
Curso
Desarrollo de aplicaciones LLM con LangChain
3 h
46.4K
El modelo o3 es capaz de resolver problemas complejos de varios pasos, combinando entradas visuales y textuales, y utilizando herramientas como Python, la búsqueda o la inspección de imágenes para mejorar sus respuestas.
En este tutorial, explicaré paso a paso cómo utilizar o3 a través de la API, qué diferencia a o3 de los modelos generalistas como GPT-4o, y cómo gestionar eficazmente los costes de razonamiento.
Mantenemos a nuestros lectores al día de lo último en IA enviándoles The Median, nuestro boletín gratuito de los viernes que desglosa las noticias clave de la semana. Suscríbete y mantente alerta en sólo unos minutos a la semana:
El modelo o3 de OpenAI está diseñado para tareas avanzadas y complejas que requieren un razonamiento profundo y autonomía. Es especialmente eficaz para resolver problemas complejos en áreas como el desarrollo de software, las matemáticas, la investigación científica y la interpretación visual de datos.
Las capacidades agénticas del modelo le permiten utilizar de forma autónoma herramientas como la búsqueda en la web, Python y la generación de imágenes, lo que lo hace ideal para tareas que exigen un análisis de varios pasos y una toma de decisiones dinámica.
Deberías plantearte utilizar el modelo o3 a través de la API cuando tus proyectos impliquen tareas de razonamiento complejas y multimodales que se beneficien de su gran autonomía y capacidad analítica avanzada.
Veamos una comparación rápida entre o3, o4-mini y GPT-4o:

Fuente: OpenAI
El precio también es un factor importante a tener en cuenta al utilizar la API:
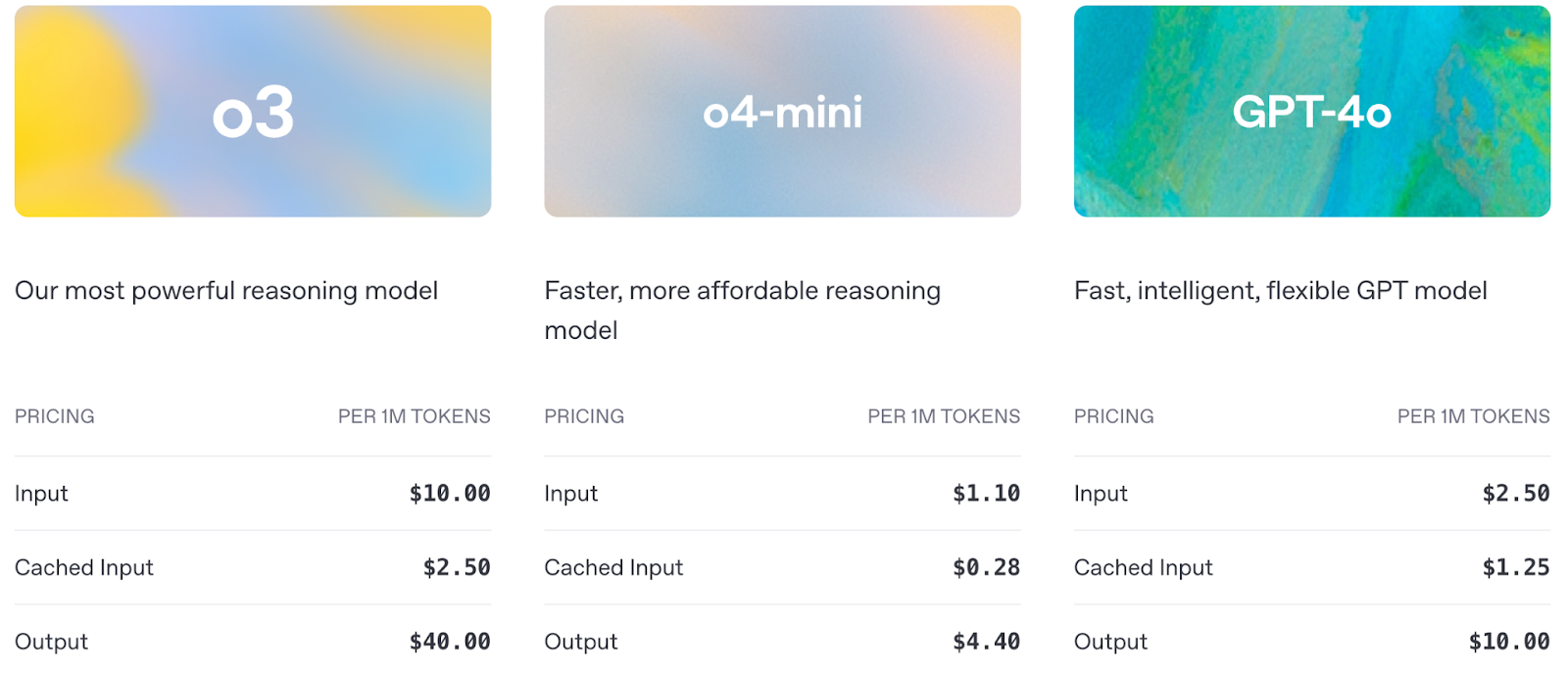
Fuente: OpenAI
Antes de que puedas empezar a utilizar las capacidades de razonamiento avanzado de o3, tienes que configurar el acceso a la API OpenAI. En esta sección, te guiaré:
Para acceder a la API de OpenAI, necesitas una clave de API válida, que puedes obtener en la página página Claves de la API de OpenAIy asegúrate de que la facturación está activada.
