
Kurs
Entwickeln von LLM-Anwendungen mit LangChain
3 Std.
46.2K
OpenAIs o3 Modell ist in der Lage, komplexe, mehrstufige Probleme zu lösen, visuelle und textuelle Eingaben zu mischen und Werkzeuge wie Python, Suche oder Bildinspektion zu nutzen, um seine Antworten zu verbessern.
In diesem Tutorial erkläre ich dir Schritt für Schritt , wie du o3 über die API nutzen kannst, was o3 von generalistischen Modellen wie GPT-4o unterscheidet und wie du die Argumentationskosten effektiv verwalten kannst.
Wir halten unsere Leserinnen und Leser mit The Median auf dem Laufenden, unserem kostenlosen Freitags-Newsletter, der die wichtigsten Meldungen der Woche aufschlüsselt. Melde dich an und bleibe in nur ein paar Minuten pro Woche auf dem Laufenden:
Das o3-Modell von OpenAI wurde für fortgeschrittene, komplexe Aufgaben entwickelt, die ein tiefes Denkvermögen und Autonomie erfordern. Sie ist besonders effektiv für komplizierte Problemlösungen in Bereichen wie Softwareentwicklung, Mathematik, wissenschaftliche Forschung und visuelle Dateninterpretation.
Dank seiner agentenbasierten Fähigkeiten kann das Modell selbstständig Tools wie Websuche, Python und Bilderzeugung nutzen und ist damit ideal für Aufgaben, die mehrstufige Analysen und dynamische Entscheidungen erfordern.
Du solltest die Nutzung des o3-Modells über die API in Betracht ziehen, wenn deine Projekte komplexe, multimodale Argumentationsaufgaben beinhalten, die von seiner hohen Autonomie und seinen fortgeschrittenen analytischen Fähigkeiten profitieren.
Sehen wir uns einen schnellen Vergleich zwischen o3, o4-mini und GPT-4o an:

Quelle: OpenAI
Auch die Preisgestaltung ist ein wichtiger Faktor, den du bei der Nutzung der API berücksichtigen musst:
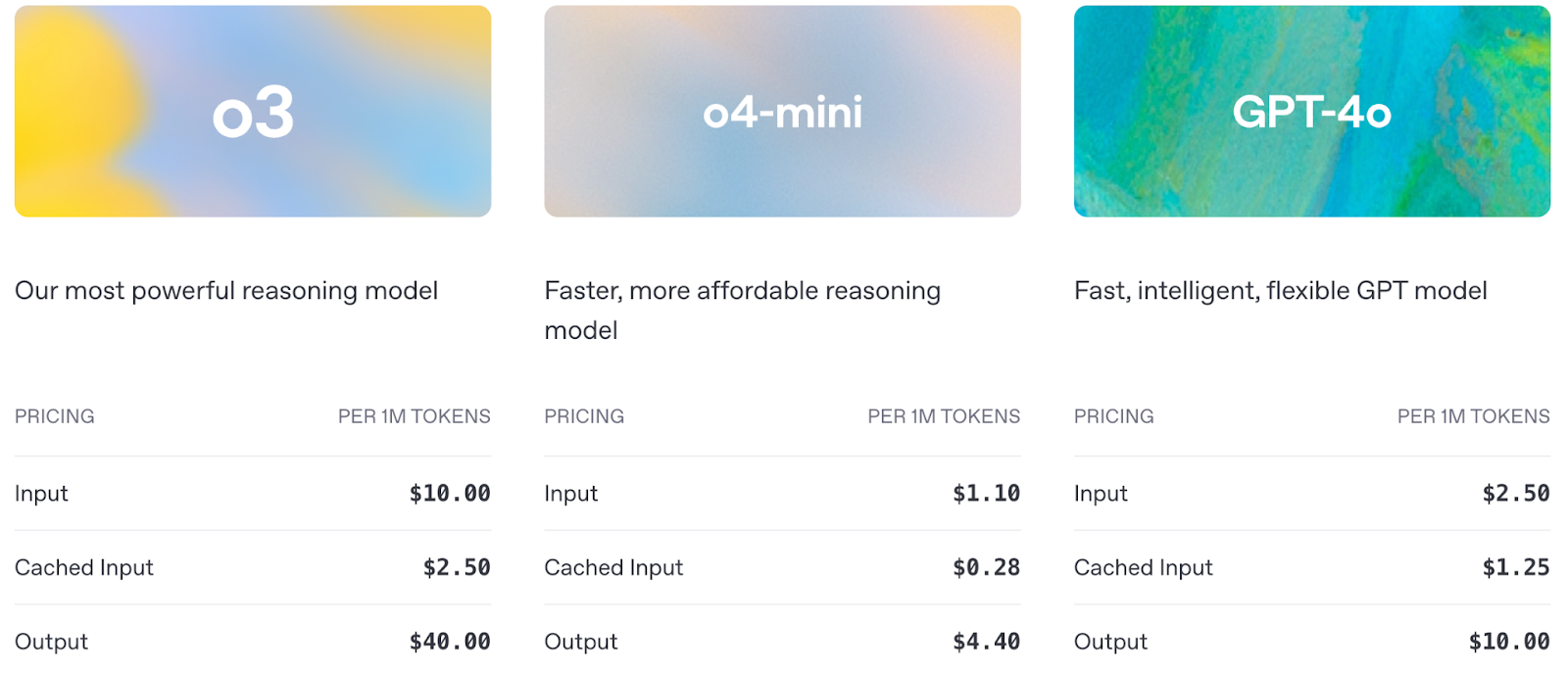
Quelle: OpenAI
Bevor du die erweiterten Argumentationsfähigkeiten von o3 nutzen kannst, musst du den Zugang zur OpenAI API einrichten. In diesem Abschnitt führe ich dich durch:
Um auf die OpenAI API zuzugreifen, benötigst du einen gültigen API-Schlüssel, den du auf der OpenAI API-Schlüssel Seiteerhalten kannst, und stelle sicher, dass deine Rechnungsstellung aktiviert ist.
Hinweis: Um o3 zu nutzen, musst du zuerst deine OpenAI Organisation verifizieren hier. Es kann bis zu 15 Minuten dauern, bis die Verifizierung aktiviert wird.
openai BibliothekWir beginnen mit der Installation und Aktualisierung der Bibliothek openai, um über die API auf das O3-Modell zuzugreifen. Führe den folgenden Befehl aus:
pip install --upgrade openaiNach der Installation importieren wir die Klasse OpenAI aus der openai-Bibliothek:
from openai import OpenAIUm mit der API von OpenAI zu interagieren, authentifizieren wir uns, indem wir unseren geheimen API-Schlüssel festlegen, damit wir autorisierte Anfragen an Modelle wie o3 stellen können.
client = OpenAI(api_key=YOUR_API_KEY)Jetzt, wo die Einrichtung abgeschlossen ist, wollen wir unseren ersten API-Aufruf an o3 machen und sehen, wie es eine einfache mehrstufige Argumentationsaufgabe über die Responses API bearbeitet.
Lass uns den o3-API-Aufruf anhand eines einfachen Beispiels verstehen.
response = client.responses.create(
model="o3",
input=[{"role": "user", "content": "What’s the difference between inductive and deductive reasoning?"}]
)
print(response.output_text)In diesem Beispiel wird eine natürlichsprachliche Frage direkt an das o3-Modell gesendet, ohne dass irgendwelche Tools oder spezielle Argumentationsparameter verwendet werden.
model="o3" weist die API an, das o3-Schlussfolgermodell zu verwenden.input=[{"role": "user", "content": "..."}] definiert eine einzelne Nutzernachricht, die nach einer konzeptionellen Erklärung fragt.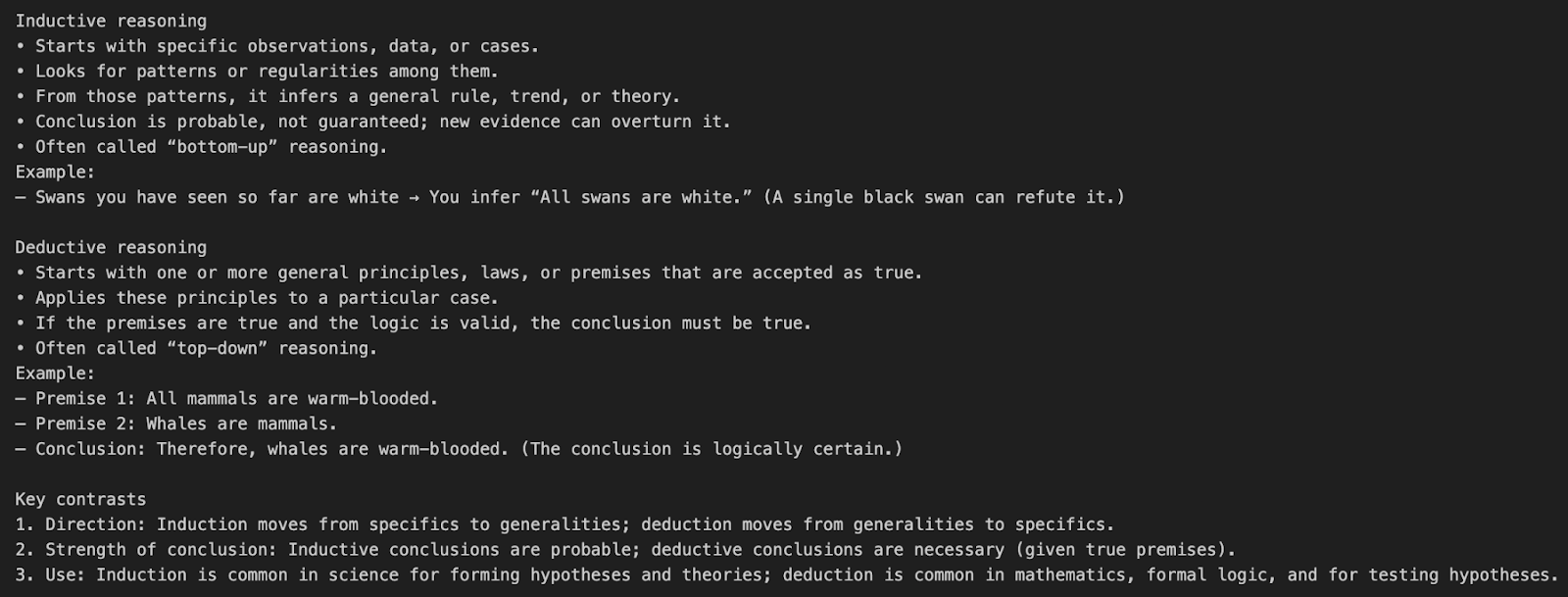
Das sind die Token, die zu den endgültigen Kosten zählen:
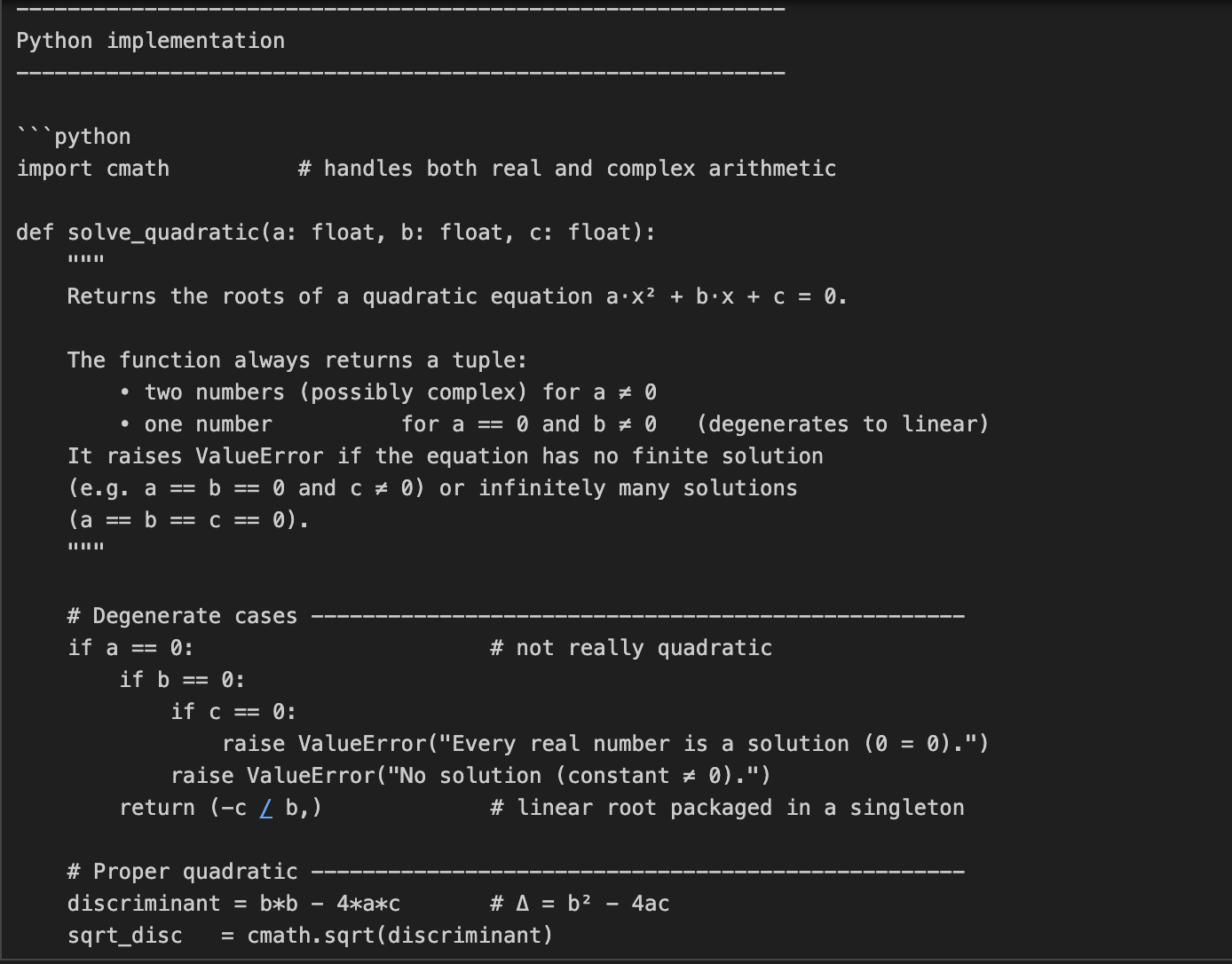
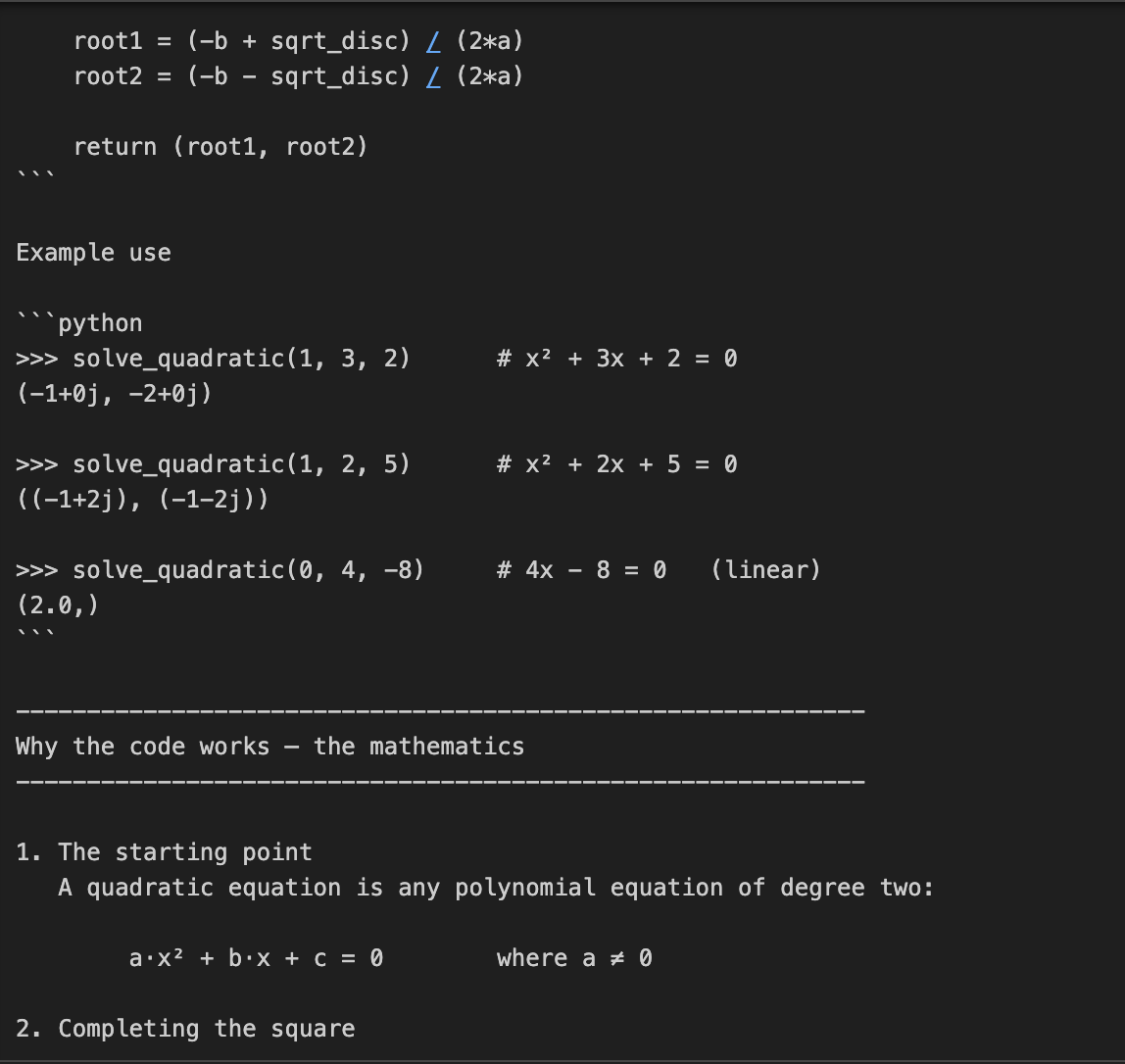
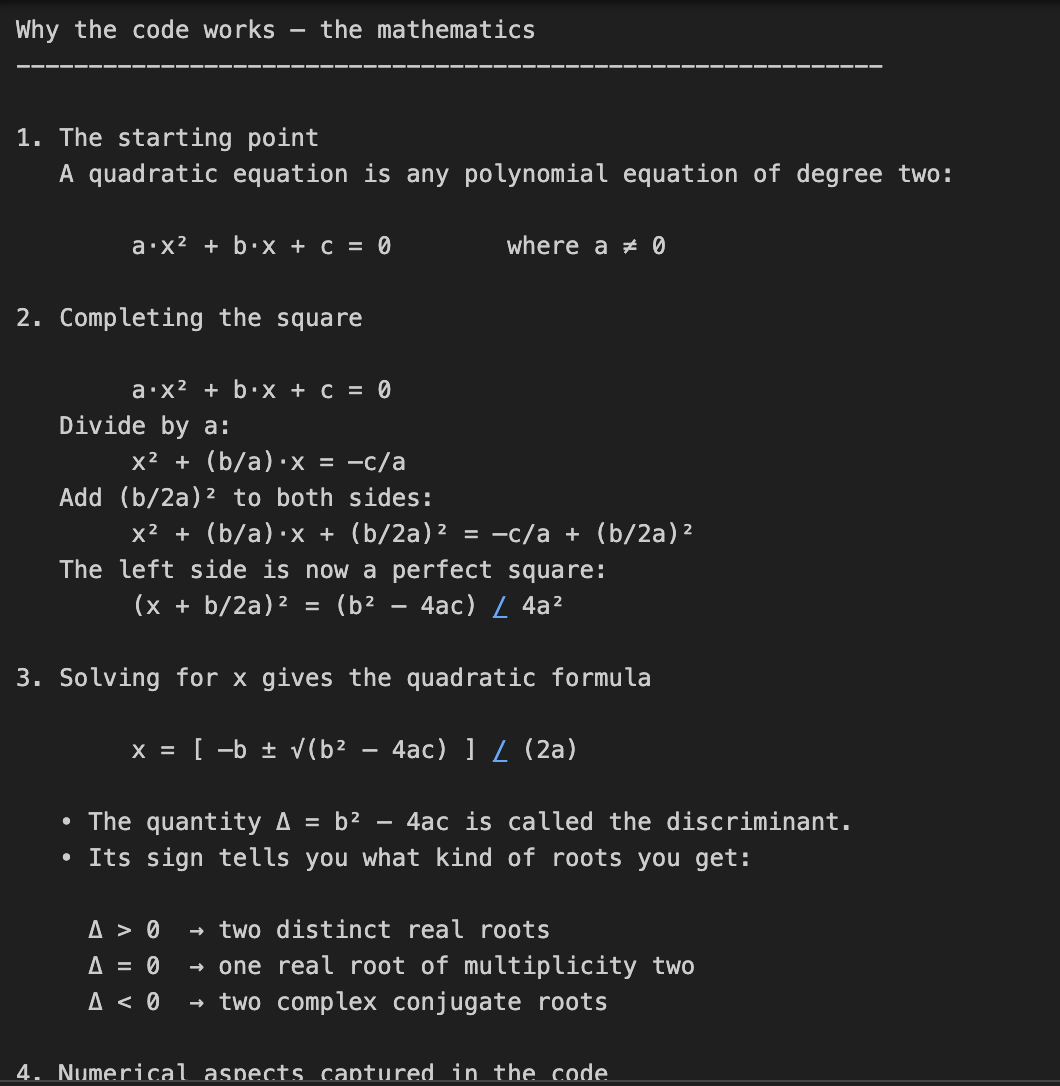
In diesem Beispiel bitten wir o3, sowohl den Code zu schreiben als auch die Mathematik zu erklären, die hinter dem Lösen quadratischer Gleichungen steckt. Das ist eine zweiteilige Aufgabe, die nicht nur eine Codierung, sondern auch eine detaillierte mathematische Erklärung erfordert.
prompt = "Write a Python function that solves quadratic equations and also explain the math behind it."
response = client.responses.create(
model="o3",
reasoning={"effort": "high"},
input=[{"role": "user", "content": prompt}]
)
print(response.output_text)Diese Aufgabe erfordert mehrstufiges mathematisches Denken, indem zuerst eine quadratische Formel gelöst und dann die Herleitung erklärt wird. Der Parameter reasoning={"effort": "high"} zwingt o3 dazu, "härter zu denken" und eine größere Argumentationsspur zu erzeugen. Das macht sie perfekt für Aufgaben, die technische Tiefe oder mehrstufige Lösungen erfordern.
Kostenhinweis: Ein höherer Denkaufwand bedeutet mehr Denkmünzen, was zu höheren Produktionskosten führt.
In diesem Beispiel übergeben wir O3 eine Code-Refactoring-Aufgabe zusammen mit einer Reihe von Anweisungen.
prompt = """
Instructions:
- Given the React component below, change it so that nonfiction books have red
text.
- Return only the code in your reply
- Do not include any additional formatting, such as markdown code blocks
- For formatting, use four space tabs, and do not allow any lines of code to
exceed 80 columns
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.responses.create(
model="o3",
reasoning={"effort": "medium", "summary": "detailed"},
input=[
{
"role": "user",
"content": prompt,
}
]
)
print(response.output_text)Im obigen Code übergeben wir O3 eine sehr strukturierte Codebearbeitungsaufgabe mit detaillierten Formatierungsregeln.
reasoning={"effort": "medium"} sagt ihm, dass er vorsichtig, aber effizient denken soll.summary="detailed" fordert eine vollständige interne Zusammenfassung des Denkprozesses des Modells. O3 wird intern Schlussfolgerungen ziehen und optional einen zusammengefassten Trace zurückgeben, wenn du später das Feld summary inspizierst.Tipp: Es gibt ein paar Es gibt einige verfügbare Zusammenfassungseinstellungen, die du verwenden kannst, z. B. "kurz", "ausführlich" oder "automatisch".

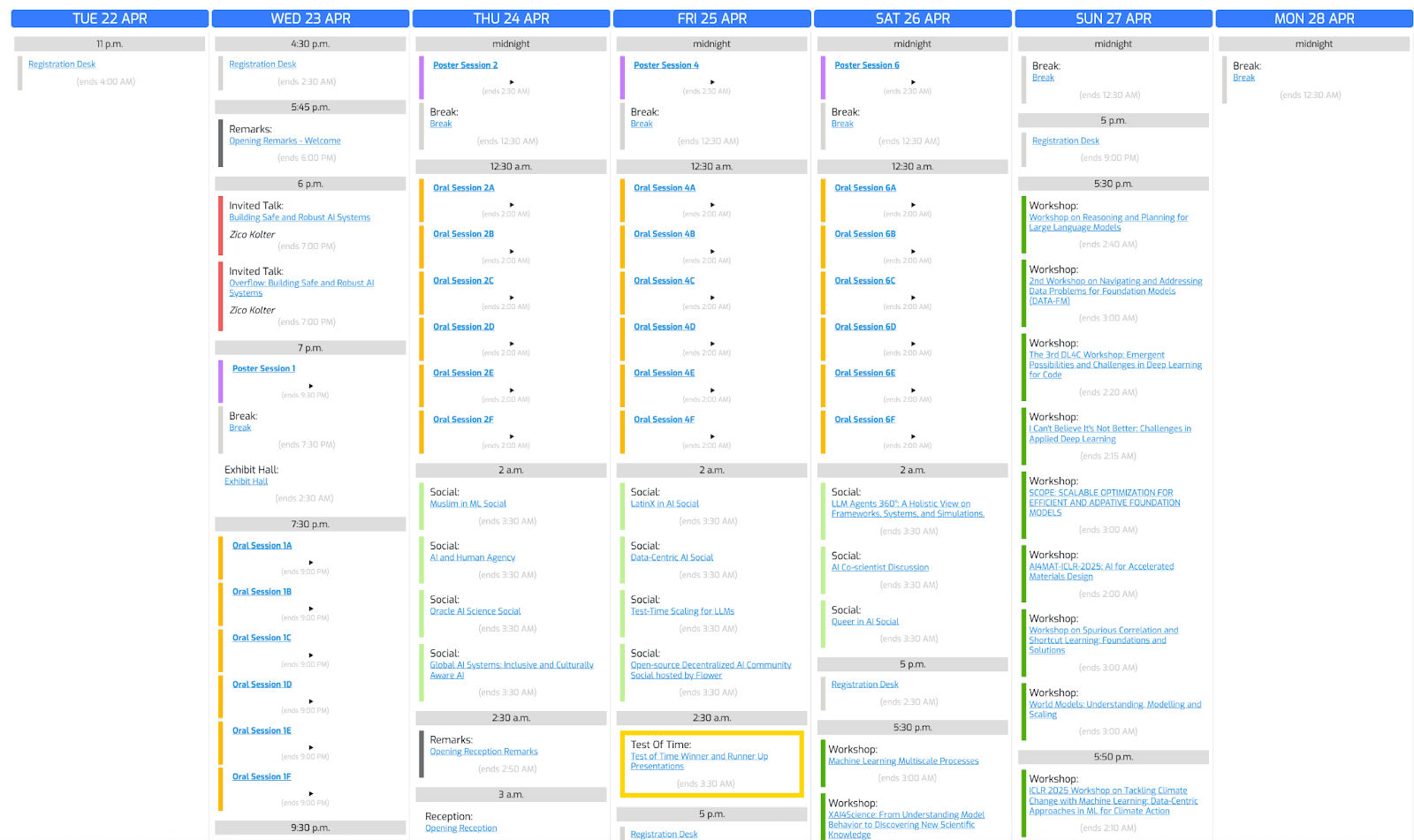
Lass uns dieses Konferenzfoto nutzen und o3 bitten, einen Zeitplan zu erstellen, der auf unseren Interessen basiert.
Beginnen wir damit, die benötigten Bibliotheken zu importieren und eine Hilfsfunktion zu schreiben:
import base64, mimetypes, pathlib
def to_data_url(path: str) -> str:
mime = mimetypes.guess_type(path)[0] or "application/octet-stream"
data = pathlib.Path(path).read_bytes()
b64 = base64.b64encode(data).decode()
return f"data:{mime};base64,{b64}"Die Funktion to_data_url() wandelt die lokale Bilddatei in eine base64-kodierte Daten-URL um. Das ist notwendig, weil die OpenAI-API Bildeingaben im URL-Format und nicht als Rohdateien erwartet.
Die Funktion to_data_url macht Folgendes:
Jetzt, wo wir unser Bild kodiert haben, übergeben wir sowohl den Text als auch die kodierten Bildinformationen an O3.
prompt = (
"Create a schedule using this blurry conference photo. "
"Ensure 10-minute gaps between talks and include all talks related to LLMs."
)
image_path = "IMAGE_PATH"
image_url = to_data_url(image_path)
response = client.chat.completions.create(
model="o3",
messages=[
{
"role": "user",
"content": [
{ "type": "text", "text": prompt },
{ "type": "image_url", "image_url": { "url": image_url } }
],
}
],
)
print(response.choices[0].message.content)So funktioniert es:
client.chat.completions.create(), wobei der Eingabeinhalt eine Liste ist, die beides enthält:response.choices[0].message.content aus, das den generierten Zeitplan enthält, den das Modell nach der Auswertung der Textanweisungen und der visuellen Daten erstellt hat.Wichtige Kostenüberlegungen:
max_completion_tokens verwalten, den wir im nächsten Abschnitt behandeln werden.Lass uns das Ergebnis sehen:
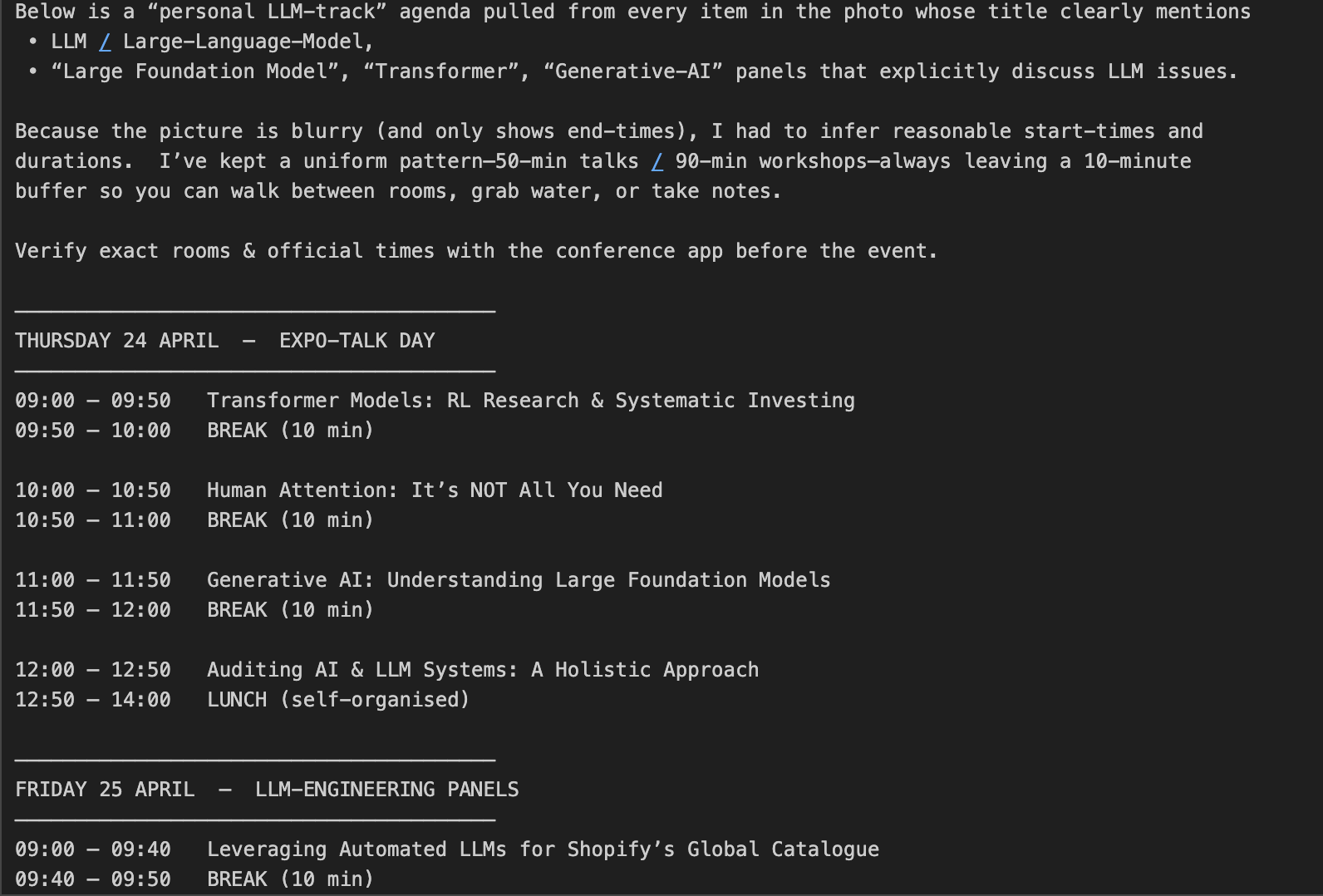

O3 verwendet zusätzlich zu den regulären Eingabe-/Ausgabe-Token auch Argumentations-Token, was mehr Token als reguläre Eingabe-/Ausgabe-Token und damit höhere Ausgabekosten bedeutet. In Anlehnung an unser vorheriges Beispiel wollen wir nun aufschlüsseln, wie sich die Argumentations-Token auf die Kosten auswirken.
print(response.usage)CompletionUsage(completion_tokens=3029,prompt_tokens=1007, total_tokens=4036, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=0, audio_tokens=0, reasoning_tokens=2112, rejected_prediction_tokens=0), prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0))Wenn du die Kosten kontrollieren willst, wende den Parameter max_completion_tokens an, um den Gesamtverbrauch zu begrenzen:
limit_token_response = client.chat.completions.create(
model="o3",
messages=[
{
"role": "user",
"content": [
{ "type": "text", "text": prompt },
{ "type": "image_url", "image_url": { "url": image_url } }
],
}
],
max_completion_tokens=3000,
)
print(limit_token_response.usage)CompletionUsage(completion_tokens=2746, prompt_tokens=1007, total_tokens=3753, completion_tokens_details=CompletionTokensDetails(accepted_prediction_tokens=0, audio_tokens=0, reasoning_tokens=2112, rejected_prediction_tokens=0), prompt_tokens_details=PromptTokensDetails(audio_tokens=0, cached_tokens=0))Aus der obigen Ausgabe geht hervor, dass der Wert max_completion_tokens entscheidend ist, um das Verhalten des Modells zu steuern. Indem wir die maximale Anzahl der generierten Token begrenzen, verhindern wir, dass o3 unnötig lange Ausgaben produziert oder übermäßig viele Argumentations-Token verbraucht, was zur Optimierung der gesamten API-Kosten beiträgt. Das ist besonders wichtig bei komplexen Aufgaben, bei denen interne Überlegungen sonst die Verwendung von Token dominieren könnten, ohne dass die Ergebnisse für den Benutzer sichtbar sind.
Wichtig! Wenn du o3 für komplexe visuelle Aufgaben verwendest, stelle max_completion_tokens immer konservativ hoch ein. Wenn das Token-Limit zu niedrig ist, kann es sein, dass das Modell während der internen Argumentation alle Token verbraucht und keine sichtbaren Ergebnisse liefert.
Das O3-Modell verhält sich anders als generalistische Modelle wie GPT-4o oder Claude 3.5 Sonnetweil o3 intern eine tiefe Denkkette durchläuft. Es funktioniert am besten mit einfachen und zielgerichteten Aufforderungen, d.h. eine Überspezifizierung der Schritte kann seine Leistung beeinträchtigen.
Hier sind einige von OpenAI empfohlene Best Practices für die Eingabeaufforderung von o3:
In diesem Blog haben wir gelernt, wie man sich über die API mit dem O3-Modell von OpenAI verbindet, die Kosten für Argumentationstoken verwaltet und effektive Prompts mit Best Practices erstellt. Wenn dein Projekt fortgeschrittene Argumentationsfähigkeiten wie mehrstufige Mathematik, Code-Refactoring oder visuelles Verständnis erfordert, ist O3 die beste Wahl.
Um mehr über die Arbeit mit den APIs zu erfahren, empfehle ich diese Blogs:
Lerne KI mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
