Curso
Ingeniería rápida con la API de OpenAI
4 h
47.9K
Los Grandes Modelos del Lenguaje (LLM) generan texto mediante una técnica llamada autoregresión, que consiste en predecir la siguiente palabra más probable de una secuencia basándose en las palabras anteriores. Los agentes potenciados por LLM, como ChatGPT, también están afinados para seguir la intención del usuario. Por tanto, no sólo completan la secuencia de entrada, sino que captan la intención del usuario sobre la entrada y generan una respuesta en consecuencia.
Si has probado ChatGPT durante un tiempo, seguro que te has dado cuenta de que la calidad de una respuesta dada también depende de la calidad de la entrada del usuario, por ejemplo, el agente proporciona "mejores" respuestas a ciertas consultas que a otras.
El secreto para obtener la mejor respuesta posible es comprender cómo generan la salida los LLM y formular la pregunta de entrada en consecuencia. El conjunto de técnicas aplicadas a la entrada del usuario para explotar todo el potencial del modelo se conoce como Ingeniería Prompt.
En este artículo, exploraremos una de las técnicas más potentes de la Ingeniería Prompt: Incitación a la cadena de pensamiento (CoT). Esta técnica consiste en estructurar la indicación de forma que facilite al modelo la realización de tareas complejas que requieran razonamiento o resolución de problemas. Se ha demostrado que, sin CoT, el mismo modelo no proporciona la respuesta correcta.
Aunque los LLM son conocidos por su capacidad de generalización, las capacidades del modelo dependen de la tarea. Al utilizar los LLM, es importante tener en cuenta que cada modelo se ha entrenado en una base de datos enorme pero limitada, y se ha optimizado para determinadas tareas. Por lo tanto, aunque el modelo puede ser muy eficaz en determinados ámbitos, puede fallar en otros.
Las capacidades del modelo también dependen del momento. Como en los humanos, si me das una suma de 5 dígitos, necesitarás tiempo para pensar y responder con la respuesta correcta. Si lo haces con prisas, podrías fácilmente calcular mal y fallar en tu respuesta.
Del mismo modo, si damos a un modelo lingüístico una tarea demasiado compleja para realizarla en el tiempo que tarda en calcular su siguiente token, puede que no dé la respuesta correcta.
Sin embargo, al igual que ocurre con los humanos, eso no significa necesariamente que el modelo sea incapaz de realizar la tarea. Con algo de tiempo u orientación para razonar las cosas, el modelo aún puede ser capaz de responder de forma fiable.
La respuesta del modelo y el tiempo necesario para generarla también pueden verse influidos por diversos factores, como la formulación concreta de la pregunta:
Las indicaciones de la cadena de pensamiento guían a los LLM para que consigan resolver tareas complejas, tanto eligiendo la forma de formular la indicación como proporcionando al modelo el tiempo o los pasos necesarios para generar la respuesta correcta.
La incitación a la cadena de pensamiento es una técnica que mejora el rendimiento de los modelos lingüísticos incitando explícitamente al modelo a generar una explicación paso a paso o un proceso de razonamiento antes de llegar a una respuesta final. Este método ayuda al modelo a desglosar el problema y a no saltarse ninguna tarea intermedia para evitar fallos de razonamiento.
El CdT es eficaz porque ayuda a centrar el mecanismo de atención del LLM. La descomposición del proceso de razonamiento hace que el modelo centre su atención en una parte del problema cada vez, minimizando el riesgo de errores que podrían surgir al manejar demasiada información simultáneamente.
Los investigadores de Google introdujeron la incitaciónala cadena de pensamiento en un artículo titulado "Chain of Thought Prompting Elicits Reasoning in Large Language Models" en 2022. Esta investigación puso de relieve cómo guiar a un modelo a través de una serie de pasos intermedios de razonamiento mejoraba significativamente su rendimiento en tareas de resolución de problemas matemáticos, razonamiento lógico y respuesta a preguntas de varios saltos.
