrolle nach unten zum Abschnitt "Pipeline", wo wir das Jenkins-Pipeline-Skript schreiben müssen.
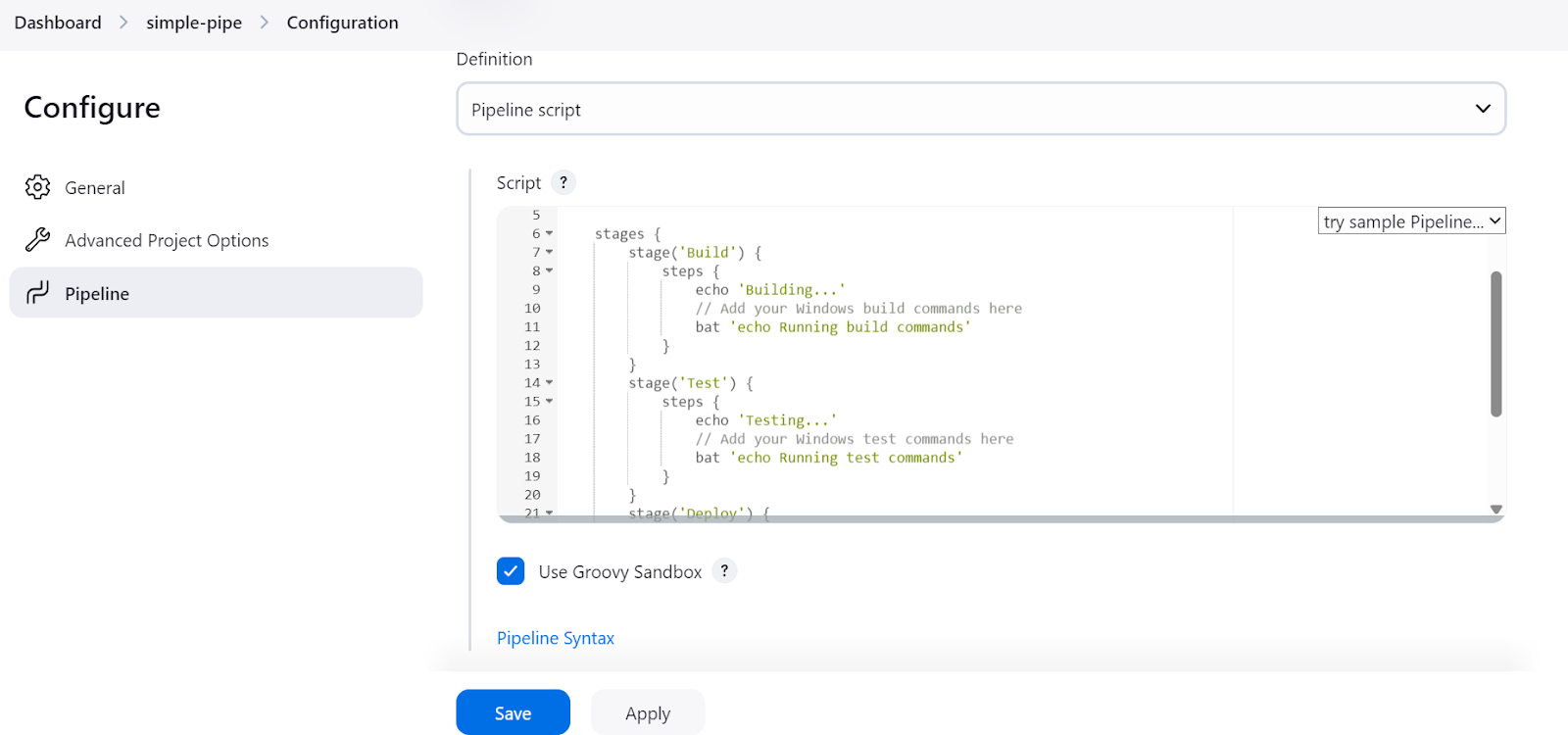
Im Jenkins-Pipeline-Skript richten wir zunächst die Umgebung und den Agenten ein. In unserem Fall setzen wir die agent, indem wir ihr das zuvor definierte Label des Agenten geben.
Danach werden wir einen Abschnitt stages schreiben, in dem die verschiedenen Schritte der Pipeline (Build, Test, Deploy) hinzugefügt werden. In unserem Fall drucken wir nur mit dem Befehl echo und führen die Terminalbefehle mit dem Befehl bat aus.
bat wird für Windows 11 verwendetsh ist für LinuxDas war's. So einfach ist das. Hier ist der Skriptcode:
pipeline {
agent {
label 'MLAgent' // Ensure this label matches your Windows 11 agent
}
stages {
stage('Build') {
steps {
echo 'Building...'
// Add your Windows build commands here
bat 'echo Running build commands'
}
}
stage('Test') {
steps {
echo 'Testing...'
// Add your Windows test commands here
bat 'echo Running test commands'
}
}
stage('Deploy') {
steps {
echo 'Deploying...'
// Add your Windows deploy commands here
bat 'echo Running deploy commands'
}
}
}
}Nachdem du das Skript hinzugefügt hast, klicke auf die Schaltflächen "Anwenden" und "Speichern".
Klicke auf die Schaltfläche "Jetzt bauen", um die Pipeline zu testen und auszuführen. Um den Status zu sehen, klicke auf die Schaltfläche "Status".
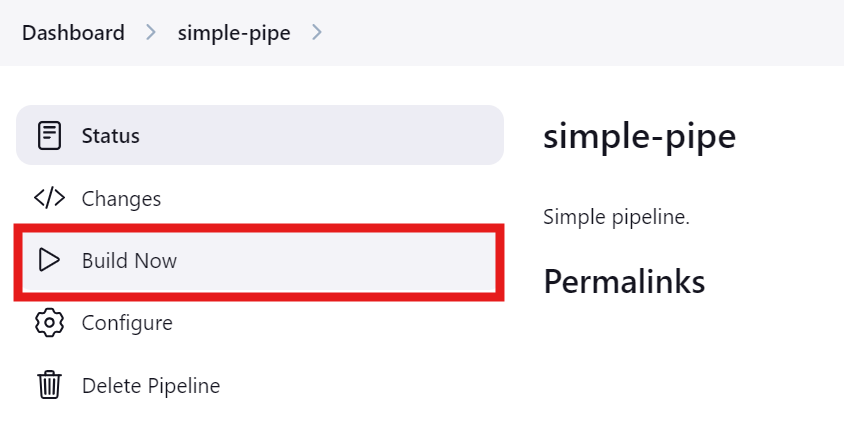
Nachdem der Lauf abgeschlossen ist, können wir die Protokolle einsehen, indem wir im Menü "Status" auf den jeweiligen Lauf klicken.
