Programa
Desenvolvimento de aplicativos de IA
21 h
Essa nova versão da OpenAI inclui três modelos:
gpt-4o-mini-tts: Um modelo de texto para áudio capaz de gerar áudio a partir de texto com vários tons e vozes. Um recurso interessante desse modelo de conversão de texto em fala é que podemos orientar o som da voz fornecendo instruções de texto específicas. Isso proporciona um alto nível de personalização, permitindo a criação de experiências de voz exclusivas e personalizadas. Você pode experimentá-lo em OpenAI.fm.gpt-4o-transcribe e gpt-4o-mini-transcribe: Dois modelos de áudio para texto projetados para converter a linguagem falada em texto escrito. Sua principal função é fornecer transcrições de áudio altamente precisas e confiáveis. Esses modelos demonstram uma taxa de erro de palavras (WER) menor, o que significa que cometem menos erros no reconhecimento de palavras faladas em comparação com as soluções anteriores.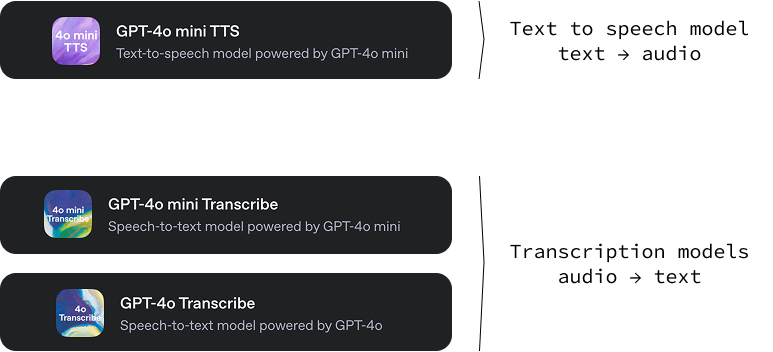
Esses novos modelos vêm com os seguintes preços:

Neste tutorial, orientarei você na criação de um assistente de voz com IA diretamente no seu terminal. Esse assistente de voz imitará essencialmente um modelo popular de IA baseado em texto, mas interagirá inteiramente por meio da linguagem falada. Imagine poder falar diretamente com seu computador, fazer qualquer pergunta que você tenha e receber uma resposta vocal quase instantaneamente.
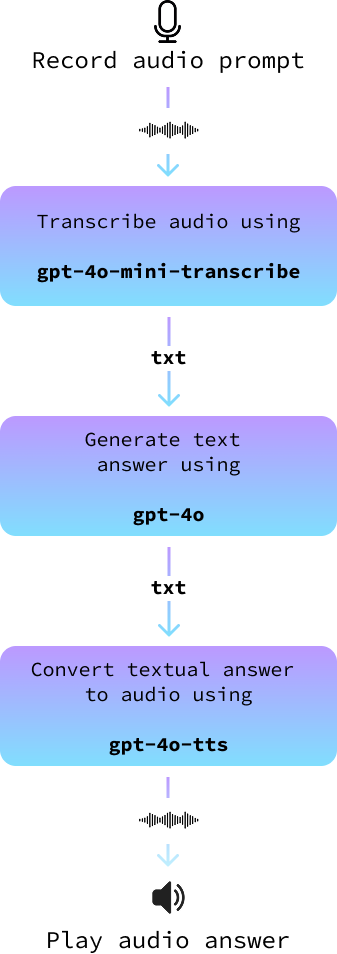
Nosso projeto usará uma arquitetura simples, porém eficaz. Começaremos usando o microfone para capturar o prompt falado por você. Depois de gravada, converteremos essa entrada de áudio em texto com a ajuda de modelos avançados de fala para texto.
Esse texto é então alimentado em um modelo de linguagem grande para gerar uma resposta adequada. Por fim, converteremos a resposta de texto novamente em áudio, permitindo que o assistente "fale" a resposta para você. Cada etapa desse processo foi projetada para garantir que nosso assistente de voz seja preciso e envolvente.
Embora a OpenAI ofereça uma API em tempo real dedicada que pode aprimorar as interações ao simplificar todo o processo, optaremos por uma abordagem diferente. A API em tempo real, embora impressionante e perfeita para desenvolvedores que buscam integrações rápidas, geralmente é mais cara e oferece menos flexibilidade.
Ao optar por criar nosso projeto usando componentes separados para cada etapa, obtemos maior controle sobre a personalização do nosso assistente de IA. Essa abordagem nos permite decidir os modelos que queremos usar, otimizando assim as necessidades específicas, sejam elas de precisão, velocidade ou preferência no tom de resposta. Dessa forma, nosso assistente de voz se torna não apenas uma ferramenta poderosa, mas também altamente personalizada, capaz de atender aos requisitos exclusivos do projeto.
Todo o código que desenvolvemos aqui está disponível em neste repositório do GitHub.
Para começar, primeiro configuraremos um novo ambiente do Anaconda chamado audio-demo. Os ambientes do Anaconda nos permitem criar espaços isolados para cada projeto, nos quais podemos instalar versões específicas de pacotes sem conflitos. Execute os seguintes comandos em sua interface de linha de comando:
conda create -n audio-demo -y python=3.9
conda activate audio-demo
pip install openai
pip install numpy
pip install dotenv
pip install sounddevice
pip install scipyVamos detalhar o que cada comando e pacote faz:
conda create -n audio-demo -y python=3.9: Esse comando cria um novo ambiente chamado audio-demo com a versão 3.9 do Python. O sinalizador -y concorda automaticamente com as instalações do pacote sem solicitar.conda activate audio-demo: Ativa o ambiente audio-demo recém-criado, para que você possa trabalhar nele.pip install openai: O OpenAI é uma biblioteca que fornece acesso fácil aos modelos e APIs do OpenAI.pip install numpy: O NumPy é uma biblioteca essencial para a computação numérica.pip install dotenv: O Dotenv ajuda a carregar variáveis de ambiente de um arquivo .env, tornando o gerenciamento de configuração mais fácil e seguro.pip install sounddevice: O Sounddevice nos permite gravar e reproduzir sons usando funções simples, o que é ideal para lidar com entrada e saída de áudio em Python.pip install scipy: O SciPy baseia-se no NumPy e oferece funcionalidade adicional para computação científica e técnica, como processamento de sinais. No nosso caso, vamos usá-lo para armazenar o arquivo de áudio.Com nosso ambiente audio-demo configurado, estamos prontos para começar a trabalhar em nosso assistente de IA que pode processar entradas de áudio. Essa configuração estruturada nos ajuda a manter um espaço de desenvolvimento limpo, garantindo que todas as dependências estejam no lugar para o nosso projeto.
Para usar a API da OpenAI, você precisa de uma chave de API. Acesse a sua página de chave de API e gere uma chave de API clicando no botão "Generate new secret key" (Gerar nova chave secreta). Copie a chave, crie um arquivo chamado .env e cole-o lá com o seguinte formato:
OPENAI_API_KEY=<paste_your_api_key_here>Vamos percorrer as etapas para que você crie um script Python que use os recursos de texto para áudio da OpenAI, transformando texto em fala com um toque personalizado. Escrevemos nosso código em um arquivo chamado text_to_audio.py na mesma pasta que o arquivo .env..
Primeiro, precisamos importar as bibliotecas necessárias que farão parte do nosso script:
import asyncio
from openai import AsyncOpenAI
from openai.helpers import LocalAudioPlayer
from dotenv import load_dotenvVamos examinar rapidamente o que cada uma dessas importações faz:
asyncio: Essa biblioteca é necessária para que você possa escrever código assíncrono em Python, o que é essencial para trabalhar com APIs de streaming.AsyncOpenAI: Parte da biblioteca OpenAI, fornece ferramentas para você interagir com as APIs da OpenAI de forma assíncrona.LocalAudioPlayer: Esse auxiliar da OpenAI nos permite reproduzir áudio localmente em nosso computador.load_dotenv: Carrega variáveis de ambiente do arquivo .env, que é onde armazenamos informações confidenciais, como nossas chaves de API.Em seguida, carregamos nossa chave de API do arquivo .env usando a função load_dotenv:
load_dotenv()Isso garante que nosso script tenha acesso seguro à chave da API.
Criamos uma instância de AsyncOpenAI para que você comece a interagir com a API da OpenAI:
openai = AsyncOpenAI()Agora definimos nossa função principal, text_to_audio(), que usará o recurso de conversão de texto em áudio da OpenAI para processar a entrada e reproduzir o áudio resultante:
async def text_to_audio(text, tone_and_style_instructions):
async with openai.audio.speech.with_streaming_response.create(
model="gpt-4o-mini-tts",
voice="coral",
input=text,
instructions=tone_and_style_instructions,
response_format="pcm",
) as response:
await LocalAudioPlayer().play(response)Vamos explicar rapidamente o que fizemos acima:
model e voice para controlar a síntese da fala. O site model usado é gpt-4o-mini-tts e a voz selecionada é "coral".response_format está definido como "pcm", adequado para processamento de áudio.LocalAudioPlayer reproduz a resposta de áudio gerada pela API.Completamos o script com as seguintes linhas para garantir que a função text_to_audio() seja executada quando o script for executado:
if __name__ == "__main__":
asyncio.run(text_to_audio("Hello world!", "Enthusiastic voice."))Esse bloco de código verifica se o script é o módulo principal que está sendo executado e executa a função text_to_audio() usando asyncio.run() para lidar com a lógica assíncrona.