Veamos uno de los ejemplos propuestos:
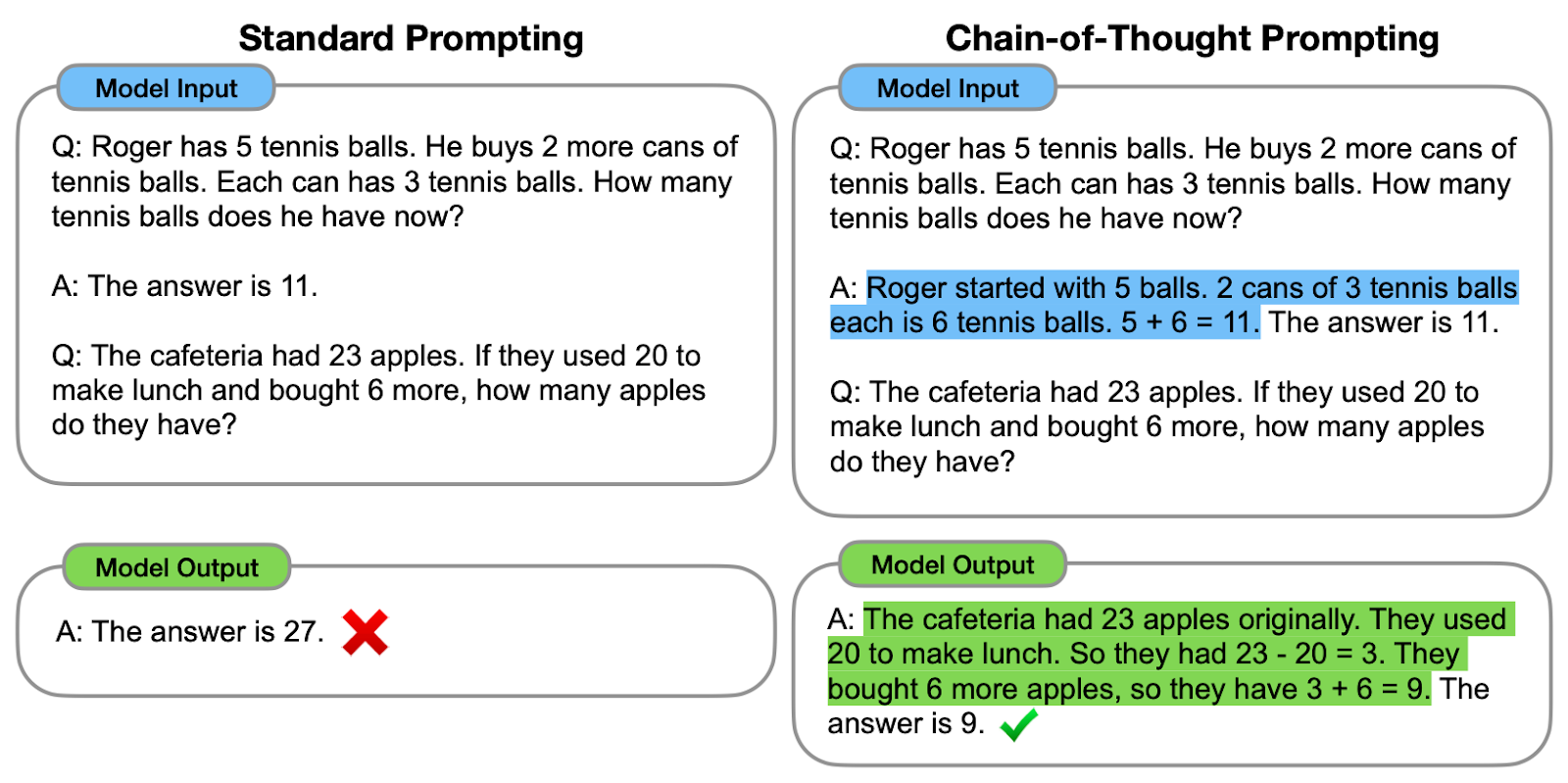
Comparación entre el estímulo estándar y el estímulo CoT. A la izquierda, se indica al modelo que proporcione directamente la respuesta final (indicación estándar). A la derecha, se indica al modelo que muestre el proceso de razonamiento para llegar a la respuesta final (CoT prompting).