Nota: Para utilizar o3, primero debes verificar tu organización OpenAI aquí. La verificación puede tardar hasta 15 minutos en activarse.
openai bibliotecaComenzamos instalando y actualizando la biblioteca openai para acceder al modelo O3 a través de la API. Ejecuta el siguiente comando:
pip install --upgrade openaiUna vez instalado, importamos la clase OpenAI de la biblioteca openai:
from openai import OpenAIPara interactuar con la API de OpenAI, nos autenticamos estableciendo nuestra clave secreta de API, lo que nos permite realizar solicitudes autorizadas a modelos como o3.
client = OpenAI(api_key=YOUR_API_KEY)Ahora que la configuración está completa, hagamos nuestra primera llamada a la API de o3 y veamos cómo gestiona una sencilla tarea de razonamiento en varios pasos a través de la API de respuestas.
Vamos a entender la llamada a la API o3 con un sencillo ejemplo de consulta.
response = client.responses.create(
model="o3",
input=[{"role": "user", "content": "What’s the difference between inductive and deductive reasoning?"}]
)
print(response.output_text)Este ejemplo envía una pregunta en lenguaje natural directamente al modelo o3 sin utilizar ninguna herramienta ni parámetros especiales de razonamiento.
model="o3" indica a la API que utilice el modelo de razonamiento o3.input=[{"role": "user", "content": "..."}] define un único mensaje de usuario pidiendo una explicación conceptual.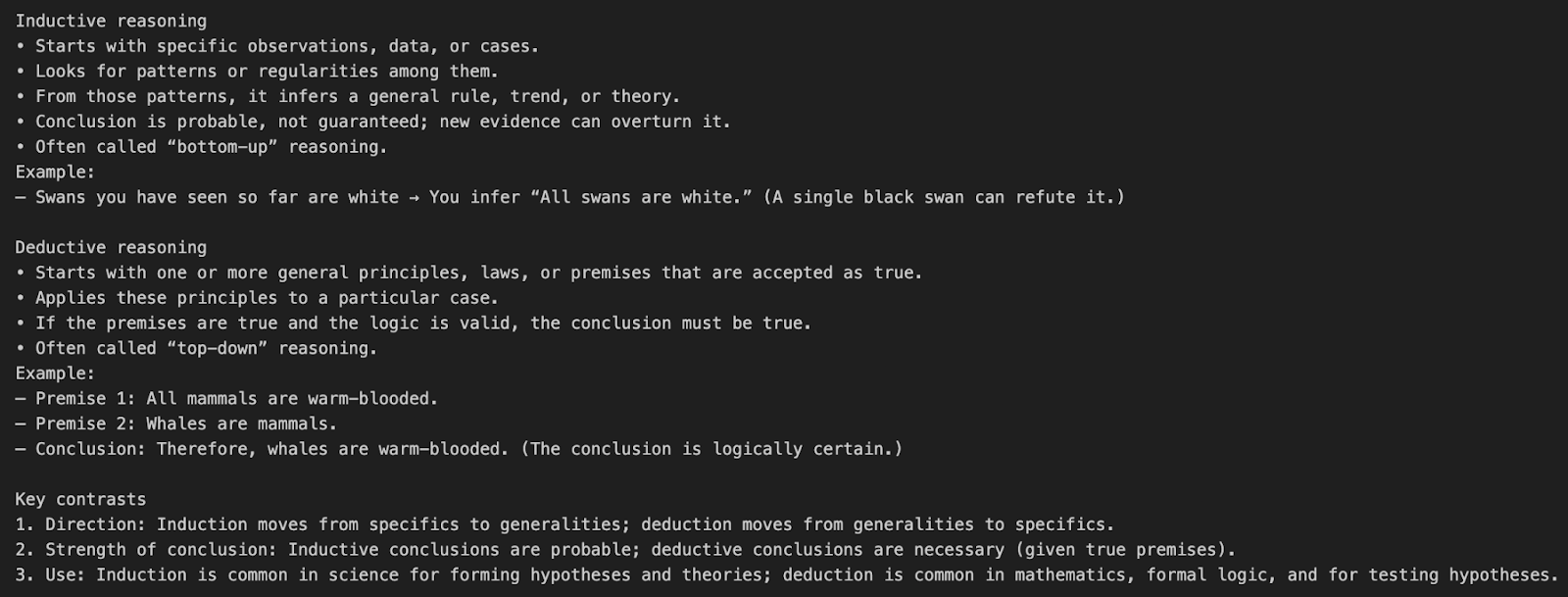
Éstas son las fichas que contarán para nuestro coste final:
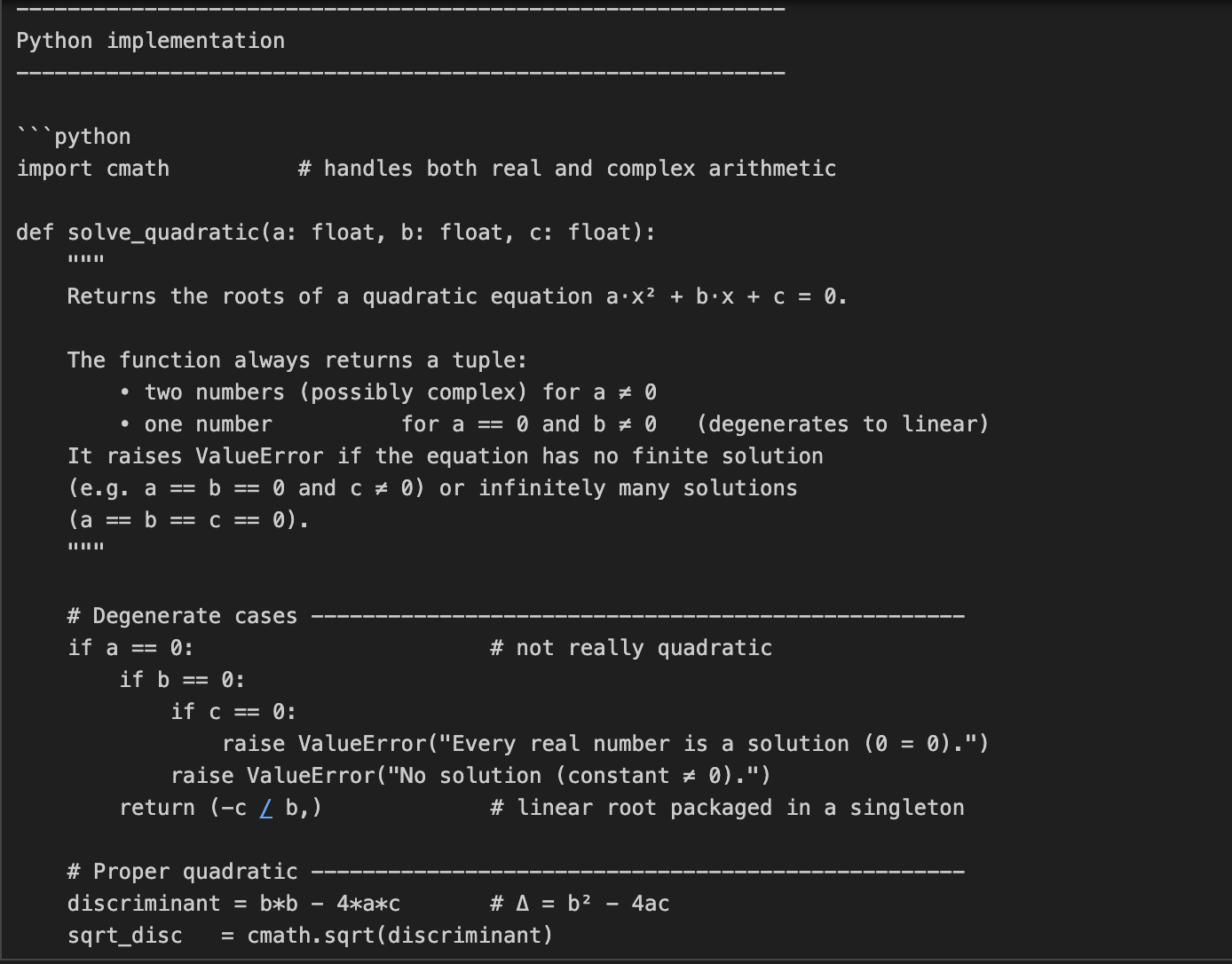
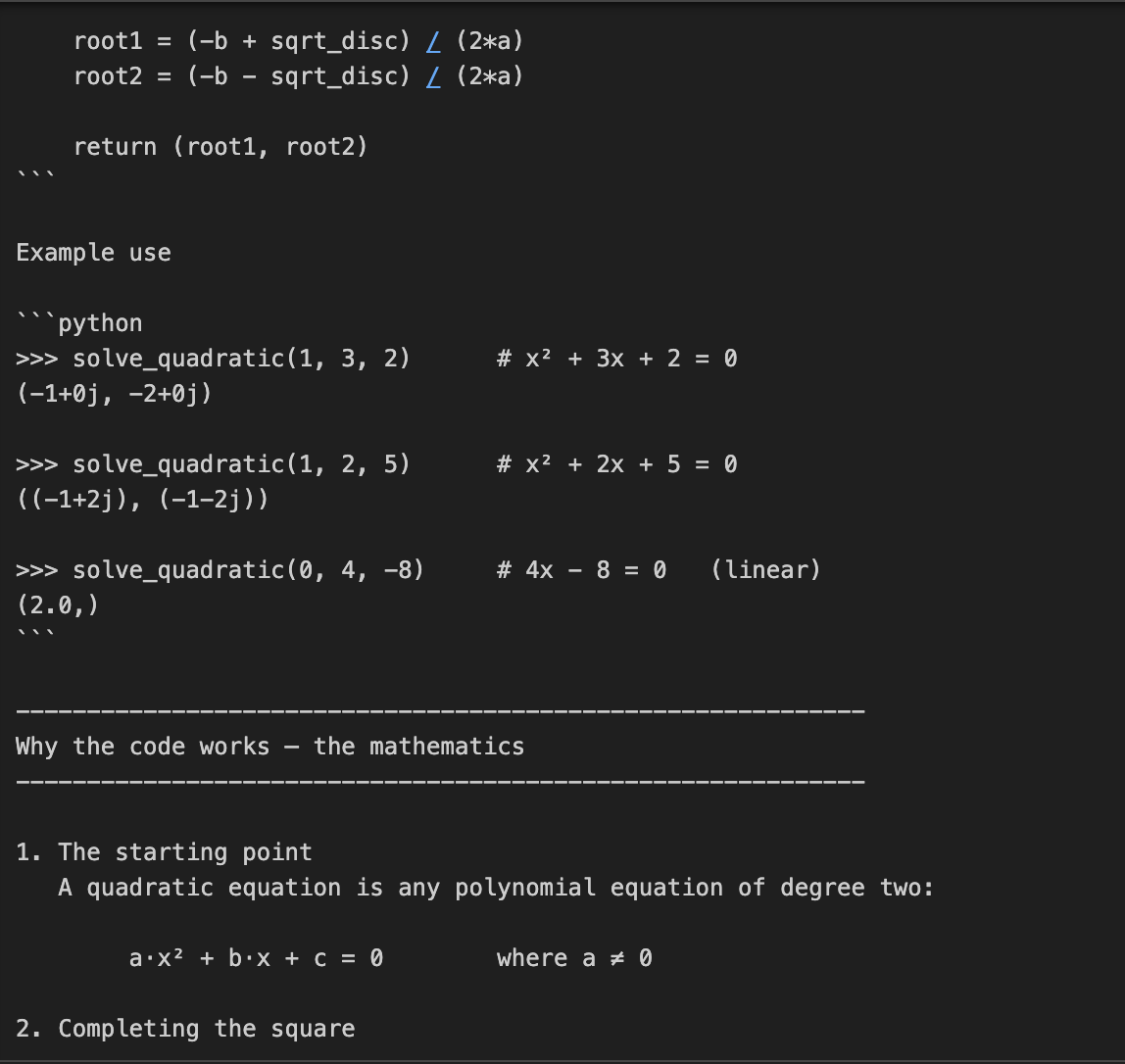
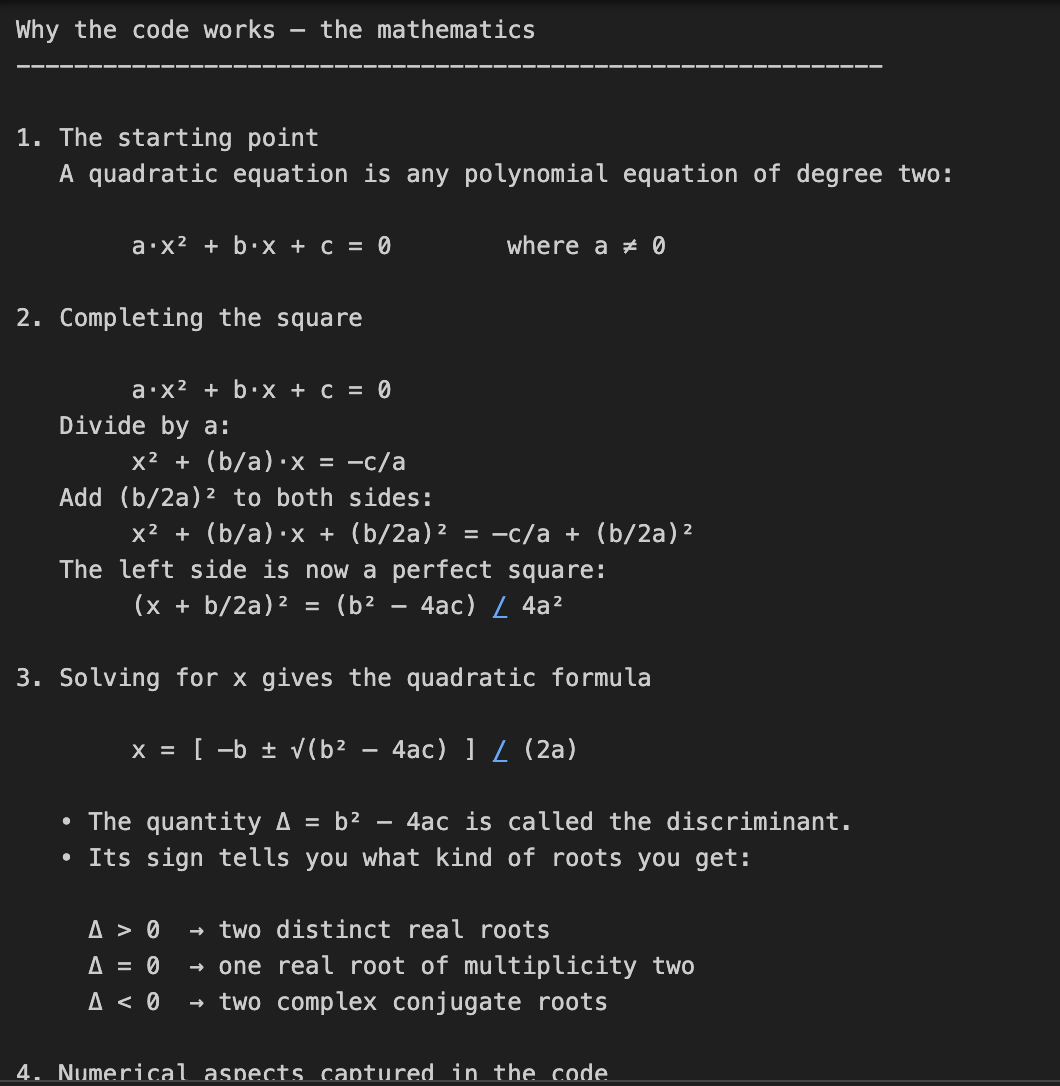
En este ejemplo, pedimos a o3 que codifique y explique las matemáticas que hay detrás de la resolución de ecuaciones cuadráticas. Se trata de una tarea en dos partes, que requiere no sólo la codificación, sino una explicación matemática detallada.
prompt = "Write a Python function that solves quadratic equations and also explain the math behind it."
response = client.responses.create(
model="o3",
reasoning={"effort": "high"},
input=[{"role": "user", "content": prompt}]
)
print(response.output_text)Esta tarea requiere un razonamiento matemático de varios pasos, primero resolviendo una fórmula cuadrática y luego explicando la derivación. El parámetro reasoning={"effort": "high"} obliga a o3 a "pensar más", generando un rastro de razonamiento mayor. Esto la hace perfecta para tareas que requieren profundidad técnica o soluciones en varias fases.
