Programa
Engenheiro de dados Em Python
40 h
As partições são componentes essenciais da arquitetura distribuída do Kafka que permitem que o Kafka seja dimensionado horizontalmente, possibilitando um processamento de dados paralelo eficiente. Eles são os blocos de construção para organizar e distribuir dados no cluster do Kafka.
Pense neles como canais individuais em um tópico em que as mensagens são armazenadas. Cada partição pode ter várias réplicas espalhadas por diferentes brokers, garantindo tolerância a falhas e redundância de dados.
Além disso, as partições oferecem garantias de ordenação, assegurando que as mensagens em uma partição sejam processadas na ordem em que foram produzidas. Isso faz com que as partições do Kafka sejam fundamentais para manter a integridade e a consistência dos dados, o que é crucial para cenários de processamento de dados em tempo real.
Neste artigo, vamos nos aprofundar nos seguintes aspectos:
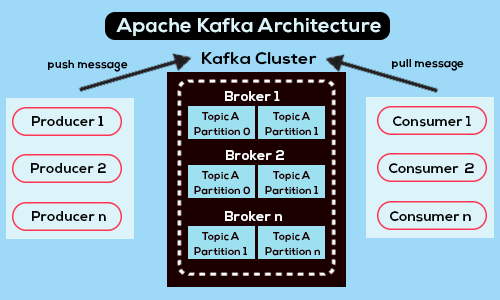
Uma visão geral da arquitetura do Kafka - Fonte
O Apache Kafka é uma plataforma de streaming distribuído de código aberto projetada para alta taxa de transferência, tolerância a falhas e escalabilidade, o que o torna uma opção popular para a criação de pipelines e aplicativos de dados em tempo real.
Em sua essência, o Kafka é composto por vários componentes. Esses componentes incluem produtores, consumidores, corretores, tópicos e partições, e cada um deles desempenha uma função crucial no sistema geral.
As partições desempenham um papel fundamental na formação da eficiência e da robustez do Kafka. Eles facilitam a distribuição de dados entre os corretores Kafka, permitindo o dimensionamento horizontal.
Ao dividir os tópicos em partições, o Kafka pode distribuir as cargas de trabalho de processamento de dados entre vários servidores, permitindo a utilização eficiente de recursos e acomodando volumes de dados cada vez maiores sem sobrecarregar os brokers individuais.
Além disso, as partições também permitem o paralelismo no processamento de dados. Os consumidores podem ler de várias partições ao mesmo tempo, distribuindo a carga computacional e aumentando a taxa de transferência. Esse consumo paralelo de dados garante a utilização eficiente dos recursos do consumidor e reduz a latência nos pipelines de processamento de dados.
Outro motivo pelo qual as partições são importantes no Kafka é que elas ajudam com os recursos de tolerância a falhas da plataforma. Cada partição pode ter várias réplicas distribuídas em diferentes brokers. No caso de falha de um broker, o Kafka pode continuar a fornecer dados de réplicas hospedadas em outros brokers, garantindo a disponibilidade e a confiabilidade dos dados.
Essencialmente, as partições são importantes por vários motivos. Eles são cruciais para a arquitetura do Kafka e desempenham um papel fundamental para permitir escalabilidade, tolerância a falhas, paralelismo e consistência de dados.
Conforme mencionado anteriormente no artigo, cada partição funciona como uma sequência de registros segmentada, ordenada e imutável. Quando um produtor envia dados para o Kafka, ele usa a lógica de particionamento para determinar em qual partição de um tópico os dados devem ser gravados.
Essa lógica pode ser baseada em vários fatores, como uma chave associada aos dados ou um particionador personalizado implementado pelo produtor. Quando a partição é determinada, o Kafka anexa os dados ao final da partição, mantendo a ordem das mensagens com base em seus offsets.
Internamente, os agentes do Kafka lidam com o armazenamento e a replicação dos dados da partição. Cada partição pode ter várias réplicas distribuídas em diferentes brokers para garantir a tolerância a falhas.
Um modelo de líder e seguidor é empregado, no qual um corretor atua como líder responsável por lidar com solicitações de leitura e gravação para a partição, enquanto os outros corretores atuam como seguidores replicando dados do líder. Essa configuração garante a durabilidade e a disponibilidade dos dados, mesmo em caso de falhas do broker.
Antes de instalar uma partição do Kafka, certifique-se de que o Apache Kafka e o Zookeeper estejam instalados, configurados e em execução no computador local. Isso é recomendado para uma compatibilidade ideal. Além disso, verifique se o Java 8 ou uma versão mais recente está instalado e funcionando.
Observação: o Kafka pode apresentar vários problemas quando instalado no Windows devido à falta de compatibilidade nativa com esse sistema operacional. Portanto, é recomendável que você utilize os seguintes métodos para iniciar o Apache Kafka no Windows:
O uso do JVM para executar o Kafka no Windows é desaconselhado porque ele não possui determinadas características POSIX inerentes ao Linux. Se você tentar executar o Kafka no Windows sem o WSL2, poderá ter dificuldades.
Você pode saber mais sobre a configuração do Apache Kafka em Apache Kafka para iniciantes: Um guia abrangente.
