
Curso
Desenvolvimento de aplicativos de LLM com LangChain
3 h
46.2K
O modelo o3 da OpenAI da OpenAI é capaz de resolver problemas complexos de várias etapas, combinando entradas visuais e textuais e usando ferramentas como Python, pesquisa ou inspeção de imagens para aprimorar suas respostas.
Neste tutorial, explicarei passo a passo como usar o o3 por meio da API, o que torna o o3 diferente dos modelos generalistas, como o GPT-4o, e como gerenciar os custos de raciocínio de forma eficaz.
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que detalha as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
O modelo o3 da OpenAI foi projetado para tarefas avançadas e complexas que exigem raciocínio profundo e autonomia. É particularmente eficaz para a solução de problemas complexos em áreas como desenvolvimento de software, matemática, pesquisa científica e interpretação de dados visuais.
Os recursos agênticos do modelo permitem que ele utilize de forma autônoma ferramentas como pesquisa na Web, Python e geração de imagens, tornando-o ideal para tarefas que exigem análise em várias etapas e tomada de decisões dinâmicas.
Você deve considerar o uso do modelo o3 via API quando seus projetos envolverem tarefas de raciocínio complexas e multimodais que se beneficiem de sua alta autonomia e habilidades analíticas avançadas.
Vamos fazer uma rápida comparação entre o o3, o4-mini e o GPT-4o:

Fonte: OpenAI
O preço também é um fator importante a ser considerado ao usar a API:
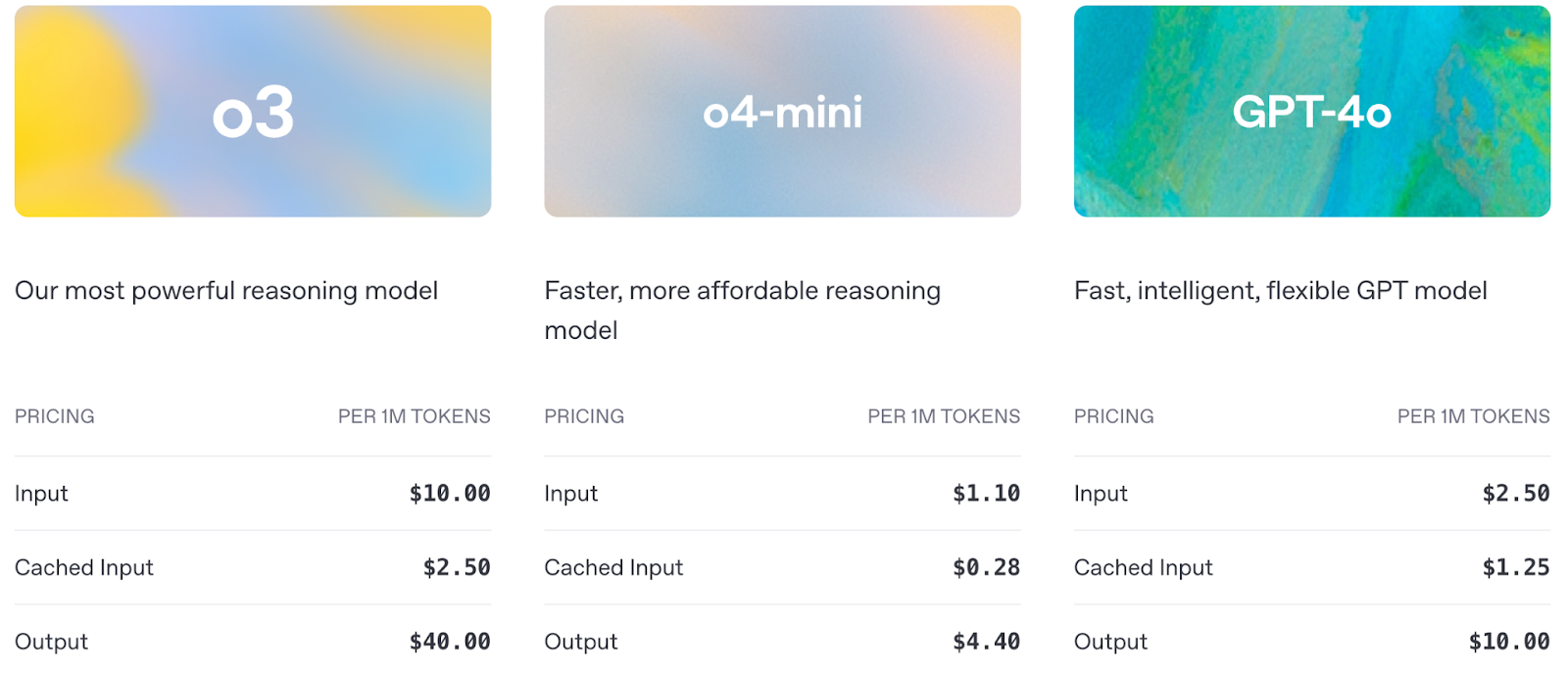
Fonte: OpenAI
Antes de começar a usar os recursos de raciocínio avançado do o3, você precisa configurar o acesso à API do OpenAI. Nesta seção, mostrarei a você o que fazer:
Para acessar a API da OpenAI, você precisa de uma chave de API válida, que pode ser obtida na página Chaves de API da OpenAIe verifique se o faturamento está ativado.
