
programa
Desarrollo de aplicaciones de IA
21 h
El o4-mini de OpenAI es la última incorporación a la serie o de modelos de IA centrados en el razonamiento. En este tutorial, te explicaré cómo crear unrevisor de trabajos de investigación utilizando la API o4-mini de OpenAI. La herramienta lo hará:
También mejoraremos nuestro asistente de revisión con soporte de herramientas estadísticas, para que el modelo pueda calcular valores p, tamaños del efecto e intervalos de confianza a petición.
Mantenemos a nuestros lectores al día de lo último en IA enviándoles The Median, nuestro boletín gratuito de los viernes que desglosa las noticias clave de la semana. Suscríbete y mantente alerta en sólo unos minutos a la semana:
El o4-mini de OpenAI es un modelo de razonamiento rentable y de alto rendimiento capaz de realizar análisis profundos en tareas como la codificación, las matemáticas y el razonamiento científico. A pesar de ser más pequeño que el o3 alcanza sistemáticamente resultados de vanguardia en pruebas de referencia como AIME 2024/2025 y GPQA.
Gracias a su velocidad y asequibilidad, es ideal para tareas como la revisión de trabajos de investigación, la generación de explicaciones de código o la asistencia en preguntas de matemáticas competitivas. Sus principales puntos fuertes son:
Para saber más, consulta este blog introductorio sobre o4-mini.
Construiremos un revisor de trabajos de investigación basado en Python que puede:
Este proyecto es totalmente local y utiliza la API de OpenAI.
Para utilizar o4-mini, necesitarás una clave API de OpenAI. He aquí cómo:
Ahora, estás listo para autenticarte y empezar a llamar a la API desde Python.
Empecemos instalando algunas dependencias y configurando una variable de entorno variable de entorno para nuestra clave API.
pip install openai PyMuPDF tiktoken numpy
export OPENAI_API_KEY =” YOUR_KEY”Ahora que nuestras dependencias están ordenadas, pasemos a nuestras funciones de ayuda. Estas funciones son invocadas por el LLM mediante llamadas a herramientas cuando es necesario.
Estas importaciones se utilizan para calcular pruebas t, errores estándar e intervalos de confianza.
from scipy.stats import ttest_ind, sem, t
import numpy as npEsta función realiza la prueba t de Welch entre dos grupos de muestras independientes. Prueba la hipótesis de que las medias de los dos grupos son estadísticamente diferentes.
def recalculate_p_value(group1, group2):
t_stat, p_value = ttest_ind(group1, group2, equal_var=False)
return {"p_value": round(p_value, 4)}La función recalculate_p_value() devuelve el valor p, redondeado a cuatro decimales, que indica la probabilidad de que la diferencia observada se haya producido por azar. Esto ayuda al LLM a validar las afirmaciones de significación estadística del trabajo de investigación.
La d de Cohen es una medida estandarizada del tamaño del efecto entre dos grupos. Empieza calculando las medias y las desviaciones típicas de cada grupo. A continuación, utiliza la desviación típica agrupada para normalizar la diferencia entre medias.
def compute_cohens_d(group1, group2):
mean1, mean2 = np.mean(group1), np.mean(group2)
std1, std2 = np.std(group1, ddof=1), np.std(group2, ddof=1)
pooled_std = np.sqrt((std1**2 + std2**2) / 2)
d = (mean1 - mean2) / pooled_std
return {"cohens_d": round(d, 4)}La función devuelve el valor d de Cohen, redondeado a cuatro decimales. Esto ayuda al LLM a comprender la importancia práctica (no sólo estadística) de las diferencias de grupo. Es especialmente valioso cuando el tamaño de la muestra es grande y los valores p por sí solos no son informativos.