Como podemos observar, generar una cadena de pensamiento -una serie de pasos intermedios de razonamiento- ayuda al modelo a proporcionar la respuesta correcta.
Los autores originales se refieren a la cadena de pensamiento como la serie de pasos intermedios de razonamiento en lenguaje natural que conducen al resultado final, refiriéndose a este enfoque como Chain-of-Thought prompting.
El proceso comienza con la elaboración de indicaciones que animen al modelo a pensar en el problema paso a paso, generando así los pasos intermedios sin saltar directamente a la respuesta final. Esto puede hacerse utilizando diferentes estrategias:
Dar instrucciones explícitas significa descomponer el problema en la propia consulta del usuario. Por ejemplo, utilizando frases como "En primer lugar, tenemos que considerar..." para que el modelo detalle su proceso de pensamiento.
¡Veámoslo en acción!
Imagina que mi madre española me ha enviado la receta familiar para preparar Cold Brew:
input_text = """
¡Preparar café Cold Brew es un proceso sencillo y refrescante!
Todo lo que necesitas son granos de café molido grueso y agua fría.
Comienza añadiendo el café molido a un recipiente o jarra grande.
Luego, vierte agua fría, asegurándote de que todos los granos de café
estén completamente sumergidos.
Remueve la mezcla suavemente para garantizar una saturación uniforme.
Cubre el recipiente y déjalo en remojo en el refrigerador durante al
menos 12 a 24 horas, dependiendo de la fuerza deseada.
"""Supongamos que nos interesa traducir al inglés todas las palabras relacionadas con el café, y queremos utilizar ChatGPT para la tarea:
prompt = f"""
Give me a numbered list of all coffee-related words in English from the text below:
Text: <{input_text}>
"""
response = chatgpt_call(prompt)
print(response)Aquí tienes la respuesta a esta pregunta:
Si pedimos al modelo que realice esta tarea directamente, podemos ver que la realiza de forma incorrecta. No sólo emite palabras de café no relacionadas, sino que además las emite en español, no en inglés.
Podríamos considerar que esta tarea es compleja, ya que requiere dos pasos:
En cambio, el modelo salta directamente a la tarea final de identificar las palabras relacionadas con el café, omitiendo el paso de la traducción. Especificando la traducción como tarea intermedia o descomponiendo la tarea en los dos pasos principales, podemos guiar al modelo hacia la salida correcta:
prompt = f"""
Give me a numbered list of all coffee-related words in English from the text below:
The task requires the following actions:
1 - Translate the given text into English.
2 - List each coffee-related word from the English text.
Text: <{input_text}>
"""
response = chatgpt_call(prompt)
print(response)Incluyendo la Cadena de Pensamiento anterior se llega a la respuesta correcta:

Si te interesa probar esta técnica con otros LLM en lugar de ChatGPT o la API OpenAI, como en este artículo, ¡el curso "Desarrollo de grandes modelos lingüísticos " es para ti!
A veces, no es necesario descomponer el problema nosotros mismos en el aviso. La Universidad de Tokio, junto con Google Research, propuso un bonito método para mejorar las respuestas de los LLM que consistía simplemente en añadir "Pensemos paso a paso" al final de la indicación original.
Esta sencilla frase incita al modelo a razonar en voz alta y a seguir todos los pasos necesarios para llevar a cabo la tarea.
Analicemos uno de los ejemplos que los autores propusieron en el artículo original "Large Language Models are Zero-Shot Reasoners":

Comparación entre las instrucciones estándar y el uso de instrucciones CoT implícitas. A la izquierda, el modelo proporciona la respuesta final al problema de inmediato (indicación de cero disparos) y falla. A la derecha, el modelo es instruido con una instrucción implícita de CoT (CoT prompting) llegando a la respuesta correcta.
[a] En el primer ejemplo, los autores piden al modelo que resuelva un problema aritmético, pero fracasa en esta tarea.
[b] Entonces, añadiendo "Pensemos paso a paso" a la pregunta original, el modelo razona la respuesta en voz alta y tiene éxito.
Aplicando este sencillo truco al conjunto de datos matemáticos MultiArith, los autores descubrieron que esta instrucción implícita cuadruplicaba la precisión, ¡del 18% al 79%!
Si te interesa, puedes leer más sobre esta técnica en "Utiliza esta breve promesa para aumentar el resultado del ChatGPT".
Hemos utilizado varias veces el término "tiro cero" en la sección anterior. El tiro por cero se refiere a la capacidad de un modelo para realizar una tarea sin haber sido entrenado explícitamente con ejemplos de esa tarea específica.
Se basa en la capacidad del modelo para generalizar y generar respuestas adecuadas a tareas nuevas y no vistas anteriormente. Eso significa que, cuando abrimos la interfaz de usuario de ChatGPT y hacemos una pregunta directamente, estamos haciendo un "zero-shot prompting".
Sin embargo, hay formas de mostrar al modelo varios ejemplos de tareas similares que queremos resolver. Proporcionar una serie de ejemplos demostrativos se conoce como incitación de un solo disparo o de pocos disparos, dependiendo del número de ejemplos proporcionados.
El estímulo de una sola vez consiste en mostrar al modelo un ejemplo similar a la tarea objetivo para guiarle.
Por ejemplo, si nos remitimos a la primera Figura del artículo, podemos observar que el modelo genera la Cadena de Pensamiento gracias al ejemplo demostrativo proporcionado en la indicación.
El aprendizaje de pocos ejemplos funciona igual que el de un solo ejemplo, pero el número de ejemplos dados es mayor, normalmente unos cien. El rendimiento del modelo aumenta linealmente con el número de ejemplos.
Jason Wei y Denny Zhou et al. de Google estudiaron la incitación de pocos disparos. Este enfoque es especialmente útil para las tareas que requieren un conocimiento más especializado o específico del dominio, en las que el modelo puede no tener suficiente conocimiento de fondo para realizar la tarea utilizando la indicación de disparo cero o de disparo único. A veces se considera que el estímulo de pocos disparos es un pequeño ajuste del modelo sobre una colección de datos nuevos o especiales.
Mira más ejemplos de avisos de uno o pocos disparos en "Mejora el rendimiento de ChatGPT con la ingeniería de avisos".
Los avisos de uno o pocos disparos no son CoT. Sin embargo, los investigadores han explorado cómo puede combinarse el aprendizaje de pocos disparos con el estímulo CoT, lo que se conoce como "estímulo CoT de pocos disparos". En una CoT de pocos disparos, se proporcionan al modelo unos cuantos ejemplos de problemas junto con sus soluciones paso a paso para guiar su proceso de razonamiento.
La combinación de la solicitud de CoT de pocos disparos con otras técnicas, como la generación aumentada por recuperación o la consulta interactiva, puede mejorar aún más el rendimiento y la fiabilidad del modelo. Integrar bases de conocimiento externas, bases de datos o sistemas de recuperación de información permite al modelo mejorar su razonamiento con información factual y actualizada.
Laberinto de problemas matemáticos para ilustrar cómo CoT puede ayudar a los modelos a navegar por el espacio del conocimiento y resolver tareas complejas. Imagen autogenerada utilizando la generación de imágenes ChatGPT 4o con la siguiente instrucción "Imagina un agente de Modelo Lingüístico a través de un laberinto de problemas matemáticos".
