programa
Desarrollo de aplicaciones de IA
21 h
Esta nueva versión de OpenAI incluye tres modelos:
gpt-4o-mini-tts: Un modelo de texto a audio capaz de generar audio a partir de texto con varios tonos y voces. Una característica interesante de este modelo de texto a voz es que podemos guiar cómo suena la voz dando instrucciones de texto específicas. Esto aporta un alto nivel de personalización, permitiendo la creación de experiencias de voz únicas y a medida. Puedes probarlo en OpenAI.fm.gpt-4o-transcribe y gpt-4o-mini-transcribe: Dos modelos audio-texto diseñados para convertir el lenguaje hablado en texto escrito. Su función principal es proporcionar transcripciones de audio muy precisas y fiables. Estos modelos demuestran una tasa de error de palabra (WER) más baja, lo que significa que cometen menos errores al reconocer palabras habladas en comparación con las soluciones anteriores.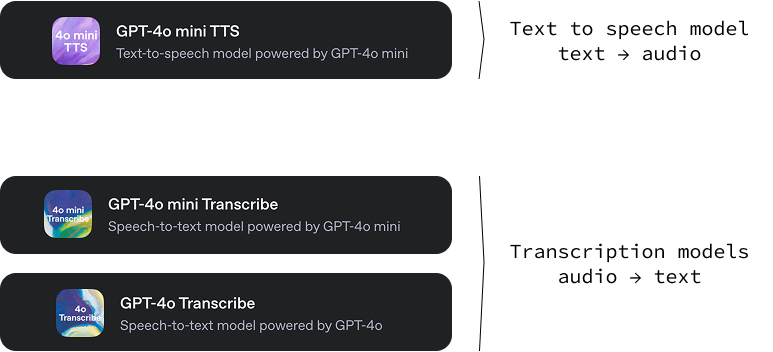
Estos nuevos modelos tienen los siguientes precios:

En este tutorial, te guiaré en la creación de un asistente de voz con IA directamente en tu terminal. Este asistente de voz imitará esencialmente un popular modelo de IA basado en texto, pero interactuará totalmente a través del lenguaje hablado. Imagina poder hablar directamente a tu ordenador, hacer cualquier pregunta que tengas y recibir una respuesta vocal casi al instante.
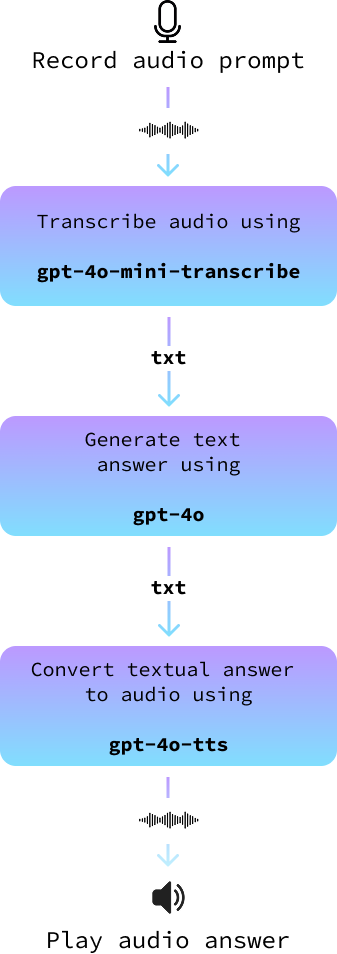
Nuestro proyecto utilizará una arquitectura sencilla pero eficaz. Empezaremos utilizando tu micrófono para captar tu mensaje hablado. Una vez grabada, convertiremos esta entrada de audio en texto con la ayuda de modelos avanzados de conversión de voz a texto.
A continuación, este texto se introduce en un gran modelo lingüístico para generar una respuesta adecuada. Por último, convertiremos la respuesta de texto en audio, para que el asistente te "diga" la respuesta. Cada paso de este proceso está diseñado para garantizar que nuestro asistente de voz sea preciso y atractivo.
Aunque OpenAI ofrece una API en tiempo real que puede mejorar las interacciones agilizando todo el proceso, optaremos por un enfoque diferente. La API en tiempo real, aunque es impresionante y perfecta para los desarrolladores que buscan integraciones rápidas, suele ser más costosa y ofrece menos flexibilidad.
Al elegir construir nuestro proyecto utilizando componentes separados para cada paso, obtenemos un mayor control sobre la personalización de nuestro asistente de IA. Este enfoque nos permite decidir los modelos que queremos utilizar, optimizando así para necesidades específicas, ya sea la precisión, la velocidad o la preferencia en el tono de respuesta. De este modo, nuestro asistente de voz se convierte no sólo en una potente herramienta, sino también en una herramienta muy personalizada, capaz de adaptarse a los requisitos únicos de cada proyecto.