Klicke auf den Link "Letzter Build (#2)" und dann auf die Schaltfläche "Konsolenausgabe". Dadurch gelangen wir zum Konsolenausgabefenster, in dem wir die Logs und Ergebnisse der Pipeline finden.
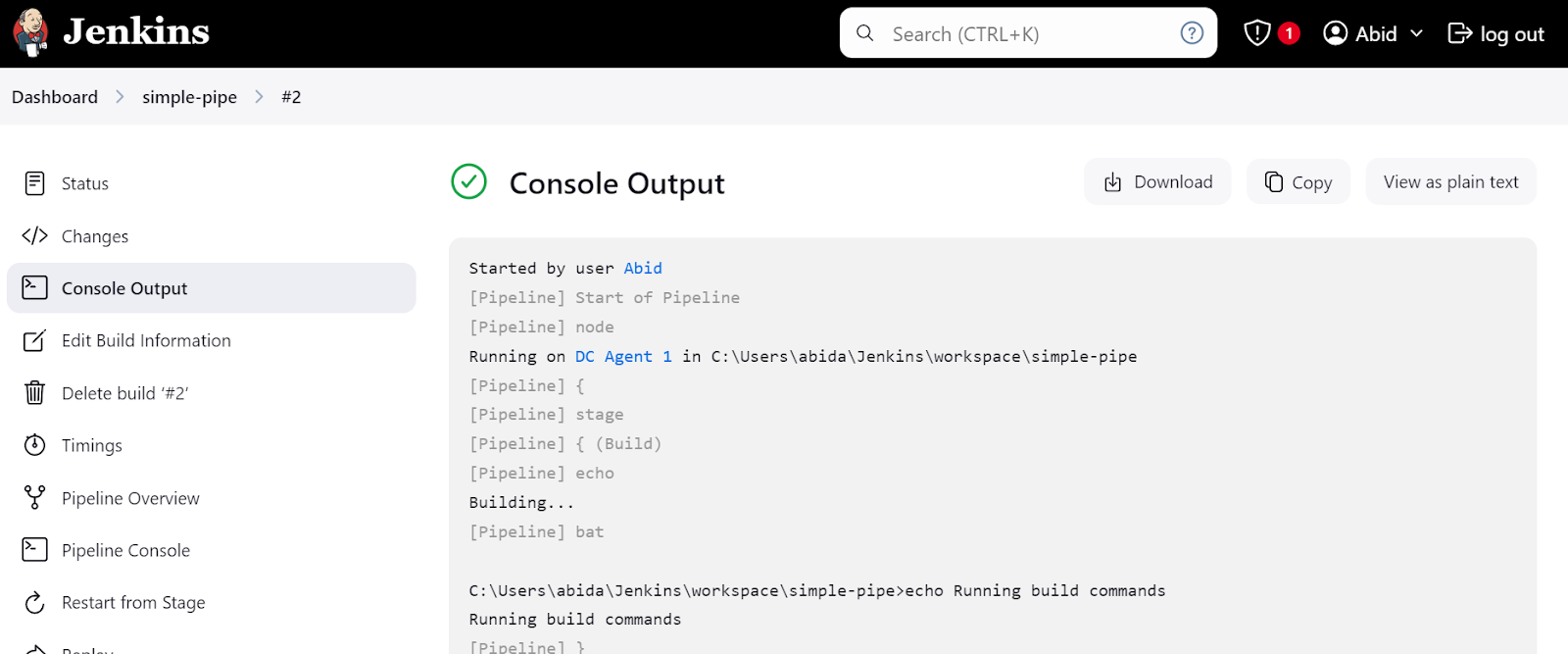
Wir können sogar auf die Schaltfläche "Pipeline-Konsole" klicken, um jeden Schritt in der Pipeline im Detail zu sehen. Dazu gehören die Ausgabe, die Zeit, die zum Starten und Beenden benötigt wurde, Pipeline-Befehle und Protokolle.