Hay múltiples formas de incluir el CdT en nuestras indicaciones:
Múltiples marcos de trabajo pueden ayudarte a aplicar CoT y otras técnicas de Ingeniería de Pronósticos, pero LangChain es mi favorito. Si estás interesado en utilizar LangChain como parte de tus proyectos impulsados por LLM, el curso "Desarrollo de aplicaciones LLM con LangChain" es un punto de partida ideal.
La incitación a la cadena de pensamiento ofrece varias ventajas, sobre todo para mejorar el rendimiento y la fiabilidad de los modelos lingüísticos en tareas complejas.
Al descomponer un problema en pasos más pequeños y manejables, el modelo puede gestionar tareas complejas con mayor precisión. Los pasos intermedios proporcionan puntos de control donde pueden detectarse y corregirse posibles errores, lo que conduce a respuestas finales más precisas.
La razón por la que tareas como los problemas matemáticos, los rompecabezas lógicos o la respuesta a preguntas de varios saltos se benefician de este enfoque es porque ya requieren de forma natural múltiples pasos de razonamiento.
El proceso de razonamiento paso a paso es transparente, lo que permite a los usuarios comprender cómo ha llegado el modelo a su conclusión. Esta transparencia genera confianza en los resultados del modelo.
También puede ayudar en la depuración, ya que los usuarios pueden detectar más fácilmente dónde puede haberse equivocado el modelo en su razonamiento.
Por supuesto, como ocurre con cualquier técnica, siempre hay ciertos inconvenientes que merece la pena tener en cuenta:
Es importante tener en cuenta que la CoT es una técnica que depende del modelo. Por lo tanto, la eficacia de las indicaciones de CoT depende en gran medida de las capacidades del modelo lingüístico subyacente.
También puede ser difícil elaborar mensajes de CdT eficaces. Requiere un diseño cuidadoso para garantizar que las indicaciones guían al modelo correctamente a través del proceso de razonamiento. Actualizar y mantener avisos para distintos tipos de tareas y dominios puede llevar mucho tiempo y requerir un perfeccionamiento constante.
La ayuda de la TdC puede no ser tan eficaz en tareas que no tienen un proceso de razonamiento secuencial claro. Además,puede que no se generalice bien a tipos de problemas totalmente nuevos o inesperados sin formación o adaptación adicionales, por lo que es crucial mantener una base de conocimientos actualizada y unas indicaciones adecuadas.
Aunque las indicaciones de CoT aumentan la interpretabilidad al proporcionar explicaciones paso a paso, también pueden dar lugar a salidas más largas y prolijas, que no siempre son deseables para todas las aplicaciones.
En este artículo, hemos visto cómo la incitación a la Cadena de Pensamiento representa un avance significativo en la mejora de las capacidades de razonamiento de los Grandes Modelos del Lenguaje, junto con algunos ejemplos prácticos de su aplicación.
Ya sea mediante plantillas de avisos, avisos interactivos o bucles de retroalimentación, la idea que subyace en estos enfoques es guiar al modelo a través del proceso de razonamiento y explotar sus capacidades.
Además, hemos explorado técnicas potentes, como los avisos de un solo disparo y de pocos disparos, que mejoran aún más el rendimiento del modelo y pueden combinarse con CoT, junto con las ventajas y algunas limitaciones que no podemos pasar por alto.
Considera la posibilidad de probar las técnicas comentadas en este artículo para crear avisos más fiables y de mayor rendimiento, y tenlo en cuenta: ¡Una ingeniería rápida puede tener un gran impacto en tus resultados!
Puedes aprender más sobre ingeniería de avisos a través de los cursos de DataCamp, Comprender la ingeniería de avisos y ChatGPT Ingeniería de avisos para desarrolladores. También puedes consultar una guía aparte sobre la certificación de ingeniería rápida y averiguar cuáles son las mejores vías de aprendizaje para ti.
Los mejores cursos de DataCamp
Curso
Curso
Curso
blog
Stanislav Karzhev
9 min
blog
Stanislav Karzhev
12 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Zoumana Keita

