Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Diese neue Version von OpenAI umfasst drei Modelle:
gpt-4o-mini-tts: Ein Text-zu-Audio-Modell, das in der Lage ist, aus Text Audio mit verschiedenen Tönen und Stimmen zu erzeugen. Eine tolle Funktion dieses Text-to-Speech-Modells ist, dass wir den Klang der Stimme steuern können, indem wir bestimmte Textanweisungen geben. Dies ermöglicht ein hohes Maß an Individualisierung und damit die Schaffung einzigartiger und maßgeschneiderter Spracherlebnisse. Du kannst es ausprobieren auf OpenAI.fm.gpt-4o-transcribe und gpt-4o-mini-transcribe: Zwei Audio-zu-Text-Modelle, die für die Umwandlung von gesprochener Sprache in geschriebenen Text entwickelt wurden. Ihre Hauptaufgabe ist es, sehr genaue und zuverlässige Transkriptionen von Audiodaten zu erstellen. Diese Modelle weisen eine niedrigere Wortfehlerrate (WER) auf, d.h. sie machen weniger Fehler bei der Erkennung von gesprochenen Wörtern als bisherige Lösungen.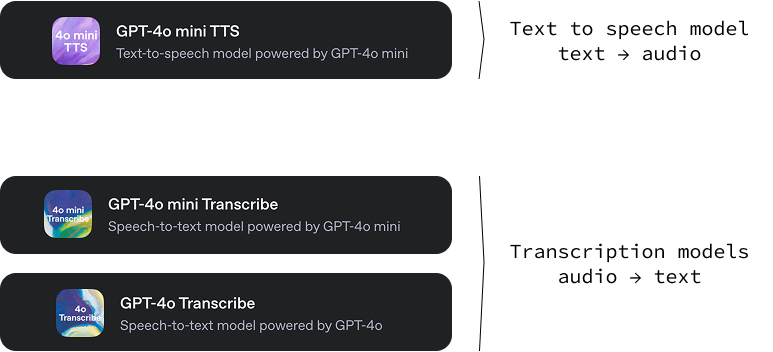
Die neuen Modelle haben die folgenden Preise:

In diesem Tutorial zeige ich dir, wie du einen KI-Sprachassistenten direkt in deinem Terminal erstellen kannst. Dieser Sprachassistent wird im Wesentlichen ein beliebtes textbasiertes KI-Modell imitieren, aber ausschließlich durch gesprochene Sprache interagieren. Stell dir vor, du könntest direkt mit deinem Computer sprechen, ihm eine Frage stellen und würdest fast sofort eine stimmliche Antwort erhalten.
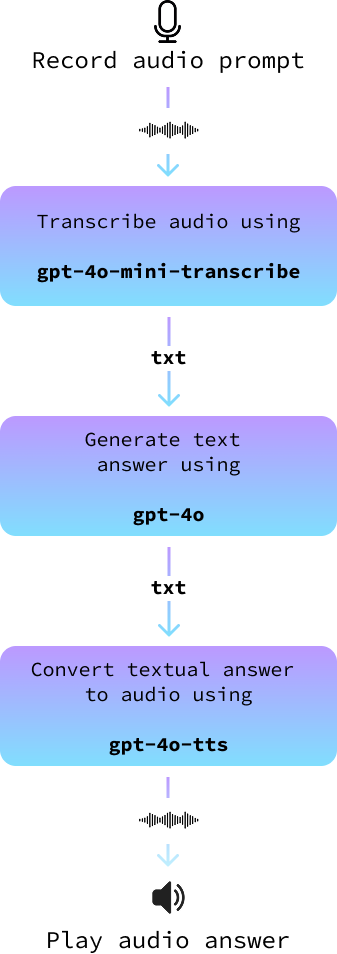
Unser Projekt wird eine einfache, aber effektive Architektur verwenden. Wir beginnen damit, dass du dein Mikrofon benutzt, um deine gesprochene Aufforderung aufzunehmen. Nach der Aufzeichnung wandeln wir diesen Audio-Input mit Hilfe von fortschrittlichen Sprache-zu-Text-Modellen in Text um.
