
Curso
Data Processing in Shell
4 h
22.9K
Data is essential to businesses and organizations, and the task of organizing the flow of all that data is where data pipelines shine. So, what are data pipelines, and what do you need to know to build a pipeline of your own?
Data is the lifeblood of modern businesses and organizations, driving decision-making, insights, and innovation. However, managing and harnessing the power of data can be a complex and daunting task. This is where data pipelines come into play. But what are data pipelines?
A data pipeline is a system for retrieving data from various sources and funneling it into a new location, such as a database, repository, or application, and performing any necessary data transformation (converting data from one format or structure into another) along the way. End users for this pipeline vary from analysts to data scientists to business leaders.
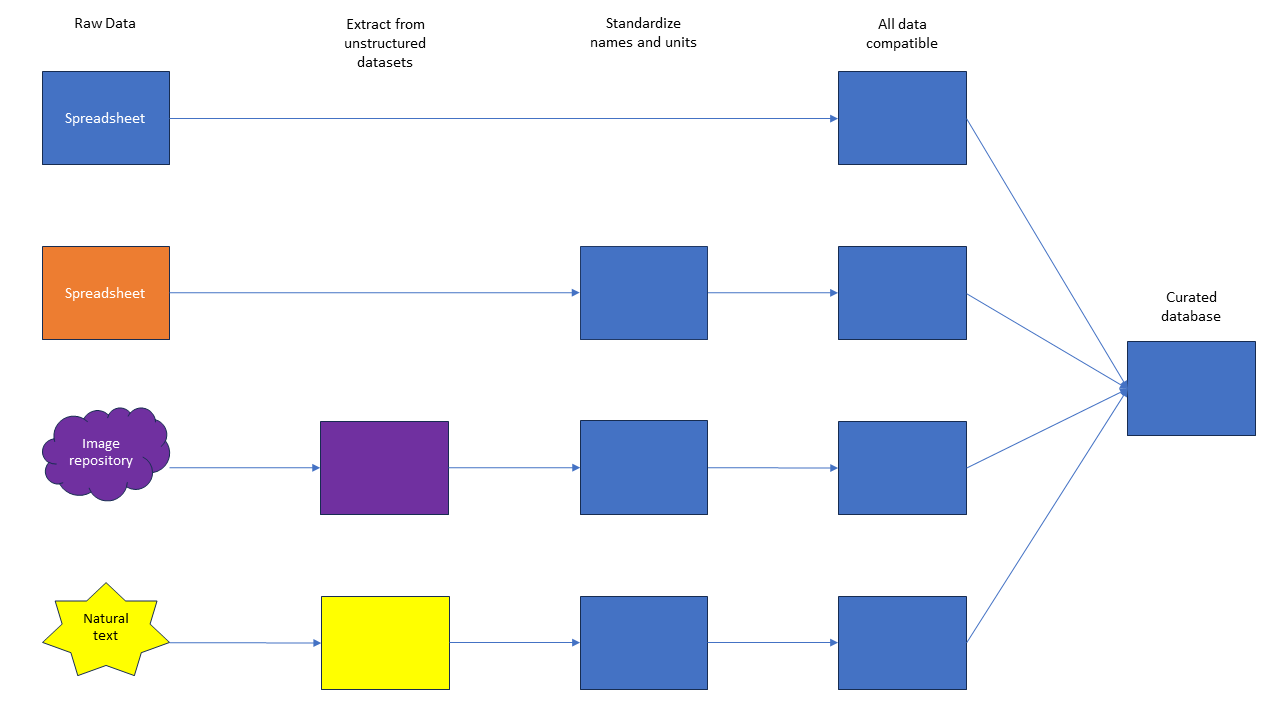
Figure 1: Example of a simple data pipeline. In this example, you have four data sources: two structured and two unstructured. Through a series of steps, you extract structured data from the unstructured data sets, standardize all the names and units, and, once all the data is compatible, you can create one, curated database with all the information necessary. This database can then be used by analysts, scientists, or business leaders.
