
Track
Data Engineer in Python
40 hr
Partitions are essential components within Kafka's distributed architecture that enable Kafka to scale horizontally, allowing for efficient parallel data processing. They are the building blocks for organizing and distributing data across the Kafka cluster.
Think of them as individual channels within a topic where messages are stored. Each partition can have multiple replicas spread across different brokers, guaranteeing fault tolerance and data redundancy.
Moreover, partitions provide ordering guarantees, ensuring that messages within a partition are processed in the order they were produced. This makes Kafka partitions instrumental in maintaining data integrity and consistency, which is crucial for real-time data processing scenarios.
In this article, we will dive deeper into the following:
You can check out our comparison of Kafka vs SQS for a detailed guide of how the two tools stack up.
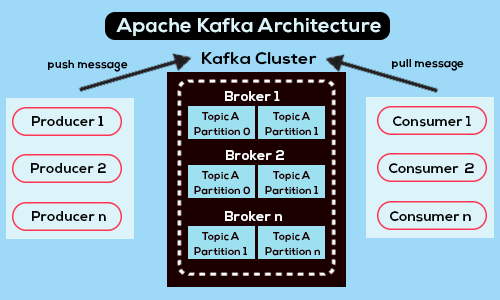
An overview of Kafka’s architecture - Source
Apache Kafka is an open-source distributed streaming platform designed for high throughput, fault tolerance, and scalability, making it a popular choice for building real-time data pipelines and applications.
At its core, Kafka comprises multiple components. These components include producers, consumers, brokers, topics, and partitions, and each plays a crucial role in the overall system.
Partitions play a key role in shaping Kafka’s efficiency and robustness. They facilitate data distribution across Kafka brokers, allowing for horizontal scaling.
By dividing topics into partitions, Kafka can spread data processing workloads across multiple servers, enabling efficient resource utilization and accommodating increasing data volumes without overwhelming individual brokers.
Moreover, partitions also enable parallelism in data processing. Consumers can read from multiple partitions concurrently, distributing the computational load and enhancing throughput. This parallel data consumption ensures efficient utilization of consumer resources and reduces latency in data processing pipelines.
Another reason partitions matter in Kafka is that they help with the platform's fault tolerance capabilities. Each partition can have multiple replicas distributed across different brokers. In the event of a broker failure, Kafka can continue to serve data from replicas hosted on other brokers, ensuring data availability and reliability.
Essentially, partitions matter for multiple reasons. They are crucial to Kafka’s architecture and play a pivotal role in enabling scalability, fault tolerance, parallelism, and data consistency.
As mentioned earlier in the article, each partition acts as a segmented, ordered, and immutable sequence of records. When a producer sends data to Kafka, it uses partitioning logic to determine which partition within a topic the data should be written to.
This logic can be based on various factors, such as a key associated with the data or a custom partitioner implemented by the producer. Once the partition is determined, Kafka appends the data to the end of the partition, maintaining the order of messages based on their offsets.
Internally, Kafka brokers handle the storage and replication of partition data. Each partition can have multiple replicas distributed across different brokers to ensure fault tolerance.
A leader-follower model is employed where one broker serves as the leader responsible for handling read and write requests for the partition, while the other brokers act as followers replicating data from the leader. This setup ensures data durability and availability even in the event of broker failures.
Before setting up a Kafka partition, ensure that Apache Kafka and Zookeeper have been installed, configured, and running on your local machine. This is recommended for optimum compatibility. Also, check that Java 8 or a newer version is installed and operational.
Note Kafka may encounter various issues when installed on Windows due to its lack of native compatibility with this operating system. Therefore, it's recommended to utilize the following methods to launch Apache Kafka on Windows:
Using the JVM to run Kafka on Windows is discouraged because it lacks certain POSIX characteristics inherent to Linux. Attempting to run Kafka on Windows without WSL2 may lead to eventual difficulties.
You can learn more about setting up Apache Kafka in Apache Kafka for Beginners: A Comprehensive Guide.
Here's a step-by-step guide to setting up partitions:
Open the command prompt and navigate to the root Kafka directory. Once there, run the following command to start Zookeeper:
bin/zookeeper-server-start.sh config/zookeeper.propertiesOpen another command prompt and run the following command from the root of Apache Kafka to start Apache Kafka:
.\bin\windows\kafka-server-start.bat .\config\server.propertiesTo create a topic with three partitions, start a new command prompt from the root Kafka directory and run the following command:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic my_topicThis will create a new Kafka topic called “my_topic.”
Note: to confirm it’s created correctly, executing the command will return “Create topic <name of topic>.”
You can verify the topic is created correctly by running:
bin/kafka-topics.sh --list --zookeeper localhost:2181Which should output:
my_topicRepartitioning existing topics in Kafka involves modifying the partition count, which can be necessary to accommodate changing data volumes, improve parallelism, or optimize resource utilization.
Here are some techniques and considerations for repartitioning existing topics:
kafka-topics.sh --alter command to increase the partition count of an existing topic. This will redistribute data across the new partitions.Optimizing partition usage and performance in Kafka is essential for ensuring efficient data processing, resource utilization, and overall system scalability.
Let’s take a look at some strategies for partition balancing and optimization:
Kafka has become the backbone of many data-intensive applications, but to play on the words of Uncle Ben from Spider-Man, with great power comes increased potential for complex challenges.
Quite a few common partition issues may arise when using Kafka. This may be due to misconfigurations, resource constraints, uneven data distribution, or something else.
In this section, we will dive deeper into the common partition issues and discuss how to solve them.
When data is distributed unevenly across partitions, some of those partitions may become hotspots, resulting in uneven resource utilization and potential performance bottlenecks. The way around this is to constantly monitor data distribution, which can be done with Kafka’s monitoring tools like Kafka Manager or Confluent Control Center. Also, consider implementing a custom partitioning strategy or increasing the partition count to achieve more balanced data distributions.
When a partition accumulates a large amount of data over time, it can lead to performance degradation and increased latency during data retrieval and processing.
The key to solving this problem is regularly monitoring partition size and splitting large partitions into smaller ones to distribute the data more evenly. Additionally, it helps to adjust retention policies to control the amount of data stored in partitions.
Under-replicated partitions occur when the number of in-sync replicas (ISRs) falls below the configured minimum in the face of broker failures or network issues.
To prevent this, monitor the replication status of partitions and investigate any under-replicated partitions. Ensure that the replication factor is appropriately configured to maintain the desired level of fault tolerance. Address any issues related to network connectivity or broker failures promptly.
Partition leaders handle, read, and write requests in a Kafka cluster. An imbalance in partition leaders across brokers can lead to uneven resource utilization and potential performance issues.
This can be prevented by monitoring partition leader distribution using Kafka Manager or Confluent Control Center and rebalancing leaders if necessary. Also, consider adjusting broker configurations to distribute partition leaders evenly across brokers.
Partition skew occurs when certain partitions receive a disproportionately high volume of traffic compared to others, leading to uneven resource utilization and potential performance degradation. This is why it’s important to analyze traffic patterns.
Consider implementing a custom partitioning strategy to distribute data across partitions evenly and optimize consumer group configurations to distribute workload among consumers evenly.
Apache Kafka is a robust distributed streaming platform that serves as the backbone for numerous data-intensive applications. At its core lies the concept of partitions, which are essential units for organizing and distributing data within Kafka topics. Partitions are pivotal in Kafka's ecosystem, enabling scalability, fault tolerance, parallelism, and efficient data processing.
By distributing data across multiple brokers, partitions allow Kafka to handle large volumes of data while maintaining high throughput and reliability. Additionally, partitions facilitate parallel data processing, ensuring optimal resource utilization and reduced latency.
Ultimately, understanding and effectively managing partitions are critical for maximizing the performance and reliability of Kafka clusters, making them indispensable components in building scalable and resilient real-time data pipelines and applications.
Here are some resources to continue your learning:
Keep Learning With DataCamp
Track
Track
Course
blog
Adejumo Ridwan Suleiman
13 min
blog
Zahara Miriam
15 min
blog
Sanjana Putchala
10 min
blog
Alex Castrounis
13 min
blog
Mike Shakhomirov
11 min
Tutorial
Kurtis Pykes