Nota sobre los costes: Un mayor esfuerzo de razonamiento implica más fichas de razonamiento, lo que se traduce en un mayor coste de producción.
En este ejemplo, pasamos una tarea de refactorización de código a O3 junto con un montón de instrucciones.
prompt = """
Instructions:
- Given the React component below, change it so that nonfiction books have red
text.
- Return only the code in your reply
- Do not include any additional formatting, such as markdown code blocks
- For formatting, use four space tabs, and do not allow any lines of code to
exceed 80 columns
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.responses.create(
model="o3",
reasoning={"effort": "medium", "summary": "detailed"},
input=[
{
"role": "user",
"content": prompt,
}
]
)
print(response.output_text)En el código anterior, pasamos a O3 una tarea de edición de código muy estructurada con reglas de formato detalladas.
reasoning={"effort": "medium"} le indica que razone con cuidado pero con eficacia.summary="detailed" solicita un resumen interno completo del proceso de pensamiento del modelo. O3 razonará internamente y, opcionalmente, devolverá una traza resumida si inspeccionas el campo summary más adelante.Consejo: Hay unos cuantos configuraciones de resumen disponibles que puedes utilizar, como "conciso", "detallado" o "automático".

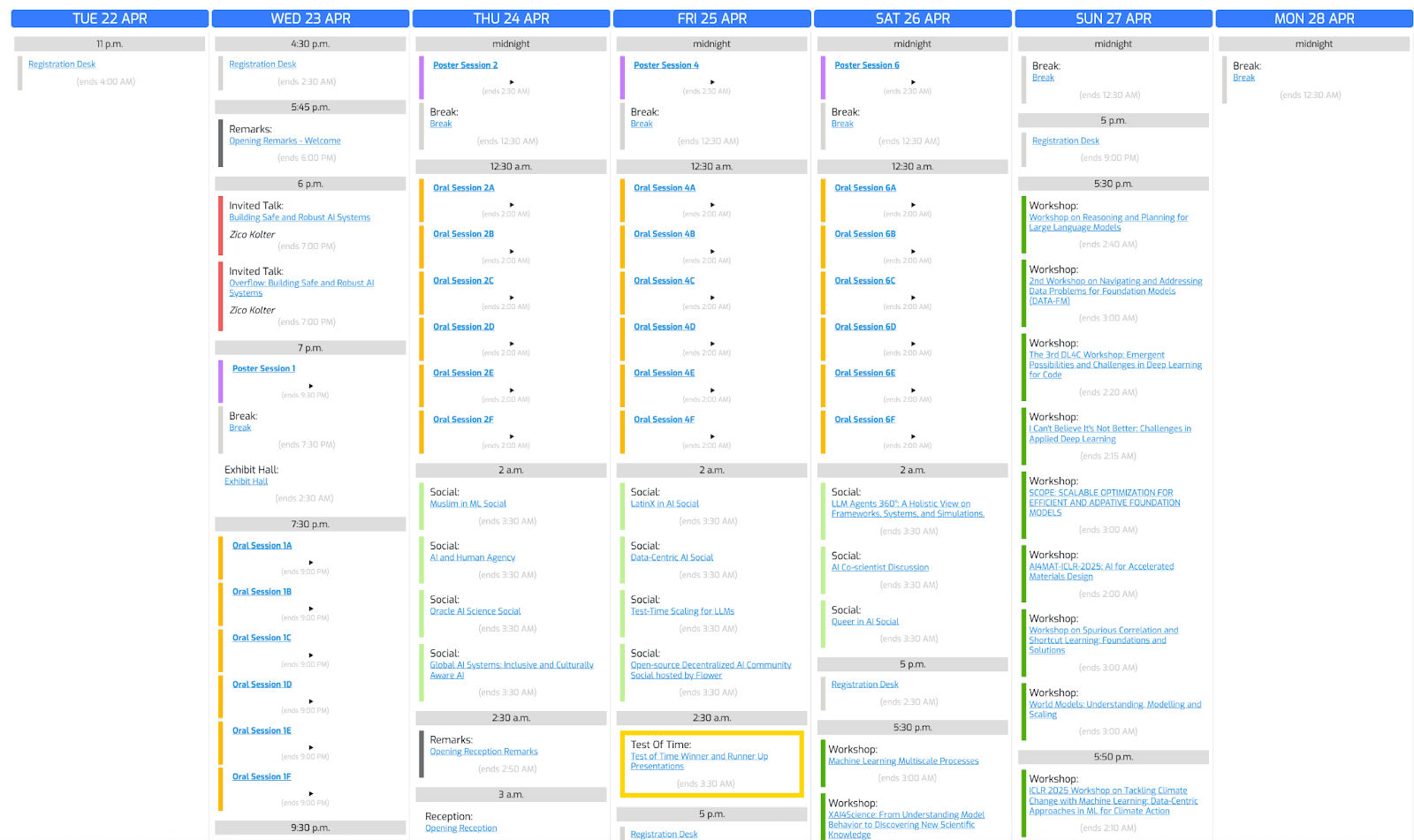
Utilicemos esta foto de la conferencia y pidamos a o3 que cree un programa basado en nuestros intereses.