Observação: Para usar o o3, você deve primeiro verificar sua organização OpenAI aqui. A verificação pode levar até 15 minutos para ser ativada.
openai bibliotecaComeçamos instalando e atualizando a biblioteca openai para acessar o modelo O3 via API. Execute o seguinte comando:
pip install --upgrade openaiDepois de instalada, importamos a classe OpenAI da biblioteca openai:
from openai import OpenAIPara interagir com a API da OpenAI, nós nos autenticamos definindo nossa chave secreta de API, o que nos permite fazer solicitações autorizadas a modelos como o o3.
client = OpenAI(api_key=YOUR_API_KEY)Agora que a configuração está concluída, vamos fazer nossa primeira chamada de API para o o3 e ver como ele lida com uma tarefa simples de raciocínio em várias etapas por meio da API de respostas.
Vamos entender a chamada da API o3 com um exemplo simples de prompt.
response = client.responses.create(
model="o3",
input=[{"role": "user", "content": "What’s the difference between inductive and deductive reasoning?"}]
)
print(response.output_text)Esse exemplo envia uma pergunta em linguagem natural diretamente para o modelo o3 sem usar nenhuma ferramenta ou parâmetro de raciocínio especial.
model="o3" diz à API para usar o modelo de raciocínio o3.input=[{"role": "user", "content": "..."}] define uma única mensagem de usuário solicitando uma explicação conceitual.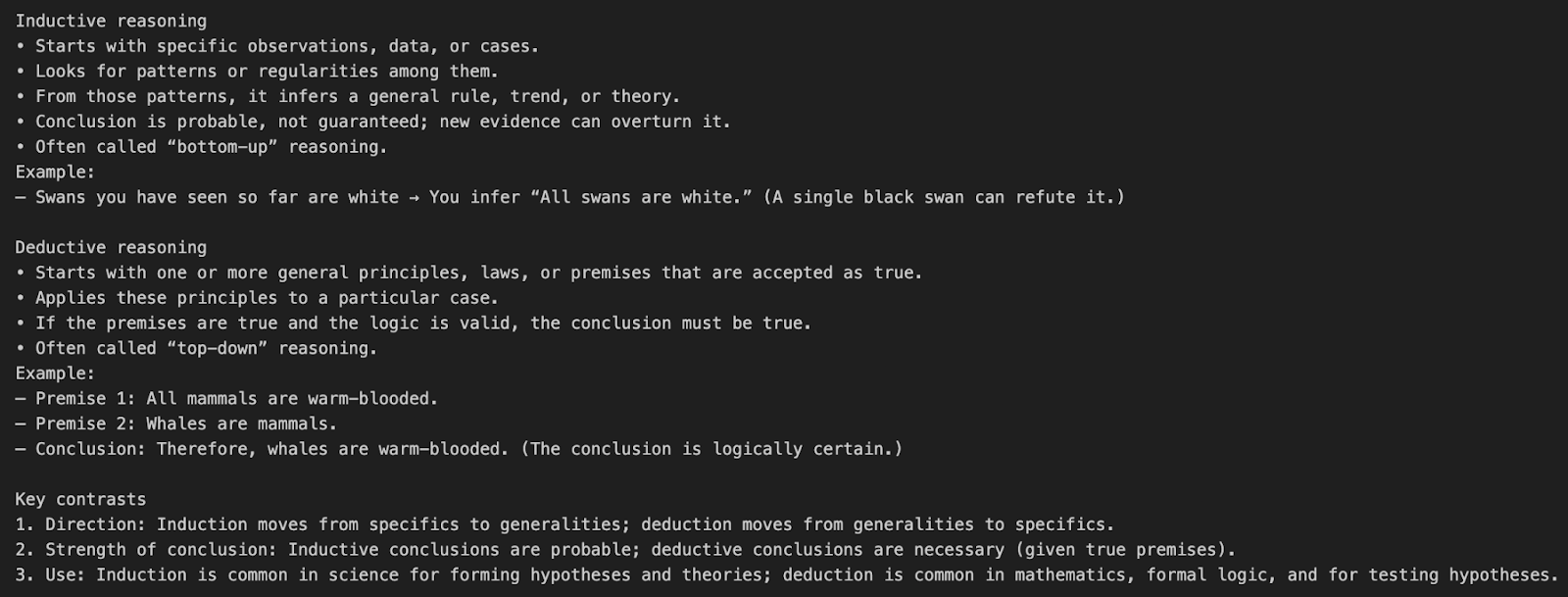
Esses são os tokens que contarão para o nosso custo final:
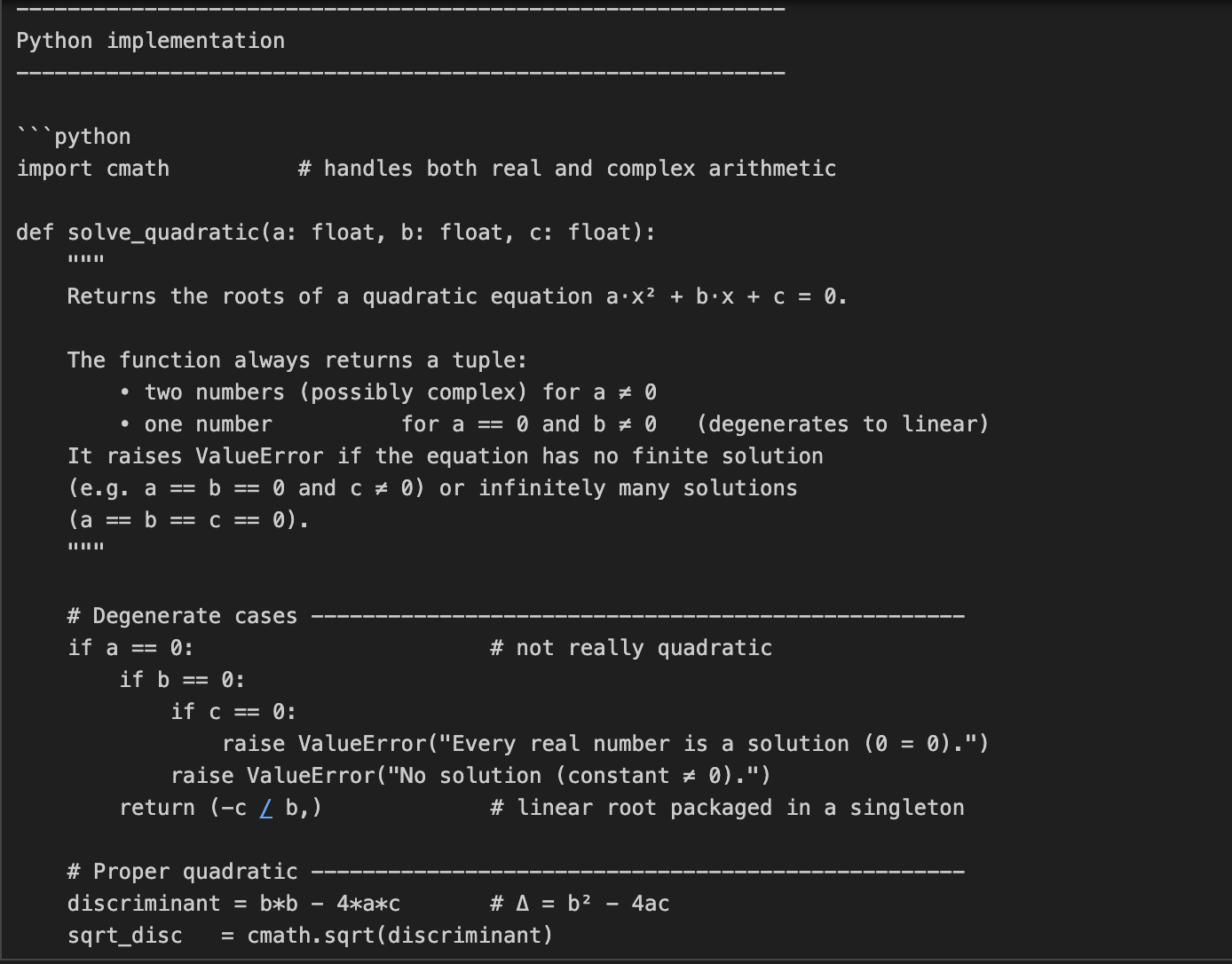
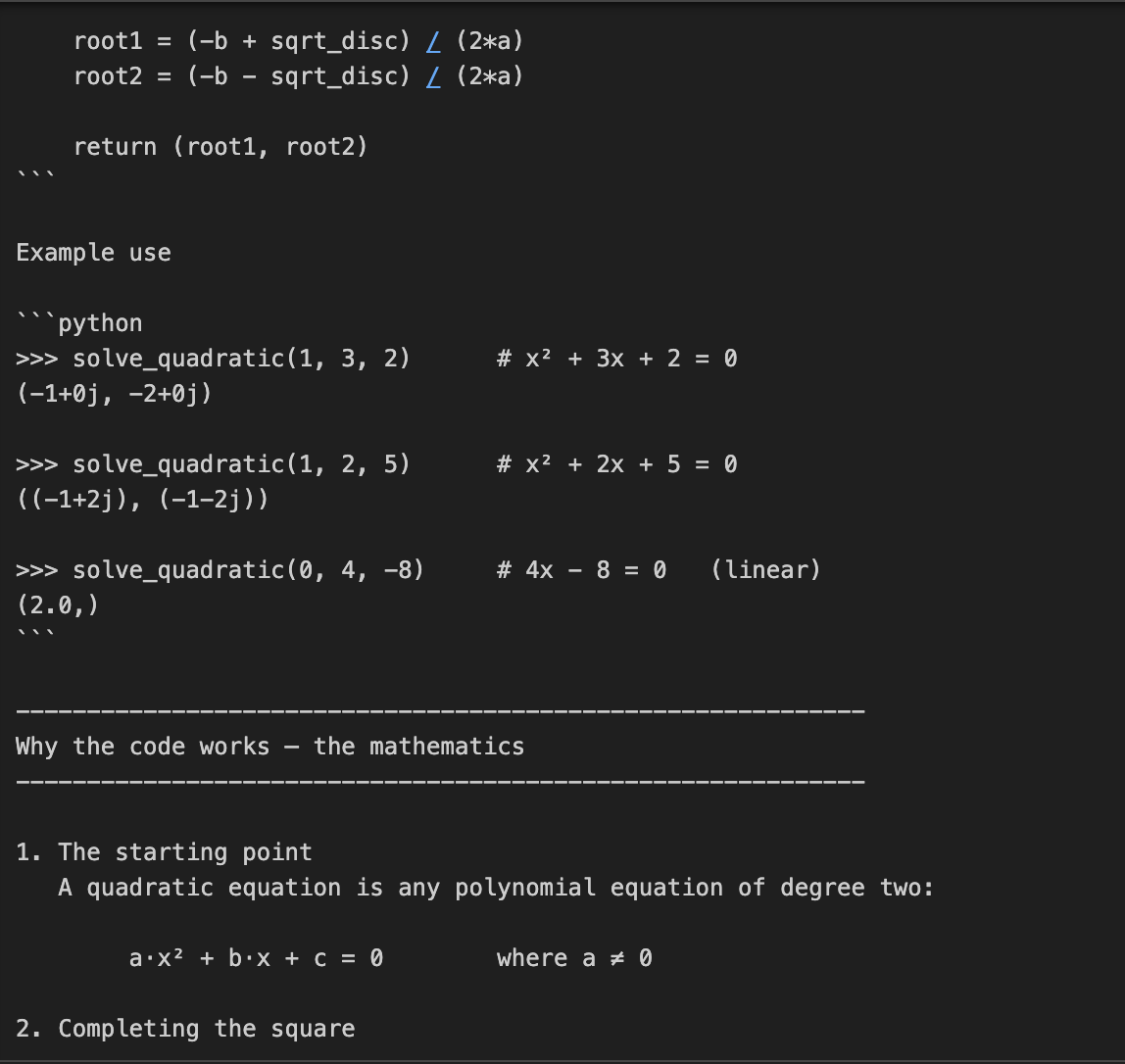
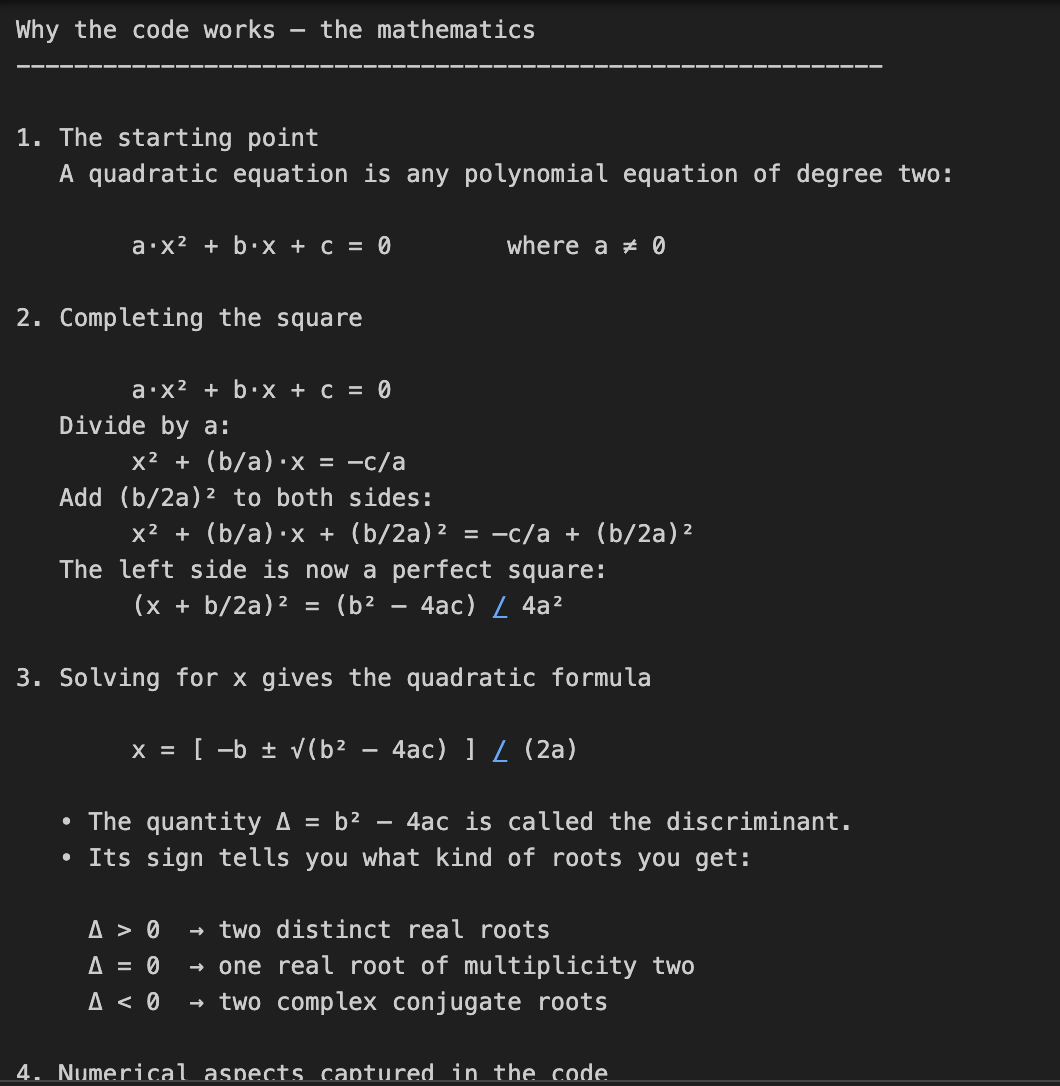
Neste exemplo, pedimos à o3 que codifique e explique a matemática por trás da solução de equações quadráticas. Essa é uma tarefa de duas partes, que exige não apenas a codificação, mas também uma explicação matemática detalhada.
prompt = "Write a Python function that solves quadratic equations and also explain the math behind it."
response = client.responses.create(
model="o3",
reasoning={"effort": "high"},
input=[{"role": "user", "content": prompt}]
)
print(response.output_text)Essa tarefa requer raciocínio matemático em várias etapas, primeiro resolvendo uma fórmula quadrática e depois explicando a derivação. O parâmetro reasoning={"effort": "high"} força o3 a "pensar mais", gerando um rastro de raciocínio maior. Isso o torna perfeito para tarefas que exigem profundidade técnica ou soluções de vários estágios.
Nota de custo: Um esforço de raciocínio maior significa mais tokens de raciocínio, o que resulta em um custo de produção maior.