While this sounds like a simple task, it comes with a lot of headaches and decisions. In many organizations, building and maintaining pipelines is an entire job handled by data engineers. In other organizations, it is merely one of the myriad tasks done by a data scientist. Who maintains the pipeline often comes down to the size of the organization, the complexity of the pipelines, and the funding available.
Building a reliable, secure, and timely pipeline is a crucial part of data-driven decision-making. Whether you’re interested in pursuing data engineering or a career in any other part of the data process, it will be worth your while to understand data pipelines.
You may be wondering why you would need to build a pipeline at all. If you’ve been working with premade data sets or data that comes from only one source, like you may find from Kaggle or DataCamp exercises, you probably didn’t need a pipeline at all. These curated datasets were already set up for analysts to pull and work with directly.
However, if you want to combine information from many sources, you may need to set up a pipeline to ensure all the data can be accessible for your analysis.
Here are some key reasons why you might consider using data pipelines:
For example, imagine you want to know if the average GPA of students in a school district correlates with the average income in the county or with the population size. For this analysis, you may need to pull GPA data from each school district in your analysis, income data from the IRS, and population size from the Census Bureau.
You could probably pull this information manually once. But imagine you need to repeat this analysis regularly. Building a reliable pipeline can help you automate this information collection, saving you time and headaches.
In addition to just collecting the data in one place, pipelines can help you deal with inconsistencies in data from different sources. For example, the Census Bureau may identify counties by full name, while the IRS may identify counties by an abbreviated name.
Within the pipeline, you can set up a system to standardize the way counties are identified in the final repository. Or, perhaps population is marked with different units in different entries, and you need to standardize which unit system is used in your final destination. These types of changes are called transformations.
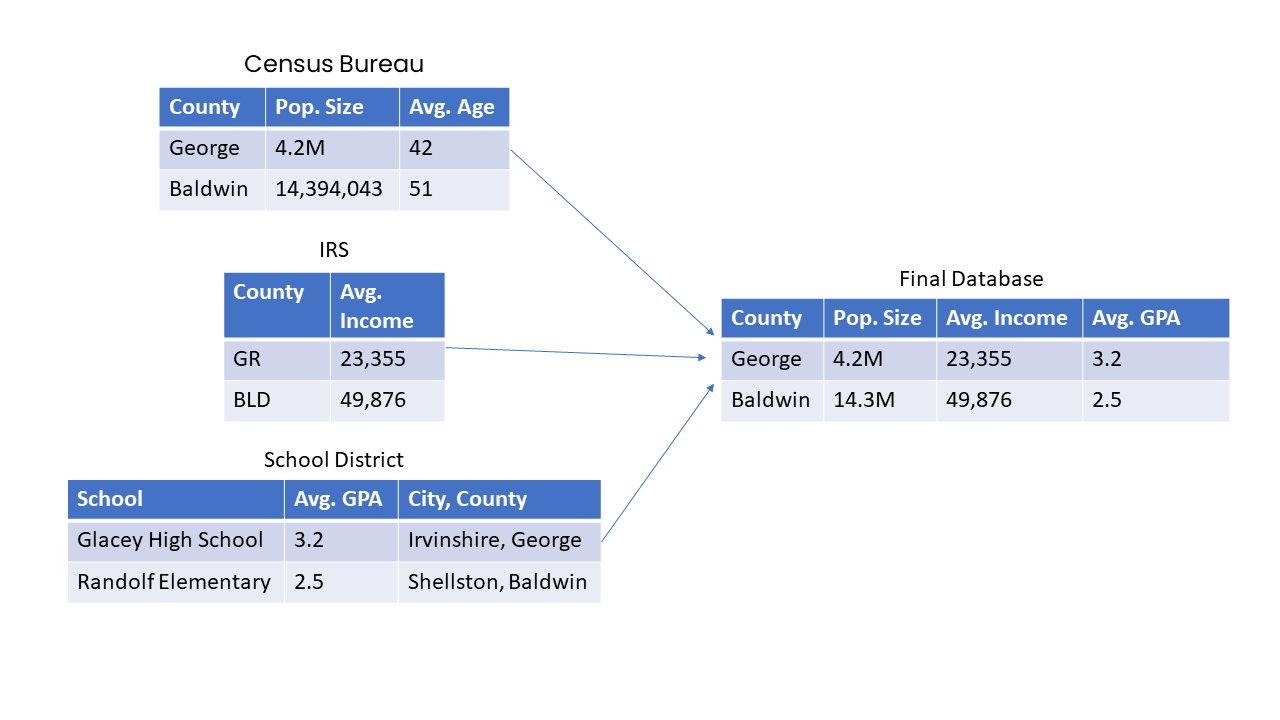
Figure 2: When combining information from different sources, transformations such as unit changes and standardized names may be necessary.
Data pipelines are generally developed and maintained by data engineers.
Once the data is collected, cleaned, and organized at the end of the pipeline, the data can be pulled by various stakeholders, including data analysts, data scientists, or business analysts.
The data can then be used for real-time analytics, dumped into an updating dashboard, or added to a machine learning model. Sometimes, the end of the pipeline may be an application or dashboard used by a business leader or individual.
Pipelines are used by virtually every sector that utilizes large amounts of data. In some large organizations, like those in the tech sector, their pipelines will be complex, highly regulated, and managed by a team of specialized engineers.
In smaller organizations, for example a single researcher trying to collect data from multiple sensors around the world, the pipeline may be very straightforward and simple, with only a few steps. Other examples where pipelines may be used are a stock broker collecting financial information to decide which stocks to buy or a hospital system collecting patient records from their various hospital affiliates.
Pipelines are also crucial for machine learning models. These models consume huge amounts of data, and a proper pipeline is imperative for smooth functioning. This MLOps tutorial gives more detail on how pipelines are used in machine learning.
Data can be stored in several different ways, depending on the type of data and your desired use. Three terms you’re likely to come across with respect to data storage are data lakes, databases, and data warehouses. Let’s briefly touch on each of these.
A data lake is a large, flexible storage repository that can hold both structured and unstructured data at scale. It allows organizations to store raw, unprocessed data from various sources, such as web logs, sensors, social media, and more, in its native format.
Data lakes are known for their versatility, as they enable data scientists and analysts to explore, transform, and analyze data in a variety of ways. They are particularly valuable for big data and advanced analytics use cases where the schema and structure of the data are not predefined, giving organizations the flexibility to extract insights from diverse data sources.
Databases are more general-purpose systems used for efficiently storing, managing, and retrieving structured data. While they share some similarities with data warehouses, databases are typically used for transactional data, day-to-day operations, and real-time applications. They come in various types, including relational databases, NoSQL databases, and in-memory databases, each suited to specific data storage and processing requirements. Databases ensure data integrity, support concurrent access, and provide various mechanisms for querying and retrieving data.
Data warehouses, on the other hand, are highly structured and optimized repositories designed for storing, organizing, and querying structured data primarily for analytical purposes. They typically follow a predefined schema, enforce data quality and consistency, and are optimized for complex querying and reporting tasks.
Data warehouses are ideal for businesses looking to make informed decisions based on historical data, as they provide a single source of truth for standardized reporting and analytics. Data is usually extracted from various sources, transformed into a consistent format, and loaded into the data warehouse for analysis.