Dieser Text wird dann in ein großes Sprachmodell eingespeist, um eine passende Antwort zu generieren. Zum Schluss wandeln wir die Textantwort wieder in Audio um, damit der Assistent die Antwort zu dir "sprechen" kann. Jeder Schritt dieses Prozesses soll sicherstellen, dass unser Sprachassistent sowohl genau als auch ansprechend ist.
OpenAI bietet zwar eine eigene Echtzeit-API anbietet, die Interaktionen verbessern kann, indem sie den gesamten Prozess rationalisiert, werden wir uns für einen anderen Ansatz entscheiden. Die Realtime API ist zwar beeindruckend und perfekt für Entwickler, die schnelle Integrationen suchen, aber sie ist oft teurer und bietet weniger Flexibilität.
Wenn wir uns dafür entscheiden, unser Projekt mit separaten Komponenten für jeden Schritt aufzubauen, haben wir mehr Kontrolle über die Anpassung unseres KI-Assistenten. Auf diese Weise können wir entscheiden, welche Modelle wir verwenden wollen, und sie für bestimmte Bedürfnisse optimieren, sei es Genauigkeit, Geschwindigkeit oder der bevorzugte Tonfall. Auf diese Weise wird unser Sprachassistent nicht nur zu einem leistungsstarken, sondern auch zu einem maßgeschneiderten Werkzeug, das sich an einzigartige Projektanforderungen anpassen lässt.
Der gesamte Code, den wir hier entwickeln, ist verfügbar in diesem GitHub-Repository.
Um loszulegen, richten wir zunächst eine neue Anaconda-Umgebung namens audio-demo ein. Die Umgebungen von Anaconda ermöglichen es uns, für jedes Projekt isolierte Bereiche zu schaffen, in denen wir bestimmte Versionen von Paketen ohne Konflikte installieren können. Führe die folgenden Befehle in deiner Befehlszeilenschnittstelle aus:
conda create -n audio-demo -y python=3.9
conda activate audio-demo
pip install openai
pip install numpy
pip install dotenv
pip install sounddevice
pip install scipySchauen wir uns an, was die einzelnen Befehle und Pakete bewirken:
conda create -n audio-demo -y python=3.9: Dieser Befehl erstellt eine neue Umgebung namens audio-demo mit Python Version 3.9. Die -y Flagge stimmt den Paketinstallationen automatisch zu, ohne dass du gefragt wirst.conda activate audio-demo: Aktiviert die neu erstellte Umgebung audio-demo, damit wir darin arbeiten können.pip install openai: OpenAI ist eine Bibliothek, die einen einfachen Zugang zu den Modellen und APIs von OpenAI bietet.pip install numpy: NumPy ist eine wichtige Bibliothek für numerische Berechnungen.pip install dotenv: Dotenv hilft, Umgebungsvariablen aus einer .env Datei zu laden, was die Konfigurationsverwaltung einfacher und sicherer macht.pip install sounddevice: Mit Sounddevice können wir mit einfachen Funktionen Töne aufnehmen und abspielen, was ideal für die Handhabung von Audioeingabe und -ausgabe in Python ist.pip install scipy: SciPy baut auf NumPy auf und bietet zusätzliche Funktionen für wissenschaftliche und technische Berechnungen, wie z.B. Signalverarbeitung. In unserem Fall werden wir sie benutzen, um die Audiodatei zu speichern.Nachdem wir unsere audio-demo Umgebung eingerichtet haben, können wir mit der Arbeit an unserem KI-Assistenten beginnen, der Audioeingaben verarbeiten kann. Dieses strukturierte Setup hilft uns dabei, einen sauberen Entwicklungsraum zu erhalten und sicherzustellen, dass alle Abhängigkeiten für unser Projekt vorhanden sind.
Um die OpenAI API zu nutzen, brauchen wir einen API-Schlüssel. Gehe zu ihrer API-Schlüssel-Seite und generiere einen API-Schlüssel, indem du auf die Schaltfläche "Neuen geheimen Schlüssel generieren" klickst. Kopiere den Schlüssel, erstelle eine Datei mit dem Namen .env und füge ihn dort in folgendem Format ein:
OPENAI_API_KEY=<paste_your_api_key_here>Gehen wir die Schritte durch, um ein Python-Skript zu erstellen, das die Text-zu-Audio-Funktionen von OpenAI nutzt und Text in Sprache mit einer persönlichen Note umwandelt. Wir schreiben unseren Code in eine Datei namens text_to_audio.py im selben Ordner wie die Datei .env..
Zuerst müssen wir die notwendigen Bibliotheken importieren, aus denen unser Skript bestehen wird:
import asyncio
from openai import AsyncOpenAI
from openai.helpers import LocalAudioPlayer
from dotenv import load_dotenvSchauen wir uns kurz an, was jeder dieser Importe bewirkt:
asyncio: Diese Bibliothek ist erforderlich, um asynchronen Code in Python zu schreiben, der für die Arbeit mit Streaming-APIs unerlässlich ist.AsyncOpenAI: Sie ist Teil der OpenAI-Bibliothek und bietet Werkzeuge, um mit den APIs von OpenAI asynchron zu interagieren.LocalAudioPlayer: Dieser Helper von OpenAI ermöglicht es uns, Audio lokal auf unserem Rechner abzuspielen.load_dotenv: Lädt Umgebungsvariablen aus der Datei .env, in der wir sensible Informationen wie unsere API-Schlüssel speichern.Als Nächstes laden wir unseren API-Schlüssel aus der Datei .env mit der Funktion load_dotenv:
load_dotenv()Dadurch wird sichergestellt, dass unser Skript sicheren Zugriff auf den API-Schlüssel hat.
Wir erstellen eine Instanz von AsyncOpenAI, um mit der OpenAI-API zu interagieren:
openai = AsyncOpenAI()Jetzt definieren wir unsere Hauptfunktion text_to_audio(), die die Text-zu-Audio-Funktion von OpenAI nutzt, um die Eingabe zu verarbeiten und das resultierende Audio abzuspielen:
async def text_to_audio(text, tone_and_style_instructions):
async with openai.audio.speech.with_streaming_response.create(
model="gpt-4o-mini-tts",
voice="coral",
input=text,
instructions=tone_and_style_instructions,
response_format="pcm",
) as response:
await LocalAudioPlayer().play(response)Lass uns kurz erklären, was wir oben gemacht haben:
model und voice an, um die Sprachsynthese zu steuern. Die verwendete model ist gpt-4o-mini-tts und die gewählte Stimme ist "Koralle".response_format ist auf "pcm" eingestellt, geeignet für die Audioverarbeitung.LocalAudioPlayer spielt dann die von der API erzeugte Audioantwort ab.Wir ergänzen das Skript mit den folgenden Zeilen, um sicherzustellen, dass die Funktion text_to_audio() ausgeführt wird, wenn wir das Skript ausführen:
if __name__ == "__main__":
asyncio.run(text_to_audio("Hello world!", "Enthusiastic voice."))Dieser Codeblock prüft, ob das Skript das Hauptmodul ist, das gerade ausgeführt wird, und führt die Funktion text_to_audio() aus, indem er asyncio.run() verwendet, um die asynchrone Logik zu steuern.
Mit diesen Schritten ist unser Skript bereit, Texteingaben mit dem Text-to-Audio-Service von OpenAI in Sprache umzuwandeln. Auf diese Weise können wir mit verschiedenen Inputs und Stilen experimentieren und den Text durch Klang zum Leben erwecken.
Wir können das Skript mit dem Befehl ausführen:
python text_to_audio.pyDen vollständigen Code findest du hier.
In diesem Abschnitt erfahren wir, wie du eine Audiodatei mit dem Audiotranskriptionstool von OpenAI in Text umwandeln kannst. Unser Skript ist darauf ausgelegt, Audiodateien asynchron zu verarbeiten, um den Prozess effizient und schnell zu machen. Wir werden dieses Skript in einer Datei namens audio_to_text.py implementieren.
Die Importe und die Ersteinrichtung sind dieselben wie zuvor, nur dass wir hier die LocalAudioPlayer nicht importieren müssen. So können wir eine Funktion schreiben, die eine Audiodatei transkribiert:
async def transcribe_audio(audio_filename = "audio.wav"):
audio_file = await asyncio.to_thread(open, audio_filename, "rb")
stream = await openai.audio.transcriptions.create(
model="gpt-4o-mini-transcribe",
file=audio_file,
response_format="text",
stream=True,
)
transcript = ""
async for event in stream:
if event.type == "transcript.text.delta":
print(event.delta, end="", flush=True)
transcript += event.delta
print()
audio_file.close()
return transcriptSchauen wir uns an, was hier passiert:
audio_file = await asyncio.to_thread(open, audio_filename, "rb"): Diese Zeile öffnet die Audiodatei im binären Lesemodus ("rb"). Die Methode asyncio.to_thread() ermöglicht es, dass dieser Datei-Öffnungsvorgang in einem separaten Thread abläuft, so dass er andere Teile des Programms nicht blockieren kann.stream = await openai.audio.transcriptions.create(...): Diese Zeile ruft die Transkriptions-API auf. model als gpt-4o-mini-transcribe an, der speziell für Transkriptionsaufgaben entwickelt wurde.file enthält unsere geöffnete Audiodatei.response_format="text" sagt der API, dass sie die Transkription als Text zurückgeben soll.stream=True wird verwendet, um die Transkription in Echtzeit zu streamen, d.h. sobald ein Teil der Audiodaten verarbeitet wird, wird er sofort zurückgegeben, was die Antwort beschleunigt.async for event in stream: Startet eine Schleife, um Ereignisse aus dem Transkriptionsstrom zu lesen, sobald sie auftreten.if event.type == "transcript.text.delta":: Prüft jeden Ereignistyp und verarbeitet ihn, wenn er vom Typ transcript.text.delta ist, was bedeutet, dass ein Teil der Transkription fertig ist.print(event.delta, end="", flush=True): Druckt die inkrementelle Transkription aus, sobald sie verfügbar ist, um sicherzustellen, dass unsere Ausgabe in Echtzeit erfolgt.audio_file.close(): Nachdem wir die Transkription abgeschlossen haben, empfiehlt es sich, die Audiodatei zu schließen, um Systemressourcen freizugeben.Mit der Funktion main() können wir eine Audiodatei effizient in Text umwandeln und als Stream verarbeiten, um sofortiges Feedback zu erhalten. Diese Einstellung ist ideal für Anwendungen, die eine schnelle Transkription erfordern oder lange Audiodateien beinhalten.
Du kannst es ausprobieren, indem du eine Audiodatei in denselben Ordner wie das Skript legst, audio.wav durch den Namen deiner Audiodatei ersetzt und den Befehl ausführst:
python audio_to_text.pyDen vollständigen Code findest du hier.
Da unser Ziel darin besteht, einen Sprachassistenten zu entwickeln, müssen wir die Audioeingabe des Benutzers in einer Audiodatei aufzeichnen.
Wir erstellen eine neue Datei namens record.py mit einer Funktion namens record_audio. Diese Funktion nimmt den Ton vom Mikrofon auf und speichert ihn als Audiodatei. Wir werden nicht näher darauf eingehen, wie es funktioniert, weil das nicht der Schwerpunkt dieses Artikels ist:
import sounddevice as sd
import numpy as np
import scipy.io.wavfile as wavfile
SAMPLE_RATE = 44100 # Sample rate in Hz
def record_audio():
print("[INFO: Recording... Press <Enter> to stop]")
audio_data = [] # Initialize a list to store audio frames
def callback(indata, frames, time, status):
audio_data.append(indata.copy())
with sd.InputStream(samplerate=SAMPLE_RATE, channels=1, callback=callback, dtype='int16'):
input() # Wait for the user to press Enter to stop recording
print("[INFO: Recording complete]")
print()
audio_data = np.concatenate(audio_data) # Concatenate the list into a single array
filename = "output.wav"
wavfile.write(filename, SAMPLE_RATE, audio_data)
return audio_dataWenn wir diese Funktion aufrufen, beginnt sie mit der Aufnahme vom Mikrofon des Nutzers. Es wartet, bis der Benutzer "Enter" drückt und speichert dann das Audio in einer Datei mit dem angegebenen Dateinamen.
