
Cours
Développement d'applications LLM avec LangChain
3 h
46.2K
Le modèle o3 est capable de résoudre des problèmes complexes à plusieurs étapes, de mélanger des entrées visuelles et textuelles, et d'utiliser des outils comme Python, la recherche ou l'inspection d'images pour améliorer ses réponses.
Dans ce tutoriel, j'expliquerai étape par étape comment utiliser o3 via l'API, ce qui différencie o3 des modèles généralistes comme GPT-4o, et comment gérer efficacement les coûts de raisonnement.
Nous tenons nos lecteurs informés des dernières nouveautés en matière d'IA en leur envoyant The Median, notre lettre d'information gratuite du vendredi qui analyse les principaux sujets de la semaine. Abonnez-vous et restez à la pointe de la technologie en quelques minutes par semaine :
Le modèle o3 d'OpenAI est conçu pour des tâches avancées et complexes nécessitant un raisonnement approfondi et de l'autonomie. Elle est particulièrement efficace pour la résolution de problèmes complexes dans des domaines tels que le développement de logiciels, les mathématiques, la recherche scientifique et l'interprétation de données visuelles.
Les capacités agentiques du modèle lui permettent d'utiliser de manière autonome des outils tels que la recherche sur le web, Python et la génération d'images, ce qui le rend idéal pour les tâches qui exigent une analyse en plusieurs étapes et une prise de décision dynamique.
Vous devriez envisager d'utiliser le modèle o3 via l'API lorsque vos projets impliquent des tâches de raisonnement complexes et multimodales qui bénéficient de sa grande autonomie et de ses compétences analytiques avancées.
Voyons une comparaison rapide entre o3, o4-mini et GPT-4o :

Source : OpenAI