Neste exemplo, passamos uma tarefa de refatoração de código para o O3 junto com várias instruções.
prompt = """
Instructions:
- Given the React component below, change it so that nonfiction books have red
text.
- Return only the code in your reply
- Do not include any additional formatting, such as markdown code blocks
- For formatting, use four space tabs, and do not allow any lines of code to
exceed 80 columns
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.responses.create(
model="o3",
reasoning={"effort": "medium", "summary": "detailed"},
input=[
{
"role": "user",
"content": prompt,
}
]
)
print(response.output_text)No código acima, passamos ao O3 uma tarefa de edição de código muito estruturada com regras de formatação detalhadas.
reasoning={"effort": "medium"} diz a ele para raciocinar com cuidado, mas de forma eficiente.summary="detailed" solicita um resumo interno completo do processo de pensamento do modelo. O O3 raciocinará internamente e, opcionalmente, retornará um rastreamento resumido se você inspecionar o campo summary posteriormente.Dica: Há algumas configurações de resumo configurações de resumo disponíveis que você pode usar, como "conciso", "detalhado" ou "automático".

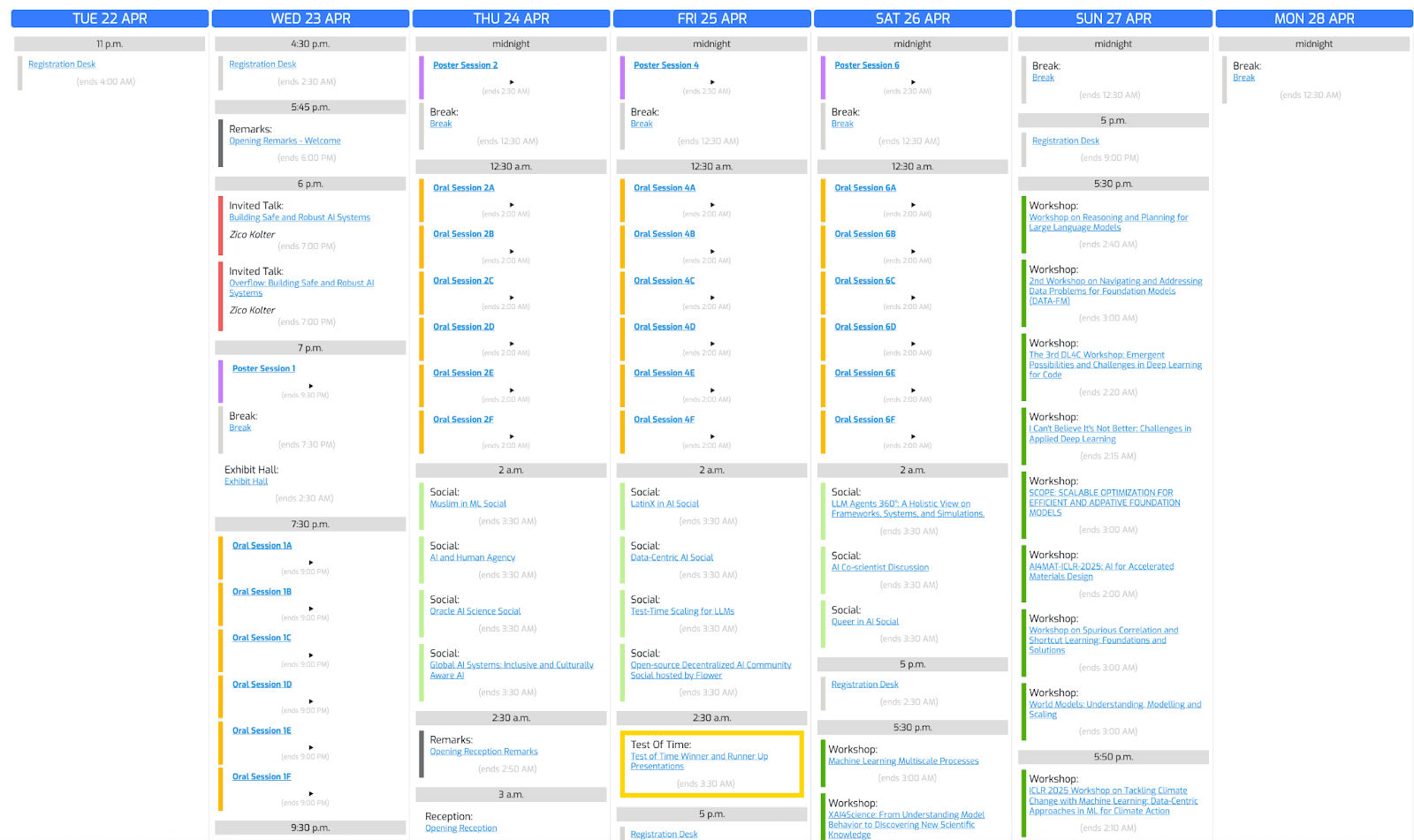
Vamos usar essa foto da conferência e pedir ao o3 que crie uma programação com base em nossos interesses.