Empecemos importando las bibliotecas necesarias y escribiendo una función de ayuda:
import base64, mimetypes, pathlib
def to_data_url(path: str) -> str:
mime = mimetypes.guess_type(path)[0] or "application/octet-stream"
data = pathlib.Path(path).read_bytes()
b64 = base64.b64encode(data).decode()
return f"data:{mime};base64,{b64}"La función to_data_url() convierte el archivo de imagen local en una URL de datos codificada en base64, lo cual es necesario porque la API de OpenAI espera entradas de imágenes en formato URL y no como archivos sin procesar.
La función to_data_url hace lo siguiente:
Ahora que hemos codificado nuestra imagen, pasamos tanto el texto como la información de la imagen codificada a O3.
prompt = (
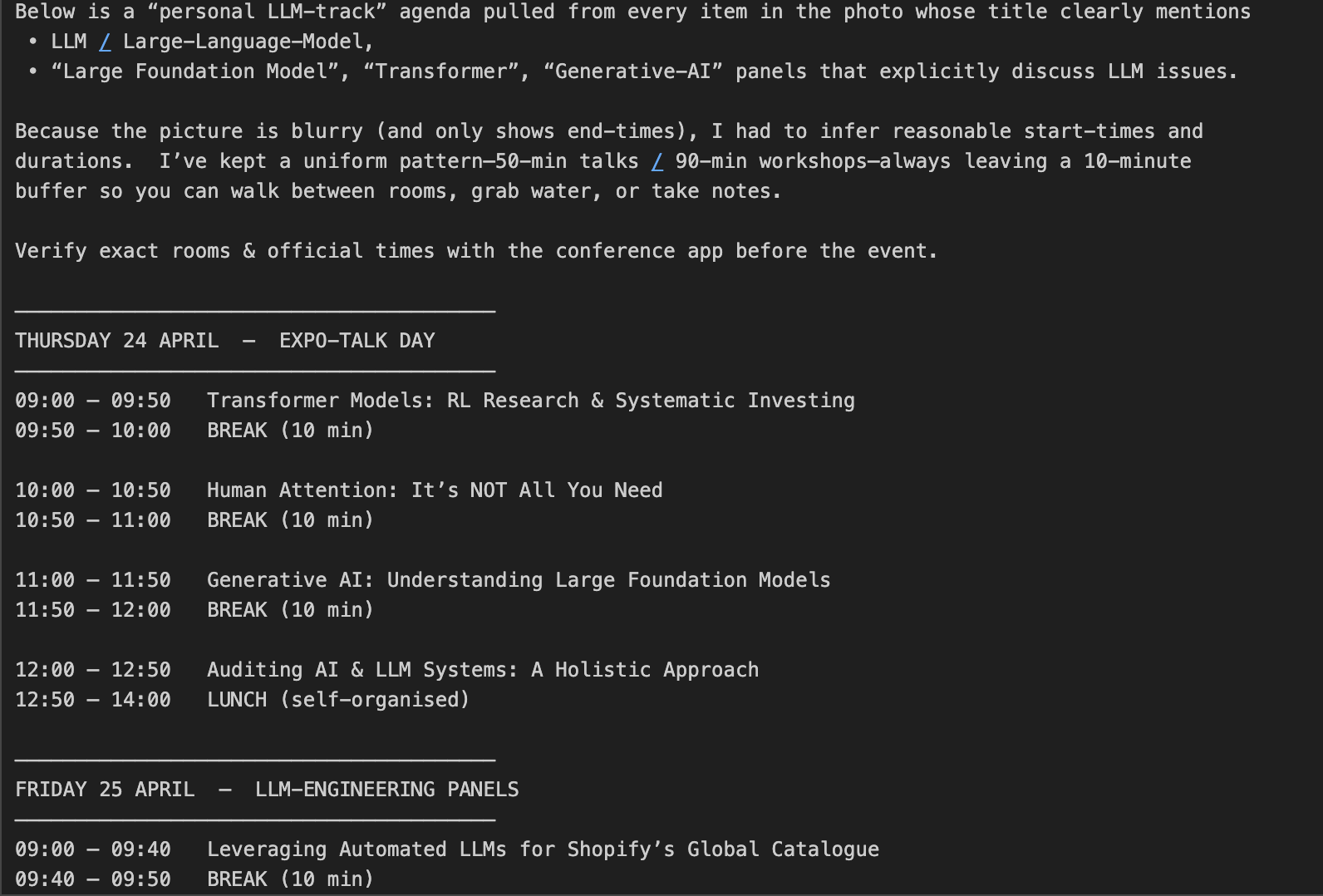
"Create a schedule using this blurry conference photo. "
"Ensure 10-minute gaps between talks and include all talks related to LLMs."