Todo el código que desarrollamos aquí está disponible en este repositorio de GitHub.
Para empezar, primero configuraremos un nuevo entorno Anaconda llamado audio-demo. Los entornos de Anaconda nos permiten crear espacios aislados para cada proyecto en los que podemos instalar versiones específicas de paquetes sin conflictos. Ejecuta los siguientes comandos en tu interfaz de línea de comandos:
conda create -n audio-demo -y python=3.9
conda activate audio-demo
pip install openai
pip install numpy
pip install dotenv
pip install sounddevice
pip install scipyVeamos qué hace cada comando y cada paquete:
conda create -n audio-demo -y python=3.9: Este comando crea un nuevo entorno llamado audio-demo con la versión 3.9 de Python. La bandera -y acepta automáticamente la instalación de paquetes sin preguntar.conda activate audio-demo: Activa el entorno audio-demo recién creado, para que podamos trabajar en él.pip install openai: OpenAI es una biblioteca que facilita el acceso a los modelos y API de OpenAI.pip install numpy: NumPy es una biblioteca esencial para la computación numérica.pip install dotenv: Dotenv ayuda a cargar variables de entorno desde un archivo .env, facilitando y haciendo más segura la gestión de la configuración.pip install sounddevice: Sounddevice nos permite grabar y reproducir sonido mediante funciones sencillas, lo que es ideal para manejar la entrada y salida de audio en Python.pip install scipy: SciPy se basa en NumPy y proporciona funciones adicionales para la informática científica y técnica, como el procesamiento de señales. En nuestro caso, lo utilizaremos para almacenar el archivo de audio.Con nuestro entorno audio-demo configurado, estamos listos para empezar a trabajar en nuestro asistente de IA que puede procesar entradas de audio. Esta configuración estructurada nos ayuda a mantener un espacio de desarrollo limpio, asegurándonos de que todas las dependencias están en su sitio para nuestro proyecto.
Para utilizar la API de OpenAI, necesitamos una clave API. Ir a su página de clave API y genera una clave API haciendo clic en el botón "Generar nueva clave secreta". Copia la clave, crea un archivo llamado .env, y pégala allí con el siguiente formato:
OPENAI_API_KEY=<paste_your_api_key_here>Vamos a recorrer los pasos para crear un script en Python que utilice las capacidades de conversión de texto a audio de OpenAI, transformando el texto en voz con un toque personalizado. Escribimos nuestro código en un archivo llamado text_to_audio.py en la misma carpeta que el archivo .env..
En primer lugar, tenemos que importar las bibliotecas necesarias que compondrán nuestro script:
import asyncio
from openai import AsyncOpenAI
from openai.helpers import LocalAudioPlayer
from dotenv import load_dotenvVeamos rápidamente qué hace cada una de estas importaciones:
asyncio: Esta biblioteca es necesaria para escribir código asíncrono en Python, que es esencial para trabajar con APIs de streaming.AsyncOpenAI: Forma parte de la biblioteca OpenAI y proporciona herramientas para interactuar con las API de OpenAI de forma asíncrona.LocalAudioPlayer: Este ayudante de OpenAI nos permite reproducir audio localmente en nuestra máquina.load_dotenv: Carga variables de entorno del archivo .env, que es donde almacenamos información sensible como nuestras claves API.A continuación, cargamos nuestra clave API desde el archivo .env utilizando la función load_dotenv:
load_dotenv()Esto garantiza que nuestro script tenga acceso seguro a la clave API.
Creamos una instancia de AsyncOpenAI para empezar a interactuar con la API de OpenAI:
openai = AsyncOpenAI()Ahora definimos nuestra función principal, text_to_audio(), que utilizará la función de conversión de texto en audio de OpenAI para procesar la entrada y reproducir el audio resultante:
async def text_to_audio(text, tone_and_style_instructions):
async with openai.audio.speech.with_streaming_response.create(
model="gpt-4o-mini-tts",
voice="coral",
input=text,
instructions=tone_and_style_instructions,
response_format="pcm",
) as response:
await LocalAudioPlayer().play(response)Vamos a explicar rápidamente lo que hicimos arriba:
model y voice para controlar la síntesis del habla. El model utilizado es gpt-4o-mini-tts y la voz seleccionada es "coral".response_format está ajustado a "pcm", adecuado para el procesamiento de audio.LocalAudioPlayer reproduce la respuesta de audio generada por la API.Completamos el script con las siguientes líneas para asegurarnos de que la función text_to_audio() se ejecuta cuando ejecutamos el script:
if __name__ == "__main__":
asyncio.run(text_to_audio("Hello world!", "Enthusiastic voice."))Este bloque de código comprueba si el script es el módulo principal que se está ejecutando y ejecuta la función text_to_audio() utilizando asyncio.run() para manejar la lógica asíncrona.