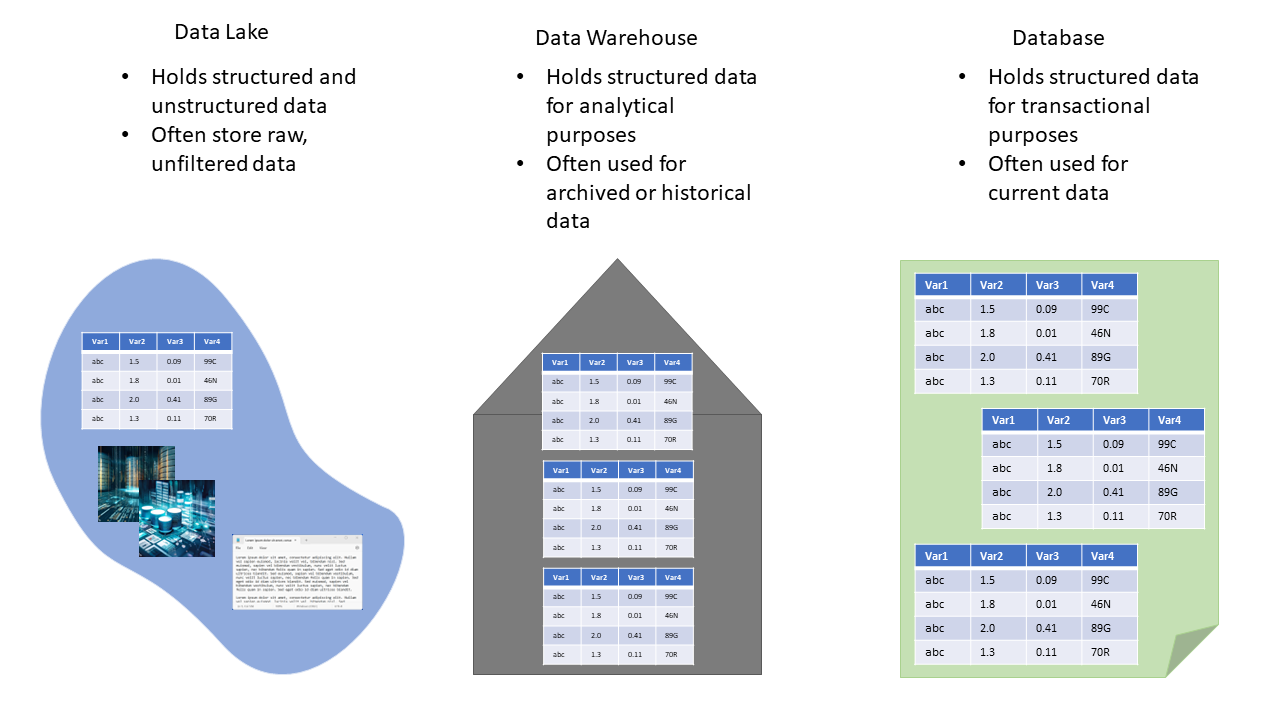
Figure 3: Showing some of the differences between a data lake, a data warehouse, and a database. A data lake may be used as a preceding step in a pipeline that may end in either a warehouse or database.
Pipelines generally follow one of two main schema: ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform).
ETL follows a sequential approach. First, data is extracted from various source systems, which can include databases, files, APIs, or other data repositories.
Once extracted, the data is transformed to meet the desired schema, quality, and business rules. This transformation can involve cleaning, aggregating, and structuring the data. Finally, the transformed data is loaded into the target data warehouse or storage system, often in a format optimized for reporting and analytics.
ETL is beneficial when data needs significant restructuring or cleaning before it's stored in the data warehouse, as it ensures that the data is clean and ready for analysis. This ETL with Python course gives you a detailed overview of ETL using Python and SQL.
ELT, on the other hand, reverses the order of the transformation step. In the ELT process, data is first extracted from source systems and loaded into a data warehouse, or sometimes a data lake, as is, without significant transformation. The transformation and processing of the data occur within the data warehouse itself.
This approach leverages the processing power and flexibility of modern data warehouses and big data platforms, making it suitable for scenarios where you want to store large volumes of raw data and perform transformations on-demand.
ELT is often favored when you have a data warehousing solution that can handle complex transformations efficiently, such as cloud-based data warehouses or distributed data processing frameworks like Hadoop.
There are a lot of tools available for developing pipelines. Choosing the right ones will depend on your pipeline size, scaling needs, available funding, and pipeline goals. You can make a complete pipeline using Python and SQL, (or R and SQL), or you can use some of a variety of commercial tools.
Here is a brief list of a few common commercial technologies and tools.
You can check out our list of the best ETL tools and why to use them in a separate article.
The first step in creating a data pipeline is collecting the data to be put into the pipeline. There are several places to get updated information online, including government web pages, social media outlets, and some nonprofit organizations. Often, these will have an API that is relatively straightforward to use.
An API (application programming interface) is essentially software that allows communication between two or more applications. For example, you may be able to incorporate an API for Twitter into your Python application that will allow your application to post tweets or “read” tweets on your behalf. It’s essentially a go-between.
You can use an API at the beginning of your pipeline to collect data from various sources. For example, you could use an API to collect company filing data from the SEC or to collect clinical data from tables kept by the NIH.
Another technique used to collect data is web scraping. This is a technique that uses a custom-coded script designed to collect information from a web page on the internet. Python libraries like BeautifulSoup and Scrapy make this process fairly easy, but you still need to be able to navigate through html or xml to be able to find the information you need.
If you’d like to learn more about web scraping, DataCamp has materials on Python’s Beautiful Soup, web scraping using R, and web scraping for NLP.
There are also code-free services for web scraping available. Here’s one such service that allows you to collect information from a webpage and monitor the page for changes.
Your data collection process may involve a mixture of structured data (such as spreadsheets or databases) and unstructured data (such as text or images).
Depending on what your end goal is for your pipeline, you may extract information from your unstructured data to create a uniformly structured dataset, or you may leave some of it unstructured and just ensure proper cross-referencing is available to the end user.
Structured data can often be extracted using SQL queries or ETL tools, while unstructured data may require natural language processing (NLP) techniques or specialized tools.
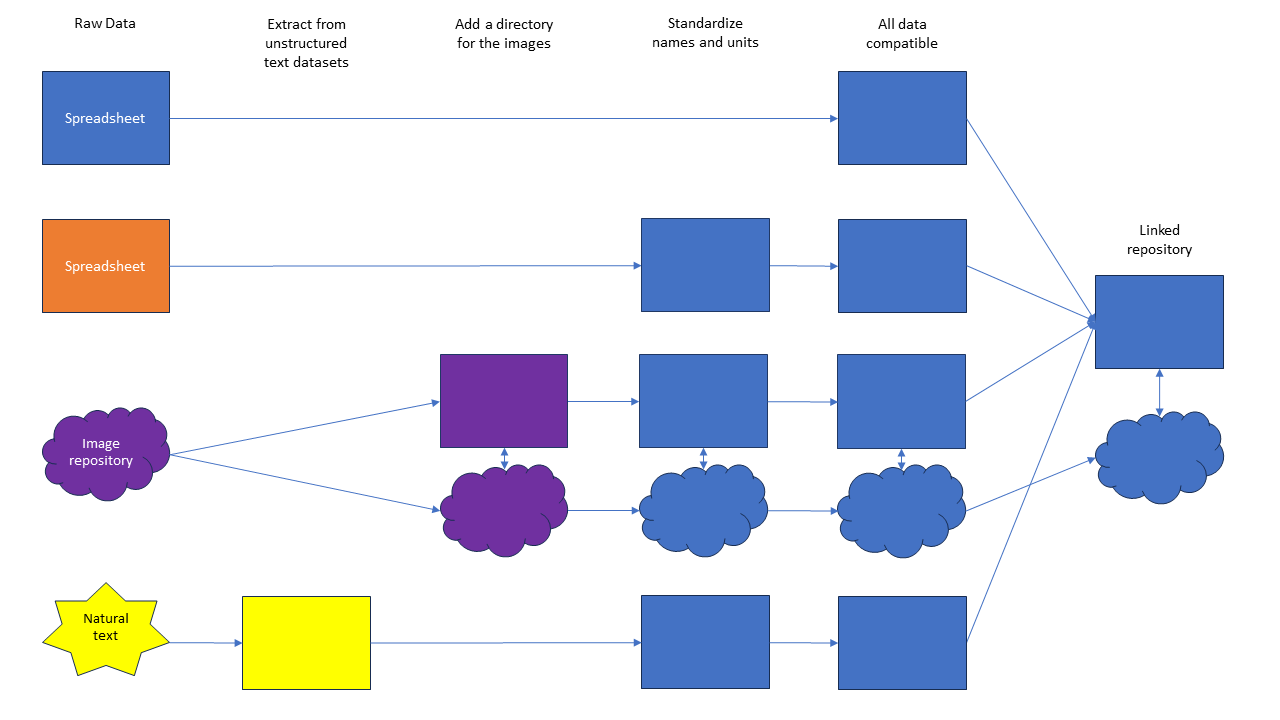
Figure 4: Example of a data pipeline with unstructured data left intact at the end. In this example, we want to create a repository of curated structured data and linked images. This could also be a data lake. So, instead of extracting structured data from the images, we created a directory linking the images to the relevant data in the database. The end user can then pull the raw image for each row in a spreadsheet, as needed. Alternatively, we could have done an analysis of the images and provided an image with sections isolated or removed. For information on how to do this, check out this image analysis tutorial.