Aqui está um guia passo a passo para você configurar partições:
Abra o prompt de comando e navegue até o diretório raiz do Kafka. Uma vez lá, execute o seguinte comando para iniciar o Zookeeper:
bin/zookeeper-server-start.sh config/zookeeper.propertiesAbra outro prompt de comando e execute o seguinte comando na raiz do Apache Kafka para iniciar o Apache Kafka:
.\bin\windows\kafka-server-start.bat .\config\server.propertiesPara criar um tópico com três partições, inicie um novo prompt de comando no diretório raiz do Kafka e execute o seguinte comando:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic my_topicIsso criará um novo tópico do Kafka chamado "my_topic".
Observação: para confirmar que ele foi criado corretamente, a execução do comando retornará “Create topic .”
Você pode verificar se o tópico foi criado corretamente executando:
bin/kafka-topics.sh --list --zookeeper localhost:2181O que deve gerar:
my_topicO reparticionamento de tópicos existentes no Kafka envolve a modificação da contagem de partições, o que pode ser necessário para acomodar volumes de dados variáveis, melhorar o paralelismo ou otimizar a utilização de recursos.
Aqui estão algumas técnicas e considerações para reparticionar os tópicos existentes:
kafka-topics.sh --alter para aumentar a contagem de partições de um tópico existente. Isso redistribuirá os dados entre as novas partições.Otimizar o uso e o desempenho da partição no Kafka é essencial para garantir o processamento eficiente de dados, a utilização de recursos e a escalabilidade geral do sistema.
Vamos dar uma olhada em algumas estratégias de balanceamento e otimização de partições:
O Kafka se tornou a espinha dorsal de muitos aplicativos com uso intensivo de dados, mas, para usar as palavras do Tio Ben do Homem-Aranha, com grande poder vem um maior potencial para desafios complexos.
Você pode ter alguns problemas comuns de partição ao usar o Kafka. Isso pode ser devido a configurações incorretas, restrições de recursos, distribuição desigual de dados ou outra coisa.
Nesta seção, vamos nos aprofundar nos problemas comuns de partição e discutir como resolvê-los.
Quando os dados são distribuídos de forma desigual entre as partições, algumas dessas partições podem se tornar pontos de acesso, resultando em utilização desigual de recursos e possíveis gargalos de desempenho. A maneira de contornar isso é monitorar constantemente a distribuição de dados, o que pode ser feito com as ferramentas de monitoramento do Kafka, como o Kafka Manager ou o Confluent Control Center. Além disso, considere implementar uma estratégia de particionamento personalizada ou aumentar a contagem de partições para obter distribuições de dados mais equilibradas.
Quando uma partição acumula uma grande quantidade de dados ao longo do tempo, isso pode levar à degradação do desempenho e ao aumento da latência durante a recuperação e o processamento de dados.
A chave para resolver esse problema é monitorar regularmente o tamanho da partição e dividir partições grandes em menores para distribuir os dados de forma mais uniforme. Além disso, ele ajuda a ajustar as políticas de retenção para controlar a quantidade de dados armazenados nas partições.
As partições sub-replicadas ocorrem quando o número de réplicas em sincronia (ISRs) cai abaixo do mínimo configurado diante de falhas do broker ou de problemas de rede.
Para evitar isso, monitore o status de replicação das partições e investigue se há alguma partição pouco replicada. Certifique-se de que o fator de replicação esteja configurado adequadamente para manter o nível desejado de tolerância a falhas. Resolva prontamente quaisquer problemas relacionados à conectividade da rede ou falhas do broker.
Os líderes de partição manipulam, leem e gravam solicitações em um cluster do Kafka. Um desequilíbrio nos líderes de partição entre os brokers pode levar à utilização desigual de recursos e a possíveis problemas de desempenho.
Isso pode ser evitado monitorando a distribuição do líder da partição usando o Kafka Manager ou o Confluent Control Center e reequilibrando os líderes, se necessário. Além disso, considere ajustar as configurações do broker para distribuir os líderes de partição uniformemente entre os brokers.
A distorção de partição ocorre quando determinadas partições recebem um volume de tráfego desproporcionalmente alto em comparação com outras, o que leva à utilização desigual de recursos e à possível degradação do desempenho. É por isso que é importante analisar os padrões de tráfego.
Considere a possibilidade de implementar uma estratégia de particionamento personalizada para distribuir uniformemente os dados entre as partições e otimizar as configurações do grupo de consumidores para distribuir uniformemente a carga de trabalho entre os consumidores.
O Apache Kafka é uma plataforma robusta de streaming distribuído que serve como espinha dorsal para vários aplicativos com uso intensivo de dados. Em seu núcleo está o conceito de partições, que são unidades essenciais para organizar e distribuir dados nos tópicos do Kafka. As partições são essenciais no ecossistema do Kafka, permitindo escalabilidade, tolerância a falhas, paralelismo e processamento eficiente de dados.
Ao distribuir os dados entre vários brokers, as partições permitem que o Kafka lide com grandes volumes de dados e, ao mesmo tempo, mantenha alta taxa de transferência e confiabilidade. Além disso, as partições facilitam o processamento paralelo de dados, garantindo a utilização ideal dos recursos e a redução da latência.
Por fim, a compreensão e o gerenciamento eficaz das partições são essenciais para maximizar o desempenho e a confiabilidade dos clusters do Kafka, tornando-os componentes indispensáveis na criação de aplicativos e pipelines de dados em tempo real escalonáveis e resilientes.
Aqui estão alguns recursos para você continuar aprendendo:
Continue aprendendo com a DataCamp
Programa
Programa
Curso
blog
Çağlar Uslu
15 min
blog
Moez Ali
11 min
blog
Abid Ali Awan
7 min
Tutorial
Bex Tuychiev
Tutorial
Kurtis Pykes