)
image_path = "IMAGE_PATH"
image_url = to_data_url(image_path)
response = client.chat.completions.create(
model="o3",
messages=[
{
"role": "user",
"content": [
{ "type": "text", "text": prompt },
{ "type": "image_url", "image_url": { "url": image_url } }
],
}
],
)
print(response.choices[0].message.content)Así es como funciona:
client.chat.completions.create(), donde el contenido de entrada es una lista que contiene ambas cosas:response.choices[0].message.content, que contiene el programa generado por el modelo tras razonar sobre las instrucciones de texto y los datos visuales.Consideraciones importantes sobre los costes:
max_completion_tokens, que trataremos en la siguiente sección.Veamos el resultado:

O3 utiliza tokens de razonamiento además de los tokens de entrada/salida normales, lo que significa más tokens que los tokens de entrada/salida normales y, por tanto, mayor coste de salida. Siguiendo nuestro ejemplo anterior, vamos a desglosar cómo influyen las fichas de razonamiento en el coste.
print(response.usage)CompletionUsage(completion_tokens=3029,prompt_tokens=1007, total_tokens=4036, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=0, audio_tokens=0, reasoning_tokens=2112, rejected_prediction_tokens=0), prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0))Si quieres controlar los costes, aplica el parámetro max_completion_tokens para limitar el uso total:
limit_token_response = client.chat.completions.create(
model="o3",
messages=[
{
"role": "user",
"content": [
{ "type": "text", "text": prompt },
{ "type": "image_url", "image_url": { "url": image_url } }
],
}
],
max_completion_tokens=3000,
)
print(limit_token_response.usage)CompletionUsage(completion_tokens=2746, prompt_tokens=1007, total_tokens=3753, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=0, audio_tokens=0, reasoning_tokens=2112, rejected_prediction_tokens=0), prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0))Del resultado anterior, podemos ver que establecer un valor max_completion_tokens es fundamental para controlar el comportamiento del modelo. Al limitar el número máximo de tokens generados, evitamos que o3 produzca salidas innecesariamente largas o consuma un número excesivo de tokens de razonamiento, lo que ayuda a optimizar los costes generales de la API. Esto es especialmente importante en tareas complejas en las que, de otro modo, el razonamiento interno podría dominar el uso de fichas sin producir un resultado proporcional visible para el usuario.
Importante: Cuando utilices o3 para tareas visuales complejas, ajusta siempre max_completion_tokens a un valor conservador alto. Si el límite de fichas es demasiado bajo, el modelo puede consumir todas las fichas durante el razonamiento interno y no devolver ninguna salida visible.
El modelo O3 se comporta de forma diferente en comparación con los modelos generalistas como GPT-4o o Claude 3.5 Sonetoporque O3 realiza internamente un razonamiento profundo en cadena. Funciona mejor con indicaciones directas y orientadas a objetivos, es decir, especificar demasiado los pasos puede perjudicar su rendimiento.
Éstas son algunas de las mejores prácticas recomendadas por OpenAI para incitar a o3:
A lo largo de este blog, hemos aprendido a conectarnos al modelo O3 de OpenAI a través de la API, a gestionar los costes de los tokens de razonamiento y a elaborar avisos eficaces utilizando las mejores prácticas. Si tu proyecto exige capacidades de razonamiento avanzadas, como matemáticas de varios pasos, refactorización de código o comprensión visual, O3 es la mejor opción.
Para saber más sobre cómo trabajar con las API, te recomiendo estos blogs:
Aprende IA con estos cursos
Curso
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes
Tutorial
Abid Ali Awan