La tarification est également un facteur important à prendre en compte lors de l'utilisation de l'API :
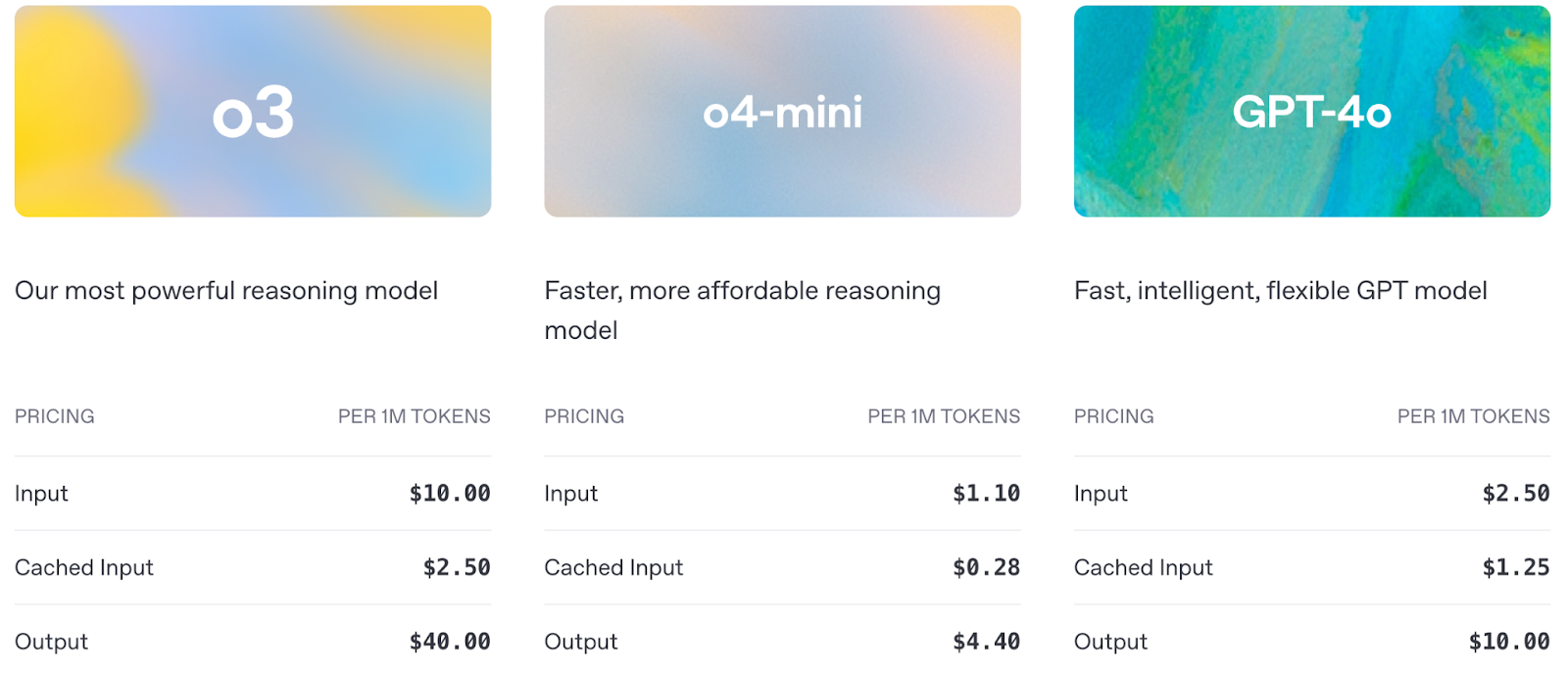
Source : OpenAI
Avant de commencer à utiliser les capacités de raisonnement avancées d'o3, vous devez configurer l'accès à l'API OpenAI. Dans cette section, je vous guiderai :
Pour accéder à l'API OpenAI, vous avez besoin d'une clé API valide, que vous pouvez obtenir à partir de la page page Clés API OpenAIet assurez-vous que votre facturation est activée.
Note: Pour utiliser o3, vous devez d'abord vérifier votre organisation OpenAI ici. L'activation de la vérification peut prendre jusqu'à 15 minutes.
openai bibliothèqueNous commençons par installer et mettre à jour la bibliothèque openai pour accéder au modèle O3 via l'API. Exécutez la commande suivante :
pip install --upgrade openaiUne fois installée, nous importons la classe OpenAI de la bibliothèque openai :
from openai import OpenAIPour interagir avec l'API d'OpenAI, nous nous authentifions en définissant notre clé d'API secrète, ce qui nous permet de faire des demandes autorisées à des modèles comme o3.
client = OpenAI(api_key=YOUR_API_KEY)Maintenant que la configuration est terminée, effectuons notre premier appel API à o3 et voyons comment il gère une simple tâche de raisonnement en plusieurs étapes via l'API Responses.
Comprenons l'appel à l'API o3 à l'aide d'un simple exemple d'invite.
response = client.responses.create(
model="o3",
input=[{"role": "user", "content": "What’s the difference between inductive and deductive reasoning?"}]
)
print(response.output_text)Cet exemple envoie une question en langage naturel directement au modèle o3 sans utiliser d'outils ou de paramètres de raisonnement particuliers.
model="o3" indique à l'API d'utiliser le modèle de raisonnement o3.input=[{"role": "user", "content": "..."}] définit un message d'utilisateur unique demandant une explication conceptuelle.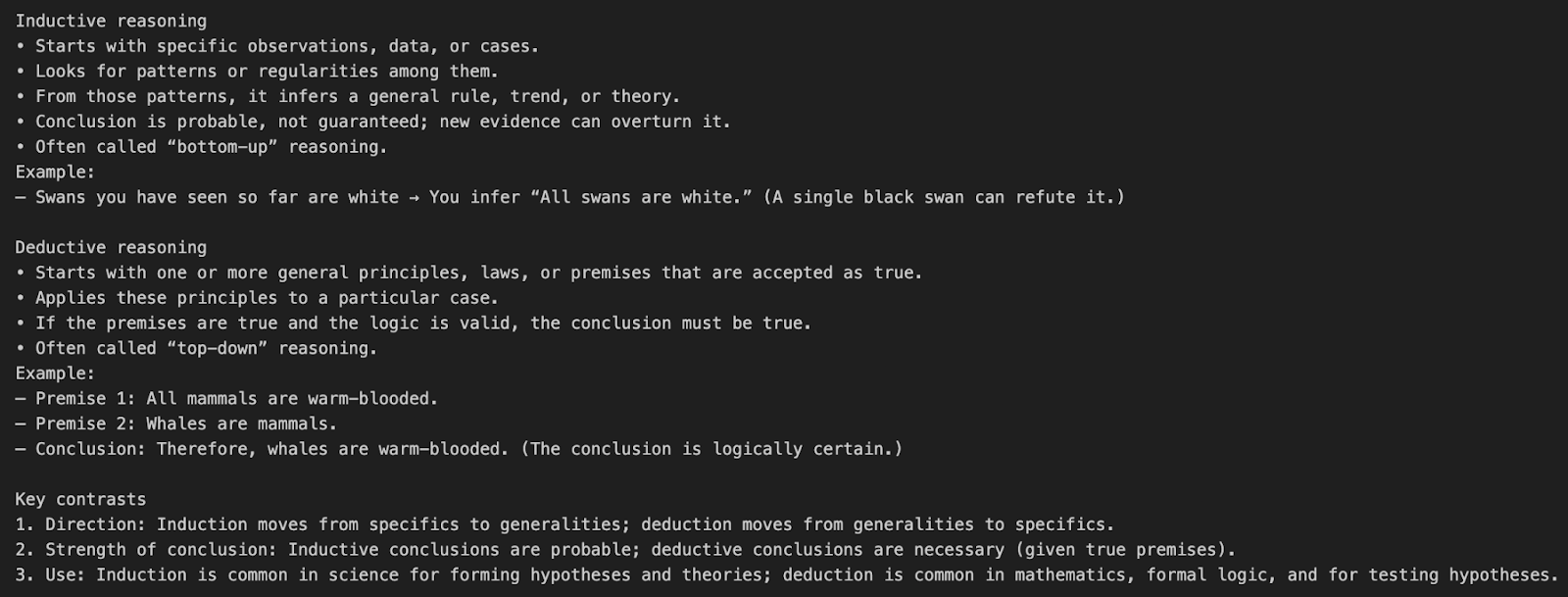
Ce sont les jetons qui seront pris en compte dans le calcul du coût final :
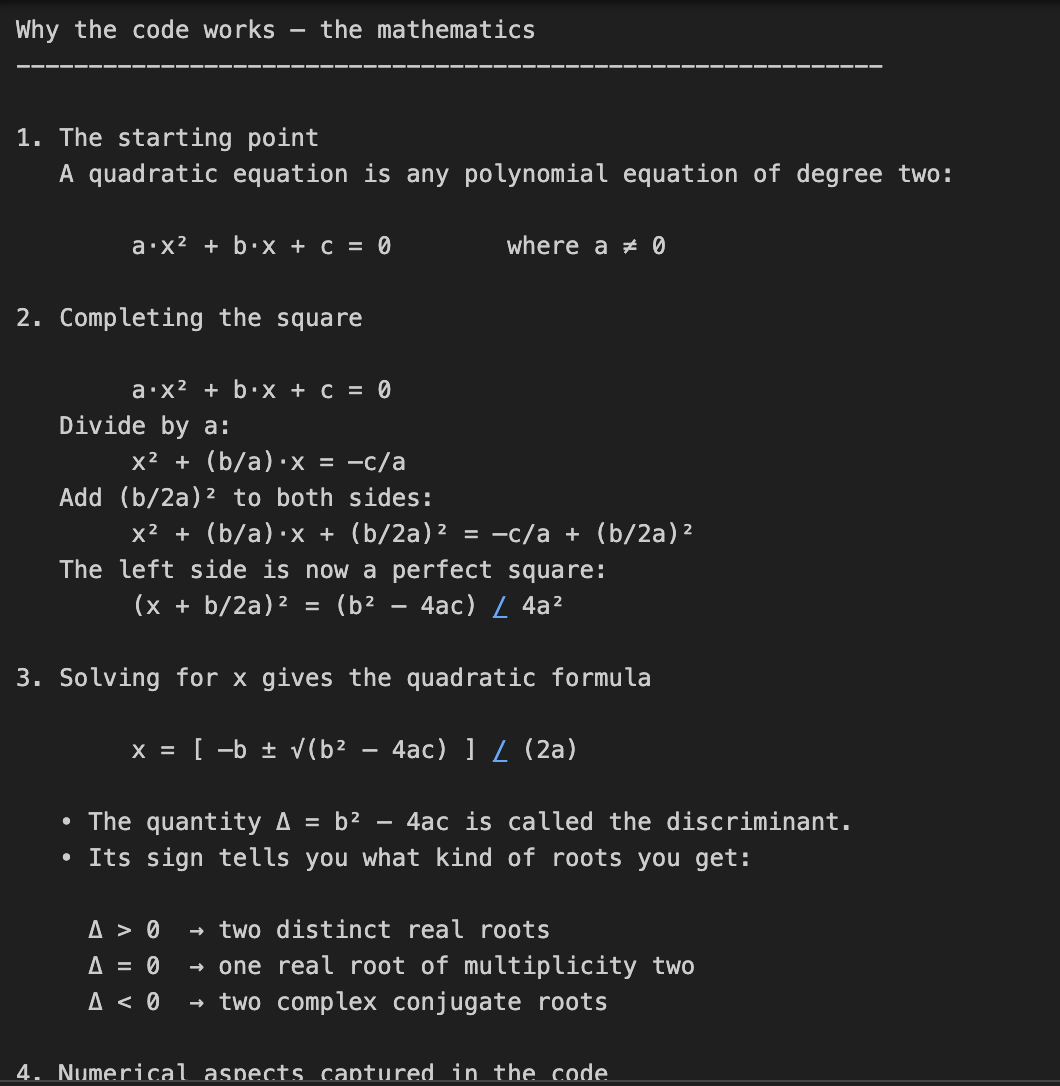
Dans cet exemple, nous demandons à o3 de coder et d'expliquer les mathématiques qui sous-tendent la résolution des équations quadratiques. Il s'agit d'une tâche en deux parties, qui nécessite non seulement un codage, mais aussi une explication mathématique détaillée.
prompt = "Write a Python function that solves quadratic equations and also explain the math behind it."
response = client.responses.create(
model="o3",
reasoning={"effort": "high"},
input=[{"role": "user", "content": prompt}]
)
print(response.output_text)Cette tâche nécessite un raisonnement mathématique en plusieurs étapes, d'abord la résolution d'une formule quadratique, puis l'explication de la dérivation. Le paramètre reasoning={"effort": "high"} oblige o3 à "réfléchir davantage", ce qui génère une trace de raisonnement plus importante. Il est donc parfait pour les tâches nécessitant une profondeur technique ou des solutions en plusieurs étapes.
Note sur les coûts : Un effort de raisonnement plus important signifie plus de jetons de raisonnement, ce qui se traduit par un coût de production plus élevé.