Ahora definimos un ayudante para calcular el intervalo de confianza de un único grupo de muestras. Los intervalos de confianza son útiles para comprender la fiabilidad de una media estimada, es decir, cuánta incertidumbre rodea al valor medio.
def compute_confidence_interval(data, confidence=0.95):
data = np.array(data)
n = len(data)
mean = np.mean(data)
margin = sem(data) * t.ppf((1 + confidence) / 2., n-1)
return {
"mean": round(mean, 4),
"confidence_interval": [round(mean - margin, 4), round(mean + margin, 4)],
"confidence": confidence
}Esto es lo que devuelve esta función
mean: El valor medio de los datos de entrada.confidence_interval: Lista que representa los límites inferior y superior en los que probablemente se encuentre la media real, según el nivel de confianza especificado.confidence: El nivel de confianza utilizado para el intervalo.Concluimos las funciones de ayuda con una ayuda sencilla que resume la media, la desviación típica y el tamaño de la muestra.
def describe_group(data):
data = np.array(data)
return {
"mean": round(np.mean(data), 4),
"std_dev": round(np.std(data, ddof=1), 4),
"n": len(data)
}Esto ayuda al LLM a interpretar la distribución de datos subyacente, proporcionando un contexto esencial para evaluar los resultados. Al exponer descriptores estadísticos como la media, la desviación típica y el recuento, nuestras herramientas de ayuda refuerzan la capacidad del modelo para razonar a través de los experimentos y las afirmaciones que se encuentran en los artículos de investigación.
En esta sección, construiremos el revisor de artículos de investigación basado en Python que utiliza la API o4-mini de OpenAI e incluye soporte de herramientas para el análisis estadístico, lo que permite al modelo realizar evaluaciones rigurosas y críticas respaldadas por datos.
Comenzamos nuestro código principal con algunas bibliotecas esenciales para extraer el contenido del PDF, tokenizarlo y hablar con la API de OpenAI.
import os
import fitz
import openai
import json
import tiktoken
from statistics_helper import (
recalculate_p_value,
compute_cohens_d,
compute_confidence_interval,
describe_group
)
openai.api_key = os.getenv("OPENAI_API_KEY")Construyamos ahora la tubería completa paso a paso.
Comenzamos leyendo el texto en bruto del trabajo de investigación. La biblioteca fitz nos permite iterar sobre todas las páginas y concatenar el texto extraído en una sola cadena.
def extract_text_from_pdf(path):
doc = fitz.open(path)
full_text = "\n".join(page.get_text() for page in doc)
return full_textEsto sienta las bases. Ahora vamos a tokenizar y trocear el texto en bruto antes de enviarlo al modelo.
Nota: He generado un trabajo de investigación falso para fines de demostración que contiene intencionadamente fallos de lógica y diseño experimental.
Los LLM tienen límites de contexto, así que dividimos los documentos largos en trozos manejables. Utilizamos Tiktoken para tokenizar el texto según el esquema de codificación del modelo.
def chunk_text(text, max_tokens=12000, model="o4-mini"):
encoding = tiktoken.get_encoding("cl100k_base")
tokens = encoding.encode(text)
chunks = []
for i in range(0, len(tokens), max_tokens):
chunk = tokens[i:i + max_tokens]
chunk_text = encoding.decode(chunk)
chunks.append(chunk_text)
return chunksFunciona así:
tiktoken para tokenizar el texto completo del documento utilizando cl100k_base tokenizer, que es compatible con los modelos modernos de OpenAI como GPT-4, GPT-4o y o4-mini.max_tokens. Esto garantiza que cada trozo se mantenga dentro del tamaño máximo de entrada permitido por el modelo, lo que es esencial para evitar errores de desbordamiento de tokens durante la inferencia.encoding.decode(). Esto preserva la redacción y el formato naturales para que el modelo reciba un contexto coherente durante el procesamiento.Este paso de fragmentación es esencial para evitar errores de corte durante la inferencia y garantiza que no se omita ningún texto importante por desbordamiento.
Antes de que el modelo pueda invocar funciones externas, tenemos que definir una correspondencia entre los nombres de las funciones (vistos por el modelo) y las funciones reales de Python que se ejecutarán. Este mapeo actúa como puente entre las llamadas a herramientas del modelo y nuestra base de código local.
tool_function_map = {
"recalculate_p_value": recalculate_p_value,
"compute_cohens_d": compute_cohens_d,
"compute_confidence_interval": compute_confidence_interval,
"describe_group": describe_group,
}Cada clave de este diccionario corresponde a un nombre de función al que el modelo podría hacer referencia durante su invocación a la herramienta, y cada valor es la función Python real importada del módulo statistics_helper.
Para mejorar el razonamiento del modelo, registramos herramientas que el LLM puede llamar mediante llamada a funciones. Estas herramientas manejan análisis estadísticos como el recálculo del valor p, los intervalos de confianza y los tamaños del efecto.
tools = [
{
"type": "function",
"name": "recalculate_p_value",
"description": "Calculate p-value between two sample groups",
"parameters": {
"type": "object",
"properties": {
"group1": {"type": "array", "items": {"type": "number"}},
"group2": {"type": "array", "items": {"type": "number"}}
},
"required": ["group1", "group2"]
}
},
{
"type": "function",
"name": "compute_cohens_d",
"description": "Compute effect size (Cohen's d) between two groups",
"parameters": {
"type": "object",
"properties": {
"group1": {"type": "array", "items": {"type": "number"}},
"group2": {"type": "array", "items": {"type": "number"}}
},
"required": ["group1", "group2"]
}
},
{
"type": "function",
"name": "compute_confidence_interval",
"description": "Compute confidence interval for a sample group",
"parameters": {
"type": "object",
"properties": {
"data": {"type": "array", "items": {"type": "number"}},
"confidence": {"type": "number", "default": 0.95}
},
"required": ["data"]
}
},
{
"type": "function",
"name": "describe_group",
"description": "Summarize sample mean, std deviation, and count",
"parameters": {
"type": "object",
"properties": {
"data": {"type": "array", "items": {"type": "number"}}
},
"required": ["data"]
}
}
]La definición de herramienta anterior permite al LLM comprender:
description)name)El LLM decide inteligentemente cuándo invocar una herramienta, como recalcular un valor p, basándose en el contexto de la revisión. Cuando encuentra una afirmación estadística o un resultado cuestionable, puede llamar a la función de ayuda adecuada, recibir el resultado y continuar su razonamiento utilizando ese resultado. Esto permite un análisis más riguroso y fundamentado, en el que el modelo no sólo critica, sino que también verifica los datos subyacentes.
Ahora definimos la lógica central que envía cada trozo de texto al modelo o4-mini. Si llama a una herramienta, gestionamos la llamada a la función y continuamos la conversación.
def review_text_chunk(chunk):
try:
response = client.responses.create(
model="o4-mini",
reasoning={"effort": "high"},
input=[
{
"role": "system",
"content": (
"You are an expert AI research reviewer. Read the given chunk of a research paper and highlight weak arguments."
"unsupported claims, or flawed methodology. You can request tools to: Recalculate p-values, Compute confidence intervals, "
"Estimate effect size (Cohen's d), Describe sample statistics. Be rigorous and explain your reasoning. "
"Conclude with suggestions and a verdict."
)
},
{
"role": "user",
"content": chunk
}
],
tools = tools,
)
# Check for tool calls
for item in response.output:
if getattr(item, "type", None) == "function_call":
fn_call = getattr(item, "function_call", {})
fn_name = getattr(fn_call, "name", "")
args = getattr(fn_call, "arguments", {})
if fn_name in tool_function_map:
tool_result = tool_function_map[fn_name](**args)
# Send back tool result as continuation input
tool_response = client.responses.create(
model="o4-mini",
reasoning={"effort": "high"},
input=[
*response.output,
{
"role": "tool",
"name": fn_name,
"content": str(tool_result)
}
],
max_output_tokens=3000
)
if hasattr(tool_response, "output_text") and tool_response.output_text:
return tool_response.output_text.strip()
# If no tool was called, return original response
if hasattr(response, "output_text") and response.output_text:
return response.output_text.strip()
if response.status == "incomplete":
reason = getattr(response.incomplete_details, "reason", "unknown")
return f" Incomplete response: {reason}"
return " No valid output returned by the model."
except Exception as e:
return f" Error during chunk review: {e}"La función review_text_chunk se encarga de enviar cada trozo del trabajo de investigación al LLM, junto con un aviso del sistema y un registro de herramientas. Así es como funciona paso a paso:
client.responses.create(), que utiliza el Responses API para razonar. En esta convocatoria:
"o4-mini", y la banderareasoning={"effort": "high"} se establece en alto, lo que fomenta el razonamiento interno detallado de varios pasos. Este ajuste indica al modelo con qué profundidad debe "pensar" antes de generar una respuesta final. Ajusta el número de fichas de razonamiento interno que el modelo puede utilizar.tool_choice="auto" explícitamente, ya que la API Respuestas decide el uso de la herramienta automáticamente.responses.create, añadiendo el resultado de la herramienta como un mensaje de función "herramienta". Esto simula una continuación del proceso de razonamiento.Este mecanismo de razonamiento y verificación en varios pasos es lo que confiere al modelo una capacidad de revisión rigurosa. Imita la forma en que un revisor humano podría detectar un problema, realizar un cálculo rápido y ajustar su opinión en consecuencia.
Una vez colocados todos los componentes, utilizamos esta función para procesar un PDF entero. Lo une todo.
def review_full_pdf(pdf_path):
raw_text = extract_text_from_pdf(pdf_path)
chunks = chunk_text(raw_text)
print(f"\n Extracted {len(chunks)} chunks from PDF\n")
all_reviews = []
for idx, chunk in enumerate(chunks):
print(f"\n Reviewing Chunk {idx + 1}/{len(chunks)}...")
review = review_text_chunk(chunk)
all_reviews.append(f"### Chunk {idx + 1} Review\n{review}")
full_review = "\n\n".join(all_reviews)
return full_reviewEsta función actúa como envoltorio para revisar un trabajo de investigación completo:
Ahora definimos el punto de entrada del script. Esto permite ejecutar el programa directamente desde el terminal con una ruta de archivo PDF como entrada.
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Review an academic paper PDF for weak arguments.")
parser.add_argument("pdf_path", type=str, help="Path to the research paper PDF")
args = parser.parse_args()
review_output = review_full_pdf(args.pdf_path)
print("\n Final Aggregated Review:\n")
print(review_output)
with open("paper_review_output.md", "w") as f:
f.write(review_output)
print("\n Review saved to paper_review_output.md")Este bloque hace lo siguiente
argparse para aceptar la ruta a un PDF como argumento de la línea de comandos.review_full_pdf() para generar la revisión completa.paper_review_output.md) para su uso o integración en el futuro.Para ejecutar este código, escribe el siguiente comando en el terminal:
python pdf_reviewer_assistant.py Fake_paper.pdf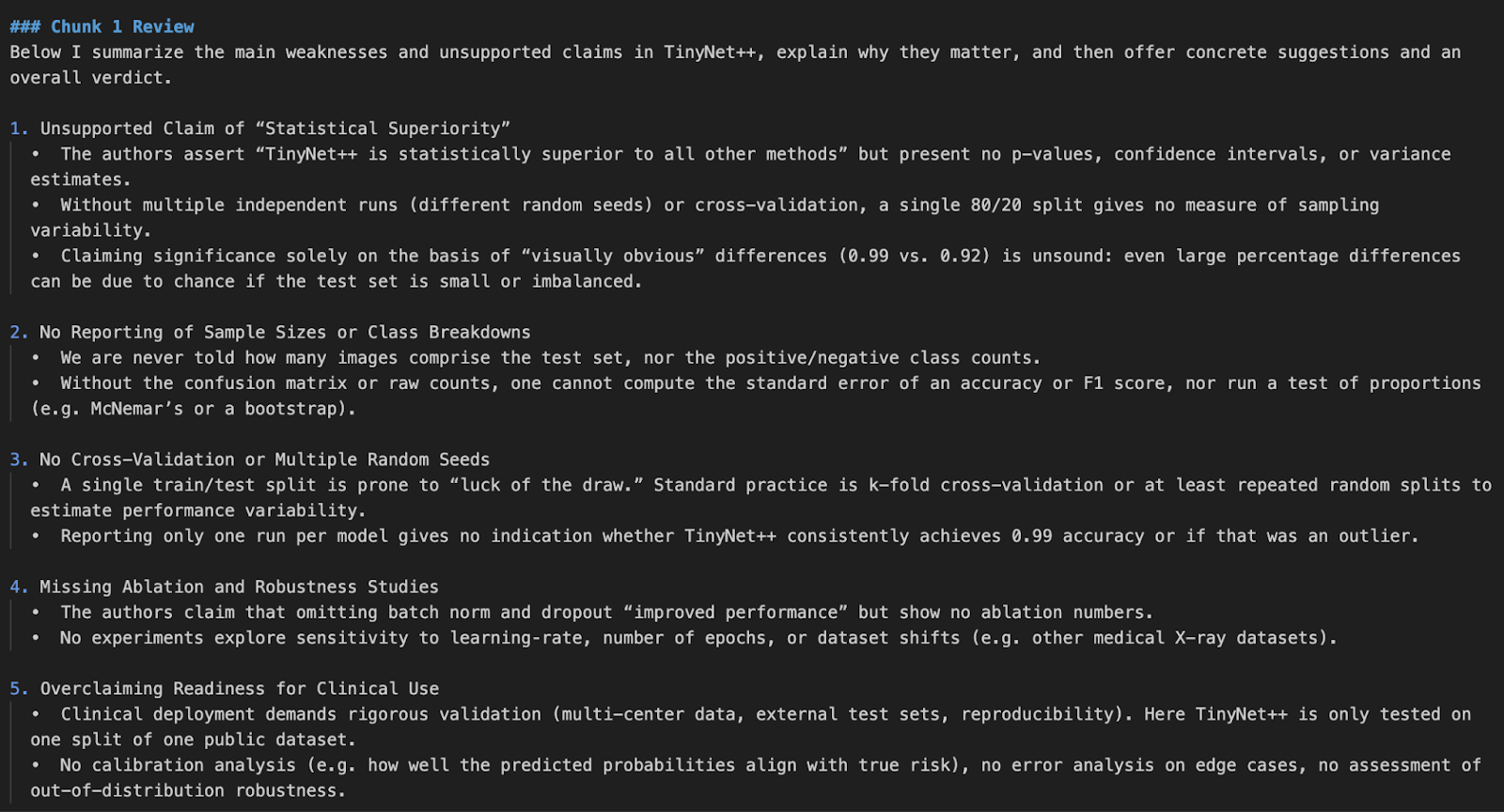
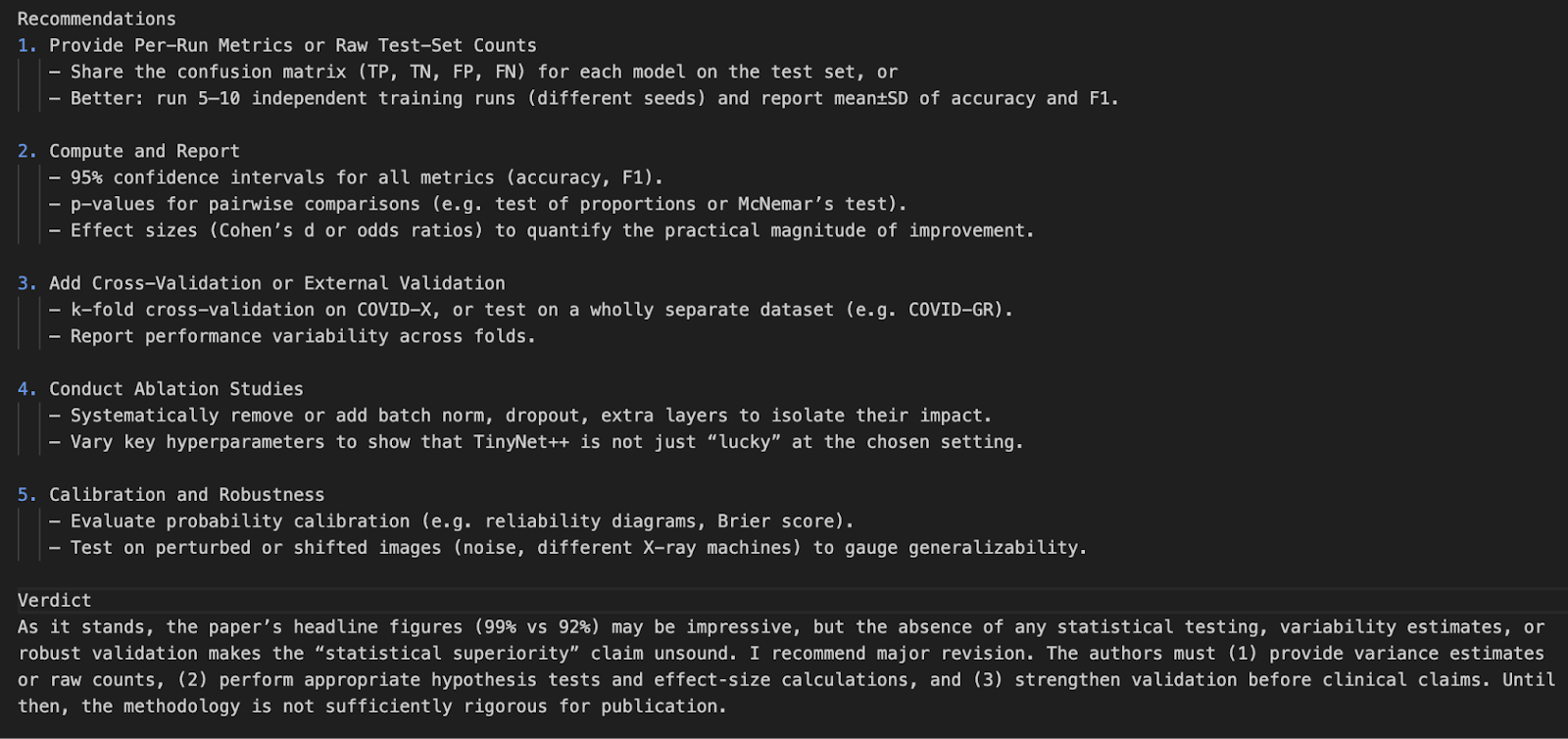
En este proyecto, creamos un revisor de artículos de investigación utilizando la API del modelo o4-mini de OpenAI. Mejoramos la capacidad del modelo integrando herramientas estadísticas en tiempo real, que le permiten volver a analizar los valores p, los intervalos de confianza y los tamaños del efecto.
Esta demostración prepara el terreno para futuras integraciones con interfaces de usuario de PDF, comprobadores de citas o incluso herramientas multimodales de ayuda a la investigación.
Para saber más sobre los últimos lanzamientos de OpenAI, consulta estos blogs:
Aprende IA con estos cursos
programa
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes
Tutorial
Arunn Thevapalan
Tutorial
Zoumana Keita