Con estos pasos, nuestro script está listo para convertir la entrada de texto en voz utilizando el servicio de conversión de texto a audio de OpenAI. Esta configuración nos permite experimentar con diferentes entradas y estilos, dando vida al texto a través del sonido.
Podemos ejecutar el script utilizando el comando
python text_to_audio.pyPuedes encontrar el código completo aquí.
En esta sección, vamos a explorar cómo transcribir un archivo de audio a texto utilizando la herramienta de transcripción de audio de OpenAI. Nuestro script está diseñado para manejar archivos de audio de forma asíncrona para que el proceso sea eficaz y rápido. Implementaremos este script en un archivo llamado audio_to_text.py.
Las importaciones y la configuración inicial son las mismas que antes, salvo que aquí no necesitamos importar el LocalAudioPlayer. Así es como podemos escribir una función que transcriba un archivo de audio:
async def transcribe_audio(audio_filename = "audio.wav"):
audio_file = await asyncio.to_thread(open, audio_filename, "rb")
stream = await openai.audio.transcriptions.create(
model="gpt-4o-mini-transcribe",
file=audio_file,
response_format="text",
stream=True,
)
transcript = ""
async for event in stream:
if event.type == "transcript.text.delta":
print(event.delta, end="", flush=True)
transcript += event.delta
print()
audio_file.close()
return transcriptVamos a desglosar lo que ocurre aquí:
audio_file = await asyncio.to_thread(open, audio_filename, "rb"): Esta línea abre el archivo de audio en modo de lectura binario ("rb"). El método asyncio.to_thread() permite que esta operación de apertura de archivos se ejecute en un hilo independiente, evitando que bloquee otras partes del programa.stream = await openai.audio.transcriptions.create(...): Esta línea llama a la API de transcripción. model como gpt-4o-mini-transcribe, diseñado específicamente para tareas de transcripción.file contiene nuestro archivo de audio abierto.response_format="text" indica a la API que devuelva la transcripción como texto.stream=True se utiliza para transmitir la transcripción en tiempo real, lo que significa que en cuanto se procesa una parte del audio, se devuelve inmediatamente, acelerando la respuesta.async for event in stream: Inicia un bucle para leer los eventos del flujo de transcripción a medida que se producen.if event.type == "transcript.text.delta":: Comprueba cada tipo de evento y procésalo si es del tipo transcript.text.delta, que indica que una parte de la transcripción está lista.print(event.delta, end="", flush=True): Imprime la transcripción incremental a medida que esté disponible, garantizando que nuestra salida sea en tiempo real.audio_file.close(): Cuando terminemos la transcripción, es una buena práctica cerrar el archivo de audio para liberar recursos del sistema.Ejecutando la función main(), podemos convertir un archivo de audio en texto de forma eficaz y procesarlo en flujo para obtener una respuesta inmediata. Esta configuración es ideal para aplicaciones que necesitan una transcripción rápida o que implican archivos de audio largos.
Puedes probarlo colocando un archivo de audio en la misma carpeta que el script, sustituyendo audio.wav por el nombre de tu archivo de audio y ejecutando el comando:
python audio_to_text.pyPuedes encontrar el código completo aquí.
Como nuestro objetivo es crear un asistente de voz, necesitamos grabar la petición de audio del usuario en un archivo de audio.
Crearemos un nuevo archivo llamado record.py con una función llamada record_audio. Esta función captura el sonido del micrófono y lo guarda como un archivo de audio. No entraremos en muchos detalles sobre su funcionamiento porque no es el tema principal de este artículo:
import sounddevice as sd
import numpy as np
import scipy.io.wavfile as wavfile
SAMPLE_RATE = 44100 # Sample rate in Hz
def record_audio():
print("[INFO: Recording... Press <Enter> to stop]")
audio_data = [] # Initialize a list to store audio frames
def callback(indata, frames, time, status):
audio_data.append(indata.copy())
with sd.InputStream(samplerate=SAMPLE_RATE, channels=1, callback=callback, dtype='int16'):
input() # Wait for the user to press Enter to stop recording
print("[INFO: Recording complete]")
print()
audio_data = np.concatenate(audio_data) # Concatenate the list into a single array
filename = "output.wav"
wavfile.write(filename, SAMPLE_RATE, audio_data)
return audio_dataCuando llamemos a esta función, empezará a grabar desde el micrófono del usuario. Espera a que el usuario pulse "Intro" y luego guarda el audio en un archivo con el nombre de archivo dado.