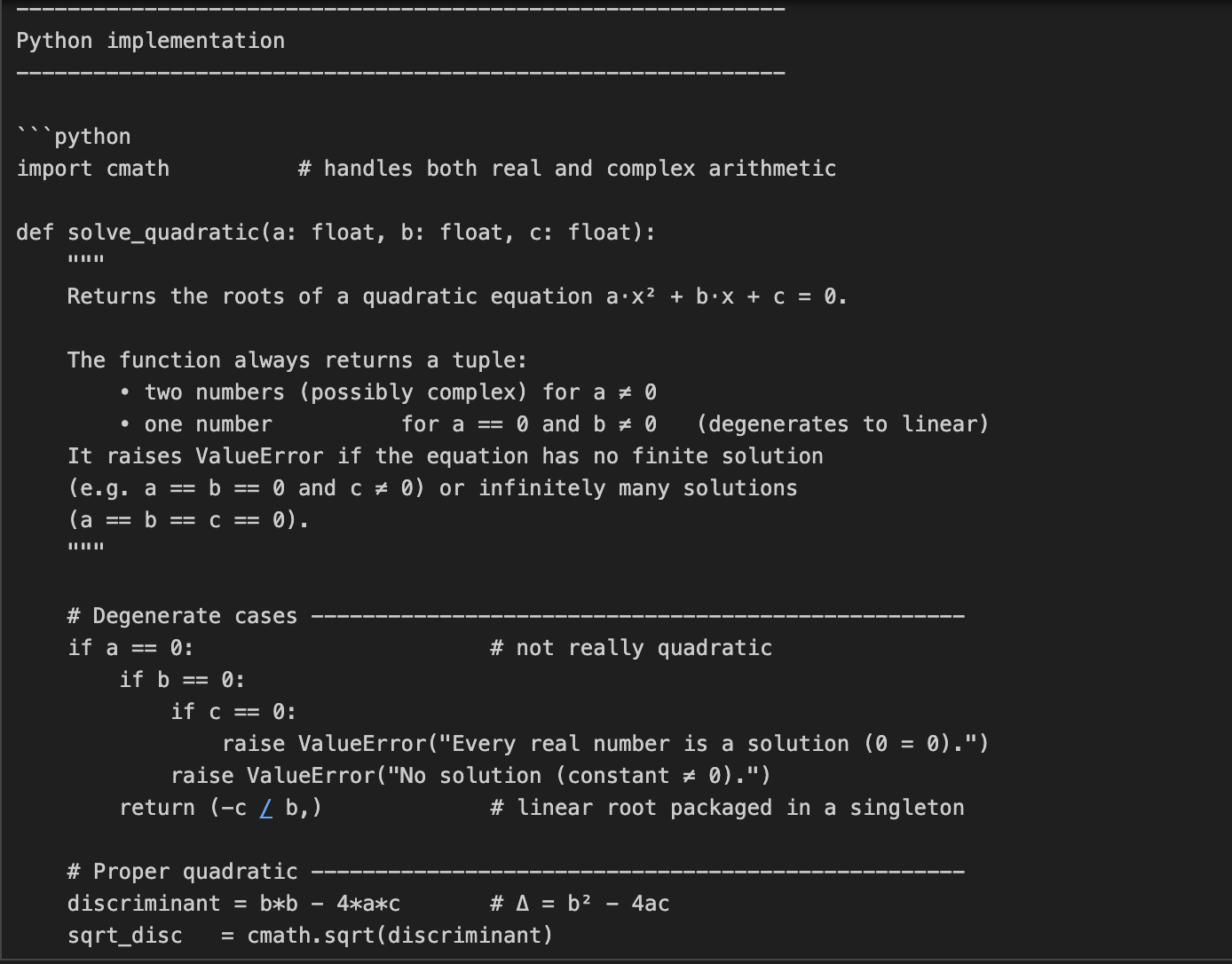
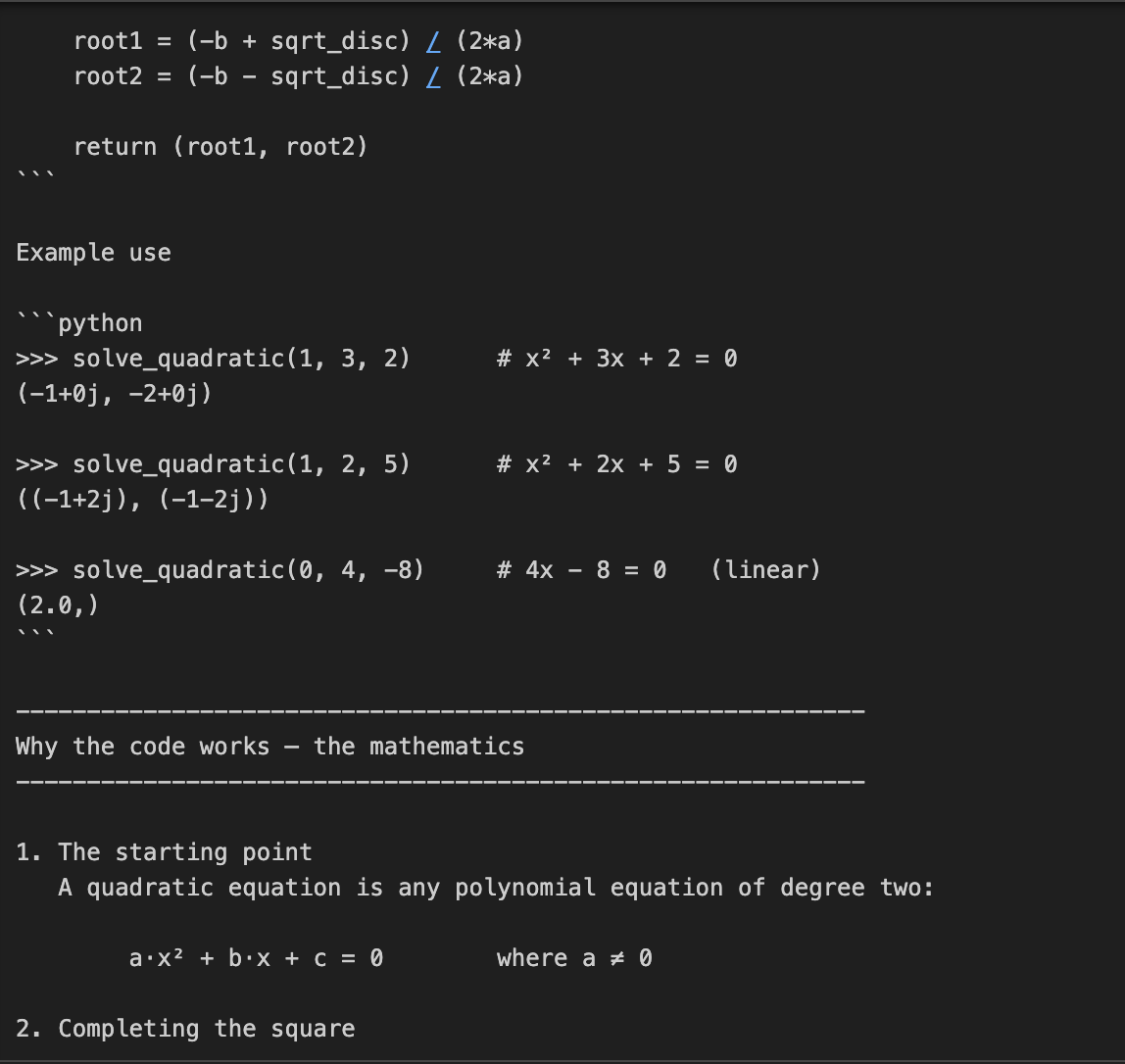
Dans cet exemple, nous transmettons à O3 une tâche de refonte de code accompagnée d'un ensemble d'instructions.
prompt = """
Instructions:
- Given the React component below, change it so that nonfiction books have red
text.
- Return only the code in your reply
- Do not include any additional formatting, such as markdown code blocks
- For formatting, use four space tabs, and do not allow any lines of code to
exceed 80 columns
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.responses.create(
model="o3",
reasoning={"effort": "medium", "summary": "detailed"},
input=[
{
"role": "user",
"content": prompt,
}
]
)
print(response.output_text)Dans le code ci-dessus, nous transmettons à O3 une tâche d'édition de code très structurée avec des règles de formatage détaillées.
reasoning={"effort": "medium"} lui demande de raisonner prudemment mais efficacement.summary="detailed" demande un résumé interne complet du processus de réflexion du modèle. O3 raisonne en interne et renvoie éventuellement une trace résumée si vous inspectez le champ summary ultérieurement.Conseil : Vous pouvez utiliser quelques paramètres de résumé tels que "concis", "détaillé" ou "automatique". Vous pouvez utiliser quelques paramètres de résumé disponibles, tels que "concis", "détaillé" ou "automatique".

