Cursus
Développer des applications d'IA
21 h
Cette nouvelle version d'OpenAI comprend trois modèles :
gpt-4o-mini-tts: Un modèle texte-audio capable de générer de l'audio à partir d'un texte avec différents tons et voix. Une caractéristique intéressante de ce modèle de synthèse vocale est qu'il est possible d'orienter le son de la voix en donnant des instructions textuelles spécifiques. Cela apporte un haut niveau de personnalisation, permettant la création d'expériences vocales uniques et personnalisées. Vous pouvez l'essayer sur OpenAI.fm.gpt-4o-transcribe et gpt-4o-mini-transcribe: Deux modèles audio/texte conçus pour convertir la langue parlée en texte écrit. Leur fonction principale est de fournir des transcriptions audio très précises et fiables. Ces modèles présentent un taux d'erreur sur les mots (WER) plus faible, ce qui signifie qu'ils commettent moins d'erreurs dans la reconnaissance des mots parlés que les solutions précédentes.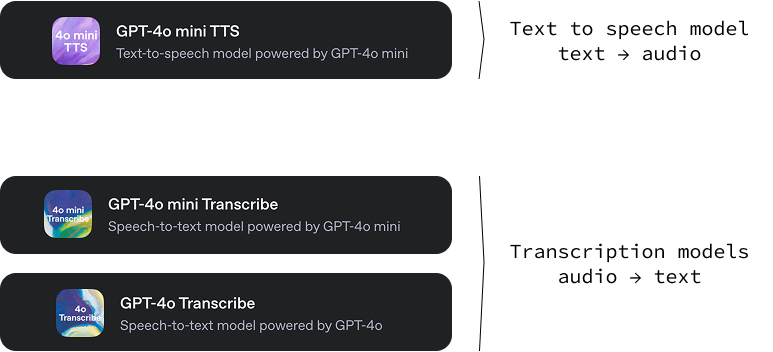
Ces nouveaux modèles sont proposés aux prix suivants :

Dans ce tutoriel, je vous guiderai dans la création d'un assistant vocal directement dans votre terminal. Cet assistant vocal imitera essentiellement un modèle d'intelligence artificielle basé sur le texte, mais interagira entièrement par le biais du langage parlé. Imaginez que vous puissiez parler directement à votre ordinateur, poser n'importe quelle question et recevoir une réponse vocale presque instantanément.
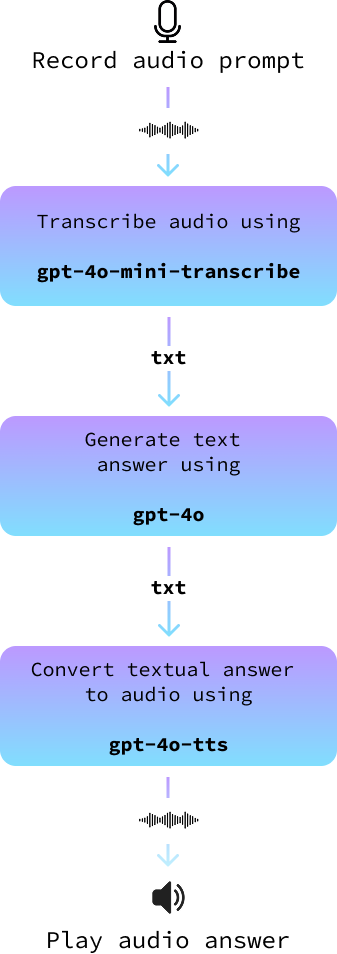
Notre projet utilisera une architecture simple mais efficace. Nous commencerons par utiliser votre microphone pour enregistrer votre message oral. Une fois enregistrée, cette entrée audio sera convertie en texte à l'aide de modèles avancés de conversion de la parole en texte.
Ce texte est ensuite introduit dans un grand modèle linguistique afin de générer une réponse appropriée. Enfin, nous convertissons la réponse textuelle en réponse audio, ce qui permet à l'assistant de "prononcer" la réponse. Chaque étape de ce processus est conçue pour garantir que notre assistant vocal est à la fois précis et attrayant.
Bien qu'OpenAI propose une API en temps réel dédiée qui peut améliorer les interactions en rationalisant l'ensemble du processus, nous opterons pour une approche différente. L'API en temps réel, bien qu'impressionnante et parfaite pour les développeurs à la recherche d'intégrations rapides, est souvent plus coûteuse et offre moins de flexibilité.
En choisissant de construire notre projet en utilisant des composants distincts pour chaque étape, nous avons un plus grand contrôle sur la personnalisation de notre assistant d'intelligence artificielle. Cette approche nous permet de choisir les modèles que nous voulons utiliser, optimisant ainsi nos besoins spécifiques, qu'il s'agisse de la précision, de la rapidité ou de la préférence dans le ton de la réponse. Ainsi, notre assistant vocal devient non seulement un outil puissant, mais aussi un outil hautement personnalisé, capable de répondre aux exigences d'un projet unique.