Com essas etapas, nosso script está pronto para converter a entrada de texto em fala usando o serviço de texto para áudio da OpenAI. Essa configuração nos permite fazer experiências com diferentes entradas e estilos, dando vida ao texto por meio do som.
Podemos executar o script usando o comando:
python text_to_audio.pyO código completo pode ser encontrado aqui.
Nesta seção, vamos explorar como transcrever um arquivo de áudio em texto usando a ferramenta de transcrição de áudio da OpenAI. Nosso script foi projetado para lidar com arquivos de áudio de forma assíncrona para tornar o processo eficiente e rápido. Implementaremos esse script em um arquivo chamado audio_to_text.py.
As importações e a configuração inicial são as mesmas de antes, exceto pelo fato de não precisarmos importar o LocalAudioPlayer aqui. Veja como podemos escrever uma função que transcreve um arquivo de áudio:
async def transcribe_audio(audio_filename = "audio.wav"):
audio_file = await asyncio.to_thread(open, audio_filename, "rb")
stream = await openai.audio.transcriptions.create(
model="gpt-4o-mini-transcribe",
file=audio_file,
response_format="text",
stream=True,
)
transcript = ""
async for event in stream:
if event.type == "transcript.text.delta":
print(event.delta, end="", flush=True)
transcript += event.delta
print()
audio_file.close()
return transcriptVamos detalhar o que acontece aqui:
audio_file = await asyncio.to_thread(open, audio_filename, "rb"): Essa linha abre o arquivo de áudio no modo de leitura binária ("rb"). O método asyncio.to_thread() permite que essa operação de abertura de arquivo seja executada em uma thread separada, evitando que ela bloqueie outras partes do programa.stream = await openai.audio.transcriptions.create(...): Essa linha chama a API de transcrição. model como gpt-4o-mini-transcribe, projetado especificamente para tarefas de transcrição.file contém nosso arquivo de áudio aberto.response_format="text" diz à API para retornar a transcrição como texto.stream=True é usado para transmitir a transcrição em tempo real, o que significa que, assim que uma parte do áudio é processada, ela é imediatamente retornada, acelerando a resposta.async for event in stream: Inicia um loop para ler eventos do fluxo de transcrição à medida que eles ocorrem.if event.type == "transcript.text.delta":: Verifica cada tipo de evento e o processa se for do tipo transcript.text.delta, o que indica que uma parte da transcrição está pronta.print(event.delta, end="", flush=True): Imprime a transcrição incremental à medida que ela se torna disponível, garantindo que nossa saída seja em tempo real.audio_file.close(): Depois de concluir a transcrição, é uma boa prática fechar o arquivo de áudio para liberar recursos do sistema.Ao executar a função main(), podemos converter um arquivo de áudio em texto de forma eficiente e processá-lo em um fluxo contínuo para obter feedback imediato. Essa configuração é ideal para aplicativos que precisam de transcrição rápida ou que envolvem arquivos de áudio longos.
Você pode experimentá-lo colocando um arquivo de áudio na mesma pasta que o script, substituindo audio.wav pelo nome do arquivo de áudio e executando o comando:
python audio_to_text.pyO código completo pode ser encontrado aqui.
Como nosso objetivo é criar um assistente de voz, precisamos gravar o prompt de áudio do usuário em um arquivo de áudio.
Criaremos um novo arquivo chamado record.py com uma função chamada record_audio. Essa função captura o som do microfone e o salva como um arquivo de áudio. Não entraremos em muitos detalhes sobre como ele funciona porque esse não é o foco principal deste artigo:
import sounddevice as sd
import numpy as np
import scipy.io.wavfile as wavfile
SAMPLE_RATE = 44100 # Sample rate in Hz
def record_audio():
print("[INFO: Recording... Press <Enter> to stop]")
audio_data = [] # Initialize a list to store audio frames
def callback(indata, frames, time, status):
audio_data.append(indata.copy())
with sd.InputStream(samplerate=SAMPLE_RATE, channels=1, callback=callback, dtype='int16'):
input() # Wait for the user to press Enter to stop recording
print("[INFO: Recording complete]")
print()
audio_data = np.concatenate(audio_data) # Concatenate the list into a single array
filename = "output.wav"
wavfile.write(filename, SAMPLE_RATE, audio_data)
return audio_dataQuando chamarmos essa função, ela iniciará a gravação do microfone do usuário. Ele aguarda até que o usuário pressione "Enter" e, em seguida, salva o áudio em um arquivo com o nome de arquivo fornecido.
