programa
Ingeniero de datos en Python
40 h
Las particiones son componentes esenciales dentro de la arquitectura distribuida de Kafka que permiten a Kafka escalar horizontalmente, permitiendo un procesamiento de datos en paralelo eficiente. Son los bloques de construcción para organizar y distribuir datos a través del clúster Kafka.
Piensa en ellos como canales individuales dentro de un tema donde se almacenan los mensajes. Cada partición puede tener varias réplicas repartidas entre distintos corredores, lo que garantiza la tolerancia a fallos y la redundancia de datos.
Además, las particiones proporcionan garantías de orden, asegurando que los mensajes dentro de una partición se procesen en el orden en que se produjeron. Esto hace que las particiones de Kafka sean fundamentales para mantener la integridad y coherencia de los datos, lo que es crucial para los escenarios de procesamiento de datos en tiempo real.
En este artículo, profundizaremos en lo siguiente:
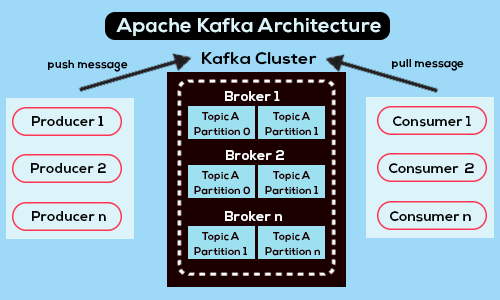
Una visión general de la arquitectura de Kafka - Fuente
Apache Kafka es una plataforma de streaming distribuido de código abierto diseñada para ofrecer un alto rendimiento, tolerancia a fallos y escalabilidad, lo que la convierte en una opción muy popular para crear canalizaciones de datos y aplicaciones en tiempo real.
En su núcleo, Kafka consta de múltiples componentes. Estos componentes incluyen productores, consumidores, intermediarios, temas y particiones, y cada uno desempeña un papel crucial en el sistema global.
Las particiones desempeñan un papel clave en la eficacia y robustez de Kafka. Facilitan la distribución de datos a través de los brokers de Kafka, permitiendo el escalado horizontal.
Al dividir los temas en particiones, Kafka puede repartir las cargas de trabajo de procesamiento de datos entre varios servidores, lo que permite una utilización eficiente de los recursos y acomodar volúmenes de datos cada vez mayores sin abrumar a los corredores individuales.
Además, las particiones también permiten el paralelismo en el procesamiento de datos. Los consumidores pueden leer de varias particiones simultáneamente, distribuyendo la carga computacional y mejorando el rendimiento. Este consumo paralelo de datos garantiza una utilización eficaz de los recursos de los consumidores y reduce la latencia en las cadenas de procesamiento de datos.
Otra razón por la que las particiones son importantes en Kafka es que ayudan con las capacidades de tolerancia a fallos de la plataforma. Cada partición puede tener varias réplicas distribuidas en distintos corredores. En caso de fallo de un broker, Kafka puede seguir sirviendo datos desde réplicas alojadas en otros brokers, garantizando la disponibilidad y fiabilidad de los datos.
Esencialmente, las particiones son importantes por múltiples razones. Son cruciales para la arquitectura de Kafka y desempeñan un papel fundamental para permitir la escalabilidad, la tolerancia a fallos, el paralelismo y la coherencia de los datos.
Como se ha mencionado antes en el artículo, cada partición actúa como una secuencia segmentada, ordenada e inmutable de registros. Cuando un productor envía datos a Kafka, utiliza la lógica de partición para determinar en qué partición dentro de un tema deben escribirse los datos.
Esta lógica puede basarse en varios factores, como una clave asociada a los datos o un particionador personalizado implementado por el productor. Una vez determinada la partición, Kafka añade los datos al final de la partición, manteniendo el orden de los mensajes en función de sus desplazamientos.
Internamente, los brokers Kafka se encargan del almacenamiento y replicación de los datos de las particiones. Cada partición puede tener varias réplicas distribuidas en distintos corredores para garantizar la tolerancia a fallos.
Se emplea un modelo líder-seguidor en el que un corredor actúa como líder responsable de gestionar las peticiones de lectura y escritura de la partición, mientras que los demás corredores actúan como seguidores replicando los datos del líder. Esta configuración garantiza la durabilidad y disponibilidad de los datos, incluso en caso de fallo del intermediario.
Antes de configurar una partición Kafka, asegúrate de que Apache Kafka y Zookeeper están instalados, configurados y funcionando en tu máquina local. Esto se recomienda para una compatibilidad óptima. Comprueba también que Java 8 o una versión más reciente está instalada y operativa.
Nota Kafka puede encontrar varios problemas cuando se instala en Windows debido a su falta de compatibilidad nativa con este sistema operativo. Por lo tanto, se recomienda utilizar los siguientes métodos para lanzar Apache Kafka en Windows:
Se desaconseja utilizar la JVM para ejecutar Kafka en Windows porque carece de ciertas características POSIX inherentes a Linux. Intentar ejecutar Kafka en Windows sin WSL2 puede provocar eventuales dificultades.
Puedes obtener más información sobre cómo configurar Apache Kafka en Apache Kafka para principiantes: Una guía completa.
Aquí tienes una guía paso a paso para configurar particiones:
Abre el símbolo del sistema y navega hasta el directorio raíz de Kafka. Una vez allí, ejecuta el siguiente comando para iniciar Zookeeper:
bin/zookeeper-server-start.sh config/zookeeper.propertiesAbre otro símbolo del sistema y ejecuta el siguiente comando desde la raíz de Apache Kafka para iniciar Apache Kafka:
.\bin\windows\kafka-server-start.bat .\config\server.propertiesPara crear un tema con tres particiones, inicia un nuevo símbolo del sistema desde el directorio raíz de Kafka y ejecuta el siguiente comando:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic my_topicEsto creará un nuevo tema Kafka llamado "mi_tema".