Tout le code que nous développons ici est disponible dans ce dépôt GitHub.
Pour commencer, nous allons d'abord mettre en place un nouvel environnement Anaconda nommé audio-demo. Les environnements d'Anaconda nous permettent de créer des espaces isolés pour chaque projet où nous pouvons installer des versions spécifiques de paquets sans conflits. Exécutez les commandes suivantes dans votre interface de ligne de commande :
conda create -n audio-demo -y python=3.9
conda activate audio-demo
pip install openai
pip install numpy
pip install dotenv
pip install sounddevice
pip install scipyVoyons ce que font chaque commande et chaque paquet :
conda create -n audio-demo -y python=3.9: Cette commande crée un nouvel environnement appelé audio-demo avec Python version 3.9. L'option -y permet d'accepter automatiquement l'installation des paquets sans y être invité.conda activate audio-demo: Active l'environnement audio-demo nouvellement créé, afin que nous puissions y travailler.pip install openai: OpenAI est une bibliothèque qui permet d'accéder facilement aux modèles et aux API d'OpenAI.pip install numpy: NumPy est une bibliothèque essentielle pour le calcul numérique.pip install dotenv: Dotenv permet de charger des variables d'environnement à partir d'un fichier .env, ce qui rend la gestion de la configuration plus facile et plus sûre.pip install sounddevice: Sounddevice nous permet d'enregistrer et de jouer du son à l'aide de fonctions simples, ce qui est idéal pour gérer l'entrée et la sortie audio dans Python.pip install scipy: SciPy s'appuie sur NumPy et offre des fonctionnalités supplémentaires pour le calcul scientifique et technique, comme le traitement des signaux. Dans notre cas, nous l'utiliserons pour stocker le fichier audio.Une fois notre environnement audio-demo mis en place, nous sommes prêts à travailler sur notre assistant d'intelligence artificielle capable de traiter les entrées audio. Cette configuration structurée nous aide à maintenir un espace de développement propre, en veillant à ce que toutes les dépendances soient en place pour notre projet.
Pour utiliser l'API OpenAI, nous avons besoin d'une clé API. Allez sur la page leur page de clé API et générez une clé API en cliquant sur le bouton "Generate new secret key". Copiez la clé, créez un fichier nommé .env, et collez-la avec le format suivant :
OPENAI_API_KEY=<paste_your_api_key_here>Découvrons les étapes pour créer un script Python qui utilise les capacités text-to-audio d'OpenAI, transformant le texte en parole avec une touche personnalisée. Nous écrivons notre code dans un fichier nommé text_to_audio.py dans le même dossier que le fichier .env..
Tout d'abord, nous devons importer les bibliothèques nécessaires à notre script :
import asyncio
from openai import AsyncOpenAI
from openai.helpers import LocalAudioPlayer
from dotenv import load_dotenvVoyons rapidement ce que fait chacune de ces importations :
asyncio: Cette bibliothèque est nécessaire pour écrire du code asynchrone en Python, ce qui est essentiel pour travailler avec des API de streaming.AsyncOpenAI: Une partie de la bibliothèque OpenAI, qui fournit des outils pour interagir avec les API d'OpenAI de manière asynchrone.LocalAudioPlayer: Cette aide d'OpenAI nous permet de jouer de l'audio localement sur notre machine.load_dotenv: Charge les variables d'environnement à partir du fichier .env, qui est l'endroit où nous stockons des informations sensibles telles que nos clés d'API.Ensuite, nous chargeons notre clé API à partir du fichier .env à l'aide de la fonction load_dotenv:
load_dotenv()Cela garantit que notre script dispose d'un accès sécurisé à la clé API.
Nous créons une instance de AsyncOpenAI pour commencer à interagir avec l'API OpenAI :
openai = AsyncOpenAI()Nous définissons maintenant notre fonction principale, text_to_audio(), qui utilisera la fonction de conversion de texte en audio d'OpenAI pour traiter l'entrée et lire l'audio qui en résulte :
async def text_to_audio(text, tone_and_style_instructions):
async with openai.audio.speech.with_streaming_response.create(
model="gpt-4o-mini-tts",
voice="coral",
input=text,
instructions=tone_and_style_instructions,
response_format="pcm",
) as response:
await LocalAudioPlayer().play(response)Expliquons rapidement ce que nous avons fait ci-dessus :
model et voice pour contrôler la synthèse vocale. Le site model utilisé est gpt-4o-mini-tts et la voix sélectionnée est "coral".response_format est réglée sur "pcm", ce qui permet d'effectuer un traitement audio.LocalAudioPlayer diffuse ensuite la réponse audio générée par l'API.Nous complétons le script avec les lignes suivantes pour nous assurer que la fonction text_to_audio() s'exécute lorsque nous exécutons le script :
if __name__ == "__main__":
asyncio.run(text_to_audio("Hello world!", "Enthusiastic voice."))Ce bloc de code vérifie si le script est le module principal en cours d'exécution et exécute la fonction text_to_audio() en utilisant asyncio.run() pour gérer la logique asynchrone.
Avec ces étapes, notre script est prêt à convertir le texte saisi en parole à l'aide du service de conversion de texte en audio d'OpenAI. Cette configuration nous permet d'expérimenter différentes entrées et différents styles, en donnant vie au texte par le son.
Nous pouvons exécuter le script à l'aide de la commande :
python text_to_audio.pyLe code complet est disponible ici.
Dans cette section, nous allons voir comment transcrire un fichier audio en texte à l'aide de l'outil de transcription audio d'OpenAI. Notre script est conçu pour traiter les fichiers audio de manière asynchrone afin de rendre le processus efficace et rapide. Nous implémenterons ce script dans un fichier nommé audio_to_text.py.
Les importations et la configuration initiale sont les mêmes que précédemment, sauf que nous n'avons pas besoin d'importer le site LocalAudioPlayer ici. Voici comment nous pouvons écrire une fonction qui transcrit un fichier audio :
async def transcribe_audio(audio_filename = "audio.wav"):
audio_file = await asyncio.to_thread(open, audio_filename, "rb")
stream = await openai.audio.transcriptions.create(
model="gpt-4o-mini-transcribe",
file=audio_file,
response_format="text",
stream=True,
)
transcript = ""
async for event in stream:
if event.type == "transcript.text.delta":
print(event.delta, end="", flush=True)
transcript += event.delta
print()
audio_file.close()
return transcriptVoyons ce qui se passe ici :
audio_file = await asyncio.to_thread(open, audio_filename, "rb"): Cette ligne ouvre le fichier audio en mode lecture binaire ("rb"). La méthode asyncio.to_thread() permet à cette opération d'ouverture de fichier de s'exécuter dans un thread séparé, ce qui l'empêche de bloquer d'autres parties du programme.stream = await openai.audio.transcriptions.create(...): Cette ligne appelle l'API de transcription. model comme gpt-4o-mini-transcribe, conçu spécifiquement pour les tâches de transcription.file contient notre fichier audio ouvert.response_format="text" indique à l'API de renvoyer la transcription sous forme de texte.stream=True est utilisé pour diffuser la transcription en temps réel, ce qui signifie que dès qu'une partie de l'audio est traitée, elle est immédiatement renvoyée, ce qui accélère la réponse.async for event in stream: Lance une boucle pour lire les événements du flux de transcription au fur et à mesure qu'ils se produisent.if event.type == "transcript.text.delta":: Vérifie chaque type d'événement et le traite s'il est de type transcript.text.delta, ce qui indique qu'une partie de la transcription est prête.print(event.delta, end="", flush=True): Imprime la transcription incrémentale au fur et à mesure qu'elle est disponible, garantissant ainsi une production en temps réel.audio_file.close(): Une fois la transcription terminée, il est conseillé de fermer le fichier audio afin de libérer les ressources du système.En exécutant la fonction main(), nous pouvons convertir efficacement un fichier audio en texte et le traiter en continu pour obtenir un retour d'information immédiat. Cette configuration est idéale pour les applications nécessitant une transcription rapide ou impliquant de longs fichiers audio.
Vous pouvez l'essayer en plaçant un fichier audio dans le même dossier que le script, en remplaçant audio.wav par le nom de votre fichier audio et en exécutant la commande :
python audio_to_text.pyLe code complet est disponible ici.
Notre objectif étant de créer un assistant vocal, nous devons enregistrer l'invite audio de l'utilisateur dans un fichier audio.
Nous allons créer un nouveau fichier nommé record.py avec une fonction appelée record_audio. Cette fonction permet de capturer le son du microphone et de l'enregistrer sous forme de fichier audio. Nous n'entrerons pas dans les détails de son fonctionnement, car ce n'est pas l'objet principal de cet article :
import sounddevice as sd
import numpy as np
import scipy.io.wavfile as wavfile
SAMPLE_RATE = 44100 # Sample rate in Hz
def record_audio():
print("[INFO: Recording... Press <Enter> to stop]")
audio_data = [] # Initialize a list to store audio frames
def callback(indata, frames, time, status):
audio_data.append(indata.copy())
with sd.InputStream(samplerate=SAMPLE_RATE, channels=1, callback=callback, dtype='int16'):
input() # Wait for the user to press Enter to stop recording
print("[INFO: Recording complete]")
print()
audio_data = np.concatenate(audio_data) # Concatenate the list into a single array
filename = "output.wav"
wavfile.write(filename, SAMPLE_RATE, audio_data)
return audio_dataLorsque nous appelons cette fonction, elle commence à enregistrer à partir du microphone de l'utilisateur. Il attend que l'utilisateur appuie sur la touche "Entrée", puis enregistre l'audio dans un fichier dont le nom est indiqué.