Para testar isso, podemos combinar essa função com a função de transcrição acima para transcrever uma mensagem falada pelo usuário. Veja como podemos criar um novo arquivo chamado record_and_transcribe.py para implementar isso:
import asyncio
from audio_to_text import transcribe_audio
from audio_recorder import record_audio
async def main():
record_audio("prompt.wav")
await transcribe_audio("prompt.wav")
if __name__ == "__main__":
asyncio.run(main())Você pode tentar executá-lo usando o comando python record_and_transcribe.py. O script gravará o que você disser até que você pressione "Enter" e, em seguida, transcreverá o que você disse.
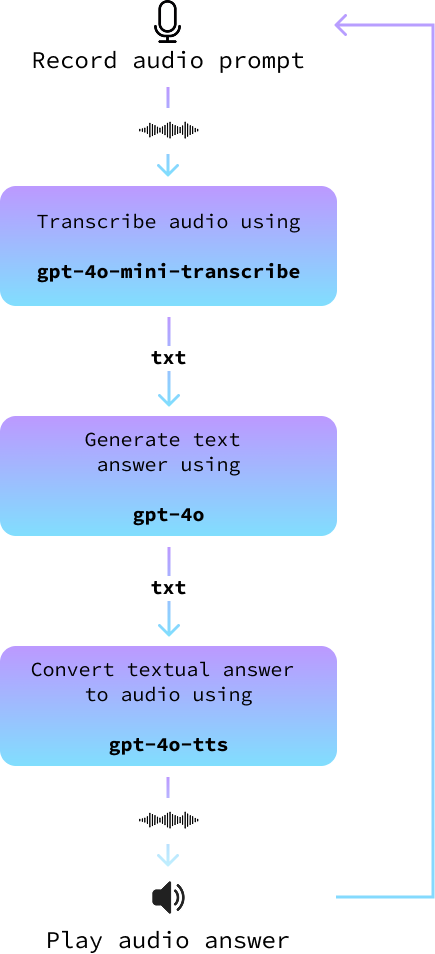
Nesta seção, juntamos tudo isso para criar um assistente de áudio. Nós o implementamos em um novo arquivo chamado audio_assistant.py seguindo estas etapas:
record_audio().transcribe_audio().gpt-4o, para gerar uma resposta.text_to_audio().O diagrama a seguir ilustra isso:
Recomendo que você tente construí-lo por conta própria antes de continuar lendo.
Primeiro, importamos as funções que implementamos anteriormente e inicializamos o cliente OpenAI.
# Import the functions we created
from text_to_audio import text_to_audio
from audio_to_text import transcribe_audio
from audio_recorder import record_audio
# Import other dependencies and initialize OpenAI
import asyncio
from openai import AsyncOpenAI
from dotenv import load_dotenv
load_dotenv()
openai = AsyncOpenAI()Então, precisamos de uma função para gerar a resposta. Isso usa a API GPT normal da OpenAI com um modelo como gpt-4o ou qualquer outro modelo de texto para texto. Se você for novo no assunto, talvez queira conferir este Tutorial da API do GPT-4o.
Aqui está uma implementação assíncrona dessa função:
async def get_answer(prompt):
stream = await openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt}
],
stream=True,
)
answer = ""
async for chunk in stream:
content = chunk.choices[0].delta.content
if content is not None:
answer += content
print(content, end="", flush=True)
print("\n\n")
return answerPara implementar o loop principal, seguimos as etapas descritas acima:
async def main(tone_and_style_instructions):
await text_to_audio("Hello, how can I help you today?", tone_and_style_instructions)
while True:
record_audio("prompt.wav")
prompt = await transcribe_audio("prompt.wav")
print()
answer = await get_answer(prompt)
await text_to_audio(answer, tone_and_style_instructions)Por fim, executamos o loop principal quando o script é executado:
if __name__ == "__main__":
tone_and_style_instructions = "Enthusiastic voice."
asyncio.run(main(tone_and_style_instructions))Aqui está uma demonstração dele em ação:
Aprenda IA com estes cursos!
Programa
Curso
Curso
Tutorial
Zoumana Keita
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan