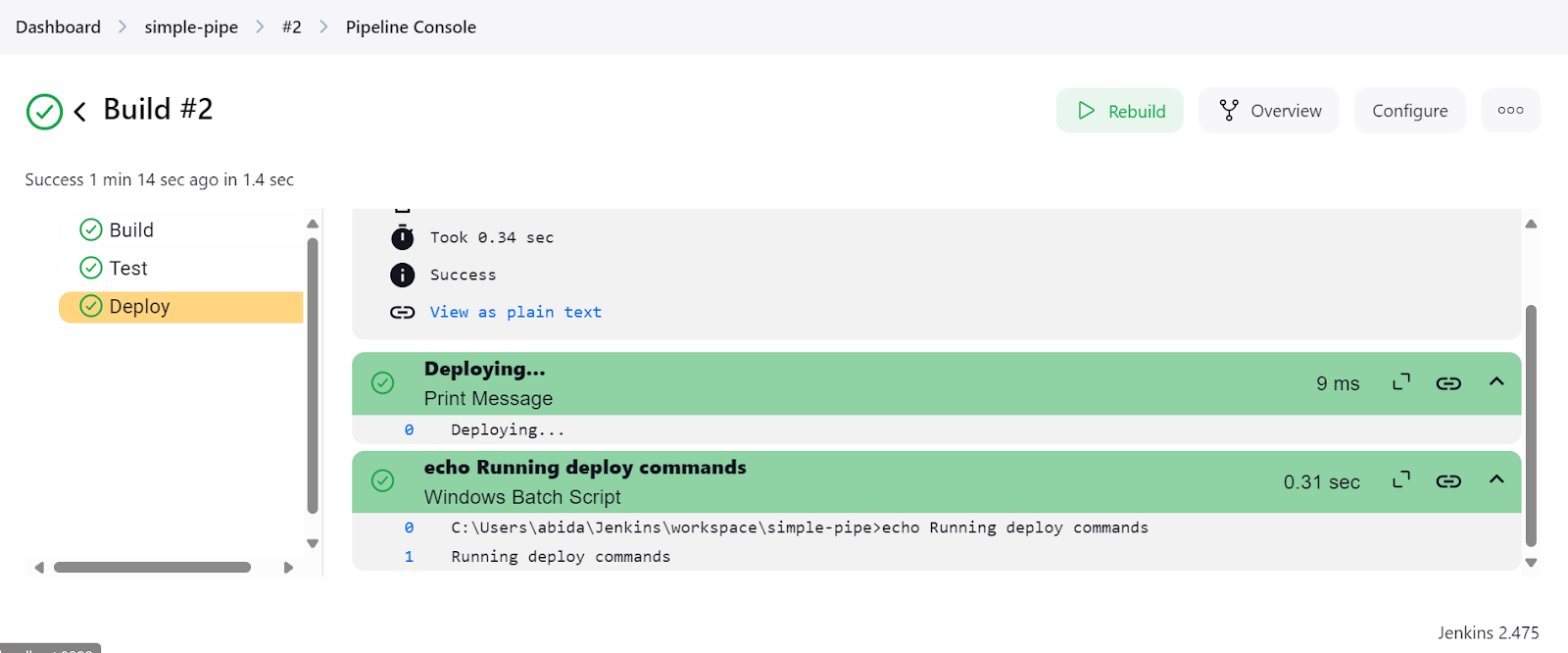
Nachdem die Jenkins-Installation abgeschlossen war, war das Erstellen und Ausführen von Pipelines einfach und schnell. Ich habe weniger als eine Stunde gebraucht, um das Skript zu verstehen und mein eigenes zu erstellen. Ich werde Jenkins anstelle von GitHub Actions verwenden, weil es mir mehr Flexibilität bietet.
Author's opinion
Nach der anfänglichen Einführung in Jenkins ist es an der Zeit, dass wir ernsthaft an dem MLOps-Projekt arbeiten.
Wir werden zwei Pipelines erstellen: Die erste Pipeline ist die KI, die die Daten lädt und verarbeitet, das Modell trainiert, das Modell auswertet und dann den Modellserver testet. Danach wird die CD-Pipeline initiiert und der Modellinferenzserver gestartet.
Um den Prozess im Detail zu verstehen, besuche den Kurs CI/CD for Machine Learning, in dem du lernst, wie du die Entwicklungsprozesse für maschinelles Lernen optimieren kannst.
Wie bei jedem Projekt müssen wir die Projektdateien erstellen, einschließlich der Python-Dateien für das Laden der Daten, das Training des Modells, die Auswertung des Modells und die Bereitstellung des Modells. Wir brauchen auch eine requirements .txt Datei, um die notwendigen Python-Pakete zu installieren.
In diesem Skript laden wir einen Scikit-Learn-Datensatz namens Wein-Datensatz und wandeln ihn in einen Pandas DataFrame um. Dann teilen wir den Datensatz in eine Trainings- und eine Testmenge auf. Zum Schluss speichern wir die verarbeiteten Daten in einer Pickle-Datei.
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
import joblib
def load_data():
# Load the wine dataset
wine = load_wine(as_frame=True)
data = pd.DataFrame(data=wine.data, columns=wine.feature_names)
data["target"] = wine.target
print(data.head())
return data
def split_data(data, target_column="target"):
X = data.drop(columns=[target_column])
y = data[target_column]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
return X_train, X_test, y_train, y_test
def save_preprocessed_data(X_train, X_test, y_train, y_test, file_path):
joblib.dump((X_train, X_test, y_train, y_test), file_path)
if __name__ == "__main__":
data = load_data()
X_train, X_test, y_train, y_test = split_data(data)
save_preprocessed_data(X_train, X_test, y_train, y_test, "preprocessed_data.pkl")In dieser Datei laden wir die verarbeiteten Daten, trainieren einen Random Forest-Klassifikator und speichern das Modell als Pickle-Datei.
from sklearn.ensemble import RandomForestClassifier
import joblib
def load_preprocessed_data(file_path):
return joblib.load(file_path)
def train_model(X_train, y_train):
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
return model
def save_model(model, file_path):
joblib.dump(model, file_path)
if __name__ == "__main__":
X_train, X_test, y_train, y_test = load_preprocessed_data("preprocessed_data.pkl")
model = train_model(X_train, y_train)
save_model(model, "model.pkl")Um das Modell zu bewerten, laden wir sowohl das Modell als auch den vorverarbeiteten Datensatz, erstellen einen Klassifizierungsbericht und drucken die Trefferquote aus.
import joblib
from sklearn.metrics import accuracy_score, classification_report
def load_model(file_path):
return joblib.load(file_path)
def load_preprocessed_data(file_path):
return joblib.load(file_path)
def evaluate_model(model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return accuracy, report
if __name__ == "__main__":
X_train, X_test, y_train, y_test = load_preprocessed_data("preprocessed_data.pkl")
model = load_model("model.pkl")
accuracy, report = evaluate_model(model, X_test, y_test)
print(f"Model Accuracy: {accuracy}")
print(f"Classification Report:\n{report}")Für das Model Serving werden wir FastAPI verwenden, um eine REST-API zu erstellen, über die Nutzer Merkmale eingeben und Vorhersagen erstellen können. Normalerweise sind die Etiketten allgemein gehalten. Um die Sache interessanter zu machen, werden wir die Weinkategorien in Verdante, Rubresco und Floralis ändern.
Wenn wir diese Datei ausführen, starten wir den FastAPI-Server, auf den wir mit dem Befehl curl oder mit der Bibliothek requests in Python zugreifen können.
from typing import List
import joblib
import uvicorn
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
# Define the labels corresponding to the target classes
LABELS = [
"Verdante", # A vibrant and fresh wine, inspired by its balanced acidity and crisp flavors.
"Rubresco", # A rich and robust wine, named for its deep, ruby color and bold taste profile.
"Floralis", # A fragrant and elegant wine, known for its floral notes and smooth finish.
]
class Features(BaseModel):
features: List[float]
def load_model(file_path):
return joblib.load(file_path)
model = load_model("model.pkl")
@app.post("/predict")
def predict(features: Features):
# Get the numerical prediction
prediction_index = model.predict([features.features])[0]
# Map the numerical prediction to the label
prediction_label = LABELS[prediction_index]
return {"prediction": prediction_label}
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=9000)Diese Datei hilft uns dabei, alle Pakete herunterzuladen und zu installieren, die wir benötigen, um die oben genannten Python-Dateien auszuführen.
scikit-learn
pandas
fastapi
uvicornWir werden nun Jenkins-Pipelines für die kontinuierliche Integration erstellen. So wie wir eine einfache Pipeline erstellt haben, werden wir eine "MLOps-Pipeline" erstellen und das Skript schreiben, das alles von der Datenverarbeitung bis zur Modellauswertung abdeckt.
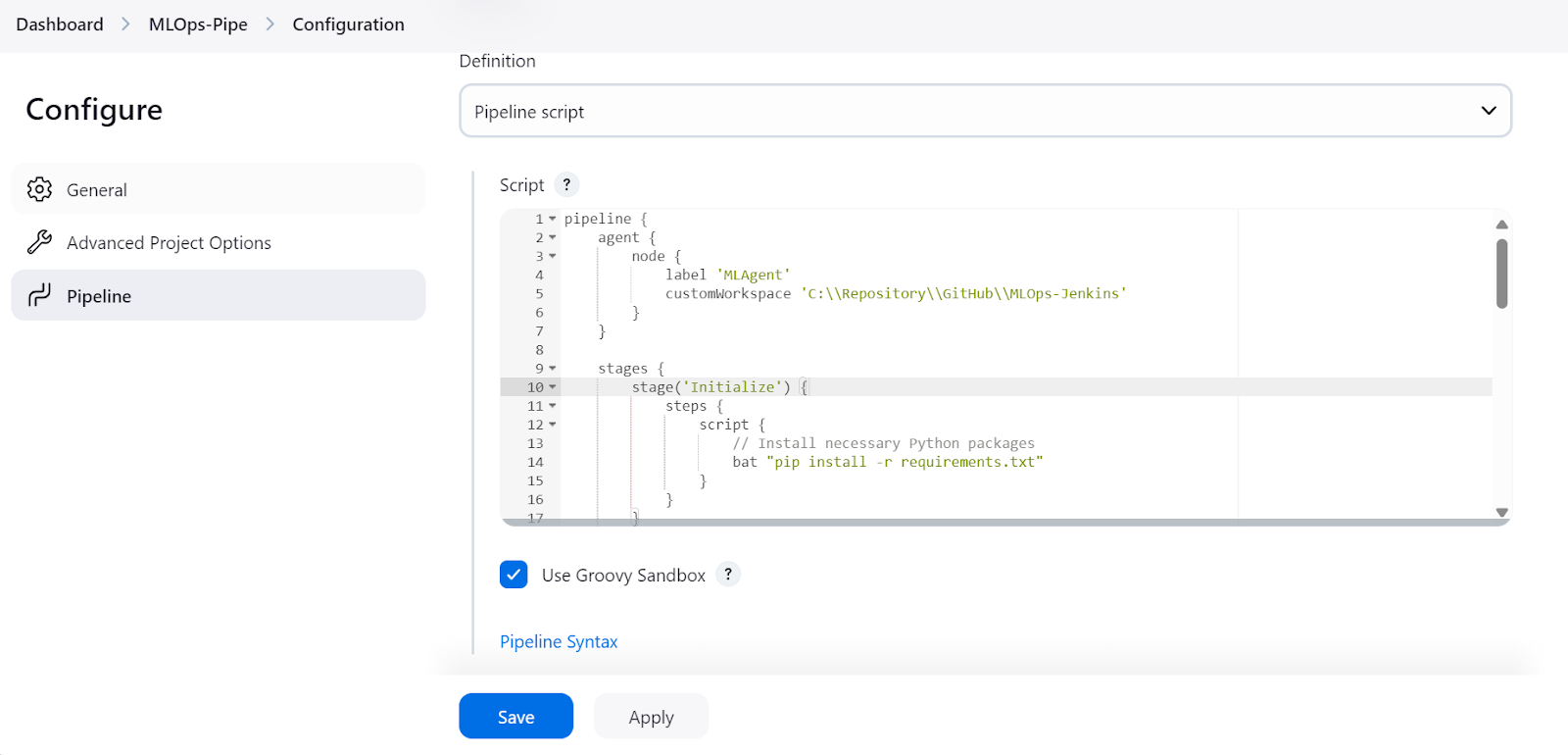
Das Skript für die MLOps-Pipeline besteht aus:
agent mit der label "MLAgent."Initialize).Load and Preprocess Data).Train Model).Evaluate Model).curl (Test Serve Model ).Hinweis: Der Befehl start /B öffnet ein neues Terminalfenster im Hintergrund und führt das Skript aus, das das Modell bedient. Außerdem funktioniert dieses Jenkins-Pipeline-Skript nur unter Windows, und wir müssen die Befehle für Linux oder andere Betriebssysteme ändern.
pipeline {
agent {
node {
label 'MLAgent'
customWorkspace 'C:\\Repository\\GitHub\\MLOps-Jenkins'
}
}
stages {
stage('Initialize') {
steps {
script {
// Install necessary Python packages
bat "pip install -r requirements.txt"
}
}
}
stage('Load and Preprocess Data') {
steps {
script {
// Run data loading script
bat "python data_loading.py"
}
}
}
stage('Train Model') {
steps {
script {
// Run model training script
bat "python model_training.py"
}
}
}
stage('Evaluate Model') {
steps {
script {
// Run model evaluation script
bat "python model_evaluation.py"
}
}
}
stage('Serve Model') {
steps {
script {
// Start FastAPI server in the background
bat 'start /B python model_serving.py'
// Wait for the server to start
sleep time: 10, unit: 'SECONDS'
}
}
}
stage('Test Serve Model') {
steps {
script {
// Test the server with sample values
bat '''
curl -X POST "http://127.0.0.1:9000/predict" ^
-H "Content-Type: application/json" ^
-d "{\\"features\\": [13.2, 2.77, 2.51, 18.5, 103.0, 1.15, 2.61, 0.26, 1.46, 3.0, 1.05, 3.33, 820.0]}"
'''
}
}
}
stage('Deploy Model') {
steps {
script {
// Trigger another Jenkins job for model serving
build job: 'ModelServingPipeline', wait: false
}
}
}
}
post {
always {
archiveArtifacts artifacts: '**.pkl', fingerprint: true
echo 'Pipeline execution complete.'
}
}
}Jetzt erstellen wir eine kontinuierliche Bereitstellungspipeline, um den Server lokal bereitzustellen und zu betreiben.
Das Pipeline-Skript ist einfach. Wir beginnen damit, den Agenten zu definieren und das Arbeitsverzeichnis in unser Projekt zu ändern. Danach lassen wir den Server auf unbestimmte Zeit laufen.
Hinweis: Es ist nicht empfehlenswert, einen Server in Jenkins auf unbestimmte Zeit laufen zu lassen, da Pipelines einen definierten Anfang und ein definiertes Ende haben sollten. In diesem Beispiel gehen wir davon aus, dass wir die App bereitgestellt haben, aber in der Praxis ist es besser, Docker zu integrieren und die App auf einem Docker-Server laufen zu lassen.
Wenn du lernen möchtest, wie ein/e Ingenieur/in für maschinelles Lernen zu denken, solltest du den Kurs Developing Machine Learning Models for Production with an MLOps Mindset besuchen, der dich in die Lage versetzt, deine maschinellen Lernmodelle zu trainieren, zu dokumentieren, zu warten und zu skalieren, um ihr volles Potenzial auszuschöpfen.
pipeline {
agent {
node {
label 'MLAgent'
customWorkspace 'C:/Repository/GitHub/MLOps-Jenkins/'
}
}
stages {
stage('Start FastAPI Server') {
steps {
script {
// Start the FastAPI server
bat 'python model_serving.py'
}
}
}
}
}Gehe zur Pipeline "MLOps-pipe" und klicke auf die Schaltfläche "Jetzt bauen", um die CI/CD-Pipeline zu starten.
Sobald die Pipeline erfolgreich ausgeführt wurde, erzeugt sie zwei Artefakte: eines für das Modell und eines für den verarbeiteten Datensatz.
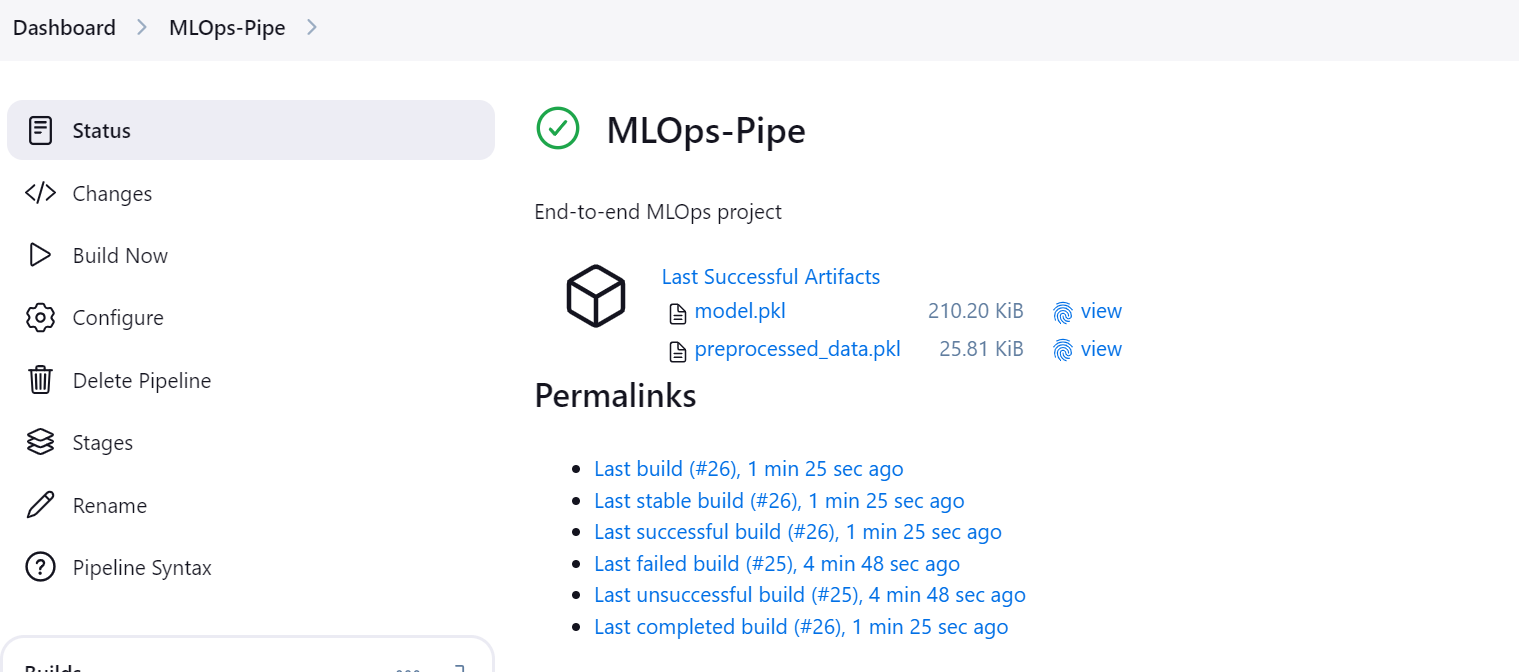
Klicke auf die Schaltfläche "Stages" im Jenkins-Dashboard, um die Pipeline zu visualisieren und alle Schritte zu sehen.