Pour tester cela, nous pouvons combiner cette fonction avec la fonction de transcription ci-dessus pour transcrire un message prononcé par l'utilisateur. Voici comment nous pouvons créer un nouveau fichier nommé record_and_transcribe.py pour mettre cela en œuvre :
import asyncio
from audio_to_text import transcribe_audio
from audio_recorder import record_audio
async def main():
record_audio("prompt.wav")
await transcribe_audio("prompt.wav")
if __name__ == "__main__":
asyncio.run(main())Vous pouvez essayer de l'exécuter à l'aide de la commande python record_and_transcribe.py. Le script enregistre ce que vous dites jusqu'à ce que vous appuyiez sur "Entrée", puis transcrit ce que vous avez dit.
Dans cette section, nous rassemblons tous ces éléments pour créer un assistant audio. Nous le mettons en œuvre dans un nouveau fichier appelé audio_assistant.py en suivant les étapes suivantes :
record_audio().transcribe_audio().gpt-4o pour générer une réponse.text_to_audio().Le diagramme suivant illustre cette situation :
Je vous encourage à essayer de le construire vous-même avant de poursuivre votre lecture.
Tout d'abord, nous importons les fonctions que nous avons implémentées précédemment et nous initialisons le client OpenAI.
# Import the functions we created
from text_to_audio import text_to_audio
from audio_to_text import transcribe_audio
from audio_recorder import record_audio
# Import other dependencies and initialize OpenAI
import asyncio
from openai import AsyncOpenAI
from dotenv import load_dotenv
load_dotenv()
openai = AsyncOpenAI()Ensuite, nous avons besoin d'une fonction pour générer la réponse. Cela utilise l'API GPT normale d'OpenAI avec un modèle comme gpt-4o ou tout autre modèle texte-à-texte. Si vous êtes novice en la matière, vous pouvez consulter ce qui suit Tutoriel sur l'API GPT-4o.
Voici une implémentation asynchrone de cette fonction :
async def get_answer(prompt):
stream = await openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt}
],
stream=True,
)
answer = ""
async for chunk in stream:
content = chunk.choices[0].delta.content
if content is not None:
answer += content
print(content, end="", flush=True)
print("\n\n")
return answerPour mettre en œuvre la boucle principale, nous suivons les étapes décrites ci-dessus :
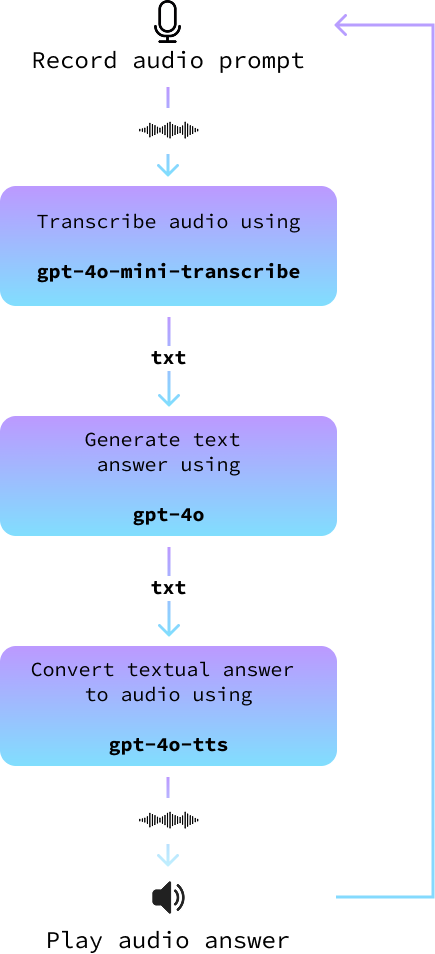
async def main(tone_and_style_instructions):
await text_to_audio("Hello, how can I help you today?", tone_and_style_instructions)
while True:
record_audio("prompt.wav")
prompt = await transcribe_audio("prompt.wav")
print()
answer = await get_answer(prompt)
await text_to_audio(answer, tone_and_style_instructions)Enfin, nous exécutons la boucle principale lorsque le script est exécuté :
if __name__ == "__main__":
tone_and_style_instructions = "Enthusiastic voice."
asyncio.run(main(tone_and_style_instructions))Voici une démonstration en action :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min