Para probarlo, podemos combinar esta función con la función de transcripción anterior para transcribir un mensaje hablado por el usuario. Así es como podemos crear un nuevo archivo llamado record_and_transcribe.py para ponerlo en práctica:
import asyncio
from audio_to_text import transcribe_audio
from audio_recorder import record_audio
async def main():
record_audio("prompt.wav")
await transcribe_audio("prompt.wav")
if __name__ == "__main__":
asyncio.run(main())Puedes intentar ejecutarlo utilizando el comando python record_and_transcribe.py. El guión grabará lo que digas hasta que pulses "Intro" y luego transcribirá lo que has dicho.
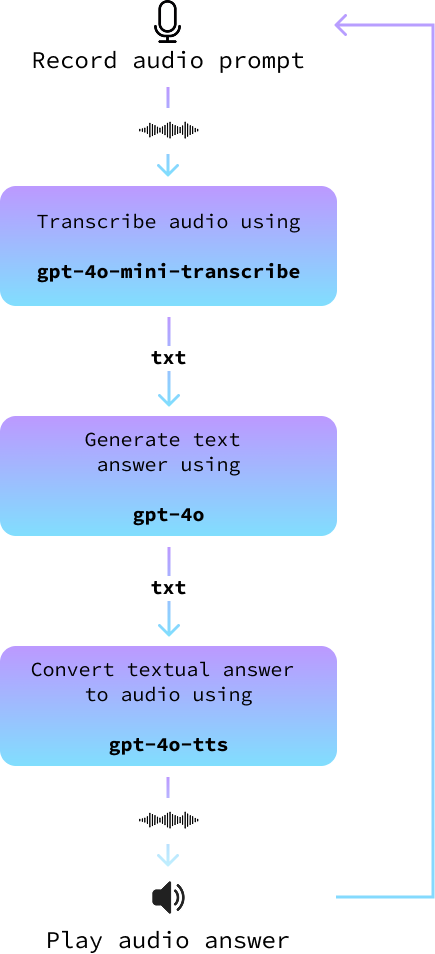
En esta sección, lo unimos todo para construir un asistente de audio. Lo implementamos en un nuevo archivo llamado audio_assistant.py siguiendo estos pasos:
record_audio().transcribe_audio().gpt-4o para generar una respuesta.text_to_audio().El siguiente diagrama lo ilustra:
Te animo a que intentes construirlo tú mismo antes de seguir leyendo.
En primer lugar, importamos las funciones que implementamos antes e inicializamos el cliente OpenAI.
# Import the functions we created
from text_to_audio import text_to_audio
from audio_to_text import transcribe_audio
from audio_recorder import record_audio
# Import other dependencies and initialize OpenAI
import asyncio
from openai import AsyncOpenAI
from dotenv import load_dotenv
load_dotenv()
openai = AsyncOpenAI()Entonces, necesitamos una función que genere la respuesta. Esto utiliza la API GPT normal de OpenAI con un modelo como gpt-4o o cualquier otro modelo de texto a texto. Si eres nuevo en esto, quizás quieras consultar este tutorial de la API GPT-4o.
Aquí tienes una implementación asíncrona de esta función:
async def get_answer(prompt):
stream = await openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt}
],
stream=True,
)
answer = ""
async for chunk in stream:
content = chunk.choices[0].delta.content
if content is not None:
answer += content
print(content, end="", flush=True)
print("\n\n")
return answerPara ejecutar el bucle principal, seguimos los pasos descritos anteriormente:
async def main(tone_and_style_instructions):
await text_to_audio("Hello, how can I help you today?", tone_and_style_instructions)
while True:
record_audio("prompt.wav")
prompt = await transcribe_audio("prompt.wav")
print()
answer = await get_answer(prompt)
await text_to_audio(answer, tone_and_style_instructions)Por último, ejecutamos el bucle principal cuando se ejecuta el script:
if __name__ == "__main__":
tone_and_style_instructions = "Enthusiastic voice."
asyncio.run(main(tone_and_style_instructions))Aquí tienes una demostración en acción:
Aprende IA con estos cursos
programa
Curso
Curso
blog
Abid Ali Awan
10 min
Tutorial
Kurtis Pykes
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita