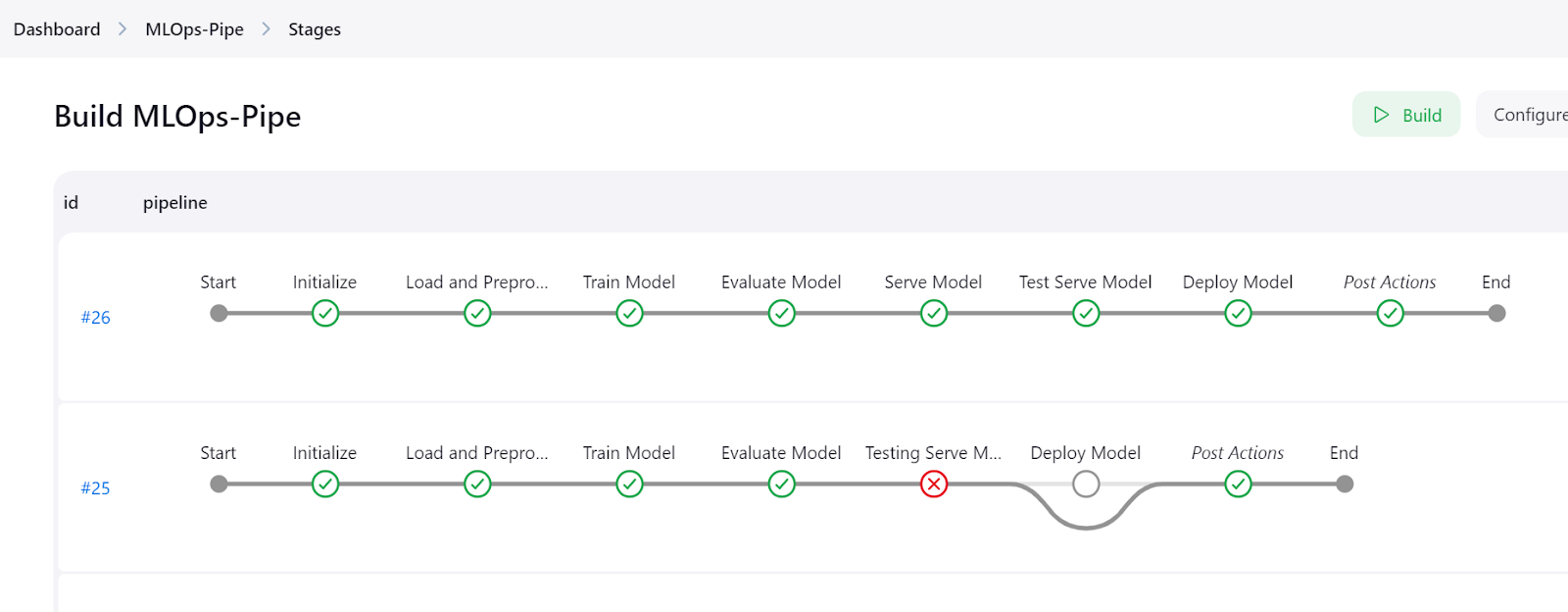
Die detaillierten Protokolle der einzelnen Schritte kannst du im Menü "Pipeline-Konsole" einsehen.
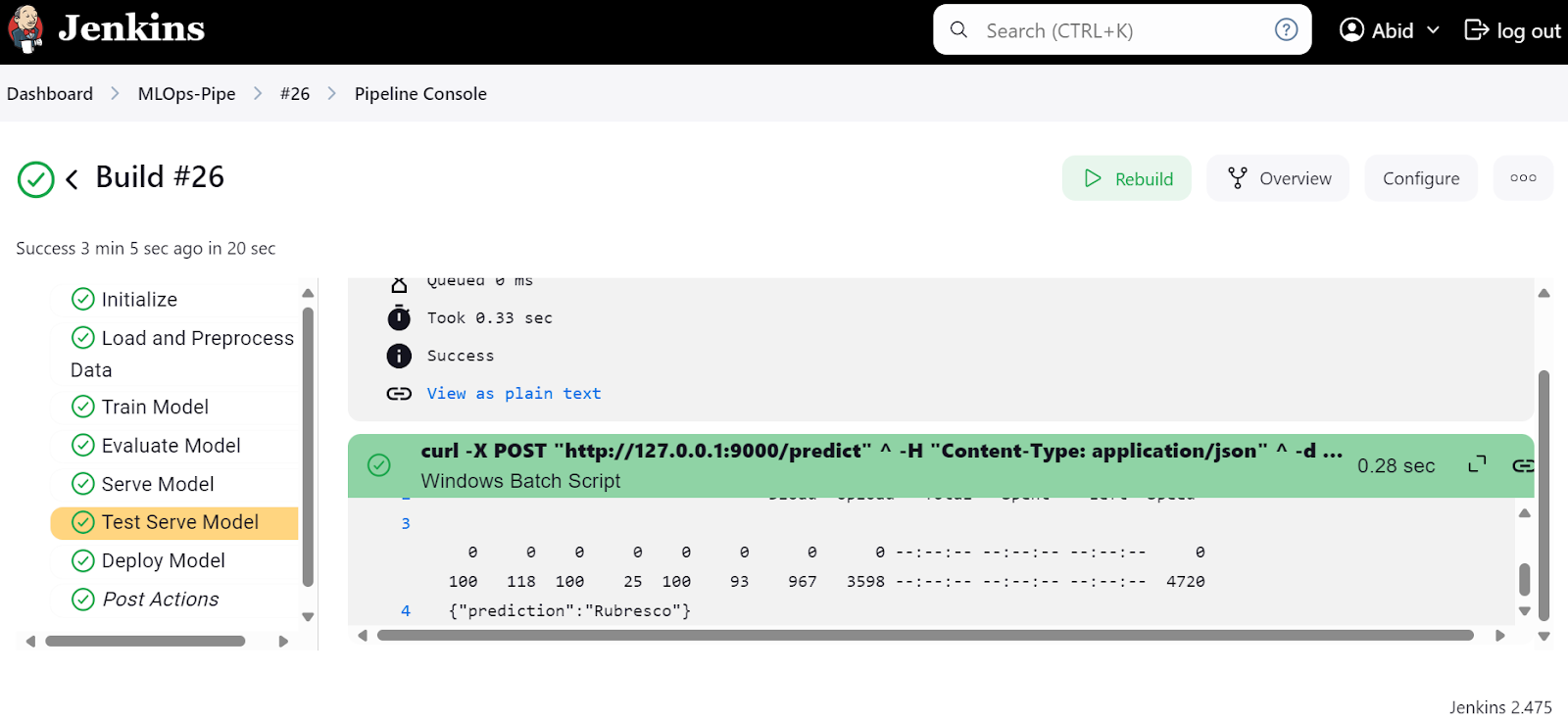
Wir können auch die "ModelServingPipeline" überprüfen, um sicherzustellen, dass unser Server unter der lokalen URL http://127.0.0.1:9000 läuft.