Once you have data sources available and an end goal in mind, you can start to set up your pipeline.
The first thing you need to do is plan out your pipeline. I suggest mapping it out on paper first. On the far left of your paper, write your data sources, and on the far right, add your end goal. In between, you can lay out all the steps you need in order to get from your sources to your end goal.

Figure 5: Example plan for a pipeline.
Some potential steps you’ll need to include may be:
Once you have mapped out your plan, you need to start building it. This may be completely coded in your favorite programming language, or it can include one or more services designed to support pipelines. It is important to always keep in mind your end user and what they’ll need throughout your pipeline construction.
A key decision you’ll need to make is how often you want the data to be updated. If the most up-to-date information is necessary, you’ll need to set up a pipeline equipped for real-time processing. However, if this level of precision is not necessary, you may consider batch processing to save resources. This means the data will go through the pipeline steps in batches, say once a week or daily, instead of continuously.
Another thing to keep in mind while building your pipeline is how you will maintain it going forward. You’ll want to create a way to monitor the pipeline’s functions and be able to detect and correct any unexpected problems.
Typos, incomplete or duplicated entries, and different file types are just a few of the many different challenges your pipeline may be confronted with well after its initial setup. Creating a solid error handling and monitoring system can save you a lot of headaches.
For a more detailed look at designing data pipelines, particularly in a machine learning context, check out DataCamp’s Designing Machine Learning Workflows in Python course.
As with all things in data, it is important to make your pipeline only as complex as is needed. Simpler pipelines are easier and cheaper to maintain, easier to update, and more understandable if you need to pass the pipeline on to another engineer.
At the beginning of the pipeline’s design process, evaluating the project’s requirements, including any future anticipated scaling, is important. Doing so will help you to choose the level of complexity that is warranted.
For example, if you need a temporary pipeline to collect data from three different sensors for a few months, you may consider a simple one-step pipeline using a widely available, free resource, such as Google Drive.
If, however, you have sensitive data or need to do multiple transformations, you may need to create a custom Python or C# code with encryption for the pipeline.
Lastly, you may be setting up a pipeline that’s small for now, but you anticipate large-scale expansion in the next few years. In this case, you’ll likely want to create a pipeline with sufficient infrastructure to handle the expansion.
It can be tempting to design a smaller pipeline initially with plans to create a new pipeline for a larger scale when it becomes necessary. That can work, but be cautious!
Many data engineers are tasked with patching a pipeline that wasn’t designed for the current scale because creating a new one is deemed too expensive or time-consuming.
Although simplicity is key, if you are creating a long-term pipeline, you would be prudent to build it with any anticipated expansion plans in mind.
A few questions you might consider asking at the beginning of a project are:
A common trap that junior engineers fall into is bending to current trends instead of using the best tools for the job.
Such an example is how many companies are trying to shoehorn generative AI into their tech stack without a good use case.
As a data professional, it is important you stay on top of new technologies and trends. However, make sure you choose the tool that is best for your project instead of trying to follow trends that may result in a poor pipeline.
Once you have a plan for your pipeline, it’s important to consider optimization methods. You want to get the data you need, with your preferred resolution and refresh rates, while minimizing the computing resources you need to consume or the time delay for the data moving through the pipeline.
A key component of pipeline optimization is monitoring and logging the flow of data through the pipeline. This will give you insight into where bottlenecks may be slowing the data flow or consuming more computer resources.
Common bottlenecks may include slow data sources, resource constraints, or inefficient data transformations.