Vamos começar importando as bibliotecas necessárias e escrevendo uma função auxiliar:
import base64, mimetypes, pathlib
def to_data_url(path: str) -> str:
mime = mimetypes.guess_type(path)[0] or "application/octet-stream"
data = pathlib.Path(path).read_bytes()
b64 = base64.b64encode(data).decode()
return f"data:{mime};base64,{b64}"A função to_data_url() converte o arquivo de imagem local em um URL de dados codificado em base64, o que é necessário porque a API da OpenAI espera entradas de imagem em formato de URL em vez de arquivos brutos.
A função to_data_url faz o seguinte:
Agora que codificamos nossa imagem, passamos o texto e as informações da imagem codificada para o O3.
prompt = (
"Create a schedule using this blurry conference photo. "
"Ensure 10-minute gaps between talks and include all talks related to LLMs."
)
image_path = "IMAGE_PATH"
image_url = to_data_url(image_path)
response = client.chat.completions.create(
model="o3",
messages=[
{
"role": "user",
"content": [
{ "type": "text", "text": prompt },
{ "type": "image_url", "image_url": { "url": image_url } }
],
}
],
)
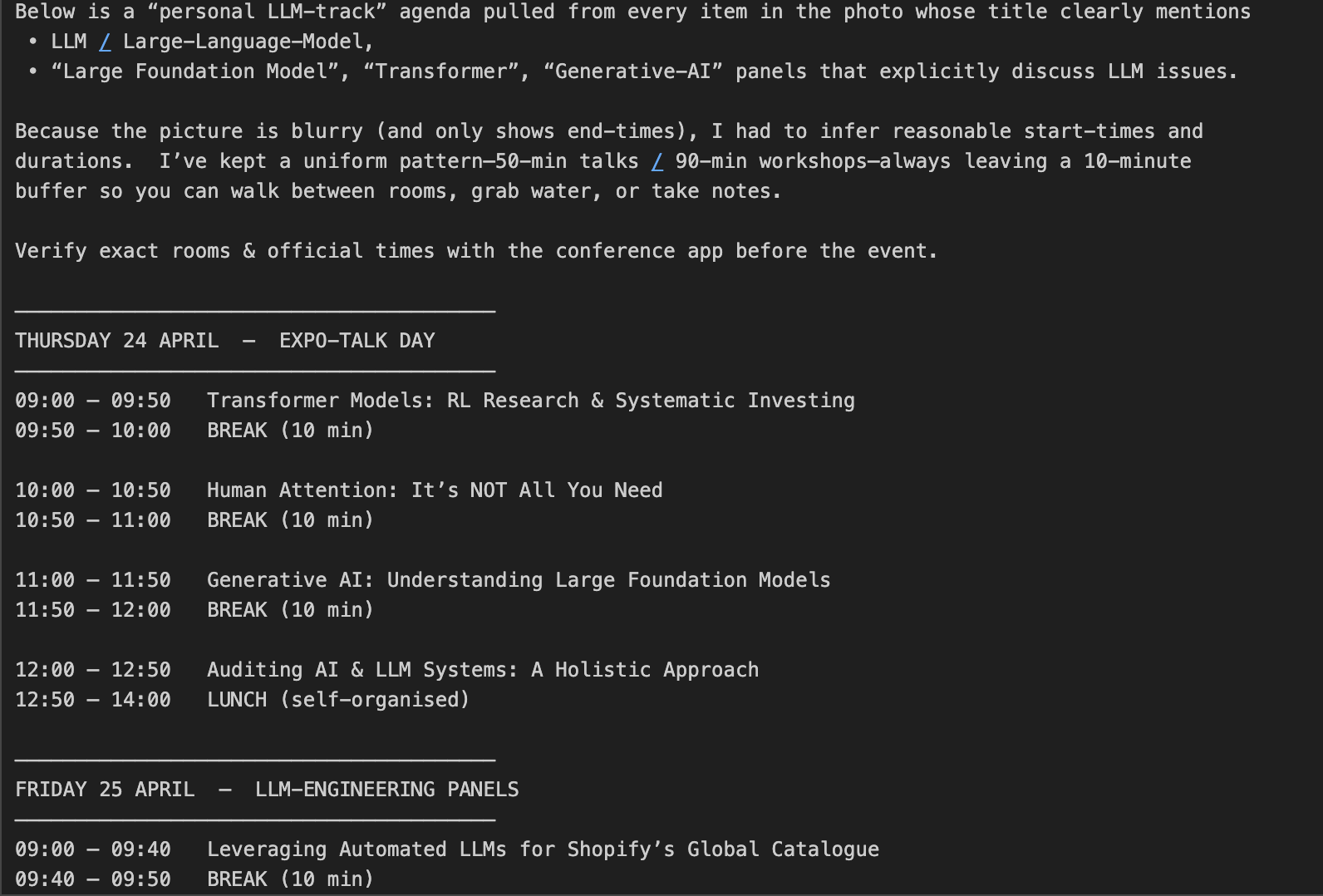
print(response.choices[0].message.content)Veja como isso funciona:
client.chat.completions.create(), em que o conteúdo de entrada é uma lista que contém ambos:response.choices[0].message.content, que contém a programação gerada que o modelo criou após raciocinar sobre as instruções de texto e os dados visuais.Considerações importantes sobre custos:
max_completion_tokens, que será abordado na próxima seção.Vamos ver o resultado:

O O3 usa tokens de raciocínio além dos tokens de entrada/saída normais, o que significa mais tokens do que os tokens de entrada/saída normais e, portanto, um custo de saída mais alto. Seguindo nosso exemplo anterior, vamos detalhar como os tokens de raciocínio afetam o custo.
print(response.usage)CompletionUsage(completion_tokens=3029,prompt_tokens=1007, total_tokens=4036, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=0, audio_tokens=0, reasoning_tokens=2112, rejected_prediction_tokens=0), prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0))Se você quiser controlar os custos, aplique o parâmetro max_completion_tokens para limitar o uso total:
limit_token_response = client.chat.completions.create(
model="o3",
messages=[
{
"role": "user",
"content": [
{ "type": "text", "text": prompt },
{ "type": "image_url", "image_url": { "url": image_url } }
],
}
],
max_completion_tokens=3000,
)
print(limit_token_response.usage)CompletionUsage(completion_tokens=2746, prompt_tokens=1007, total_tokens=3753, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=0, audio_tokens=0, reasoning_tokens=2112, rejected_prediction_tokens=0), prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0))No resultado acima, podemos ver que a definição de um valor max_completion_tokens é fundamental para controlar o comportamento do modelo. Ao limitar o número máximo de tokens gerados, evitamos que a o3 produza saídas desnecessariamente longas ou consuma tokens de raciocínio excessivos, o que ajuda a otimizar os custos gerais da API. Isso é especialmente importante em tarefas complexas em que o raciocínio interno poderia dominar o uso de tokens sem produzir resultados proporcionais visíveis ao usuário.
Importante: Ao usar o o3 para tarefas visuais complexas, sempre defina max_completion_tokens como conservadoramente alto. Se o limite de tokens for muito baixo, o modelo poderá consumir todos os tokens durante o raciocínio interno e não retornar nenhum resultado visível.
O modelo O3 se comporta de forma diferente em comparação com modelos generalistas como GPT-4o ou Claude 3.5 Sonnetporque o O3 se envolve internamente em um raciocínio profundo de cadeia de pensamento. Ele tem melhor desempenho com prompts diretos e orientados a objetivos, ou seja, especificar demais as etapas pode prejudicar seu desempenho.
Aqui estão algumas práticas recomendadas pela OpenAI para solicitar o3:
Ao longo deste blog, aprendemos a nos conectar ao modelo O3 da OpenAI por meio da API, a gerenciar os custos do token de raciocínio e a criar prompts eficazes usando as práticas recomendadas. Se o seu projeto exigir recursos avançados de raciocínio, como matemática em várias etapas, refatoração de código ou compreensão visual, o O3 é a melhor opção.
Para saber mais sobre como trabalhar com as APIs, recomendo estes blogs:
Aprenda IA com estes cursos!
Curso
Curso
Curso
blog
Richie Cotton
8 min
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan