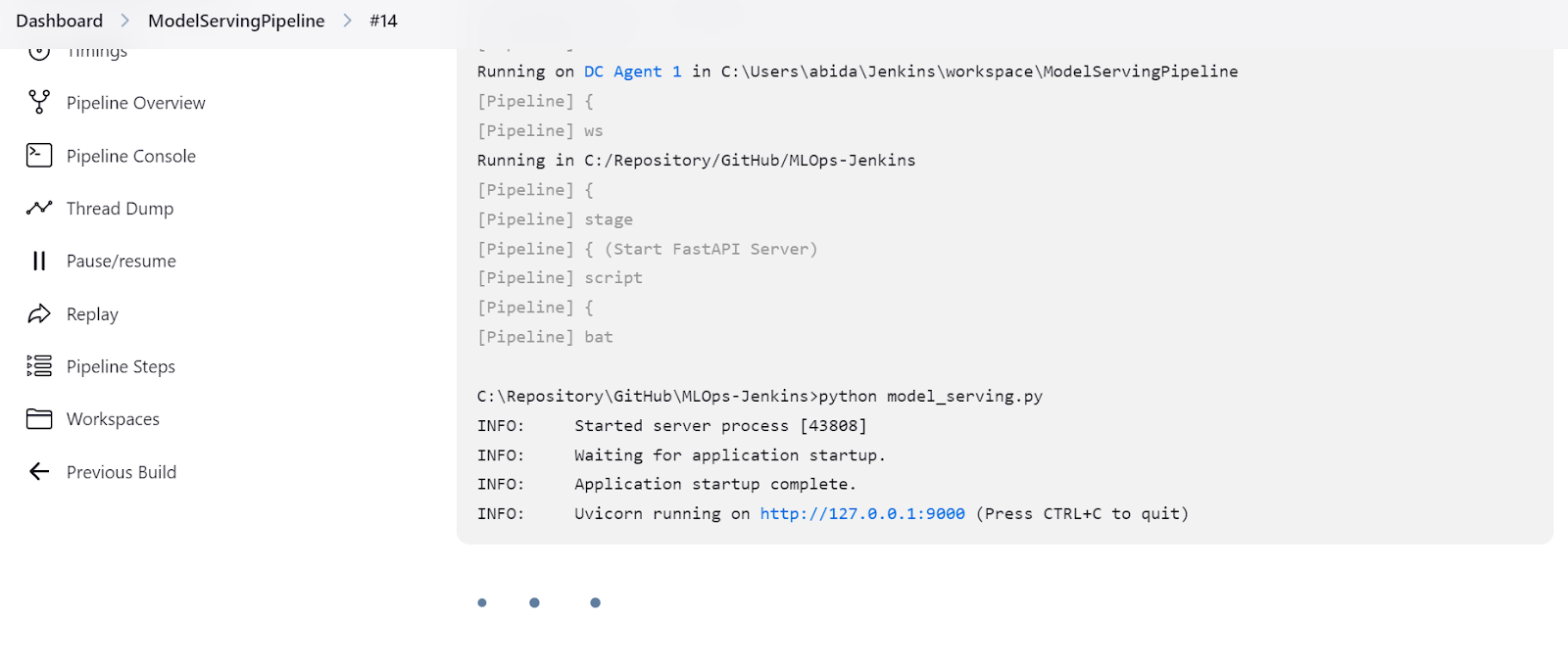
Die FastAPI wird mit der Swagger UI ausgeliefert, die durch Hinzufügen von /docs zur lokalen URL aufgerufen werden kann: http://127.0.0.1:9000/docs.
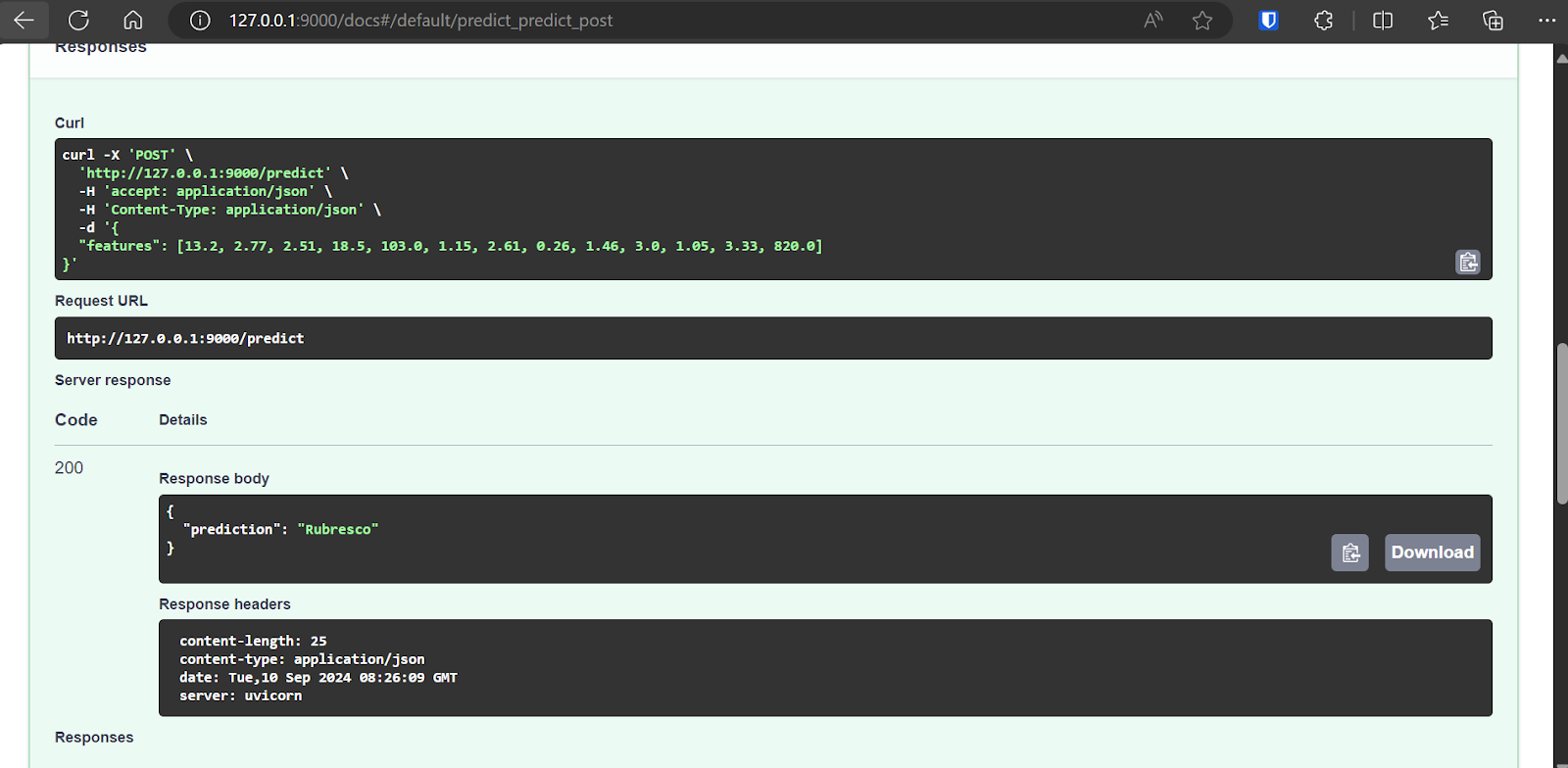
Mit der Swagger UI können wir die FastAPI-Anwendung im Browser testen. Es ist ganz einfach, und wir können sehen, dass unser Modellserver gut funktioniert. Die vorhergesagten Probenwerte deuten darauf hin, dass der Weintyp Rubresco ist.
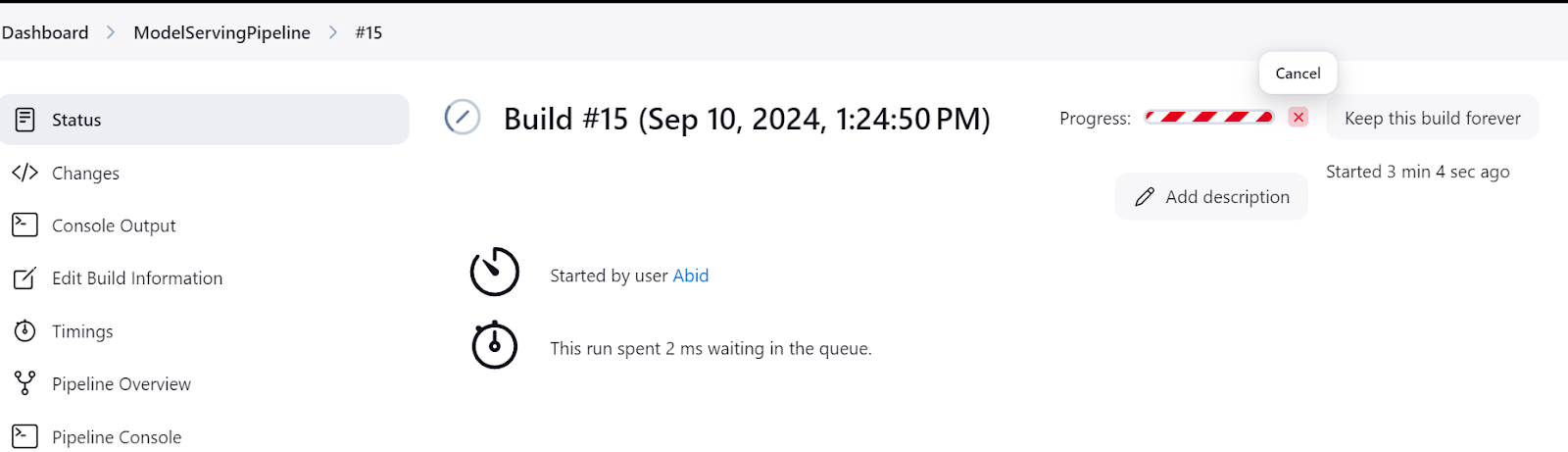
Achte immer darauf, dass du den Modellserver nach dem Experimentieren herunterfährst. Du kannst das tun, indem du im Jenkins-Dashboard zum Menü "Status" gehst und dann auf die Schaltfläche "Kreuz" klickst, wie unten gezeigt:
Der gesamte Code, die Datensätze, die Modelle und die Metadateien in diesem Tutorial sind im GitHub-Repository verfügbar, damit du siey: kingabzpro/MLOps-with-Jenkins.
Jenkins ist ein großartiger Automatisierungsserver für alle Arten von MLOps-Aufgaben. Es zeichnet sich als hervorragende Alternative zu GitHub Actions aus, da es mehr Funktionen, mehr Kontrolle und mehr Datenschutz bietet.
Einer der attraktivsten Aspekte von Jenkins ist seine Einfachheit bei der Erstellung und Ausführung von Pipelines, die es sowohl für Anfänger als auch für erfahrene Nutzer zugänglich macht.
Wenn du daran interessiert bist, ähnliche Möglichkeiten mit GitHub Actions zu erkunden, solltest du dir das Tutorial A Beginner's Guide to CI/CD for Machine Learning nicht entgehen lassen. Für diejenigen, die ihr Verständnis von MLOps vertiefen wollen, ist der Kurs "Fully Automated MLOps " eine fantastische Ressource. Es bietet umfassende Einblicke in die MLOps-Architektur, CI/CD/CM/CT-Techniken und Automatisierungsmuster für die Bereitstellung von ML-Systemen, die über einen längeren Zeitraum hinweg konsistent Werte liefern können.
In diesen Kursen erfährst du mehr über MLOps!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