Nota: para confirmar que se ha creado correctamente, al ejecutar el comando se devolverá “Create topic .”
Puedes verificar que el tema se ha creado correctamente ejecutando:
bin/kafka-topics.sh --list --zookeeper localhost:2181Que debería salir:
my_topicReparticionar temas existentes en Kafka implica modificar el recuento de particiones, lo que puede ser necesario para acomodar volúmenes de datos cambiantes, mejorar el paralelismo u optimizar la utilización de recursos.
He aquí algunas técnicas y consideraciones para reparticionar los temas existentes:
kafka-topics.sh --alter para aumentar el número de particiones de un tema existente. Esto redistribuirá los datos entre las nuevas particiones.Optimizar el uso y el rendimiento de las particiones en Kafka es esencial para garantizar un procesamiento eficaz de los datos, la utilización de los recursos y la escalabilidad general del sistema.
Veamos algunas estrategias para equilibrar y optimizar las particiones:
Kafka se ha convertido en la columna vertebral de muchas aplicaciones de uso intensivo de datos, pero para jugar con las palabras del Tío Ben de Spiderman, con un gran poder viene un mayor potencial de retos complejos.
Al utilizar Kafka pueden surgir algunos problemas comunes de partición. Esto puede deberse a una configuración incorrecta, a limitaciones de recursos, a una distribución desigual de los datos o a otra causa.
En esta sección, profundizaremos en los problemas habituales de las particiones y discutiremos cómo resolverlos.
Cuando los datos se distribuyen de forma desigual por las particiones, algunas de ellas pueden convertirse en puntos calientes, lo que provoca una utilización desigual de los recursos y posibles cuellos de botella en el rendimiento. La forma de evitarlo es supervisar constantemente la distribución de datos, lo que puede hacerse con las herramientas de supervisión de Kafka, como Kafka Manager o Confluent Control Center. Además, considera la posibilidad de aplicar una estrategia de partición personalizada o aumentar el número de particiones para conseguir distribuciones de datos más equilibradas.
Cuando una partición acumula una gran cantidad de datos a lo largo del tiempo, puede provocar una degradación del rendimiento y un aumento de la latencia durante la recuperación y el procesamiento de los datos.
La clave para resolver este problema es controlar regularmente el tamaño de las particiones y dividir las particiones grandes en otras más pequeñas para distribuir los datos de forma más uniforme. Además, ayuda a ajustar las políticas de retención para controlar la cantidad de datos almacenados en las particiones.
Las particiones insuficientemente replicadas se producen cuando el número de réplicas sincronizadas (ISR) cae por debajo del mínimo configurado ante fallos del broker o problemas de red.
Para evitarlo, supervisa el estado de replicación de las particiones e investiga si hay particiones insuficientemente replicadas. Asegúrate de que el factor de replicación está configurado adecuadamente para mantener el nivel deseado de tolerancia a fallos. Aborda con prontitud cualquier problema relacionado con la conectividad de la red o los fallos del intermediario.
Los líderes de las particiones gestionan, leen y escriben peticiones en un clúster Kafka. Un desequilibrio en los líderes de partición entre los corredores puede provocar una utilización desigual de los recursos y posibles problemas de rendimiento.
Esto puede evitarse controlando la distribución de los líderes de partición mediante Kafka Manager o Confluent Control Center y reequilibrando los líderes si es necesario. Además, considera la posibilidad de ajustar las configuraciones de los corredores para distribuir los líderes de partición uniformemente entre los corredores.
El sesgo de partición se produce cuando determinadas particiones reciben un volumen de tráfico desproporcionadamente alto en comparación con otras, lo que provoca una utilización desigual de los recursos y una posible degradación del rendimiento. Por eso es importante analizar los patrones de tráfico.
Considera la posibilidad de aplicar una estrategia de particionamiento personalizada para distribuir los datos entre las particiones de forma uniforme y optimizar las configuraciones de los grupos de consumidores para distribuir la carga de trabajo entre los consumidores de forma uniforme.
Apache Kafka es una robusta plataforma de streaming distribuido que sirve de columna vertebral para numerosas aplicaciones intensivas en datos. En su núcleo se encuentra el concepto de particiones, que son unidades esenciales para organizar y distribuir los datos dentro de los temas de Kafka. Las particiones son fundamentales en el ecosistema de Kafka, ya que permiten la escalabilidad, la tolerancia a fallos, el paralelismo y el procesamiento eficiente de los datos.
Al distribuir los datos entre varios corredores, las particiones permiten a Kafka manejar grandes volúmenes de datos manteniendo un alto rendimiento y fiabilidad. Además, las particiones facilitan el procesamiento paralelo de los datos, garantizando una utilización óptima de los recursos y una latencia reducida.
En última instancia, la comprensión y la gestión eficaz de las particiones son fundamentales para maximizar el rendimiento y la fiabilidad de los clústeres Kafka, convirtiéndolos en componentes indispensables para crear canalizaciones y aplicaciones de datos en tiempo real escalables y resistentes.
Aquí tienes algunos recursos para continuar tu aprendizaje:
Sigue aprendiendo con DataCamp
programa
programa
Curso
blog
Mike Shakhomirov
11 min
blog
Adejumo Ridwan Suleiman
13 min
blog
Abid Ali Awan
7 min
Tutorial
Kevin Babitz