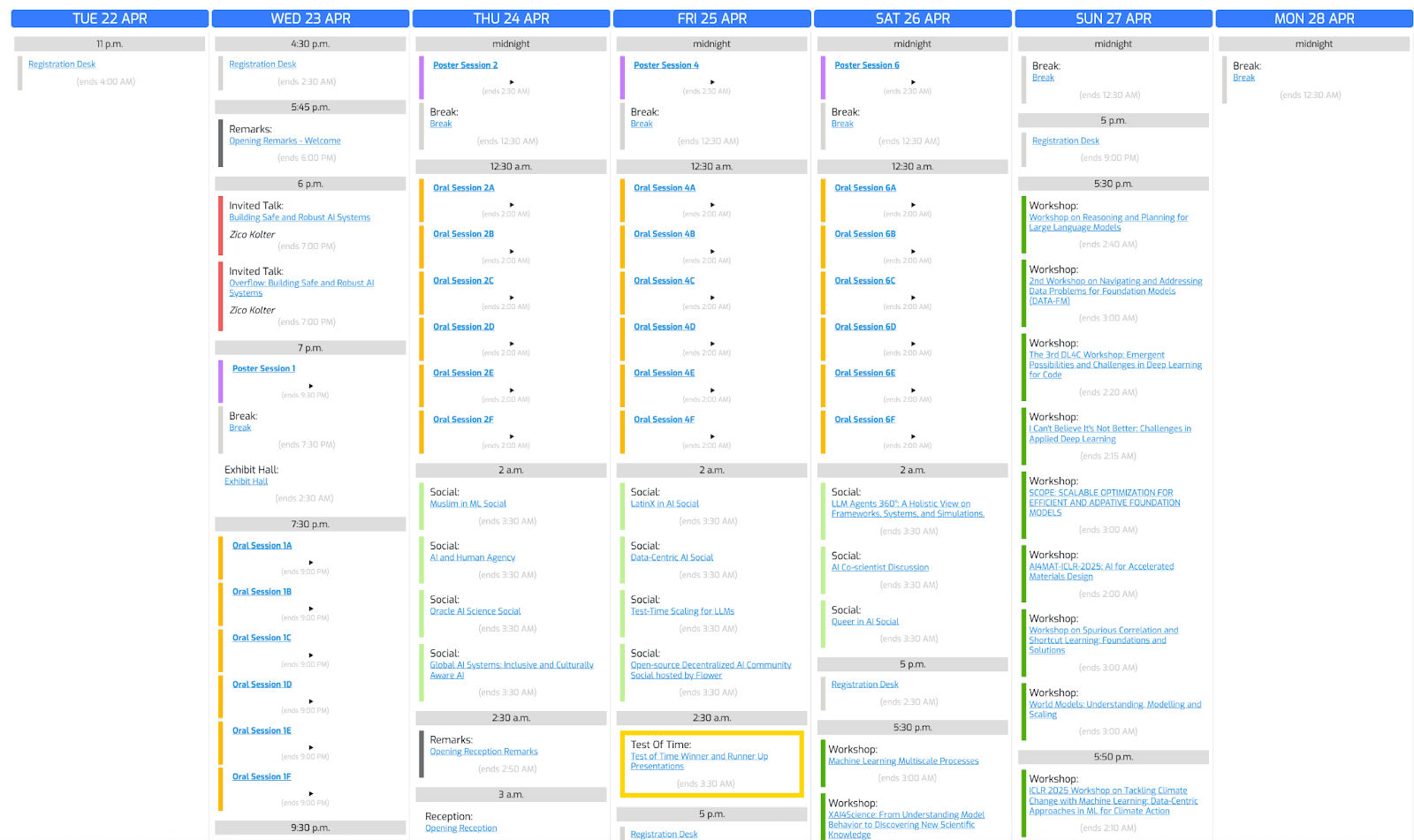
Utilisons cette photo de conférence et demandons à o3 de créer un horaire basé sur nos intérêts.
Commençons par importer les bibliothèques nécessaires et par écrire une fonction d'aide :
import base64, mimetypes, pathlib
def to_data_url(path: str) -> str:
mime = mimetypes.guess_type(path)[0] or "application/octet-stream"
data = pathlib.Path(path).read_bytes()
b64 = base64.b64encode(data).decode()
return f"data:{mime};base64,{b64}"La fonction to_data_url() convertit le fichier image local en une URL de données encodée en base64, ce qui est nécessaire car l'API d'OpenAI attend des entrées d'images au format URL plutôt que sous forme de fichiers bruts.