Um dies zu testen, können wir diese Funktion mit der obigen Transkriptionsfunktion kombinieren, um eine vom Nutzer gesprochene Nachricht zu transkribieren. So können wir eine neue Datei mit dem Namen record_and_transcribe.py erstellen, um dies umzusetzen:
import asyncio
from audio_to_text import transcribe_audio
from audio_recorder import record_audio
async def main():
record_audio("prompt.wav")
await transcribe_audio("prompt.wav")
if __name__ == "__main__":
asyncio.run(main())Du kannst versuchen, ihn mit dem Befehl python record_and_transcribe.py auszuführen. Das Skript zeichnet auf, was du sagst, bis du "Enter" drückst, und schreibt dann ab, was du gesagt hast.
In diesem Abschnitt fügen wir alles zusammen, um einen Audioassistenten zu bauen. Wir implementieren sie in einer neuen Datei namens audio_assistant.py, indem wir die folgenden Schritte ausführen:
record_audio() auf.transcribe_audio() in Text um.gpt-4o, um eine Antwort zu generieren.text_to_audio() in Audio um.Das folgende Diagramm veranschaulicht dies:
Ich möchte dich ermutigen, es selbst zu versuchen, bevor du weiterliest.
Zuerst importieren wir die Funktionen, die wir zuvor implementiert haben, und initialisieren den OpenAI-Client.
# Import the functions we created
from text_to_audio import text_to_audio
from audio_to_text import transcribe_audio
from audio_recorder import record_audio
# Import other dependencies and initialize OpenAI
import asyncio
from openai import AsyncOpenAI
from dotenv import load_dotenv
load_dotenv()
openai = AsyncOpenAI()Dann brauchen wir eine Funktion, um die Antwort zu generieren. Dazu wird die normale OpenAI GPT API mit einem Modell wie gpt-4o oder einem anderen Text-zu-Text-Modell verwendet. Wenn du neu in diesem Bereich bist, solltest du dir dieses GPT-4o API-Anleitung.
Hier ist eine asynchrone Implementierung dieser Funktion:
async def get_answer(prompt):
stream = await openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt}
],
stream=True,
)
answer = ""
async for chunk in stream:
content = chunk.choices[0].delta.content
if content is not None:
answer += content
print(content, end="", flush=True)
print("\n\n")
return answerUm die Hauptschleife zu implementieren, folgen wir den oben beschriebenen Schritten:
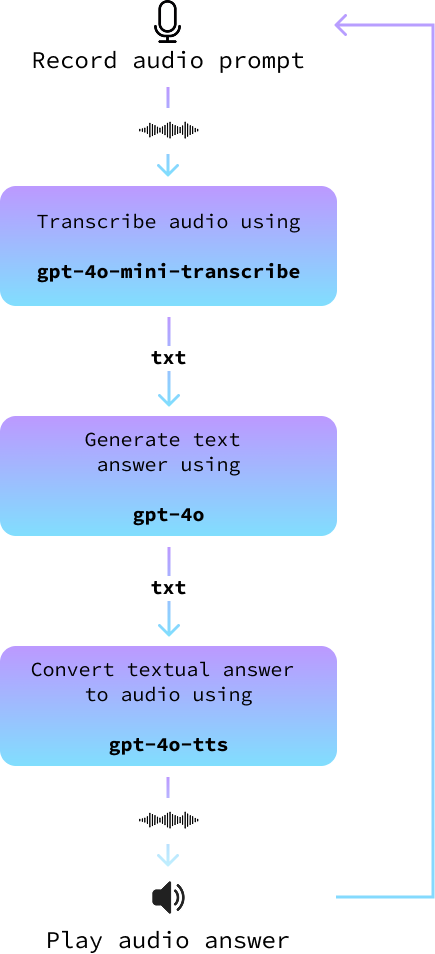
async def main(tone_and_style_instructions):
await text_to_audio("Hello, how can I help you today?", tone_and_style_instructions)
while True:
record_audio("prompt.wav")
prompt = await transcribe_audio("prompt.wav")
print()
answer = await get_answer(prompt)
await text_to_audio(answer, tone_and_style_instructions)Schließlich führen wir die Hauptschleife aus, wenn das Skript ausgeführt wird:
if __name__ == "__main__":
tone_and_style_instructions = "Enthusiastic voice."
asyncio.run(main(tone_and_style_instructions))Hier ist eine Demo, die es in Aktion zeigt:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