Once you have identified bottlenecks, you can consider ways to optimize the performance:
Another consideration for optimization is the refresh rate for the data. If data is being refreshed through your pipeline every minute, but you only need the data to be updated every five minutes, then reducing the number of times it is refreshed unnecessarily can free up processors and reduce energy consumption.
Certain types of data that may flow through your pipelines may have security or privacy concerns. Medical data, for example, is highly regulated by the US government and requires significantly more security measures than data concerning media viewing habits. Other examples of data that require more security are financial data and passwords.
The types of security measures you employ will depend on the security concerns for that type of data. In some cases, anonymization may be sufficient, where personal information is decoupled or deleted from the dataset. This may be used in medical research where personal identifying information is not necessary, but other information in the medical records is.
Other security measures you may need to employ include encryption and controlling access to the data through login authorizations. These methods may be used for financial data or company secrets.
With all sensitive data, it is important that you become familiar with and comply with government regulations, such as GDPR (General Data Protection Regulation) or HIPAA (Health Insurance Portability and Accountability Act).
Depending on your industry and the types of data you handle, you may need to comply with additional regulations, such as CCPA (California Consumer Privacy Act) or FERPA (Family Educational Rights and Privacy Act).
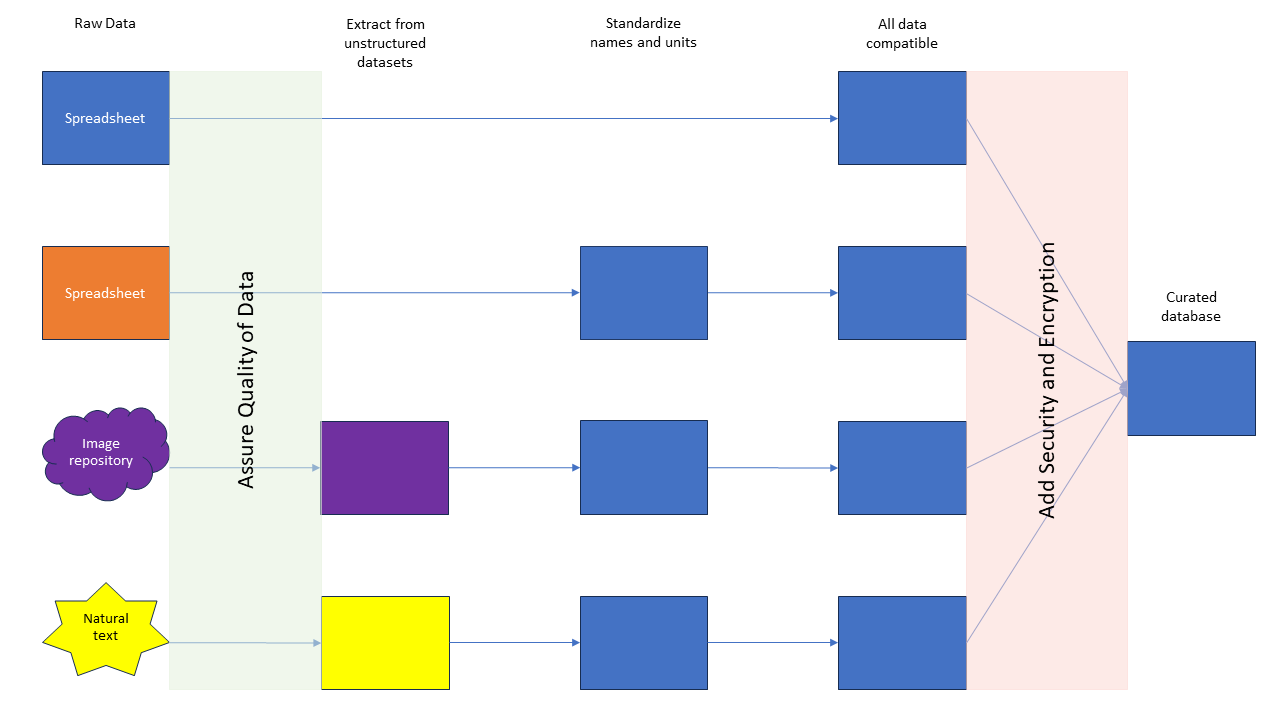
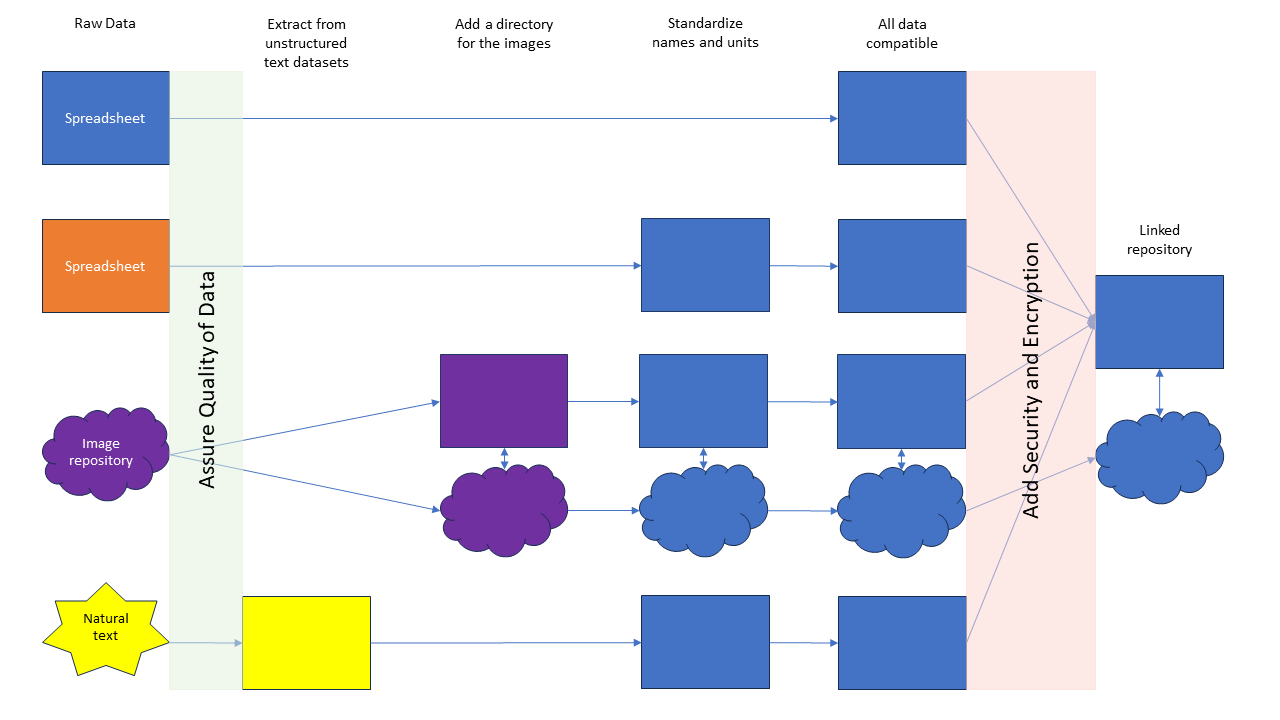
Figure 6: Example of adding quality assurance and security steps into a pipeline.
Data pipelines and the engineers that build them are the unsung heroes of the data world. They allow data to flow seamlessly from place to place, organizing and sorting it. According to Statista, the world generated, consumed, and stored 64.2 zettabytes of data in 2020 alone, and this figure increases every year.
Building and maintaining robust data pipelines is increasingly critical in this data environment. If this tutorial has piqued your interest in data pipelines, check out this introductory course for a more in-depth view. If you are interested in learning how to build data pipelines, check out this Python Data Engineering course to get started. And if you're looking to begin your career and prove your credentials to employers, check out our Data Engineer Certification.
Our certification programs help you stand out and prove your skills are job-ready to potential employers.

Start Learning to Use Data Pipelines Today!
Curso
Curso
blog
Sanjana Putchala
10 min
Tutorial
Jake Roach
Tutorial
Jake Roach
Tutorial
Moez Ali
code-along
Jake Roach
code-along
Mike Metzger