La fonction to_data_url permet d'effectuer les opérations suivantes :
Maintenant que nous avons encodé notre image, nous transmettons le texte et les informations de l'image encodée à O3.
prompt = (
"Create a schedule using this blurry conference photo. "
"Ensure 10-minute gaps between talks and include all talks related to LLMs."
)
image_path = "IMAGE_PATH"
image_url = to_data_url(image_path)
response = client.chat.completions.create(
model="o3",
messages=[
{
"role": "user",
"content": [
{ "type": "text", "text": prompt },
{ "type": "image_url", "image_url": { "url": image_url } }
],
}
],
)
print(response.choices[0].message.content)Voici comment cela fonctionne :
client.chat.completions.create(), où le contenu d'entrée est une liste contenant les deux :response.choices[0].message.content, qui contient le programme généré par le modèle après avoir raisonné sur les instructions textuelles et les données visuelles.Des considérations importantes en matière de coûts :
max_completion_tokens, que nous aborderons dans la section suivante.Voyons le résultat :

O3 utilise des jetons de raisonnement en plus des jetons d'entrée/sortie normaux, ce qui signifie plus de jetons que les jetons d'entrée/sortie normaux et donc un coût de sortie plus élevé. Dans le prolongement de notre exemple précédent, examinons l'impact des jetons de raisonnement sur les coûts.
print(response.usage)CompletionUsage(completion_tokens=3029,prompt_tokens=1007, total_tokens=4036, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=0, audio_tokens=0, reasoning_tokens=2112, rejected_prediction_tokens=0), prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0))Si vous souhaitez contrôler les coûts, appliquez le paramètre max_completion_tokens pour plafonner l'utilisation totale :
limit_token_response = client.chat.completions.create(
model="o3",
messages=[
{
"role": "user",
"content": [
{ "type": "text", "text": prompt },
{ "type": "image_url", "image_url": { "url": image_url } }
],
}
],
max_completion_tokens=3000,
)
print(limit_token_response.usage)CompletionUsage(completion_tokens=2746, prompt_tokens=1007, total_tokens=3753, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=0, audio_tokens=0, reasoning_tokens=2112, rejected_prediction_tokens=0), prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0))Le résultat ci-dessus montre que la définition d'une valeur max_completion_tokens est essentielle pour contrôler le comportement du modèle. En plafonnant le nombre maximal de jetons générés, nous empêchons o3 de produire des résultats inutilement longs ou de consommer des jetons de raisonnement excessifs, ce qui permet d'optimiser les coûts globaux de l'API. Ceci est particulièrement important dans les tâches complexes où le raisonnement interne pourrait autrement dominer l'utilisation des jetons sans produire de résultats proportionnels visibles par l'utilisateur.
Important : Lorsque vous utilisez o3 pour des tâches visuelles complexes, réglez toujours max_completion_tokens à un niveau prudent. Si la limite de jetons est trop basse, le modèle peut consommer tous les jetons pendant le raisonnement interne et ne renvoyer aucun résultat visible.
Le modèle O3 se comporte différemment des modèles généralistes tels que GPT-4o ou Claude 3.5 Sonnetparce que le modèle O3 s'engage dans un raisonnement interne en chaîne de pensée. Il fonctionne mieux avec des invites simples et orientées vers un objectif, c'est-à-dire qu'une spécification excessive des étapes peut nuire à ses performances.
Voici quelques bonnes pratiques recommandées par l'OpenAI pour l'invite o3 :
Tout au long de ce blog, nous avons appris à nous connecter au modèle O3 d'OpenAI via l'API, à gérer les coûts des jetons de raisonnement et à créer des invites efficaces en utilisant les meilleures pratiques. Si votre projet nécessite des capacités de raisonnement avancées, telles que les mathématiques à plusieurs étapes, le remaniement de code ou la compréhension visuelle, O3 est le meilleur choix.
Pour en savoir plus sur l'utilisation des API, je vous recommande ces blogs :
Apprenez l'IA avec ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min